WM-DAgger:利用世界模型实现模仿学习中的高效数据聚合
26年4月来自北大、京东物流、南开大学、港科大、新泽西Rutgers大学和德州Dallas分校的论文“WM-DAgger: Enabling Efficient Data Aggregation for Imitation Learning with World Models”。
模仿学习是一种用于训练机器人策略的强大范式,但其性能受限于“累积误差”问题:策略中微小的偏差可能导致机器人偏离训练集中的已知分布,进入未曾见过的“分布外”(OOD)状态;在这些状态下,策略可能会产生更大的误差,最终导致任务失败。尽管“数据聚合”(DAgger)框架旨在解决这一问题,但其对持续人工干预的依赖严重限制了其可扩展性。本文提出 WM-DAgger,这是一种高效的数据聚合框架,它利用“世界模型”(World Models)来合成 OOD 状态下的恢复数据,且无需任何人工干预。具体而言,专注于涉及“眼在手”(eye-in-hand)构型机械臂的操纵任务,且仅利用少量专家演示数据进行训练。为了避免合成具有误导性的数据,并克服世界模型固有的“幻觉”问题,框架引入两个关键机制:(1) “纠正动作合成模块”,用于生成面向任务的恢复动作,从而防止产生误导性的监督信号;(2) “一致性引导过滤模块”,通过将合成轨迹的最终帧锚定(对齐)至专家演示中的对应真实帧,来剔除那些在物理上不合理的轨迹。在多个实际机器人任务中对 WM-DAgger 进行广泛验证。实验结果表明,方法显著提高任务成功率;源代码已公开发布于 https://github.com/czs12354-xxdbd/WM-Dagger。
模仿学习是一种将人类专业技能迁移至机器人系统中的强大范式 [1], [2], [3]。然而,其有效性却受限于“累积误差”问题 [4]:即使策略中存在微小的偏差,也可能导致机器人偏离人类演示所涵盖的范围,进入“分布外”(OOD)状态;一旦进入此类状态,策略便会产生进一步的误差,最终导致任务失败。
