深度强化学习与控制学习笔记(一)-----强化学习与马尔可夫决策过程
目录
一、学习内容概述
本节课程主要围绕强化学习的基本思想、智能体与环境的交互机制、探索与利用问题、多臂老虎机问题、马尔可夫决策过程以及值迭代和策略迭代展开。通过本节课学习,我对强化学习与传统的监督学习、无监督学习之间的区别有了更清晰的认识,同时也了解了马尔可夫决策过程这一强化学习的重要数学框架。
- 监督学习:使用有标签的数据来训练模型,学习输入与目标输出之间的映射关系
- 无监督学习:训练数据没有标签(只有输入),让机器自主发觉数据的内在结构
- 强化学习:智能体在环境中不断采取行动,通过环境反馈的奖励来调整自身策略,最终目标是在长期时间范围内最大化累积奖励,可以概括为“agent在交互中学习”。
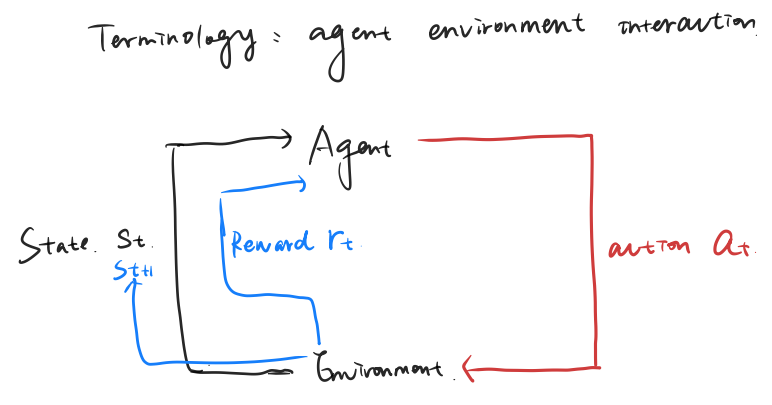
二、强化学习的基本思想
强化学习的基本结构包括智能体、环境、观察、动作和奖励。智能体在每个时刻接收来自环境的观察和奖励,然后根据当前策略选择动作;环境接收动作后,转移到新的状态,并给出下一时刻的观察与奖励。这一过程不断循环,形成序贯决策过程。
其中,
表示agent在i时刻的状态,
表示agent在i时刻采取的动作(policy决定),
表示agent获得的奖励(env给的).
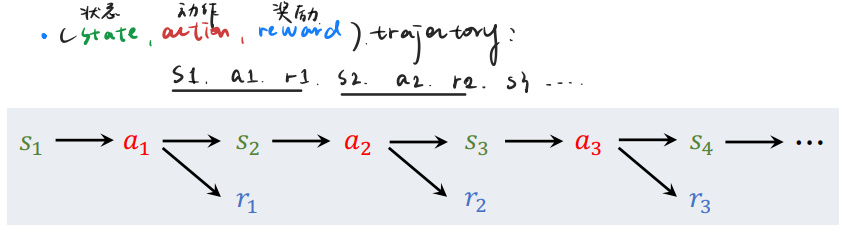
强化学习是agent在与动态环境交互时不断产生新数据。故不同策略会导致不同的交互轨迹,因此强化学习中的数据分布会受到智能体行为本身的影响。
三、强化学习系统的核心要素
- 状态(state):状态是对历史信息的压缩表达,是一种用于确定接下来会发生的事情的信息,是关于历史的函数
- 策略(policy):表示智能体在某一状态下如何选择动作。确定性策略可以表示为:
确定性策略可以表示为:
,
即在状态 s 下直接选择动作 a。随机策略可以表示为:
即在状态 s 下以一定概率选择动作 a
- 奖励:环境对智能体行为的即时评价,是强化学习目标的直接体现。奖励告诉智能体“当前行为好不好”,但并不一定能直接反映长期效果。
- 价值函数:价值函数用于衡量状态或状态—动作对的长期好坏程度。与即时奖励相比,价值函数考虑的是未来累积奖励。例如动作价值函数可以写为:
γ 是折扣因子,用于控制未来奖励的重要程度。折扣因子越接近 1,智能体越重视长期收益;折扣因子越接近 0,智能体越重视当前收益。

- 环境模型:环境模型用于描述状态转移和奖励产生机制,通常包括状态转移概率和奖励函数:
如果已知环境模型,就可以利用动态规划方法进行值迭代或策略迭代;如果环境模型未知,则需要通过采样、试错和学习来估计价值或策略。
四、多臂老虎机
多臂老虎机问题引出强化学习中"探索与利用"的关系。多臂老虎机可以看成一种没有状态转移的简化强化学习问题。智能体每次从多个动作中选择一个动作,并得到一个随机奖励。目标是在有限时间内最大化累积奖励。
动作价值可以通过采样平均估计:
增量更新形式(更节省存储空间):
这说明每次获得新奖励后,只需要利用旧估计值、当前奖励和采样次数即可更新动作价值。衡量多臂老虎机算法效果的一个重要指标是 Regret,即实际选择动作与最优动作之间的收益差。若一个算法长期选择次优动作,Total Regret 会随时间线性增长。理想情况下,算法应在早期进行适当探索,后期逐渐稳定到较优动作,使 Total Regret 的增长尽可能慢。多臂老虎机中理论渐近最优 regret 为
,而 ϵ-greedy 等方法是常用的探索策略。
五、常见的探索策略
- 贪心策略:贪心策略始终选择当前估计价值最大的动作:
它的优点是简单,缺点是容易因为早期估计不准而陷入局部最优。
- ϵ-greedy 策略:该策略以 1−ϵ 的概率选择当前估计最优动作,以 ϵ 的概率随机选择动作。这样既能利用已有经验,也能保留一定探索能力。但是如果 ϵ 为常数,智能体即使已经学到较优动作,仍然会持续随机探索,因此 Total Regret 仍可能线性增长。
- 衰减 ϵ-greedy 策略。该策略让 ϵ 随时间逐渐减小,前期多探索,后期多利用。这更符合学习规律,但难点在于如何设计合适的衰减速度。衰减过快可能探索不足,衰减过慢则会降低长期收益。
