论文精读--《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》--RAG“开山鼻祖”,含简易RAG搭建实验过程
写在前面
原文发表于NIPS2020(原文链接),中文名机翻过来就是《用于知识密集型自然语言处理任务的检索增强生成》。
本文是我的翻译+笔记+简单RAG的“hello world”实验记录。
并且由于原始RAG确实比较老了,因此在笔记中简单补充了GraphRAG和AgenticRAG,本博客中的三张动图取自一文搞懂GraphRAG、LightRAG、AgenticRAG,看这一篇就够了!-CSDN博客
目录
2.2.简易LangChain + Chroma + OpenAI API
1.翻译和笔记
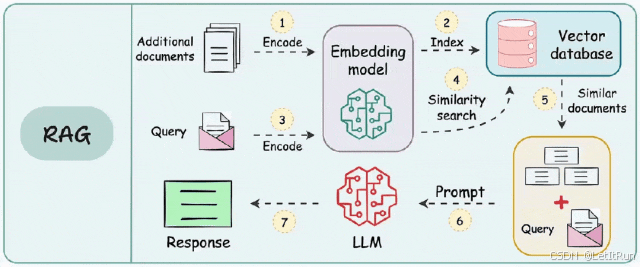
1.0.摘要
大型预训练语言模型已被证明可以将事实性知识存储在其参数中,并在下游NLP任务上进行微调时达到最先进的结果。然而,它们获取和精确操纵知识的能力仍然有限,因此在知识密集型任务上,它们的性能落后于特定任务的体系结构。此外,为他们的决策提供来源和更新他们的世界知识仍然是开放的研究问题。具有显式非参数记忆的可微访问机制的预训练模型可以克服这一问题,但迄今为止只针对抽取式下游任务进行了研究。 我们为检索增强生成 (RAG) 探索了一个通用的微调方法--结合预训练的参数和非参数记忆进行语言生成的模型。我们引入RAG模型,其中参数记忆是预训练的seq2seq模型,非参数记忆是维基百科的稠密向量索引,通过预训练的神经检索器访问。我们比较了两种RAG方式,一种是在生成整个序列时都基于同一批检索到的段落,另一种则允许在生成每个 token 时使用不同的检索段落。 我们在广泛的知识密集型NLP任务上微调和评估了我们的模型,并在三个开放领域的QA任务上达到了sota,优于参数化的seq2seq模型和特定任务的检索和提取架构。对于语言生成任务,我们发现RAG模型生成的语言比最先进的参数化seq2seq基准模型生成的语言更具体、更多样、更真实。
- 通过预训练LLM可以获取token之间的关系概率。但不好更新或扩展、不好追溯来源或说明依据、可能幻觉。
- RAG-Sequence:生成一整个答案时,主要依赖同一个检索文档;RAG-Token:生成答案的不同 token 时,可以参考不同的文档(每生成一个 token,模型都可以重新决定:现在更该依赖哪篇检索文档)。
- 个人感觉相当于一个搜索引擎+一个LLM组织生成的输出
1.1.介绍
已有研究表明,预训练神经语言模型能够从数据中学习到大量深入的知识。它们可以在不访问任何外部记忆的情况下做到这一点,表现为一种由参数承载的隐式知识库。尽管这一发展令人兴奋,但这类模型确实也有缺点:它们不能轻易地扩展或修改自己的记忆,不能直接清楚地说明其预测依据,并且可能产生“幻觉”。将参数化记忆与非参数化记忆,即基于检索的记忆,结合起来的混合模型,可以解决其中一些问题,因为知识可以被直接修改和扩展,而且被访问到的知识可以被检查和解释。REALM 和 ORQA 是最近提出的两个模型,它们将 masked language models 与可微分检索器结合起来,并已经显示出有前景的结果,但它们只探索了开放域抽取式问答。在本文中,我们将这种参数化记忆与非参数化记忆相结合的混合方式,引入到 NLP 的“主力模型”中,也就是序列到序列模型。
- “external memory” 指外部知识源,比如 Wikipedia、数据库、文档库。
- 开放域,问题可以来自任何主题,不局限于某篇给定文章。抽取式问答,答案通常是从检索到的文档中截取一个文本片段,而不是自由生成。
- seq2seq 模型就是输入一个序列,输出另一个序列,如:文章 → 摘要;英文 → 中文。
我们通过一种通用的微调方法,为预训练的、具有参数化记忆的生成模型赋予非参数化记忆;我们将这种方法称为检索增强生成,即 RAG。我们构建的 RAG 模型中,参数化记忆是一个预训练的序列到序列 Transformer,而非参数化记忆是 Wikipedia 的稠密向量索引,并通过一个预训练的神经检索器来访问。我们将这些组件结合到一个端到端训练的概率模型中。检索器,即 Dense Passage Retriever,以下简称 DPR,会在给定输入的条件下提供潜在文档;随后,序列到序列模型,即 BART,会同时基于这些潜在文档和输入来生成输出。我们使用 top-K 近似对这些潜在文档进行边缘化;这种边缘化可以基于整个输出进行,即假设同一个文档负责所有 token,也可以基于每个 token 进行,即不同文档负责不同 token。像 T5 或 BART 一样,RAG 可以在任何序列到序列任务上进行微调,在这个过程中,生成器和检索器会被联合学习。
- RAG可以理解为:先检索,再生成;用检索结果增强生成模型。(BART 生成器 + DPR 检索器 + Wikipedia 向量库)
- “probabilistic model” 是因为论文把检索到的文档看成一个潜变量,然后对不同文档的生成概率进行加权求和。
- “trained end-to-end” 的意思是:模型训练时不是只训练生成器,也不是只训练检索器,而是让检索器和生成器在同一个目标函数下联合优化。文档编码器和索引是固定的,主要训练的是 query encoder 和 BART generator。训练过程中,生成器 BART 会学习如何利用检索文档,检索器 DPR 的 query encoder 也会学习如何检索对生成答案更有帮助的文档。
- 现在个人认为已经有些过时了,从今天做工程 RAG 的角度看,query encoder现在可以不用自己训练了,有开源的小参数embedding模型或者可以直接api调用embedding模型。(qwen或openai)
- “latent documents“是因为训练数据通常只有输入和答案,没有明确标注“应该检索哪篇文档”。所以文档 z 是模型自己推断出来的中间变量。输入问题 x → DPR 检索文档 z → BART 根据 x 和 z 生成答案 y。
- 检索器不可能对 Wikipedia 中所有文档都计算生成概率,所以只取最相关的前 K 个文档。模型不直接确定“唯一正确文档是哪一个”,而是把多个可能文档的贡献综合起来。按两种方式加权:
- per-output basis,即RAG-Sequence
- per-token basis,即RAG-Token
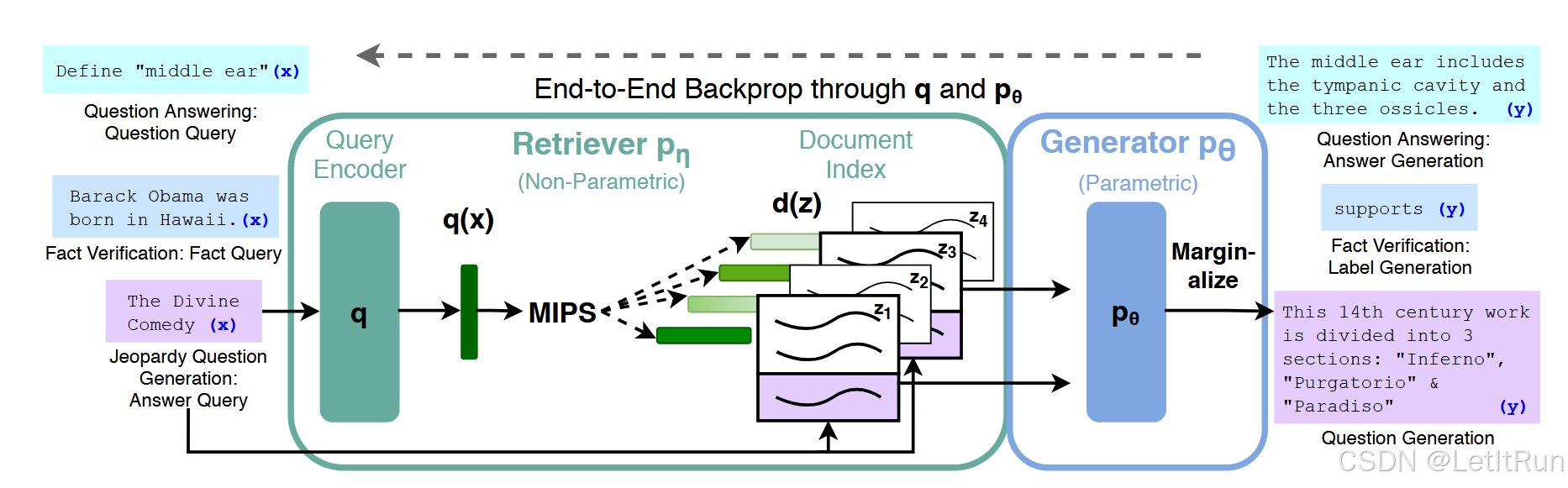
- RAG 的完整工作流程:输入一个问题/任务 → 检索器去 Wikipedia 里找相关文档 → 生成器结合“原始输入 + 检索文档”生成答案 → 训练时让检索器和生成器一起变好。
- 左边:输入 x(问答任务、事实验证任务、问题生成任务)
- 中间绿色大框:Retriever 检索器,也就是非参数化记忆(Query Encoder把文字问题变成一个向量表示q(x) -> Document Index 是已经提前建好的 Wikipedia 文档向量库 -> MIPS 在所有 Wikipedia 文档向量中找出和 q(x) 最相似的几个文档向量)
- 右边蓝色大框:Generator 生成器,也就是参数化记忆
