全面超越11种主流方法:这个拓扑工具重新定义了细胞轨迹推断
论文信息
标题:Detecting and quantifying overparametrization in RNA language models with REDIAL
全面超越11种主流方法:这个拓扑工具重新定义了细胞轨迹推断
一句话速览: 该研究提出了一种基于零样本、无监督框架 REDIAL 的 RNA 语言模型评估方法,首次发现当前 RNA 语言模型存在严重的过参数化和记忆化问题。通过提取共进化信号,研究不仅揭示了模型架构设计缺陷,还证实结构化引导训练能显著提升信噪比,为开发更高效的 RNA 基础模型提供了关键诊断工具。
当模型“作弊”:下游任务高分背后的危机
想象一下,你花重金雇佣了一位“天才”员工,他的所有考核成绩都接近满分。直到有一天,你交给他一个从未见过的新任务,他却完全不知所措——原来他之前的所有成功,都只是靠死记硬背了标准答案。
这就是当前 RNA 语言模型领域面临的真实困境。过去几年,各种 RNA 语言模型层出不穷,它们被宣传为“RNA 界的 AlphaFold”,宣称能精准预测 RNA 结构。但马里兰大学的研究团队发现了一个令人不安的事实:许多 RNA 语言模型在下游任务中的优异表现,并非源于真正学会了 RNA 的折叠规律,而是靠“记忆”训练数据中的结构答案。
更直接地说:这些模型在“作弊”。
被隐藏的痛点:RNA 语言模型的“暗箱”困局
