小企业信用模型评价及信用风险评估:基于流水数据的视角-西财博士毕业论文
大家好我是toby老师,今天为大家分享一篇西财博士毕业论文-小企业信用模型评价及信用风险评估。这篇文章提出当企业财报“失灵”,银行如何用流水数据破解小企业信用风险?这篇文章为后人研究提供了大量宝贵数据参考。我方公司专业从事企业建模,期刊论文专利定制服务。具体场景包括:个人信用贷款违约风控模型,企业信用贷款违约风控模型,债券违约预测模型,政府信用评级模型,股票价格预测模型,房价预测模型。

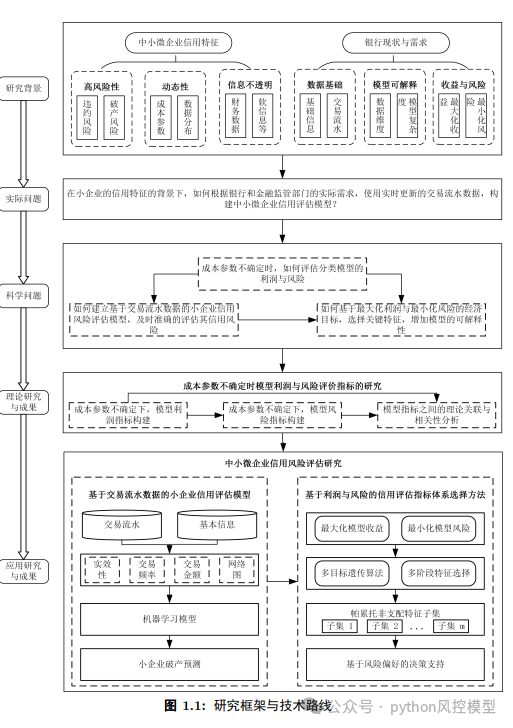
背景
中小微企业贡献了我国60%以上的GDP和80%的就业,但“融资难”始终是悬在它们头顶的一把剑。西南财经大学徐雍的博士论文《小企业信用模型评价及信用风险评估:基于流水数据的视角》,为这一难题提供了新的解题思路。
这篇论文的核心判断简洁有力:中小微企业财务数据缺失、不可靠,且信用风险具有明显的动态性和突发性,导致传统基于静态财务数据的信用评估模型失效。而银行恰恰坐拥一座尚未充分挖掘的“数据金矿”——实时更新的企业交易流水数据。作者的破题路径由此展开:用流水数据替代财务数据,同时重新设计一套兼顾“利润”与“风险”的模型评价和特征选择体系。
关键词
信用评分,模型评价指标,特征选择,现金流水数据,条件在险价值,模型利润,模型风险
重新定义“好模型”:当成本参数不再确定
传统的信用评分模型评价指标,比如AUC、KS值,衡量的是模型区分“好企业”和“坏企业”的能力。但银行真正关心的是:用这个模型放贷,能赚多少钱?会不会出现极端亏损?
