【领域驱动设计 打通DDD的最小闭环】二 模型的建立-领域建模
前面提到过,DDD的开发过程就是围绕业务领域进行的,是一种将现实世界中的业务运转过程映射到虚拟世界的方法。我们围绕这一描述再来拆解下DDD的开发过程:
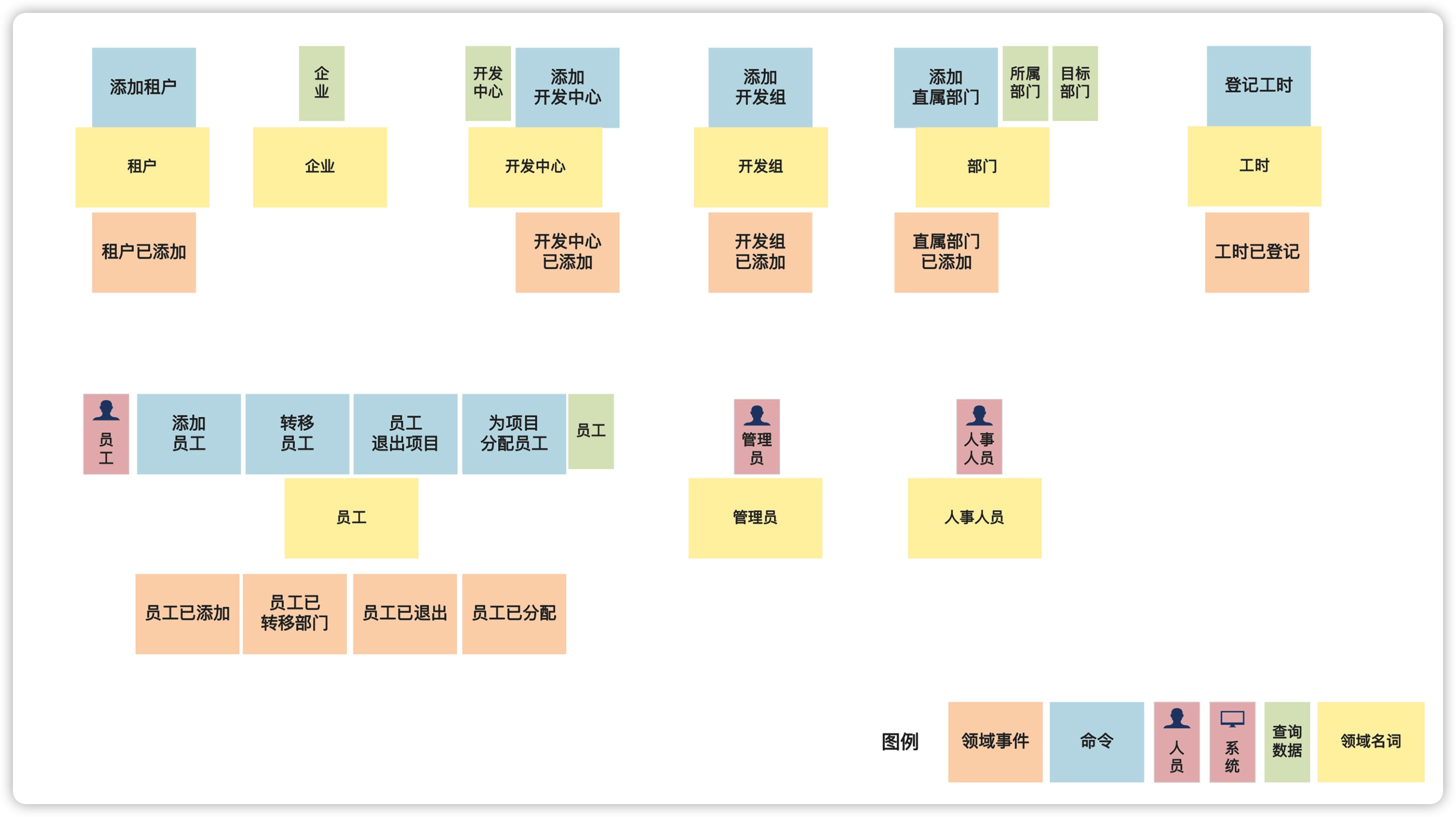
- 捕获行为需求:了解真实客观世界的业务运转过程。也就是业务是怎样运转的,事件风暴就怎样反映,最终产出领域名词。
- 领域建模:根据领域名词,提取实体概念和行为,通过抽象提取隐含实体概念和行为(目的是深入业务本质),最终形成领域模型。整个过程需要业务和技术共同协作,以保证领域模型和业务需求的一致性。
- 设计和实现:基于领域模型,进行架构设计、数据库设计和编码实现。要注意,领域模型中的每个元素,都应该在系统实现中有所体现。所以,如果领域模型中的某个元素不需要体现在实现中,就应该在领域模型里删除这个元素,以保证系统实现和领域模型的一致性。
最终保证系统实现和业务需求总是一致的,避免了系统实现和业务需求差距越来越大。
下面就介绍下如何基于事件风暴的产物领域名词进行领域建模。
领域建模的基本概念
建立领域模型,主要是要识别领域对象、领域对象的关键属性,以及领域对象之间的关系。
什么是领域对象呢?我们系统中要处理的各种“事物”就是领域对象。比如说项目、员工、账户等等。这些对象都反映了名词性的概念。
在DDD 中将领域对象分成实体(entity)和值对象(value object)。本文主要介绍实体,值对象会在后面的章节中介绍到。
什么是领域模型?
在讨论什么是领域模型之前,咱们先说说什么是模型。模型有以下几个特点:
- 首先,模型是以解决特定问题为目的的。例如沙盘模型是为了卖房,而建筑图纸是为了盖楼。没有目的就谈不上模型。
- 第二,模型都是对现实世界或人们思维中的事物进行的模拟。例如沙盘模型和建筑图纸都是对建筑物的模拟,而玩具车是对真车的模拟。
- 第三,模型总是提取了被模拟事物中的部分信息,而忽略掉了其他大部分信息。例如,沙盘模型提取了楼盘的外观信息,但是忽略了内部结构和建筑材料信息。而建筑图纸反映了内部结构信息,但忽略了外观信息。到底提取哪些信息,忽略哪些信息,取决于模型的目的。
- 第四,模型可以有多种表现形式,例如图纸、影像、公式以及电脑中的文件等等。具体采用哪种形式,取决于要解决的问题和当前的技术水平。
- 最后,模型是一种人造物,大自然本身是不存在模型的。
领域模型,就是解决特定业务领域的模型。
领域建模的关键
在介绍领域建模之前,要强调一点,DDD 强调领域模型要兼顾业务和技术两个视角。所以领域建模的整个过程都需要业务和技术共同参与,产出的领域模型必须由业务和技术双方达成一致。
- 业务人员的参与,能为领域模型带来专业的领域知识。
- 而技术人员可以为领域模型带来更高的抽象性和严谨性,同时可以选出更适合的模型。前面我们说过,模型是一种人造物,会带入主观因素。对于同一业务,可能会构建出不同形式的领域模型,这些模型可能都“对”,关键在于哪一个“更好”。这时候,技术人员从技术视角出发,往往可以发现,有些模型更容易进行技术实现。所以,尽管领域模型中都是业务概念,却可以通过技术视角选出更恰当的模型。
如何描述领域模型
在后面介绍领域建模的时候,会通过UML来描述领域模型。UML 是“统一建模语言”的意思,英文是 Unified Modeling Language,是面向对象建模的国际标准。其中,领域对象用下面这个符号来表示:
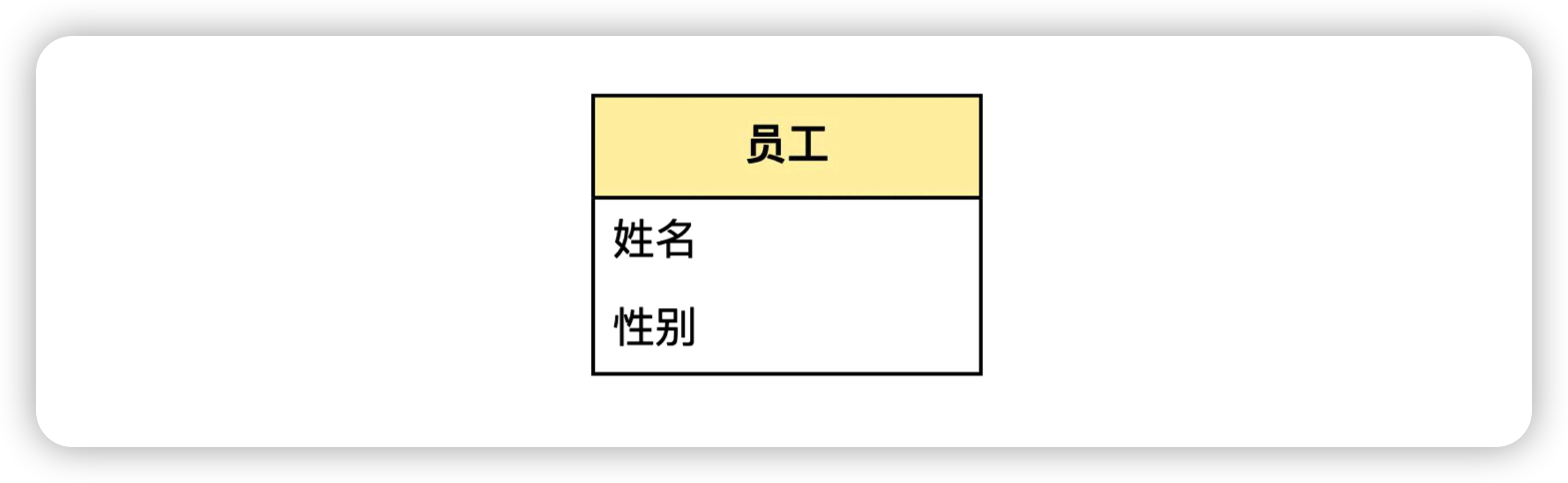
这个符号表示“员工”对象。其中第一栏是领域对象的名称,第二栏列出了对象的属性(attribute),姓名、性别都是员工的属性。
严格地说,在 UML 中,这个符号叫做“类”(class)。由类和类之间的关系组成的图叫做类图,这也是领域建模里用到的最主要的图。
UML类图的六种关系详见:https://blog.csdn.net/qq_45087487/article/details/134953881、https://www.cnblogs.com/hzxll/p/16195711.html
领域建模的过程
下面开始进行领域建模。
初步识别实体
我们可以从上文中识别的领域名词入手,分成几部分来建模。我们先考虑租户、组织和人员。上节课的图是这样的:
首先,我们先假定每个领域名词都是一个实体,把它们用类的符号画出来。如下图:
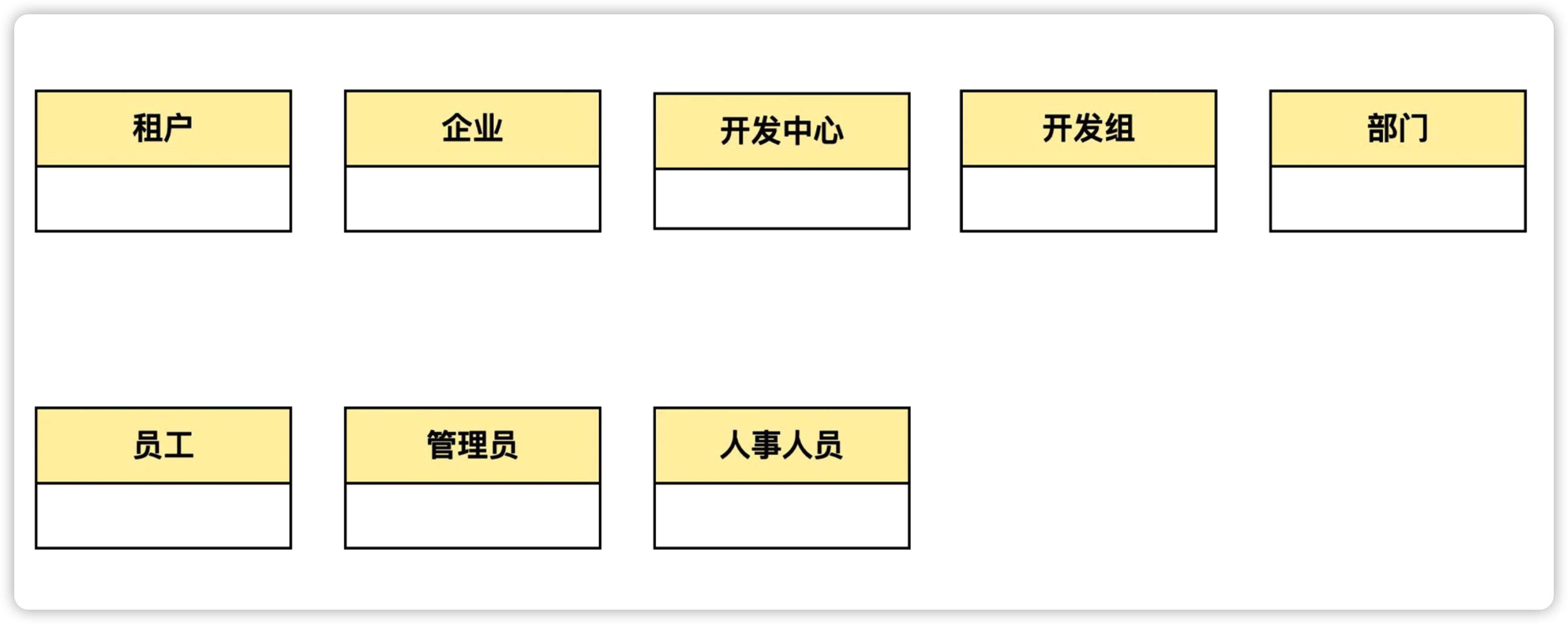
在领域建模阶段,我们主要关注的是实体和实体之间的关系,所以上图并没有写属性。
另外,这里只是简单粗暴地假定了领域名词就是实体。通过后面的分析会发现,有些名词不是实体,有些要转换成其他形式。
识别关联关系
现在我们来识别实体之间的关系。假设有 A 和 B 两类实体,可以通过几个问题把他们之间的关系搞清楚。
- 实体 A 和实体 B 有关系吗?
