Jina v5-omni:文本、图片、音频、视频,一个模型全部向量化
Jina AI 刚发布了 jina-embeddings-v5-omni,第一个同时支持文本、图片、音频和视频的通用嵌入模型。最关键的一点:如果你已经在用 v5-text,现有的文本向量索引不用重建,直接就能搜图片和视频。
做多模态检索,最头疼的不是模型
做 RAG 系统的人大概都经历过这样的阶段:
一开始只有文本检索,选一个好用的 Embedding 模型,把文档向量化,存进向量数据库,搜索效果还不错。然后需求来了——用户想搜图片。
你找了个 CLIP 模型,把图片也向量化了。但 CLIP 的向量空间和文本 Embedding 的向量空间不一样,两套向量没法放在同一个索引里搜。结果是要么维护两套索引分开搜,要么把所有文本数据用 CLIP 的文本编码器重新向量化一遍。
如果后面又加了音频、视频的检索需求,每加一种模态就多一套编码器、一套索引、一套维护成本。
Jina AI 刚发布的 jina-embeddings-v5-omni 的做法是:把文本、图片、视频、音频全部映射到同一个向量空间里,而且这个向量空间和纯文本版本(v5-text)完全一致——你之前用 v5-text 建好的文本索引,一行代码不用改,直接就能用图片或音频来搜。
提供两个版本:Small(约 1.74B 参数)和 Nano(约 0.95B 参数),ArXiv 论文编号 2605.08384,CC BY-NC 4.0 协议。
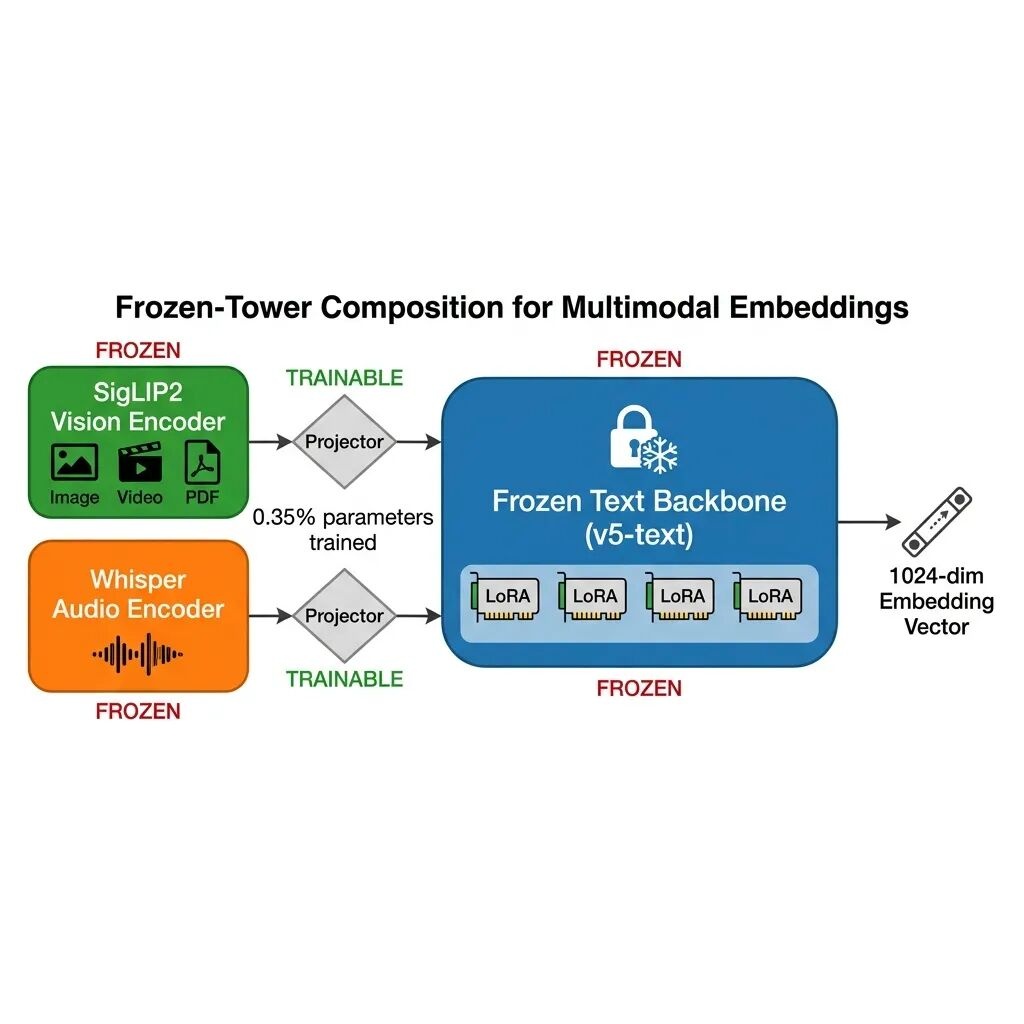
冻住文本主干,只训一个投影层
v5-omni 的架构设计思路很克制。
传统做法是从头训一个多模态模型,所有模态的编码器一起训练。好处是对齐效果好,坏处是训完之后的向量空间和之前的纯文本模型不兼容,已有数据必须全部重新向量化。
v5-omni 反过来做:把已经训好的 jina-embeddings-v5-text 作为文本主干,连带它的四套 LoRA 任务适配器(检索、分类、聚类、文本匹配),全部冻住,一个参数都不动。
新加的部分只有两个东西:
视觉编码器,Small 版用 SigLIP2 So400m(来自 Qwen3.5-2B),Nano 版用 SigLIP2 Base(来自 Qwen3.5-0.8B)。视频的处理方式是采样 32 帧,走视觉通道。PDF 也是渲染成图片走视觉通道。
音频编码器,两个版本都用 Whisper-large-v3(来自 Qwen2.5-Omni-7B)。
这两个编码器的输出维度和文本主干的输入维度不一样,中间靠一个跨模态投影层做维度转换(Small 投影到 1024 维,Nano 投影到 768 维)。
训练的时候,文本主干冻住,视觉和音频编码器也冻住,只有投影层的参数在更新。这部分参数大概 550 万(Small 版),占总参数的 0.35%。
用对比学习加跨模态硬负例来训练投影层,目标是让图片、视频、音频的向量和文本的语义空间对齐。
