Linux Pcie(3)————中断+DMA
1:中断
该中断的类型应该划分为硬件中断,有别于这个软件中断
1.1 自定义驱动中增添中断寄存器相关内容
/*
* QEMU edu IRQ 寄存器。
*
* 写 EDU_REG_IRQ_RAISE 会让设备产生中断,并把对应 bit 置入 IRQ_STATUS。
* 中断处理函数必须把读到的 status 写回 EDU_REG_IRQ_ACK,否则中断不会被清掉。
*/
#define EDU_REG_IRQ_STATUS 0x24
#define EDU_REG_IRQ_RAISE 0x60
#define EDU_REG_IRQ_ACK 0x64
#define EDU_IRQ_TEST BIT(0)
#define EDU_IRQ_DMA_DONE BIT(8)1.2自定义驱动中自定义结构体新增部分
struct edu_pci_dev {
//PCI 设备资源
struct pci_dev *pdev;
void __iomem *bar0;
resource_size_t bar0_len;
//IRQ
int irq;
struct completion irq_done;
u32 last_irq_status;
u64 irq_count;
//DMA
void *dma_virt;
dma_addr_t dma_addr;
size_t dma_size;
//并发 加锁
struct mutex lock;
//字符设备
int instance;
struct miscdevice miscdev;
char misc_name[32];
};其中:
- irq:Linux IRQ 号。
- irq_done:中断完成同步用 completion。
- last_irq_status:最近一次 IRQ status。
- irq_count:累计中断次数。
1.3 probe中自定义驱动向内核申请中断相关资源
1.3.1前置知识:
①MSI&传统INTx:
MSI (Message Signaled Interrupts,消息信号中断)是一种基于内存写事务的中断机制,它完全取代了传统的引脚中断 (INTx)。传统引脚中断:设备通过物理引脚向中断控制器发送电信号,MSI 中断:设备通过向一个特定的内存地址写入一个特定的数据值来发送中断信号。
//传统INTx机制
设备引脚 → I/O APIC → 前端总线 → 本地APIC → CPU
//MSI中断机制
设备 → PCIe根复合体 → 本地APIC → CPU②IDT&APIC:
IDT (Interrupt Descriptor Table,中断描述符表) 是一个位于内存中的数组,它的每个元素称为中断描述符,对应一个CPU 中断向量号 (0-255)。IDT 的本质是CPU 的中断向量表,它告诉 CPU:当某个中断向量号的中断发生时,应该跳转到哪里去执行处理代码。
当 CPU 收到 Local APIC 发来的中断请求时:
- CPU 从 Local APIC 获取中断向量号
- CPU 将当前的程序状态 (CS、RIP、RFLAGS、SS、RSP) 自动压入栈中
- CPU 根据中断向量号在 IDT 中查找对应的中断描述符
- CPU 跳转到中断描述符中指定的入口地址执行
- 中断处理函数执行完毕后,执行
iret指令,从栈中恢复程序状态,继续执行被中断的程序
APIC 高级可编程中断控制器,APIC 的核心作用是中断路由和分发,它决定了哪个中断应该被哪个 CPU 核心处理。
- EDU 设备通过 PCIe 总线的 INTx 信号线发送中断请求
- 中断请求到达 I/O APIC 的某个输入引脚
- I/O APIC 查找预先配置的重定向表 (Redirection Table),将该引脚映射到一个 CPU 中断向量号
- I/O APIC 通过 APIC 总线将中断消息发送给指定的 Local APIC
- Local APIC 检查中断优先级,如果高于当前 CPU 正在处理的中断优先级,就向 CPU 核心发出中断请求
- CPU 核心响应中断,开始执行中断处理流程
