从零实现springboot整合xxl-job: 实现库存对账功能
目录
2.在 application.yaml 中配置 XXL-JOB 相关参数:
(1)传统 MyBatis-Plus 的 Page存在性能瓶颈和死循环问题
引言:刚接触xxl-job,以下是我在参考多篇文章后进行部署后的一些理解,如有不当之处,欢迎指正。
一、库存对账的必要性
电商系统采用“拍下预扣减库存”模式时,用户下单会立即扣减Redis中的可用库存,同时增加锁定库存。这种设计依赖订单超时自动取消机制来释放锁定库存,避免超卖问题。
二、异步架构的挑战
系统通过Redis预扣减库存后,会发送MQ消息异步同步到数据库。这种架构虽然提升了并发处理能力,但也带来了数据一致性问题。MQ消息丢失、消费失败或网络抖动都可能导致Redis与数据库库存数据不一致。
三、解决方案设计
引入XXL-JOB分布式定时任务进行定时对账,对比Redis和数据库两个数据源的库存数据。发现差异后按照预设的分级策略自动修复,同时记录详细的审计日志以便追踪问题根源。这种兜底方案确保了系统在异常情况下仍能维持数据一致性。
https://docker.aityp.com/docker/run?name=docker.io%2fxuxueli%2fxxl-job-admin%3a2.4.0&platform=linux%2famd64
四、数据库准备事项
部署前需确保MySQL中已创建xxl_job数据库,并执行官方提供的SQL脚本初始化表结构。
创建xxl-job的数据库复制下面sql即可:
CREATE TABLE IF NOT EXISTS xxl_job_group (
id INT AUTO_INCREMENT PRIMARY KEY,
app_name VARCHAR(64) NOT NULL COMMENT '执行器AppName',
title VARCHAR(12) NOT NULL COMMENT '执行器名称',
address_type TINYINT DEFAULT 0 NOT NULL COMMENT '执行器地址类型:0=自动注册、1=手动录入',
address_list TEXT NULL COMMENT '执行器地址列表,多地址逗号分隔',
update_time DATETIME NULL
) CHARSET=utf8mb4;
CREATE TABLE IF NOT EXISTS xxl_job_info (
id INT AUTO_INCREMENT PRIMARY KEY,
job_group INT NOT NULL COMMENT '执行器主键ID',
job_desc VARCHAR(255) NOT NULL,
add_time DATETIME NULL,
update_time DATETIME NULL,
author VARCHAR(64) NULL COMMENT '作者',
alarm_email VARCHAR(255) NULL COMMENT '报警邮件',
schedule_type VARCHAR(50) DEFAULT 'NONE' NOT NULL COMMENT '调度类型',
schedule_conf VARCHAR(128) NULL COMMENT '调度配置,值含义取决于调度类型',
misfire_strategy VARCHAR(50) DEFAULT 'DO_NOTHING' NOT NULL COMMENT '调度过期策略',
executor_route_strategy VARCHAR(50) NULL COMMENT '执行器路由策略',
executor_handler VARCHAR(255) NULL COMMENT '执行器任务handler',
executor_param VARCHAR(512) NULL COMMENT '执行器任务参数',
executor_block_strategy VARCHAR(50) NULL COMMENT '阻塞处理策略',
executor_timeout INT DEFAULT 0 NOT NULL COMMENT '任务执行超时时间,单位秒',
executor_fail_retry_count INT DEFAULT 0 NOT NULL COMMENT '失败重试次数',
glue_type VARCHAR(50) NOT NULL COMMENT 'GLUE类型',
glue_source MEDIUMTEXT NULL COMMENT 'GLUE源代码',
glue_remark VARCHAR(128) NULL COMMENT 'GLUE备注',
glue_updatetime DATETIME NULL COMMENT 'GLUE更新时间',
child_jobid VARCHAR(255) NULL COMMENT '子任务ID,多个逗号分隔',
trigger_status TINYINT DEFAULT 0 NOT NULL COMMENT '调度状态:0-停止,1-运行',
trigger_last_time BIGINT DEFAULT 0 NOT NULL COMMENT '上次调度时间',
trigger_next_time BIGINT DEFAULT 0 NOT NULL COMMENT '下次调度时间'
) CHARSET=utf8mb4;
CREATE TABLE IF NOT EXISTS xxl_job_lock (
lock_name VARCHAR(50) NOT NULL COMMENT '锁名称' PRIMARY KEY
) CHARSET=utf8mb4;
CREATE TABLE IF NOT EXISTS xxl_job_log (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
job_group INT NOT NULL COMMENT '执行器主键ID',
job_id INT NOT NULL COMMENT '任务,主键ID',
executor_address VARCHAR(255) NULL COMMENT '执行器地址,本次执行的地址',
