计算机视觉入门案例 高速公路车辆计数系统技术解析
本文用于计算机视觉小白的入门案例,本文使用的是预训练模型未经过微调和二次训练后续会更新二次训练教程
Github链接
https://github.com/ning696/highway-vehicle-counter
一、系统目标与技术边界
车辆计数系统不能简单等同于车辆检测系统。目标检测模型只能回答“当前帧中有哪些车辆目标”,但计数系统还需要解决连续视频中的时序一致性和业务判定问题。
本项目实际处理的问题可以拆成三层:
- 目标检测:识别视频帧中的车辆目标。
- 多目标跟踪:判断连续帧中的检测框是否属于同一辆车。
- 业务计数:判断车辆轨迹是否在 ROI 内按指定方向穿过计数线。
第一阶段的系统边界如下:
- 输入源限定为本地视频文件或视频目录。
- 场景限定为固定机位高速公路画面。
- 业务范围限定为左侧指定道路车辆总数统计。
- 检测类别限定为
car、truck、bus。 - 模型使用
RF-DETR通用预训练权重,不进行训练或微调。 - 输出为标注视频和
summary.csv,不接入数据库或实时流服务。
这种边界设计的价值在于:先验证“检测 + 跟踪 + 计数规则”的闭环,再考虑分车型统计、模型微调、实时流接入和部署加速。
二、整体架构与数据流
系统采用离线视频处理架构。核心流程如下:
各层职责如下:
| 层级 | 关键技术 | 职责 |
|---|---|---|
| 视频 I/O 层 | OpenCV |
视频读取、窗口显示、标注绘制、视频写出 |
| 模型推理层 | PyTorch、RF-DETR |
对每帧图像执行车辆目标检测 |
| 检测后处理层 | NumPy、COCO 类别映射 |
过滤非车辆类别,保留 car/truck/bus |
| 空间规则层 | ROI、多边形点包含判断 | 排除非左侧道路区域目标 |
| 跟踪层 | supervision、ByteTrack |
为连续帧车辆目标分配稳定 track_id |
| 计数层 | 计数线、方向约束、去重集合 | 对同一 track_id 只计数一次 |
| 导出层 | csv、pathlib、VideoWriter |
输出统计表和标注视频 |
系统设计的关键点是:检测结果不会直接累加为车辆数,而是先经过 ROI 过滤、轨迹关联和过线判定。这样可以避免同一辆车在多帧中被重复统计。
三、核心代码分析
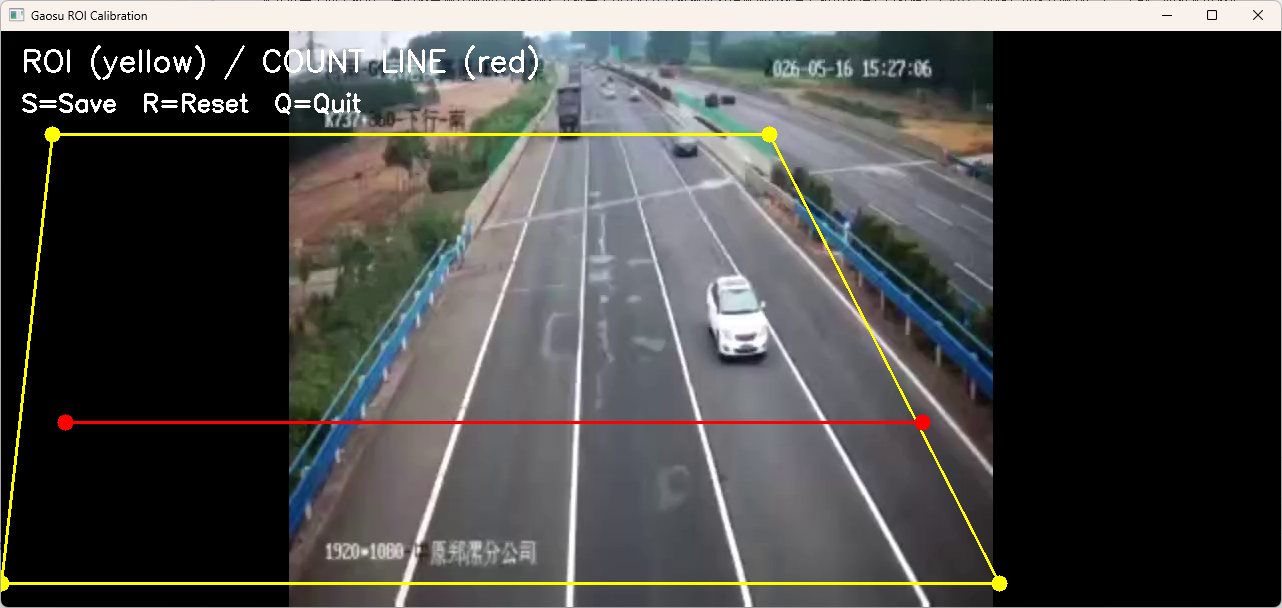
1. calibrate.py:交互式几何配置
calibrate.py 负责读取视频帧、显示校准窗口、响应鼠标拖拽并保存配置。
入口逻辑:
def main() -> None:
args = parse_args()
video_path = Path(args.input).expanduser()
frame = load_frame(video_path, args.frame_index)
frame_size = FrameSize(width=frame.shape[1], height=frame.shape[0])
config_path = resolve_config_path(args.config)
if config_path.exists():
config = scale_config(load_config(config_path), frame_size)
else:
config = default_config(frame_size)
editor = ConfigEditor(frame=frame, config=config)
saved = editor.run()
if saved is None:
print("Calibration cancelled. No config saved.")
return
save_config(saved, config_path)
技术要点:
load_frame()从视频中读取指定帧作为校准背景。FrameSize记录配置对应的视频尺寸。scale_config()支持已有配置在不同分辨率下缩放复用。ConfigEditor.run()负责窗口循环和键盘事件。save_config()将 ROI 和计数线持久化为 JSON。
绘制逻辑:
cv2.polylines(canvas, [roi_points], True, (0, 255, 255), 2)
cv2.line(canvas, line.start, line.end, (0, 0, 255), 2)
这里将 ROI 绘制为黄色闭合多边形,将计数线绘制为红色线段。
2. config.py:配置模型与分辨率缩放
核心配置结构:
@dataclass(frozen=True)
class CountConfig:
frame_size: FrameSize
roi_polygon: Polygon
count_line: CountLine
direction: Direction = "top_to_bottom"
vehicle_classes: list[str] = field(default_factory=lambda: ["car", "truck", "bus"])
