收藏夹500篇文章看了不到10篇,我用Claude Code帮我全整理了
我的浏览器收藏夹里大概有几百篇文章。认真会看过的,可能不到十分之一。
问题不是文章不好,是收藏完就完事了。链接堆在那里,找的时候搜不到,打开的时候网页可能已经挂了。后来我开始想,与其继续往收藏夹里塞,不如把内容抓到本地,让AI帮我整理。
试了一阵子Obsidian + Claude Code的组合,效果比我预期好。同事看我直接在Obsidian里问AI"这篇文章讲了什么"、"帮我整理成一篇知识条目",觉得挺实用,催我写一篇。
这篇就讲讲我怎么搭的。
目录结构
很多人用Obsidian一开始很兴奋,今天建一个文件夹,明天改一套分类,过几个月自己都不知道东西放哪了。
我现在的结构是这样的:
knowledge-base
├── raw/ # 原始资料,只读不改
│ ├── article1.md
│ ├── article2.md
│ └── ...
├── wiki/ # 整理后的知识
│ ├── index.md # 知识索引,AI 自动维护
│ ├── log.md # 变更日志
│ └── ...
├── output/ # 输出内容:文章、报告、HTML
└── CLAUDE.md # 给 AI 看的操作规则
raw/ 只存原文,不改。原文是证据,AI总结错了还能回来对照。要是上来就让AI改原文,后面出了问题没法追。
wiki/ 是真正的知识库。AI读raw/里的内容,提炼核心观点、可复用方法、跟已有知识的关联,写成结构化笔记。不是简单摘要——简单摘要只是"这篇文章说了什么",知识整理要回答"以后查这个主题该看哪篇"。
output/ 放成品。写公众号、整理FAQ、生成 HTML、输出报告,都放这里。wiki是知识源,output是结果,分开存不会互相污染。不然AI把你写好的文章又当资料学习,来回套娃,越来越乱。
用 Web Clipper 把网页抓到本地
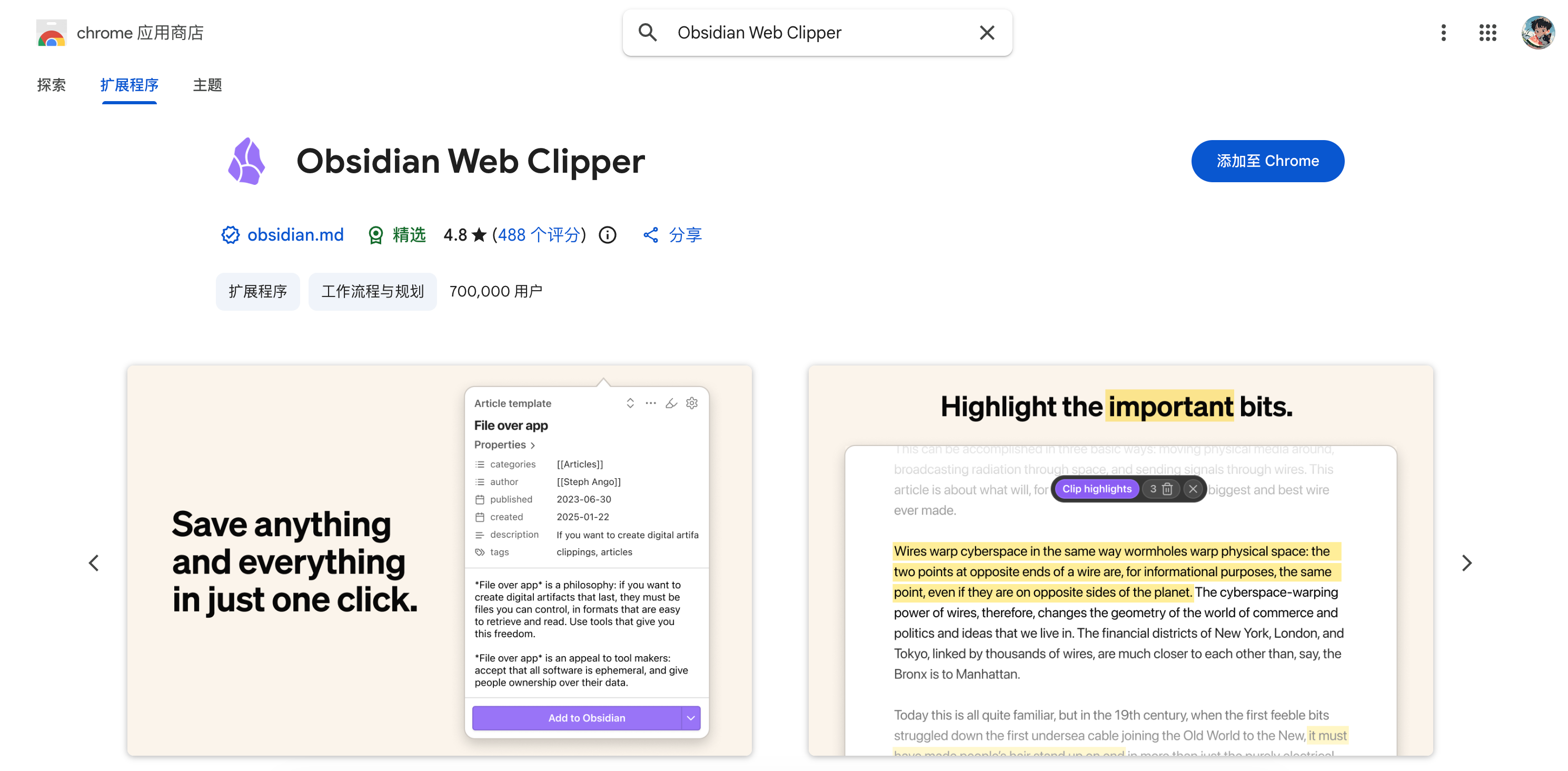
目录定好之后就是采集。我用的是Obsidian官方的浏览器插件Obsidian Web Clipper。
Chrome用户直接去应用商店搜"Obsidian Web Clipper"安装就行,也可以直接访问:
https://chromewebstore.google.com/detail/obsidian-web-clipper/cnjifjpddelmedmihgijeibhnjfabmlf
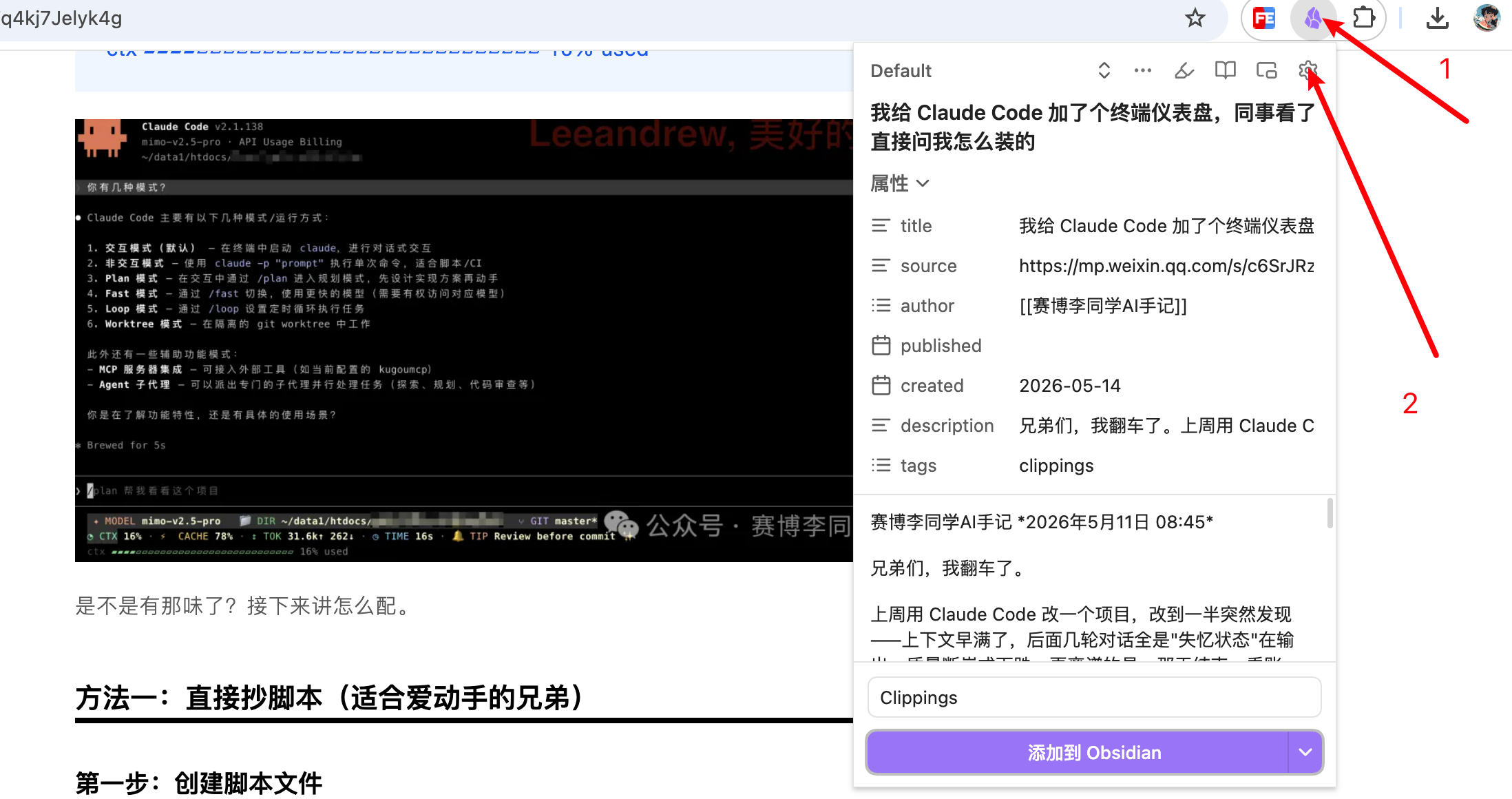
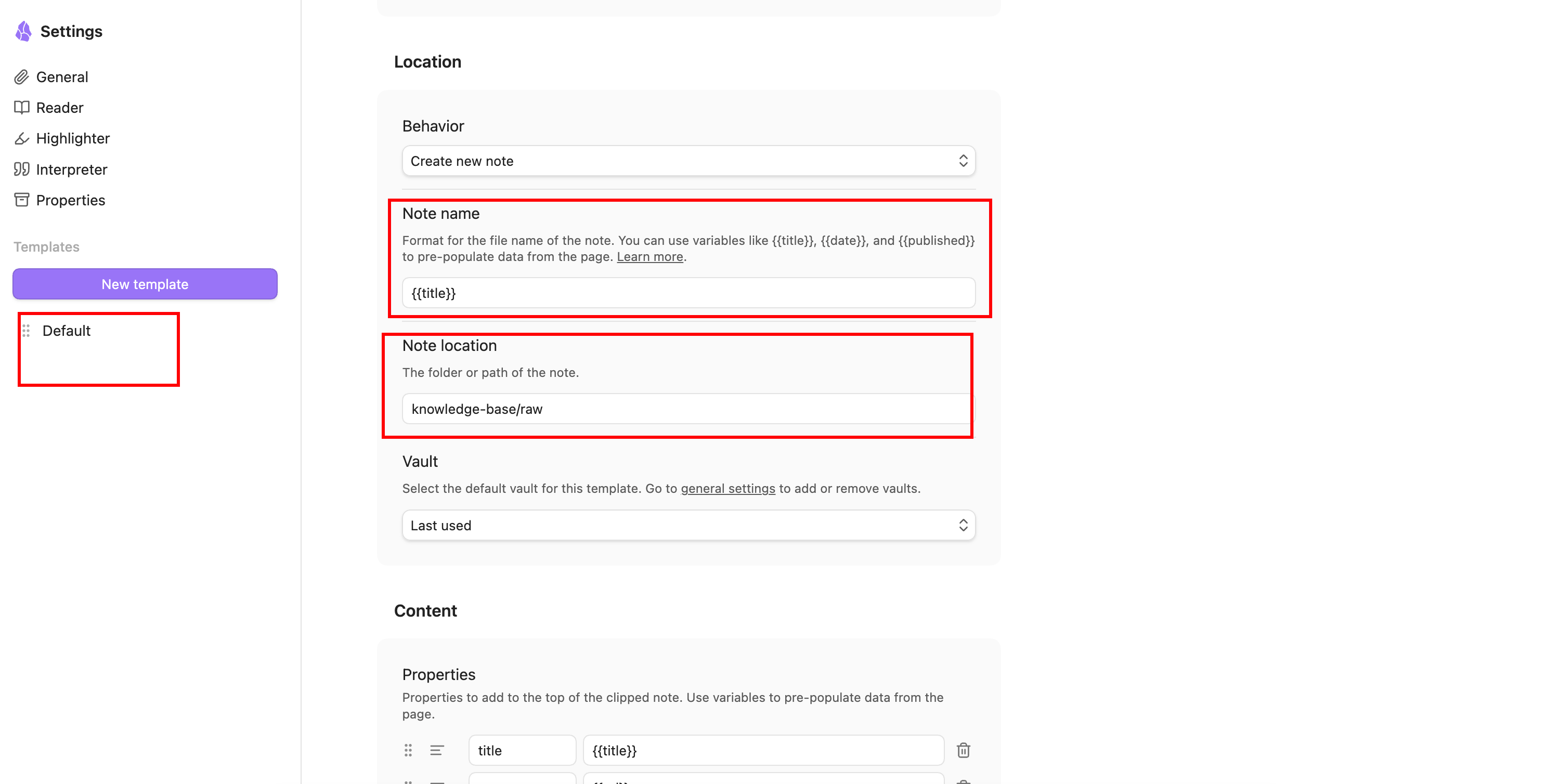
装好之后点浏览器工具栏里的Obsidian图标,进设置,三个地方要改:
Vault — 选你的Obsidian知识库目录。
Note name — 用默认的 {{title}} 就行,网页标题当文件名。
Note location — 填raw。所有采集内容先统一进knowledge-base/raw/,不要直接进wiki/,因为刚抓下来的东西还是原始资料。
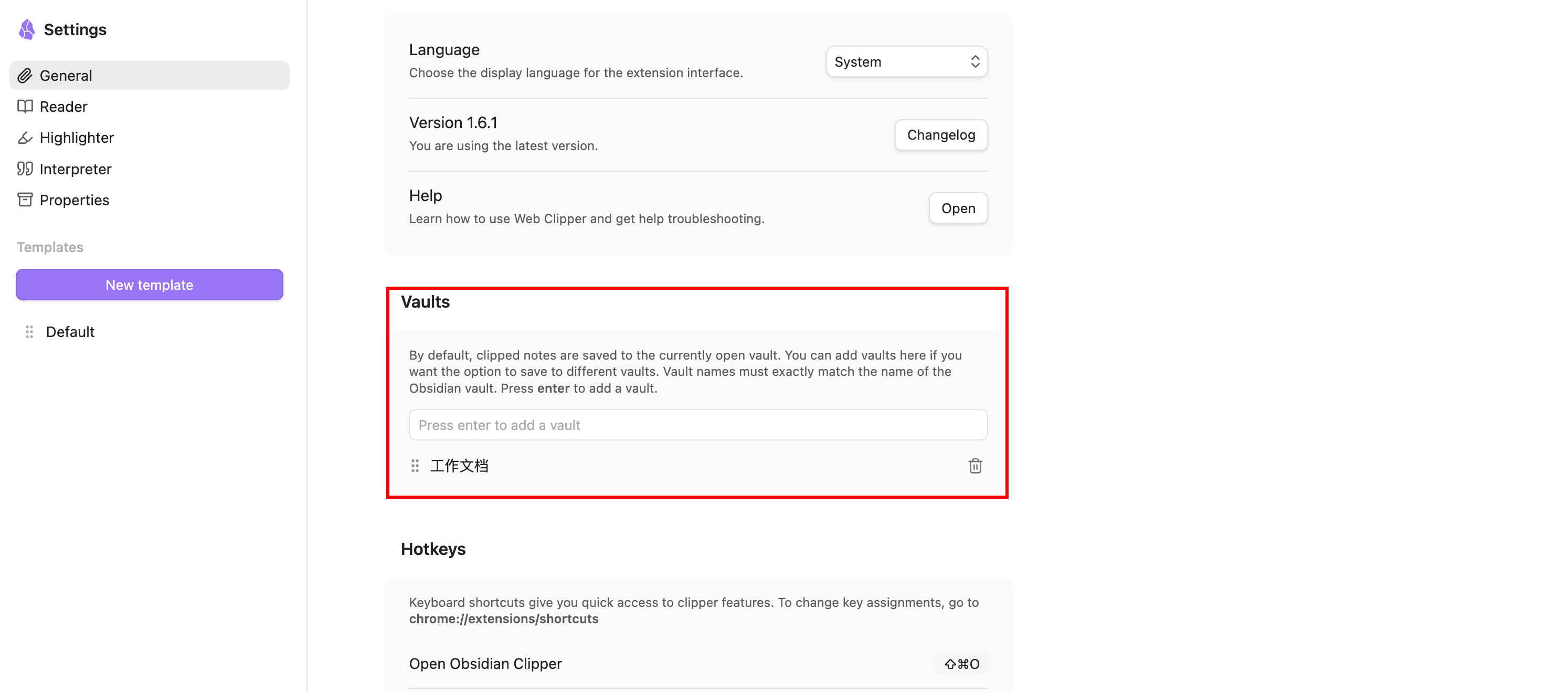
设置好之后,打开一篇想保存的网页,点一下插件图标,选保存为 Markdown,一瞬间就进到knowledge-base/raw/ 里了。
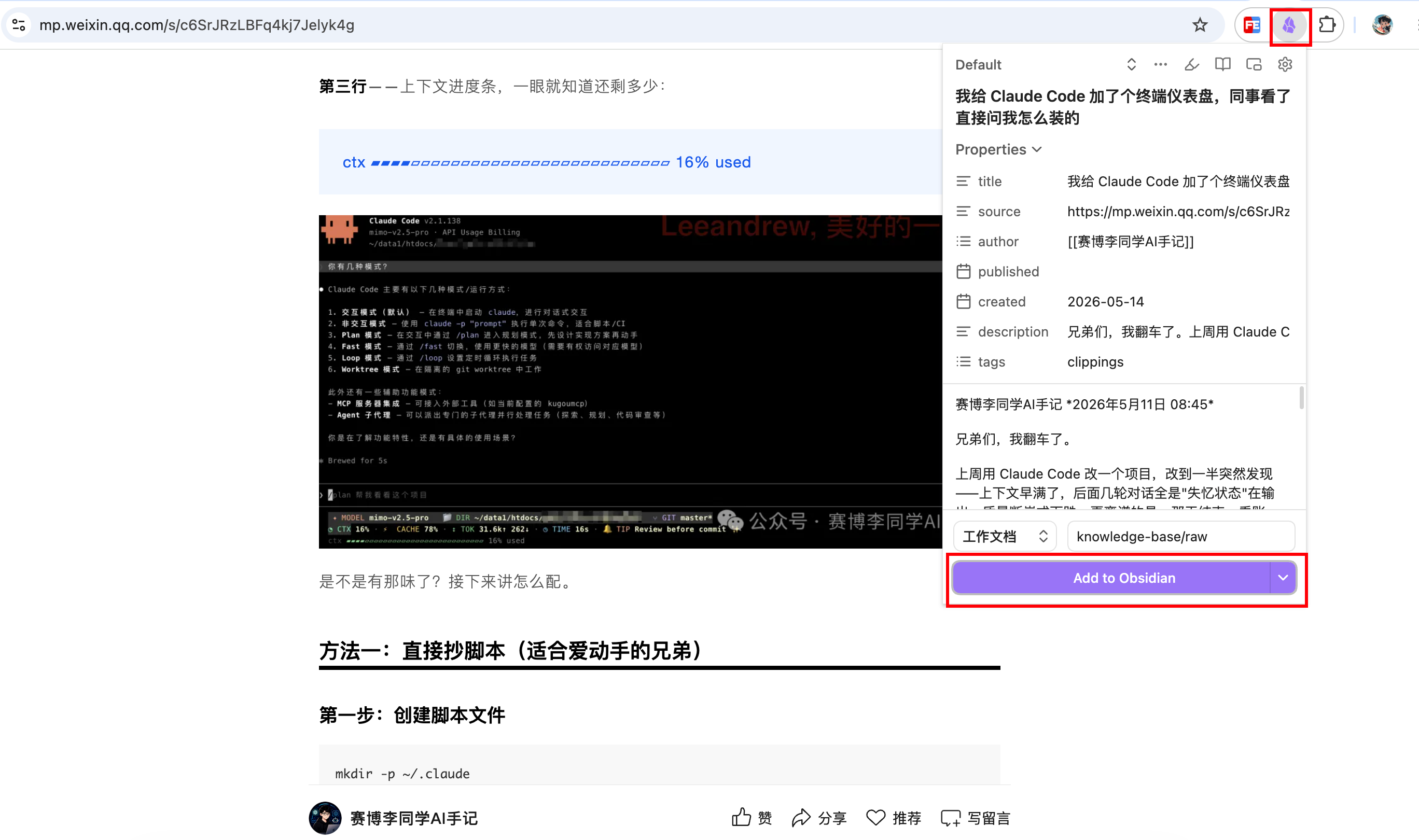
