从零开始学AI15——K-近邻
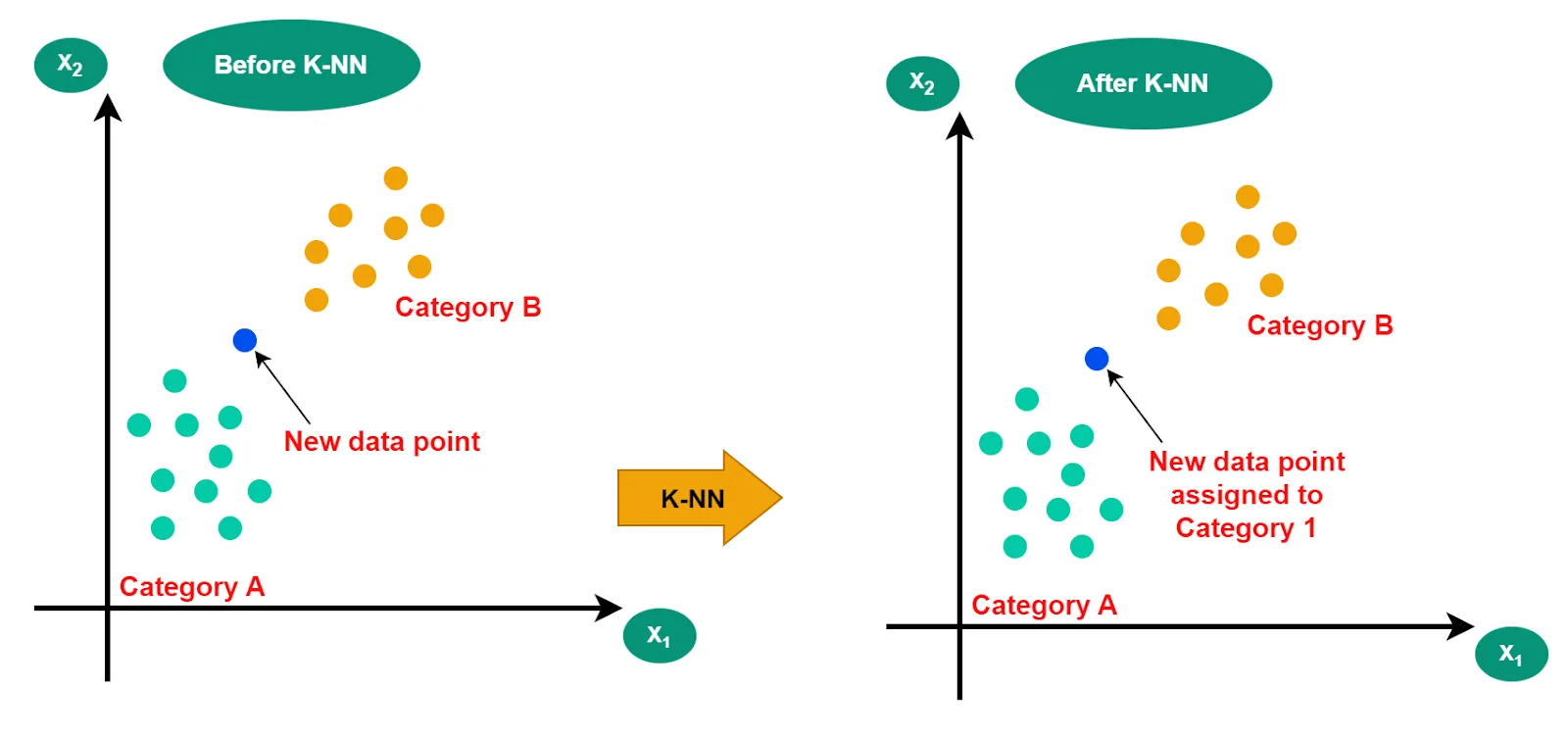
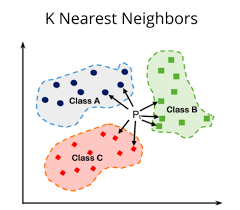
简单理解
K近邻算法 (K-Nearest Neighbors, KNN), 绝对是机器学习里最接地气、最好懂的算法,没有之一。
如果用一句中国古话来概括它,就是:“物以类聚,人以群分”。
或者更通俗一点:“看一个人怎么样,看他的朋友就知道。”
1. 核心逻辑:随大流
想象一下,你作为一个**“未知身份的新点”**,突然掉进了一个聚会里。
- 左边一堆穿球衣的(A类:运动员)。
- 右边一堆戴眼镜抱书本的(B类:学霸)。
你想知道自己属于哪一类,怎么办?KNN 的办法非常简单粗暴:
- 量距离:拿把尺子,看看离你最近的几个人是谁。
- 数人头:假设你只看离你最近的 3 个人(这就是 K=3)。
- 搞投票:
- 如果这 3 个人里,有 2 个是学霸,1 个是运动员。
- 结论:少数服从多数,那你肯定也是个学霸。
这就是 KNN 的全部秘密。它不需要算复杂的公式,不需要画线,全靠比谁离得近。
2. 那个关键的 "K" 是什么?