- 一个实体 A 最多可以对应多少个实体 B?
- 一个实体 A 最少可以对应多少个实体 B?
- 一个实体 B 最多可以对应多少个实体 A?
- 一个实体 B 最少可以对应多少个实体 A?
下面,我们以组织和员工为例实操一下。
- 组织和员工之间有关系吗? 有关系。可以在两个实体之间画一条线,表示它们之间有关系。
- 一个组织最多有多少个员工? 可以有很多个员工。于是在员工端写了“*”来表示。
- 一个组织可以没有任何员工吗? 业务上允许先建立一个组织,暂时不往里面分配任何员工。员工端变成了“0..*”。
- 一个员工最多属于多少个组织?一个员工最多属于一个组织。于是在组织那端写了“1”表示。
- 一个员工可以不属于任何组织吗? 一个员工必须属于一个组织,组织端变成了“1..1”。
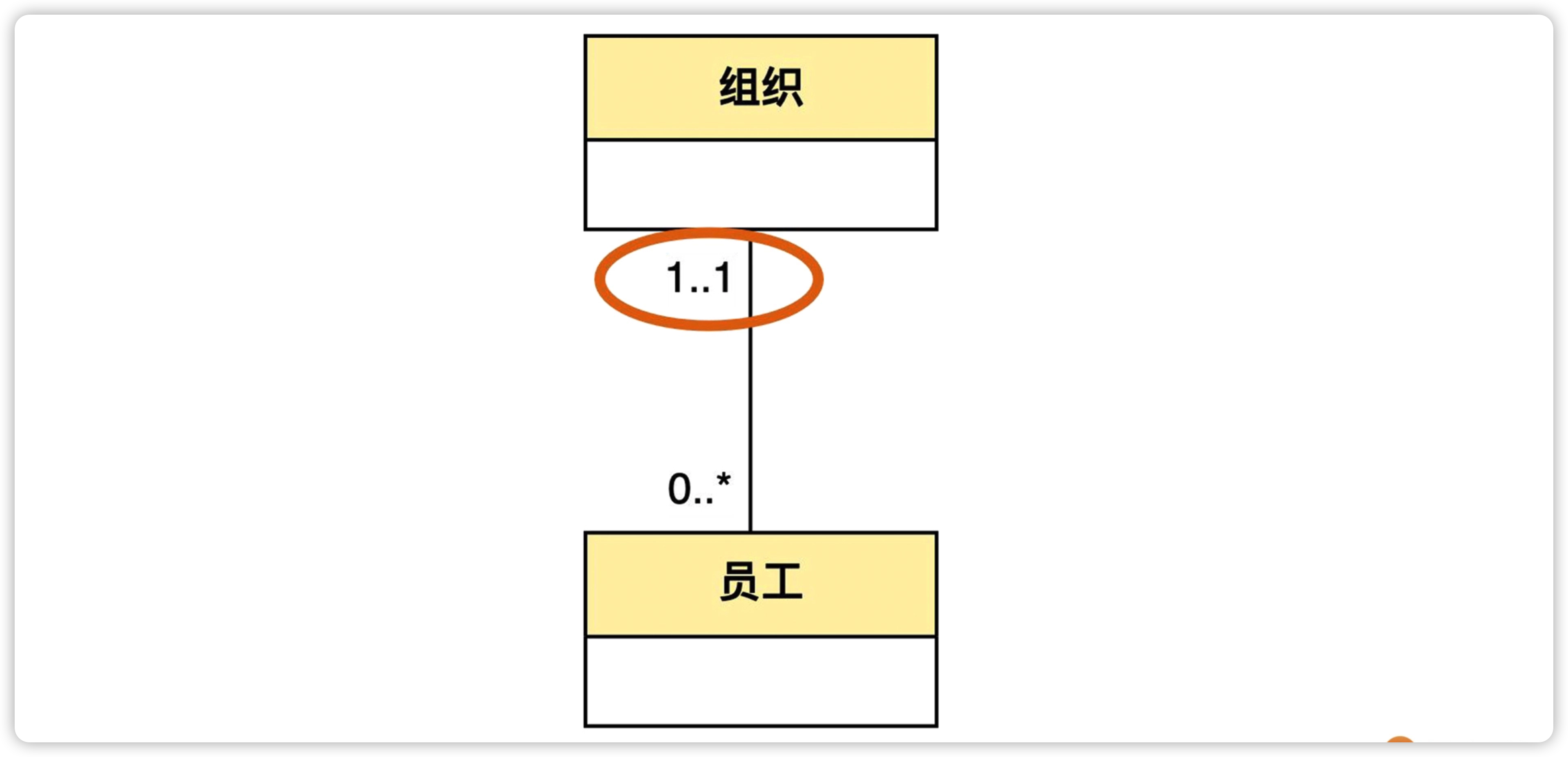
这里的两端的 “0..*” 和 “1..1”,在 UML 中称为多重性(multiplicity)。在实际项目中,团队可以自行决定,把多重性识别得粗一点,只写 “1”和 “*” ;还是细一点,识别出 “1..1” “0..*” 。一般来说,如果目的是在短时间内大致了解业务概念,就可以粗一点;如果是为了指导具体的开发,则可以做细一点。
上面组织和员工的这种关系,在 UML 的术语里叫做“关联”(association)。关联又分为:一对一关联、一对多关联、多对多关联。图中组织和员工就是一对多关联。
一对一关联
我们看下租户和企业之间的关系,这里我们把多重性识别的粗一点,只问三个问题:
- 租户和企业之间有关系吗? 有关系。
- 一个租户最多可以对应几个企业? 只能对应一个企业。
- 一个企业可以作为几个租户? 一个企业只能作为一个租户。

这样我们可以说,租户和企业是一对一关联。
一对多关联
我们再看下企业和开发中心的关联关系。
- 企业和开发中心之间有关系吗? 有关系。
- 一个企业可以有多少个开发中心? 可以有很多个。
- 一个开发中心可以属于多少个企业呢? 只能属于一个企业。
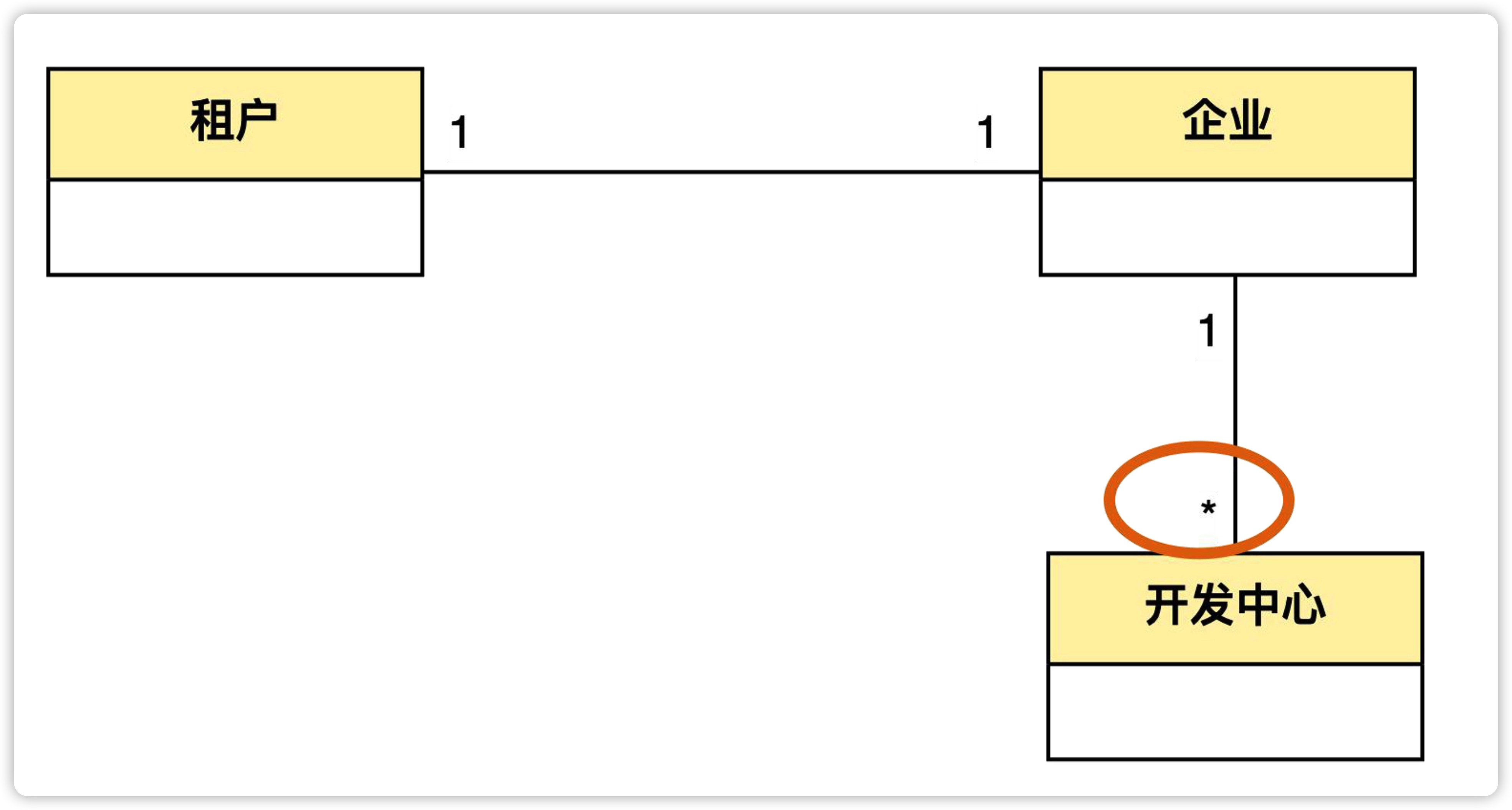
这时我们可以说,企业和开发中心具有一对多关联。
多对多关联
按照类图的产生顺序,这部分内容应该放在 识别自关联 和 识别操作 两小节之间,大家按照文章的顺序看会有点奇怪。这里是按照关联关系整体划分的一节。