这个架构有个直接的工程收益:因为文本主干一个参数没动,所以 v5-omni 对纯文本输入的输出和 v5-text 逐位一致(bit-identical)。用大白话说:你之前用 v5-text 建的索引不用动,换上 v5-omni 之后,拿图片或音频去搜文本索引,直接就能出结果。
四种模态,一套接口
用起来很简洁。sentence-transformers 的接口是最省事的:
from sentence_transformers import SentenceTransformermodel = SentenceTransformer( "jinaai/jina-embeddings-v5-omni-small", trust_remote_code=True, model_kwargs={"default_task": "retrieval"},)# 文本q_vec = model.encode_query("哪颗行星被称为红色星球?")# 文档d_vec = model.encode_document("火星因其红色外观而被称为红色星球。")# 图片(URL、本地路径、PIL.Image 都行)i_vec = model.encode("photo.jpg")# 视频v_vec = model.encode("clip.mp4")# 音频a_vec = model.encode("speech.wav")
五种输入,同一个 encode 方法,出来的向量在同一个空间里,可以直接算余弦相似度。
还有一个不错的功能——多模态融合。把文本和图片组成一个 tuple 传进去,模型会在一次前向传播里把它们融合成一个向量:
# 文本 + 图片 + 视频 → 一个向量emb = model.encode(("冬季防水皮靴", "boot.jpg", "boot.mp4"))
这在电商场景里很实用:一个商品同时有标题、主图和短视频,以前要分开编码再加权合并,现在一步到位。
选择性加载,节省显存
四个模态的编码器全部加载,显存消耗不小。v5-omni 支持按需加载——只用图片搜索就只加载视觉编码器,其余的不加载:
from transformers import AutoModel# 只加载视觉 + 文本model = AutoModel.from_pretrained( "jinaai/jina-embeddings-v5-omni-small", trust_remote_code=True, modality="vision")# 只加载音频 + 文本model = AutoModel.from_pretrained( "jinaai/jina-embeddings-v5-omni-small", trust_remote_code=True, modality="audio")# 只要文本model = AutoModel.from_pretrained( "jinaai/jina-embeddings-v5-omni-small", trust_remote_code=True, modality="text")