model_size: ModelSize = "large"
detector_conf: float = 0.5
tracker_activation: float = 0.35
tracker_match_thresh: float = 0.8
lost_track_buffer: int = 30
minimum_consecutive_frames: int = 2
该结构把业务规则、模型参数和跟踪参数统一放入配置文件,避免硬编码。
分辨率缩放逻辑:
scale_x = target_size.width / config.frame_size.width
scale_y = target_size.height / config.frame_size.height
缩放能力的意义在于:ROI 和计数线可在不同输入分辨率下按比例映射,提高配置复用性。
3. detector.py:设备解析、模型加载与类别过滤
模型加载函数:
def build_model(model_size: ModelSize, requested_device: str = "cuda"):
from rfdetr import RFDETRLarge, RFDETRMedium
normalized = model_size.lower()
device = resolve_device(requested_device)
if normalized == "large":
return RFDETRLarge(device=device)
if normalized == "medium":
return RFDETRMedium(device=device)
raise ValueError(f"Unsupported model_size: {model_size}")
该函数将配置中的 model_size 映射到具体 RF-DETR 模型类,并将解析后的设备传给模型。
类别过滤函数:
def filter_detections_by_class(detections, allowed_ids: set[int]):
if len(detections) == 0:
return detections
mask = np.isin(detections.class_id, list(allowed_ids))
return detections[mask]
该函数基于 COCO 类别 ID 过滤检测结果,仅保留配置中的车辆类别。
4. count.py:视频处理主流水线
计数入口加载配置、输入视频和模型:
config = load_config(config_path)
videos = collect_video_files(input_path)
device = resolve_device(args.device)
model = build_model(config.model_size, requested_device=device)
单视频处理主循环:
while True:
success, frame = cap.read()
if not success:
break
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
detections = model.predict(rgb_frame, threshold=scaled_config.detector_conf)
detections = filter_detections_by_class(detections, set(allowed_ids.keys()))
detections = filter_detections_by_roi(detections, scaled_config)
tracked_detections = tracker.update_with_detections(detections)
该流程依次完成:
- 视频帧读取。
- OpenCV BGR 图像转 RGB。
- RF-DETR 推理。
- 车辆类别过滤。
- ROI 空间过滤。
- ByteTrack 轨迹更新。
计数更新逻辑:
point = bbox_bottom_center(xyxy)
history = update_track_history(track_histories, tracker_id, point, class_name)
if len(history.points) >= 2 and should_count_track(
track_id=tracker_id,
previous_point=history.points[-2],
current_point=history.points[-1],
counted_ids=counted_ids,
config=scaled_config,
):
counted_ids.add(tracker_id)
total_count += 1
关键设计:
- 使用检测框底边中心点代表车辆位置。
- 每个