下面我们看下管理员和人事人员之间的关系。
首先,按照 识别自关联 这一节后得到的图可以发现,图中已经有 员工 这个实体了,管理员和人事人员其实也是员工。后续可能会出现其他的员工类型,所以为了扩展性考虑,参照 进行抽象 这一节,我们要对这些实体概念 找出共性和差异化的地方。
- 共性很简单了,管理员、人事人员,甚至后续新增的其他员工类型 都是员工。
- 但是他们担任的岗位不同,也就是 管理员、人事人员 有不同的岗位。
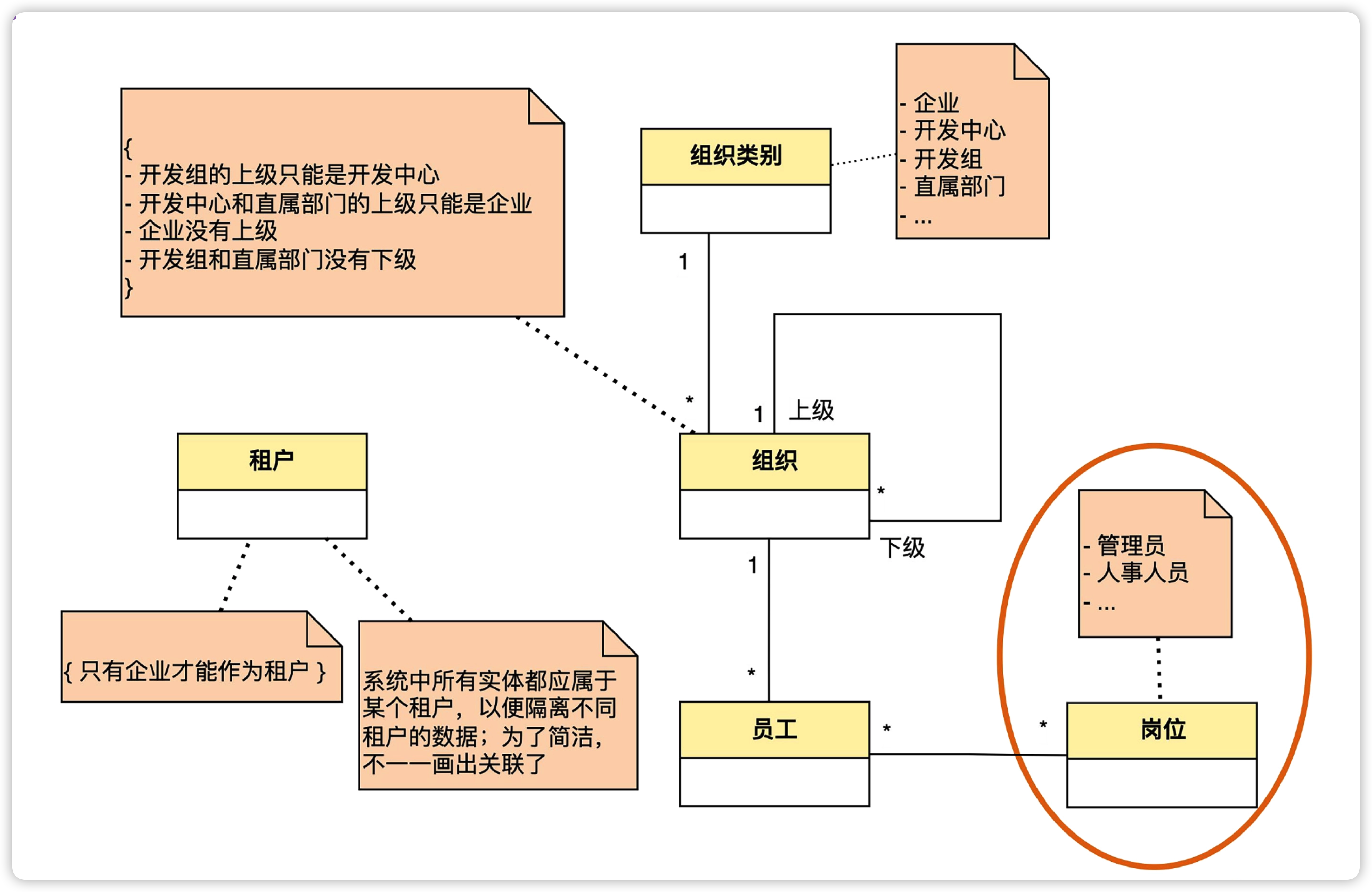
可以得到上图,图中表示一个员工可以担任多个岗位,而一个岗位也可以有多个员工担任。员工和岗位之间是“多对多”关联。
另外可以发现,图中还有很多折角的矩形
- 没有用大括号包含的叫做注释,和被注释的实体之间用虚线连接。
- 用大括号包含的叫做“约束”(constraint)。和一般性的注释不同,凡是约束,必须在程序中的某个地方进行实现。
因为注释和约束对于领域建模本身来说过于细节,属于后续模型的实现需要重点关注的内容,这里就不详细介绍了。
多对多关联的拆分
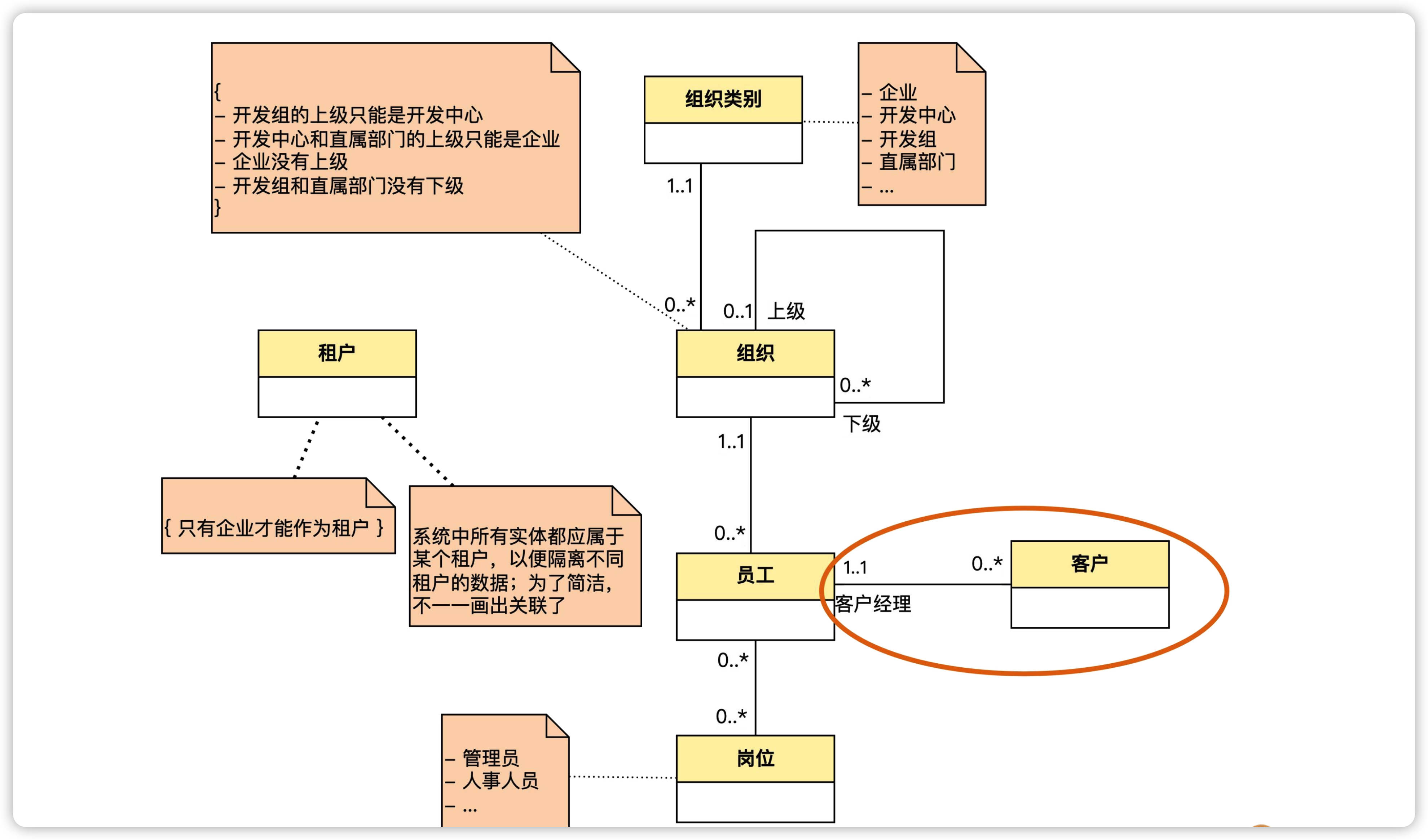
接下来,我们继续识别客户和客户经理、合同和销售人员、项目和项目经理、员工和项目之间的关系。
- 客户和客户经理:每个客户都有一个客户经理负责。因为客户经理也是员工,我们可以把客户经理当作角色。员工和客户的关联翻译成自然语言就是“一个员工可以充当多个客户的客户经理,而一个客户有且仅有一个员工作为他的客户经理”。
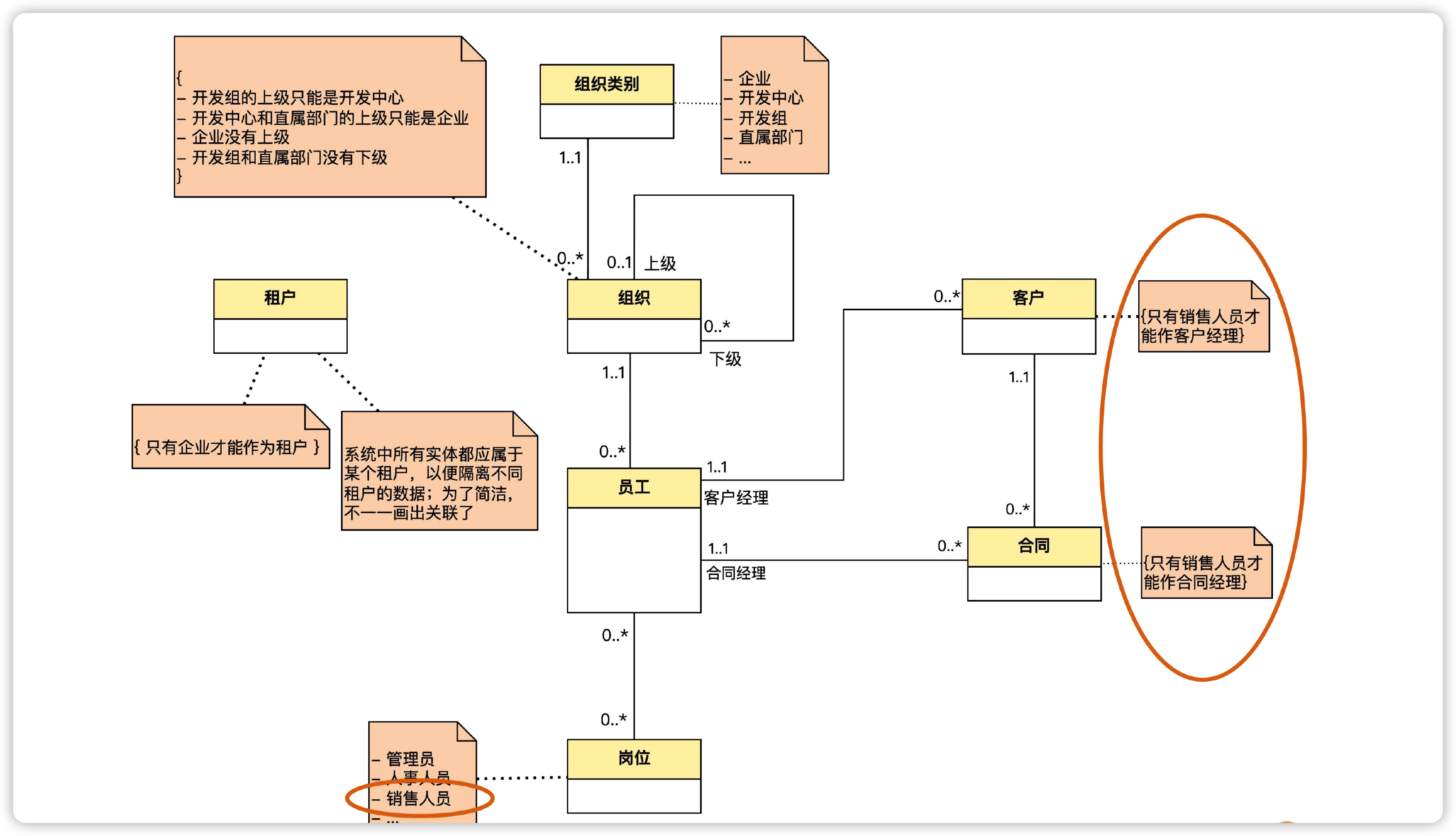
- 合同和销售人员:每个合同都有一个销售人员负责。但客户经理也是销售人员,所以销售人员应该是员工的一种岗位。并且在与客户的关联中,充当了客户经理这个角色。在与合同的关联中,充当了合同经理这个角色。
- 项目和项目经理:每个项目都有一个项目经理负责。因为项目经理也是员工,我们同样可以把项目经理当作角色。员工和项目的关联翻译成自然语言就是“一个员工可以充当多个项目的项目经理,而一个项目有且仅有一个员工作为他的项目经理”。
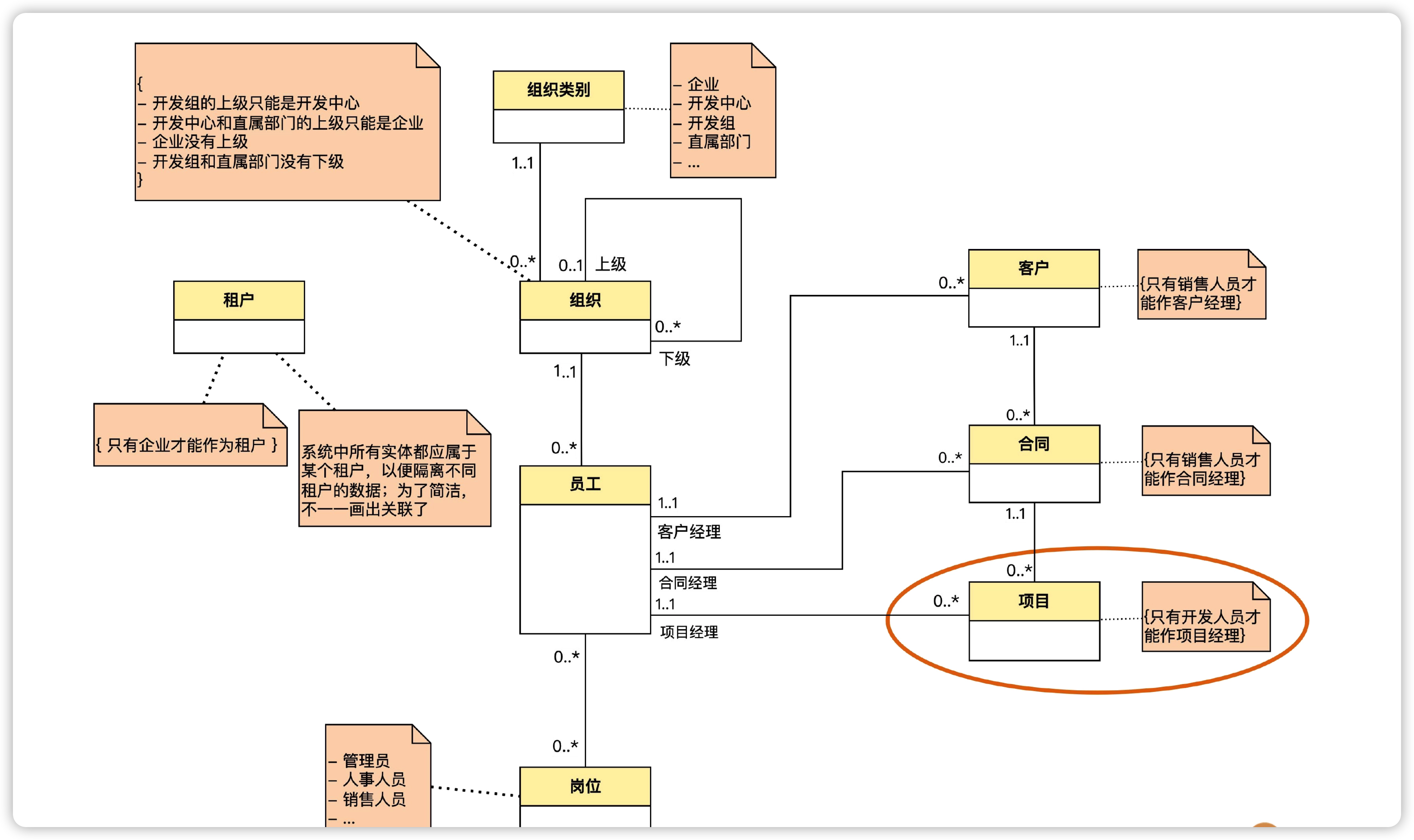