③ irq_vectors & Linux IRQ:
- 中断向量号:CPU 硬件层面的概念,范围 0-255,由 APIC 分配
- Linux IRQ 号:内核软件层面的概念,全局唯一,由内核分配
- 它们之间是多对一的映射关系:多个中断向量号可以映射到同一个 Linux IRQ 号
1.3.2 真正开始索要资源:
驱动需要向内核申请中断资源并注册处理函数
// 步骤10:分配IRQ向量,优先MSI,失败则回退到传统INTx
irq_vectors = pci_alloc_irq_vectors(pdev, 1, 1, PCI_IRQ_MSI | PCI_IRQ_LEGACY);
if (irq_vectors < 0) {
dev_err(&pdev->dev, "pci_alloc_irq_vectors failed: %d\n", irq_vectors);
return irq_vectors;
}
// 注册devm action,设备移除时自动释放中断向量
ret = devm_add_action_or_reset(&pdev->dev, edu_free_irq_vectors, pdev);
if (ret)
return ret;
// 获取分配到的Linux IRQ号
edu->irq = pci_irq_vector(pdev, 0);
// 根据中断类型设置标志:MSI不共享,INTx必须共享
irq_flags = pci_dev_msi_enabled(pdev) ? 0 : IRQF_SHARED;
// 注册中断处理函数
ret = devm_request_irq(&pdev->dev, edu->irq, edu_irq_handler, irq_flags,
"edu_pci", edu);
if (ret) {
dev_err(&pdev->dev, "request_irq %d failed: %d\n", edu->irq, ret);
return ret;
} ①pci_alloc_irq_vectors():
现代 PCIe 驱动推荐使用的中断分配函数,自动处理 MSI/MSI-X 和传统 INTx 的兼容性,也就是硬件给内核提交一个硬件中断号,内核返还回一个中断向量凭证,硬件提交的中断向量在内核当中体现为一个唯一确定的Linux IRQ号,此后用户自定义的驱动只需要对唯一的Linux IRQ号进行操作,即可体现为对实际的硬件号的操作。
总结irq_vectors 的核心作用:它是连接硬件中断和内核中断处理的桥梁。没有它,内核就不知道这个中断应该交给哪个驱动的哪个处理函数来处理。
- 硬件 IRQ 号 → 中断控制器 → 映射为 CPU 中断向量号
- CPU 中断向量号 → 内核 → 映射为 Linux IRQ 号
- 驱动程序只需要和Linux IRQ 号打交道,不需要关心底层的硬件细节
②devm_add_action_or_reset:则是向内核注册了一个自定义的清理函数
edu_free_irq_vector(),该函数会在以下两种情况下发生
(1) 设备被移除时
当你执行
rmmod edu_pci或者热插拔移除设备时,内核会自动调用edu_free_irq_vectors(pdev)来释放中断向量。(2) probe 过程中后续步骤失败时
这是
_or_reset后缀的含义,也是这个函数最有价值的地方。如果步骤 11 分配 DMA 缓冲区失败,probe 函数会直接返回-ENOMEM。在没有 devm 机制的情况下,你需要手动释放之前分配的中断向量,但有了devm_add_action_or_reset,内核会自动调用edu_free_irq_vectors(pdev)来释放中断向量,不需要你手动写任何清理代码。
总结也就是说:前边先申请一些了资源,但是可能出现中间某些资源没未申请成功或者是初始化未成功等等不希望发生的事情发生的时候,我们就会自动的释放前边已经申请到手的种种资源.
③注册中断处理函数:
devm_request_irq(),依旧是用户自定义驱动向pci内核注册中断函数,当中断到来,并且交由用户自定义的edu_irq_handler进行处理.