K 就是**“你要参考多少个邻居的意见”**。这个数字选多少,非常有讲究:
-
如果 K=1(墙头草):
- 你只看离你最近的那 1 个人。
- 风险: 如果离你最近的那个人恰好是个卧底(噪声数据/异常点),那你直接就被带沟里去了。这叫过拟合,太容易受个别极端分子的影响。
-
如果 K=100(随大流):
- 你一下子看周围 100 个人。
- 风险: 范围划得太大,可能把很远很远、跟你没啥关系的人也算进来了。最后变成了“谁在这个区域人多谁就赢”,忽略了局部的特征。这叫欠拟合。
-
最佳实践:
- 通常 K 会选一个比较小的奇数(比如 3、5、7),这样投票时不会出现平票的尴尬。
3. KNN 的一个大特点:最懒的学渣
在机器学习界,KNN 被称为**“懒惰学习”(Lazy Learning)**。
- 别的算法(勤奋型): 拿到数据(课本)后,拼命学习,总结出一套公式(模型),然后把课本扔了。考试时直接套公式。
- KNN(懒惰型): 平时根本不学习,也不总结公式,就把数据(课本)背在身上。
- 考试时: 遇到一道新题,它赶紧翻开背后的课本,一行一行比对:“哎,这道题跟书上第 5 页那道题很像,那答案应该也差不多!”
后果:
- 训练快: 因为它根本不训练,基本是秒完成。
- 预测慢: 每次来个新数据,它都要把所有老数据重新算一遍距离,累得半死。
总结
KNN 就是一个没有主见的家伙。
当它不知道自己是谁时,它就问离它最近的 K 个邻居:“哎,你们是什么成分?”
邻居们回答:“我们大部分是好人。”
KNN 就说:“好,那我也当个好人。”
应用场景
1. KNN (K-Nearest Neighbors)
角色:新来的插班生
任务:分类 (Classification) 或 回归 (Regression)
核心问题: “我是谁?我属于哪一派?”
应用场合:
当你手里已经有了一堆贴好标签的数据(也就是你需要先知道谁是好人、谁是坏人),然后来了一个新数据,你想知道这个新数据属于哪一类。
- 推荐系统(简化版):
- 场景: 用户 A 喜欢看《战狼》、《红海行动》。新来个用户 B,也看了《战狼》。
- KNN逻辑: 找跟 B 最像的 5 个用户(邻居),发现他们都看了《红海行动》,所以给 B 推荐《红海行动》。
- 手写数字识别:
- 场景: 写了一个潦草的“5”。
- KNN逻辑: 在数据库里找跟这个字长得最像的 10 张图,发现有 9 张标签是“5”,1 张是“6”,那这个字就是“5”。
- 房价预测(回归问题):
- 场景: 估算一套新房子的价格。
- KNN逻辑: 找附近 3 公里内、面积户型最接近的 5 套刚成交的房子,算算它们的平均价,就是这套房子的估价。
一句话总结 KNN: 已知阵营,新兵入列。
2. DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
角色:拓荒者 / 警察扫黄打非
任务:聚类 (Clustering)
核心问题: “这堆乱七八糟的人里,有哪些小团伙?还有哪些是独行侠?”