回到Obsidian客户端,左侧就能看到刚保存的文件。
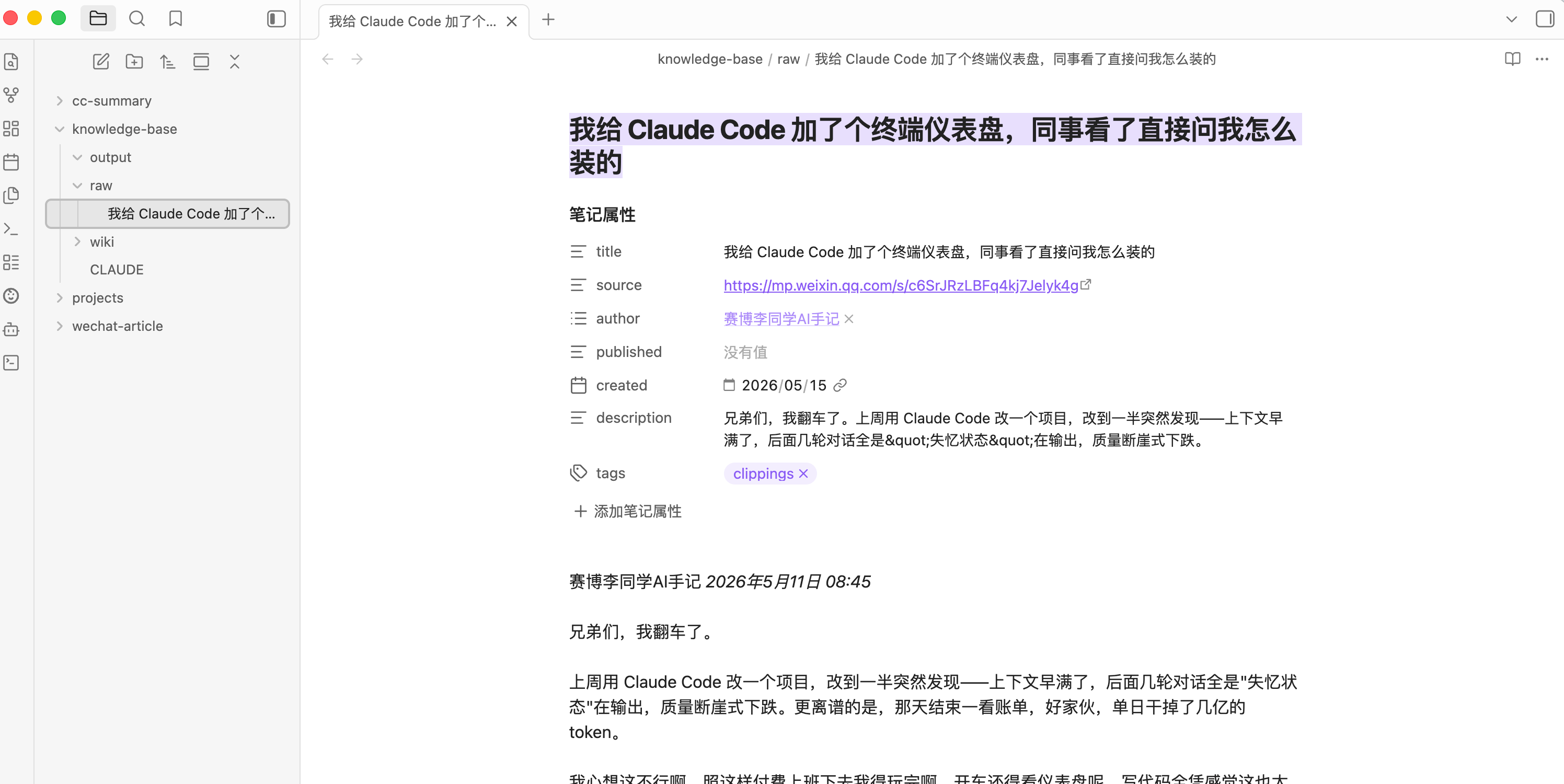
资料进来了,接下来是怎么让AI把它变成知识。
写一个CLAUDE.md
AI很聪明,但它不知道你的规矩。哪些文件能改、整理后放哪、索引要不要更新、用什么格式输出——这些你不说,它就自己猜。
所以需要一个规则文件,放在知识库根目录下:
CLAUDE.md
不用写太长,太长每次都占上下文,AI 也抓不住重点。核心规则够用就行:
# 知识库工作指南
## 1. 身份
你是我的Obsidian知识库管理助手。你的职责是读取原始资料、整理结构化知识、维护索引、记录日志,并在需要时生成可复用的输出内容。
你的目标不是简单摘要,而是把零散资料转化为可查询、可链接、可复用、可持续更新的知识系统。
## 目录结构
knowledge-base/
├── raw/ # 原始资料,只读,不可修改
├── wiki/ # 结构化知识
│ ├── index.md # 知识条目索引(标题、来源、摘要、标签)
│ └── log.md # 变更日志
├── output/ # 文章、问答、HTML、报告等输出