static irqreturn_t edu_irq_handler(int irq, void *data)
{
// 从data参数取回设备私有数据结构
struct edu_pci_dev *edu = data;
u32 status;
// 第一步:读取设备的中断状态寄存器
status = edu_readl(edu, EDU_REG_IRQ_STATUS);
// 第二步:判断是否是本设备产生的中断(共享中断必须检查)
if (!status)
return IRQ_NONE;
// 第三步:清除设备的中断请求
edu_writel(edu, EDU_REG_IRQ_ACK, status);
// 第四步:保存中断状态,供进程上下文使用
WRITE_ONCE(edu->last_irq_status, status);
edu->irq_count++;
// 第五步:唤醒等待中断的进程
complete(&edu->irq_done);
// 第六步:返回中断已处理
return IRQ_HANDLED;
}1.3.3中断流程推演
硬件触发中断
↓
EDU设备向PCIe总线发送中断消息(MSI)或中断信号(INTx)
↓
PCIe Root Port接收中断,转发给APIC(高级可编程中断控制器)
↓
APIC根据预先配置的映射关系,将中断转换为**CPU中断向量号**
↓
CPU收到中断向量号,在IDT(中断描述符表)中查找对应的处理入口
↓
CPU跳转到内核的通用中断处理函数`common_interrupt`
↓
内核根据**CPU中断向量号**找到对应的**Linux IRQ号**
↓
内核根据Linux IRQ号找到对应的`struct irq_desc`结构体
↓
遍历`irq_desc`中的`action`链表,调用我们注册的`edu_irq_handler`
↓
中断处理完成,返回被中断的进程2:DMA
2.1:新增宏定义与结构体
/*
* QEMU edu DMA 寄存器。
*
* 设备内部有一个 4096 字节 DMA buffer,设备侧地址固定从 0x40000 开始。
* DMA 命令 bit0=start,bit1=方向,bit2=完成后产生 0x100 中断。
*/
#define EDU_REG_DMA_SRC 0x80
#define EDU_REG_DMA_DST 0x88
#define EDU_REG_DMA_COUNT 0x90
#define EDU_REG_DMA_CMD 0x98
#define EDU_DMA_DEVICE_BUF 0x40000ULL
#define EDU_DMA_TEST_SIZE 256
#define EDU_DMA_ALLOC_SIZE (EDU_DMA_TEST_SIZE * 2)
#define EDU_DMA_CMD_START BIT(0)
#define EDU_DMA_CMD_FROM_EDU BIT(1)
#define EDU_DMA_CMD_IRQ BIT(2)
#define EDU_TIMEOUT_MS 1000
/*
* 每一个 edu PCI function 对应一个 edu_pci_dev。
*
* pdev:Linux PCI 子系统创建的 PCI 设备对象。
* bar0:BAR0 ioremap 后的内核虚拟地址,只能用 ioread/iowrite 访问。
* irq:pci_alloc_irq_vectors() 后得到的 Linux IRQ 号。
* irq_done:ISR 收到中断后 complete,用于同步等待 IRQ/DMA 完成。
* dma_virt/dma_addr:一致性 DMA buffer 的 CPU 地址和设备 DMA 地址。
* lock:串行化字符设备 read/write/ioctl,避免 DMA 和寄存器访问相互打架。
* miscdev:misc 字符设备对象,注册成功后生成 /dev/eduN。
*/
struct edu_pci_dev {
//PCI 设备资源
struct pci_dev *pdev;
void __iomem *bar0;
resource_size_t bar0_len;
//IRQ
int irq;
struct completion irq_done;
u32 last_irq_status;
u64 irq_count;
//DMA
void *dma_virt;
dma_addr_t dma_addr;
size_t dma_size;
//并发 加锁
struct mutex lock;
//字符设备
int instance;
struct miscdevice miscdev;
char misc_name[32];
};2.2:DMA 初始化(probe 函数)
①dma_set_mask_and_coherent():告诉内核设备支持的最大 DMA 地址宽度。EDU 设备只支持 28 位地址,所以最大可以访问 256MB 内存。
②pci_set_master():允许设备作为总线主设备发起 PCIe 事务。这是 DMA 工作的必要条件,没有这个设置,设备无法主动访问系统内存。
③dmam_alloc_coherent():分配一致性 DMA 缓冲区。会返回两个结果,-其一是内核虚拟地址(供CPU访问) ,其二总线地址(供设备访问)
// edu->dma_virt = 0xffff888001234000(内核虚拟地址)
// edu->dma_addr = 0x1234000(总线地址)
也就说 这两个地址实际上指向的是同一块在RAM当中的地址,CPU通过0xffff888001234000找打该地址,PCI设备通过0x1234000找到该RAM地址,也就是同一个RAM地址,在不同器件的不同视角会有不同的地址产生.