为了解决这一问题,“数据聚合”(DAgger)范式 [4], [5] 依赖于持续的人工干预:操作者需引导机器人从 OOD 状态回归正轨,并在此过程中同步收集恢复数据,以供后续的模仿学习之用。然而,这种对人工操作的依赖性,在实际应用中严重限制该范式的可扩展性。近期,基于扩散的模型已被用于合成“分布外”(OOD)的恢复数据 [6]。然而,由于这些模型仅限于单帧生成,它们无法对恢复过程中的连续动态进行建模。此外,由于缺乏对环境动态的内在理解,这些模型难以处理复杂的物理交互及可变形体。
“世界模型”(World Models,WMs)[7], [8], [9] 领域的近期进展,为解决这一累积误差问题提供独特契机。以 Cosmos-Predict [10] 为代表的世界模型,能够接收历史帧图像及预定动作作为输入,进而合成未来状态下的后续帧图像。通过利用此类模型合成 OOD 恢复数据,可以大幅减少 DAgger 范式下数据收集所需的人力投入。此外,与现有的用于数据合成的单帧扩散模型不同,世界模型能够生成连续的多帧图像,从而捕捉复杂现实场景中的环境动态 [7];这使得它们特别适用于涉及复杂物理交互及可变形体的各类任务。
尽管前景广阔,但利用世界模型(WMs)来合成高质量的 OOD(分布外)恢复数据绝非易事。首要挑战在于缺乏专家的参与,从而无法提供最优的恢复监督信号。尽管标准的“人机协作”(human-in-the-loop)式 DAgger 算法 [5] 依赖专家来提供 OOD 状态下的恢复动作,但在世界模型内部合成轨迹时,这种人工标注的方式是不可行的。如果这些 OOD 状态被错误地匹配次优动作,将会严重误导策略(policy)的训练过程 [11]。第二个挑战在于如何减轻合成恢复数据中“幻觉”(hallucinations)现象带来的负面影响。世界模型不可避免地会产生幻觉,例如物体形态发生畸变,或出现不符合物理常理的状态跃迁。若基于此类数据进行策略训练,其性能提升将微乎其微,因为策略所学习的物理动力学规律是错误的,且与现实世界的环境存在严重脱节。