- 员工和项目:员工可以被分配到项目上,同时每个员工预计投入的百分比不能大于百分之百。通过分析可以发现,一个员工可以被分配到多个项目上,一个项目上又可以有多个员工,因此两者是“多对多”关联,并且员工在项目中充当了项目成员这个角色。
在这里我们可以发现,员工和项目之间有了两个不同的关联,当员工作为项目经理时与项目之间是一对多关联,当员工作为项目成员时与项目之间是多对多关联。
所以两个实体之间,是可以有多个关联关系的。不同的关联代表不同含义,数量关系也可以不同,可以用角色名来区分。
但是还有一个问题,我们记录了一个关于投入百分比的规则,这个属性应该记录在哪个实体上呢?分析发现,这个百分比既不能记录在员工实体上,也不能记录在项目实体上。因为,只有员工和项目建立了项目成员这一关联的时候,记录投入百分比才是有意义的。也就是说,这个属性应该记录在这个多对多关联上。
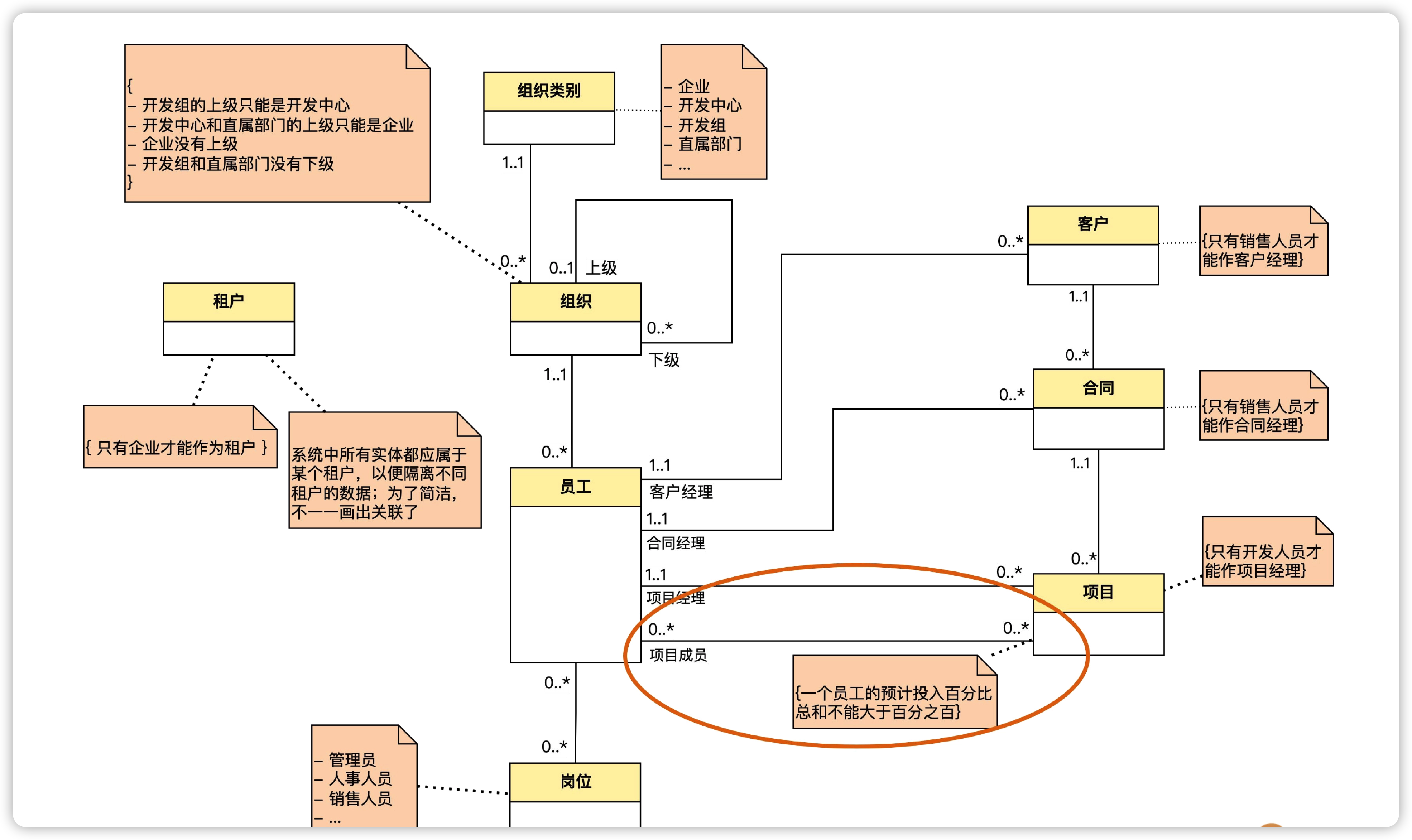
那要怎么记录呢?我们把原来的项目成员角色演变成了一个独立的实体,来表达员工和项目之间的多对多关联。预计投入百分比作为这个实体的属性。
注意,这时候,原本员工和项目之间多对多的关联关系,因为项目成员实体的出现,变成了员工和项目成员之间的一对多关联,项目和项目成员之间也是一对多关联。
所以我们发现,任何多对多关联,都能通过引入一个表示关联的实体,拆成两个一对多的关联,这就是多对多关联关系的拆分。
多对多关联的拆分原则
看到这里,不知道大家有没有这样一个疑惑,为什么“员工和岗位”的多对多关联没有拆分,但是“员工和项目”的多对多关联却拆分了呢?对于多对多关联来说,什么时候该拆分,什么时候不拆分呢?其实是有一些原则可以作为拆分标准的。
- 目的决定手段:当我们需要快速建模,了解宏观结构时,可以先不拆;而当我们需要深入细节,用于指导开发的时候,就要拆分了。
- 业务对于关联实体的关注程度:当关联实体自身有值得关注的属性,或者业务对关联实体独立的状态有关注的时候(常常表现为在业务的术语里面有),就需要拆。
进行抽象
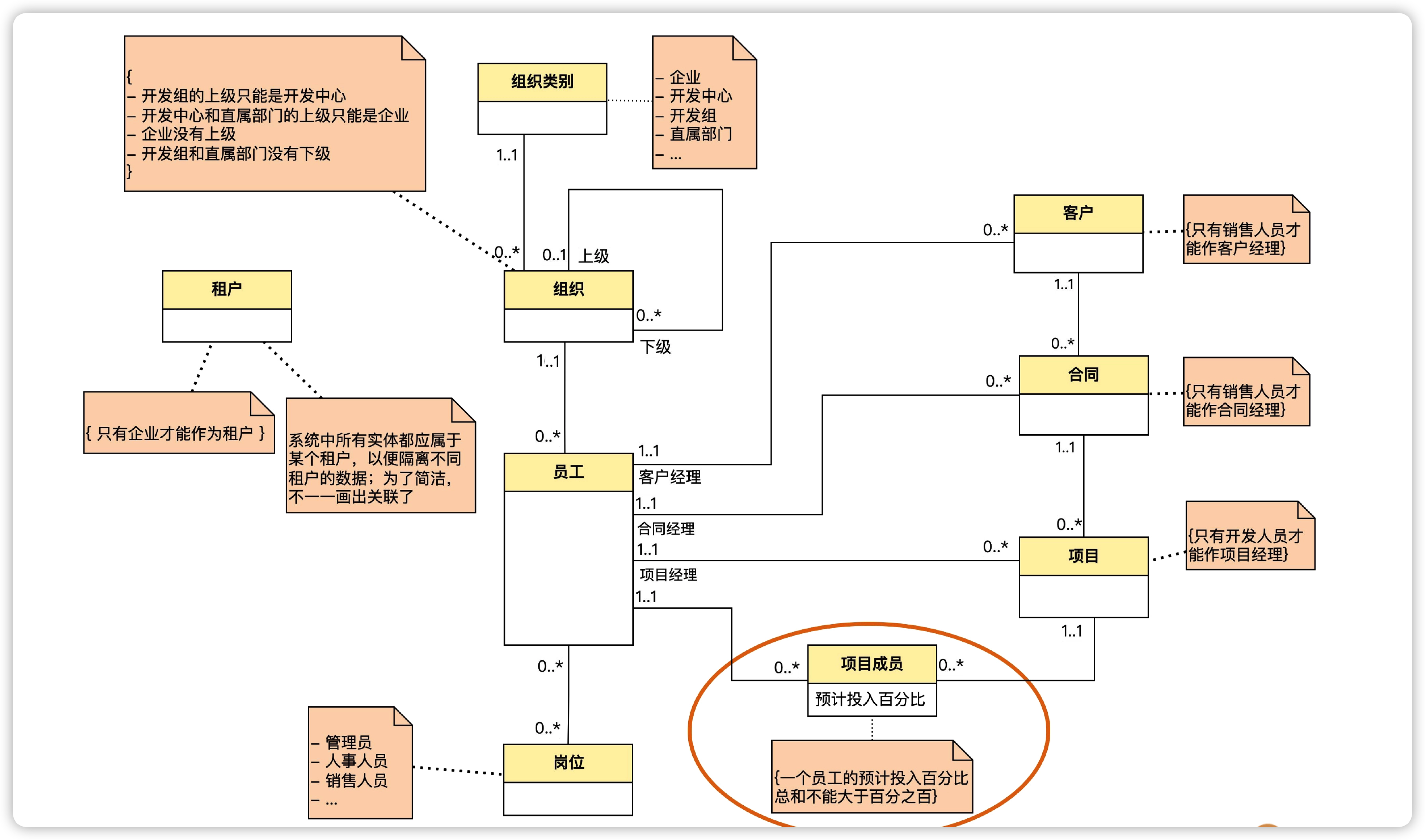
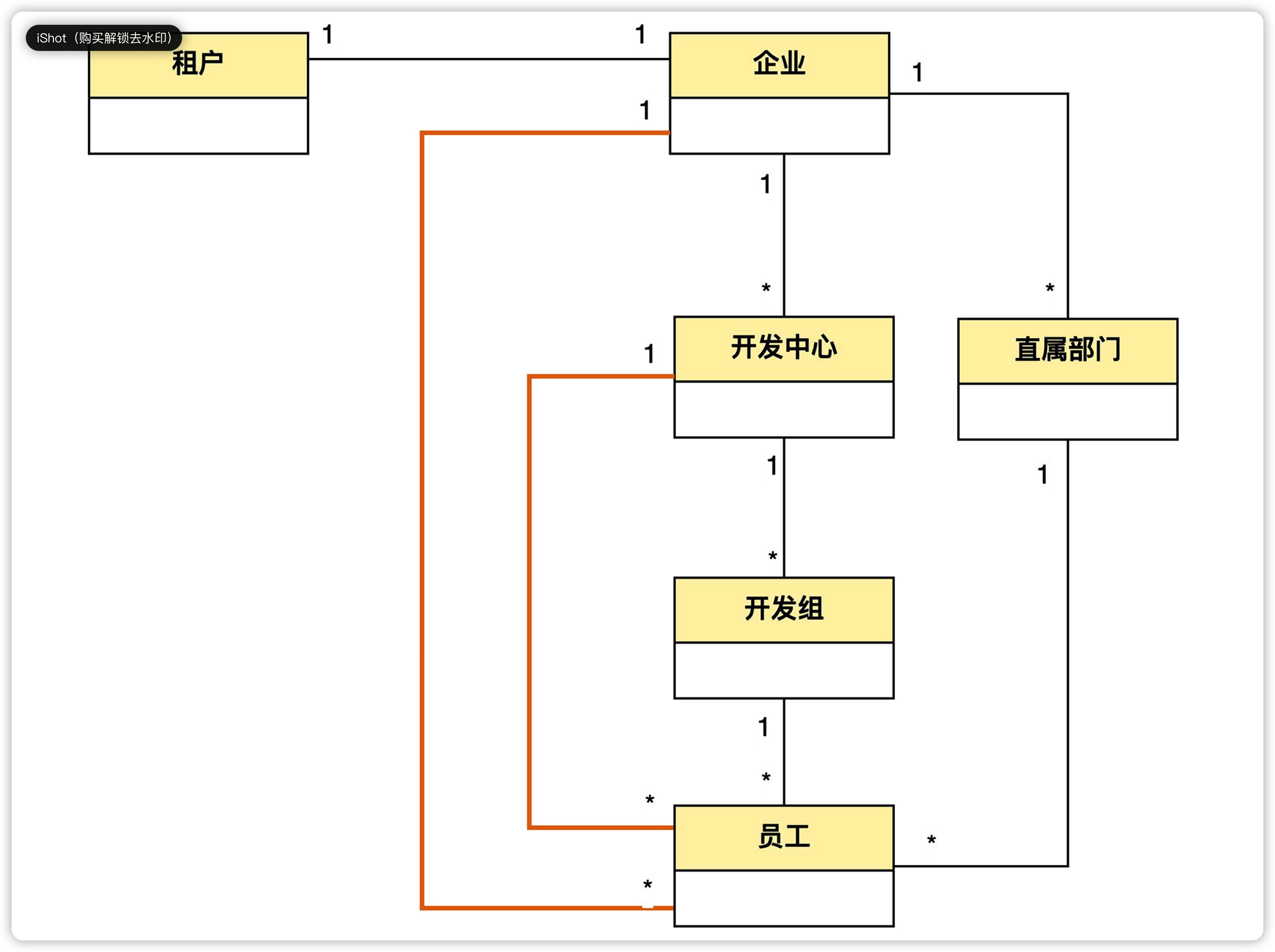
按照上面的方式,找到各个实体之间的关系,可以得到下图。