executor_handler VARCHAR(255) NULL COMMENT '执行器任务handler',
executor_param VARCHAR(512) NULL COMMENT '执行器任务参数',
executor_sharding_param VARCHAR(20) NULL COMMENT '执行器任务分片参数,格式如 1/2',
executor_fail_retry_count INT DEFAULT 0 NOT NULL COMMENT '失败重试次数',
trigger_time DATETIME NULL COMMENT '调度-时间',
trigger_code INT NOT NULL COMMENT '调度-结果',
trigger_msg TEXT NULL COMMENT '调度-日志',
handle_time DATETIME NULL COMMENT '执行-时间',
handle_code INT NOT NULL COMMENT '执行-状态',
handle_msg TEXT NULL COMMENT '执行-日志',
alarm_status TINYINT DEFAULT 0 NOT NULL COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败'
) CHARSET=utf8mb4;
CREATE INDEX I_handle_code ON xxl_job_log (handle_code);
CREATE INDEX I_trigger_time ON xxl_job_log (trigger_time);
CREATE TABLE IF NOT EXISTS xxl_job_log_report (
id INT AUTO_INCREMENT PRIMARY KEY,
trigger_day DATETIME NULL COMMENT '调度-时间',
running_count INT DEFAULT 0 NOT NULL COMMENT '运行中-日志数量',
suc_count INT DEFAULT 0 NOT NULL COMMENT '执行成功-日志数量',
fail_count INT DEFAULT 0 NOT NULL COMMENT '执行失败-日志数量',
update_time DATETIME NULL,
CONSTRAINT i_trigger_day UNIQUE (trigger_day)
) CHARSET=utf8mb4;
CREATE TABLE IF NOT EXISTS xxl_job_logglue (
id INT AUTO_INCREMENT PRIMARY KEY,
job_id INT NOT NULL COMMENT '任务,主键ID',
glue_type VARCHAR(50) NULL COMMENT 'GLUE类型',
glue_source MEDIUMTEXT NULL COMMENT 'GLUE源代码',
glue_remark VARCHAR(128) NOT NULL COMMENT 'GLUE备注',
add_time DATETIME NULL,
update_time DATETIME NULL
) CHARSET=utf8mb4;
CREATE TABLE IF NOT EXISTS xxl_job_registry (
id INT AUTO_INCREMENT PRIMARY KEY,
registry_group VARCHAR(50) NOT NULL,
registry_key VARCHAR(255) NOT NULL,
registry_value VARCHAR(255) NOT NULL,
update_time DATETIME NULL
) CHARSET=utf8mb4;
CREATE INDEX i_g_k_v ON xxl_job_registry (registry_group, registry_key, registry_value);
CREATE TABLE IF NOT EXISTS xxl_job_user (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL COMMENT '账号',
password VARCHAR(50) NOT NULL COMMENT '密码',
role TINYINT NOT NULL COMMENT '角色:0-普通用户、1-管理员',
permission VARCHAR(255) NULL COMMENT '权限:执行器ID列表,多个逗号分割',
CONSTRAINT i_username UNIQUE (username)
) CHARSET=utf8mb4;
五、从零部署XXL-JOB的Docker命令解析
以下是通过Docker部署XXL-JOB的核心命令及参数说明:
docker run \
--name xxl-job-admin \
-e PARAMS="--xxl.job.accessToken=default_token" \
-e SPRING_DATASOURCE_URL="jdbc:mysql://192.168.100.101:3306/xxl_job?allowPublicKeyRetrieval=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai" \
-e SPRING_DATASOURCE_USERNAME=root \
-e SPRING_DATASOURCE_PASSWORD=123 \
-dp 8080:8080 \
--network hm-net \
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/xuxueli/xxl-job-admin:2.4.0
关键参数配置说明
-e PARAMS="--xxl.job.accessToken=default_token"
设置XXL-JOB的访问令牌,需与执行器配置保持一致。
-e SPRING_DATASOURCE_URL="jdbc:mysql://[IP]:3306/xxl_job?...