论文第三章直指一个现实痛点:小企业信用风险随经济环境动态变化,导致衡量模型经济损失的“成本参数”难以准确估计。比如经济上行时,企业违约少、损失低;经济下行时,即使同一个模型,放贷亏损也可能大幅飙升。如果银行假设成本参数是固定不变的,就可能在不知不觉中高估利润、低估风险。
作者的解决方案颇具巧思:引入鲁棒优化的思想,提出“极端情况下的期望最小成本”(WEMC)和“极端情况下的条件在险价值”(WCVaR)两个新指标。通俗地说,WEMC回答的是“最坏情况下模型能带来多少利润”,WCVaR回答的是“极端糟糕时可能亏多少”。这两个指标让银行对信用评分模型的评价,从“看平均表现”升级为“看底线风险”。
论文还通过12个真实信用数据集的实验验证了新指标的合理性。一个有趣的发现是,当银行对成本参数了解越少、波动越大时,新指标与传统指标(如AUC)的差异就越显著,此时银行尤其需要单独衡量模型风险,而非简单用AUC“一刀切”。
流水数据:被忽视的信用“指纹”
第四章是论文最具应用价值的部分。作者与合作银行合作,获取了涵盖17万家小企业、约2.4亿条现金流水记录的海量数据集,构建了一套完全脱离财务报告的信用风险评估模型。
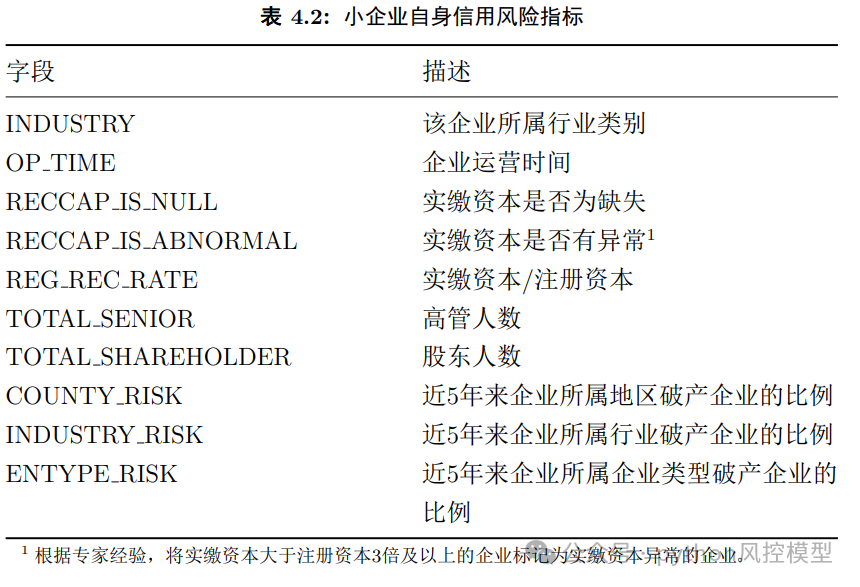
这套模型从三个维度刻画企业风险:企业自身特征(行业、经营年限、注册资本等)、企业关联网络特征(股东/高管关联、交易往来关系)、以及交易流水本身的特征(近期交易频率、金额、净流入等)。
实验结果显示,加入交易流水特征后,模型预测小企业破产的AUC值从0.62提升至0.72以上,提升幅度约16%;模型带来的利润提升了数倍。在线上真实环境中测试,效果同样稳健。
论文进一步分析了为何流水数据能显著提升预测效果。交易流水实时更新,反映企业最新的经营脉搏,而财务报告只是过去一年的“静态快照”;流水数据由银行直接记录,真实可靠,企业无法轻易伪造。此外,作者构建的企业交易网络能捕捉到供应链上下游的风险传导——一个企业的客户或供应商大量倒闭,往往意味着它自己也岌岌可危。
“既要赚钱,又要安全”:多目标特征选择的智慧
第四章虽然提升了预测效果,但引入大量流水特征后,模型变得臃肿复杂,不利于理解和监管。第五章由此切入一个实际问题:如何在成百上千个特征中,筛选出既能最大化利润、又能最小化风险的关键指标?
