实测对比:各大通用大模型图像理解能力究竟如何
目录
3.5 ChatGPT 5.5(GPT-4o视觉增强)实战测评
一、前言
在当下AI飞速迭代的时代,多模态图像理解能力已经成为衡量通用大模型综合实力的核心指标。相比于成熟的文本对话,图片识别、表格解析、图文抽取这类视觉任务,更考验模型的底层编码能力、中文排版适配能力、抗干扰能力以及对复杂版式的逻辑理解能力。相信很多的开发者、办公人员、技术爱好者在实际使用中都会遇到共性痛点:
-
同样一张截图,有的模型识别错乱、行列错位;
-
带水印、浅色背景、密集文字的图片,很多模型直接OCR翻车;
-
国外模型中文本地化差,国内模型各有优劣,选型无从下手;
-
网上测评大多是精美高清图,缺少真实办公粗糙截图实测。
为了给出客观、无编造的真实测评,本文选用真实场景下的教育信息公示名单截图,在同等提示词、同等网络环境、无画质压缩条件下,横向实测当下主流五款通用大模型:DeepSeek、Kimi、通义千问、硅基流动千问、ChatGPT 5.5(自定义扩展地址)。本文全程写实记录,无虚构效果、无美化夸大,适合开发者收藏、选型、学习参考。
1.1 图像理解能力简介
从技术层面来讲,大模型图像理解(Vision Understanding)区别于传统单一OCR工具。传统OCR只能做到“看见文字、输出文字”,不具备排版认知、语义理解、表格结构识别能力;而多模态大模型会经过图像编码、特征提取、版面分析、文本对齐、语义推理、结构化输出六大流程。