本文提出一种名为 WM-DAgger 的框架,该框架利用世界模型实现面向模仿学习的高效“数据聚合”(Data Aggregation)过程。具体而言,其专注于解决机器人操纵任务,并采用业界广泛应用的“手眼”(eye-in-hand)配置 [6, 12]。如图 1 所示,框架利用少量的专家演示数据,并辅以大规模的 OOD 恢复数据来训练策略;这些恢复数据由“手眼条件世界模型”(EAC-WM,基于 Cosmos-Predict-2.5 [10] 改进而来)所合成。该模型能够将机器人的动作映射为像素级的运动场(motion fields),以此表征“手眼”相机在空间中的位移;通过提供这种显式的几何条件约束,模型得以合成出与相应恢复动作相匹配的视觉观测数据。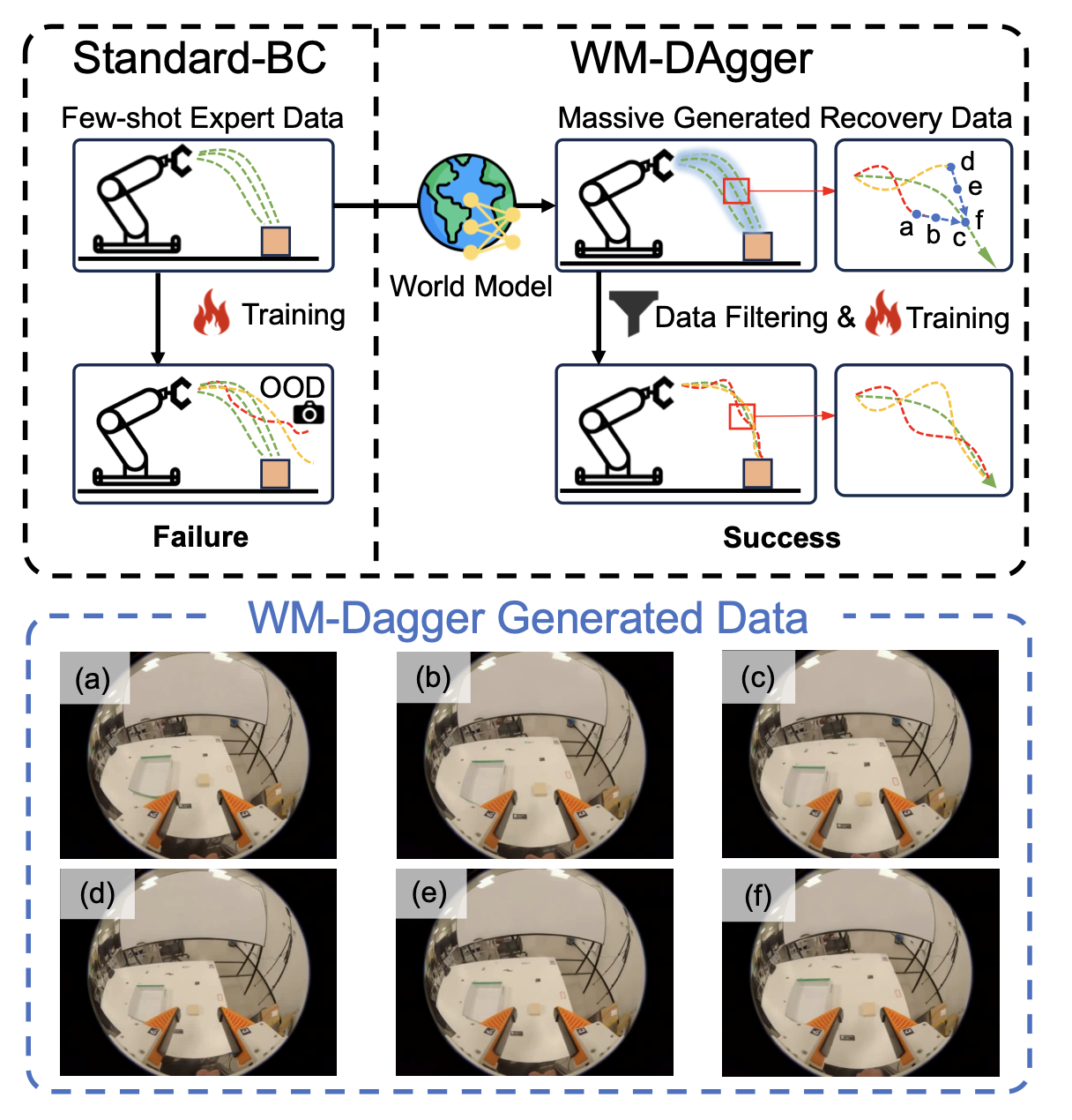
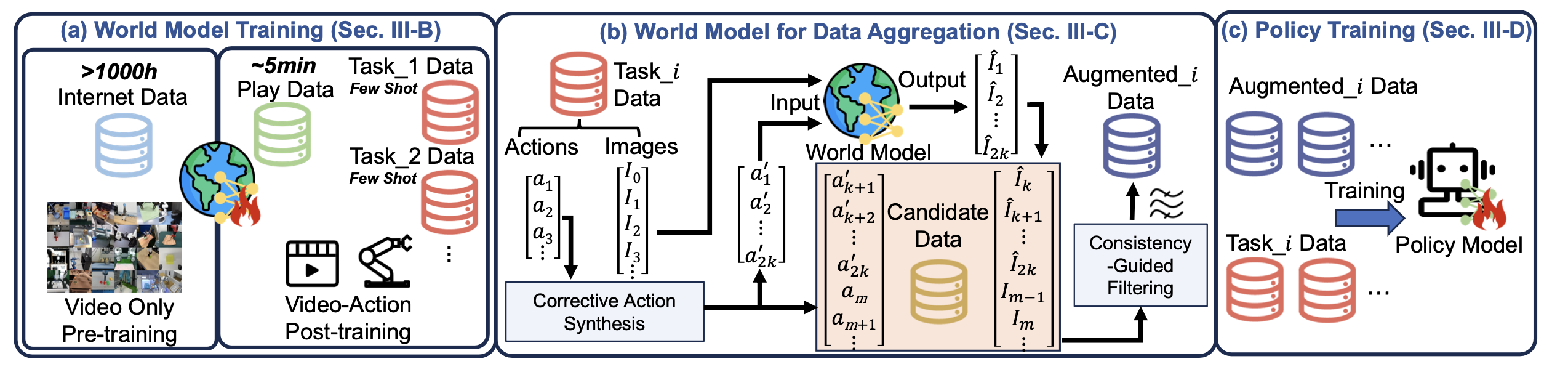
WM-DAgger 是一种由世界模型驱动的框架,它通过合成 OOD(分布外)状态及其相应的恢复轨迹,来训练具有鲁棒性的策略。如图 2 所示,该框架的整体流程始于训练一个“手眼协调”且受动作条件制约的世界模型。该模型综合利用探索性的“游玩数据”(Play Data)和专家演示的“任务数据”(Task Data),来学习符合物理规律的环境动力学。具体而言,“游玩数据”是通过对工作空间进行无特定目标的探索而收集的;而“任务数据”则包含专家为完成特定操作任务所演示的详细轨迹。利用这一经过训练的世界模型(WM),基于专家的“任务数据”生成大规模的 OOD 恢复数据。具体来说,“纠正动作合成模块”通过有意偏离专家轨迹、进入周边的 OOD 状态,随后再引导系统回归正轨的方式,来生成相应的恢复动作。随后,该世界模型会沿着这些恢复路径合成对应的视觉帧序列。为了确保数据的保真度,“一致性引导过滤模块”会剔除那些在合成帧中呈现出不符合物理常理“幻觉”现象的轨迹。最后,将原始的专家“任务数据”与经过验证的合成恢复数据进行整合,以此来训练出一个能够纠正累积执行误差的策略。
A. 手眼协调动作条件下的世界模型设计