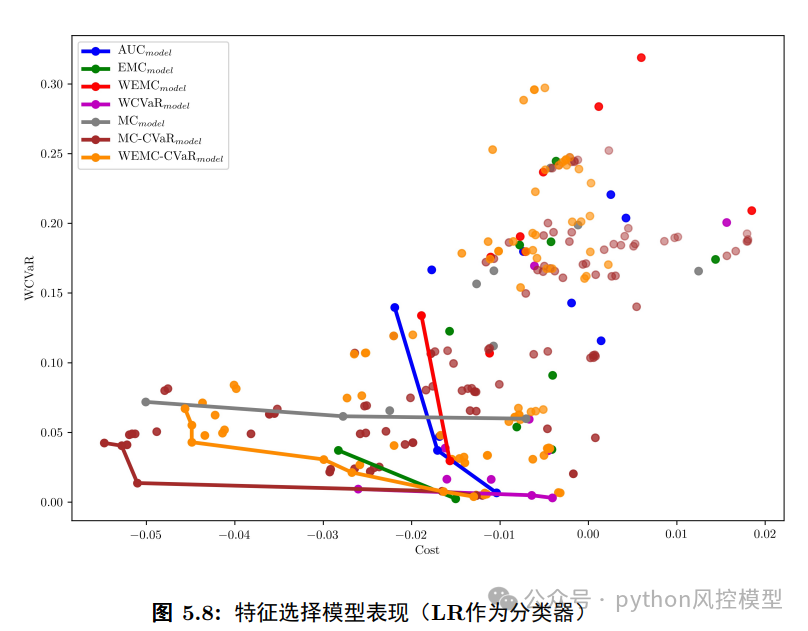
作者提出了一套两阶段多目标特征选择算法。第一阶段“粗筛”,用过滤法剔除无关特征;第二阶段“精选”,用遗传算法同时优化利润和风险两个目标,输出一组“帕累托最优解集”。这意味着银行可以根据自身风险偏好做选择:激进型的选利润最高的方案,保守型的选风险最低的方案。
实验对比发现,两阶段方法比直接在原始数据上做特征选择,能将特征维度从近50个压缩至25-30个,同时模型表现不降反升。多目标算法的解,在多数情况下能同时做到利润更高、风险更低,优于单独优化AUC或单独优化利润的传统方法。
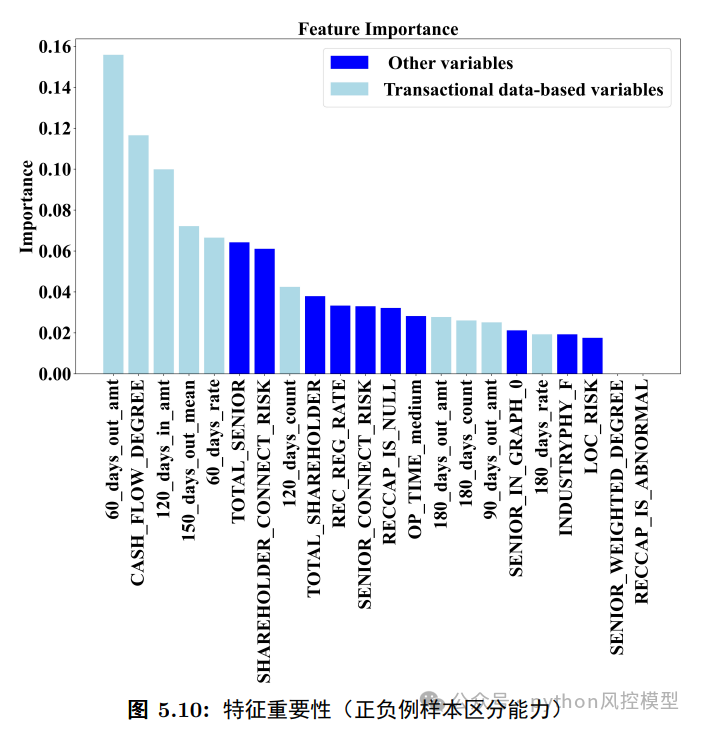
特征重要性分析还揭示了一个关键结果:在所有特征中,对模型利润和风险影响最大的,几乎全部来自交易流水数据。尤其是“交易网络中的节点度”(即与这家企业有交易往来的其他企业数量),在各项重要性排名中都高居榜首——客户的多样性和交易活跃度,本身就是企业健康度的有力信号。
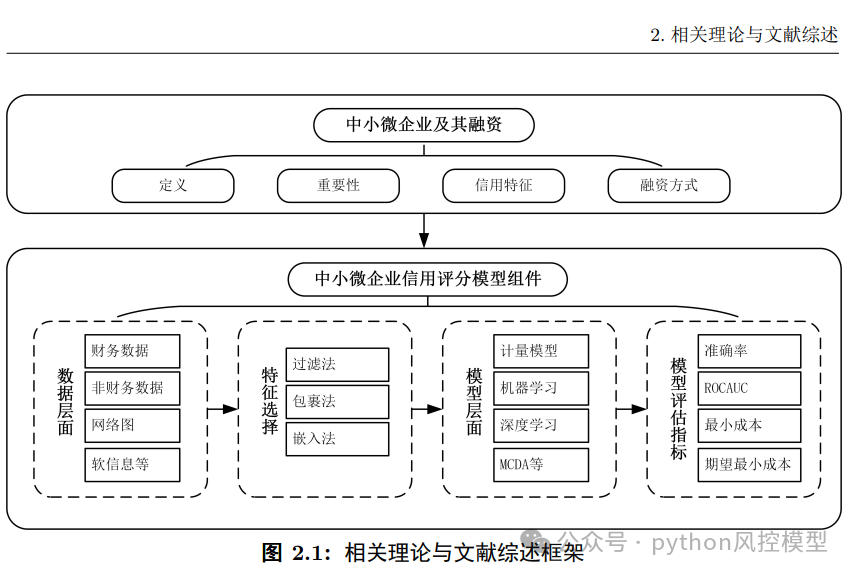
中小企业信用风险指标



实证分析详细描述
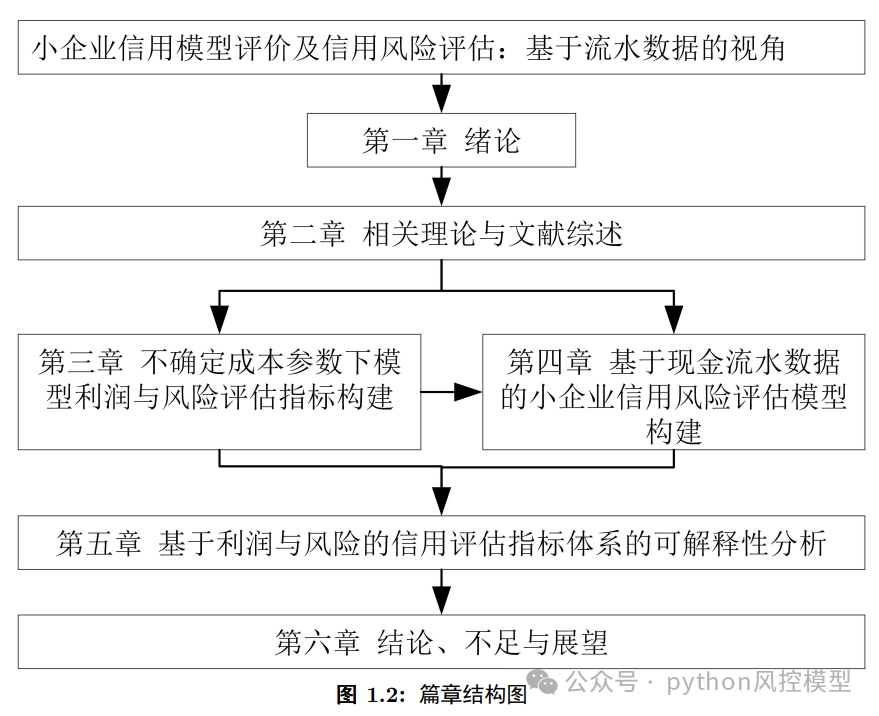
该论文的实证分析围绕三个核心研究内容展开,分别对应第三、四、五章,形成了从模型评价指标构建、信用评估建模到特征选择的完整实证链条。
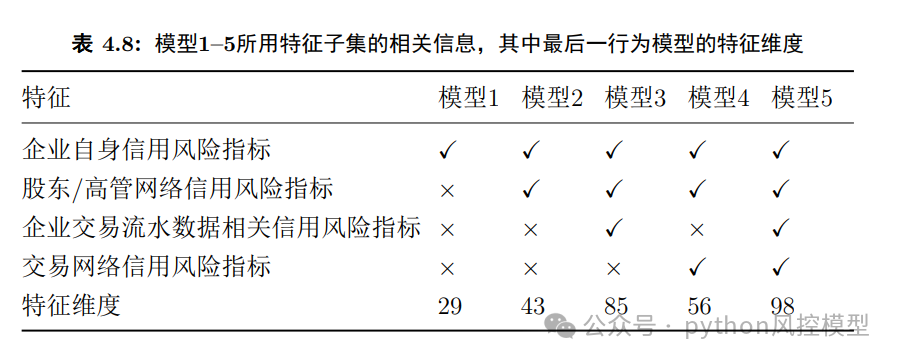
一、成本参数不确定下的模型利润与风险指标验证
