Agent Skills详解
import os
from typing import Literal
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from deepagents.middleware import SkillsMiddleware
from langchain_core.tools import tool
from tavily import TavilyClient
from agent.my_llm import llm
tavily_client = TavilyClient(api_key='')
@tool
def internet_search(query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,):
"""使用 Tavily API 进行网络搜索,获取最新的新闻和信息。
支持通用搜索、新闻搜索和金融搜索三种模式,可以获取实时网络信息。
Args:
query: 搜索查询词,描述要搜索的内容
max_results: 返回的最大结果数量,默认 5
topic: 搜索主题类型,可选 "general"(通用)、"news"(新闻)、"finance"(金融)
include_raw_content: 是否包含原始页面内容,默认 False
Returns:
包含搜索结果的字典,包括标题、URL、内容片段等信息
"""
print(f'调用网络查询工具,查询内容:{query}')
return tavily_client.search(query=query, max_results=max_results, topic=topic, include_raw_content=include_raw_content)
backend = FilesystemBackend(root_dir=os.getcwd(),virtual_mode=True)
skills_middleware = SkillsMiddleware(
backend=backend,
sources=["skills"],
)
agent = create_deep_agent(
model=llm,
tools = [internet_search],
system_prompt="你是一名研究助理。你可以使用 'web_search' 技能来寻找最新信息。",
middleware=[skills_middleware]
)
result = agent.invoke({"messages": [{"role": "user", "content": "2026特朗普访华新闻"}]})
print(result['messages'][-1].content)2025 年 10 月中旬,Anthropic 正式发布 Claude Skills。 两个月后,Agent Skills 作为开放标准被进一步发布,意在引导一个新的 AI Agent 开发生态。Agent 可通过加载不同的 Skills 包,来具备不同的专业知识、工具使用能力,稳定完成特定任务。 Skills 是模块化的能力,扩展了 Agent 的功能。每个Skill 都打包了 LLM 指令、元数据、可选资源(脚本、模板等),Agent 会在需要时自动使用他们。
什么是 Agent Skill?
Agent Skill 是一个自包含、按需加载的知识/行为模块,通常表现为一个标准文件夹,内含核心的 SKILL.md 指令文件以及可选的脚本、参考文档等资源。
-
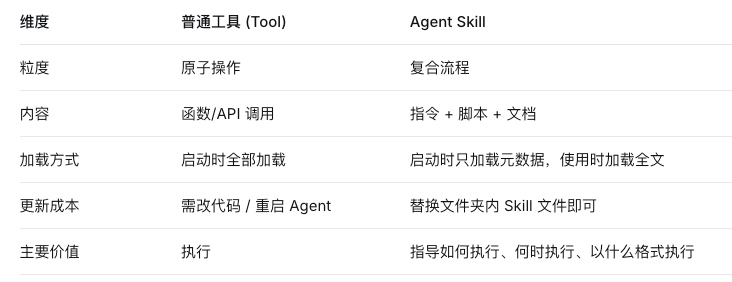
它不是普通工具:普通工具(Tool)只负责“执行一个原子操作”(如搜索、计算),而 Skill 更关注“如何完成一个相对复杂的任务流程”,它可能指导模型组合调用多个工具、遵守特定格式、处理错误、分步推理。
-
它是动态提示词:Skill 本质上是可被 Agent 在运行时按需读取并注入到上下文中的长指令。Agent 平时只“知道”有哪些 Skill(名称+简短描述),当用户问题匹配某个 Skill 时,才读取其完整内容。
用通俗的话讲:Agent Skill 就是一份“工作说明书”,平时只看到书名,需要做具体工作时才翻开看详细步骤。
Agent Skills 能做什么?