与 KNN 的最大区别: DBSCAN 手里的数据没有标签。它不知道谁是好人坏人,它只管把凑得近的人圈成一个圈子。
应用场合:
当你有一堆杂乱无章的数据,想发现其中的结构或异常时。
- 地图上的热点区域分析(外卖/打车):
- 场景: 地图上有成千上万个打车点。
- DBSCAN逻辑: 设定一个半径(比如 100米)和最小人数(比如 5人)。它会自动把密密麻麻的打车点圈成一个个“商圈”或“小区”。那些孤零零散落在郊区的点,会被它标记为噪音(Noise)。
- 异常检测 / 反欺诈(抓独行侠):
- 场景: 银行信用卡交易流水。
- DBSCAN逻辑: 正常人的消费习惯会聚集成一团(比如都在某城市、某时段)。如果突然出现几个点,离所有的大团伙都很远(比如凌晨 3 点在国外刷了一笔巨款),DBSCAN 会直接把它们踢出来,标记为异常点。
- 优势: 它不需要你预先告诉它有几类人,它能自动发现奇形怪状的团伙。
- 社交网络社群发现:
- 场景: 微博上的关注关系。
- DBSCAN逻辑: 自动把互相关注紧密的人圈成一个“饭圈”或“兴趣小组”。
一句话总结 DBSCAN: 未知阵营,自动画圈,顺便抓出捣乱分子。
3. 对比总结表
| 特性 | KNN (K近邻) | DBSCAN (密度聚类) |
|---|---|---|
| 任务类型 | 监督学习 (有老师教,数据有标签) | 无监督学习 (自学,数据没标签) |
| 核心目的 | 预测新数据的类别 | 发现数据内部的团伙结构 |
| 对待孤独者 | 强行归类 (必须选个最近的邻居) | 标记为噪音 (承认它是离群点,不归类) |
| 谁是它的朋友 | 无论远近,必须要凑够 K 个 | 必须在指定半径内,太远就不算 |
| 典型比喻 | 孟母三迁 (找好邻居) | 警察查房 (把聚众的抓起来,把落单的标出来) |
怎么选?
- 如果你想预测未来,用 KNN。
- 如果你想探索现状(找圈子、找异常),用 DBSCAN。
KNN 的应用场景主要集中在**“已知历史样本,预测新样本”的领域。由于它逻辑简单、效果直观,经常作为基准模型(Baseline)**或者在数据量不大的轻量级应用中使用。
我们把它分为**分类(这是什么?)和回归(这是多少?)**两大类场景。
一、 分类场景 (Classification)
核心逻辑: 看看邻居都是谁,我也跟着是谁。
1. 简单推荐系统 (电商/流媒体)
这是 KNN 最经典的入门应用。
- 场景: “看了这部电影的人也看了……”
- 做法: 把每个用户看成一个点(或者把每部电影看成一个点)。
- User-based KNN: 新用户来了,在数据库里找跟该用户历史行为最像的 KK 个老用户,看看老用户买了啥,就推给新用户。
- Item-based KNN: 用户正在看《哈利波特1》,找跟《哈利波特1》特征最像的 KK 部电影(比如《哈利波特2》、《指环王》),推给用户。
2. 手写数字/文字识别 (OCR的原始版)
- 场景: 邮局自动分拣信件,识别邮政编码。
- 做法: 把每张手写的数字图片看作一个由像素组成的向量。
- KNN: 拿到一个新写的“8”,去图库里比对。发现它跟以前存的 1000 张“8”的图片像素重合度最高(距离最近),所以判定它是“8”。
- 注:虽然现在深度学习(CNN)更强,但 KNN 在简单场景下依然有效。
3. 疾病辅助诊断
- 场景: 判断肿瘤是良性还是恶性。
- 做法: 数据库里有几千个病历,记录了肿瘤大小、纹理、平滑度等特征以及最终确诊结果。
- KNN: 来了一个新病人,测完指标后,去数据库找指标最接近的 KK 个旧病历。如果这几个旧病历大多是恶性,医生就要高度警惕了。
4. 入侵检测/故障诊断 (简单版)
- 场景: 监控服务器日志,判断是否被黑客攻击。
- 做法: 正常访问的数据流特征是很稳定的。
- KNN: 如果突然来了一个访问请求,它的特征(访问频率、包大小)跟数据库里正常的访问记录距离都很远,反而跟已知的攻击记录很近,那就报警。
二、 回归场景 (Regression)
核心逻辑: 看看邻居是多少,算个平均值给我。
1. 房价/二手车估值
- 场景: 类似于“贝壳找房”的估价系统。
- 做法: 你想卖房,输入小区、面积、楼层、朝向。
- KNN: 系统立刻在历史成交库里,找到跟你条件最接近的 KK 套房子(比如最近半年成交的同小区同户型)。把这几套房子的成交价加起来算个平均数(或者根据相似度加权平均),这就是你房子的估值。
2. 缺失值填补 (数据预处理)
- 场景: 做数据分析时,发现有一行数据里“年龄”这一栏空了。直接删掉太可惜,填平均值又太粗糙。
- 做法(KNN Imputation): 看看这一行数据的其他特征(性别、收入、职业)。去数据库里找其他特征跟它最像的 KK 个人,把这几个人的年龄平均一下,填进去。
三、 KNN 什么时候不好用?(避坑指南)
虽然 KNN 听起来很万能,但在以下场景千万别用:
- 数据量特别大时(亿级数据):
- 原因: KNN 是个“懒鬼”,预测一次都要把所有历史数据翻一遍算距离。数据量一在大,它能算到天荒地老,实时性极差。
- 维度特别高时(几千个特征):
- 原因: 也就是所谓的“维度灾难”。在高维空间里,欧氏距离会失效,所有点之间的距离看起来都差不多远,根本分不清谁是近邻。
- 数据极度不平衡时:
- 原因: 比如样本里有 99 个好人,1 个坏人。新来一个坏人,随便抓 KK 个邻居大概率都是好人(因为坏人太少了),导致预测永远偏向多数派。
数学推导
