影刀RPA店群自动化实战:Python协同多实例隔离与高并发任务调度系统架构设计
大家好,我是林焱。
过去这几年,我一直扎根在电商自动化研发与系统交付的最前线。
看着许多电商团队从单机单店的“草莽时代”,一步步走向拼多多、TEMU、TikTok Shop 的全域矩阵铺货。
在这个过程中,大家在享受机器替人带来的效率飞升红利时,也几乎都经历过极其惨痛的系统性崩溃。
刚开始拥抱自动化时,业务部门的诉求往往非常简单。
找个懂点技术的运营,用影刀 RPA 拖拽几个“点击”和“输入”的控件,把上架商品、同步物流的动作录制下来,搞个简单的循环。
在开发机的单节点测试中,看着鼠标自己移动,表格里的数据一行行被处理,大家觉得这简直就是一台不知疲倦的印钞机。
但真正的问题,从来不是脚本会不会点击。
而是系统是否具备在复杂网络、多变前端和严苛风控下,长期稳定运行的能力。
当你的店铺矩阵从三个,膨胀到五十个、甚至两百个的时候,原有的“连点器思维”就会在顷刻间崩盘。
你会开始遭遇离奇的浏览器无响应、服务器内存溢出宕机、代理 IP 频繁串号。
以及所有电商操盘手最恐惧的噩梦——关联。
今天这篇长文,我们不讲那些基础的元素抓取教学。
我们将站在系统工程和自动化架构师的视角,深度拆解如何利用 Python 的生态纵深,结合影刀 RPA 的可视化编排优势,构建一套真正具备高可用、分布式调度能力的矩阵自动化运营基座。
一、 跨越玩具阶段:摒弃脆弱的线性执行流
市面上绝大多数的初级自动化项目,往往死于逻辑的极度脆弱。
很多团队在编写流程时,习惯用一长串的流程图把业务死死地串在一起:打开网页 -> 登录校验 -> 抓取订单 -> 自动发货。
这种“面条式”的线性执行逻辑,在面对拼多多和 TEMU 这种高频迭代的电商后台时,简直是一场灾难。
只要页面的 DOM 树出现一点点微小的扰动,原本写死的 XPath 或视觉捕获就会彻底失效。
脚本原地卡死,死等元素出现直到全局超时,导致后续几百个店铺的任务全部堆积。
企业级自动化工程设计的第一准则,是绝对不盲目信任单一的执行路径。
在我们的核心引擎中,全面引入了有限状态机(FSM)的任务生命周期模型。
店群矩阵自动化突破运营极限!
我们不再把业务当成一连串固定的按键动作,而是将其拆分为互相独立的“状态节点”。
核心节点通常包括:环境就绪(INIT)、账号鉴权(AUTH)、业务执行(EXEC)、异常挂起(BLOCKED)、任务完成(DONE)。
如果系统在执行任务时被一个未知的弹窗拦截了。
它绝不会死等,而是触发异常捕获机制,截取当前报错屏幕,将该店铺的任务状态变更为 BLOCKED,并异步推送到监控告警群。
然后,主控程序会立刻释放资源,无缝流转去拉起队列里下一个排队的店铺。
这种防御性设计,保证了局部的 UI 异常或网络波动,绝对不会引发整条物理流水线的停摆。
二、 浏览器实例池:彻底切断环境交叉污染
做多账号店群运营,环境隔离是生死线。
很多团队在影刀里简单切分了几个用户数据目录(User Data Dir),就以为万事大吉了。
这个问题其实在高并发阶段特别容易暴露。
如果没有在操作系统的进程级别进行严密的参数管控,底层的特征依然会发生严重的交叉污染。
我们要做的,是用 Python 硬生生劈出绝对隔离的运行空间。
每一次拉起浏览器,都是一次动态的“容器化沙箱编排”。
不仅要物理隔离缓存文件,还要在命令行启动级别强制绑定特定的代理出口。
并且,必须通过启动参数阻断可能泄露真实物理位置的协议。
这里还有一个巨坑:系统缩放比例。
在矩阵部署时,不同 Windows 执行机的显示器 DPI 设置往往五花八门。
如果不强制锁死浏览器渲染的缩放比例,你的影刀脚本换台机器就会频繁点错位置,视觉捕获全部错位。
下面这段核心代码,展示了我们如何利用底层配置,编写一个专用的实例调度引擎:
Python
import os
import socket
import logging
import subprocess
from typing import Dict, Optional
自动化架构核心:独立沙箱环境调度器