track_id维护轨迹点历史。 - 通过
counted_ids保证同一轨迹只计一次。 - 只有前后两个轨迹点完成过线动作时才更新总数。
5. counting.py 与 geometry.py:业务计数规则
计数判定函数:
def should_count_track(
track_id: int,
previous_point: Point,
current_point: Point,
counted_ids: Set[int],
config: CountConfig,
) -> bool:
if track_id in counted_ids:
return False
if not point_in_polygon(previous_point, config.roi_polygon):
return False
if not point_in_polygon(current_point, config.roi_polygon):
return False
return crossed_line(previous_point, current_point, config.count_line, config.direction)
该函数组合了三类规则:
- 去重规则:已计数
track_id不重复计数。 - ROI 规则:前后点都必须位于有效区域内。
- 过线规则:轨迹从计数线一侧移动到另一侧,且方向符合配置。
检测框位置抽象:
def bbox_bottom_center(xyxy: Iterable[float]) -> Point:
x1, _, x2, y2 = xyxy
return int(round((x1 + x2) / 2.0)), int(round(y2))
底边中心点比矩形中心点更接近车辆与路面的接触位置,适合透视道路画面中的过线判断。
过线判断:
def crossed_line(previous: Point, current: Point, line: CountLine, direction: str) -> bool:
previous_side = line_side(previous, line)
current_side = line_side(current, line)
if direction == "top_to_bottom":
return previous_side < 0 <= current_side
raise ValueError(f"Unsupported direction: {direction}")
该逻辑通过点到有向线段两侧的符号变化判断穿越事件。
四、技术栈与选型分析
项目技术栈如下:
Python + uv + OpenCV + PyTorch + RF-DETR + supervision +
ByteTrack + NumPy + argparse/json/csv/pathlib
1. OpenCV
OpenCV 在项目中承担视频工程能力:
cv2.VideoCapture()读取输入视频。cv2.VideoWriter()写出标注视频。cv2.namedWindow()、cv2.imshow()、cv2.waitKey()支撑交互式校准。cv2.polylines()、cv2.line()、cv2.rectangle()绘制 ROI、计数线和检测框。
选型理由:
- 对视频文件、图像数组、窗口交互和基础绘制支持成熟。
- 与 NumPy 数组天然兼容。
- 适合承担模型推理以外的视觉工程逻辑。
2. supervision 与 ByteTrack
检测模型只能产生单帧检测框,不能天然判断“同一辆车”在不同帧中的身份。ByteTrack 用于把连续帧检测结果关联成轨迹,并生成 track_id。
选型理由:
- 计数系统必须依赖稳定 ID 做去重。
ByteTrack可直接与supervision的检测结构衔接。- 对第一阶段的总量计数来说,轨迹 ID 足以支持“同一辆车只计一次”的业务逻辑。
3. RF-DETR 与 YOLO 的选型取舍
YOLO 系列是非常成熟的实时目标检测路线,优势主要体现在推理速度、部署生态、工程资料和上手成本。对于边缘设备部署、极低延迟实时检测、摄像头流在线推理等场景,YOLO 通常是很有竞争力的选择。
本项目第一阶段选择 RF-DETR,不是因为 YOLO 不能完成车辆检测,而是因为当前目标更偏向“先建立可演进的检测 + 跟踪 + 计数规则闭环”。在这个目标下,RF-DETR 的优势主要体现在:
RF-DETR是实时检测 Transformer 架构,适合在保持实时检测能力的同时,为后续模型微调保留同一技术路线。- 当前项目规划包含后续高速公路场景微调,选择
RF-DETR可以在第一阶段先使用通用预训练模型跑通流程,后续再替换或微调同体系权重。 - 计数系统的主体难点不只是检测速度,而是 ROI、轨迹 ID、计数线和去重规则。先固定一个检测框架,有利于把工程重心放在计数闭环本身。
- 项目已经围绕
RF-DETR的 COCO 类别映射、model_size配置、CUDA 版 PyTorch 环境和rfdetr包完成工程集成,继续沿用可以减少模型切换带来的变量。