KNN 是机器学习算法中数学推导最少、最简单的一个。它甚至可以说没有“训练推导”过程。
因为它属于 Lazy Learning(懒惰学习):
- 其他算法(如逻辑回归): 训练时要疯狂推导公式(求导、梯度下降),算出一组参数 ww 和 bb。预测时直接用公式 y=wx+by=wx+b 算,很快。
- KNN: 训练时啥也不干,就是把数据存进内存。预测时才开始疯狂计算距离。
所以,KNN 的“数学推导”其实就是**“距离怎么算”和“怎么投票”**这两个数学定义的展示。
第一步:定义距离 (Distance Metric)
KNN 的核心在于判断“谁离我最近”。在数学上,这就是计算两个点(向量)之间的距离。
假设有两个数据点:
- 新样本(未知点): x=(x1,x2,...,xn)
- 老样本(训练点): y=(y1,y2,...,yn)
- nn 代表特征的数量(比如房子的面积、楼层、房龄,那就是 3 维)。
最常用的距离公式有以下几种:
1. 欧氏距离 (Euclidean Distance) —— 最常用
就是我们在中学学的“直线距离”。拿尺子直接量两点间的直线长度。
d(x,y)=∑i=1n(xi−yi)2
- 适用: 连续数值型数据(如身高、体重、房价)。
2. 曼哈顿距离 (Manhattan Distance)
想象你在曼哈顿街区(或者棋盘)上走,不能穿墙,只能走横平竖直的街道。
d(x,y)=∑i=1n∣xi−yi∣d(x,y)=∑i=1n∣xi−yi∣
- 适用: 网格状数据,或者某些对异常值敏感的场景。
3. 闵可夫斯基距离 (Minkowski Distance) —— 通用形式
这是上面两者的爸爸。
d(x,y)=(∑i=1n∣xi−yi∣p)1pd(x,y)=(∑i=1n∣xi−yi∣p)p1
- 当 p=1p=1 时,就是曼哈顿距离。
- 当 p=2p=2 时,就是欧氏距离。
4. 余弦相似度 (Cosine Similarity) —— 看方向
它不看距离远近,只看方向是否一致(夹角大小)。
similarity=cos(θ)=x⋅y∣∣x∣∣⋅∣∣y∣∣similarity=cos(θ)=∣∣x∣∣⋅∣∣y∣∣x⋅y
- 适用: 文本分类、推荐系统。因为在文本中,文章的长度(词频总量)不重要,重要的是内容的侧重(词频分布的方向)。(注意:KNN用的是距离,所以通常用 1−Cosine Similarity1−Cosine Similarity 作为距离)
第二步:决策规则 (Decision Rule)
算出了新样本 xx 和所有老样本的距离后,我们要选出距离最小的 KK 个点,集合记为 Nk(x)Nk(x)。
接下来怎么做决定?数学表达如下:
1. 分类任务 (Classification) —— 多数表决
我们要让这 KK 个邻居投票。
ypred=argmaxc∑xi∈Nk(x)I(yi=c)ypred=argmaxc∑xi∈Nk(x)I(yi=c)
- cc:代表类别(比如猫、狗)。
- I(⋅)I(⋅):指示函数。如果邻居 yiyi 的类别是 cc,就记 1 票,否则记 0 票。
- argmaxargmax:找票数最多的那个类别。
进阶版(加权投票):
离得越近的邻居,话语权越重。
Weighti=1d(x,xi)Weighti=d(x,xi)1
也就是:距离越小,权重越大。最后看谁的加权票数最高。
2. 回归任务 (Regression) —— 平均值
我们要算这 KK 个邻居的平均值。
ypred=1K∑xi∈Nk(x)yiypred=K1∑xi∈Nk(x)yi
进阶版(加权平均):
同样是离得越近,对结果的影响越大。
ypred=∑wiyi∑wiypred=∑wi∑wiyi
总结 KNN 的“数学模型”
如果非要写出 KNN 的数学模型 f(x)f(x),它其实是一个分段函数,把特征空间切得像碎玻璃一样(这叫 Voronoi 图)。
- 没有优化目标函数(Loss Function): 它不求导,不下降。
- 没有参数更新: 它的“参数”就是全体训练数据本身。
它的所有数学都在那条简单的距离公式里: (x1−y1)2+...(x1−y1)2+...。
代码实例
我将使用著名的 Iris 鸢尾花数据集(分类任务)来演示。
代码分为两部分:
- 手写版 (From Scratch):完全基于欧氏距离公式 (∑(x−y)2∑(x−y)2) 和投票机制实现,不依赖任何机器学习库。
- Sklearn 版:使用工业界标准的
KNeighborsClassifier。
Python 代码实现
请确保你的环境中安装了 numpy, scikit-learn, matplotlib, collections。
import numpy as np
from collections import Counter
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# ==========================================
# 第一部分:基于数学推导的手写 KNN
# ==========================================
class MyKNN:
def __init__(self, k=3):
self.k = k
self.X_train = None
self.y_train = None
# 训练过程:KNN 是懒惰学习,所谓训练就是把数据存起来
def fit(self, X, y):
self.X_train = X
self.y_train = y