Linux 内核提供了两种 DMA 缓冲区分配方式,它们有本质的区别:
| 特性 | 一致性 DMA(Coherent DMA) | 流式 DMA(Streaming DMA) |
|---|---|---|
| 分配函数 | dma_alloc_coherent() |
dma_map_single() |
| 缓存特性 | 非缓存的,或者硬件自动保持缓存一致性 | 缓存的,需要手动管理缓存同步 |
| 生命周期 | 长期存在,适合设备和 CPU 同时访问的缓冲区 | 短期存在,适合单次数据传输 |
| 性能 | 较低,因为不使用 CPU 缓存 | 较高,因为使用 CPU 缓存 |
| 使用场景 | 设备寄存器映射、环形缓冲区、长期共享的数据结构 | 大块数据的单次传输(如网络数据包、磁盘块) |
// 步骤2:设置DMA mask。QEMU edu默认只支持28-bit DMA地址。
ret = dma_set_mask_and_coherent(&pdev->dev, DMA_BIT_MASK(28));
if (ret) {
dev_err(&pdev->dev, "dma_set_mask_and_coherent failed: %d\n", ret);
return ret;
}
// 步骤8:打开bus mastering;DMA必须允许设备主动发起PCIe事务。
pci_set_master(pdev);
// 步骤11:分配coherent DMA buffer,前半段作源,后半段作目的。
edu->dma_size = EDU_DMA_ALLOC_SIZE;
edu->dma_virt = dmam_alloc_coherent(&pdev->dev, edu->dma_size,
&edu->dma_addr, GFP_KERNEL);
if (!edu->dma_virt)
return -ENOMEM;
dev_info(&pdev->dev, "DMA buffer cpu=%p dma=%pad size=%zu\n",
edu->dma_virt, &edu->dma_addr, edu->dma_size);2.3DMA启动与等待
核心逻辑:
- 重置用于同步的
completion和中断状态变量- 向设备写入 DMA 源地址、目的地址和传输长度
- 写入 DMA 命令寄存器,启动 DMA 传输,并设置
EDU_DMA_CMD_IRQ标志,要求设备在传输完成后产生中断- 调用
edu_wait_for_irq()进入睡眠,等待 DMA 完成中断
/*
* 启动一次 DMA 并等待 DMA 完成中断。
*
* src/dst 可以是 guest RAM 的 DMA 地址,也可以是 EDU 设备内部 buffer 地址
* 0x40000。cmd_flags 用来选择方向:0 表示 RAM->EDU,EDU_DMA_CMD_FROM_EDU
* 表示 EDU->RAM。
*/
static int edu_dma_start_and_wait(struct edu_pci_dev *edu, u64 src, u64 dst,
u32 count, u32 cmd_flags)
{
u32 cmd;
// 重置completion和中断状态
reinit_completion(&edu->irq_done);
WRITE_ONCE(edu->last_irq_status, 0);
// 配置DMA寄存器
edu_writeq_split(edu, EDU_REG_DMA_SRC, src);
edu_writeq_split(edu, EDU_REG_DMA_DST, dst);
edu_writel(edu, EDU_REG_DMA_COUNT, count);
// 启动DMA,并设置完成后产生中断
cmd = EDU_DMA_CMD_START | EDU_DMA_CMD_IRQ | cmd_flags;
edu_writel(edu, EDU_REG_DMA_CMD, cmd);
// 等待DMA完成中断
return edu_wait_for_irq(edu, EDU_IRQ_DMA_DONE);
