【SLIM】Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
目录
Background
当前主流skill方法分为两类:
| 范式 | 代表方法 | 行为 | 问题 |
|---|---|---|---|
| 持续积累 | SkillRL | 外部技能只增不减,越用越多 | 上下文过长、路由噪声增加、性能下降 |
| 逐步消除 | Skill0 | 技能逐渐内化到模型中,最终完全消除 | 强制零技能推断可能丢失有价值的外部支持 |
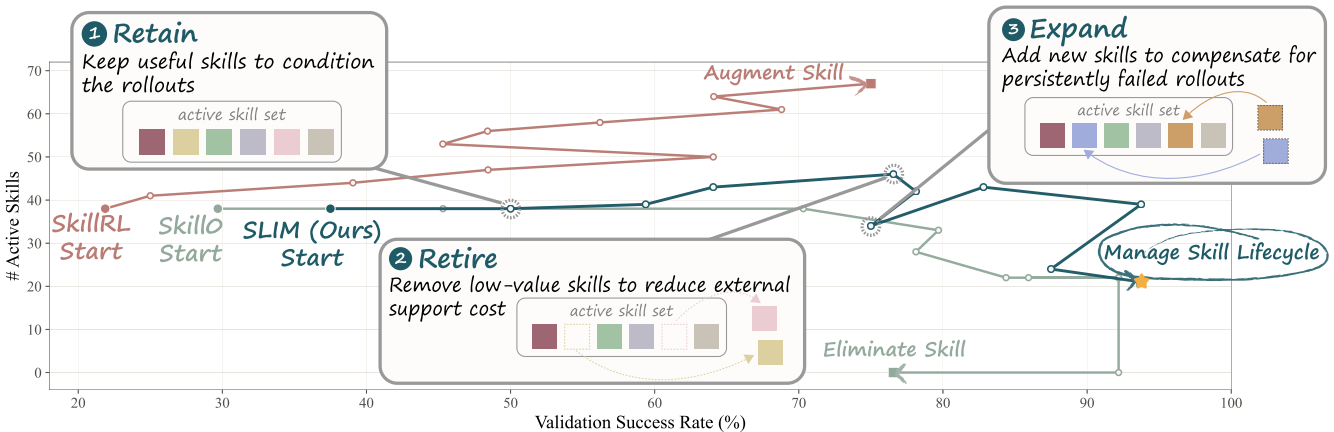
这两种做法都是单调的,忽略了技能价值随任务阶段变化、模型容量有限等现实约束。最优的活跃技能集应该是非单调的,即某些阶段需要某些技能,某些阶段则不再需要。
活跃的外部技能集应被视为一个动态优化变量,与策略学习共同更新。
Method
SLIM 不假设技能集单调增长或消失,而是通过训练过程中的周期性审计(audit),动态决定:
- 保留(retain):仍然提供边际价值的技能
- 淘汰(retire):不再有用的技能
- 扩展(expand):缺失必要能力时补充新技能
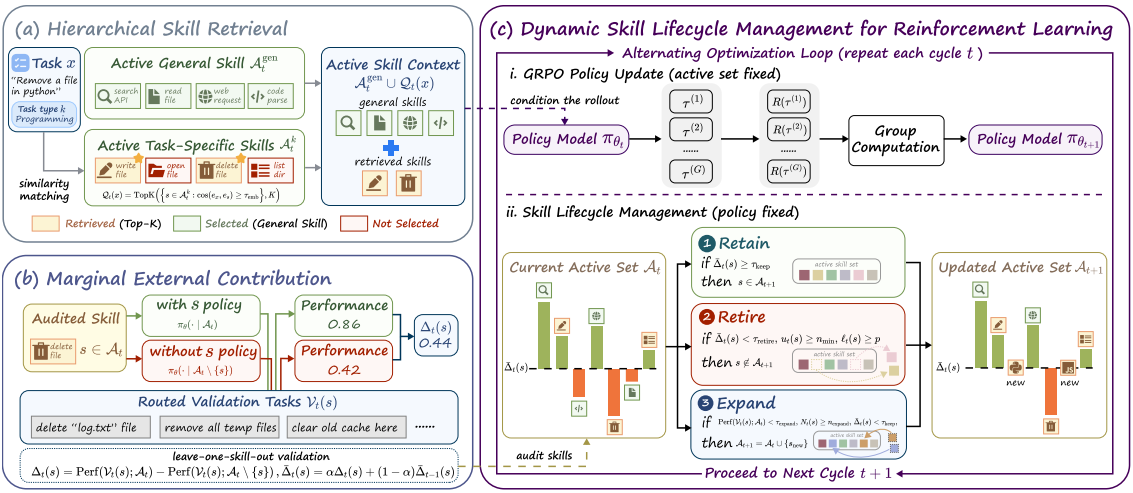
Hierarchical Skill Retrieval
- 活跃的通用技能 A t gen \mathcal{A}^\text{gen}_t Atgen全拿,任务特定技能从这一任务类别 k k k的skill集 S k \mathcal{S}_k Sk中、基于任务描述的相似度选择一个子集:
Q t ( x ) = TopK ( { s ∈ A t k : cos ( e x , e s ) ≥ τ e m b , K } ) \mathcal{Q}_t(x) = \text{TopK}(\{s ∈ \mathcal{A}^k_t : \cos(e_x, e_s) ≥ τ_{emb},K\}) Qt(x)=TopK({s∈Atk:cos(ex,es)≥τemb,K}) - 活跃的通用仅能和选择的任务特定技能用于这一任务 x x x的技能增强: π θ ( a t ∣ h t , A t gen ∪ Q t ( x ) ) π_θ(a_t | h_t, \mathcal{A}^\text{gen}_t ∪\mathcal{Q}_t(x)) πθ(at∣ht,Atgen∪Qt(x))
- 仅当技能与任务相关时,才可能对任务有用;但只是任务描述相似,并不能证明这一skill对实际任务是有贡献的。因此需要对活跃技能的边际贡献做明确的评估。