不需要的编码器在加载时直接跳过,显存立竿见影地省下来。这在资源有限的部署环境里是一个很实际的考量。
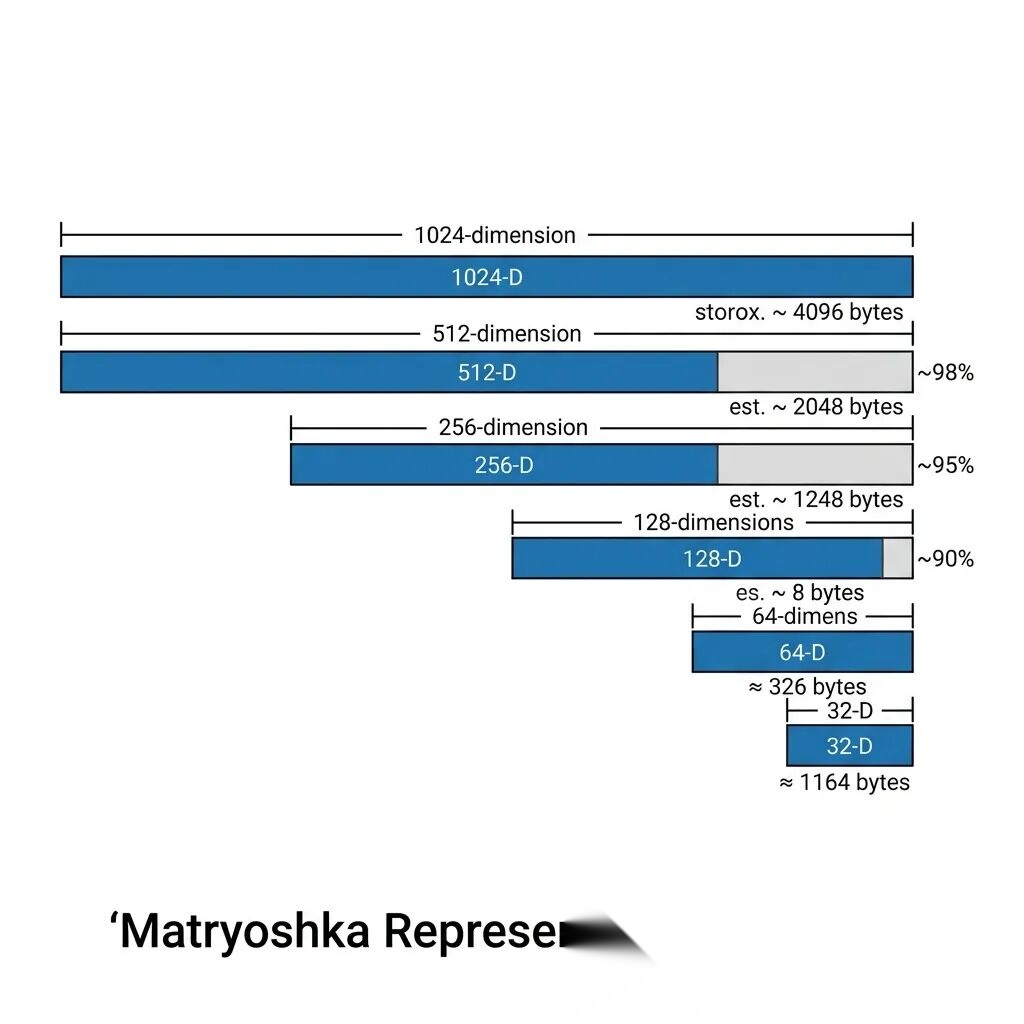
Matryoshka 降维:1024 维压到 32 维
v5-omni 用了 Matryoshka Representation Learning(MRL)训练,允许你把 1024 维的完整向量直接截断到更短的维度——256 维、128 维、甚至 32 维——性能衰减很小。
# transformersvec = model.embed(truncate_dim=256, **inputs)# sentence-transformersvec = model.encode("hello", truncate_dim=256)# vLLMfrom vllm import PoolingParamsouts = llm.embed(prompts, pooling_params=PoolingParams(dimensions=256))
1024 维的向量占 4KB(float32),如果你的数据量是千万级,光是向量索引就要几十 GB。截到 256 维,存储成本降到四分之一;截到 32 维,降到三十二分之一。
这在实际场景里的意义很大:你可以先用 32 维做粗筛(速度快、存储省),再对 top-k 结果用完整 1024 维做精排。这种两阶段策略在大规模检索系统里是标准做法,但要求模型本身支持 Matryoshka 训练才行——v5-omni 原生支持。
四种任务适配器,不只是检索
v5-omni 不是只能做检索。它继承了 v5-text 的四套 LoRA 适配器,每套针对不同任务优化:
retrieval(检索):query-document 语义搜索和 RAG。查询端用 encode_query(),文档端用 encode_document(),不能混用。
classification(分类):通过向量相似度做零样本和少样本分类。比如用一段文字描述类别,然后用图片的向量去匹配最近的类别描述。
clustering(聚类):把语义相似的内容分组,做主题发现、去重、探索性分析。
text-matching(文本匹配):对称的相似度打分,做 STS、近义句检测、近似查重。
加载的时候选一个就行:
model = SentenceTransformer( "jinaai/jina-embeddings-v5-omni-small", trust_remote_code=True, model_kwargs={"default_task": "classification"},)
或者直接用预合并的变体,不用在加载时指定:
- jinaai/jina-embeddings-v5-omni-small-retrieval
- jinaai/jina-embeddings-v5-omni-small-classification