- 右边:输出 y
此前已经有大量工作提出各种架构,用非参数化记忆来增强系统;这些系统通常是针对特定任务从零开始训练的,例如记忆网络、栈增强网络和记忆层。相比之下,我们探索的是一种设置:其中参数化记忆组件和非参数化记忆组件都已经经过预训练,并且已经预先装载了大量知识。关键的是,通过使用预训练好的访问机制,模型在不需要额外训练的情况下就已经具备访问知识的能力。
-
DPR 预训练是因为如果检索器也完全从零开始训练,模型可能很难学会怎么从几千万篇文档中找到有用知识。
我们的结果凸显了在知识密集型任务中将参数化记忆、非参数化记忆与生成结合起来的好处。所谓知识密集型任务,是指那些如果不能访问外部知识源,人类也不能被合理期待完成的任务。我们的 RAG 模型在开放域 Natural Questions、WebQuestions 和 CuratedTrec 上取得了当时最先进的结果,并且在 TriviaQA 上显著超过了使用专门预训练目标的近期方法。尽管这些任务本身是抽取式任务,但我们发现,不受约束的生成方法超过了以往的抽取式方法。对于知识密集型生成任务,我们在 MS-MARCO 和 Jeopardy 问题生成任务上进行了实验,并发现我们的模型相比 BART 基线模型,能够生成更加符合事实、更加具体、也更加多样的回答。在 FEVER 事实验证任务上,我们取得的结果与使用强检索监督的当时最先进流水线模型相差在 4.3% 以内。最后,我们展示了可以通过替换非参数化记忆,随着世界变化来更新模型的知识。
- RAG 不是抽取答案片段,它是直接生成答案。这叫 unconstrained generation,也就是生成内容不被限制为文档中的连续片段。
- 作者发现:即使任务传统上是抽取式的,RAG 这种自由生成方式反而效果更好。
- 原因可能是:有些文档提供了线索,但没有完全包含答案原文。抽取式模型必须找到原文片段;生成式模型可以综合证据后生成答案。
- 只要替换 Wikipedia index,模型就能基于新的外部知识回答新事实。这就是论文后面说的 index hot-swapping,也就是“热替换索引”。
1.2.方法
我们研究 RAG 模型,这类模型使用输入序列 x 来检索文本 z,并在生成目标序列 y 时,将这些文档作为额外上下文。如图 1 所示,我们的模型利用两个组件:第一,一个带有参数 η 的检索器 pη(z|x),它在给定查询 x 时,返回文本段落上的一个经过 top-K 截断的概率分布。第二,一个由参数 θ 参数化的生成器 pθ(yi | x, z, y1:i−1),它基于此前的 i−1 个 token,即 y1:i−1,原始输入 x,以及检索到的段落 z,来生成当前 token。为了端到端地训练检索器和生成器,我们将检索到的文档视为一个潜变量。我们提出了两个模型,它们以不同方式对这些潜在文档进行边缘化,从而产生生成文本上的概率分布。在第一种方法 RAG-Sequence 中,模型使用同一篇文档来预测每一个目标 token。第二种方法 RAG-Token,可以基于不同的文档来预测每一个目标 token。接下来,我们将形式化地介绍这两个模型,然后描述 pη 和 pθ 这两个组件,以及训练和解码过程。
- pη(z | x):在给定输入 x 的条件下,检索到文档 z 的概率。也就是说,检索器会判断:“哪些文档最可能和输入 x 有关?”
- top-k:实际 Wikipedia 文档太多,模型不会对所有文档都算概率,只保留最相关的前 K 篇文档(只在 top-K 个检索文档上分配概率)。
- pθ(yi | x, z, y1:i−1):在给定输入 x、检索文档 z、以及前面已经生成的 token 的条件下,生成当前第 i 个 token yi 的概率。
- 如,模型要生成回答:“The middle ear includes the tympanic cavity.”,当它正在生成第 4 个词时:x = “Define middle ear”;z = 检索到的 Wikipedia 段落;y1:i−1 = 前面已经生成的词,即 “The middle ear”;yi = 当前要预测的词,即 “includes”。生成器会计算概率并选择概率高的词继续生成。
- 隐变量:z 是隐藏的、不直接给定的。模型必须自己学习“哪些文档有助于生成正确答案”。
1.2.1.模型
RAG-Sequence 模型。RAG-Sequence 模型使用同一个检索到的文档来生成完整序列。从技术上说,它把检索到的文档视为一个单一的潜变量,并通过 top-K 近似对其进行边缘化,从而得到序列到序列概率 p(y|x)。具体来说,首先使用检索器检索出前 K 个文档,然后生成器针对每个文档分别产生输出序列的概率,最后再将这些概率进行边缘化。
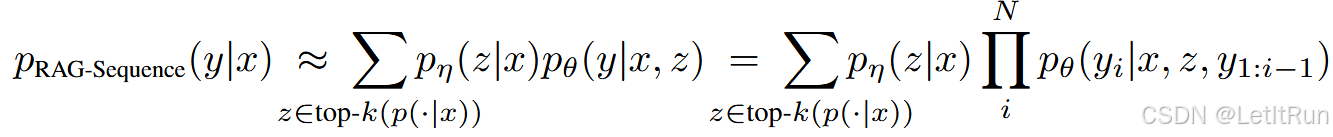
- 单一的潜变量:对于整个输出 y,模型隐含地认为有一个文档 z 在支撑它。
- 流程:先选 top-K 个最相关文档;然后对每个文档分别进行 beam search,生成若干候选答案;再把所有候选答案放到一起,用 RAG-Sequence 的边缘化概率重新打分;最后选总分最高的答案。
- 最终打分不是只看“这段答案来自哪篇文档”,而是看这个答案在所有 top-K 文档上的加权总支持。p(y|x) ≈ 所有 top-K 文档对 y 的贡献之和。直观一些就是“文档贡献 = 检索概率 × 生成概率”,最后把 top-K 文档的贡献加起来,就是 RAG-Sequence 的整体生成概率。
先固定一篇文档,生成整句话;最后在文档层面求和。
- 假设用户输入:x = “Who wrote The Divine Comedy?”(谁写了《神曲》?)
- 目标是生成答案:y = Dante Alighieri
第一步:检索器先找 top-K 文档
假设 K=3。检索器根据问题 x,从 Wikipedia 向量库里找出 3 个最相关文档:
文档
内容大意
检索概率
z1
《神曲》是 Dante Alighieri 写的意大利长诗
0.50
z2
Dante Alighieri 是意大利诗人,代表作是《神曲》
0.35
z3
《神曲》分为 Inferno、Purgatorio、Paradiso
0.15
这里的检索概率就是pη(z | x),意思是:给定问题 x,这篇文档 z 有多相关。
第二步:生成器分别基于每篇文档生成候选答案
基于 z1 生成:输入给生成器的是:
问题 x:Who wrote The Divine Comedy?
文档 z1:《神曲》是 Dante Alighieri 写的意大利长诗生成器可能产生候选答案:
候选答案
生成概率
Dante Alighieri
0.80
Dante
0.15
an Italian poet
0.05
基于 z2 生成:输入给生成器的是:
问题 x:Who wrote The Divine Comedy?
文档 z2:Dante Alighieri 是意大利诗人,代表作是《神曲》生成器可能产生候选答案:
候选答案
生成概率
Dante Alighieri
0.70
Dante
0.25
Italian poet
0.05
基于 z3 生成:输入给生成器的是:
问题 x:Who wrote The Divine Comedy?