配置MySQL数据库连接地址,需替换为实际服务器IP,注意时区设置为Asia/Shanghai。
-e SPRING_DATASOURCE_USERNAME=root
数据库用户名,默认为root,可按需修改。
-e SPRING_DATASOURCE_PASSWORD=[密码]
数据库密码,需替换为实际密码。
1.网络与端口配置
--network hm-net
指定容器运行的Docker网络,若无现有网络需提前创建。
-dp 8080:8080
将容器内8080端口映射到宿主机8080端口,-d表示后台运行。
2.镜像源说明
推荐使用华为云镜像源加速下载:swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/xuxueli/xxl-job-admin:2.4.0
或通过以下地址docker命令在线生成网址:https://docker.aityp.com/docker/run?name=docker.io%2fxuxueli%2fxxl-job-admin%3a2.4.0&platform=linux%2famd64
3.请访问以下地址登录XXL-JOB管理后台:
- 访问地址:http://[你的Linux服务器IP]:8080/xxl-job-admin/jobinfo
- 登录账号:admin
- 默认密码:123456

-
六、Spring Boot 集成 XXL-JOB 配置指南
-
1.引入xxl-job依赖(同docker版本一致)
<!-- XXL-JOB 执行器核心依赖 --> <dependency> <groupId>com.xuxueli</groupId> <artifactId>xxl-job-core</artifactId> <version>2.4.0</version> </dependency>2.在 application.yaml 中配置 XXL-JOB 相关参数:
# XXL-JOB 配置项 xxl: job: # 调度中心部署地址(请替换为实际服务器IP) admin: addresses: http://192.168.100.101:8080/xxl-job-admin # 执行器配置 executor: # 执行器名称(需与后台配置的AppName保持一致) appname: xxl-job-executor-sample # 执行器服务端口(用于接收调度请求,默认9999) port: 9999 # 任务日志存储路径 logpath: /data/applogs/xxl-job/jobhandler # 日志保留天数 logretentiondays: 30 # 调度中心认证令牌(默认值为空,若未修改Docker配置则保持默认) accessToken: default_token -
3.XXL-JOB 配置类实现
-
package com.sky.item.config; import com.xxl.job.core.executor.impl.XxlJobSpringExecutor; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class XxlJobConfig { private static final Logger logger = LoggerFactory.getLogger(XxlJobConfig.class); @Value("${xxl.job.admin.addresses}") private String adminAddresses; @Value("${xxl.job.accessToken}") private String accessToken; @Value("${xxl.job.executor.appname}") private String appName; @Value("${xxl.job.executor.port}") private int port; @Value("${xxl.job.executor.logpath}") private String logPath; @Value("${xxl.job.executor.logretentiondays}") private int logRetentionDays; @Bean public XxlJobSpringExecutor xxlJobExecutor() { logger.info("Initializing XXL-JOB configuration..."); XxlJobSpringExecutor executor = new XxlJobSpringExecutor(); executor.setAdminAddresses(adminAddresses); executor.setAppname(appName); executor.setPort(port); executor.setAccessToken(accessToken); executor.setLogPath(logPath); executor.setLogRetentionDays(logRetentionDays); return executor; } }4.定时任务类实现