# 预测过程:核心逻辑在这里
def predict(self, X):
predicted_labels = [self._predict_single(x) for x in X]
return np.array(predicted_labels)
def _predict_single(self, x):
# 1. 计算距离 (数学推导中的欧氏距离)
# 这一行代码实现了: sqrt( sum( (x_train - x_new)^2 ) )
distances = [np.sqrt(np.sum((x_train - x)**2)) for x_train in self.X_train]
# 2. 获取最近的 K 个邻居的索引
# argsort 会返回排序后的索引,我们要前 k 个
k_indices = np.argsort(distances)[:self.k]
# 3. 获取这 K 个邻居的标签
k_nearest_labels = [self.y_train[i] for i in k_indices]
# 4. 投票 (Majority Vote)
# most_common(1) 返回出现次数最多的元素,格式如 [(label, count)]
most_common = Counter(k_nearest_labels).most_common(1)
return most_common[0][0]
# ==========================================
# 数据准备
# ==========================================
# 加载鸢尾花数据集
iris = datasets.load_iris()
X, y = iris.data, iris.target
# 为了方便可视化,我们只取前两个特征 (萼片长度, 萼片宽度)
# 注意:正式应用通常使用所有特征
X = X[:, :2]
# 划分训练集和测试集 (80% 训练, 20% 测试)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234)
print(f"训练集样本数: {len(X_train)}")
print(f"测试集样本数: {len(X_test)}")
print("-" * 30)
# ==========================================
# 运行对比
# ==========================================
# --- 1. 运行手写 KNN ---
k_value = 5
my_knn = MyKNN(k=k_value)
my_knn.fit(X_train, y_train)
predictions_scratch = my_knn.predict(X_test)
acc_scratch = accuracy_score(y_test, predictions_scratch)
print(f"手写 KNN (K={k_value}) 准确率: {acc_scratch * 100:.2f}%")
# --- 2. 运行 Sklearn KNN ---
sklearn_knn = KNeighborsClassifier(n_neighbors=k_value)
sklearn_knn.fit(X_train, y_train)
predictions_sklearn = sklearn_knn.predict(X_test)
acc_sklearn = accuracy_score(y_test, predictions_sklearn)
print(f"Sklearn KNN (K={k_value}) 准确率: {acc_sklearn * 100:.2f}%")
# 检查两者结果是否一致
is_same = np.array_equal(predictions_scratch, predictions_sklearn)
print(f"两者预测结果完全一致吗? {'是' if is_same else '否'}")
# ==========================================
# 可视化决策边界 (Decision Boundary)
# ==========================================
# 为了直观展示 KNN 是如何划分地盘的
def plot_decision_boundary(X, y, model, title):
# 创建网格
h = .02 # 网格步长
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# 预测网格中每个点的类别
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘图
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.coolwarm) # 背景色
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm, edgecolor='k', s=50) # 数据点
plt.title(title)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.show()
print("\n正在生成可视化图表...")