- jinaai/jina-embeddings-v5-omni-small-clustering
- jinaai/jina-embeddings-v5-omni-small-text-matching
部署选项
v5-omni 支持三种部署方式:
原生 transformers,适合研究和小规模实验。需要 transformers>=4.57,torch>=2.5。
sentence-transformers,最省事的 API,一行代码支持所有模态。适合中等规模的生产场景。
vLLM,适合大规模高吞吐部署。经过 vllm==0.20.1 验证,支持 H100 FP8 推理。CLI 一行启动:
vllm serve jinaai/jina-embeddings-v5-omni-small \ --trust-remote-code \ --hf-overrides '{"task": "retrieval"}'
Elastic 也已经集成了 v5-omni,通过 Elastic Inference Service 可以直接用,不需要自己部署模型。
跟 CLIP 比,v5-omni 的优势在哪
CLIP 是多模态检索的事实标准,但它有几个限制:
CLIP 只支持文本和图片,不支持音频和视频。要搜音频得另找一个模型(比如 CLAP),要搜视频得再找一个(比如 VideoCLIP),每加一种模态就多一套体系。
CLIP 的文本向量和纯文本 Embedding 模型的向量不兼容。你不能把 CLIP 的文本向量和 jina-embeddings-v3 的文本向量放在同一个索引里搜,两个向量空间对不上。
v5-omni 解决了这两个问题:四种模态一个模型搞定,而且文本向量和纯文本版完全兼容。
在具体指标上,Jina 官方数据显示 v5-omni 在 MIEB(图像)、ViDoRe(文档检索)、MAEB(音频)等基准上超越了参数量 20 倍以上的模型。在视觉相似度和检索任务上,也超过了自家的 jina-clip-v2。
值不值得用
v5-omni 解决了一个很具体的工程问题:怎么在不重建现有文本索引的前提下,给系统加上图片、视频和音频的检索能力。
"冻住主干只训投影层"这个思路不新,但 Jina 把它做到了工程可用的程度——向量完全兼容、多任务适配器完整保留、部署方式齐全(transformers / sentence-transformers / vLLM / Elastic),再加上 Matryoshka 降维的存储优化,整个方案从研究到落地的路径很短。
两个限制需要注意:协议是 CC BY-NC 4.0,商用需要联系 Jina 获取授权;另外模型刚发布不到一周,社区工具链和最佳实践还在积累中。
如果你正在运营一个基于 Jina v5-text 的 RAG 系统,或者正在规划一个需要多模态检索的新项目,v5-omni 是目前最值得评估的选项。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献204条内容
已为社区贡献204条内容

所有评论(0)