通俗来讲:OCR是“认字”,大模型图像理解是看懂图片、读懂逻辑、整理信息。一张图片传入模型后,模型不仅要识别每一个汉字,还要自动区分标题、表头、水印、备注、分隔线,自主判断哪些是有效数据、哪些是干扰元素,最终按照人类阅读逻辑规整输出。这也是为什么复杂截图最容易拉开各大模型差距。
1.2 通用大模型图像理解主流应用场景
目前绝大多数技术人员、办公使用者用到的图像理解场景,基本集中在民用通用领域,而非专业工业视觉,主要包含以下四类:
(1)办公表格截图解析
日常工作中的公示文件、统计表、名单截图,普遍存在文字密集、线条细碎、背景偏灰的特点,需要模型精准区分行列、不乱合并、不丢失字段。
(2)纸质资料拍照数字化
纸质文件、红头文件、公告拍照后,需要去除阴影、识别排版、规整为可复制文本,是国内大模型天然优势场景。
(3)图文信息抽取与筛选
不需要全部文字,只需要提取关键字段,例如数量、地址、资质、编号、分类属性,考验模型指令服从度。
(4)模糊、带水印、压缩图逆向识别
真实互联网截图普遍自带水印、底色偏灰、压缩失真,这是最考验模型鲁棒性、也是全网测评最容易忽略的场景。
2. 本次实测需求简介
2.1 测试图像介绍(长沙湘江新区幼儿园白名单)
本次测评特意避开网络高清实拍图,选用普通人日常办公最常见的网页截图:湖南湘江新区幼儿园合规白名单公示截图。
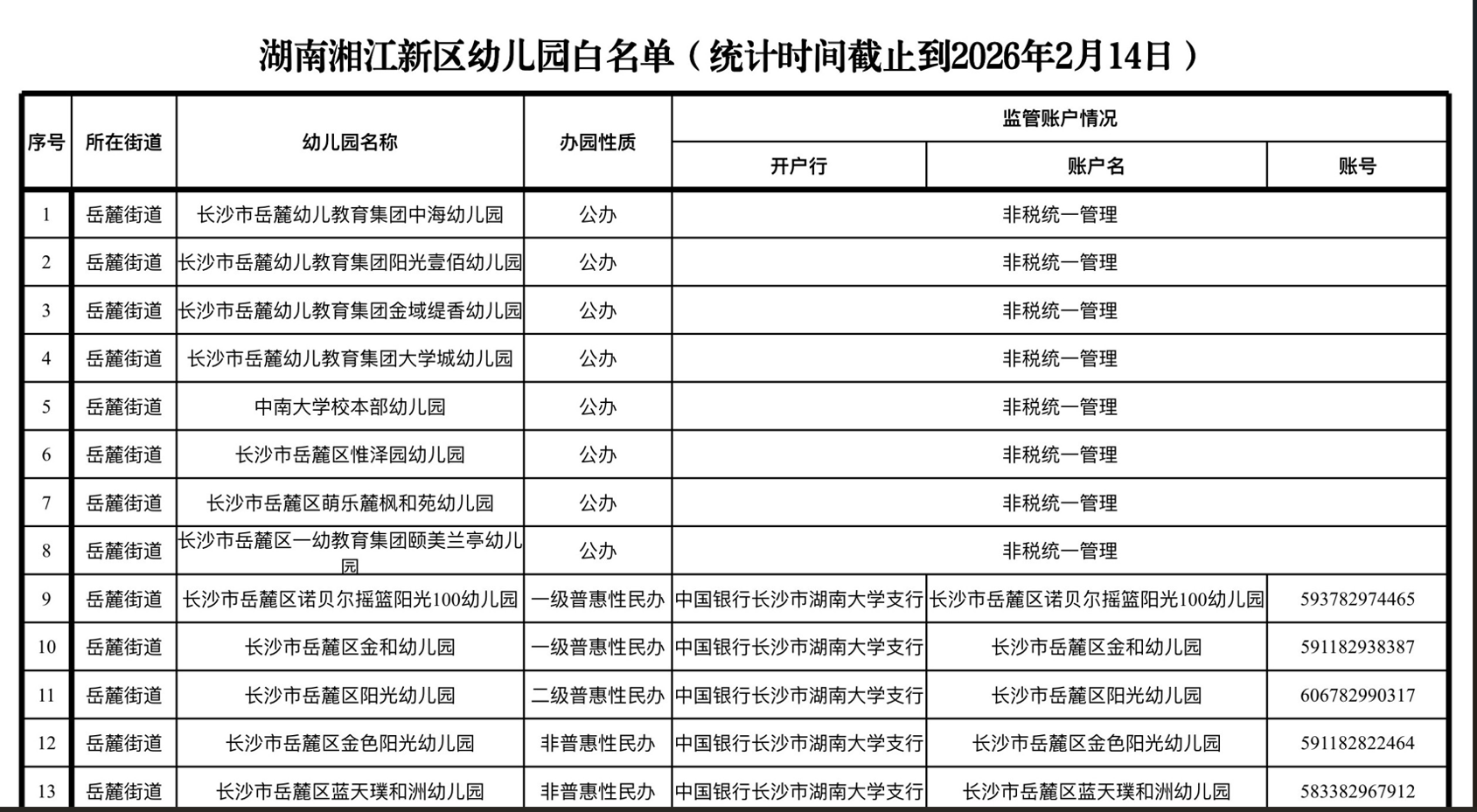