Marginal External Contribution Estimation
- 在训练过程中,SLIM定期执行audit。对用到活跃技能 s s s的验证任务子集 V t ( s ) \mathcal{V}_t(s) Vt(s),通过leave-one-skill-out validation计算其边际贡献;使用指数滑动平均平滑估计值,减少噪声。
Δ t ( s ) = Perf ( V t ( s ) ; A t ) − Perf ( V t ( s ) ; A t / { s } ) Δ ‾ t ( s ) = α ∆ t ( s ) + ( 1 − α ) Δ ‾ t − 1 ( s ) \Delta_t(s) = \text{Perf}(\mathcal{V}_t(s);\mathcal{A}_t) - \text{Perf}(\mathcal{V}_t(s);\mathcal{A}_t / \{s\}) \\ \overline{\Delta}_t(s) = α∆_t(s) + (1 − α) \overline{\Delta}_{t−1}(s) Δt(s)=Perf(Vt(s);At)−Perf(Vt(s);At/{s})Δt(s)=α∆t(s)+(1−α)Δt−1(s)
Dynamic Skill Lifecycle Management for RL
策略模型参数 θ \theta θ是一个连续的优化变量,需要用基于梯度的RL;而外部技能库 A \mathcal{A} A是一个离散集合,需要进行不可微的操作。因此对两者进行交替优化:
- GRPO policy update with the active set fixed
- skill lifecycle management with the policy fixed
| 操作 | 触发条件 | 含义 |
|---|---|---|
| 保留 | Δ ˉ t ( s ) ≥ τ keep \bar{\Delta}_t(s) \geq \tau_{\text{keep}} Δˉt(s)≥τkeep | 技能仍有明显正向边际价值,继续保留 |
| 淘汰 | Δ ˉ t ( s ) < τ retire \bar{\Delta}_t(s) < \tau_{\text{retire}} Δˉt(s)<τretire,且暴露次数足够、连续低贡献次数达标 | 技能已被内化或不再有用,移除 |
| 扩展 | 当前技能覆盖区域持续失败、性能低于阈值、且无技能可改进 | 创建新技能(通过LLM生成)补充缺失能力 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)