该部分实证旨在验证论文第三章提出的WEMC(极端情况期望最小成本)和WCVaR(极端情况条件在险价值)两个新指标的合理性。研究选取了12个信用评估领域常用的公开数据集,涵盖不同样本量和违约率。在此基础上,使用逻辑回归、随机森林、XGBoost等7大类共18个分类器,对每个模型分别计算新指标与AUC、精准率、召回率等传统指标下的表现排名,再计算不同指标排名的相关性。
结果发现,WEMC与AUC的平均相关系数为0.87,整体呈正相关。但当成本收益比增大或成本参数波动加剧时,新指标与传统指标的差异显著扩大,意味着此时若仅用AUC评价模型,可能选错方案。这验证了在成本参数不确定时引入新指标的必要性。
二、基于交易流水数据的小企业破产预测模型构建
如果说第一部分是方法论验证,这部分就是论文的核心应用。作者与合作银行合作,获取了约17万家小企业、2.4亿条现金流水记录。以企业是否破产为预测目标,提取三层次特征:企业自身信用风险指标(行业、经营年限、注册资本等)、企业关联网络特征(股东/高管网络和交易网络的节点度、PageRank值、邻居企业破产率等)、交易流水特征(近期30至180天现金流入流出总量、交易笔数、平均金额等)。
实验设计了5个特征组合递增的对比模型:模型1仅用企业自身特征,模型2加入股东/高管网络特征,模型3进一步加入流水特征,模型4改为加入交易网络特征,模型5纳入所有特征。使用逻辑回归、XGBoost等7个分类器,并进行线下和线上两阶段测试。
结果清晰:仅用传统特征训练时平均AUC约0.62;加入流水特征后平均AUC达0.72,提升约16%;综合所有特征后平均AUC达0.79。在利润指标上,模型5比模型1的利润提升近8倍。从经济学角度解释,交易流水反映了企业近期真实运营脉搏,交易网络中的节点度(即客户和供应商数量)是企业健康度的强信号,这些都是传统数据难以捕捉的。
三、基于利润与风险的两阶段多目标特征选择