logging.basicConfig(level=logging.INFO, format=‘%(asctime)s - %(levelname)s - %(message)s’)
logger = logging.getLogger(“EnvOrchestrator”)
class BrowserInstancePool:
“”"
核心沙箱分配引擎:负责多实例 Chromium 的资源调度与环境混淆
“”"
def init(self, root_storage: str, exec_path: str):
self.root_storage = root_storage
self.exec_path = exec_path
if not os.path.exists(self.root_storage):
os.makedirs(self.root_storage, exist_ok=True)
def get_free_port(self) -> int:
“”“动态分配 CDP 端口,确保高并发任务不冲突”“”
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.bind((‘127.0.0.1’, 0))
return s.getsockname()[1]
def spawn_isolated_node(self, shop_id: str, proxy_node: Optional[str] = None) -> Dict:
“”"
点火:拉起一个完全隔离的浏览器容器进程
“”"
# 每个店铺分配独立的持久化工作区,切断 Cookies 污染
profile_path = os.path.join(self.root_storage, f"shop_ctx{shop_id}")
cdp_port = self._get_free_port()
# 启动参数装配:剥离自动化特征
chrome_args = [
self.exec_path,
f"--remote-debugging-port={cdp_port}",
f"--user-data-dir={profile_path}",
"--disable-blink-features=AutomationControlled", # 抹除 Webdriver 特征
"--no-first-run",
"--disable-infobars",
"--force-device-scale-factor=1", # 锁定缩放比,这是影刀识别稳定的基石
"--disable-background-networking"
]
# 跨境网络强绑定
if proxy_node:
chrome_args.append(f"--proxy-server={proxy_node}")
# 阻断 WebRTC 泄漏机房 IP
chrome_args.append("--enforce-webrtc-ip-handling-policy=disable-non-proxied-udp")
try:
# 采用异步非阻塞拉起
process = subprocess.Popen(chrome_args)
logger.info(f"店铺 {shop_id} 沙箱就绪 | CDP端口: {cdp_port} | PID: {process.pid}")
return {
"status": "READY",
"cdp_port": cdp_port,
"pid": process.pid,
"profile": profile_path
}
except Exception as e:
logger.error(f"拉起环境失败: {str(e)}")
return {"status": "FAILED", "error": str(e)}
这段代码的灵魂在于它抛出的 cdp_port。
在影刀 RPA 的编排流中,我们彻底抛弃了自带的“打开网页”指令。
我们在流程开头通过 Python 拿到动态端口,然后使用影刀的“接管已打开的浏览器”指令精准连接。