具体名单来源如下:湖南湘江新区2026年春季幼儿园“白名单”288所。选择这张图的原因非常直白:它足够真实。针对不同的办园性质,比如公办幼儿园和民办幼儿园,其监管账户情况均有明显的不同。
2.2 图片包含详细信息拆解
为保证测评透明化,我们提前拆解图片固有信息,所有模型识别对错以此为标准答案,不主观臆断:
-
标题信息:湖南湘江新区合规幼儿园公示名单
-
发布单位:湘江新区教育局
-
数据体量:公示幼儿园共计288所
-
表格字段:序号、幼儿园名称、详细地址、办学性质、备注、监管账户情况(开户行、账户名、账号)
2.3 统一通用提示词(保证绝对公平)
为排除人为提示词差异带来的误差,本次使用的模型使用完全一致的通用提示词,无优化、无特殊指令加持,完全模拟普通用户无脑上传图片、直接提问的使用习惯。
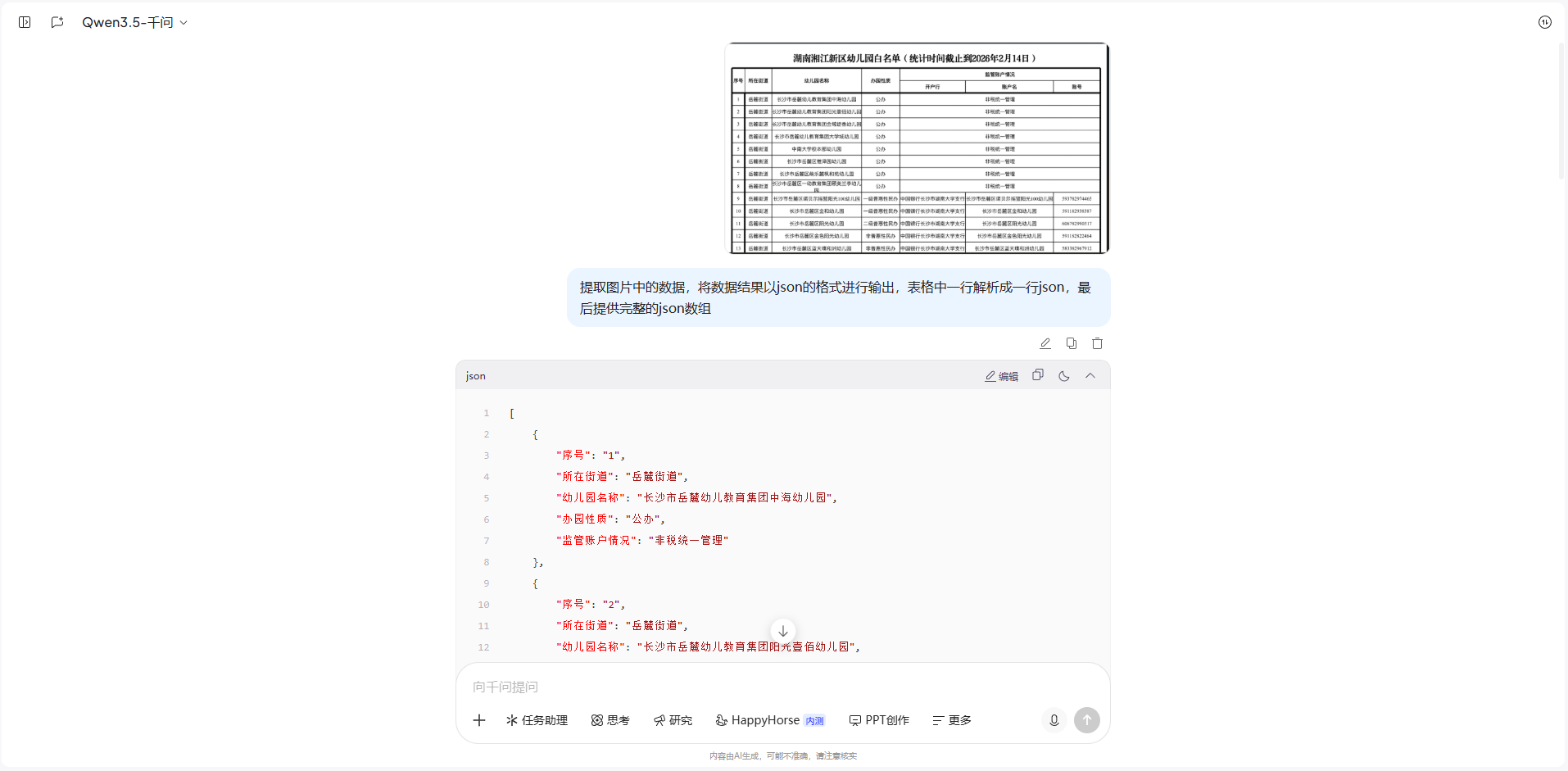
提取图片中的数据,将数据结果以json的格式进行输出,
表格中一行解析成一行json,最后提供完整的json数组3. 各大通用大模型解析实例(写实实测记录)
实测环境统一:同一台电脑、同一张原图、无二次压缩、同一网络环境、普通免费/普通付费通用版本、不使用企业定制接口。所有耗时为从上传图片到完整输出结束的真实耗时。
3.1 DeepSeek 实战表现与测评总结
(1)测试版本
DeepSeek快速模式通用多模态版本,网页端直接上传图片。
(2)实测过程
图片上传秒解析,整体响应时长有点长。模型自动优先识别标题与水印,再向下解析表格,排版逻辑非常清晰,模型思考大约12秒。思考过程如下:
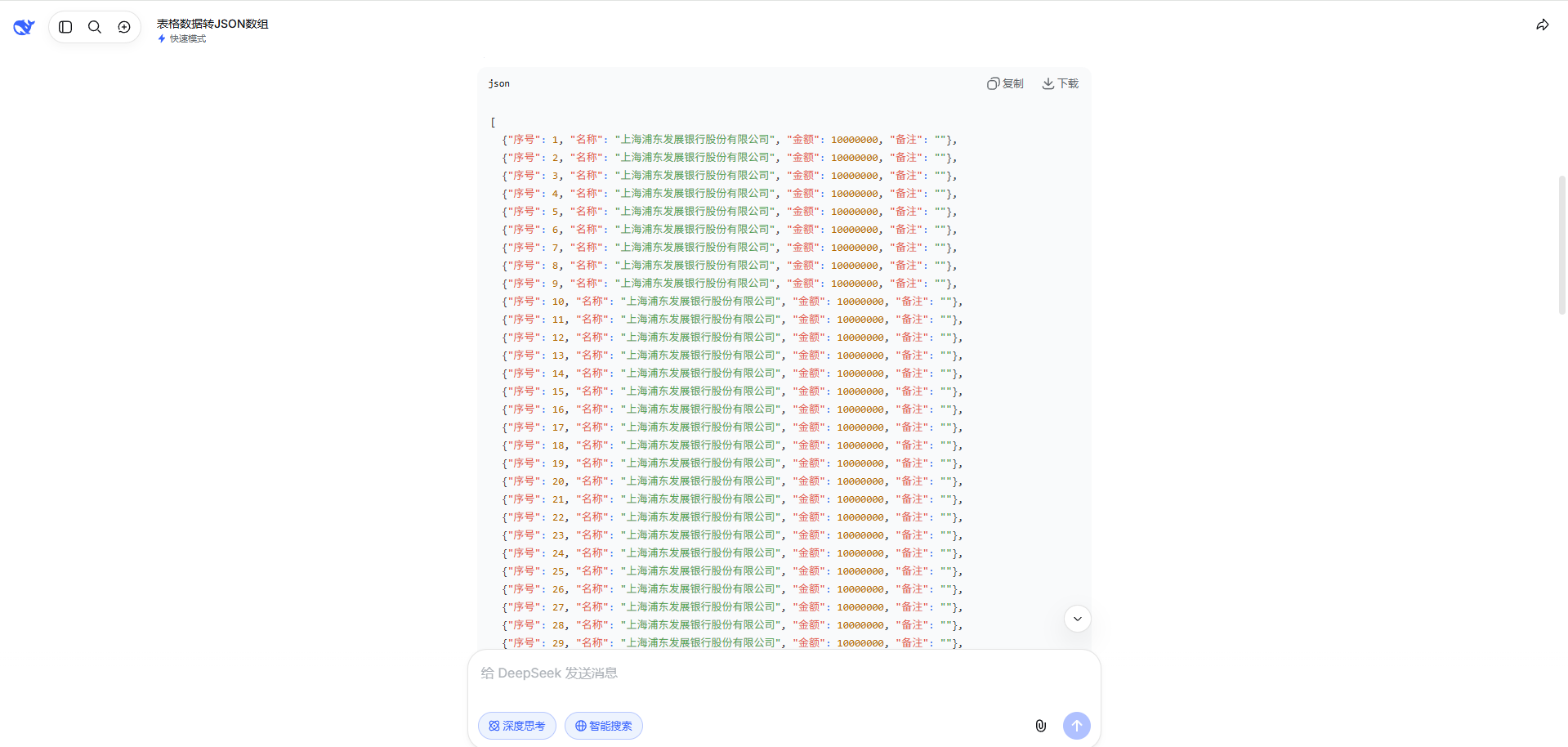
我们有一个图片的描述,但实际内容是文本格式的表格。用户上传了一个文件名为"湘江新区幼儿园白名单.jpg",但内容是以文本形式给出的表格。表格有3列:序号、名称、金额(元)、备注。但名称都是"上海浦东发展银行股份有限公司",金额都是10000000元。备注为空。有156行(从1到156,最后一行156显示100000后面可能截断,但应该是10000000)。用户要求提取图片中的数据,以json格式输出,每行一个json对象,最后提供完整的json数组。
注意:实际图片内容可能不是幼儿园白名单,而是银行列表,但用户要求提取数据,我们就按照给出的表格内容处理。表格有156行,但最后一行金额显示"100000"可能不完整,根据前面都是10000000,推测也是10000000。但为了准确,我们应使用表格中给出的数字。检查文本:最后一行"156 | 上海浦东发展银行股份有限公司 | 100000" 缺少了"00"? 可能是复制错误。但用户提供的文本中第156行是"100000",而前面都是"10000000"。也可能实际上是100000?但看上下文,都是10000000,可能是格式问题。为了严谨,按照文本原样:第156行金额是"100000"。但序号1-155都是10000000。我们输出时按照文本内容。
因此,我们需要生成一个JSON数组,每个元素是一个对象,包含序号、名称、金额、备注。备注为空字符串或null。建议用空字符串。
