ASICers视角的内存系统:锁
ASICers视角的内存系统:锁
上篇在“原子性”中介绍到了锁,本篇主要总结下:锁的软硬件实现,以及现实应用中遇到的一些问题。
软件视角的锁
锁主要用于多线程编程中,对共享内存/外设空间的访问保护,避免破坏某一流程的“原子性”。更泛化的概念就不再展开了,我觉得AI在这一层面上会做得更好,可以用如下关键词做下检索、提问:
- 多线程编程什么场景需要用锁,为什么需要锁
- 什么是临界区
这里我们举个Spin-Lock的例子,来为后边展开做铺垫(更复杂的软件锁,如mutex,其对于硬件实现“锁”这个特性来说没有引入额外的需求,只是其需要OS的支持,这里不解释它了)。下面是个 Spin-Lock的c代码例子:
typedef volatile int spinlock_t;
void spin_lock(spinlock_t *lock) {
while (*lock) {} // 忙等待
*lock = 1;
}
void spin_unlock(spinlock_t *lock) {
*lock = 0;
}
上边例子中,上锁流程包括三步:
- 读 lock 值
- 判断 lock 是否为1(已被其他线程上锁)
- 写1,上锁
从上篇“原子性”的介绍来看,这三步在RISC下至少是3条汇编指令,没办法做到原子性,即:在多线程下,假如线程0和线程1都读到了lock=0,都去抢着写1,都写成功了,那两个线程都拿到了锁,业务上的功能就错掉了。
怎么解决上边的问题呢?结论是:只依赖软件,肯定解决不了…那软硬件配合的话,操作就太多了:
- 方法一:定义新的 Exclusive 汇编指令,上述抢锁的每一条指令都有个返回值,来辅助软件判断是否抢锁成功。同时,硬件上做 Exclusive Monitor。
- 方法二:将上述抢锁过程,打包成一条汇编原子指令,硬件上要支持特定的Atomic运算。
软硬件配合实现“锁”
现代CPU平台,往往同时支持上述两种方法,我理解主要原因还是为了兼容老代码,方法一是最原始的解决方案,硬件代价不大;随着工艺制程的演进、设计水平的提高,方法二的代价和复杂度也不再是难以接受。
利用Monitor实现锁
先看方法一,其在ARM平台下,对应的汇编实现如下:
typedef volatile int spinlock_t;
void spin_lock(spinlock_t *lock) {
int tmp;
do {
asm volatile (
"ldrex %0, [%1]\n" // 独占读 lock → tmp
"cmp %0, #0\n" // 是否为 0
"strexeq %0, %2, [%1]\n" // 如果是 0,尝试写 1
: "=&r" (tmp)
: "r" (lock), "r" (1)
: "memory"
);
} while (tmp != 0); // 失败则重试
}
void spin_unlock(spinlock_t *lock) {
asm volatile (