因此,这里的选择不是做模型绝对排名,而是说明 RF-DETR 更符合本项目当前阶段的连续演进目标。如果项目目标改为更强的边缘端部署、移动端推理、极低延迟实时流处理,YOLO 仍然是值得优先评估的方案。
参考资料:
五、环境配置与依赖管理
项目要求 Python 版本不低于 3.12。推荐在项目根目录创建本地虚拟环境:
cd F:\MyProject\shijua\main\gaosu
uv venv --python 3.12
uv sync
当前 pyproject.toml 的核心依赖如下:
[project]
requires-python = ">=3.12"
dependencies = [
"numpy>=2.0",
"opencv-python>=4.10",
"rfdetr>=1.5.0",
"supervision>=0.28.0",
"torch>=2.6.0",
"torchvision>=0.21.0",
]
其中 torch 和 torchvision 使用 PyTorch CUDA 12.8 wheel 源:
[tool.uv.sources]
torch = [
{ index = "pytorch-cu128", marker = "sys_platform == 'win32' or sys_platform == 'linux'" },
]
torchvision = [
{ index = "pytorch-cu128", marker = "sys_platform == 'win32' or sys_platform == 'linux'" },
]
[[tool.uv.index]]
name = "pytorch-cu128"
url = "https://download.pytorch.org/whl/cu128"
explicit = true
explicit = true 表示该索引只用于显式指定的包,普通依赖仍从默认 Python 包源解析。这可以避免把所有依赖都导向 PyTorch wheel 源。
六、我的踩坑过程与问题排查
本项目的主要问题集中在运行环境、推理设备、OpenCV GUI 和计数线位置四个方面。下面按“问题现象 -> 根因分析 -> 解决方法 -> 验证方式”的形式总结。
1. GPU 推理报错:PyTorch 实际安装成 CPU 版
问题现象:
项目初始阶段可以使用 CPU 跑通流程。将推理设备切换为 GPU 后,运行时出现:
CUDA GPU was requested, but PyTorch cannot use CUDA.
torch.cuda.is_available() is False
根因分析:
代码请求使用 cuda,但当前 Python 环境中的 PyTorch 不能访问 CUDA。常见原因包括:
- 当前安装的是 CPU 版 PyTorch。
- NVIDIA 驱动未安装或异常。
- PyTorch CUDA wheel 版本与当前显卡或驱动环境不匹配。
- 当前机器没有 NVIDIA GPU。
本项目中的实际原因是:初始依赖只声明了普通 torch,没有指定 PyTorch CUDA wheel 源,环境解析后安装到了 CPU 版 PyTorch。
排查命令:
.venv\Scripts\python.exe -c "import torch; print(torch.__version__); print(torch.version.cuda); print(torch.cuda.is_available())"
关键输出含义:
| 输出项 | 含义 | 异常信号 |
|---|---|---|
torch.__version__ |
PyTorch 版本 | 带 +cpu 通常表示 CPU 版 |
torch.version.cuda |
PyTorch wheel 绑定的 CUDA 运行时 | None 表示该 PyTorch 不含 CUDA |
torch.cuda.is_available() |
当前 Python 环境是否可用 CUDA | False 表示不能使用 GPU 推理 |
随后使用系统层面的 NVIDIA 工具查看显卡和驱动:
nvidia-smi
该命令可显示 GPU 型号、驱动版本、驱动支持的 CUDA 版本和当前显存占用。本项目排查时识别到的显卡为 RTX 5060 Ti。结合 PyTorch 官方安装页面和 uv 的 PyTorch 集成方式,最终选择 pytorch-cu128,即 CUDA 12.8 wheel 源。
需要注意:nvidia-smi 能证明系统层面存在 NVIDIA 驱动和显卡,但不能证明当前 Python 环境中的 PyTorch 已经支持 CUDA。最终仍要以 torch.cuda.is_available() 为准。
原始 pyproject.toml 只声明普通 torch:
[project]
name = "gaosu"
version = "0.1.0"
description = "Highway vehicle counting prototype powered by RF-DETR and ByteTrack."