在生物信息学领域,蛋白质语言模型已经取得了巨大成功。ESMFold 等模型能够像人类理解语言一样理解蛋白质序列,从中提取“共进化信号”——即两个氨基酸残基在进化过程中同时发生突变的现象,这往往意味着它们在空间上相互靠近。
然而,RNA 领域的情况完全不同。首先,RNA 不会像蛋白质那样折叠成一个稳定的“原生态”,许多非编码 RNA 在构象景观中不断游走,这让共进化信号变得模糊不清。其次,RNA 的“词汇量”极小——只有 A、U、G、C 四种碱基,而蛋白质有 20 种氨基酸。这就好比用仅包含 4 个字母的语言去写一篇复杂的学术论文,表达效率极低。
更棘手的是,如何评估这些模型的质量?目前的主要方法是用监督式下游任务(如二级结构预测)来测试模型。但研究团队指出,这种方法存在根本性缺陷:模型可能只是记住了训练集中的结构,而不是真正理解序列与结构的关系。就像学生通过背诵答案通过考试,而不是真正掌握了解题方法。
REDIAL:给 RNA 语言模型做“核磁共振”
为了解决这个问题,研究团队提出了一个名为 REDIAL 的创新方法。这个名字来自“RNA Embedding perturbation Diagnostics for Language models”的缩写,但它的核心理念其实非常直观。
想象你有一个巨大的图书馆(语言模型),里面藏满了书籍(RNA 序列)。传统方法只检查图书馆的管理员能否回答具体问题(下游任务),但 REDIAL 采取了一种完全不同的策略:它直接测试图书馆的内部组织系统是否合理。