Skill 赋予 Agent 以下几类核心能力:
1. 封装复杂流程,降低主提示词负担
你可以把一个 5000 字的业务操作指南放进一个 Skill。Agent 平时只消耗几十个字符的 description,需要时才加载全文。
示例:postgres-query Skill 里写明如何连接数据库、如何构造安全查询、如何解释结果,主提示词只需一句“当你需要查询数据库时使用此技能”。
2. 实现多步骤任务的稳定复现
Skill 可以将成功经验固化,避免 Agent 每次都“重新发明轮子”。
示例:一个 customer-complaint Skill 定义了收到投诉后:① 识别情绪 → ② 调用工单系统 → ③ 生成标准回复 → ④ 记录日志。Agent 按此执行,输出质量稳定。
3. 让 Agent 安全地调用敏感工具
通过 Skill 里的 allowed-tools 元数据(虽然目前多是提示),你可以告知模型“执行此 Skill 时可安全使用哪些工具”,降低越权风险。
示例:send-email Skill 只允许 write_file 和 send_smtp 工具,禁止 delete_file。
4. 实现角色扮演或领域专家模式
一个 Skill 可以让 Agent 临时变身为“财务专家”、“法律顾问”或“客服代表”,切换系统提示和行为约束。
示例:tax-expert Skill 内写满税法条款和计算规则,一旦启用,Agent 回答税务问题会更专业严谨。
5. 构建可插拔的 Agent 能力生态
为了更好的理解,你可以把 Skills 理解为“通用 Agent 的扩展包”: Agent 可通过加载不同的 Skills 包,来具备不同的专业知识、工具使用能力,稳定完成特定任务。
团队或个人可以像“安装插件”一样共享、复用 Skill,只需把 Skill 文件夹放入指定目录,Agent 自动识别。
示例:一个开源的 weather-forecast Skill 被下载后,放入 ./skills/ 文件夹,Agent 立刻具备全球天气查询能力。
为什么提出 Agent Skills?
提出 Agent Skill 是为了同时解决传统方法中的两大矛盾:
矛盾一:大模型上下文窗口有限 vs. 我们希望它掌握海量知识
-
直接放进系统提示:会迅速撑爆上下文(例如让 Agent 记住 100 个复杂任务的详细步骤)。
-
靠微调(Fine-tuning):成本高、更新慢,无法实时添加新能力。
-
靠检索增强(RAG):虽然能外挂知识库,但对过程性、指令性知识(“如何做”)的检索效果不如结构化 Skill。
Skill 的解法:渐进式披露(Progressive Disclosure)—— 先给目录,按需翻正文。用极小的元数据开销,换取无限的详细指令扩展。
矛盾二:Agent 的行为随机性强 vs. 业务场景需要稳定流程
-
普通 Prompt 下,模型对同一任务的执行方式可能每次不同,导致不可预测。
-
手写复杂的工具调用链(LangChain Chain / Graph)虽然稳定,但开发成本高、不够灵活。
Skill 的解法:流程固化 + 自然语言约束。Skill 中用 Markdown 写明“步骤1做什么,步骤2做什么,如果出现异常怎么办”,模型被引导沿着稳定路径前进,同时保留了自然语言的适应性。
额外动机:能力复用的工业化需求
-
过去每个 Agent 的能力都需要定制开发(写工具、写提示)。
-
Skill 提出后,团队可以把一个“技能”打包成文件夹,上传到内部仓库或 GitHub,其他人复制粘贴即用。这类似于AI Agent 领域的 “Docker 容器”,大大提高了能力复用效率。
工具和skills对比
Agent Skills和Milti-Agent对比
Agent Skills Multi-Agent架构 都旨在解决“如何让AI Agent处理复杂任务”的问题,但它们的思路、实现路径和适用场景有本质区别。
Agent Skills是“模块化的方式强化个人”,而Supervisor多Agent是“协作的方式建设团队”。

使用场景
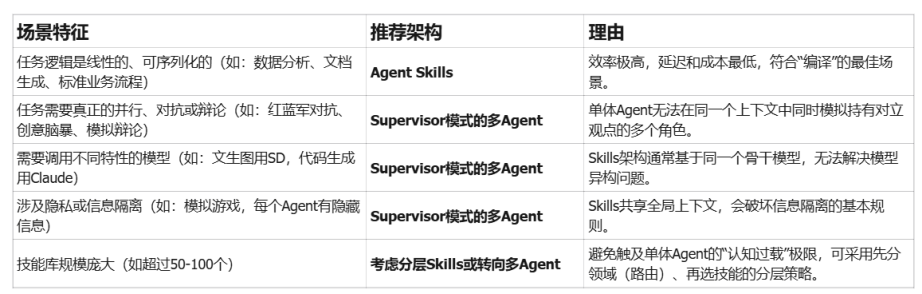
核心机制:为何它能“知晓一切”又不“内存爆炸”?