requires-python = ">=3.12"
dependencies = [
"numpy>=2.0",
"opencv-python>=4.10",
"rfdetr>=1.5.0",
"supervision>=0.28.0",
"torch>=2.6.0",
]
[build-system]
requires = ["setuptools>=68", "wheel"]
build-backend = "setuptools.build_meta"
[tool.setuptools]
package-dir = {"" = "src"}
[tool.setuptools.packages.find]
where = ["src"]
修改后显式加入 torchvision 和 pytorch-cu128 源:
[project]
name = "gaosu"
version = "0.1.0"
description = "Highway vehicle counting prototype powered by RF-DETR and ByteTrack."
requires-python = ">=3.12"
dependencies = [
"numpy>=2.0",
"opencv-python>=4.10",
"rfdetr>=1.5.0",
"supervision>=0.28.0",
"torch>=2.6.0",
"torchvision>=0.21.0",
]
[tool.uv.sources]
torch = [
{ index = "pytorch-cu128", marker = "sys_platform == 'win32' or sys_platform == 'linux'" },
]
torchvision = [
{ index = "pytorch-cu128", marker = "sys_platform == 'win32' or sys_platform == 'linux'" },
]
[[tool.uv.index]]
name = "pytorch-cu128"
url = "https://download.pytorch.org/whl/cu128"
explicit = true
[build-system]
requires = ["setuptools>=68", "wheel"]
build-backend = "setuptools.build_meta"
[tool.setuptools]
package-dir = {"" = "src"}
[tool.setuptools.packages.find]
where = ["src"]
解决方法:
uv lock
uv sync
如果环境里已经装过 CPU 版 PyTorch,可先卸载再同步:
uv pip uninstall --python .venv\Scripts\python.exe torch torchvision
uv sync
验证方式:
.venv\Scripts\python.exe -c "import torch; print(torch.__version__); print(torch.version.cuda); print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'CPU only')"
预期状态:
torch.version.cuda不为None。torch.cuda.is_available()输出True。- 可以打印出 NVIDIA GPU 名称。
如果显卡不是 RTX 5060 Ti,不要机械套用 cu128。应先用 nvidia-smi 确认显卡和驱动,再到 PyTorch 官方安装页面选择当前推荐的 Compute Platform。如果官方推荐 cu126、cu130 或其他版本,就同步修改 uv 索引名称和 URL。
例如 CUDA 13.0 wheel 可配置为:
[tool.uv.sources]
torch = [
{ index = "pytorch-cu130", marker = "sys_platform == 'win32' or sys_platform == 'linux'" },
]
torchvision = [
{ index = "pytorch-cu130", marker = "sys_platform == 'win32' or sys_platform == 'linux'" },
]