- 至此,基础部署已完成。接下来只需编写自定义定时业务逻辑,相关定时配置可在后台管理界面中完成设置。
package com.sky.item.job.handler;
import com.sky.item.service.IProductStockService;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class MyJobHandler {
private static final Logger logger = LoggerFactory.getLogger(MyJobHandler.class);
@Autowired
private IProductStockService productStockService;
/**
* 简单任务示例(Bean模式)
* 任务处理器名称需与后台配置保持一致
*/
@XxlJob("demoJobHandler")
public void demoJobHandler() {
String param = XxlJobHelper.getJobParam();
logger.info("XXL-JOB执行成功,参数:{}", param);
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
long jobId = XxlJobHelper.getJobId();
logger.info("执行库存对账定时任务");
productStockService.checkStock(shardIndex, shardTotal, String.valueOf(jobId));
}
}
注意事项:
@XxlJob注解参数需与后台"任务管理"中的"运行模式"名称一致- 业务逻辑应封装在service层实现
-
XxlJobHelper.getShardIndex()
功能:获取当前执行器的分片序号(从 0 开始计数)仅在任务的路由策略为「分片广播」时有效(否则返回默认值 0)。
用于标识当前执行器在任务分片中的位置,通常与
shardTotal配合使用,实现数据集的分布式并行处理。 -
XxlJobHelper.getShardTotal()
功能:获取总分片数(即任务分配到的执行器实例总数)同样仅在「分片广播」模式下有效,其值等于当前在线的可用执行器数量。
与
shardIndex结合使用,确保每个执行器只处理分配给自己的数据片段。 -
XxlJobHelper.getJobId()
功能:获取本次任务调度的唯一执行 ID每次调度中心触发任务时,都会在
xxl_job_log表中生成一条记录,jobId即为该记录的主键。适用于所有路由策略,主要用于日志追踪和批次标记(例如将其拼接到
batch_id中可追溯差异记录对应的调度批次)。
在库存对账中的典型用法
int shardIndex = XxlJobHelper.getShardIndex(); // 例如 0 int shardTotal = XxlJobHelper.getShardTotal(); // 例如 3 long jobId = XxlJobHelper.getJobId(); // 例如 10427 String batchId = jobId + "-" + shardIndex + "-" + shardTotal; // "10427-0-3" // 用 batch_id 标记本次对账批次,便于后续审计和排查
5.库存对账遇到的问题
(1)传统 MyBatis-Plus 的 Page存在性能瓶颈和死循环问题
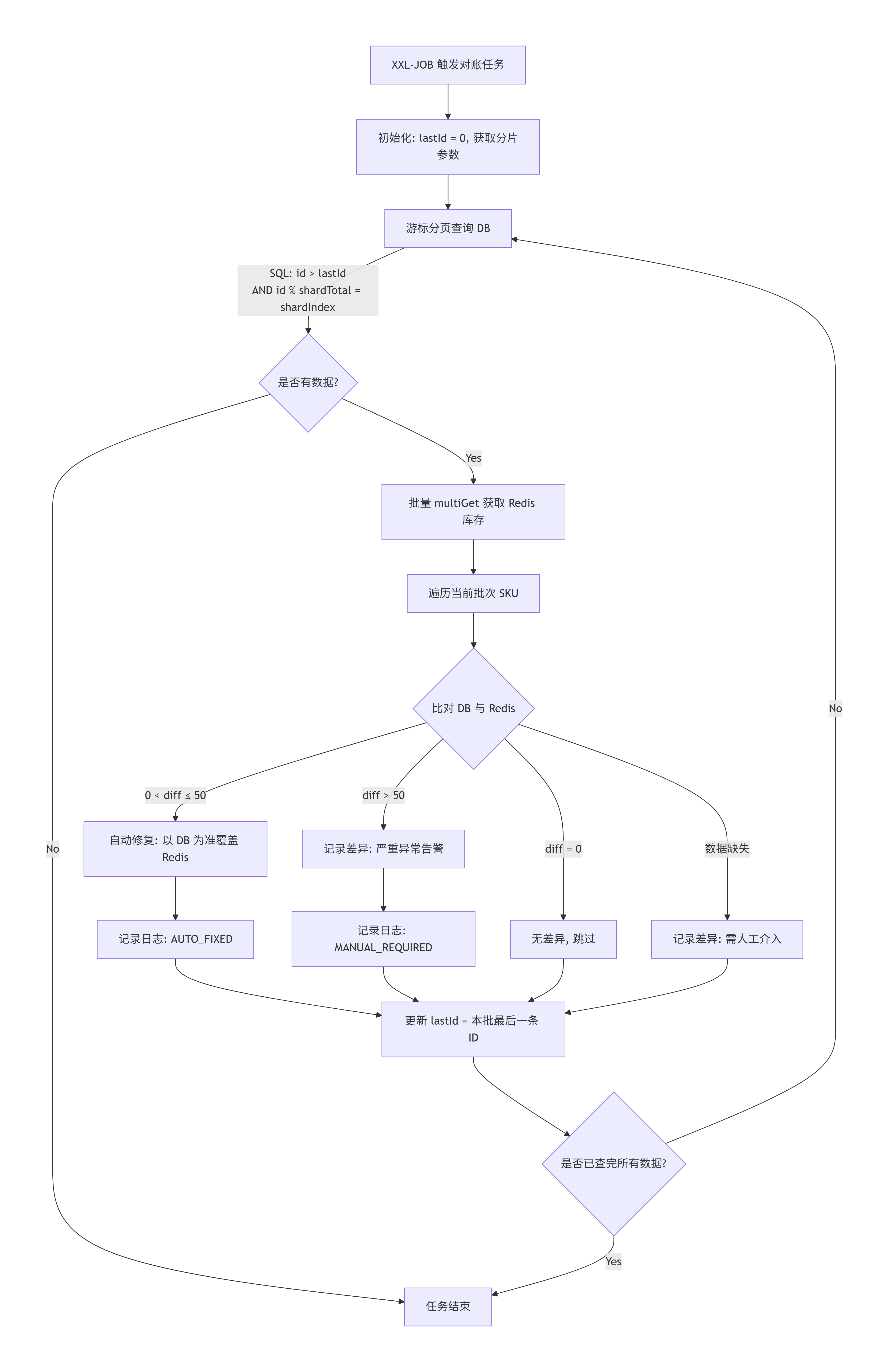
在实现分片查询时,传统 MyBatis-Plus 的 Page(offset, size) 方法存在性能瓶颈和死循环问题。为此,我采用了游标分页方案:
问题分析:
- 取模查询无法利用索引
- 数据变动会导致 OFFSET 偏移量不准确
解决方案: 通过记录上一批查询的最后一条记录 ID,后续查询直接使用 WHERE id > lastId 条件。这种方法充分利用主键索引优势,确保查询性能稳定不受页码影响。
@Override
public void checkStock(int shardIndex, int shardTotal, String taskId) {
final int BATCH_SIZE = 1000;
Long lastId = 0L;
while (true) {
// 实现 ID 推进 + 取模分片
LambdaQueryWrapper<ProductStock> wrapper = new LambdaQueryWrapper<>();
wrapper.gt(ProductStock::getId, lastId)
.and(w -> w.apply("id % {0} = {1}", shardTotal, shardIndex))
.orderByAsc(ProductStock::getId)