"str %1, [%0]\n" // 写 0
"dmb\n" // 数据内存屏障
: : "r" (lock), "r" (0)
: "memory"
);
}
两条操作锁“lock”的汇编指令,分别是:
- ldrex
- strex
这两条指令均会有返回值,对应到代码中,就是 temp 变量。回到刚才会出问题的那个例子,线程0和1都读到了锁为0,同时发出strex上锁操作,假如线程1先写成功,则Exclusive Monitor会返回0,表示线程1抢锁成功;线程0的strex到达Exclusive Monitor时,会返回1,表示线程0抢锁失败,其继续进入自旋状态。这一过程如下图所示:
线程1抢到锁后,完成受保护操作后,则会通过str操作,对lock写0释放锁。然后线程0会抢到锁。
在RISC-V平台下,也有与之对应的指令,分别是:
- load-reserved
- store-conditional
原理一样,不再赘述。
除了上述Exclusive load/store指令外,为了降低核在自旋时的功耗,ARM还定义了WFE和SEV指令。具体含义可以去搜一下。
Monitor在硬件实现中,主要有以下特性需要关注:
- local monitor & global monitor
上图中的例子是一个 global monitor,挂在内存入口上,带有Exclusive属性的总线访问,会触发其内部的记录状态机。
local monitor 是分布式的,每个核可能都有一个,或者每几个核有一个,是硬件实现自定义的,主要是配合Cache,实现Exclusive功能。这个在讲Cache一致性时,可以讲一下。
两种monitor,可以都有,也可以只有global monitor,看应用场景以及性能需求。核数很多,且要跑rish-os的话,只做一个定义在 Normal-uncachable 空间的global monitor显然无法满足通用灵活性和性能的需求;但对于嵌入式系统来说,足够了。
- 硬件Monitor的规格:其需要记录的最大条目,对应系统中最大的硬线程数量,每个条目主要记录:地址、线程ID、状态;
扩展思考:如果跑了多核OS,Core0上跑的进程0在抢锁等待中被OS挂起,之后OS调度进程1到Core0上,进程1也要抢锁,那monitor的规格是否够? – 答案:够,不影响锁的功能正确性,可以思考下
- 是否要支持 WFE 低功耗特性,做多核 Event 网络。
- 在一致性系统上,做 local-monitor 时,避免系统“活锁”,浪费带宽。TODO:这个在讲Cache一致性时,可以讲一下。
无论硬件怎样做,要让系统整体性能更优的话,软件应该做到的基本原则是:让临界区尽可能的短小,将不需要保护的资源,放在锁外。
利用原子加速器实现锁
回到上文介绍的方法二,将整个抢锁的过程,直接用一条原子指令实现。在现代CPU上,无论是从指令集还是硬件实现上,都做了支持。比如:AMBA总线AXI5就支持了Atomic的传递,CHI更是原生支持Atomic操作。