- 乐观初始化:该方法给所有动作一个较高的初始价值估计,使智能体倾向于尝试尚未充分探索的动作。随着采样次数增加,初始偏差会逐渐减弱。乐观初始化的优点是能够鼓励探索,但仍然可能在复杂问题中陷入局部最优。
六、马尔可夫过程与马尔可夫决策过程
随机过程描述随机系统随时间演化的规律。若一个过程满足“未来只与当前状态有关,而与过去历史无关”,则称其具有马尔可夫性质:
这句话可以理解为:在当前状态已知的条件下,过去的信息对预测未来不再提供额外帮助。当前状态是未来的充分统计量。
马尔可夫决策过程:
即 MDP,是强化学习中最重要的数学模型之一。MDP 用来描述结果部分随机、部分受决策者控制的序贯决策过程。一个 MDP 通常由五元组表示:
其中,S是状态合集,R是动作合集,P是状态转移概率,r是折扣因子,R是奖励函数。MDP 假设环境完全可观测,即当前状态能够完整表征决策过程。课件强调,MDP 为强化学习提供了数学框架,建模了随机决策过程与因果关系。
在 MDP 中,智能体从初始状态 S0 出发,选择动作 a0,获得奖励 R(s0,a0),然后环境根据转移概率进入下一状态 s1。这个过程持续进行,最终形成一条状态—动作—奖励序列。智能体的目标是最大化折扣累积奖励:
(此公式为奖励只与状态有关)
七、价值函数与 Bellman 等式
给定一个策略 π,状态价值函数定义为从状态 s 出发并按照策略 π 行动所能获得的期望折扣累积奖励:
Bellman 等式将长期价值分解为“当前奖励 + 折扣后的下一状态价值”:
此公式!!!重要,它把一个长期决策问题转化为递推计算问题。也就是说,一个状态的价值可以通过当前奖励和后继状态价值来计算。

最优价值函数定义为所有策略中能够获得的最大状态价值:
对应的最优 Bellman 等式为:
最优策略则可以通过选择使后继状态价值最大的动作得到:
这说明,只要能够求出最优价值函数,就可以进一步得到最优策略。
八、值迭代与策略迭代
在状态空间和动作空间有限的情况下,可以用表格存储价值函数和策略,并基于 Bellman 等式进行迭代更新。
值迭代:直接对价值函数进行贪心更新。其基本步骤是:
- 对每个状态 s,初始化
;
- 重复更新每个状态的价值,直到收敛:
值迭代的特点是更新过程中没有显式维护一个固定策略,而是直接向最优价值函数逼近。课件指出,价值迭代是贪心更新法,对于空间较大的 MDP 更实用,效率也更高。
策略迭代:包括策略评估和策略改进两个步骤。首先随机初始化策略 π,然后重复执行:
- 策略评估:计算当前策略对应的价值函数
- 策略改进:根据当前价值函数更新策略:
策略迭代的优点是在小规模 MDP 中通常收敛较快,但缺点是每次策略评估都需要计算价值函数,代价可能较大。
二者比较:小规模 MDP 中策略迭代通常很快;大规模 MDP 中价值迭代更实用;如果没有状态转移循环,最好使用价值迭代。
九、个人理解与总结
通过本节学习,我认为强化学习的核心可以概括为三个关键词:交互、试错、长期收益。监督学习更像是在已有数据中寻找输入与输出之间的映射关系,而强化学习更像是在一个动态系统中不断做决策,并根据结果修正行为方式。因此,强化学习不仅关心“当前动作是否正确”,更关心“这一动作是否有助于长期目标”。
探索与利用问题让我认识到,强化学习并不是简单地选择当前最优动作。由于智能体对环境的了解一开始并不充分,如果过早相信当前估计,就可能错过更优策略。因此,适当探索是必要的。但探索本身也有代价,所以如何平衡探索与利用,是强化学习算法设计中的关键问题。
马尔可夫决策过程则为强化学习提供了一个清晰的数学框架。通过状态、动作、转移概率、奖励和折扣因子,可以把复杂的序贯决策问题形式化。Bellman 等式进一步揭示了长期价值的递推结构,使得值迭代和策略迭代成为可能。
本节课也让我意识到,后续深度强化学习的基础仍然是这些基本概念。即使使用深度神经网络近似价值函数或策略函数,本质上仍然是在解决“如何估计价值、如何改进策略、如何最大化长期奖励”的问题。因此,理解 MDP、价值函数、Bellman 等式、值迭代和策略迭代,是继续学习 DQN、Actor-Critic、DDPG 等深度强化学习算法的重要基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)