文档 z3:《神曲》分为 Inferno、Purgatorio、Paradiso这篇文档没有直接说作者是谁,所以生成器可能比较不确定:
候选答案
生成概率
Dante Alighieri
0.20
Inferno
0.30
unknown
0.10
第三步:把所有候选答案放到一起,现在候选答案池里有:
- Dante Alighieri
- Dante
- an Italian poet
- Italian poet
- Inferno
- unknown
Dante Alighieri 同时被 z1、z2、z3 支持,只是支持程度不同。
第四步:给每个候选答案算综合分
RAG-Sequence 一个答案的最终综合分 = 它在 z1 下的分数 × z1 的相关性 + 它在 z2 下的分数 × z2 的相关性 + 它在 z3 下的分数 × z3 的相关性
“Dante Alighieri” 的综合分:0.50 × 0.80 + 0.35 × 0.70 + 0.15 × 0.20
= 0.40 + 0.245 + 0.03 = 0.675“Dante” 的综合分:0.50 × 0.15 + 0.35 × 0.25 + 0.15 × 0.05
= 0.075 + 0.0875 + 0.0075 = 0.17“Inferno” 的综合分:0.50 × 0.01 + 0.35 × 0.01 + 0.15 × 0.30
= 0.005 + 0.0035 + 0.045 = 0.0535第五步:选择综合分最高的答案输出
候选答案
综合分
Dante Alighieri
0.675
Dante
0.17
Inferno
0.0535
所以最终输出:Dante Alighieri
RAG-Token 模型。在 RAG-Token 模型中,我们可以为每一个目标 token 抽取一个不同的潜在文档,并相应地进行边缘化。这使得生成器在生成一个答案时,可以从多个文档中选择内容。具体来说,首先使用检索器检索出前 K 个文档(这一步和 RAG-Sequence 一样)。然后,生成器会针对每一篇文档,为下一个输出 token 产生一个概率分布,之后再进行边缘化(得到当前 token $y_i$ 的综合概率)。然后对后续的输出 token 重复这一过程。
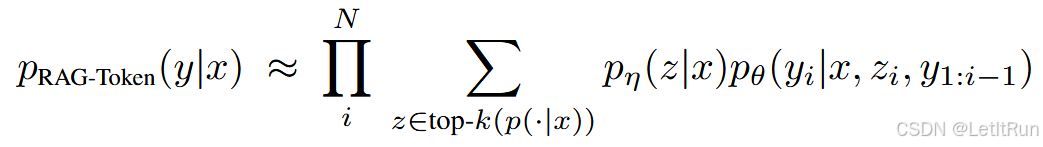
-
生成每个 token 时,模型都可以重新考虑 top-K 文档中哪篇更有用。
每生成一个 token,都先在 top-K 文档中求和;然后把所有 token 的概率连乘。
假设用户输入:x = “Tell me one sentence about Hemingway’s famous novels.”(说一句关于海明威著名小说的话。)
目标是生成答案:y = Hemingway wrote The Sun Also Rises and A Farewell to Arms.(这句话包含两个作品名,可能分别由不同文档支持)
第一步:检索器先找 top-K 文档
假设 K=3。检索器根据输入 x 找到三篇相关文档:
文档
内容大意
检索概率
z1
Hemingway 是美国作家,作品包括 A Farewell to Arms
0.45
z2
The Sun Also Rises 是 Hemingway 的小说
0.40
z3
Hemingway 获得诺贝尔文学奖
0.15
第二步:开始逐 token 生成
(在解码生成时,RAG-Token 可以理解为:每一步都先计算“下一个 token 的综合概率分布”,然后从里面选择概率高的 token。实际生成通常不是简单每一步贪心选最大,而是用 beam search 保留多个高概率候选序列)
RAG-Token 的关键是:每生成一个 token,都在 top-K 文档上重新综合一次概率。假设要生成第一个 token:Hemingway,生成器分别基于每篇文档计算这个 token 的概率:
文档
检索概率
生成 “Hemingway” 的概率
加权贡献
z1
0.45
0.90
0.405
z2
0.40
0.85
0.340
z3
0.15
0.80
0.120
综合后:p(y1=Hemingway∣x)=0.405+0.340+0.120=0.865,所以第一个 token 很可能生成:Hemingway
第三步:生成第二个 token
现在已经生成了:Hemingway,接下来预测:$y_2 =$ wrote。计算综合分:
文档
检索概率
生成 “wrote” 的概率
加权贡献
z1
0.45
0.80
0.360
z2
0.40
0.75
0.300
z3
0.15
0.30
0.045
0.360+0.300+0.045=0.705
所以第二个 token 生成:wrote,当前输出变成:Hemingway wrote
……后续逐个生成直到结束
最后,我们指出,RAG 也可以用于序列分类任务:只需要把目标类别看作一个长度为 1 的目标序列。在这种情况下,RAG-Sequence 和 RAG-Token 是等价的。
-
比如判断或分类任务,因为输出只有一个 token,所以RAG-Sequence 和 RAG-Token 两个公式完全一样。
1.2.2.检索器DPR
检索组件pη(z | x)基于 DPR(Dense Passage Retriever,稠密段落检索器)。DPR 采用双编码器架构。其中,d(z)是由一个 BERTBASE 文档编码器产生的文档稠密表示,而q(x)是由一个查询编码器产生的查询表示,该查询编码器同样基于 BERTBASE。计算top-k(pη(·|x))也就是找出先验概率pη(z | x)最高的k个文档z,是一个最大内积搜索问题,即 MIPS(Maximum Inner Product Search);这个问题可以用近似方法在次线性时间内解决。我们使用 DPR 中预训练好的双编码器来初始化我们的检索器,并构建文档索引。这个检索器曾被训练用于检索包含 TriviaQA 和 Natural Questions 问题答案的文档。我们将文档索引称为非参数化记忆。
![]()
- bi-encoder 就是两个 encoder:一个编码问题/查询;一个编码文档/段落。它们结构类似,但参数可以不同。
- q(x):用 query encoder 把输入问题 $x$ 编码成一个向量,这个向量表示“这个问题在语义空间中的位置”。
- d(z):用 document encoder 把文档 $z$ 编码成一个向量。dense representation 指稠密向量。它不是关键词列表,而是连续数值向量,能够表达语义相似性。
- 文档向量和问题向量的内积,内积越大,说明问题和文档越相关。
- 加指数函数exp:内积可以是任意实数,而概率需要是正数。概率和这个指数分数成正比。
- MIPS:不能每次问题来了都和所有文档逐个精确比较,那太慢。而是找和问题向量最相似的 K 个文档向量。
- DPR 原本就是为开放域问答训练的。训练目标大致是:给定一个问题,检索到包含答案的文档。
1.2.3.生成器BART
生成器组件 $p_\theta(y_i|x, z, y_{1:i-1})$ 可以用任何编码器-解码器模型来建模。我们使用 BART-large,这是一个拥有 4 亿参数的预训练序列到序列 Transformer。为了在使用 BART 生成时将输入 $x$ 和检索到的内容 $z$ 结合起来,我们只是简单地将它们拼接在一起。BART 是通过去噪目标以及多种不同的加噪函数进行预训练的。它已经在多种生成任务上取得了当时最先进的结果,并且超过了参数规模相近的 T5 模型。从此以后,我们将 BART 生成器的参数 $\theta$ 称为参数化记忆。
- 这个生成器不一定非得是 BART。理论上,只要是 encoder-decoder 架构都可以,比如后来的 T5、FLAN-T5、BART 变体等。
- 作者没有设计复杂的融合模块,而是直接拼接,然后让 BART 自己通过 attention 学会如何利用文档和问题。