- 整体架构:提出“手眼协调动作条件下的世界模型”(EAC-WM),这是一种专门用于捕捉并合成手眼视觉动态的架构。EAC-WM 以 GE-Sim [18] 框架为基础,并采用 Cosmos-Predict2.5 (2B) [10] 作为骨干网络;在此基础上,它引入一个名为“Action2Image”的条件模块。该模块通过将动作转化为手眼相机中每个像素的相对空间位移,为世界模型(WM)提供细粒度的几何条件信息,从而提升预测手眼视觉动态的逼真度。
如图 3 所示EAC- WM的架构: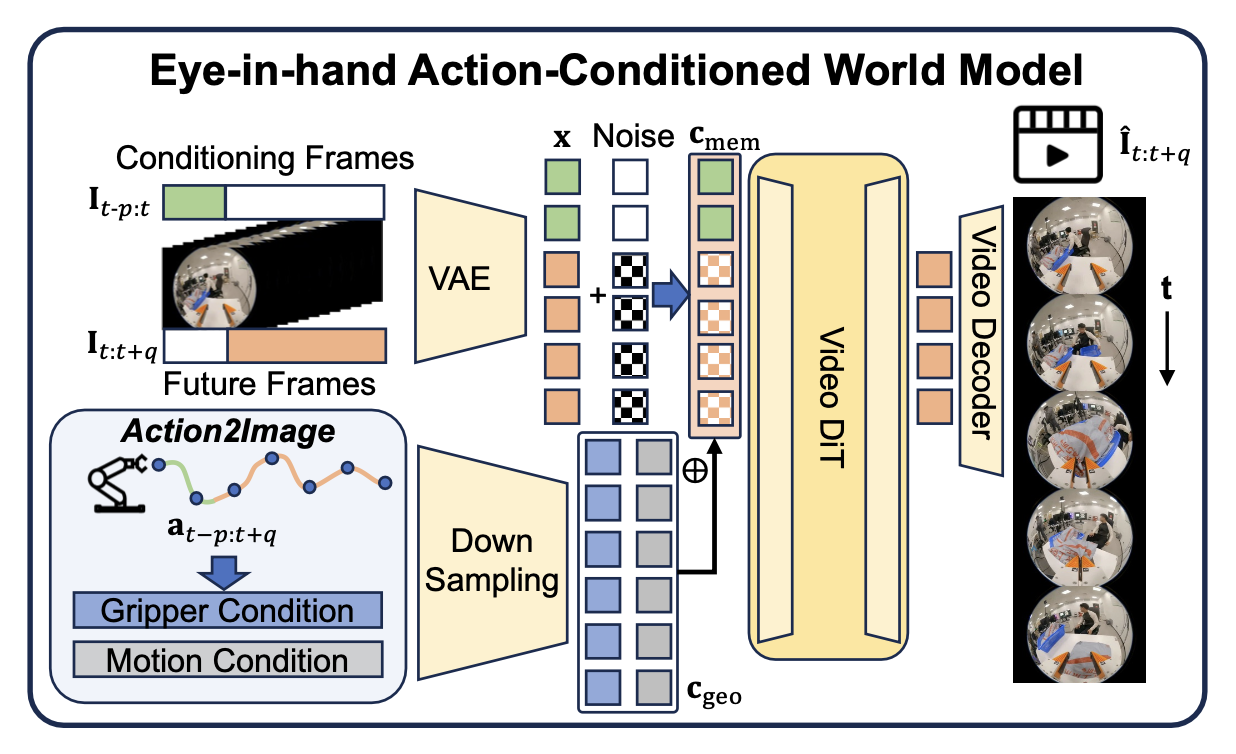
将时刻 t 的机器人控制输入定义为一个向量 a_t = [t_t, q_t, g_t],该向量包含笛卡尔坐标系下的平移量 t_t、单位四元数表示的姿态 q_t 以及连续的夹爪状态 g_t。形式上,设 f_θ 表示由参数 θ 参数化的世界模型。给定一个包含 p 个历史观测值的上下文窗口,以及一个包含 q 个未来动作的序列,EAC-WM 能够预测随后的 q 个视觉状态 ˆI_t:t+q。
- Action2Image 条件化处理:将世界模型 f_θ 基于低维动作序列 a_t-p:t+q 进行条件化处理是一项充满挑战的任务,因为稀疏的动作向量很容易被高维的视觉条件 I_t-p:t 所掩盖。受计算机视觉领域中相机参数编码方法 [19] 的启发,引入 Action2Image 模块;该模块将稀疏的动作向量投影为一种稠密且与像素对齐的几何条件信息,从而弥合了动作与视觉之间存在的维度鸿沟。
在该模块中,首先利用一个固定的手眼标定矩阵对动作向量 [t_t, q_t] 进行变换,从而推导出相机在世界坐标系下的旋转矩阵 R_t 和平移向量o_t。基于三维投影几何原理,图像中的每一个像素 (u, v) 都对应着一条源自相机光心的三维射线。为了有效地对模型进行条件化,使其能够基于时刻 t 的图像及二者之间的相对动作,生成时刻 t + i 的图像,将该相对动作转化为图像中每个像素的高维相对光线变换。
-