这种“Python 建地基,影刀盖房子”的协同架构,才是支撑大规模店群的正确姿势。
三、 高并发任务调度:从 Excel 转向消息队列
当你的店铺数量突破 50 个,还打算在影刀里通过读取本地 Excel 来跑任务,你就已经离崩溃不远了。
多机并发下的文件读写冲突、任务进度的黑盒状态、无法实时观测的异常日志。
这些问题会在业务高峰期集中爆发。
我们要告别“面条代码”,建立“任务生命周期”管理。
在企业级架构设计中,所有的执行节点(云服务器或本地执行机)都是没有感情的“消费者”。
我们在云端部署任务分发中枢:
生产者: 业务后端根据 Cron 计划生成任务,推送到消息队列(如 Redis 或 RabbitMQ)。
调度器: 根据各执行节点的硬件负载(CPU、内存闲置率)实时分发载荷。
消费者: 节点上的守护进程捞取载荷,点火拉起对应的沙箱,再唤醒影刀执行。
这个问题其实在高并发阶段特别容易暴露。
很多团队最开始都会忽略这里,导致多台机器抢占同一个账号,最终触发风控。
通过消息队列的 ACK 机制,我们可以精准确保:同一个店铺在同一时间,只会在一个物理节点上运行。
四、 资源收割:无情的内存清道夫
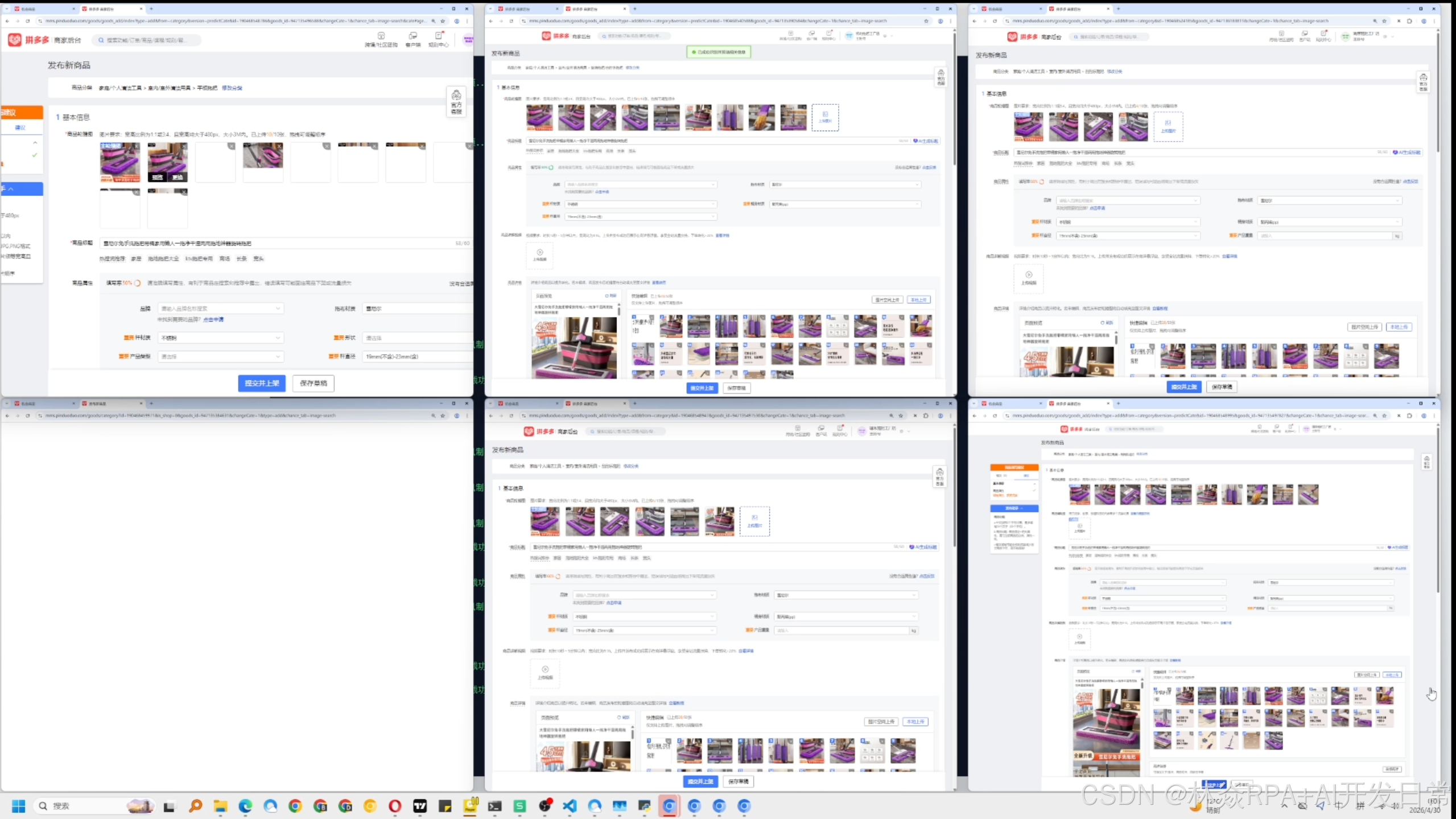
如果你在一台 32G 内存的云主机上,同时拉起 15 个影刀+Chromium 实例,跑不了六个小时,内存就会溢出。
Chromium 是内存巨兽,影刀在频繁调用视觉识别时也会产生大量的内存堆叠。
temu店群自动化报活动案例
我们当时在线上环境里踩过一次很严重的内存泄漏。
原本以为流程结束时调用影刀的“关闭浏览器”就万事大吉了。
但实际排查发现,大量的渲染子进程依然残留在系统里,变成了无法回收的僵尸。
优秀的自动化架构师,必须是一个残酷的“进程收割者”。
在我们的生命周期管理逻辑中,任务完成后,由 Python 外壳上报执行结果,然后无视浏览器的优雅关闭,直接强杀进程树。
Python
import psutil
def ruthlessly_terminate_node(main_pid: int):
“”"
资源回收引擎:确保不留下一兆僵尸内存
“”"
try:
parent = psutil.Process(main_pid)
# 递归搜寻所有渲染子进程
for child in parent.children(recursive=True):
child.kill()
parent.kill()
logger.info(f"资源强行回收完成: PID {main_pid}“)
except psutil.NoSuchProcess:
pass
except Exception as e:
logger.error(f"资源回收异常: {e}”)
真正跑到几十个店铺后,这种对细节的把控才能体现出价值。
五、 稳定性堡垒:分布式运维与上帝视角
真正做过项目的人都知道,RPA 最大的敌人是“不确定性”。
如果每台执行机的日志都分散在本地,你根本无法进行运维。
我们引入了中心化日志监控体系。
影刀里的每一个重要节点,都会通过 API 异步发送心跳和日志到后端的分析服务器。
我们在办公室的大屏幕上,就能实时看到哪一个店铺的任务被弹窗卡住了。
为了应对这种边缘环境的排错,我们会为每台执行机部署虚拟局域网工具。
通过虚拟局域网,我们在办公室可以直接 RDP 登录到分布在各地的任何一台执行机进行人工干预。
这种“上帝视角”的运维能力,是系统能否支撑大规模业务的关键。
结语:从脚本到工程的蜕变
在电商自动化这个赛道,工具本身并不产生绝对的护城河。
护城河来自于你如何解决那 1% 的极端稳定性问题。
真正的问题,从来不是脚本会不会点击。
而是当系统面对成百上千个任务涌入时,它是否具备像工业流水线一样的调度、隔离与自我修复能力。
从“脚本小子”到“工程负责人”的蜕变,往往就在于你开始关注这些藏在代码背后的运维细节。
希望这些踩坑经验,能帮你在建设店群自动化的路上少走一些弯路。
作者:林焱

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)