从图中可以看出,一个员工可以属于开发组,也可以属于直属部门,好像已经满足了需求,但实际存在两个问题。
第一个问题:如果将来组织层级发生变化,比如说在开发中心和开发组之间又增加了一层开发团队;或者有些开发组不属于任何开发中心,而是直属企业,那么这个模型就要修改了。也就是说,这个模型不容易适应组织层级的变化。模型的扩展性差
第二个问题是,一个员工其实可以不属于开发组,而只属于开发中心,比如开发中心的主管就是这样。同理,企业总经理也只属于企业本身而不属于任何下属部门。那么为了表达这种关系,我们就要再增加两条表示关联的线。但线越多,图就越杂乱。模型不够简洁
为了解决上面的问题,我们要对这个模型进行抽象。
抽象是什么呢?抽象就是不再停留在业务的表面,而是深入挖掘业务本质,找出隐含的实体概念。
如何进行抽象呢?找出共性和差异化的地方分别进行定义。
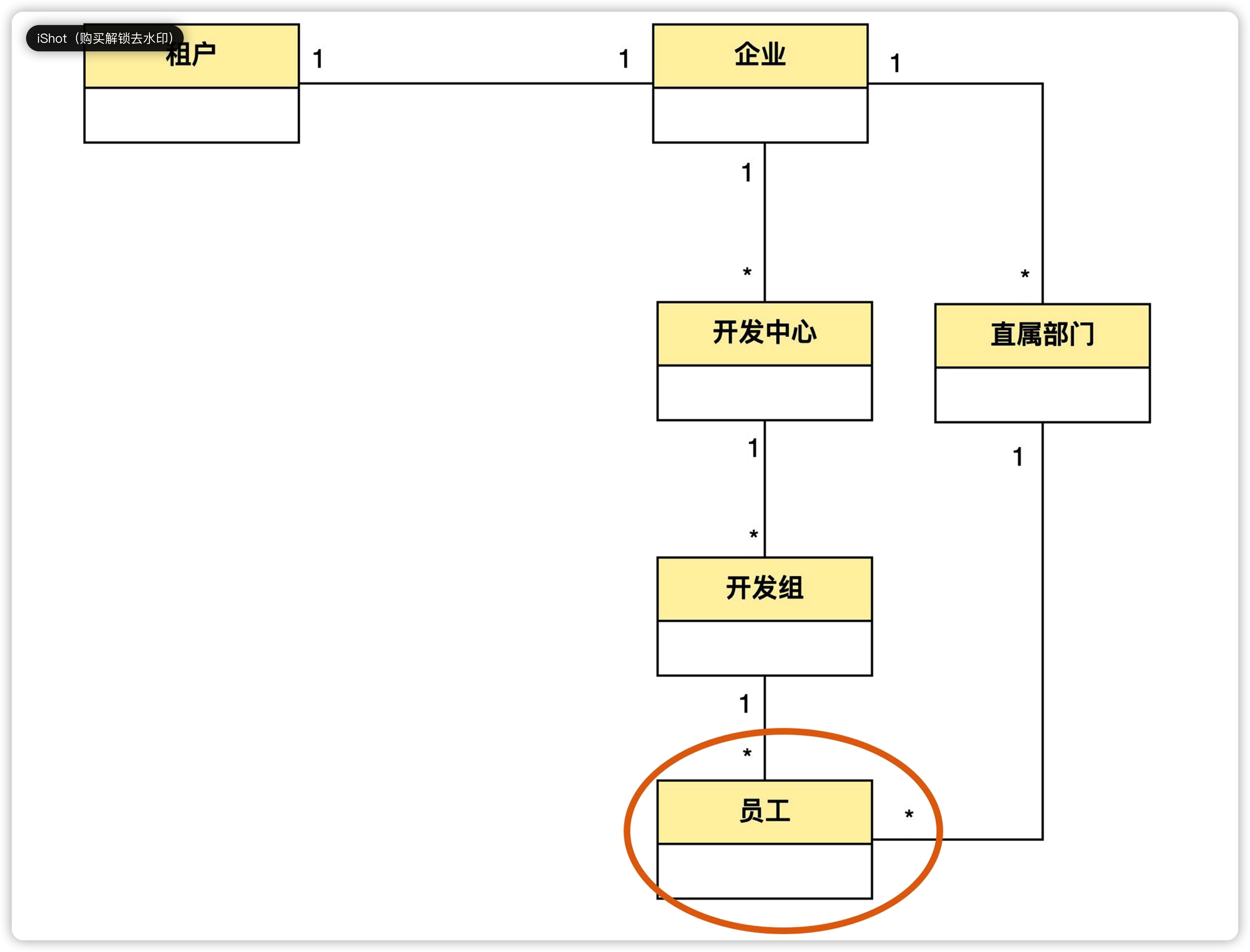
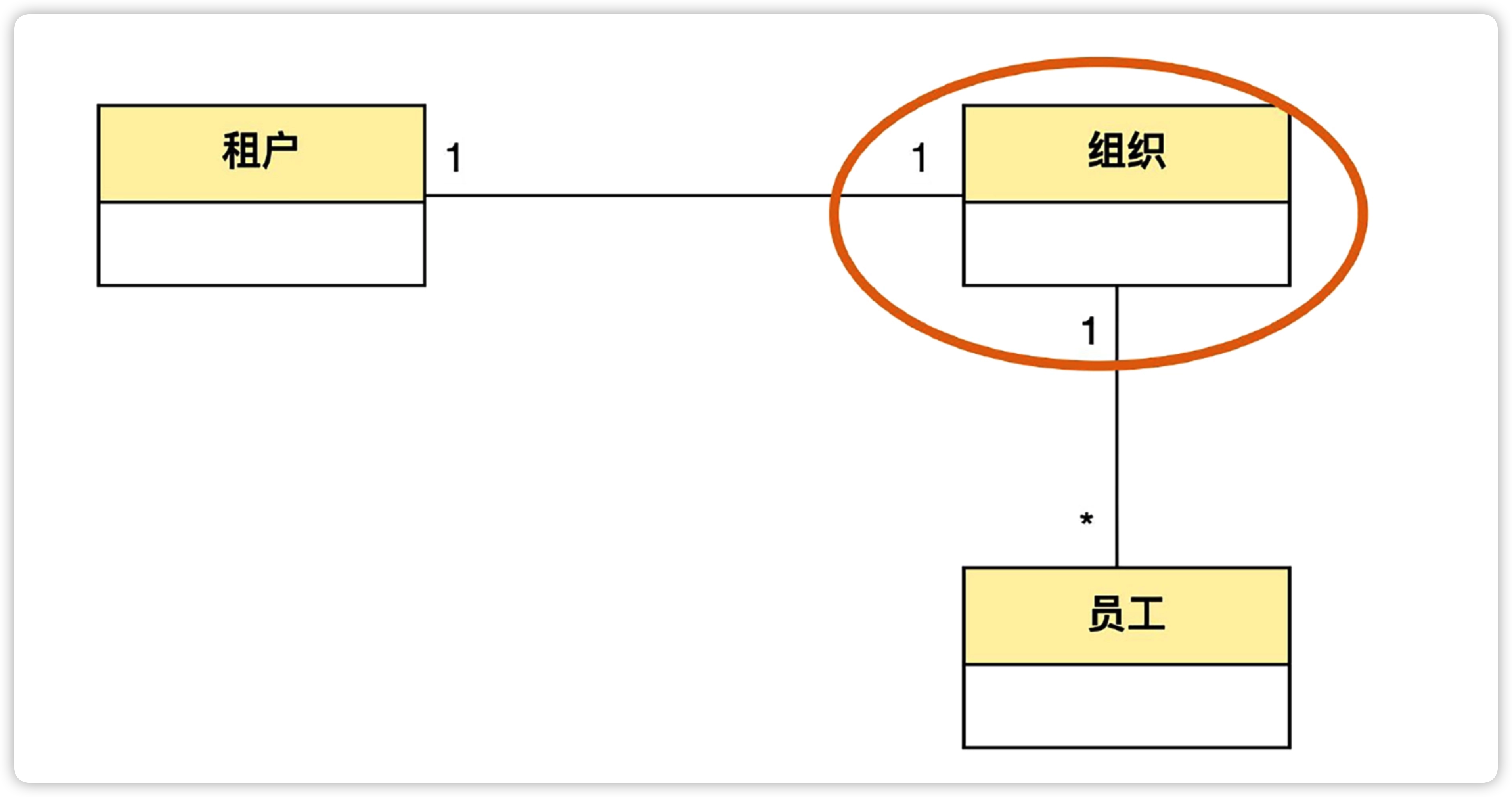
上面的问题中,企业、开发中心、开发组、直属部门,都是组织结构中的节点,从这一点来说,他们是有共性的,在业务上可以统称为 “组织”。
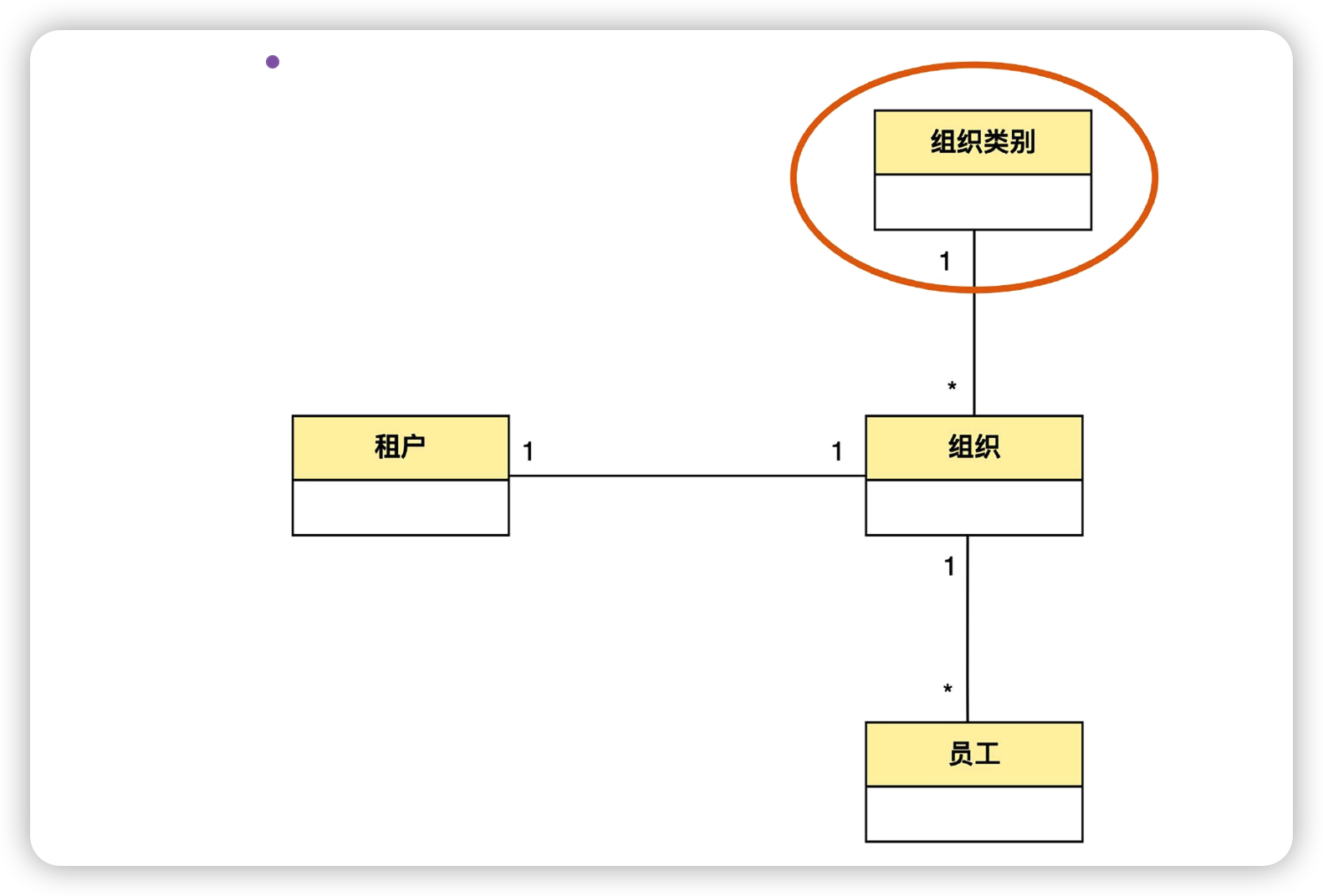
但是只有组织的话,就无法区分一个组织到底是开发组还是开发中心了,也就是归纳了共性,但个性却丢了。这时候可以通过新增“组织类别”这个实体进行区分,企业、开发中心、直属部门、开发组都是组织类别。一个组织类别下可以有多个组织,而一个组织只能属于一个组织类别。比如说,开发组这个组织类别,下面可以有开发一组、开发二组很多具体的组织。
识别自关联
我们发现,上面的图还不能表示企业、开发中心、开发组之间的上下级关系。这可以用组织的“自关联”来表达,也就是自己到自己的关联关系,是一种特殊的关联关系。
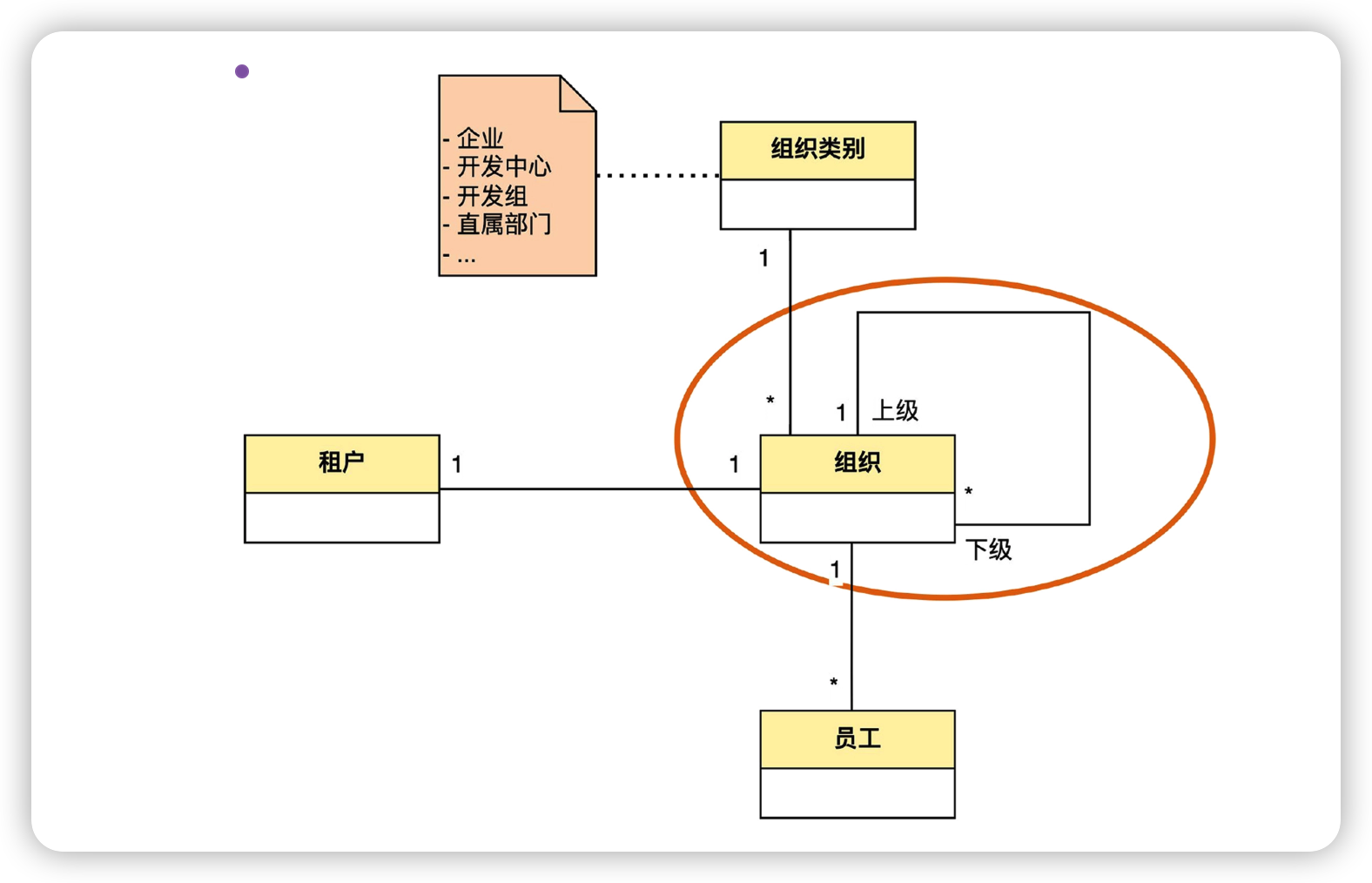
上图中,组织实体上有一个自己到自己的一对多关联。这个关联翻译成自然语言可以这么说:一个组织可以有多个组织作为自己的下级;而一个组织只能有一个组织作为自己的上级,这样就表达出了上下级的层级关系。这种一对多的自关联,实际上表达的是一种树形结构。
当然,除了一对多的自关联,也存在一对一的自关联和多对多的自关联。其中,一对一的自关联表达的是一种线性结构,多对多的自关联表达的是一种网状结构。