视频-动作token化(Tokenization):为了利用世界基础模型处理高维视觉和几何数据,用预训练的变分自编码器(VAE)将输入投影到一个紧凑的潜空间中。给定一系列历史上下文帧 I_{t-p:t} 和目标未来帧 I_{t:t+q},VAE 生成视觉图像token x_{t-p:t+q}。与此同时,密集的几何条件 C_geo 经过下采样投影,以获得动作token c_geo。这种统一的token化机制确保视觉观测和机器人控制动作都能在共享的潜空间中得到表示,从而促进世界基础模型内部有效的跨模态交互。
-
世界模型训练与数据策略:EAC-WM 以 Cosmos-Predict2.5 (2B) 基础模型作为初始化,该模型通过在互联网规模的纯视频数据 D_I 上进行预训练,建立通用的物理先验知识。随后,用来自“游玩数据”(Play Data)D_P 和“任务数据”(Task Data)D 的同步视觉-动作序列,将该模型适配于特定的操纵动力学。游玩数据 D_P 包含非脚本化的人类探索性动作,用于内化特定场景的几何结构;而任务数据 D 则包含专家演示,用于细化模型对受动作条件制约的物理动力学的理解。
EAC-WM 的训练是在“修正流”(Rectified Flow)框架 [20] 下构建的,该框架学习沿着一条确定的线性路径将噪声映射回数据。在视频-动作后训练阶段,历史上下文token x_t-p:t 充当无噪声的条件锚点 c_mem。目标未来token x_k(其中 k ∈ {t,…,t+q})被用于构建带噪的潜变量 z_λ,k;这一构建过程通过线性插值实现,并引入噪声尺度为 λ ∈ [0,1] 的高斯噪声 ε ~ sim N(0,I)。
一个视频扩散 Transformer(DiT)模型 φ_θ 被训练用于预测速度场,该速度场指引着从噪声向数据分布回溯的流动方向。模型的优化目标是最小化预测流的均方误差MSE,即L。
B. 用于数据聚合的世界模型
在获得训练好的 EAC-WM 之后,现在针对模仿学习任务进行数据聚合。首先,利用“纠正动作合成模块”来推导恢复动作;随后,利用“一致性引导过滤模块”对生成的、在物理或视觉上存在不一致的数据进行过滤。