这个巧妙的平衡,依赖于一个叫做“渐进式披露 (Progressive Disclosure)”的机制。整个过程分为三步:
-
加载“目录”:Agent启动时,只会读取所有Skill的简要信息(
name和description),并将其作为一份目录整合到系统提示词里。初始加载成本极低,模型只知道有这些能力存在,但并不清楚具体怎么做。 -
判断与选择:当你提出需求时,Agent会根据需求,与“目录”中的描述进行匹配,判断是否需要调用某个Skill。
-
只读“正文”:当确定需要时,Agent才会去完整读取该Skill文件夹下的
SKILL.md等具体文件,获取如何执行的详细指令并据此执行任务。
这个机制的精妙之处在于,它将“知道有什么能力”和“知道如何使用能力”分成了两步,从而用极小的上下文成本,赋予了模型海量的“知识”。
SKILL.md:一个Skill的精髓
SKILL.md 是定义能力的唯一入口。它的内部结构由两部分组成:
-
YAML 前置元数据 (Frontmatter):用
---包裹,包含供Agent快速识别的字段。-
name(必填):Skill的唯一标识,要求使用小写字母和连字符,1-64个字符。通常与Skill的文件夹同名。 -
description(必填):用一句话说明这个Skill的功能和使用场景,1-1024个字符。这是Agent决定是否调用的关键依据。 -
license(可选):技能许可协议,如MIT,Apache-2.0。 -
compatibility(可选):说明运行该技能所需的环境要求,如特定软件、网络访问等。 -
allowed-tools(可选):提供一个信任的“允许列表”,告知模型在执行此技能时可以安全地使用哪些工具。
-
-
Markdown 指令 (Instructions):这是YAML之后的核心内容。需要用清晰的语言指导Agent在什么时机、按什么步骤、采用什么格式来执行该技能。
技术实现:如何让Agent拥有Skills?
在技术层面,这主要靠 SkillsMiddleware 来实现。它就像搭在Agent和底层存储系统之间的桥梁,负责从你指定的目录加载Skill,并协调“渐进式披露”的流程。这让你可以灵活选择文件系统、云端存储甚至数据库来存放你的Skills。
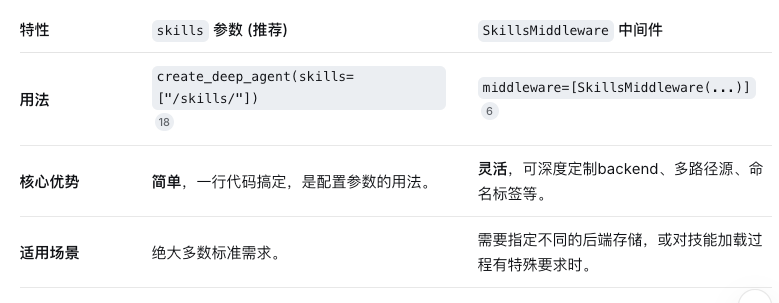
方法对比:技能加载的两种方式
在deepagents中,主要有两种方式来加载技能,理解它们的区别对你选择合适的写法会很有帮助:
最佳实践:如何写出一个好的Skill?