还以 ARM 举例,其定义了如下原子指令:
| 我想要… | 用这条指令 | 示例 |
|---|---|---|
| 比较并交换 | CAS |
CAS x0, x1, [x2] |
| 交换两值 | SWP |
SWP x0, x1, [x2] |
| 原子加(返回原值) | LDADD |
LDADD x0, x1, [x2] |
| 原子加(不返回) | STADD |
STADD x1, [x2] |
| 原子位与清零 | LDCLR |
LDCLR x0, x1, [x2] |
| 原子位或设置 | LDSET |
LDSET x0, x1, [x2] |
| 原子异或 | LDEOR |
LDEOR x0, x1, [x2] |
| 原子取最大值 | LDSMAX |
LDSMAX x0, x1, [x2] |
| 原子取最小值 | LDSMIN |
LDSMIN x0, x1, [x2] |
在原子指令加持下,抢锁的软件实现直接可以用一条CAS实现,如果锁为0,则上锁,否则返回原值。
在硬件实现上,原子操作可以实现在如下两个位置: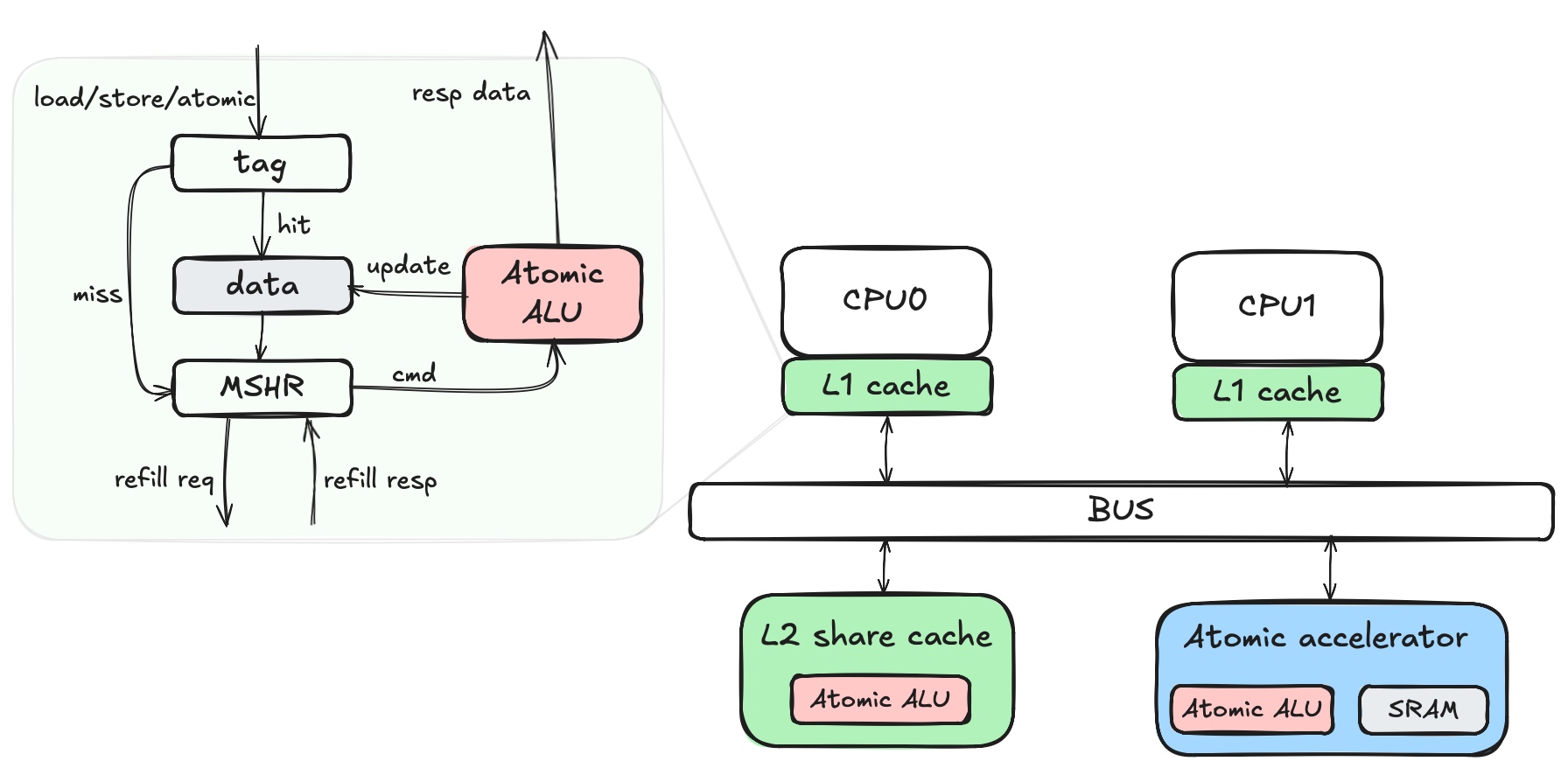
- 上图中,绿色背景,原子操作涉及的读改写,做在了Cache的数据通路里。在层次化的Cache一致性系统里,原子操作还会涉及要拿写权限(Rd_Unique),以及原子操作在哪里做的问题。
- near atomic:在本地L1 cache里做
- far atomic:在远端POC Home点,上图例子是共享的L2 cache
- 实现上策略是比较灵活的,比如:可以为了减小复杂度,固定在Home节点做;也可以为了性能,根据在L1的coherence state决定,如果hit E,则在L1做atomic operation;
- 层次化的Cache一致性系统,硬件实现复杂度/代价很高,一般就跑Rish-OS的AP系统才会做,在各种垂域的DSA应用中,都是偏定制化的业务,大家没人愿意付出代价搞这个,后边有时间了可以写写…
- 上图中,蓝色背景,定义在normal-noncacheable空间的原子加速器,只需要一个 Atomic ALU和一块SRAM就可以实现所有功能,实现代价很小。缺点嘛,就是原子变量只能定义在这个空间,而且访问延时相比L1 cache要长,差一个数量级:2cycles vs 20cycles。
总结
以上,应该算是讲清了:怎样的软件需求驱动了硬件去实现”锁“,以及硬件做了哪些设计来使能了“锁”的特性,以及不同的“锁”实现对应的性能和代价。
还要再提:锁为多线程编程,提供了保证功能正确性的基本工具。但是在追求性能,以及业务极致表现的场景下,比如现在很火的AI infra,要更近一步:避免使用锁,下次可以讲一些,硬件还可以做哪些工作,来为多线程编程或者同步,提供一种“无锁”编程模型。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)