第四章虽然提升了模型表现,但引入大量特征后模型臃肿、难以解释。第五章将银行放贷时“既要多赚钱、又要少担险”的经营目标,直接嵌入特征筛选过程。
算法分两阶段:第一阶段用过滤法基于特征与标签相关性排序,通过改进的0.618优选法剔除无关和冗余特征;第二阶段用NSGA-II多目标遗传算法,同时优化WEMC(利润)和WCVaR(风险)。与单目标不同,多目标算法输出一组“帕累托最优解集”,每个解代表一种特征组合方案,银行可根据风险偏好选择。
实验对比发现,两阶段方法将特征维度从近50个压缩至25-30个,预测效果不降反升,优于直接在原始数据上做特征选择的单阶段方法。多目标算法得到的解在多数情况下能同时做到利润更高、风险更低,优于单独优化AUC或单独优化利润的传统方案。特征重要性分析显示,交易网络中的节点度(CASH_FLOW_DEGREE)在三项重要性排名中都居榜首,近期现金流入总量、交易频次等流水特征也位居前列,验证了流水数据在风险评估中的核心价值。
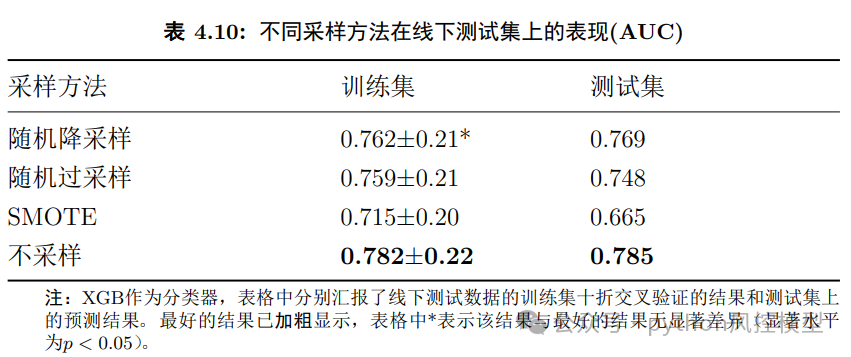
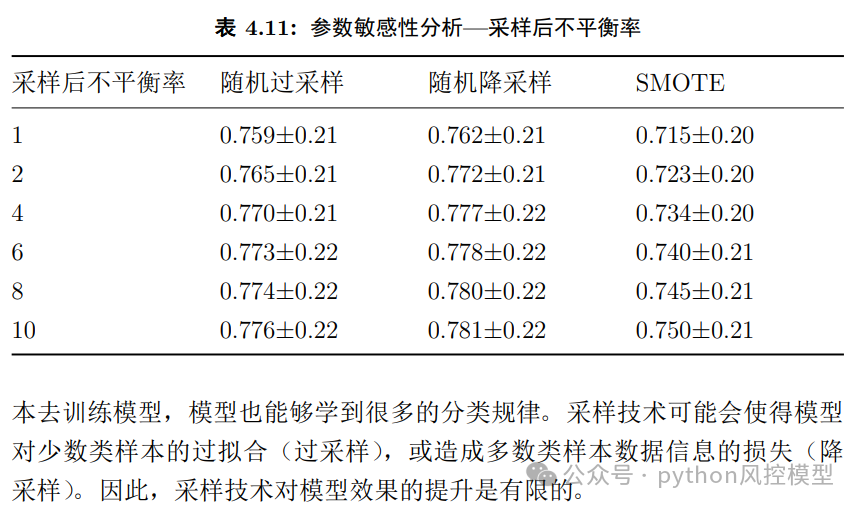
四.非平衡数据处理
作者发现该实证分析中非平衡数据处理带来收益不大,作者非常坦诚。
五,多算法比较
作者发现xgboost模型算法最优,当然比xgboost性能好的模型还有很多,这环节还有提升空间。
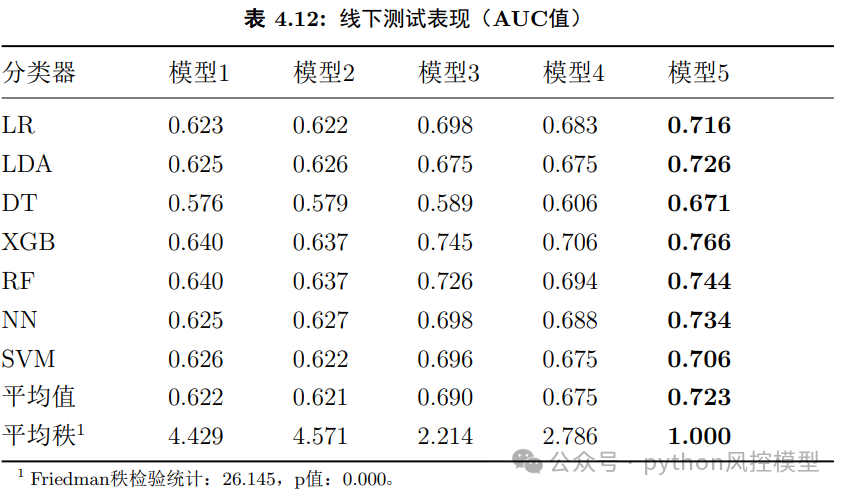
实证分析汇总,变量重要性分析展示交易流水变量在识别企业信用风险中非常重要。
创新点汇总
回顾这篇论文,可以提炼出以下创新之处:
第一,模型评价指标创新。 在成本参数分布信息部分可知的条件下,首次提出WEMC和WCVaR两个指标,分别衡量模型利润和风险,刻画了成本参数不确定性带来的影响,为信用评分模型的风险管理提供了量化工具。