}
/*
* 等待某个中断 bit 出现。
*
* IRQ handler 会读取 IRQ_STATUS、写 IRQ_ACK 清中断,并把状态保存到
* edu->last_irq_status,然后 complete(&edu->irq_done) 唤醒这里。
*/
static int edu_wait_for_irq(struct edu_pci_dev *edu, u32 expected_status)
{
unsigned long timeout;
u32 status;
timeout = wait_for_completion_timeout(&edu->irq_done,
msecs_to_jiffies(EDU_TIMEOUT_MS));
if (!timeout)
return -ETIMEDOUT;
status = READ_ONCE(edu->last_irq_status);
if (!(status & expected_status))
return -EIO;
return 0;
}3 DMA与IRQ交互
3.1CPU 准备阶段
/*
* 字符设备 ioctl 命令定义。
*
* 目前接口保持教学性质:
* - EDU_IOC_GET_ID:读取 edu ID 寄存器。
* - EDU_IOC_REG_READ:读取任意 32-bit 对齐的 BAR0 寄存器。
* - EDU_IOC_REG_WRITE:写入任意 32-bit 对齐的 BAR0 寄存器。
* - EDU_IOC_IRQ_TEST:触发一次设备中断,并等待 ISR 收到状态。
* - EDU_IOC_DMA_TEST:用设备 DMA buffer 做一次 RAM->EDU->RAM 回环测试。
*/
#define EDU_IOC_MAGIC 'e'
#define EDU_IOC_GET_ID _IOR(EDU_IOC_MAGIC, 0x00, __u32)
#define EDU_IOC_REG_READ _IOWR(EDU_IOC_MAGIC, 0x01, struct edu_ioc_reg)
#define EDU_IOC_REG_WRITE _IOW(EDU_IOC_MAGIC, 0x02, struct edu_ioc_reg)
#define EDU_IOC_IRQ_TEST _IOWR(EDU_IOC_MAGIC, 0x03, __u32)
#define EDU_IOC_DMA_TEST _IOWR(EDU_IOC_MAGIC, 0x04, struct edu_ioc_dma_test)也是同样通过switch case这样的匹配实现这个命令的转发
case EDU_IOC_IRQ_TEST:
if (copy_from_user(&value, (void __user *)arg, sizeof(value))) {
ret = -EFAULT;
break;
}
if (!value)
value = EDU_IRQ_TEST;
ret = edu_irq_selftest(edu, value, &value);
if (!ret && copy_to_user((void __user *)arg, &value, sizeof(value)))
ret = -EFAULT;
break;
case EDU_IOC_DMA_TEST:
if (copy_from_user(&dma_test, (void __user *)arg, sizeof(dma_test))) {
ret = -EFAULT;
break;
}
ret = edu_dma_selftest(edu, dma_test.size, dma_test.pattern);
dma_test.result = ret ? (__u32)-ret : 0;
if (copy_to_user((void __user *)arg, &dma_test, sizeof(dma_test)))
ret = -EFAULT;
break;2 内核态进入edu_ioctl函数,调用edu_dma_selftest