└── CLAUDE.md # 当前规则
## 工作流程
### 1. 整理资料时
当用户说“整理”“整理某个文件”“整理全部”时:
1. 阅读原文:提取核心知识点
2. 生成wiki条目:写入`wiki/`目录,文件名与raw文件保持一致
3. 更新索引:`wiki/index.md`,添加条目摘要和标签
4. 记录变更:`wiki/log.md`
### 2.Wiki条目格式
每个wiki文件必须包含:
```markdown
---
title: "条目标题"
source: "原始链接"
created: YYYY-MM-DD
tags: [标签1, 标签2]
---
## 概述
一句话说明这是什么。
## 核心内容
提取并重构原文的关键知识点,要求:
- 去除广告、引流、无关内容
- 结构化整理,使用清晰的层级
- 保留技术细节、命令、代码示例
- 补充必要的上下文说明
- 用平实中文,避免翻译腔
## 要点速览
- 用列表快速概括最重要的 3-5 个知识点
## 参考
- 原文链接
### 3. Wiki索引格式
`wiki/index.md` 按主题分组,每条记录包含:标题(链接)、来源、创建日期、摘要、标签。
### 4. 整理原则
- **raw保留原文不动**,wiki是提炼后的知识
- 知识条目应该能独立阅读,不依赖原文
- 优先保留:概念定义、操作步骤、代码示例、架构图说明
- 优先去除:引流话术、重复内容、平台特有元素(点赞、收藏数等)
## 查询资料时
当用户提问或要求查询知识库时:
1. 先读`wiki/index.md`。
2. 找到相关`wiki/` 条目。
3. 综合多个条目回答。
4. 回答中说明依据和相关条目。
5. 没有匹配内容时说明:知识库中没有找到匹配内容。
## 生成输出时
当用户说“写篇文章”“生成 HTML”“沉淀结果”“输出到 output”时:
1. 先从`wiki/index.md`查找相关素材。
2. 读取相关`wiki/`条目,必要时读取`raw/`。
3. 整合内容,避免简单拼接和重复。
4. 生成文件到`output/`。
5. 文件名用一句话概括内容。
6. 更新`wiki/log.md`
这份规则短、清楚、AI容易执行。后面知识库文件多了再慢慢加东西,比如文件命名规范、标签规则、归档机制。但一开始别贪多,先跑通。