第二,数据源的创新应用。 系统验证了交易流水数据在小企业破产预测中的价值,证明在没有财务报告的情况下,流水数据同样能建立有效的信用评估模型,对银行来说更易获取、更实时、更可靠。
第三,特征选择方法的创新。 提出两阶段多目标特征选择框架,将银行“最大化利润、最小化风险”的经营目标直接嵌入特征筛选过程,同时兼顾模型可解释性,输出可供银行按需选择的风险-收益权衡方案。
第四,对异质性的深入分析。 从企业自身特征、关联网络、交易行为三个层次构建指标体系,揭示了交易网络中的社区风险传导和节点位置对信用风险的影响。
点评:从理论到落地的距离与可能性
这篇论文完成于2021年,相比第一篇论文(2012年),显著体现了大数据和机器学习技术对信用风险研究的渗透。
从学术价值看,论文的理论创新集中于第三章的模型评价指标。将鲁棒优化和条件在险价值引入信用评分模型评价,拓展了基于利润的分类模型评价体系。从应用价值看,论文基于17万家企业的真实流水数据,且通过了银行的线上测试,可信度和可操作性较高。
然而,研究也存在局限。论文坦承未能与基于财务数据的模型做直接对比,因此“流水数据优于财务数据”的结论更多是基于数据特性的推断,而非严格的实证比较。此外,流水数据只能反映企业在合作银行账户内的交易,如果企业在多家银行开户,单家银行看到的只是“冰山一角”。论文对模型可解释性的分析也停留在特征重要性层面,未深入探讨关键变量与破产之间的因果关系。
与第一篇论文对照来看,两篇研究形成了一个有趣的互补。第一篇论文的核心贡献在于证明“非财务信息(公司治理指标)能提升中小企业信用风险度量的准确性”;第二篇论文则在此基础上更进一步,证明了“交易流水这类新型数据甚至可以在没有财务报告的情况下独立完成信用评估”。两篇论文共同指向一个趋势:中小企业信用评估正在从依赖“硬信息”(财务报表)转向挖掘“软信息”(治理结构)和“行为数据”(交易流水),数据维度越丰富,风险评估就越精准。