自定义的DMA回环测试,其中:
edu->dma_virt:CPU 虚拟地址,只能被 CPU 访问edu->dma_addr:DMA 总线地址,只能被 PCIe 设备访问
/*
* DMA 回环自测:验证EDU设备DMA数据传输路径的完整性和正确性
*
* 测试原理:通过两次DMA传输形成数据回环,验证数据在"CPU内存→EDU设备→CPU内存"
* 的完整传输过程中没有丢失或损坏。这是PCIe设备驱动开发中最常用的DMA功能验证方法。
*
* 完整测试流程:
* 1. 在一致性DMA缓冲区的前半段填充已知模式的数据
* 2. 第一次DMA:将数据从Guest物理内存传输到EDU设备内部的4KB缓冲区(0x40000)
* 3. 第二次DMA:将数据从EDU设备内部缓冲区传输回Guest物理内存的后半段
* 4. 比较源缓冲区和目的缓冲区的内容,完全一致则说明DMA路径正常
*
* @param edu: EDU设备私有数据结构指针
* @param size: 要传输的数据大小(字节),为0时使用默认值EDU_DMA_TEST_SIZE
* @param pattern: 数据填充模式的基值,用于生成可预测的测试数据
* @return: 0表示测试成功,负数表示错误码(-EINVAL参数错误, -ETIMEDOUT超时, -EIO数据错误)
*/
static int edu_dma_selftest(struct edu_pci_dev *edu, u32 size, u32 pattern)
3 CPU填充DMA源缓冲区,设置目的缓冲区为0
也就是向src[index]中添加 pattern + 索引的数据(这些数据可预测 也就是我们事先是知道数据是什么样的)
- 数据丢失:如果某个字节没有被传输,目的缓冲区中对应的位置会是 0
- 数据错误:如果某个字节被传错了,值会不符合
pattern + index的规律- 字节错位:如果传输过程中字节顺序错了,会出现连续的错误
- 缓冲区溢出:如果 DMA 传输了过多的数据,会覆盖目的缓冲区后面的内容
// 步骤1:在源缓冲区填充可预测的测试数据
// 每个字节的值为 pattern + 索引,这样可以很容易地检测到数据错误
for (index = 0; index < size; index++)
src[index] = (u8)(pattern + index);
// 步骤2:将目的缓冲区清零,确保没有残留数据影响测试结果
memset(dst, 0, size);
// 步骤3:写内存屏障(Write Memory Barrier)
// 这是DMA编程中最关键也最容易被忽略的一步!
// 作用:确保CPU对DMA缓冲区的所有写入操作在启动DMA之前全部完成
// 并且这些写入对PCIe设备是可见的
// 如果没有这个屏障,CPU可能会将写入操作缓存起来,设备看到的还是旧数据
dma_wmb();4 调用dma_wmb()确保所有写入对设备可见
dma_wmb() 会做两件关键的事情:
- 禁止指令重排:确保所有在
dma_wmb()之前的写指令,都不会被重排到dma_wmb()之后执行 - 刷新写缓存:确保所有在
dma_wmb()之前的写操作,都已经从 CPU 缓存刷新到了物理内存
这样,当执行到start_dma()的时候,所有的数据都已经被正确地写入了物理内存,设备可以读到最新的数据。指令重排列的意思是由于这个编译器的作用,可能会打乱人工编译代码的顺利,平常代码还行,但是在DMA数据传输的环境下,打乱指令的顺序执行,会导致这个DMA错误的传递一些没有用的数据.
5 调用edu_dma_start_and_wait启动第一次DMA
也就是向指定寄存器的位置写下的数据,然后对应的DMA处理器,会绕过CPU向对应地址的内存进行数据帮运.然后再等待搬运数据的完成.
3.2 DMA 传输阶段(CPU 不参与)
6. edu_dma_start_and_wait配置DMA寄存器
edu_writeq_split(edu, EDU_REG_DMA_SRC, src); 写入源地址
edu_writeq_split(edu, EDU_REG_DMA_DST, dst); 写入目的地址