.last("LIMIT " + BATCH_SIZE);
List<ProductStock> records = list(wrapper);
if (CollUtil.isEmpty(records)) break;
batchCheckStock(records, shardTotal, shardIndex, taskId);
// 更新游标位置
lastId = records.get(records.size() - 1).getId();
if (records.size() < BATCH_SIZE) break;
}
}
(2)Redis 批量比对优化
// 批量获取 Key 并一次性从 Redis 查询
List<String> redisAvailList = stringRedisTemplate.opsForValue().multiGet(availKeys);
// multiGet 返回结果与输入 keys 的顺序严格一致,可通过索引直接匹配
String redisAvail = redisAvailList.get(i);
(3)对账流程图如下:
(4)库存差异记录表
这张表是为库存对账的审计日志表,建表sql如下(非必须):
-- 库存差异审计日志表(专为库存对账设计)
CREATE TABLE IF NOT EXISTS stock_diff_record (
id BIGINT AUTO_INCREMENT COMMENT '主键' PRIMARY KEY,
sku_id BIGINT NOT NULL COMMENT '商品规格SKU ID',
batch_id VARCHAR(64) NOT NULL COMMENT '对账批次号(任务执行ID + 分片索引)',
diff_dimension VARCHAR(16) NOT NULL COMMENT '差异维度',
diff_type VARCHAR(32) DEFAULT 'REDIS_DB_DIFF' NOT NULL COMMENT '差异类型',
redis_available INT NULL COMMENT 'Redis可用库存',
redis_locked INT NULL COMMENT 'Redis锁定库存',
db_available INT NULL COMMENT '数据库可用库存',
db_locked INT NULL COMMENT '数据库锁定库存',
expected_available INT NULL COMMENT '期望可用库存',
expected_locked INT NULL COMMENT '期望锁定库存',
diff_amount INT NOT NULL COMMENT '差异绝对值(当前维度差异值)',
diff_status VARCHAR(32) DEFAULT 'PENDING' NOT NULL COMMENT '状态:PENDING/AUTO_FIXED/MANUAL_REQUIRED/IGNORED',
fixed_by VARCHAR(64) NULL COMMENT '修复人/系统',
fixed_at DATETIME NULL COMMENT '修复时间',
fix_comment VARCHAR(512) NULL COMMENT '修复备注',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP NOT NULL COMMENT '记录创建时间',
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间'
) COMMENT '库存差异记录表' CHARSET=utf8mb4;
-- 索引定义
CREATE INDEX idx_batch_id ON stock_diff_record(batch_id);
CREATE INDEX idx_created_at ON stock_diff_record(created_at);
CREATE INDEX idx_diff_status ON stock_diff_record(diff_status);
CREATE INDEX idx_product_id ON stock_diff_record(sku_id);
七、互动问题
话题 1:权威数据源的选择权衡 "在我的对账逻辑中,采用'以Redis为准'的策略反向修复DB。考虑到预扣减模式下,Redis才是实时库存的唯一真实数据源。想请教大家:在高并发写入场景下,选择Redis作为权威数据源更可靠,还是采用DB最终一致性更安全?是否有遇到过因Redis数据异常导致DB数据连带出错的实际案例?"
话题 2:对账期间的并发控制 "当前syncStock操作直接更新DB。如果在对账任务执行过程中,MQ恰好也在异步同步同一批商品的库存,是否会产生并发更新冲突?针对这种情况,大家更推荐采用分布式锁方案,还是使用数据库版本号(乐观锁)机制来解决?"

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)