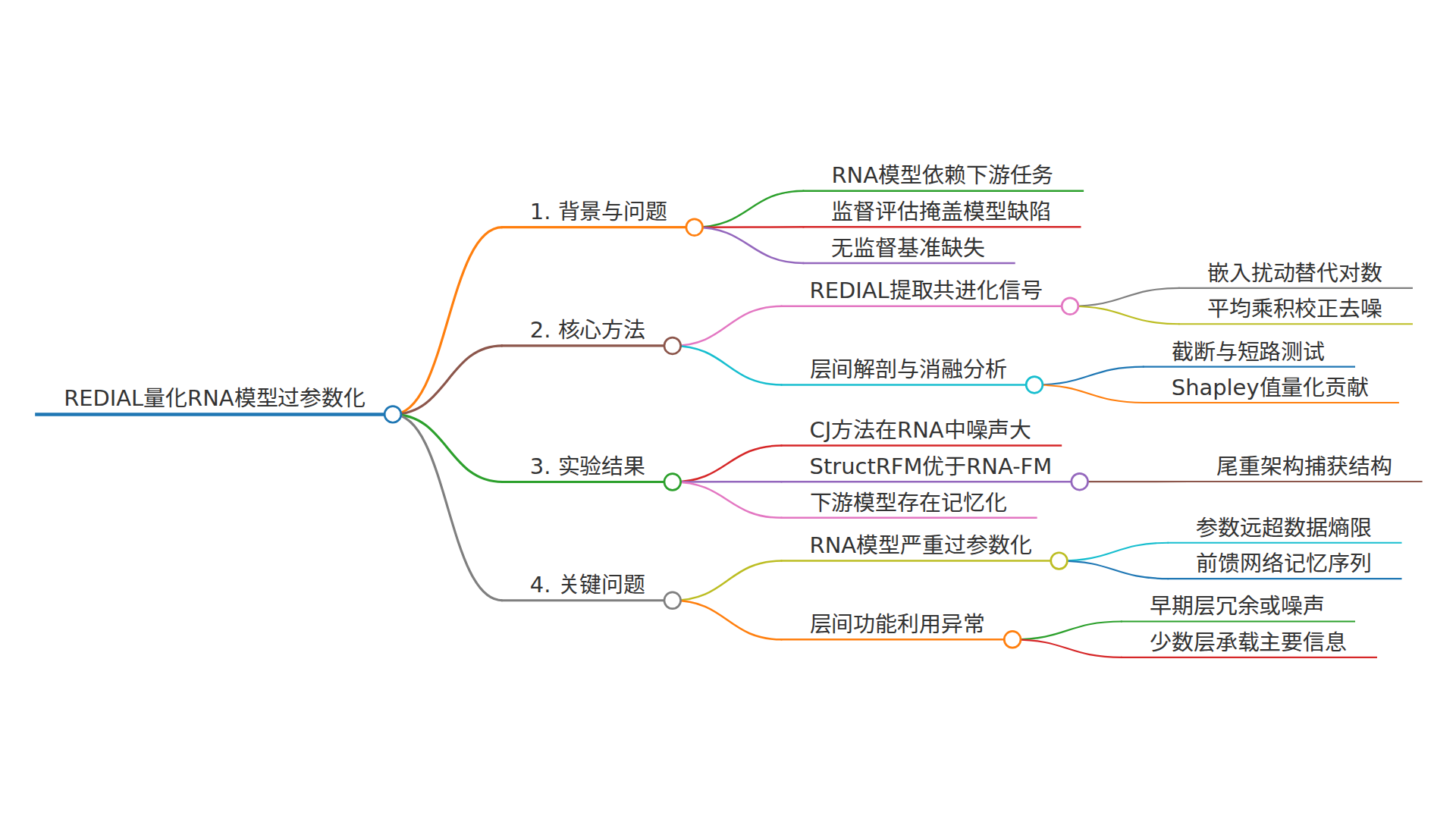
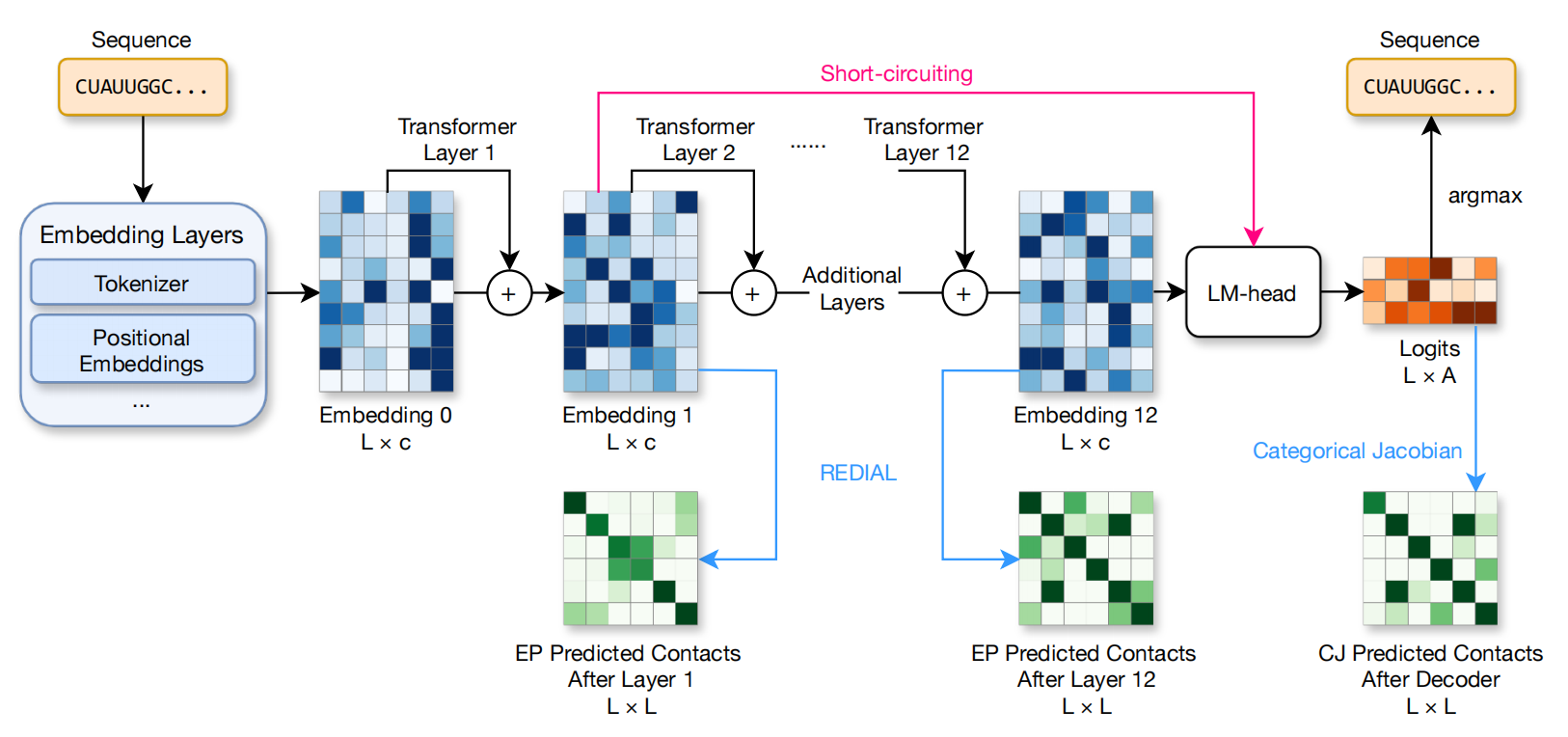
具体来说,REDIAL 的工作原理是这样的:当你对 RNA 序列中的某个碱基进行“虚拟突变”时,一个真正学懂 RNA 的语言模型会在其内部表示(embedding)中产生可预测的变化。如果这个碱基与另一个碱基存在相互作用(比如它们之间形成氢键),突变其中一个应该在另一个的位置上也产生信号响应。
与之前的方法相比,REDIAL 有两个关键优势:
-
零样本、无监督:不需要任何标注数据,直接评估模型学到的东西
-
高信噪比:由于监控的是高维嵌入空间(而不是低维输出层),信号不容易被噪声淹没
为了验证这个想法,研究团队首先用蛋白质语言模型 ESM-2 进行了概念验证。当他们突变一个关键残基 F30 时,系统不仅在局部二级结构位置(i±4)检测到了显著信号,还在序列上相距甚远但空间相邻的 L5 位置观测到了响应——这证明模型确实学到了三维结构约束。
颠覆性发现:模型在“作弊”,而非“学习”
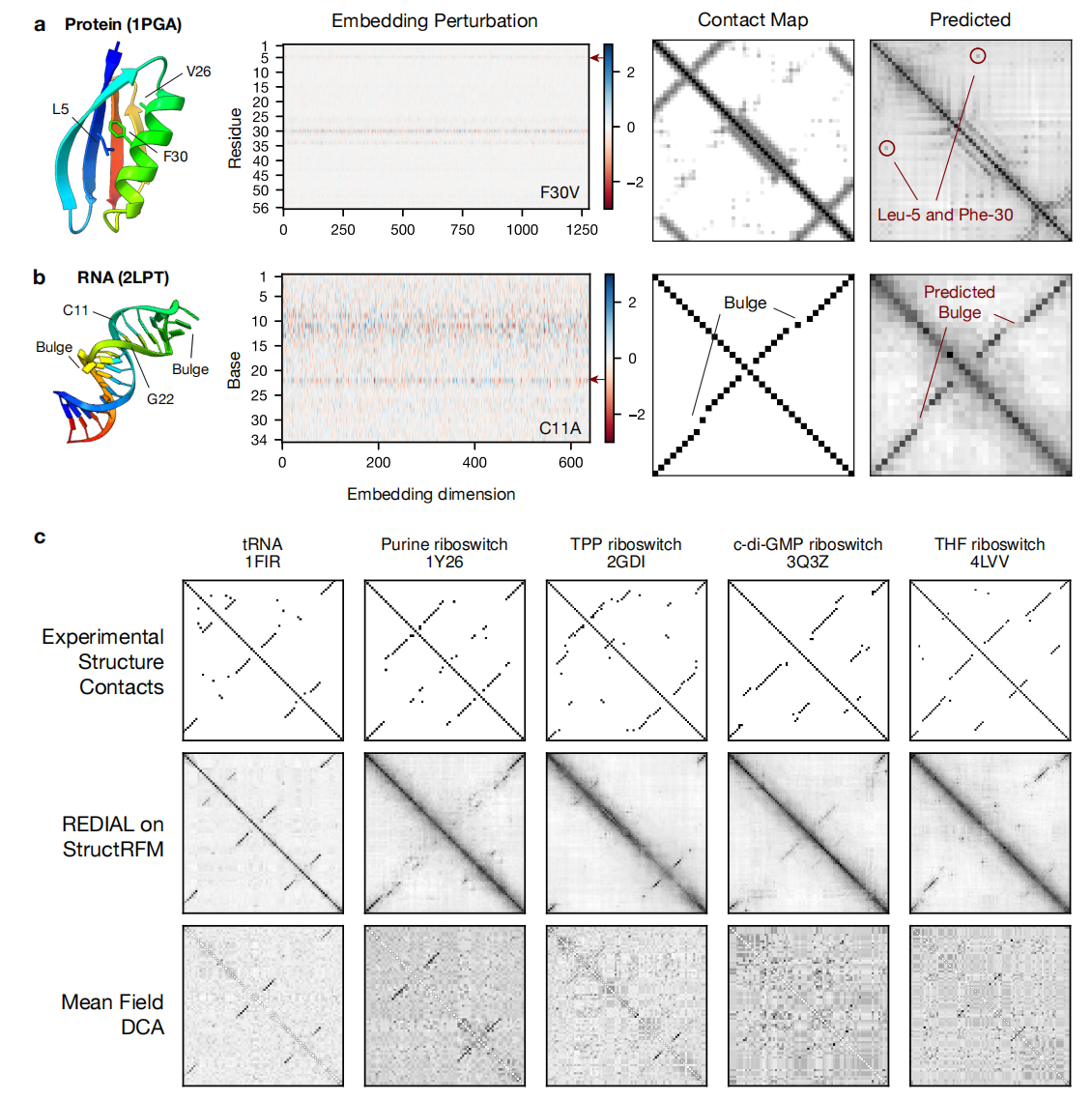
当研究团队用 REDIAL 检视当前最流行的两个 RNA 语言模型——RNA-FM 和 StructRFM——时,他们发现了令人震惊的结果。
案例一:HIV-1 TAR RNA