- 纠正动作合成模块:该模块利用 EAC-WM 机制,针对那些偏离专家演示轨迹的 OOD(分布外)状态,合成相应的恢复数据。如图 4 所示,对于一条专家演示轨迹 τ = {a_i, I_i},随机选取一个“枢纽时间步”m 作为合成过程的锚点。将偏离跨度设定为 k,并随机采样一个单位向量 v_d,用以表征潜 OOD 状态的偏离方向。为避免引入误导性的监督信号,若向量 v_d 与后续专家动作 a_m+1 之间的夹角小于 120°,则对该偏离方向予以过滤。这一约束条件确保所合成的恢复动作不会与专家轨迹的行进方向相悖,从而有效防止因训练信号相互矛盾而引发策略发散的问题。此外,为使动作速率与专家演示保持一致,合成恢复数据中各动作的偏离位移均被设定为任务数据集 D 中所有动作位移的平均值。
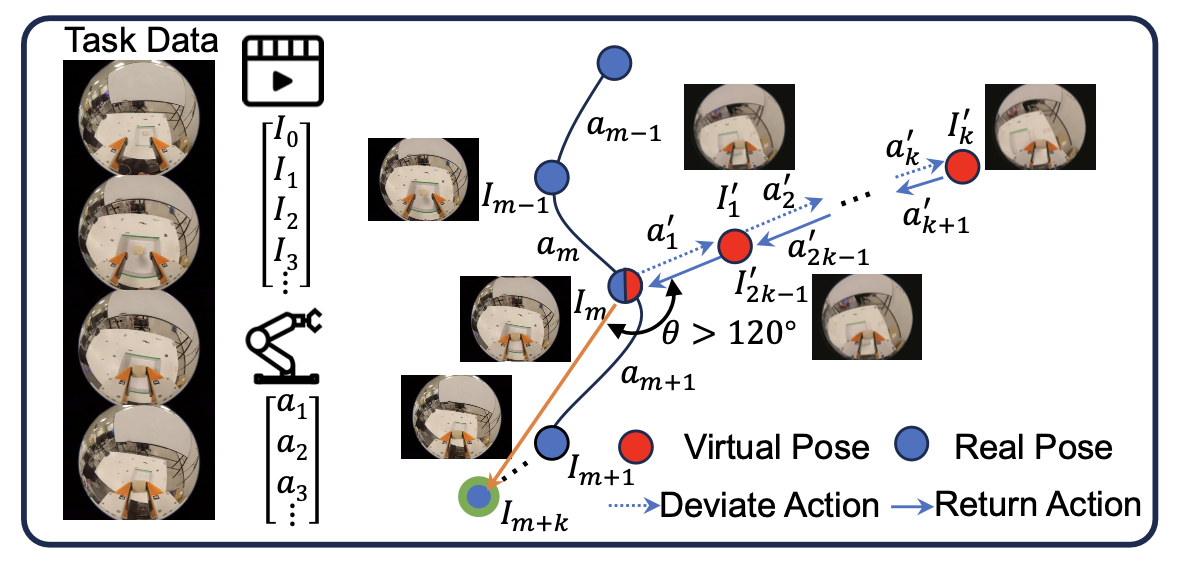
合成轨迹 τ′ = {a′_j , ˆI_j } 的构建分为两个对称的阶段。首先,在“偏离阶段”(τ’_d)中,机器人从时间步 m 处的专家位姿出发,沿着方向 v_d 被引导至一个受扰动的 OOD(分布外)状态。其次,在“恢复阶段”(τ’_r)中,机器人从该受扰动状态返回至时间步 m 处的原始专家流形。这两个阶段分别遵循 v_d 和 −v_d 的方向。给定历史视觉状态 I_m−p:m 和合成动作序列 a′_1:2k 作为条件,世界模型(World Model)预测合成轨迹的视觉状态 ˆI_1:2k。
对于整条合成轨迹 τ′,舍弃其中的“偏离阶段” τ’_d,仅保留“恢复阶段” τ’_r 用于策略训练。这确保模型能够专门学习如何从 OOD 状态中进行恢复。
- 一致性引导过滤模块:世界模型(WMs)不可避免地会产生“幻觉”现象,例如物体形变或物理状态不一致等。为了确保数据的保真度,引入一个“一致性引导过滤模块”来识别并剔除这些样本。核心洞察基于世界模型固有的时间误差累积特性。由于终止帧 ˆI_2k 在时间上距离条件帧(conditioning frames)最为遥远,因此它蕴含着最大的潜在幻觉风险 [22]。