值得深思的是,论文提出的WEMC和WCVaR指标虽然理论完备,但实际应用中需要银行对成本参数的不确定集做出设定,这对一线业务人员可能是较高的门槛。如何将复杂的鲁棒优化模型封装成简单易用的工具,是理论走向实践必须跨越的鸿沟。论文提出的多目标特征选择算法为银行提供了利润与风险的灵活权衡,但如果银行自身对风险偏好缺乏清晰界定,再精巧的工具也可能难以发挥效用。
受到宏观经济下滑,AI取代人类大量工作后,很多企业订单下降,交易流水下降。但交易流水下降这并不意味着该企业信用风险高。因此评估企业信用风险还是要结合财务数据,流水数据,逾期分析等多个维度分析才更稳健。论文的建模场景就是“财务数据缺失”,且自认为模型“不依赖于”财务数据。无法区分风险是由企业自身经营恶化(特质风险)引起的,还是由外部环境冲击(系统性风险)引起的。
和财务数据一样,企业流水数据同样可以造假。很多骗取银行贷款企业通过构造多家空壳公司互相汇款制造流水交易。如何识别虚假流水也是可以继续深挖。
信用风险的两个主要维度是还款能力和还款意愿。在经济下滑环境下,企业交易流水大幅减少,但负债率低或无负债或有大量财富累积企业仍然是信用优质企业。
银行需要的是能识别出“逆境中仍具还款能力”的客户,而非一刀切地收缩对所有交易量下滑企业的授信。
总的来说,这篇论文为小企业信用风险评估提供了从数据、模型到指标选择的完整方案。它告诉银行,当企业财报不可信时,不妨去看看它的流水账单——那里或许藏着比财务报表更真实的经营密码。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)