- BART 的预训练方式可以理解成:先把一段正常文本破坏掉,再让模型恢复原文。BART 在预训练中已经学到很多语言知识和事实知识,称其为参数化记忆。
1.2.4.训练
我们联合训练检索器和生成器组件,但并不对“应该检索哪篇文档”提供任何直接监督。给定一个由输入/输出对 $(x_j, y_j)$ 组成的微调训练语料,我们使用 Adam 随机梯度下降,最小化每个目标的负边缘对数似然(这就是标准的最大似然训练,负号是因为优化器通常做“最小化”,而我们想“最大化正确答案概率”)。在训练过程中更新文档编码器 $BERT_d$ (文档编码器)是代价很高的,因为这要求像 REALM 在预训练时那样,周期性地更新文档索引。我们发现,为了获得强性能,这一步并不是必要的;因此我们保持文档编码器以及索引固定,只微调查询编码器 $BERT_q$ 和 BART 生成器。
-
如果训练时更新 $BERT_d$,那就意味着:文档向量 $d(z)$ 会变化,原来的文档索引就过期了。
1.2.5.解码
在测试时,RAG-Sequence 和 RAG-Token 需要用不同的方法来近似求解 $\arg\max_y p(y|x)$。
RAG-Token 的解码。RAG-Token 模型可以被看作一个标准的自回归 seq2seq 生成器,只不过它的转移概率如下式。为了解码,我们可以把这个 $p'_\theta(y_i|x,y_{1:i-1})$ 直接放进一个标准的 beam decoder 中。
$$p'_\theta(y_i|x,y_{1:i-1})=
\sum_{z \in top-k(p(\cdot|x))} p_\eta(z_i|x)p_\theta(y_i|x,z_i,y_{1:i-1})$$
- RAG-Token 比较好解码,因为它可以写成标准的逐 token 生成形式。它仍然是一个标准自回归模型,只是把普通的seq2seq的生成改写成了 $p'_\theta(y_i|x,y_{1:i-1})$ 。
- 每一步都让 top-K 文档一起给下一个 token 投票,然后 beam search 保留整体概率高的候选序列。
RAG-Sequence 的解码。对于 RAG-Sequence,似然 $p(y|x)$ 不能分解成传统的逐 token 似然,因此我们不能用一次普通 beam search 来求解它。相反,我们会对每一篇文档 $z$ 分别运行 beam search,并使用 $p_\theta(y_i|x,z,y_{1:i-1})$ 给每个假设序列打分。这会得到一个候选假设集合 $Y$,其中有些候选答案可能并没有出现在所有文档对应的 beam 中。为了估计某个候选答案 $y$ 的概率,对于那些在其 beam 中没有出现 $y$ 的文档 $z$,我们会额外运行一次前向传播,计算该文档下生成 $y$ 的概率;然后将生成概率与 $p_\eta(z|x)$ 相乘,再把不同文档上的概率相加,得到边缘概率。我们把这种解码过程称为 “Thorough Decoding”。对于较长的输出序列,$|Y|$ 可能会变得很大,从而需要很多次前向传播。为了更高效地解码,我们可以进一步近似:如果某个答案 $y$ 在基于 $x,z_i$ 的 beam search 中没有被生成出来,那么就认为 $p_\theta(y|x,z_i)\approx 0$。这样一来,一旦候选集合 $Y$ 被生成出来,就不需要再运行额外的前向传播。我们把这种解码过程称为 “Fast Decoding”。
在前文解读所举的例子中,假设所有候选答案的集合Y = {Dante Alighieri, Dante, Italian poet, Inferno},但不是每个答案都在每篇文档的 beam search 结果里出现。如:
|
候选答案 |
z1 beam 中出现? |
z2 beam 中出现? |
z3 beam 中出现? |
|---|---|---|---|
|
Dante Alighieri |
是 |
是 |
否 |
|
Dante |
是 |
是 |
是 |
|
Inferno |
否 |
否 |
是 |
可是 RAG-Sequence 的最终概率需要:
$$p(y|x)=\sum_z p_\eta(z|x)p_\theta(y|x,z)$$
也就是说,对于每个候选答案 $y$,理论上都要知道它在每个文档 $z$ 下的概率。因此提出:“Thorough Decoding”。它的做法是:哪怕某个候选答案没有在某篇文档的 beam search 中出现,也要额外算一下它在这篇文档下的概率。例如候选答案:Dante Alighieri,它在 z1 和 z2 的 beam 中出现了,但在 z3 的 beam 中没出现。Thorough Decoding 仍然会额外计算:pθ(Dante Alighieri∣x,z3),并最终综合:
$$p(\text{Dante Alighieri}|x)
=
p_\eta(z1|x)p_\theta(y|x,z1)
+
p_\eta(z2|x)p_\theta(y|x,z2)
+
p_\eta(z3|x)p_\theta(y|x,z3)$$
这样最准确,但更慢。
如果答案很长,每篇文档的 beam search 会产生很多候选答案。合并后的候选集合 $Y$ 很大。如果对每个候选答案、每篇文档都额外计算概率,计算成本会很高。因此提出:“Fast Decoding”,认为如果某个答案在某篇文档的 beam search 里根本没出现,就认为这篇文档对这个答案的支持概率约等于 0。Fast Decoding 不再额外计算pθ(Dante Alighieri∣x,z3),而是直接近似它约等于0,这样更快,但更粗略。
1.3.实验与结果
我们在一系列广泛的知识密集型任务上对 RAG 进行实验。在所有实验中,我们都使用同一个 Wikipedia dump 作为我们的非参数化知识源。按照 Lee 等人和 Karpukhin 等人的做法,我们使用 2018 年 12 月的 Wikipedia dump。每篇 Wikipedia 文章都被切分成互不重叠的 100 词文本块,总共形成了 2100 万个文档。我们使用文档编码器为每个文档计算一个 embedding,并使用 FAISS 构建一个单一的 MIPS 索引,其中采用 Hierarchical Navigable Small World 近似方法来实现快速检索。在训练过程中,我们为每个查询检索前 $k$ 个文档。训练时,我们考虑 $k \in \{5,10\}$,并使用验证集(dev)数据来设置测试时的 $k$。接下来,我们将讨论每个任务的实验细节。
- Wikipedia dump 指某个时间点导出的 Wikipedia 全量数据。
- 这里的 “documents” 不是完整 Wikipedia 文章,而是切出来的小段(chunk)。
- disjoint 意思是互不重叠,也就是每个 chunk 之间没有重复词。即每100个单词一个chunk。
- 为什么要切成 100 词?个人理解:因为完整文章太长,检索和输入给生成器都不方便。切成短段后:检索更精准;BART 输入长度更可控;文档向量表示更聚焦。
- MIPS:Maximum Inner Product Search,最大内积搜索。就是找出和 query 向量内积最大的文档向量。
- FAISS:Facebook AI Similarity Search,一个高效向量检索库。用于在海量向量中快速做相似度检索。
- Hierarchical Navigable Small World approximation,HNSW:一种近似最近邻搜索算法。它通过构建图结构,让检索不必扫描全部 2100 万个向量,从而加速搜索。
1.3.1.开放域QA
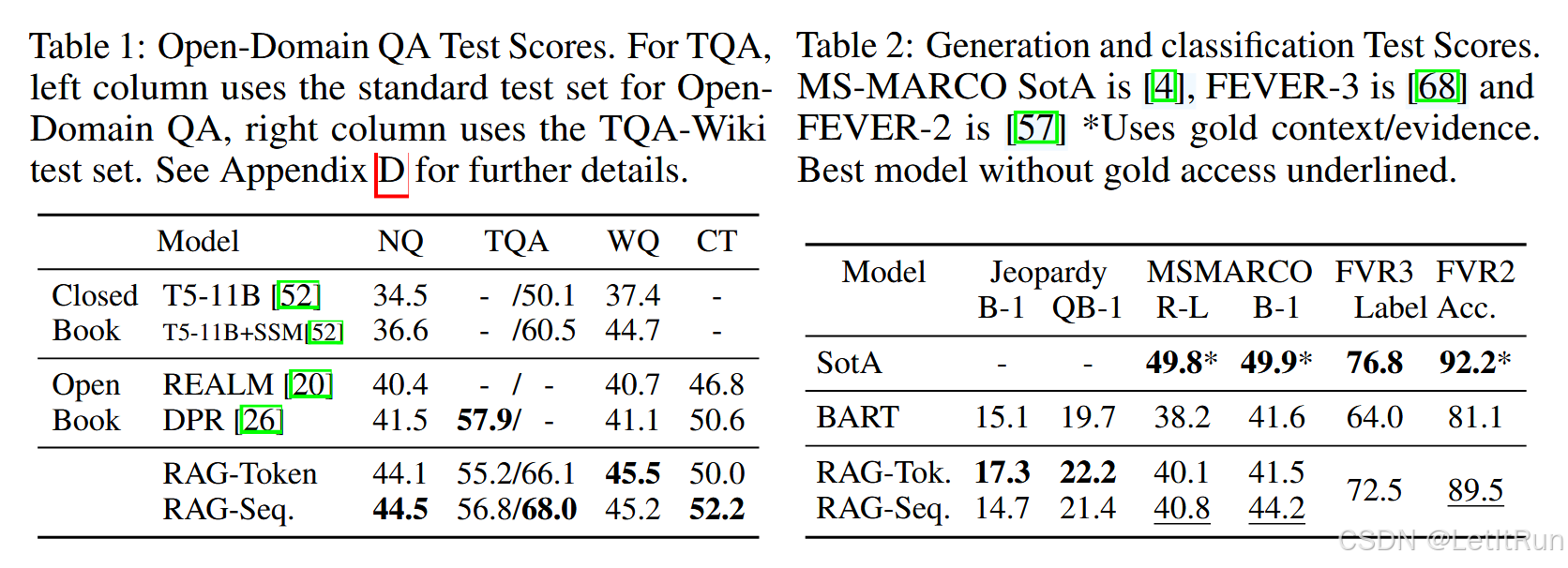
