什么是机器学习
机器学习是人工智能的一个子领域,通过数据驱动让计算机自动学习数据中的潜在规律,进而对新数据进行分类或预测。核心目标是通过训练数据优化模型参数,使模型在未知数据上的泛化性能最大化。
机器学习按不同类型的分类
按学习方式分类
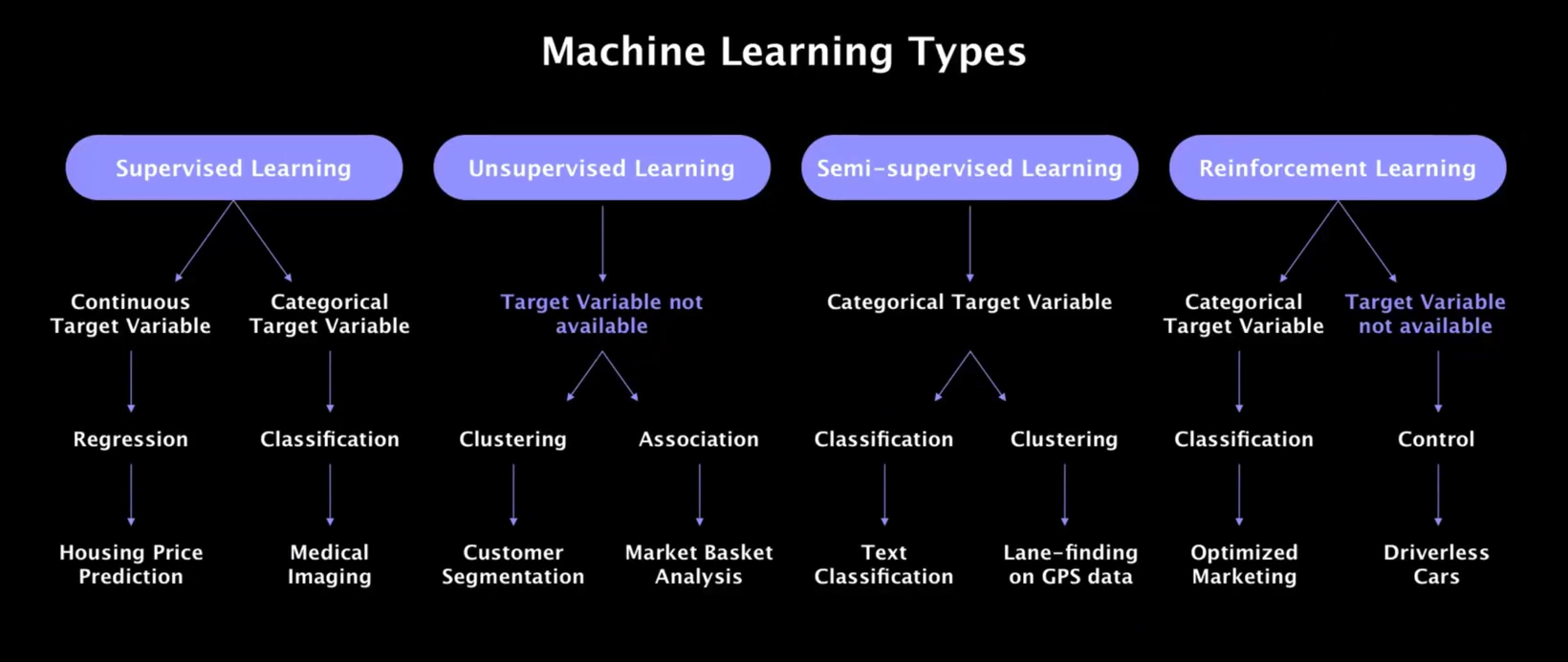
监督学习(Supervised Learning)
模型通过带有标签的训练数据进行学习,预测未知数据的标签。典型任务包括分类(如图像识别,因为目标变量是类别型的)和回归(如房价预测,因为目标变量是连续型的)。常见算法:线性回归、支持向量机(SVM)、决策树。
无监督学习(Unsupervised Learning)
模型从无标签数据中发现隐藏模式或结构。典型任务包括聚类(如客户分群)和降维(如PCA)。常见算法:K-means、层次聚类、主成分分析(PCA)。
半监督学习(Semi-supervised Learning)
结合少量标注数据和大量未标注数据进行训练,适用于标注成本高的场景。典型应用:医学图像分析。常见方法:自训练(Self-training)、生成对抗网络(GAN)。
强化学习(Reinforcement Learning)
通过与环境交互学习最优策略,以最大化累积奖励。典型应用:游戏AI(如AlphaGo)、自动驾驶。常见算法:Q-Learning、深度强化学习(DQN)。
按模型输出分类
分类(Classification)
输出离散类别标签,如垃圾邮件检测(二分类)、手写数字识别(多分类)。
回归(Regression)
输出连续数值,如股票价格预测、温度趋势分析。
聚类(Clustering)
输出数据分组,无预先定义的类别,如社交网络用户分群。
按模型结构分类
传统机器学习
依赖特征工程和浅层模型,如逻辑回归、随机森林。