另外,在这个自关联的两端,有上级和下级两个词。它们在 UML 里称为“角色”(role)。也就是说,在这个关联的 “1” 端的组织充当上级这个角色,在另一端充当下级角色。如果没有这两个角色名称的话,我们就不知道是一个上级有多个下级,还是一个下级有多个上级了。
识别操作
经过上面的梳理,我们已经把模型梳理得差不多了。但是还遗留了一个问题:怎么处理客户经理上级、销售人员上级和项目经理上级这几个概念?现在看来,它们不太像是独立的实体,而更像是某种关系。
可以发现,客户经理、销售人员、项目经理,都是员工,所以他们的上级,其实可以归纳为取员工上级这个操作,它的具体逻辑为:
- 如果员工不是所属组织的负责人,那么这个组织的负责人就是员工的上级;
- 如果员工就是所属组织的负责人,那么这个组织的上级组织的负责人就是这个员工的上级。
上面的逻辑中,我们引入了一个组织负责人的概念,可以负责任作为员工在与组织的关系中充当的一种角色。现在,组织和员工之间就有两种不同的关联了,分别用了成员和负责人两种角色来区分。
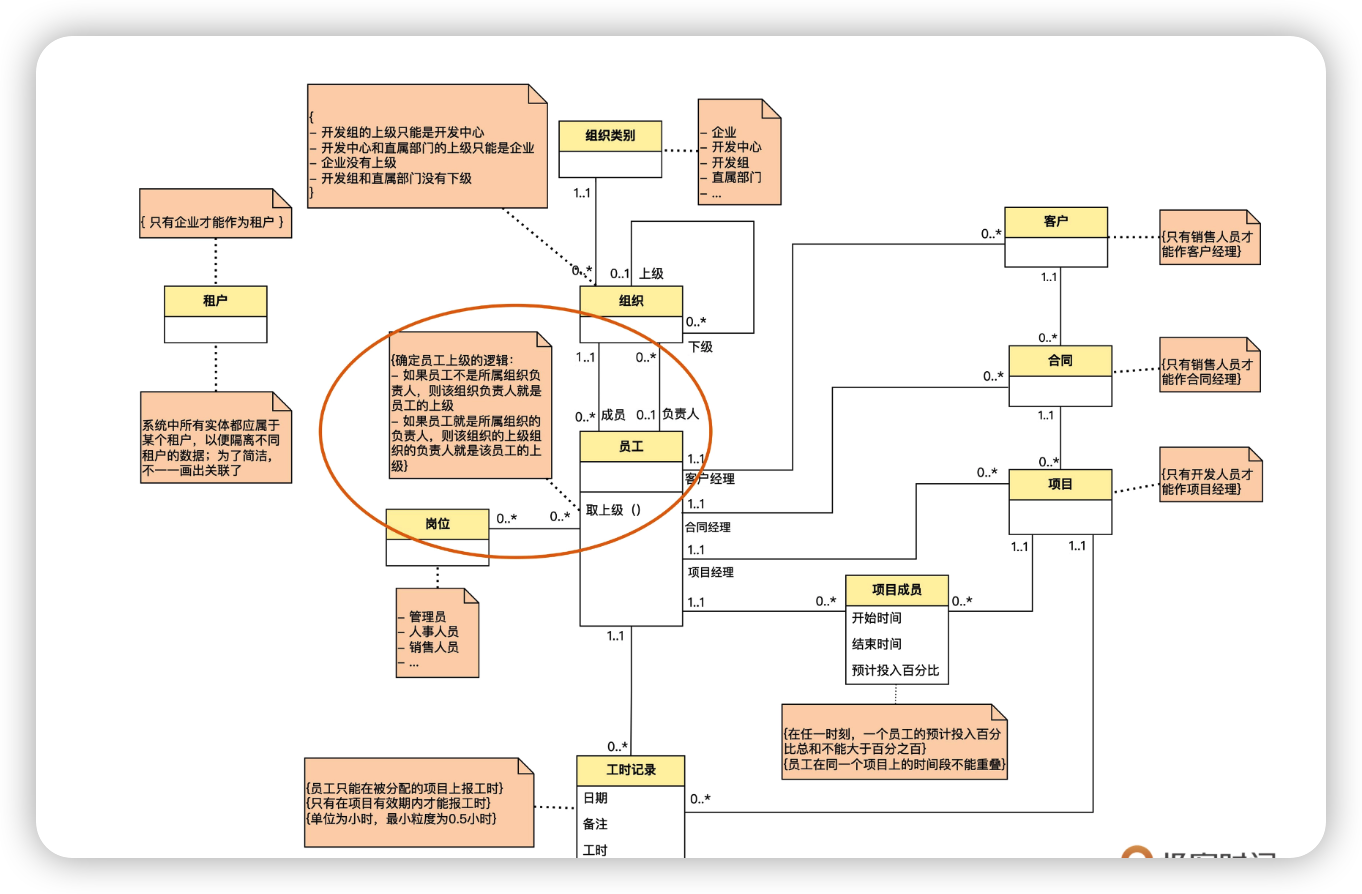
另外,我们在员工实体上增加了取上级这个操作。操作(operation)在 UML 里也叫方法(method)。对象的属性是静态的值,而方法是动态的逻辑。在 UML 中,操作用“操作名 + 括号”的方式表示,括号中可以写参数。
划分模块
现在,我们的领域模型已经覆盖了事件风暴中发现的所有领域概念,但是,你有没有觉得这个图已经有点乱,不太容易理解了呢?
这是因为很多实体和关联混杂在一起,形成了一个“蜘蛛网”。但人的认知能力是有限的,面对这样一张复杂的对象网络,就产生了认知过载(cognitive overload)。
解决这一问题的方法就是“模块化”。也就是说,把模型中的业务概念组织成若干高内聚的模块(module),而模块之间尽量低耦合。
在 UML 中,可以用包来表示模块。包的符号是下面这样:
包的内部可以包含实体,也可以包含另外的包。
最终,我们采用如下的方式划分模块。将模型分成了 4 个模块,分别是租户管理、组织管理、项目管理和工时管理。
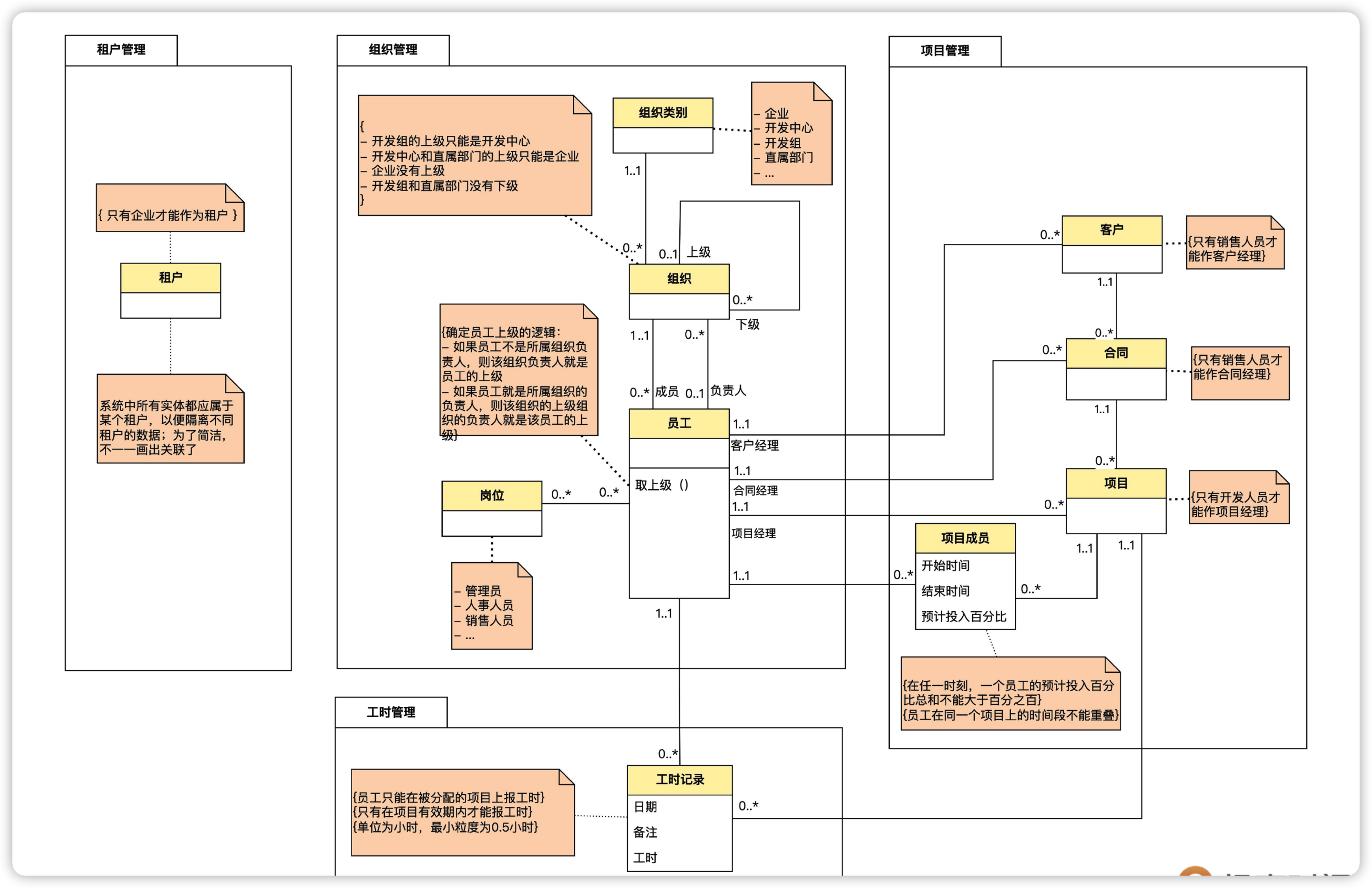
有了模块,我们就可以从两个层面理解模型。