开放域问答是一个重要的现实应用,也是知识密集型任务的常见测试平台。我们将问题和答案看作输入-输出文本对 $(x,y)$,并通过直接最小化答案的负对数似然来训练 RAG。我们将 RAG 与流行的抽取式问答范式进行比较:在这种范式中,答案是从检索到的文档中抽取出来的文本片段,主要依赖非参数化知识。我们也将 RAG 与 “闭卷问答” 方法进行比较:这些方法和 RAG 一样会生成答案,但它们不利用检索,而是完全依赖参数化知识。我们考虑四个流行的开放域问答数据集:Natural Questions,TriviaQA,WebQuestions 和 CuratedTrec。由于 CT 和 WQ 数据集较小,我们遵循 DPR 的做法,用我们的 NQ RAG 模型来初始化 CT 和 WQ 模型。我们使用与先前工作相同的训练集、开发集和测试集划分,并报告 Exact Match 分数。对于 TriviaQA,为了与 T5 进行比较,我们还在 TQA Wiki 测试集上进行了评估。
- 传统方法通常是:检索文档 → 从文档中抽取答案 span
- 闭卷问答通常是:输入问题 → 大模型直接生成答案
- RAG 可以看作“开卷生成式问答”。
表 1 展示了 RAG 以及其他当时最先进模型的结果。在所有四个开放域问答任务上,RAG 都取得了新的最先进结果;其中 TriviaQA 是在与 T5 可比较的数据划分上取得的。RAG 结合了“闭卷”方法,即纯参数化方法的生成灵活性,以及“开卷”检索式方法的性能优势。不同于 REALM 和 T5+SSM,RAG 在没有昂贵且专门的 “salient span masking” 预训练的情况下,也取得了很强的结果。值得注意的是,RAG 的检索器是用 DPR 的检索器初始化的,而 DPR 的检索器在 Natural Questions 和 TriviaQA 上使用了检索监督。与 DPR QA 系统相比,RAG 也表现得很有竞争力;DPR QA 系统使用基于 BERT 的 cross-encoder 来重排序文档,并结合一个抽取式阅读器。RAG 表明,要达到最先进性能,并不一定需要重排序器,也不一定需要抽取式阅读器。
即使答案可以被抽取出来,生成答案仍然有几个优势。一些文档虽然包含关于答案的线索,但并没有逐字包含答案本身;这些文档仍然可以帮助模型生成正确答案,而这对于标准抽取式方法是不可能的,因此生成式方法可以更有效地对文档进行边缘化。此外,即使正确答案不在任何检索到的文档中,RAG 仍然可以生成正确答案;在 NQ 数据集的这类情况下,RAG 达到了 11.8% 的准确率,而抽取式模型在这种情况下会得 0%。
1.3.2.抽象式QA
RAG 模型可以超越简单的抽取式问答,用自由形式的、抽象式文本生成来回答问题。为了在知识密集型场景中测试 RAG 的自然语言生成能力,我们使用 MSMARCO NLG v2.1 任务。这个任务由问题、每个问题对应的十个由搜索引擎检索出的 gold passages,以及根据这些检索段落标注出的完整句子答案组成。我们不使用数据集中提供的段落,只使用问题和答案,从而将 MSMARCO 当作一个开放域抽象式问答任务。MSMARCO 中有一些问题,如果不能访问 gold passages,就无法生成与参考答案匹配的回答,例如 “What is the weather in Volcano, CA?”,因此在不使用 gold passages 的情况下,性能会更低。我们还指出,有些 MSMARCO 问题仅靠 Wikipedia 是无法回答的(实时信息、本地服务等)。在这种情况下,RAG 可以依靠参数化知识来生成合理的回答(不过这也有风险:如果外部知识没有支持,模型可能更容易生成不精确甚至错误的答案)。
-
抽象式问答 = 看懂资料后自己组织语言回答;抽取式问答 = 从资料里直接摘出答案片段。
如表 2 所示,在 Open MS-MARCO NLG 上,RAG-Sequence 比 BART 高出 2.6 个 BLEU 分数和 2.6 个 Rouge-L 分数。RAG 接近了当时最先进模型的性能;考虑到以下几点,这一点令人印象深刻:第一,那些模型可以访问 gold passages,其中包含生成参考答案所需的具体信息;第二,很多问题如果没有 gold passages 就无法回答;第三,并不是所有问题都能仅靠 Wikipedia 回答。表 3 展示了我们模型生成的一些答案。从定性分析来看,我们发现 RAG 模型比 BART 更少产生幻觉,并且更经常生成符合事实的文本。后面(原文section4.5)我们还会展示,RAG 生成的文本比 BART 生成的文本更加多样。
-
BLEU 和 Rouge-L 都是文本生成常用指标。分数高,通常表示生成答案和人工参考答案更接近。BLEU:看模型生成文本和参考答案在词/短语上有多相似。Rouge-L:看生成文本和参考答案之间最长公共子序列的重合程度。
1.3.3.疑难问题生成
为了在非问答场景中评估 RAG 的生成能力,我们研究开放域问题生成。我们没有使用标准开放域问答任务中的问题,因为那些问题通常较短且简单;相反,我们提出了一个要求更高的任务:生成 Jeopardy 问题。Jeopardy 是一种不寻常的形式,其内容是根据关于某个实体的事实来猜测这个实体。例如,“The World Cup” 是下面这个问题的答案:“1986 年,墨西哥成为第一个两次举办这项国际体育赛事的国家。”由于 Jeopardy 问题是精确的事实性陈述,因此在给定答案实体的条件下生成 Jeopardy 问题,构成了一个具有挑战性的知识密集型生成任务。我们使用 SearchQA 的数据划分,其中包含 10 万个训练样本、1.4 万个验证集(dev)样本和 2.7 万个测试样本。由于这是一个新任务,我们训练了一个 BART 模型作为比较(纯 BART baseline)。我们使用经过 SQuAD 调整的 Q-BLEU-1 指标进行评估。Q-BLEU 是 BLEU 的一种变体,它对实体匹配赋予更高权重,并且在问题生成任务上比标准指标与人类判断的相关性更高。我们还进行了两项人工评估:一项用于评估生成内容的事实性,另一项用于评估具体性。我们将事实性定义为:一个陈述是否能够被可信的外部来源证实;将具体性定义为:输入和输出之间是否具有高度的相互依赖关系。我们遵循最佳实践,使用成对比较评估。评估者会看到一个答案和两个生成的问题,其中一个来自 BART,另一个来自 RAG。然后,他们被要求在四个选项中选择一个:问题 A 更好,问题 B 更好,两者都好,或者两者都不好。
- 问题生成:答案/实体 → 问题
- Q-BLEU-1 是用于问题生成的自动评价指标。普通 BLEU 主要看 n-gram 重合,但问题生成任务里,实体、关键词、语义匹配更重要。
所以作者用了更适合问题生成的 Q-BLEU-1。
表 2 显示,在 Jeopardy 问题生成任务上,RAG-Token 的表现优于 RAG-Sequence,并且两个 RAG 模型在 Q-BLEU-1 指标上都超过了 BART。表 4 展示了人工评估结果,评估对象是来自 BART 和 RAG-Token 的 452 对生成结果。评估者认为,只有在 7.1% 的情况下 BART 比 RAG 更符合事实;而在 42.7% 的情况下,RAG 比 BART 更符合事实;另外还有 17% 的情况下,RAG 和 BART 都是符合事实的。这清楚地表明,RAG 在这个任务上比一个当时先进的生成模型更有效。评估者还发现,RAG 生成的内容在很大程度上更加具体。表 3 展示了每个模型的一些典型生成结果。Jeopardy 问题通常包含两条相互独立的信息,而 RAG-Token 可能表现最好,因为它能够生成结合多个文档内容的回答。图 2 展示了一个例子。当生成 “Sun” 时,文档 2 的后验概率很高,因为文档 2 提到了 “The Sun Also Rises”。类似地,当生成 “A Farewell to Arms” 时,文档 1 在后验概率中占主导。有趣的是,在每本书名的第一个 token 被生成之后,文档后验概率变得平坦。这一观察表明,生成器可以在不依赖特定文档的情况下补全这些书名。当给 BART 部分解码结果 “The Sun Also Rises is a novel by this author of A” 时,BART 会将其补全为 “The Sun Also Rises is a novel by this author of A Farewell to Arms”。这个例子展示了参数化记忆和非参数化记忆如何协同工作:非参数化组件帮助引导生成过程,从而引出存储在参数化记忆中的具体知识。