想写出高质量的Skill,可以从以下几点入手:
-
单一职责:一个Skill只专注做好一件事,保持模块的简洁和清晰。
-
Meta指令先行:在
description中写清“何时使用”和“解决什么问题”,这是Agent调用Skill的“第一道门”。 -
善用技能组合:一个复杂的业务可以由多个简单的Skill组合完成。不同Skill之间可以通过
SKILL.md中的Tool调用其他Skill或外部工具来实现复杂流程。 -
保持"目录"精简:
SKILL.md文件本身应保持小巧(建议<5k tokens),将详细的API文档、代码示例等放在reference/等子文件夹中,仅供Agent按需查阅。 -
版本控制:将Skill及其配套文件纳入Git等版本管理,便于追踪变更、进行Code Review和协同开发。
-
评测驱动迭代:收集真实任务作为测试基准,基于评测结果持续优化Skill的指令和逻辑。
注意事项与常见问题
-
文件大小限制:为了性能考虑,每个
SKILL.md文件的大小有限制(如在Deep Agents中必须小于10 MB),过大的文件会被跳过。 -
allowed-tools仅为提示:请注意,allowed-tools字段目前仅是一个给Agent的“提示”(hint),中间件并不会强制执行这一限制。 -
工具隔离性:Skill本质上是“提示片段”,而不是“运行时单元”,因此没有开始和结束事件可供钩子捕捉。
-
命名规则:Skill的
name必须严格遵循命名规范(小写字母、连字符、数字),不要使用下划线或空格。
示例一:使用 skills 参数 (最推荐)
这种方式是最快捷的,适合大多数情况。
目录结构:
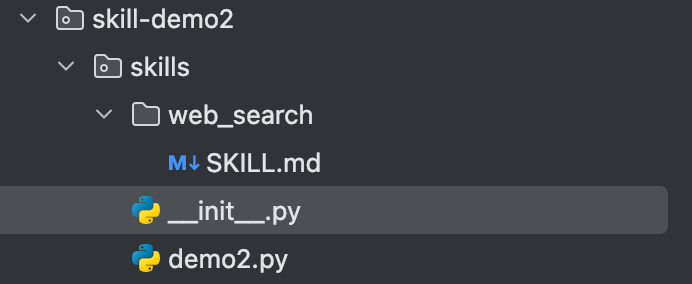
在项目根目录下创建一个 skills 文件夹,并按照官方规范创建技能描述文 件 web_search/SKILL.md。请确保该文件中使用YAML格式定义了技能的 name 和 description
SKILL.md内容如下:
---
name: web_search
description: 当你需要从互联网上查找最新信息来回答用户问题时,使用此技能。
---
# Web Search Skill
- **何时使用**:当用户的问题需要联网搜索、获取实时数据或背景信息时。
- **如何执行**:通过调用 `internet_search` 工具来完成。你需要分析用户的问题,提炼出精确的搜索关键词,并将其作为 `query` 参数进行搜索。测试代码:
import os
from typing import Literal
from deepagents import create_deep_agent
from langchain_core.tools import tool
from tavily import TavilyClient
from agent.my_llm import llm
tavily_client = TavilyClient(api_key='')
@tool
def internet_search(query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,):
"""使用 Tavily API 进行网络搜索,获取最新的新闻和信息。
支持通用搜索、新闻搜索和金融搜索三种模式,可以获取实时网络信息。
Args:
query: 搜索查询词,描述要搜索的内容
max_results: 返回的最大结果数量,默认 5
topic: 搜索主题类型,可选 "general"(通用)、"news"(新闻)、"finance"(金融)
include_raw_content: 是否包含原始页面内容,默认 False
Returns:
包含搜索结果的字典,包括标题、URL、内容片段等信息
"""
print(f'调用网络查询工具,查询内容:{query}')
return tavily_client.search(query=query, max_results=max_results, topic=topic, include_raw_content=include_raw_content)
agent = create_deep_agent(
model=llm,
tools = [internet_search],
system_prompt="你是一名研究助理。你可以使用 'web_search' 技能来寻找最新信息。",
skills=["skills"]
)
result = agent.invoke({"messages": [{"role": "user", "content": "2026特朗普访华新闻"}]})
print(result['messages'][-1].content)示例二:使用 SkillsMiddleware 中间件 (适合高度定制)
这种方式提供了更多的控制权,适合需要深度定制的场景。
-
技能文件夹结构
与方式一相同,需要一个skills/web_search/SKILL.md文件
测试代码如下:
import os
from typing import Literal
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from deepagents.middleware import SkillsMiddleware
from langchain_core.tools import tool
from tavily import TavilyClient
from agent.my_llm import llm
tavily_client = TavilyClient(api_key='')
@tool
def internet_search(query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,):
"""使用 Tavily API 进行网络搜索,获取最新的新闻和信息。
支持通用搜索、新闻搜索和金融搜索三种模式,可以获取实时网络信息。
Args:
query: 搜索查询词,描述要搜索的内容
max_results: 返回的最大结果数量,默认 5
topic: 搜索主题类型,可选 "general"(通用)、"news"(新闻)、"finance"(金融)
include_raw_content: 是否包含原始页面内容,默认 False
Returns:
包含搜索结果的字典,包括标题、URL、内容片段等信息
"""
print(f'调用网络查询工具,查询内容:{query}')