让Claude Code整理资料
目录有了,资料抓了,规则写好了。在Claude Code里输入:
整理下文档内容
它会按 CLAUDE.md 的规则执行:读取原始文章,提炼核心内容,生成结构化 wiki 条目,更新 index,记录 log。
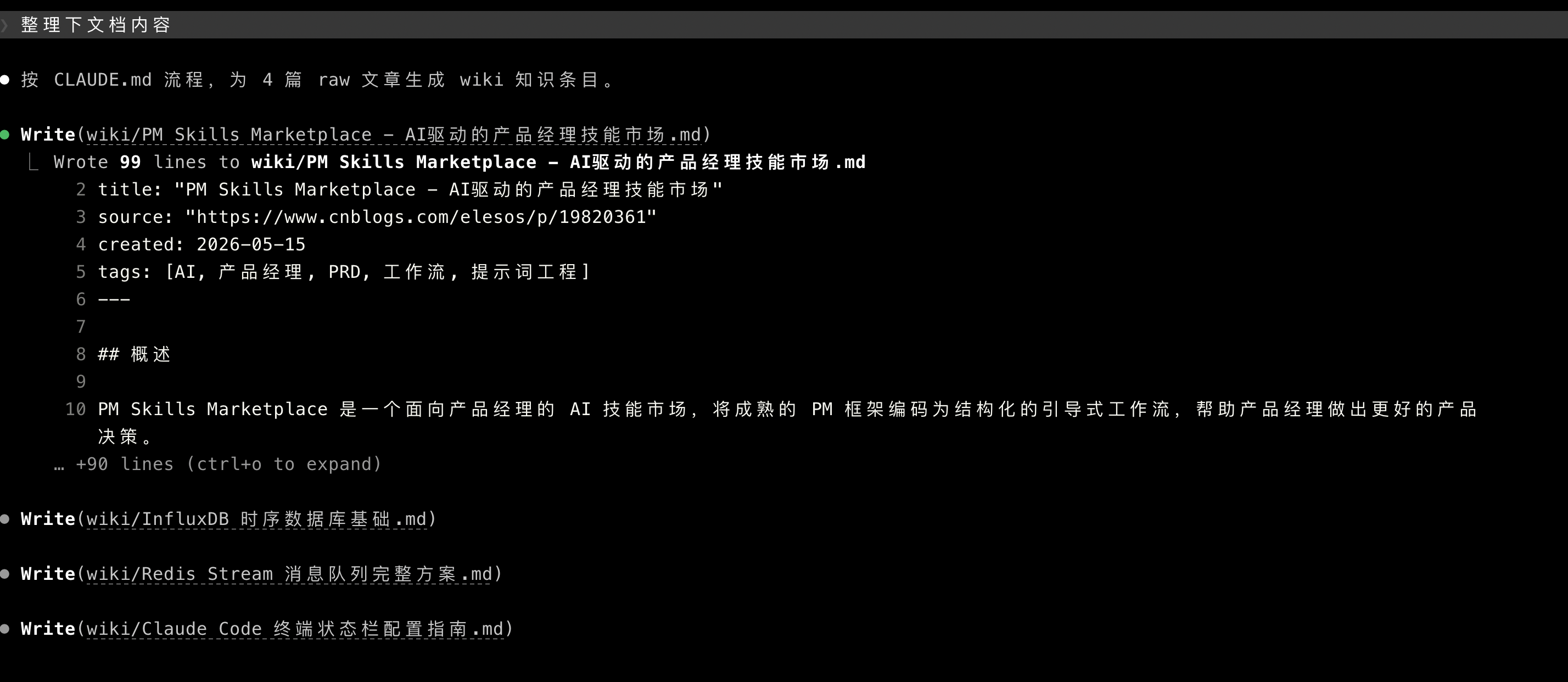

整理完回到Obsidian,wiki/里就多了一篇结构化笔记。这时候它不再是"收藏文章"了,而是可以复用的知识条目。
在Obsidian里直接让AI提炼文章
除了终端里的Claude Code,也可以直接在Obsidian里配合使用。
搜索文章中跟redis队列相关的内容,整理文中核心点,输出一篇文章
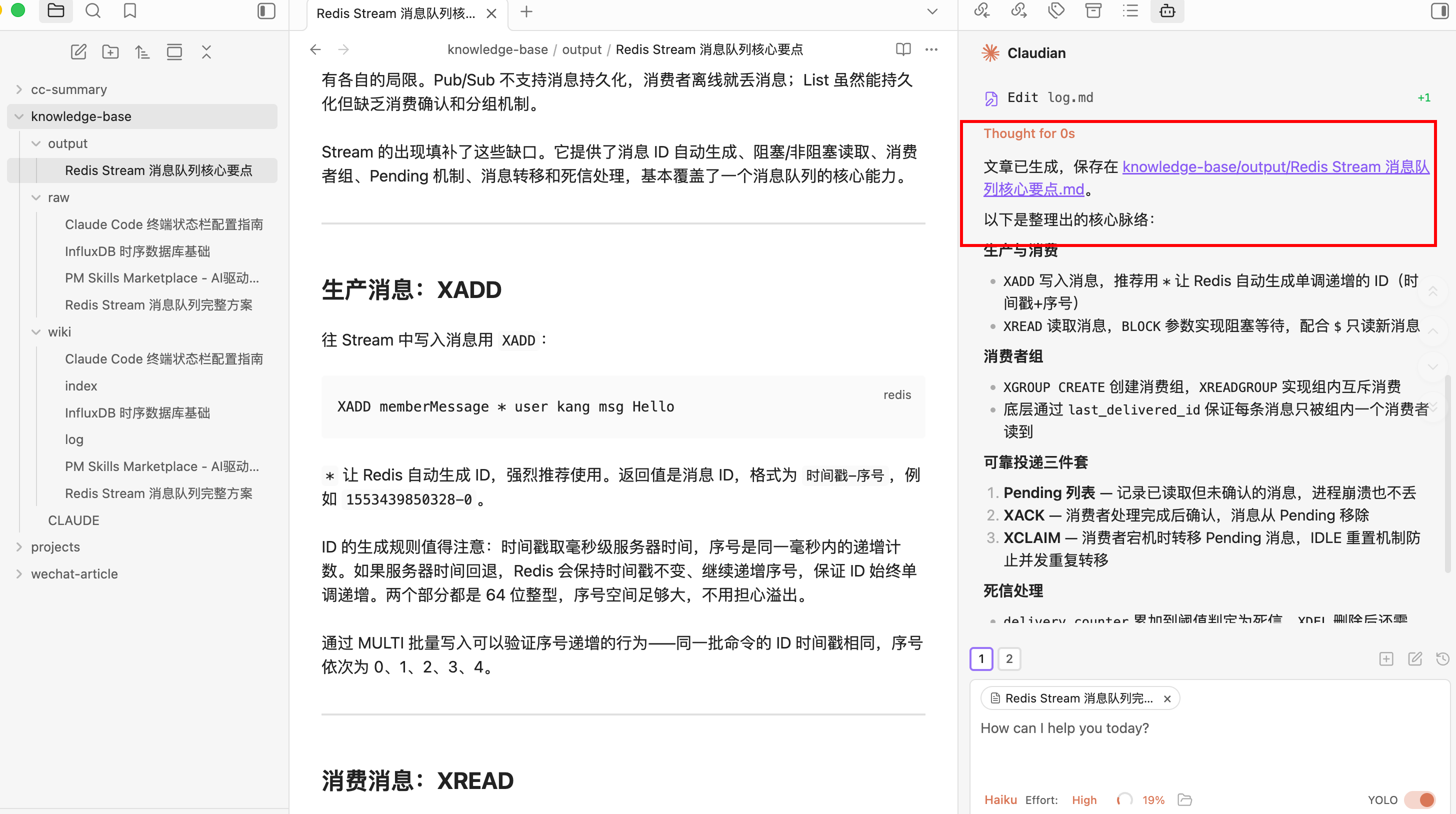
跟普通聊天的区别在于,AI 不是凭空回答,而是在读你的资料。你把资料都放进知识库里,让它基于raw/和wiki/来回答,输出更贴近你的内容,也更容易回溯来源。
这套方法适合什么场景
收藏夹里有几百篇文章但基本不回看的——把链接抓到本地,整理成自己的知识,比躺在收藏夹里强太多。
经常写公众号、博客、方案的——素材已经在Obsidian里整理好了,写的时候直接让AI从知识库里找素材、搭结构、出初稿。
学技术的——今天看一个命令,明天看一个框架,不整理的话脑子里都是碎片。用这套方式可以把教程、文档、代码示例慢慢沉淀成技术 wiki。
想长期积累知识系统的——这套目录和规则解决的是长期问题:资料越来越多之后怎么不乱。
最后
工具会变。今天是Claude Code,明天可能是Codex,后天又是爱马仕。但你的资料、知识库、整理规则,是可以一直积累的。
我现在把Obsidian当成本地知识底座:网页资料进raw/,AI整理后进wiki/,写文章做报告进output/。流程不复杂,但很稳。
如果你也收藏了一堆资料从来不看,可以试试。建好目录,装好插件,写个简单的 CLAUDE.md,随便抓一篇文章跑一遍就知道适不适合自己了。
我是赛博李同学大厂写代码的,觉得有用的话,点个赞 + 转发给需要的TA,感谢支持!,我们下期再见!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)