- 因为 Jeopardy 问题往往需要组合多个知识点,RAG-Token 可以在每个 token 级别切换文档,因此更适合这个任务。
- posterior flattens:模型不再特别强烈依赖某一篇文档,各文档的后验概率变得比较接近。如生成 “The Sun Also Rises” 时:生成 “Sun” 的时候,模型强烈依赖文档 2;但一旦 “The Sun...” 已经出来,后面 “Also Rises” 可能模型自己就能补全,不再需要强依赖文档 2。也就是说,文档主要帮助模型“启动”或“指向”正确知识,之后模型参数里的记忆可以完成剩余部分。

1.3.4.事实验证
FEVER 要求模型判断一个自然语言声明是否被 Wikipedia 支持、是否被 Wikipedia 反驳,或者是否没有足够信息来做出判断。这个任务要求从 Wikipedia 中检索与该声明相关的证据,然后基于这些证据进行推理,以判断这个声明是真的、假的,还是仅凭 Wikipedia 无法验证的。FEVER 是一个检索问题,同时还结合了一个具有挑战性的蕴含推理任务。它也为探索 RAG 模型处理分类任务而非生成任务的能力,提供了一个合适的测试平台。我们将 FEVER 的类别标签,也就是 supports、refutes 或 not enough info,映射为单个输出 token,并直接使用 claim-class 对进行训练。关键的是,与大多数其他 FEVER 方法不同,我们不使用关于检索证据的监督信号(gold evidence,即明确告知模型对这个 claim,应该检索哪几句 Wikipedia 证据)。在许多现实应用中,检索监督信号并不存在;因此,不需要这种监督信号的模型将适用于更广泛的任务。我们探索两个变体:标准的三分类任务,即 supports/refutes/not enough info;以及 Thorne 和 Vlachos 研究过的二分类任务,即 supports/refutes。在这两种情况下,我们都报告标签准确率。
-
该任务的目的在于测试 RAG 是否也能做分类任务,而不只是生成任务。
表 2 展示了我们在 FEVER 上的结果。对于三分类任务,RAG 的得分与当时最先进模型的差距在 4.3% 以内;而那些最先进模型是复杂的流水线系统,使用了特定领域架构和大量工程设计,并且通过中间检索监督进行训练,而这些都是 RAG 不需要的。对于二分类任务,我们与 Thorne 和 Vlachos 的方法进行比较;他们训练 RoBERTa,在给定 gold evidence sentence 的情况下,将 claim 分类为真或假。尽管 RAG 只被提供 claim,并且需要自己检索证据,它仍然取得了与该模型相差在 2.7% 以内的准确率。我们还分析了 RAG 检索到的文档是否与 FEVER 中标注为 gold evidence 的文档相对应。我们计算 RAG 检索到的 top-k 文档与 gold evidence 标注之间,在文章标题上的重合度。我们发现,在 71% 的情况下,排名第一的检索文档来自 gold article;并且在 90% 的情况下,top 10 检索文章中包含 gold article。
1.3.5.额外结果
生成多样性
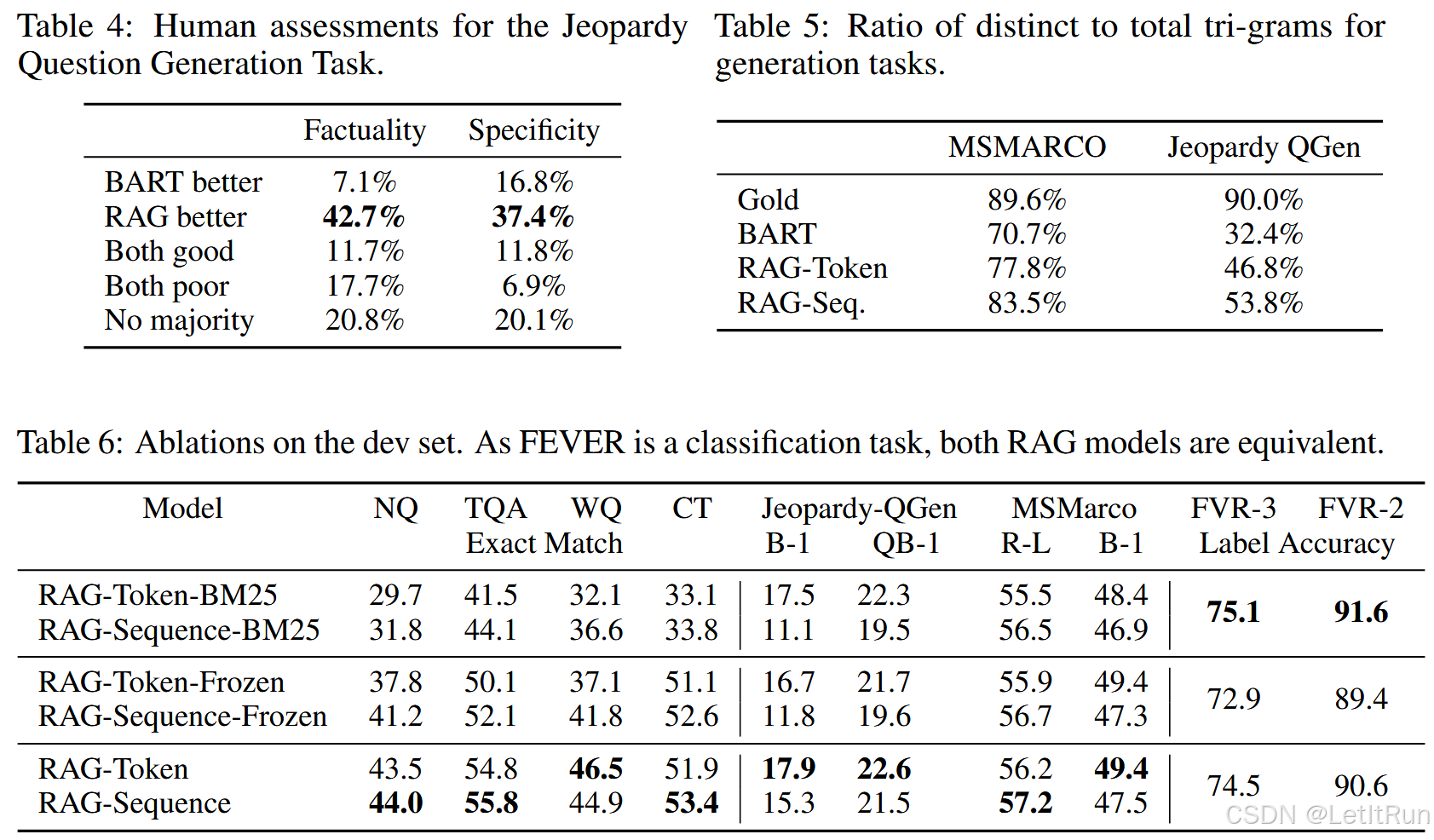
第 4.3 节表明,在 Jeopardy 问题生成任务中,RAG 模型比 BART 更符合事实,也更加具体。按照近期关于促进多样性的解码方法的研究,我们还通过计算不同模型生成结果中 distinct n-grams 占总 n-grams 的比例,来研究生成多样性。表 5 显示,RAG-Sequence 的生成结果比 RAG-Token 更多样,而二者都显著比 BART 更多样,并且不需要任何促进多样性的解码方法。
-
这可能是因为 RAG-Sequence 对整段生成依赖某一篇文档,不同文档会引导生成出风格和内容差异更大的完整句子。并且RAG 能看到不同检索文档,外部文档提供了更多事实和表达方式;而 BART 只靠参数记忆,容易生成更模板化的句子。
检索消融实验
RAG 的一个关键特征是学习为任务检索相关信息。为了评估检索机制的有效性,我们进行了消融实验:在训练过程中冻结检索器。如表 6 所示,经过学习的检索在所有任务上都提升了结果。我们还将 RAG 的稠密检索器与基于词重叠的 BM25 检索器进行比较。在这里,我们将 RAG 的检索器替换为一个固定的 BM25 系统,并在计算 $p(z|x)$ 时,把 BM25 检索分数作为 logits。表 6 展示了这些结果。对于 FEVER,BM25 表现最好,这可能是因为 FEVER 的声明高度以实体为中心,因此非常适合基于词重叠的检索。可微分检索在其他所有任务上都提升了结果,尤其是在开放域问答中,它非常关键。
-
BM25 更像传统搜索引擎:问题和文档中共同出现的关键词越多,相关性越高。
索引热替换
像 RAG 这样的非参数化记忆模型的一个优势是:在测试时,知识可以很容易地被更新(只要替换外部文档索引,就可以更新模型知识,而不一定要重新训练模型)。像 T5 或 BART 这样的纯参数化模型,随着世界变化,需要进一步训练才能更新它们的行为。为了证明这一点,我们使用 DrQA 的 2016 年 12 月 Wikipedia dump 构建了一个索引,并将使用这个索引的 RAG 输出,与主实验中使用的较新索引,即 2018 年 12 月索引,进行比较。我们准备了一份包含 82 位世界领导人的列表,这些领导人在这两个时间点之间发生了变化;然后使用模板 “Who is {position}?”,例如 “Who is the President of Peru?”,分别用每个索引来查询我们的 NQ RAG 模型。当使用 2016 年索引回答 2016 年世界领导人问题时,RAG 的正确率为 70%;当使用 2018 年索引回答 2018 年世界领导人问题时,RAG 的正确率为 68%。当索引和目标年份不匹配时,准确率很低:使用 2018 年索引回答 2016 年领导人时准确率为 12%;使用 2016 年索引回答 2018 年领导人时准确率为 4%。这表明,我们可以仅仅通过替换 RAG 的非参数化记忆来更新它的世界知识。
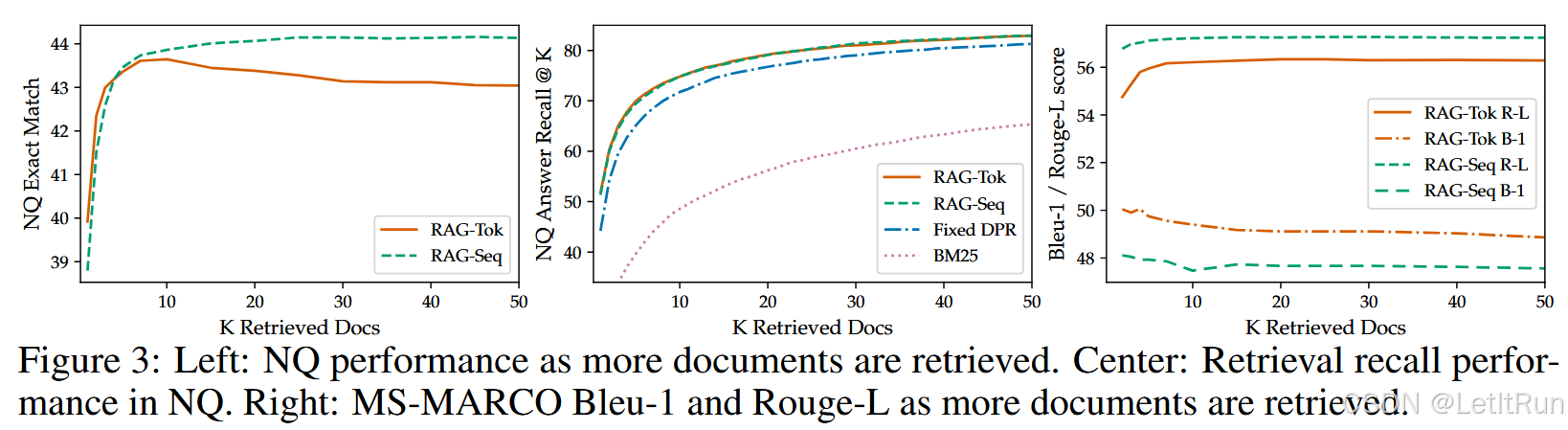
检索更多文档的影响
模型在训练时使用 5 个或 10 个检索到的潜在文档,我们没有观察到二者在性能上的显著差异。我们可以灵活地在测试时调整检索文档的数量,而这会影响性能和运行时间。图 3 左侧显示,在测试时检索更多文档,会单调提升 RAG-Sequence 在开放域问答上的结果;但对于 RAG-Token,性能在检索 10 个文档时达到峰值。图 3 右侧显示,对于 RAG-Token,检索更多文档会带来更高的 Rouge-L,但代价是 Bleu-1 降低;而这种影响在 RAG-Sequence 上不那么明显。
1.4.相关工作
单任务检索
先前工作已经表明,当分别考虑各种 NLP 任务时,检索可以提升这些任务的性能。这些任务包括开放域问答、事实核查、事实补全、长文本问答、Wikipedia 文章生成、对话、翻译以及语言建模。我们的工作统一了此前在各个单独任务中引入检索所取得的成功,表明一个单一的基于检索的架构能够在多个任务上取得强性能。
通用 NLP 架构