plot_decision_boundary(X_test, y_test, sklearn_knn, f"KNN Decision Boundary (K={k_value})")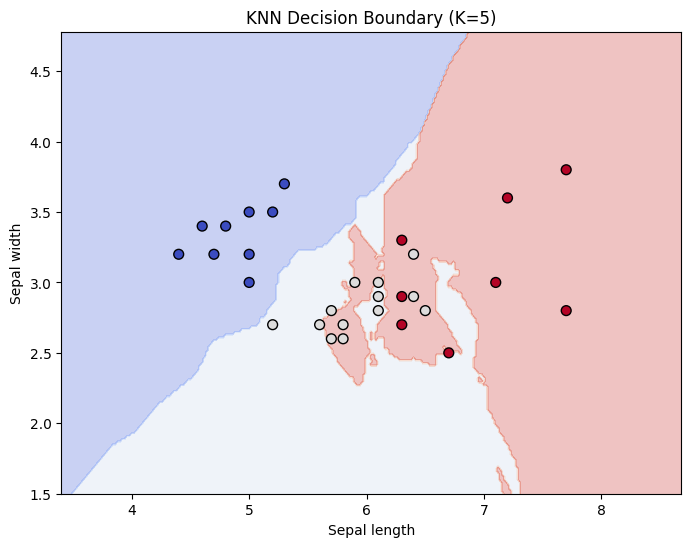
代码深度解析
1. 手写版 (MyKNN) 的核心逻辑
这段代码完全对应了我们之前讲的数学步骤:
-
np.sqrt(np.sum((x_train - x)**2)):- 这就是 欧氏距离公式。
x_train - x: 两个向量相减。**2: 平方。np.sum: 求和。np.sqrt: 开根号。- 这一行代码在 Python 中利用 Numpy 的广播机制,一次性算出了新样本
x和所有训练样本x_train的距离。
-
np.argsort(distances)[:self.k]:- 这是找 最近的 K 个邻居。
argsort不返回距离的值,而是返回从小到大排序后的索引位置。取前k个,就是最近的邻居。
-
Counter(k_nearest_labels).most_common(1):- 这是 投票机制。
- 如果有 3 个邻居是 [类别A, 类别A, 类别B],
Counter会统计出 A:2票, B:1票。most_common(1)就返回 A。
2. 结果对比
你会发现,手写版的准确率和 Sklearn 版的准确率是完全一样的(或者极度接近,取决于平票时的处理策略)。
这证明了 KNN 的原理真的就这么简单:算距离,然后投票。Sklearn 只是在底层做了很多加速优化(比如使用了 KD-Tree 或 Ball-Tree 结构来加速查找邻居,避免遍历所有数据),但数学核心是一模一样的。
3. 可视化图表
生成的图表会展示一个五颜六色的背景图。
- 颜色区域:代表了 KNN 划分的“势力范围”。你会看到边界是不规则的、甚至像锯齿一样的。这正是 KNN “非线性”分类能力的体现。
- 散点:是测试集的真实数据点。
- 如果一个红色的点落在了蓝色的区域里,说明这个点被 KNN 预测错了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)