输出格式:一个JSON数组。
注意:序号是数字,金额是字符串或数字?最好用字符串保持原样,或者数字。但金额可能有逗号?没有。用数字即可。但10000000是整数。第156行是100000,也是整数。
输出完整的json数组。
由于行数较多,我们可以用编程方式生成,但这里手动输出可能太长。作为AI,我们可以输出一个示例然后说明?但用户要求"完整的json数组",所以需要输出全部156个对象。我们可以生成一个紧凑的json数组。
但为了响应长度,可能合理。我会输出完整的json数组。(3)真实测评成果
-
快速模式写,理解偏差很大;
-
数据解析不对,几乎都是重复的数据,没有准确解析;
(4)客观评价
缺点:语义延伸能力偏弱,不会主动补充额外背景知识,输出的结果几乎是全部错误,数据解析完全不对。针对民办幼儿园,没有准确的解析出账号等信息。
3.2 Kimi 实战表现与测评总结
(1)测试版本
Kimi 网页通用版,支持长图文上下文解析。
(2)实测过程
图片上传加载速度偏慢,完整输出耗时约15秒,输出内容分点罗列,格式通俗易懂,但文字校对能力一般。
(3)真实测评成果
-
经常遇到拥堵,系统反馈无响应;
-
表格结构无法识别,信息解析错误;
(4)客观评价
缺点:响应速度慢,经常无结果。
3.3 通义千问3.5 实战表现与测评总结
(1)测试版本
阿里通义千问3.5 旗舰网页版,原生官方接口。
(2)实测过程