edu_writel(edu, EDU_REG_DMA_COUNT, count); 写入传输长度
7. 写入EDU_REG_DMA_CMD启动DMA传输
cmd = EDU_DMA_CMD_START | EDU_DMA_CMD_IRQ | cmd_flags;
edu_writel(edu, EDU_REG_DMA_CMD, cmd);
这是真正启动 DMA 传输的一行代码。我们向EDU_REG_DMA_CMD(0x98)寄存器写入一个命令字,包含三个部分:
EDU_DMA_CMD_START(BIT(0)):DMA 启动位,写 1 表示开始传输EDU_DMA_CMD_IRQ(BIT(2)):中断使能位,写 1 表示传输完成后产生中断cmd_flags:额外标志,主要是EDU_DMA_CMD_FROM_EDU(BIT(1)),表示传输方向是从设备到内存
关键细节:当 CPU 向这个寄存器写入值的瞬间,EDU 设备的 DMA 控制器就会立即开始工作,不需要 CPU 做任何其他事情。
调用edu_wait_for_irq函数进入睡眠状态,直到 DMA 完成中断发生或者超时
8. EDU设备的DMA控制器接管PCIe总线
和很多的串行传输协议一样,一个完整的PCIe体系结构包括应用层、事务层(Transaction Layer)、数据链路层(Data Link Layer)和物理层(Physical Layer)。其中,应用层并不是PCIe Spec所规定的内容,完全由用户根据自己的需求进行设计,另外三层都是PCIe Spec明确规范的,并要求设计者严格遵循的。
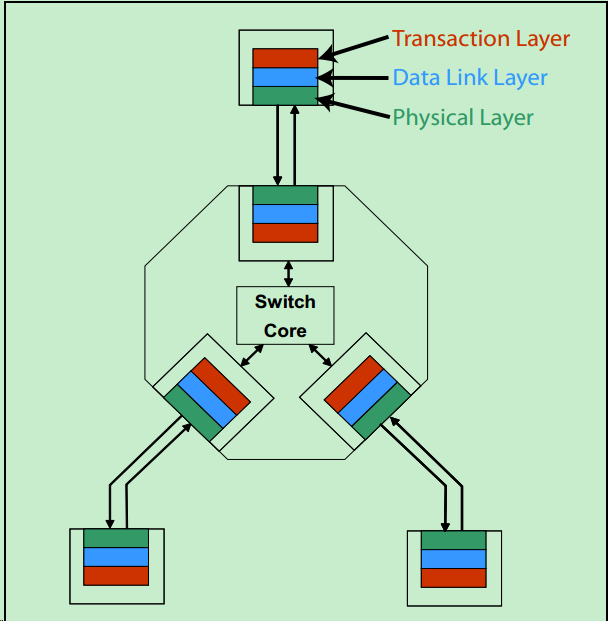
每层分管不同的具体事务:
┌─────────────────────────────────────────────────────────┐
│ 事务层(Transaction Layer) │
│ 负责:TLP包的组包/解包、流量控制、事务管理、QoS优先级 │
└───────────────────────────┬─────────────────────────────┘
│
┌───────────────────────────┼─────────────────────────────┐
│ 数据链路层(Data Link Layer) │
│ 负责:数据包的可靠传输、错误检测与重传、CRC校验 │
└───────────────────────────┬─────────────────────────────┘
│
┌───────────────────────────┼─────────────────────────────┐
│ 物理层(Physical Layer) │
│ 负责:电信号传输、8b/10b或128b/130b编码、链路训练 │
└─────────────────────────────────────────────────────────┘9. DMA控制器从系统内存的src_dma地址读取数据
我们先前在源缓冲区里边写了pattern + 索引这样的数据(是CPU写入的),
src是CPU 虚拟地址,指向dmam_alloc_coherent分配的一致性 DMA 缓冲区- CPU 通过自己的 MMU 访问这个虚拟地址,最终写入物理内存
现在我们做一下,把数据从源缓冲区(也就是内存当中)写入到endpoint的设备中(也就是EDU_DMA_DEVICE_BUF这个位置),再进行比对.
ret = edu_dma_start_and_wait(edu, src_dma, EDU_DMA_DEVICE_BUF, size, 0);
src_dma是DMA 总线地址,不是 CPU 虚拟地址,也不是物理地址- 这个地址是
dmam_alloc_coherent返回的,专门供 PCIe 设备访问系统内存使用
10. DMA控制器将数据写入EDU设备内部缓冲区0x40000
这个缓冲区的地址是查询这个edu的数据手册获知的,这个数据手册上说,该设备的地址上的该区域是一块数据缓冲区,用于暂存数据.