return tavily_client.search(query=query, max_results=max_results, topic=topic, include_raw_content=include_raw_content)
backend = FilesystemBackend(root_dir=os.getcwd(),virtual_mode=True)
skills_middleware = SkillsMiddleware(
backend=backend,
sources=["skills"],
)
agent = create_deep_agent(
model=llm,
tools = [internet_search],
system_prompt="你是一名研究助理。你可以使用 'web_search' 技能来寻找最新信息。",
middleware=[skills_middleware]
)
result = agent.invoke({"messages": [{"role": "user", "content": "2026特朗普访华新闻"}]})
print(result['messages'][-1].content)示例三:技能自包含脚本实现方法
目录如下:
SKILL.md文件内容如下:
---
name: tavily-search
description: 使用 Tavily API 搜索互联网,获取实时新闻、金融数据或通用信息。当用户询问最新新闻、实时事件、股价等需要联网的内容时,必须使用此技能。
allowed-tools: execute
---
# Tavily 搜索技能
## 何时使用
- 用户询问最新新闻、事件(如“特朗普2026年5月访华最新消息”)
- 用户需要实时数据、股价、天气等
- 任何你的内部知识无法回答且需要联网的问题
## 如何使用
你拥有 `execute` 工具,可以直接运行 Shell 命令。请按以下格式执行搜索脚本:
```bash
python skills/tavily-search/search.py --query "搜索关键词" --topic general --max-results 5search.py如下:
#!/usr/bin/env python3 """ Tavily 搜索脚本 - 通过命令行调用 用法: python search.py --query "关键词" [--max-results 5] [--topic general] """ import os import sys import json import argparse from typing import Literal # 设置 API Key(可以从环境变量读取) TAVILY_API_KEY = os.environ.get("TAVILY_API_KEY") if not TAVILY_API_KEY: print("错误: 请设置环境变量 TAVILY_API_KEY", file=sys.stderr) sys.exit(1) # 优先使用 tavily 包,如果没有则使用 requests(更轻量) try: from tavily import TavilyClient client = TavilyClient(api_key=TAVILY_API_KEY) USE_TAVILY_PACKAGE = True except ImportError: import requests USE_TAVILY_PACKAGE = False def internet_search( query: str, max_results: int = 5, topic: Literal["general", "news", "finance"] = "general", include_raw_content: bool = False, ) -> dict: """使用 Tavily API 进行网络搜索,返回字典结果""" print(f"🔍 正在搜索: {query} (主题: {topic})", file=sys.stderr) if USE_TAVILY_PACKAGE: # 使用官方包 return client.search( query=query, max_results=max_results, topic=topic, include_raw_content=include_raw_content, ) else: # 使用 requests 直接调用 API(无需安装 tavily-python) url = "https://api.tavily.com/search" payload = { "api_key": TAVILY_API_KEY, "query": query, "max_results": max_results, "topic": topic, "include_raw_content": include_raw_content, "include_answer": True, } resp = requests.post(url, json=payload, timeout=30) resp.raise_for_status() return resp.json() def main(): parser = argparse.ArgumentParser(description="Tavily 网络搜索") parser.add_argument("--query", "-q", required=True, help="搜索关键词") parser.add_argument("--max-results", "-n", type=int, default=5, help="最大结果数 (默认5)") parser.add_argument("--topic", "-t", choices=["general", "news", "finance"], default="general", help="搜索主题") parser.add_argument("--raw", action="store_true", help="包含原始内容") parser.add_argument("--json", action="store_true", help="以 JSON 格式输出") args = parser.parse_args() result = internet_search( query=args.query, max_results=args.max_results, topic=args.topic, include_raw_content=args.raw, ) if