NLP 的通用架构。此前关于 NLP 任务通用架构的工作,在不使用检索的情况下已经取得了巨大成功。已有研究表明,一个单一的预训练语言模型,在经过微调之后,可以在 GLUE 基准中的多种分类任务上取得强性能。后来 GPT-2 表明,一个单一的、从左到右生成的预训练语言模型,可以在判别式任务和生成式任务上都取得强性能。为了进一步提升性能,BART 和 T5 提出了单一的预训练编码器-解码器模型,该模型利用双向注意力,在判别式和生成式任务上取得更强表现。我们的工作旨在通过学习一个检索模块来增强预训练生成式语言模型,从而用一个单一、统一的架构扩展可处理任务的范围。
学习式检索
在信息检索领域,已有大量关于学习如何检索文档的工作;最近也有一些类似我们的工作,使用预训练神经语言模型来进行检索。一些工作会优化检索模块,以帮助某个特定下游任务,例如问答;它们使用搜索、强化学习,或者像我们一样使用潜变量方法。这些成功工作利用不同的检索架构和优化技术,在单个任务上取得强性能;而我们展示的是,一个单一的基于检索的架构可以通过微调,在多种任务上取得强性能。
基于记忆的架构
我们的文档索引可以看作神经网络可以关注的大型外部记忆,这类似于记忆网络。同期工作学习为输入中的每个实体检索一个训练好的 embedding,而不是像我们的工作这样检索原始文本。其他工作通过让对话模型关注事实 embedding,或者更接近我们工作地直接关注检索到的文本,来提升对话模型生成事实性文本的能力。我们的记忆有一个关键特征:它由原始文本组成,而不是由分布式表示组成。这使得这种记忆既是:第一,人类可读的,从而为模型提供了一种可解释性;第二,人类可写的,使我们能够通过编辑文档索引来动态更新模型的记忆。
retrieve-and-edit 方法
我们的方法与 retrieve-and-edit 风格的方法有一些相似之处;在这些方法中,对于给定输入,系统会检索一个相似的训练输入-输出对,然后对其进行编辑以得到最终输出。这些方法已经在多个领域取得成功,包括机器翻译和语义解析。不过,我们的方法确实有几个不同点:我们并不强调对某个检索到的项目进行轻微编辑,而是强调聚合多个检索内容中的信息;此外,我们学习的是潜变量式检索,并且检索的是证据文档,而不是相关的训练样本对。话虽如此,RAG 技术也可能在这些场景中表现良好,并可能成为有前景的未来工作。
1.6.讨论
在这项工作中,我们提出了能够访问参数化记忆和非参数化记忆的混合生成模型。我们展示了 RAG 模型在开放域问答任务上取得了当时最先进的结果。我们发现,相比纯参数化的 BART,人们更偏好 RAG 的生成结果,认为 RAG 更符合事实,也更加具体。我们对学习得到的检索组件进行了全面研究,验证了它的有效性。并且我们展示了如何通过热替换检索索引,在不需要任何重新训练的情况下更新模型。在未来工作中,研究这两个组件是否可以从零开始联合预训练,可能会很有价值;这种预训练可以使用类似 BART 的去噪目标,也可以使用其他目标。我们的工作开启了新的研究方向,即研究参数化记忆和非参数化记忆如何相互作用,以及如何最有效地结合二者,并显示出应用于广泛 NLP 任务的潜力。
1.7.社会影响
与先前工作相比,这项工作提供了若干积极的社会效益:由于它更强地扎根于真实的事实性知识(在这里指 Wikipedia),因此它更少产生“幻觉”,生成内容也更符合事实,并且提供了更多控制性和可解释性。RAG 可以被应用于许多能直接造福社会的场景,例如给它配备一个医学索引,并向它提出该领域的开放域问题,或者帮助人们更高效地完成工作。伴随这些优势,也存在潜在缺点:Wikipedia,或者任何可能的外部知识源,可能永远都不会完全事实正确,也不会完全没有偏见。由于 RAG 可以作为语言模型使用,因此类似于 GPT-2 的担忧在这里同样成立,尽管可以说程度可能较轻。这些担忧包括:它可能被用于生成辱骂性内容、新闻或社交媒体中的虚假或误导性内容;用于冒充他人;或者用于自动化生产垃圾信息和钓鱼内容。先进语言模型也可能在未来几十年导致各种工作的自动化。为了缓解这些风险,可以使用 AI 系统来对抗误导性内容以及自动化垃圾信息和钓鱼内容。
2.简易RAG搭建实验
从0搭建一个Tiny-RAG可以参考happyllm的教程(link2happyllm),这里展示一个调用api的RAG。
2.1.一个最小可运行 RAG “Hello World”
不用 LangChain/LlamaIndex,不训练模型,只调用 API 做 embedding 和生成。
pip install openai numpyimport numpy as np
from openai import OpenAI
client = OpenAI(api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxx")
# 1. 准备一个很小的“知识库”
docs = [
"RAG 是 Retrieval-Augmented Generation 的缩写,中文常译为检索增强生成。",
"RAG 的基本流程是:先根据用户问题检索相关文档,再把检索结果作为上下文交给大语言模型生成回答。",
"RAG 可以缓解大语言模型幻觉问题,因为模型回答时可以参考外部知识库。",
"DPR 是一种稠密检索方法,通常使用 query encoder 和 document encoder 把问题和文档编码成向量。",
"FAISS 是一个高效向量检索库,常用于在大量 embedding 中做相似度搜索。",
"RAG 不等于微调。RAG 主要通过外部知识检索增强回答,而微调是更新模型参数。"
]
# 2. 调用 embedding API,把文本转成向量
def get_embedding(text: str):
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return np.array(response.data[0].embedding)
# 3. 预先把文档都向量化
doc_embeddings = [get_embedding(doc) for doc in docs]
# 4. 计算余弦相似度
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 5. 检索最相关的 top_k 个文档
def retrieve(query: str, top_k: int = 3):
query_embedding = get_embedding(query)
scores = [
cosine_similarity(query_embedding, doc_embedding)
for doc_embedding in doc_embeddings
]
top_indices = np.argsort(scores)[::-1][:top_k]
results = []
for idx in top_indices:
results.append({
"text": docs[idx],
"score": scores[idx]
})
return results
# 6. 把检索结果塞进 LLM,让它基于上下文回答
def rag_answer(query: str):
retrieved_docs = retrieve(query, top_k=3)
context = "\n".join(
[f"- {item['text']}" for item in retrieved_docs]
)
prompt = f"""
你是一个严谨的问答助手。
请只根据下面提供的资料回答问题。
如果资料中没有答案,就说“资料中没有相关信息”。
资料:
{context}
问题:
{query}
"""
response = client.responses.create(
model="gpt-5.2",
input=prompt
)
return response.output_text, retrieved_docs
if __name__ == "__main__":
question = "RAG 和微调有什么区别?"