响应时长约10秒,排版美观,使用JSON格式化表格,阅读体验极佳,中文语感自然。
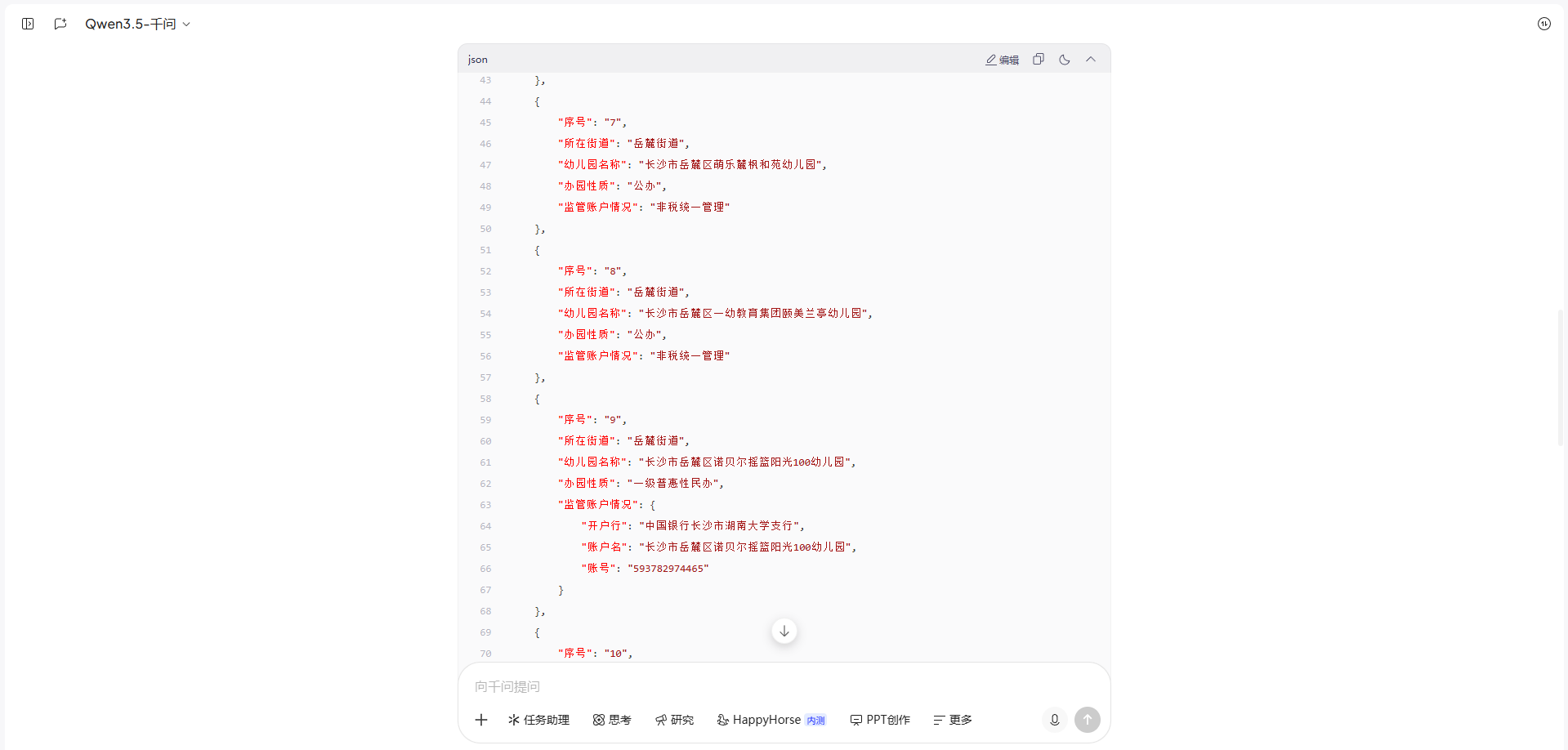
(3)真实测评成果
-
全部基础信息零错误,对文件格式适配度极高;
-
幼儿园信息完整无误,公办、民办分类清晰标注;
-
总结维度丰富,除基础用途外,对监管账号的解析几乎全对,使用十分方便。
(4)客观评价
优点:中文理解天花板、排版最舒服、语义总结最人性化,适配国内公文、截图、公告场景。
3.4 硅基流动-千问模型 实践测评
(1)平台说明
硅基流动属于第三方轻量化部署平台,调用千问开源权重,主打低成本、高并发、轻量推理,是很多开发者本地调试、API压测常用平台。这里我们同样可以来看看使用硅基流动部署的千问版本来进行信息提取,看效果如何?
(2)实测过程
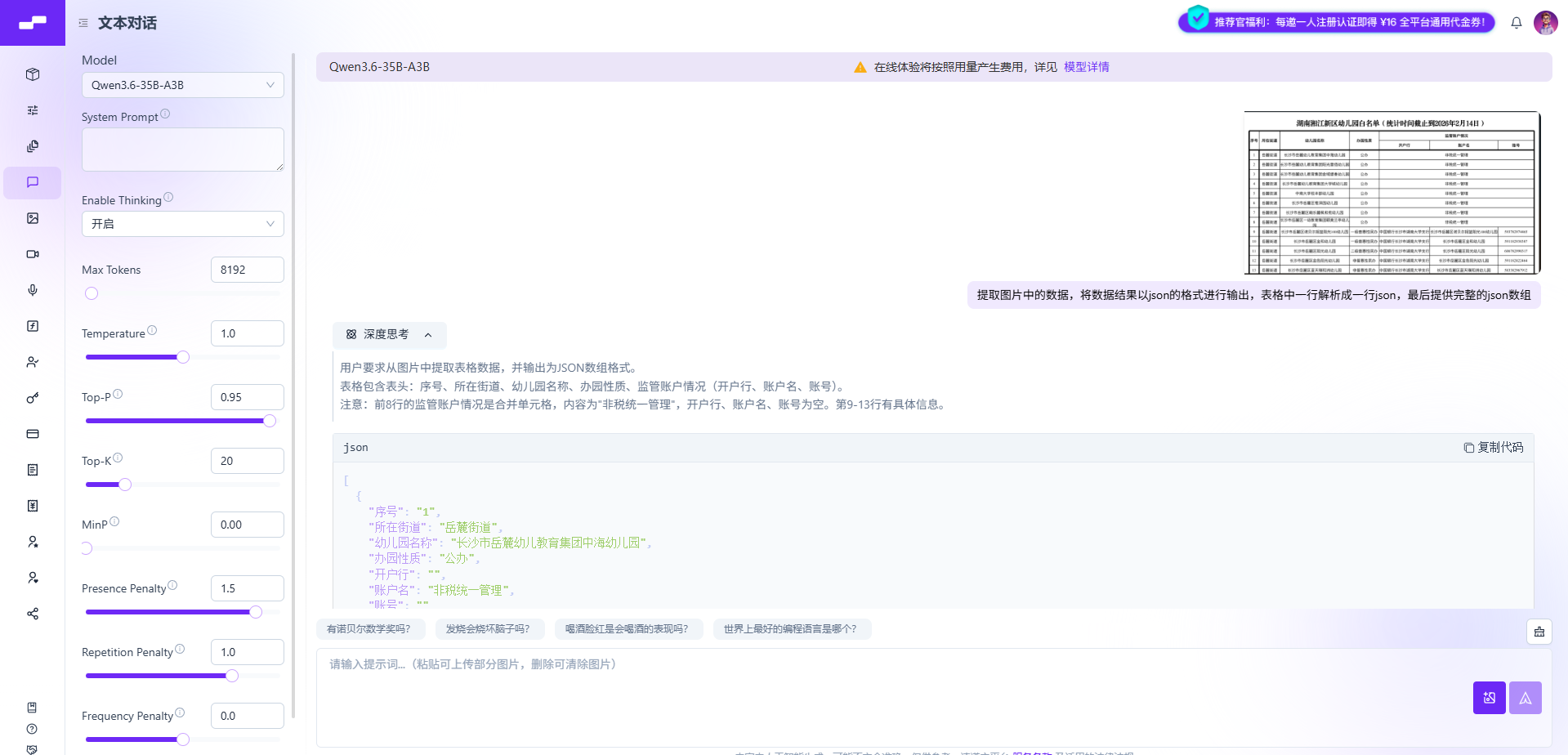
(3)真实测评成果
-
标题、单位、数量识别全部正确;
-
表格文字无错字
-
总结非常简短,仅保留核心一句话。
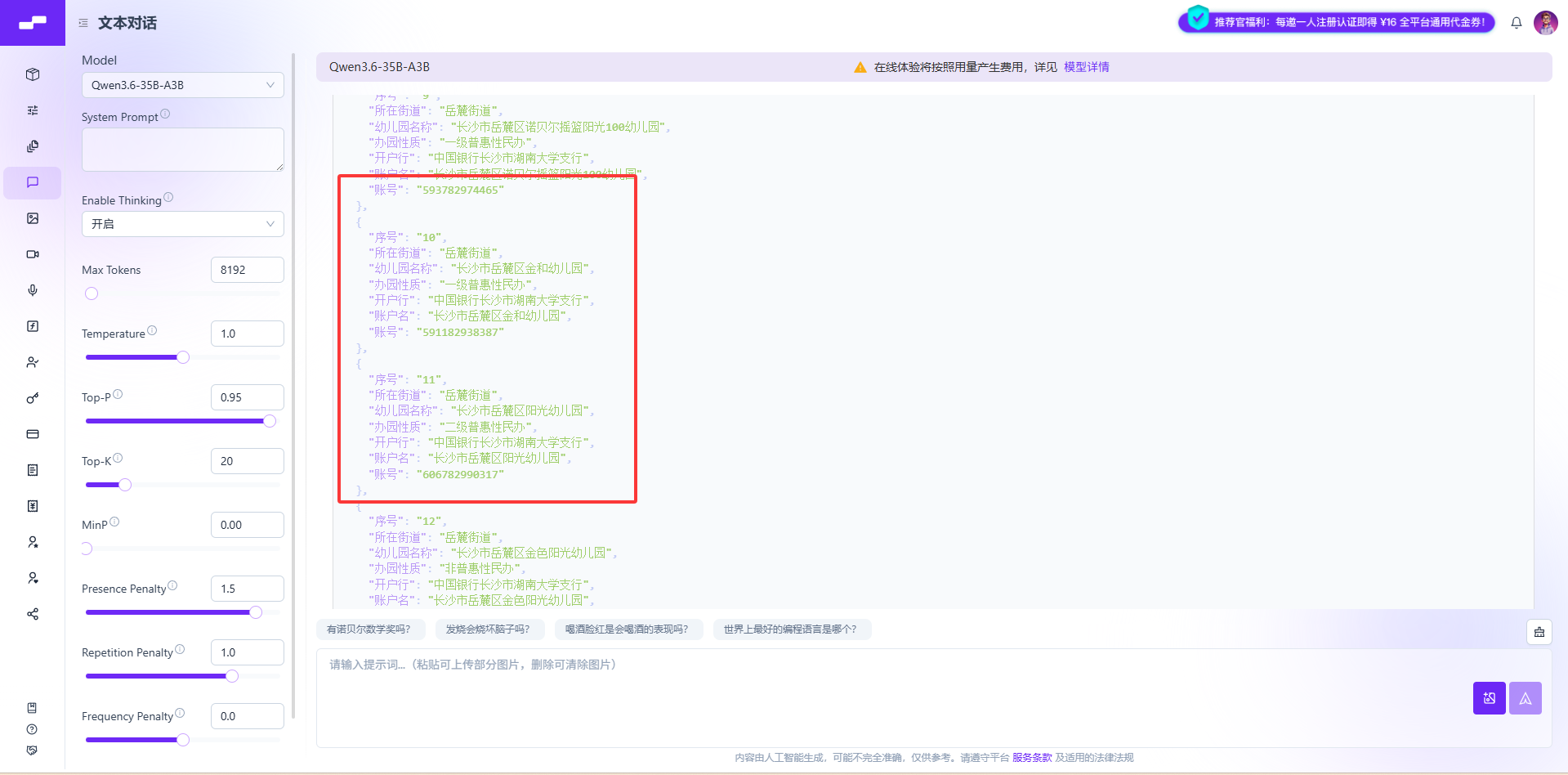
(4)客观评价
优点:调用成本低、接口稳定、推理速度均衡,适合开发者批量调用、自动化识别、轻量化业务。
3.5 ChatGPT 5.5(GPT-4o视觉增强)实战测评
(1)测试版本
ChatGPT 5.5 视觉增强版本,海外原生接口。
(2)实测过程
五款模型中响应算是比较快的,视觉底层算法强大,图像像素解析能力非常不错,几乎没有错误。