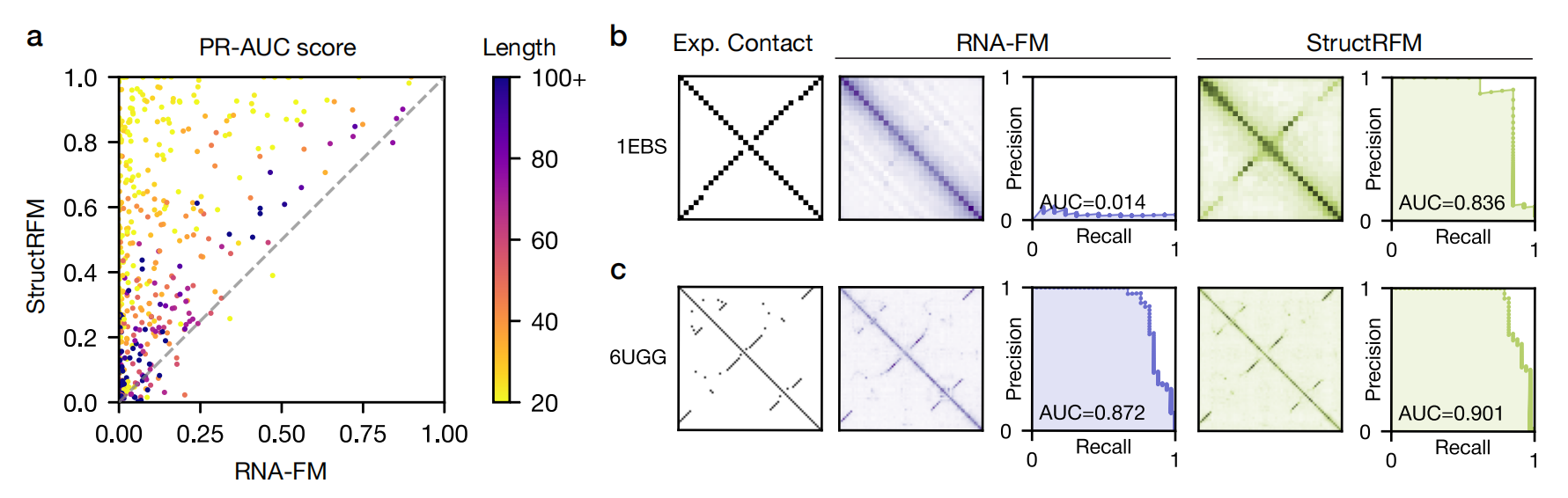
这个病毒 RNA 在结构数据库中拥有大量实验结构,但在进化数据库中几乎找不到同源序列。REDIAL 的分析显示,语言模型根本没有学到任何共进化信号。然而,基于 RNA-FM 的下游结构预测模型 RhoFold+ 却精准地预测出了正确结构。
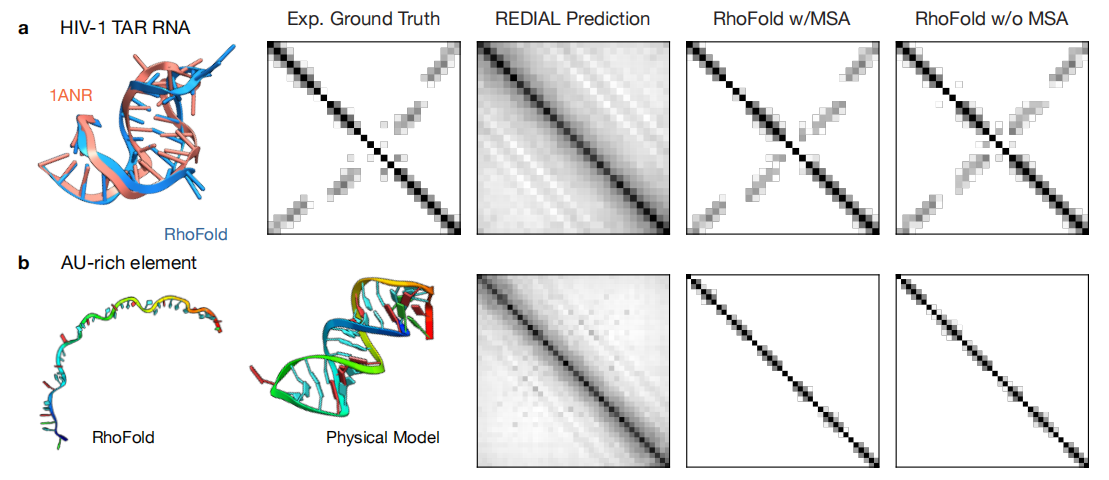
这意味着什么?研究团队设计了一个精妙的对照实验:他们测试了一个 AU 富集元件(ARE),这个 RNA 既在进化库中无同源序列,也不存在于结构训练集中。结果 RhoFold+ 预测出一个没有任何二级结构的线性聚合物——这完全违背了基本的生物化学原理,因为理论上这条序列中的腺嘌呤(A)和尿嘧啶(U)应该能形成碱基对。
而简单的物理模型(如 mFold)就能正确预测出该 RNA 的折叠结构。这个对比清楚地表明:RhoFold+ 在 HIV-1 TAR RNA 上的成功,纯属记忆训练数据的结果,而非真正理解了 RNA 折叠规则。
层间拆解:RNA 语言模型的“神经解剖学”
REDIAL 的另一个强大功能是它能逐层分析 Transformer 编码器的行为。这就像给模型做了一次“神经解剖”,看看信息在不同层面的流动情况。
研究团队针对两个模型进行了两种测试:
-
截断测试:从中间层提取嵌入,计算共进化图
-
短路测试:跳过某些层直接输入解码器,观察困惑度变化