args.json: print(json.dumps(result, ensure_ascii=False, indent=2)) return # 文本输出(便于 Agent 阅读) if result.get("answer"): print(f"📌 答案摘要: {result['answer']}\n") results = result.get("results", []) if not results: print("未找到相关结果。") return print(f"共找到 {len(results)} 条结果:\n") for i, item in enumerate(results, 1): title = item.get("title", "无标题") url = item.get("url", "") content = item.get("content", "")[:300] print(f"{i}. {title}") print(f" 链接: {url}") print(f" 内容: {content}...\n") if __name__ == "__main__": main()
测试代码:
import os
import subprocess
from pathlib import Path
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
# 假设你的 LLM 配置在 agent.my_llm 中
from agent.my_llm import llm
# 设置 Tavily API Key(也可以从环境变量读取,这里显式设置)
os.environ['TAVILY_API_KEY'] = ''
EXAMPLE_DIR = Path(__file__).parent
# 通用命令执行工具(所有技能共用)
@tool
def execute(command: str) -> str:
"""执行 Shell 命令并返回输出。用于运行 Python 脚本、系统命令等。"""
try:
result = subprocess.run(
command,
shell=True,
capture_output=True,
text=True,
timeout=60,
cwd=str(EXAMPLE_DIR) # 确保在项目根目录执行
)
return result.stdout + result.stderr
except subprocess.TimeoutExpired:
return "命令执行超时(60秒)"
except Exception as e:
return f"执行错误: {e}"
# 创建 Agent:只有通用工具 + skills 目录
agent = create_deep_agent(
model=llm,
tools=[execute], # 唯一工具:执行命令
backend=FilesystemBackend(root_dir=EXAMPLE_DIR, virtual_mode=False),
skills=[str(EXAMPLE_DIR / 'skills')], # 加载 skills 文件夹
system_prompt=(
"你是我的AI助手。当需要联网搜索、查询新闻或实时信息时,"
"必须使用 'tavily-search' 技能。用 execute 工具运行 "
"python skills/tavily-search/search.py --query ... 命令。"
)
)
if __name__ == "__main__":
resp = agent.invoke({
"messages": [HumanMessage("帮我查询特朗普2026年5月访华的最新新闻")]
})
print(resp['messages'][-1].content)示例四:下载网上的skill
下载地址:https://hub.cocoloop.cn/, 这里使用tavily-search-pro做测试,直接放在代码目录下
测试代码:
import os
from pathlib import Path
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from agent.my_llm import llm
import subprocess
os.environ['TAVILY_API_KEY'] = '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'
EXAMPLE_DIR = Path(__file__).parent
# 提供通用命令执行工具
@tool
def execute_command(command: str) -> str:
"""执行 shell 命令并返回输出(用于运行 Python 脚本等)。"""
try:
print(f"执行脚本:{command}")
result = subprocess.run(command, shell=True, capture_output=True, text=True, timeout=60)
return result.stdout + result.stderr
except subprocess.TimeoutExpired:
return "命令执行超时(60秒)"
except Exception as e:
return f"执行错误: {e}"
agent = create_deep_agent(
model=llm,
tools=[execute_command],
backend=FilesystemBackend(root_dir=EXAMPLE_DIR, virtual_mode=False),
skills=[str(EXAMPLE_DIR / 'skills')],
system_prompt="你是我的AI助手,当用户询问新闻、实时信息或需要搜索时,请务必使用tavily技能进行网络搜索。不要仅依赖自己的知识,要主动使用搜索技能获取最新信息。"
)
resp = agent.invoke(input={"messages": [HumanMessage("帮我查询特朗普2026年5月访华的最新新闻")]})
print(resp['messages'][-1].content)
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)