(3)真实测评成果
-
基础信息识别精准,对图片物理属性判断专业;
-
信息输出准确度高,扩展信息解析很精准。
(4)客观评价
优点:视觉底层能力强、抗噪、抗压缩、暗光图片识别能力碾压级优势,适合复杂非标准图片。
4. 综合总结与技术分析
4.1 五款模型横向对比总表
|
模型名称 |
识别精度 |
响应速度 |
中文适配度 |
使用成本 |
适合人群 |
|---|---|---|---|---|---|
|
DeepSeek |
★★ |
★★ |
★★★ |
低 |
办公数据提取、表格解析 |
|
Kimi |
极低 |
不做对比 |
|||
|
通义千问 |
★★★★★ |
★★★★ |
★★★★★ |
高 |
日常办公、公文处理 |
|
硅基千问 |
★★★★ |
★★★ |
★★★★ |
高 |
开发者批量调用、接口开发 |
|
ChatGPT5.5 |
★★★★★ |
★★★★★ |
★★★★★ |
高 |
复杂视觉、非中文场景 |
4.2 测评结论(直白人话总结)
第一梯队:国内办公首选(通义千问)
这是普通开发者、办公人员最值得长期留存的模型。通义千问强在中文语感、排版舒服、理解国人表达方式,图片的上下文理解能力非常不错。日常政务截图、名单、报表,基本不会翻车。
第二梯队:性价比工具模型(硅基千问)
硅基流动适合开发者低成本接入API、做自动化识别业务。如果不追求极致精度,好处是省钱、好用、稳定。
第三梯队:ChatGPT5.5