结果令人大跌眼镜:
StructRFM 是“尾重”型:前 10 层几乎没学到任何共进化信号,几乎所有关键信息都集中在最后两层(L11 和 L12)。
RNA-FM 是“头重”型:前 6 层就完成了绝大部分工作,后面几层几乎成了“摆设”——它们的主要作用是过滤掉低频词汇(如稀有碱基符号),而不是提取更深的共进化特征。
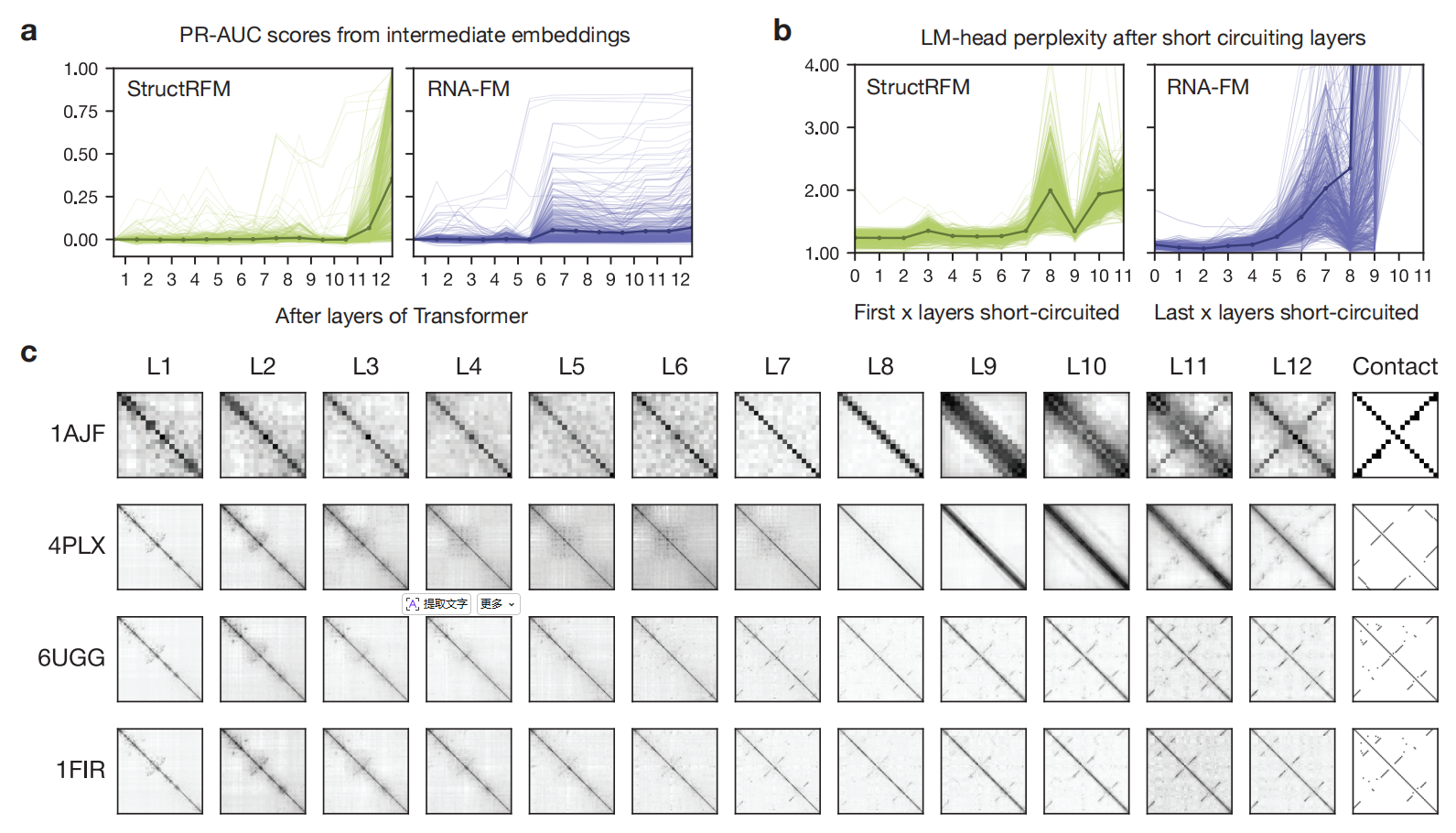
这种非理性的层利用模式,暗示着严重的架构冗余。
过参数化:RNA 语言模型的“肥胖症”
研究团队进一步进行了量化分析。当前 RNA 语言模型的参数规模令人瞠目:StructRFM 约 8600 万参数,RNA-FM 约 1 亿参数。但训练它们的数据集呢?RNAcentral 的 24.0 版本虽然包含大量序列,但有效信息量远低于模型容量。
做一个类比:假设你要记住一本只有 100 个有效单词的密码本,但你找了一个能背诵整本《大英百科全书》的人来干这个活。这个人的能力完全冗余,而且他很可能记下一些无关的噪声模式。
具体数字更有说服力:研究团队计算发现,学习 RNA 共进化关系所需的信息容量仅约 880 万比特,而 RNA-FM 的有效记忆容量高达约 3 亿比特——超出需求 30 多倍。
这种过参数化导致了灾难性后果:模型的前馈神经网络(FFN)充当了巨大的键值存储器,它们更倾向于直接记忆序列,而不是迫使自注意力机制去学习基础的进化耦合关系。这就像学生直接背诵考试答案,而不是理解背后的物理和化学原理。