第一个是宏观层面。宏观层面只关心模型中有哪些模块,以及模块间的依赖关系,不关心模块内部的细节。为了达到这个目的,我们可以画出更宏观的包图。像下面这样:
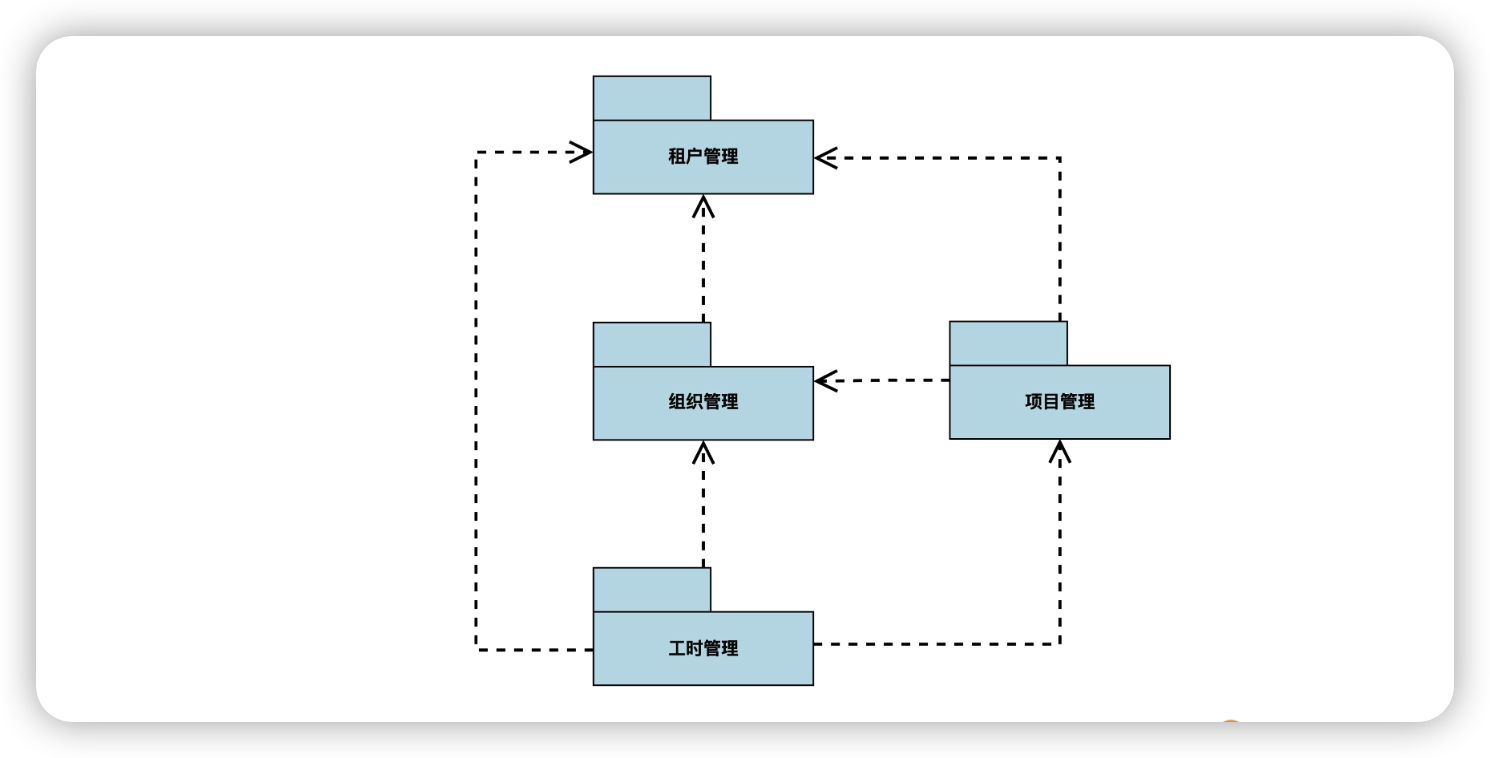
这里我们又引入了一个新的符号,就是带箭头的虚线。这在 UML 中表示依赖(dependency)关系,箭头由依赖方指向被依赖方。
依赖关系和前面讲的关联关系是不一样的。
- 关联表示的是数据上的导航关系,耦合更强。例如,当我们说组织和员工之间具有一对多关联的时候,就意味着,由组织可以找到下面的员工,由员工也可以找到所属的组织。在Java代码实现上,通常以成员变量的形式存在,比如类 Customer 作为类 Order 的成员变量,我们就可以说类 Order 长期持有 Customer。
- 依赖关系,耦合更弱。比如说项目管理模块依赖于组织管理模块,两者之间未必有直接的数据导航关系,可能只是项目管理调用组织管理,获得需要的数据。在Java代码实现上,通常以局部变量、方法参数的形式存在,比如类 Order 中的方法 ship 的参数为类 Address,我们就可以说类 Order 依赖类 Address。
// 关联:长期持有 Customer
class Order {
private Customer customer;
}
// 依赖:方法里临时用 Address
class Order {
void ship(Address addr) { ... }
}第二个是微观层面,也就是深入到模块内部,了解实体和关联关系的细节。
通过这种分而治之的方法,我们可以在一定程度上管理复杂性,解决认知过载的问题。
建立业务概念表
其实,划分完模块,领域模型基本就完成了。但是为了后续方便进行知识传递,统一产品、研发、业务之间的语言,我们还要将领域模型识别出来的一些概念定义给出来,产出业务概念表。
下图就是对四个模块中的概念给出定义,这里最好再加上描述一列,详细描述这个概念的含义,给出一些解释。
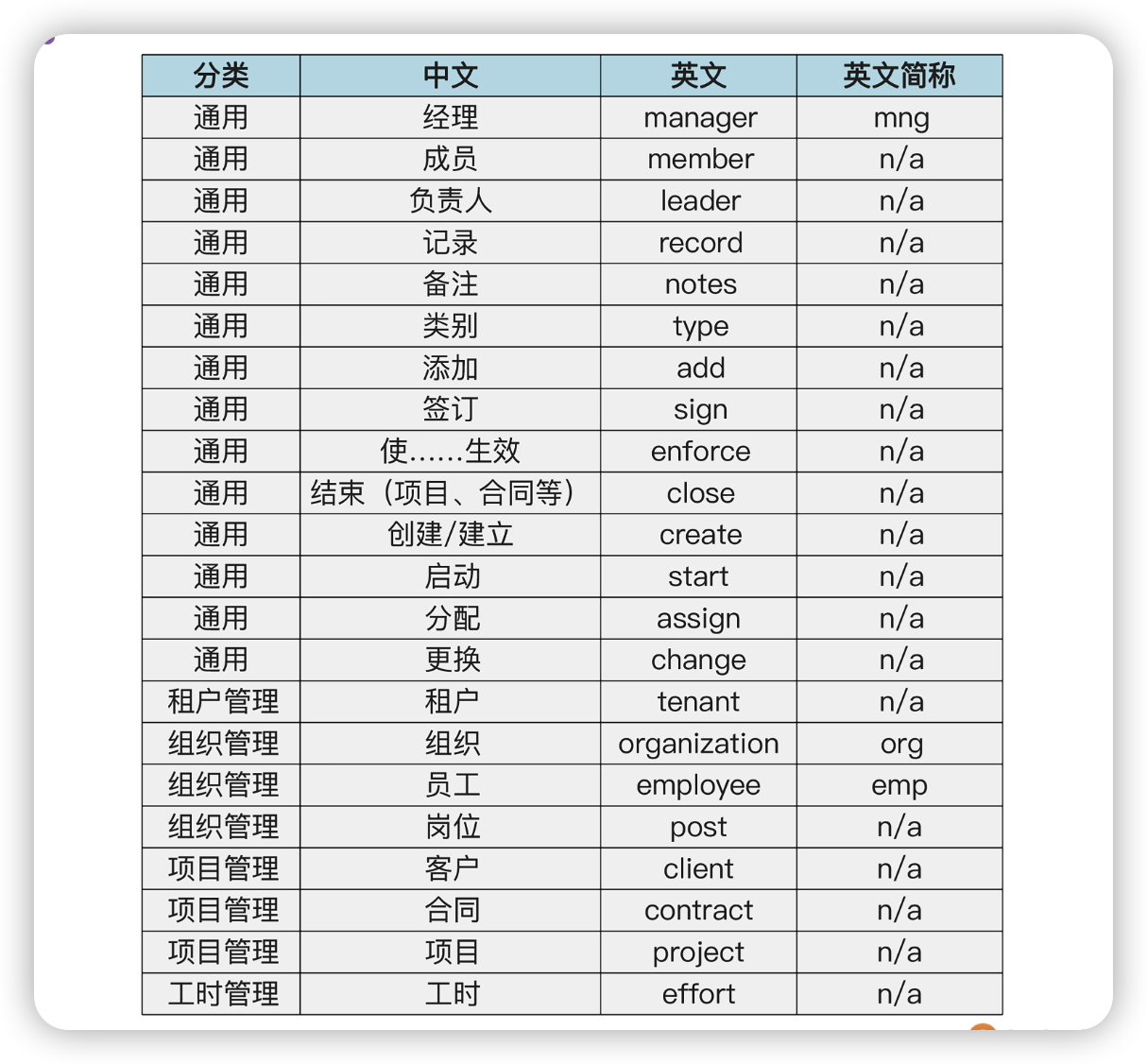
有了业务概念表,可以实现以下目的:
- 统一业务、产研对同一业务概念或者行为的命名。比如 项目已开始、已立项 虽然表达相同的含义,但是 业务概念表中明确为 已立项,那后续所有的沟通都要使用 「已立项」。