[[tool.uv.index]]
name = "pytorch-cu130"
url = "https://download.pytorch.org/whl/cu130"
explicit = true
如果没有 NVIDIA GPU,只需要 CPU 验证流程,可以显式配置 CPU wheel 源:
[tool.uv.sources]
torch = [
{ index = "pytorch-cpu" },
]
torchvision = [
{ index = "pytorch-cpu" },
]
[[tool.uv.index]]
name = "pytorch-cpu"
url = "https://download.pytorch.org/whl/cpu"
explicit = true
环境判断原则:
nvidia-smi 确认系统显卡和驱动 -> PyTorch 官方页面确认 wheel 源 -> uv 配置 torch/torchvision 索引 -> torch.cuda.is_available() 验证 Python 环境
参考资料:
2. 校准窗口打不开:OpenCV 安装成 headless 版本
问题现象:
运行 ROI 校准工具时,OpenCV 无法创建窗口,出现类似错误:
The function is not implemented
cvNamedWindow
GUI: NONE
根因分析:
交互式 ROI 校准依赖 OpenCV GUI 能力:
cv2.namedWindow()cv2.imshow()cv2.waitKey()
如果环境中实际生效的是 opencv-python-headless,这些窗口能力不可用,校准工具无法弹出交互窗口。
检查命令:
.venv\Scripts\python.exe -c "import cv2; print(cv2.__version__); info=cv2.getBuildInformation(); print([line for line in info.splitlines() if 'GUI:' in line])"
解决方法:
uv pip uninstall --python .venv\Scripts\python.exe opencv-python-headless
uv pip uninstall --python .venv\Scripts\python.exe opencv-python
uv pip install --python .venv\Scripts\python.exe opencv-python==4.13.0.92
验证方式:
再次执行 GUI 检查命令。只要 GUI 项不再是 NONE,即可运行:
.venv\Scripts\python.exe -m gaosu.calibrate --input "视频\高速视频.mp4"
3. 计数线贴近 ROI 边缘:车辆通过但没有加数
问题现象:
在校准 ROI 和计数线时,如果将红色计数线放到非常靠近黄色 ROI 下边界的位置,会出现肉眼看到车辆通过红线,但程序没有加数的情况。
根因分析:
当前代码的计数条件比较严格:
- 车辆位置使用检测框的底部中心点,而不是整个车身区域。
- 检测结果先经过 ROI 过滤,底部中心点必须位于黄色 ROI 内。
- 计数时要求上一帧底部中心点在 ROI 内,当前帧底部中心点也在 ROI 内。
- 在前后两帧都位于 ROI 内的基础上,再判断轨迹是否从红线上方跨到红线下方。
相关代码链路:
count.py中先调用filter_detections_by_roi(detections, scaled_config)对检测结果做 ROI 过滤。count.py中通过bbox_bottom_center(xyxy)取车辆框底部中心点。counting.py中的should_count_track()要求previous_point和current_point都在 ROI 内。geometry.py中的crossed_line()负责判断前后两个点是否跨越计数线。
当红线位置合理时,红线下方仍然保留一段明显的黄色 ROI。车辆底部中心点穿过红线后,后续几帧仍然位于 ROI 内,程序可以稳定捕捉到:
上一帧:线前,ROI 内
当前帧:线后,ROI 内
这种情况下,should_count_track() 的 ROI 条件和过线条件都能满足,因此车辆会被计数。
错误示例:计数线过于靠近 ROI 下边界。
当红线靠后并接近黄色 ROI 下边界时,车辆底部中心点一旦越过红线,下一帧很可能已经离开黄色 ROI。程序看到的状态变成:
上一帧:线前,ROI 内
当前帧:线后,ROI 外
这种情况会被 should_count_track() 直接拒绝。也就是说,车辆虽然在视觉上穿过了红线,但由于当前点已经不在 ROI 内,系统不会把它计入总数。
还有一个边界细节:point_in_polygon() 对刚好落在多边形边界附近的点可能判定为不在 ROI 内。计数线越贴近黄色 ROI 边缘,底部中心点越容易在边界附近被过滤掉,漏计风险也越高。
优化示例:计数线下方保留足够 ROI 缓冲区。

解决方法:
- 不要把红色计数线放在黄色 ROI 的边缘附近。
- 红线下方建议至少保留一段明显的黄色 ROI 区域,例如
50-100像素,让车辆穿线后的底部中心点仍然有几帧停留在 ROI 内。 - 如果业务上必须把计数线放得很靠后,应同步将黄色 ROI 的下边界继续向下扩展,保证红线后方仍属于有效区域。
- 如果要从代码层面放宽条件,可以考虑计数时只要求
previous_point在 ROI 内,不强制current_point也在 ROI 内;但这种改动会增加 ROI 边缘误计风险,需要结合测试谨慎评估。
更稳妥的调参原则是:
计数线应放在车辆检测较稳定的位置,并且计数线后方必须保留足够的 ROI 缓冲区。
七、ROI 与计数线校准
在固定机位视频中,ROI 和计数线是业务规则的核心配置。ROI 用于限定左侧道路区域,计数线用于定义车辆通过事件。
运行校准工具:
.venv\Scripts\python.exe -m gaosu.calibrate --input "视频\高速视频.mp4"
交互窗口中的标注元素:
- 黄色多边形:ROI,限定有效检测区域。
- 红色线段:计数线,定义通过事件。
快捷键:
S:保存配置。R:重置配置。Q:退出不保存。
校准后生成 count_config.json:
{
"frame_size": {
"width": 1280,
"height": 576
},
"roi_polygon": [
[531, 85],
[663, 66],
[1055, 453],
[211, 574]
],
"count_line": {
"start": [309, 433],
"end": [947, 354]
},
"direction": "top_to_bottom",
"vehicle_classes": ["car", "truck", "bus"],
"model_size": "large",
"detector_conf": 0.5
}
calibrate 运行成功后截图位置:
八、运行命令与结果分析
校准完成后,使用以下命令执行计数:
.venv\Scripts\python.exe -m gaosu.count --input "视频\高速视频.mp4" --config "count_config.json" --device cuda
如需自动兼容无 GPU 环境:
.venv\Scripts\python.exe -m gaosu.count --input "视频\高速视频.mp4" --config "count_config.json" --device auto
如需强制 CPU:
.venv\Scripts\python.exe -m gaosu.count --input "视频\高速视频.mp4" --config "count_config.json" --device cpu
运行完成后生成:
outputs\<时间戳>\高速视频_annotated.mp4
outputs\<时间戳>\summary.csv
本次验证结果:
video_name,total_frames,total_count,avg_fps,output_path,config_path,model_size
高速视频.mp4,2863,65,21.52,outputs\20260517_151706\高速视频_annotated.mp4,F:\MyProject\shijua\main\gaosu\count_config.json,large
最终成功截图位置:
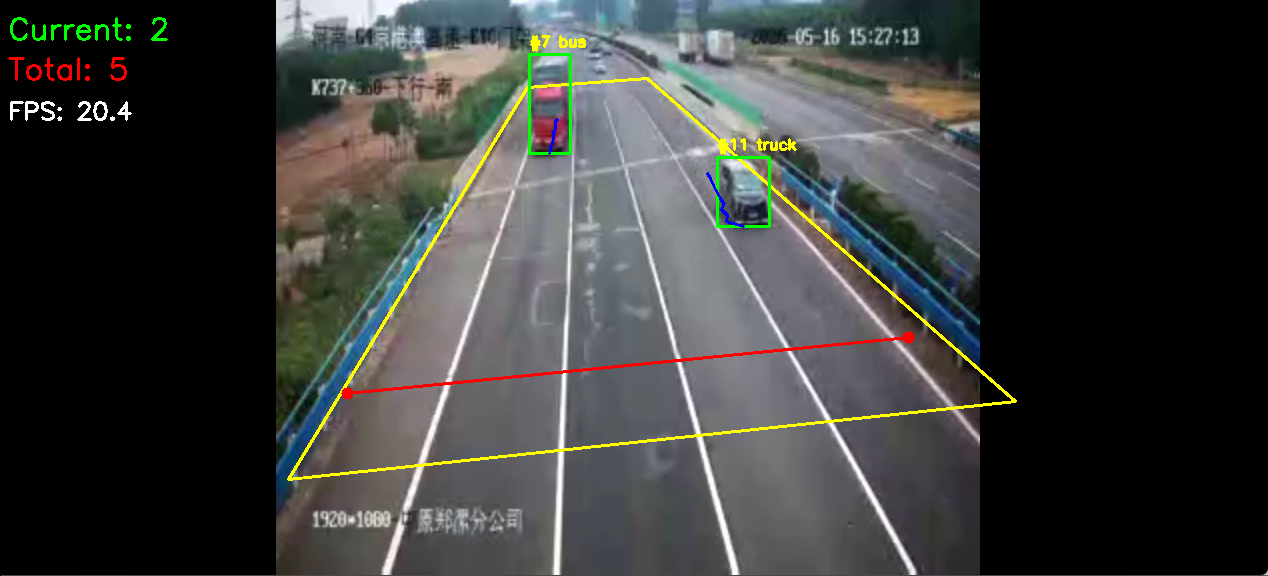
结果视频中应包含以下可视化元素:
- 黄色 ROI 多边形。
- 红色计数线。
- 绿色车辆检测框。
- 车辆
track_id和类别标签。 - 蓝色轨迹线。
- 左上角
Current、Total、FPS指标。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)