11. 传完后,DMA控制器设置EDU_REG_IRQ_STATUS的EDU_IRQ_DMA_DONE位
EDU设备事务层生成内存读请求TLP
↓
TLP包含:类型=内存读、地址=src_dma、长度=1DW、请求者ID=01:00.0
↓
通过PCIe链路发送到Root Complex
↓
Root Complex解析TLP,将请求转发到内存控制器
↓
内存控制器从物理地址src_dma读取4字节数据
↓
内存控制器生成Completion TLP,包含读取到的数据
↓
Completion TLP通过PCIe链路发送回EDU设备
↓
EDU设备事务层提取数据,写入内部缓冲区
↓
DMA控制器更新地址计数器和剩余长度计数器
↓
重复上述过程,直到所有数据传输完成12. DMA控制器向CPU发送中断请求
cmd = EDU_DMA_CMD_START | EDU_DMA_CMD_IRQ | cmd_flags;
edu_writel(edu, EDU_REG_DMA_CMD, cmd);
return edu_wait_for_irq(edu, EDU_IRQ_DMA_DONE);向edu设备中指定位置的寄存器中写入这个命令字,其中就包含这个 EDU_DMA_CMD_IRQ ,也就是说相关控制寄存器位置由该参数的话,就会像CPU发送中断请求,这个应该是edu设备内部的状态机自动完成的.
3.3 中断处理阶段
13. CPU响应中断,保存上下文,跳转到内核通用中断处理入口
这个是涉及到异步中断,CPU会先完成手头最后一条指令,然后CPU自动保存正在执行程序上下文,再清除中断标志位(CPU会不断轮询这个标志位 以此判断是否有中断来到),再通过IDT找到中断向量号,再找对应的描述符,再找到中断函数的地址.
要实现对硬中断的屏蔽,则可以从清除中断标志位IF\Local APIC 中断屏蔽 \ IRQ 线级中断屏蔽 \ 设备中断控制字等角度入手 是先不同粒度的中断控制.
14. 内核调用edu_irq_handler
中断函数的地址就是这个edu_irq_hander在RAM中的地址,CPU会执行这个自定义的中断函数
15. edu_irq_handler读取EDU_REG_IRQ_STATUS,确认是DMA完成中断
用户自定义的中断函数应该先清除这个pci硬件上的中断标志位,以此完成硬件→CPU请求,CPU→硬件回应,清楚完,硬件就不向CPU发申请了
16. 写入EDU_REG_IRQ_ACK清除中断
依旧是清除一些相关的寄存器
17. 保存中断状态到edu->last_irq_status
暂存一下状态到自定义结构体中
18. 调用complete(&edu->irq_done)唤醒等待的进程
19. 中断处理完成,返回被中断的进程
1. 驱动调用edu_dma_start_and_wait
↓
2. 构造DMA命令字:EDU_DMA_CMD_START | EDU_DMA_CMD_IRQ | cmd_flags
↓
3. 向EDU_REG_DMA_CMD寄存器写入命令,启动DMA传输
↓
4. EDU设备DMA控制器自动完成所有数据传输
↓
5. DMA控制器检查EDU_DMA_CMD_IRQ标志位
↓
6. 如果标志位为1,设置EDU_REG_IRQ_STATUS的EDU_IRQ_DMA_DONE位
↓
7. 向CPU发送中断请求
↓
8. CPU响应中断,调用edu_irq_handler
↓
9. edu_irq_handler读取中断状态,清除中断,保存状态
↓
10. 调用complete(&edu->irq_done)唤醒等待的进程
↓
11. edu_wait_for_irq被唤醒,检查中断状态
↓
12. edu_dma_start_and_wait返回,DMA传输完成3.4 CPU 继续处理
20. edu_wait_for_irq被唤醒,检查中断状态
在向pci设备中写完控制字以后,就用户驱动就进入休眠状态了,然后,等着DMA完成之后,执行中断函数完最后,会把用户驱动接着唤醒.接着下一步的操作,在我们驱动中的定义就是,再次执行第二次驱动.
21. 第一次DMA传输完成,启动第二次DMA传输
22. 重复步骤6-19,完成第二次DMA传输
23. 调用dma_rmb()确保设备的所有写入对CPU可见
24. 比较源和目的缓冲区的内容
也就是DMA测试中的回环,先是CPU写到RAM中,再RAM写入到edu中,再edu写入到RAM中,比较两者看看数据一样不一样.
25. 将结果返回给用户态


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)