深度学习(Deep Learning)
基于多层神经网络自动提取特征,适用于图像、语音等复杂数据。常见模型:卷积神经网络(CNN)、循环神经网络(RNN)。
按学习目标分类
生成模型(Generative Models)
学习数据分布以生成新样本,如GAN、变分自编码器(VAE)。
判别模型(Discriminative Models)
直接学习输入到输出的映射,如SVM、逻辑回归。
按应用场景分类
在线学习(Online Learning)
模型实时更新以适应动态数据流,如推荐系统。
批量学习(Batch Learning)
一次性使用全部数据训练,适用于静态数据集。
迁移学习(Transfer Learning)
利用预训练模型解决新任务,如BERT用于文本分类。
其他分类方式
集成学习(Ensemble Learning)
结合多个基模型提升性能,如随机森林、AdaBoost。
多任务学习(Multi-task Learning)
单个模型同时学习多个相关任务,如联合训练文本分类和情感分析。
元学习(Meta-Learning)
学习如何快速适应新任务,如小样本学习(Few-shot Learning)。
其实就主要关注下按学习方式的分类,其他了解一下即可。
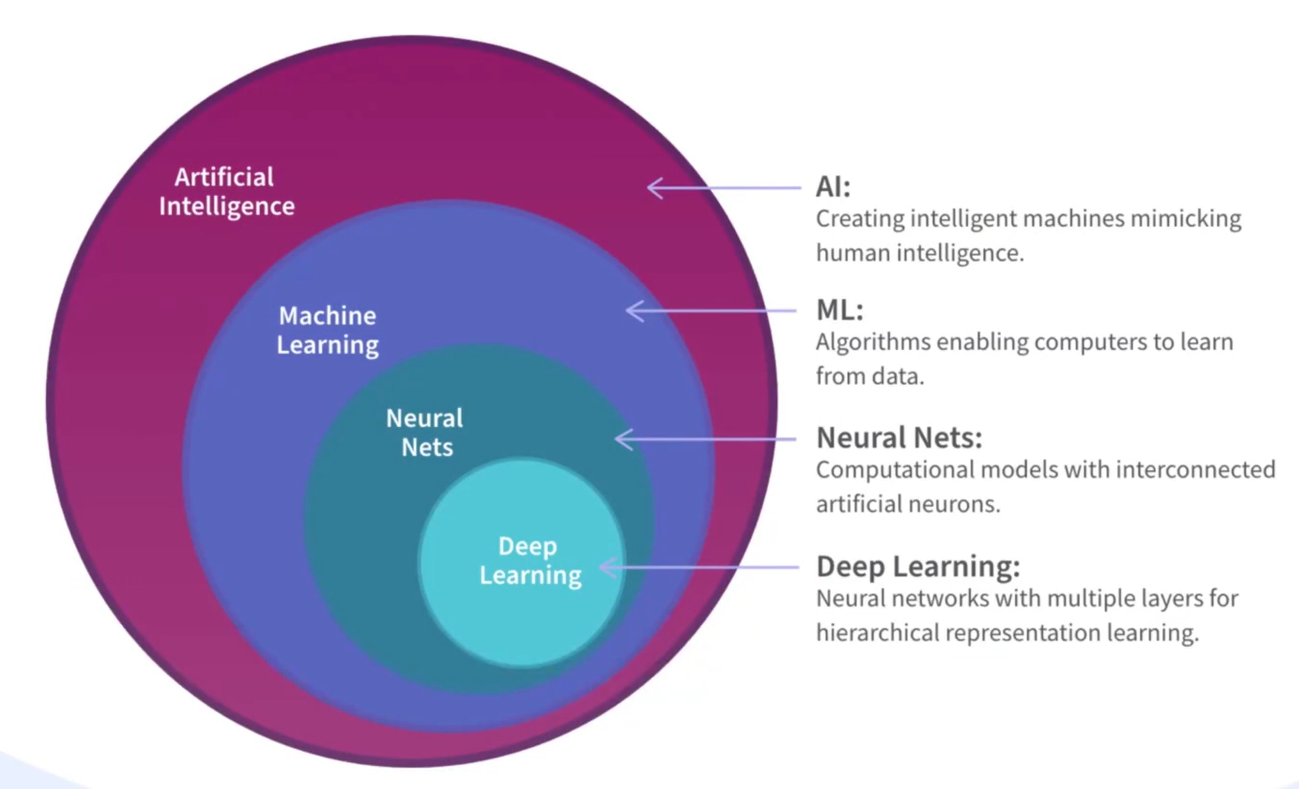
人工智能、机器学习、深度学习之间的关系是什么?
- 人工智能(AI)是让机器模拟人类智能的广泛领域,涵盖规则系统、统计方法等多种实现方式。
- 机器学习是 AI 的子领域,专注于通过数据训练模型自动发现规律,无需显式编程。
- 深度学习是机器学习的子领域,基于多层神经网络处理复杂任务(如图像、文本),是机器学习的一种实现方式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)