因此,它可以作为衡量整个轨迹生成序列(rollout)质量的一个严格智体指标:如果 ˆI_2k 与处于同一视角位置的专家观测帧 I_m 保持一致,便可以可靠地推断出,该合成轨迹中的各帧均保持高度的物理与视觉完整性。
为了对视觉幻觉进行量化,利用预训练的 DINOv2 [23] 编码器来提取上述两帧的嵌入特征,进而计算它们之间的余弦相似度。采用一种自适应阈值策略:凡是相似度得分低于平均水平的合成轨迹均被过滤剔除,从而将包含幻觉的样本排除在外。
如图 5 展示这一过滤过程。图 5(a) 和 (d) 分别展示“软袋推动”任务和“抓取放置”任务的专家演示帧。图 5(b) 展示一帧被舍弃的图像,其中发生图像形变;而图 5(e) 展示另一帧被舍弃的图像,其中图像块的位置偏离专家参考。相比之下,图 5© 和 (f) 均为被保留的图像帧,其中未观察明显的幻觉现象。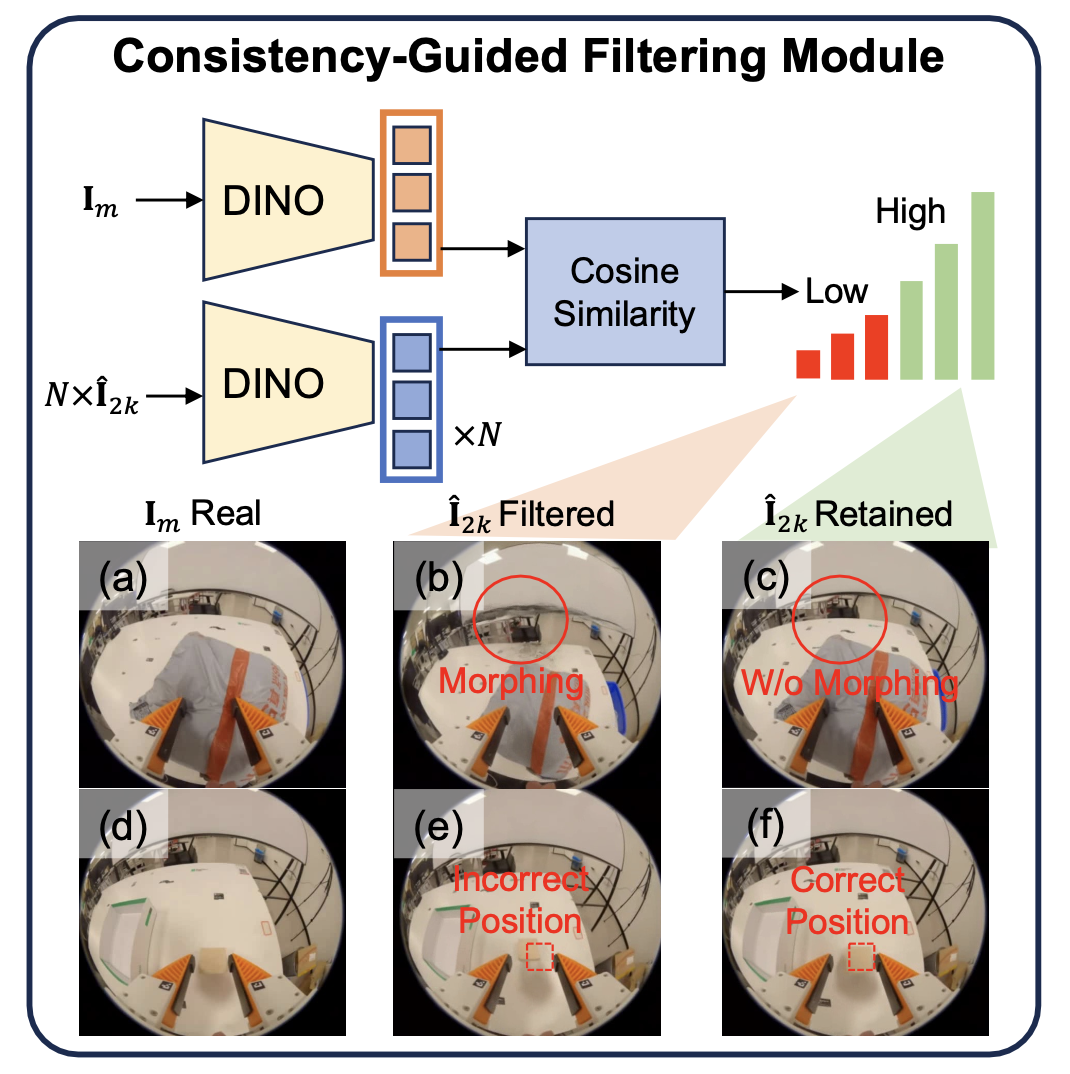
C. 策略训练
训练集 D_aug = D ∪ D_virtual 是通过将专家演示数据 D 与合成轨迹 D_virtual 进行聚合而构建的。为了增强动作的时间一致性,采用“动作分块”(Action Chunking)范式 [24]。该策略被设计为:给定当前观测 I_t,预测一个跨越时间窗口 H 的未来动作序列,即 Aˆ_t = π(I_t) = [aˆ_t,aˆ_t+1,…,aˆ_t+H−1]。策略的训练目标是最小化预测动作块与训练集中的实际动作之间的均方误差(MSE),即 L_policy。
通过在 D_aug 上进行训练,该策略不仅内化专家的行为模式,还学习在处于分布外(OOD)状态时进行恢复的能力。
A. 实验设置
-
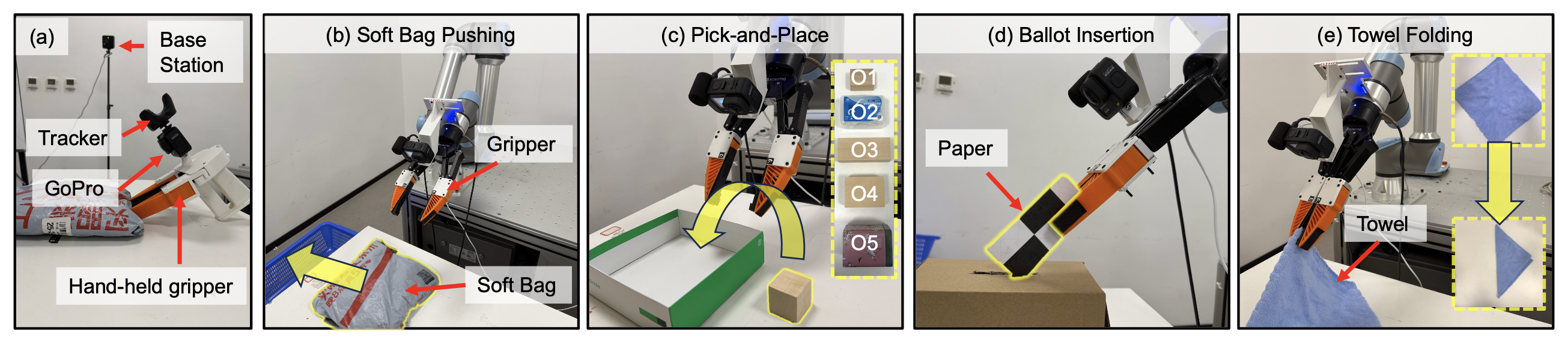