- 指导后续模型实现时的命名。按照 DDD 的要求,程序中的各种命名需要与领域模型中保持一致。
知识传递
其实,在领域建模之后,模型实现之前,还有一个过程是极其重要,但不被重视的,那就是知识传递,目的是统一多方语言。
知识传递的重要性
为什么知识传递这么重要呢?
- 研发之间的知识传递,可以让开发者都理解模型,才能正确的编码实现,保证系统实现和领域模型的一致性。
- 业务、产研之间的知识传递,可以让领域模型与业务需求保持一致,最终让系统实现和业务需求保持一致。
知识传递带来的效益是非常大的,它能在业务、产研之间快速统一语言,降低沟通成本。
知识传递的形式
知识传递的形式有很多,大家按需选择。
- UML图:简单的非正式的 UML 图。虽然我们上面介绍 UML 图的时候很正规,但在实际应用过程中,能够示意即可,不希望 UML 图的应用增加太多的学习成本,希望更专注于业务本身。
- 词典表:要产出一份官方的业务概念表,避免沟通歧义。
- 原型图:可交互的原型展示。
- 交互图:系统中各模块的交互逻辑。
如何更好的知识传递?
知识传递的好处很容易理解,难点在于怎么真正在实践中落地。
要在实践里真正实现知识传递,我们可以从基础文档和实际应用这两个方面来考虑。
- 基础文档:领域模型、词典表等文档性的产物,就是知识传递的基础。
- 实际应用:而业务和技术人员在开发过程中的沟通协作,就是知识传递的实际应用。
这两方面缺一不可。
写在最后
本文介绍的是领域建模的过程,它是DDD的核心部分。整个过程:
- 先确定实体、实体间关系(通过关联关系表示,自关联也是关联关系)
- 再借助抽象,确定隐含实体、实体间关系
- 识别实体的属性和方法,当然这一部分是非必须的,除非对实体的确定是必须要的
- 模块划分,形成不同的领域模块
- 最后,通过知识传递,在业务、产研间统一语言
要注意,在项目初期这个过程会占据大量时间,之后也会一直持续进行。这是因为:
-
对一个事物的理解是不断深入的,认知是持续迭代的
-
事物本身也是在不断发展变化的
所以,即使大家已经完成了领域建模和代码实现,也建议定期回顾一下领域模型,当初的领域模型现在看设计得是否合理,是否与当前的业务发展匹配。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)