结构化训练:破局的关键
面对这个困境,StructRFM 采用了一种更具洞察力的解决方案:结构引导的掩码语言模型(SgMLM)。
传统方法随机遮蔽序列中的碱基,让模型去预测。而 StructRFM 的改进很巧妙:如果随机选中的碱基已知参与某个碱基对,它会同时遮蔽其结构配对伙伴。这迫使模型不仅要理解单个碱基的统计规律,还要理解碱基之间的结构关系。
REDIAL 的评估结果证实了这一策略的有效性。在 533 个测试系统的对比中,StructRFM 在几乎所有序列上都优于 RNA-FM,尤其是在短序列上。对于长度 < 60 的 RNA,由于共进化信号原本就很弱,RNA-FM 几乎完全失败,而 StructRFM 却能准确预测出茎环结构和凸起导致的配对偏移。
意义与展望:从“堆参数”到“巧设计”
这项工作对整个 RNA 语言模型领域发出了重要的警示信号。
一方面,它揭示了盲目追求更大模型规模的陷阱。在蛋白质领域,ESM-2 从 8M 到 3B 参数的扩展带来了性能提升,但这得益于惊人的序列多样性(数十亿条序列)。RNA 领域的数据量远逊于此,无法享受这种“大力出奇迹”的福利。
另一方面,它强调了无监督评估的重要性。如果没有 REDIAL,研究者可能会继续认为 RhoFold+ 等模型表现良好,而忽视了它们在真正泛化能力上的致命缺陷。这种评估范式转变可能比任何单一模型的改进都更有价值。