硬件平台:数据采集流程主要遵循“通用操作接口”(UMI)框架 [12]。如图 6(a) 所示,用一个手持式双指夹爪,并在其上搭载一枚配备鱼眼镜头的“手眼”式 GoPro 摄像头,以此作为视觉观测的来源。在采集演示动作的位姿数据时,利用 HTC Vive [25] 设备来捕捉夹爪的 6 自由度(6-DoF)位姿信息。整个机器人系统由一台 Universal Robots UR7e 机械臂和一台配备“鲨鱼鳍”指尖的 Robotiq 2F-140 夹爪组成。模型训练在 4 块 NVIDIA L20 GPU 上进行,推理过程则在 1 块 NVIDIA L20 GPU 上执行。
-
世界模型与策略架构:用 EAC-WM 作为生成式世界模型;该模型构建于 GE-Sim [18] 框架之上,并以 Cosmos-Predict2.5 (2B) [10] 作为其基础模型,旨在合成高保真且受动作条件制约的未来观测图像。对于机器人策略模型,采用 Gr00t N1.5 [26];这是一个集视觉、语言与动作处理能力于一体的模型,在框架中充当核心策略模型。
-
基线模型:将 WM-DAgger 的性能与两个基线模型进行对比:(1) 标准行为克隆(Standard Behavioral Cloning,简称 BC):这是一个标准的模仿学习基线模型,其训练过程未采用数据聚合技术。该基线模型可作为参照,用于衡量在实际部署阶段因遭遇 OOD 状态而导致的性能衰退程度。 (2) 扩散结合数据聚合(Diffusion Meets DAgger,DMD) [6]:一种利用基于扩散模型的合成技术进行数据聚合(Data Aggregation)的当前最佳(SOTA)方法。该方法被用作基准,旨在证明相比于标准生成式数据增强方法,世界模型(WMs)能够提供更优越的、受动作制约的物理一致性。
-
数据准备:为每项任务收集5分钟的“游玩数据”(Play Data)。在收集游玩数据期间,演示者手持夹爪,在环境中随机移动并与物体进行交互。在收集“任务数据”(Task Data)期间,为每项任务收集20组人类演示数据。默认情况下,为每项任务生成1500个回合的恢复动作数据。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)