answer, sources = rag_answer(question)
print("问题:", question)
print("\n检索到的资料:")
for s in sources:
print(f"- 相似度 {s['score']:.4f}: {s['text']}")
print("\n模型回答:")
print(answer)2.2.简易LangChain + Chroma + OpenAI API
同样不训练模型,只是用了LangChain集成包
pip install -U langchain langchain-openai langchain-chromafrom langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
OPENAI_API_KEY = "sk-xxxxxxxxxxxxxxxxxxxxxxxx"
# 1. 准备一个很小的知识库
texts = [
"RAG 是 Retrieval-Augmented Generation 的缩写,中文常译为检索增强生成。",
"RAG 的基本流程是:先根据用户问题检索相关文档,再把检索结果作为上下文交给大语言模型生成回答。",
"RAG 可以缓解大语言模型幻觉问题,因为模型回答时可以参考外部知识库。",
"DPR 是一种稠密检索方法,通常使用 query encoder 和 document encoder 把问题和文档编码成向量。",
"FAISS 是一个高效向量检索库,常用于在大量 embedding 中做相似度搜索。",
"RAG 不等于微调。RAG 主要通过外部知识检索增强回答,而微调是更新模型参数。"
]
docs = [Document(page_content=t) for t in texts]
# 2. 切分文档
splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20
)
splits = splitter.split_documents(docs)
# 3. 创建 embedding 模型
embedding_model = OpenAIEmbeddings(
model="text-embedding-3-small",
api_key=OPENAI_API_KEY
)
# 4. 把文档存进 Chroma 向量库
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embedding_model
)
# 5. 创建检索器
retriever = vectorstore.as_retriever(
search_kwargs={"k": 3}
)
# 6. 创建 LLM
llm = ChatOpenAI(
model="gpt-5.2",
temperature=0,
api_key=OPENAI_API_KEY
)
###########################
# 其他模型也都支持 OpenAI 兼容接口,只需改 api_key、base_url、model
# llm = ChatOpenAI(
# api_key=OTHER_API_KEY,
# base_url="https://xxx",
# model="qwen-xxx",
# temperature=0
#)
###########################
# 7. Prompt 模板
prompt = ChatPromptTemplate.from_template("""
你是一个严谨的问答助手。
请只根据下面的资料回答问题。
如果资料中没有答案,就说“资料中没有相关信息”。
资料:
{context}
问题:
{question}
""")
# 8. RAG 问答函数
def rag_answer(question: str):
retrieved_docs = retriever.invoke(question)
context = "\n".join(
[doc.page_content for doc in retrieved_docs]
)
messages = prompt.invoke({
"context": context,
"question": question
})
response = llm.invoke(messages)
return response.content, retrieved_docs
if __name__ == "__main__":
question = "RAG 和微调有什么区别?"
answer, sources = rag_answer(question)
print("问题:", question)
print("\n检索到的资料:")
for i, doc in enumerate(sources, 1):
print(f"{i}. {doc.page_content}")
print("\n模型回答:")
print(answer)3.GraphRAG
RAG的核心是“语义检索”——看用户问的问题和哪块文档在意思上最像。但现实中的知识是互相连接的,比如“刘备的军师是谁?他的儿子又是谁?”这种问题,RAG就很难处理。
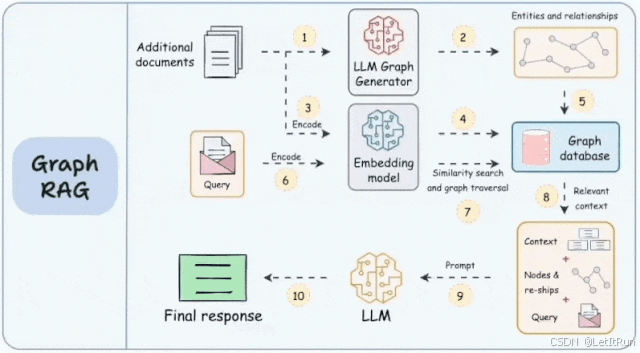
GraphRAG的改进点正在于此:
- 知识表示升级:它不依赖简单的文档切片,而是先从文档中抽取出 “实体” (如:刘备、诸葛亮、刘禅)和它们之间的 “关系” (如:刘备→军师→诸葛亮,刘备→父亲→刘禅),构建成一个知识图谱。
- 检索机制革新:当用户提问时,GraphRAG不再只做语义搜索,而是在这个知识图谱上进行 “图遍历” 。它就像在一个信息网络中“跳跃”,从一个实体出发,沿着关系边找到所有相连的实体。
- 能力增强:这种机制让它非常适合 “多跳推理” ,并且能清晰地展示推理路径,让答案有据可查,可解释性更强
3.1.如何进入图谱
- 向量匹配入口:用户问题进来,先转成向量。用这个向量去向量数据库里匹配“最相似的实体名”或“最相关的文档块”。找到的那个实体,就作为知识图谱遍历的起点。
- 优点:这种方式可以复用RAG的向量检索组件,技术门槛低。并且即使用户问法不精确(比如“那个写《红楼梦》的胖子”),向量检索也能模糊匹配到“曹雪芹”。
- 缺点:如果向量入口就找错了(比如问“刘备的儿子”却匹配到了“刘备的军师”),后面的图遍历再厉害也是白搭。并且入口这一步依然受限于语义相似度,没有体现出图的关联推理能力。
- 实体链接入口(更“图原生”的方式):直接从用户问题中抽取明确的实体名称(比如“刘备”、“诸葛亮”),然后通过精确匹配或模糊匹配(如Elasticsearch)在知识图谱中找到对应的实体节点,以此为起点。
- 优点:完全绕过了向量检索的“语义近似”阶段,直接进入精确的图关系遍历。
- 缺点:需要很好的命名实体识别模型,且对口语化、指代(“他”、“那个人”)处理困难。用户必须说出准确的实体名或常用别名。问“那个三顾茅庐的人”就可能失败。
- 典型代表:基于Neo4j的知识图谱问答系统
- 混合入口(工程上的最佳实践):同时进行实体链接和向量匹配,然后通过某种机制(如排序模型)融合两者的结果,选择最合适的起点。
4.AgenticRAG
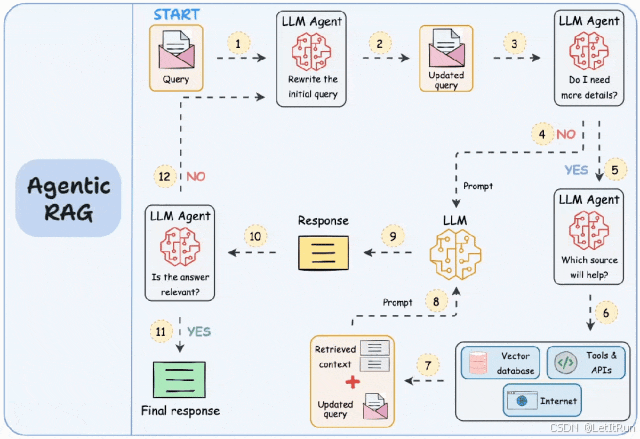
如果说GraphRAG强化了RAG的“知识结构”,那么Agentic RAG则是强化了RAG的“工作流程”。它不满足于“问一句,答一句”,而是引入了一个AI“智能体”,让它像个项目经理一样去规划任务。
传统RAG像个被动的工具,而Agentic RAG则升级为一个主动的“行动者”:
- 自主规划与反思:面对一个复杂问题,Agent不会只检索一次。它会先制定一个执行计划,比如“第一步,检索相关文档;第二步,计算具体数值;第三步,如果信息不足,修改关键词再搜一次”。它能在行动中反思并调整策略。
- 工具调用能力:这是Agentic RAG最核心的升级。它不仅会查文档,还能自主决定调用 计算器 做数学运算,调用 API 查实时天气或股票,甚至执行 SQL 查询数据。
5.多模态RAG
经典RAG处理非结构化文本,GraphRAG处理实体关系,而图片、表格属于多模态数据和半结构化数据,处理思路有所不同。
后续会专门读两篇论文《VideoRAG》和《RAG-Anything》
5.1.图片数据
图片本身是像素矩阵,无法直接检索语义。主流方案有两种:
- 多模态嵌入模型:使用像 CLIP、BLIP 这样的模型,将图片和文本映射到同一个向量空间。用户问“红色的狗”,模型既能检索到文本“red dog”,也能检索到狗的图片。
- 图片描述生成 + 文本RAG:先用 GPT-4V、LLaVA 等多模态大模型为每张图片生成详细的文本描述(“这是一只金毛寻回犬,在草地上追逐网球……”),然后只对描述文本做向量检索。
- 结合两者。
5.2.表格数据
表格是行列结构,直接转成纯文本丢给RAG会丢失结构信息。常见做法:
- 表格序列化 + 分块策略:按行(适用于行间独立的数据)/列(适用于需要纵向分析)/单元格(适用于稀疏问答)分块。
- 表格感知的检索:训练或使用专门的模型(如 TAPAS、Table-BERT),能够理解“第3行第2列”这类位置信息,以及表头与单元格的从属关系。(将表格编码成特殊注意力机制的位置嵌入 → 用户问“技术部有多少人” → 模型定位到“部门=技术部”的所有行 → 返回这些行或统计结果。)
- 转换描述 + 文本RAG:用模型将表格转成自然语言描述:“有一个员工表,包含姓名、年龄、部门三列。张三25岁在技术部,李四30岁在销售部……” → 然后对这段描述做普通RAG。
- 查询-元数据映射:离线分析表格的统计特征(列名、枚举值、数值范围等)→ 用户问“年龄大于25的人” → 路由到数值过滤模块,而不是走向量检索 → 直接对表格执行过滤操作。适合明确的条件查询。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 59
59 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)