对于 RNA 药物设计和全新 RNA 序列的设计,这项研究提供了一条明确的道路:更浅的 Transformer 堆栈、更小的词汇表、以及更多的训练轮次,或许比扩大参数规模更有效。结构化训练策略本质上是通过注入物理约束来增强有限的序列数据,这可能成为 RNA 领域的基础模型开发方向。
局限与未来方向
当然,REDIAL 也有其局限性。目前尚不清楚模型提取的信号究竟是真正的共进化信号,还是仅仅是二级结构模式识别。研究团队承认,对于长序列(>60 碱基),即使 StructRFM 的表现也不理想,说明挑战依然存在。
此外,REDIAL 的计算复杂度较高,需要对所有可能的单点突变进行扰动,这对于更大型的模型来说可能成为瓶颈。未来是否可以开发出更高效的近似算法,值得探索。
看着这些 RNA 语言模型在 REDIAL 的探照灯下暴露无遗,我们不禁要问:当模型越来越庞大,参数越来越冗余,我们投入的海量计算资源究竟是构建了真正的生物智能,还是仅仅制造了更精致的“记忆机器”?而当我们用下游任务分数衡量一切时,有多少“天才模型”其实只是替自己背下了答案的“作弊生”?
这个问题没有简单的答案,但 REDIAL 至少给了我们一面镜子——照一照,那些号称理解 RNA 的语言模型,究竟是真的看懂了生命密码,还是只是在算法世界里玩了一场精致的模仿游戏。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)