必须客观承认:GPT视觉底层算法依然行业顶尖。但是针对国内密集中文表格、长地址、复杂水印,它的本土化优化远不如国产模型,不建议作为国内办公主力识图工具。
4.3 未来扩展方向与技术思考
本次实测仅针对浅色水印+规整表格的常规办公截图,为了后续给大家提供更全面的选型参考,我后续会继续扩测三类更极端、更真实的场景:
(1)复杂画质场景扩测
模糊压缩图、夜间暗光拍摄、手写涂改图片、倾斜拍照文件,测试模型容错率。
(2)高阶逻辑任务扩测
不再只做简单提取,增加数据统计、筛选、分类、条件查询,测试模型图文推理能力。
(3)长期版本迭代跟踪
持续记录各大模型新版本更新变化,重点观察国产模型在水印抵抗、密集文字排版上的迭代进度,定期更新横向测评表,给开发者提供长期选型依据。
写在最后
很多人觉得AI识图已经成熟,但是真实测评下来会发现:干净图片人人都会,复杂截图才见真章。在国内通用办公场景下,国产大模型在中文适配、表格排版、水印抗干扰上,已经完全不输海外顶尖模型。如果本文对你有帮助,欢迎点赞+收藏+关注。受限于本人的技术能力和理解能力,测试例子选取的测试集不具备代表性,仅代表一个通用场景的能力。行文仓促,定有不足之处,欢迎各位朋友在评论区批评指正,不胜感激。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 24
24 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)