并发模型对比 - 传统 epoll/事件循环
传统 epoll / 事件循环:高性能网络编程的基石
在上一讲 Go GMP 调度器时提到过,"传统 epoll/事件循环"是另一条并发路线,与协程调度形成了鲜明对比。本节就来系统梳理,帮助你彻底理解这一经典的网络并发模型。
一、前置基础:IO 模型的演进路径
理解 epoll 之前,需要先搞清楚它在 Linux IO 模型中的生态位。
1. 阻塞 IO (Blocking IO)
最原始的模型。调用 read() 后,如果数据还没准备好,线程会直接被挂起(进入阻塞状态),直到数据就绪才返回。
缺点:为了同时处理多个连接,必须为每个连接创建一个线程。并发量一大,内存开销(每个线程栈约 1MB)和上下文切换开销都会爆炸。
2. 非阻塞 IO (Non-blocking IO)
设置 O_NONBLOCK 标志后,read() 无数据时立即返回 EAGAIN(即资源暂时不可用)错误,线程不会被挂起。
但这样带来的新问题是:为了知道数据什么时候就绪,你不得不在一个循环里不断轮询——"每隔一秒拉起来看看有没有鱼",手都给你累断,CPU 空转严重。
这就引出了第三个方案。
3. IO 多路复用 (I/O Multiplexing)
"你一口气下了 100 根鱼竿,然后坐在旁边等,哪根鱼竿的报警器响了,你就去拉哪根。"
这就是 IO 多路复用的核心思想:用一个线程监控成百上千个文件描述符,数据就绪才通知你。它完美地结合了阻塞和非阻塞的优势——监控过程是阻塞的(避免 CPU 空转),但一旦数据就绪,对单个连接的读写操作是非阻塞的。
二、epoll 的前世今生:select -> poll -> epoll
epoll 不是 IO 多路复用的唯一实现,但它是最好的那个。从它的演进历程中,能看出高性能系统的设计智慧。
| 特性 | select | poll | epoll |
|---|---|---|---|
| 最大连接数 | 1024(宏限制) | 无限制 | 无限制 |
| 数据结构 | 位图 | 数组 | 红黑树+就绪队列 |
| 查找就绪 fd 复杂度 | O(n) | O(n) | O(1) |
| 每次调用时数据拷贝 | 拷贝全部 fd 集合 | 拷贝全部 fd 集合 | 仅首次注册时拷贝 |
| 触发模式 | 仅水平触发 (LT) | 仅水平触发 (LT) | LT 或 ET |
| 跨平台性 | POSIX 标准 | POSIX 标准 | Linux 独有 |
select 和 poll 最致命的问题:用户态 -> 内核态的数据拷贝 + 内核线性扫描全部 fd,在 10 万连接场景下 CPU 占用比 epoll 高出 87%。epoll 重新设计了 API,核心价值在于"先注册、后等待"的模式,配合回调机制实现了一次注册、零拷贝等待——你不需要在每次循环中都把监控列表传给内核,事件就绪后内核主动通过回调通知你。
三、epoll 的三大核心函数
epoll 将完整的监控流程拆成了三次独立的调用,逻辑清晰,易于维护。
-
epoll_create():在内核中创建 epoll 实例,返回一个文件描述符。内核会建立红黑树和就绪队列等数据结构。
-
epoll_ctl():增、删、改被监控的文件描述符。
EPOLL_CTL_ADD(添加)、EPOLL_CTL_MOD(修改)、EPOLL_CTL_DEL(删除)。所有被监控的 fd 会被存入内核红黑树中,插入删除时间复杂度为 O(log n)。 -
epoll_wait():阻塞等待事件就绪,返回就绪的 fd 列表。内核直接将就绪队列的链表头指针返回,
epoll_wait只需从就绪队列中取出数据就能知道哪些 fd 有了新事件。这个过程的时间复杂度是 O(1),与总连接数完全无关。
四、LT 与 ET:两种截然不同的通知哲学
epoll 支持两种事件触发模式,这是它与 select/poll 最重要的区别之一。
水平触发 (Level Triggered, LT) —— epoll 的默认模式
只要 fd 的 IO 缓冲区中有数据可读/可写,epoll_wait 会持续不断地通知你,直到你把数据完全读完。
用一个形象的比喻:快递员张师傅,你的 5 个包裹到了,他就一直给你打电话让你下来取,取了一个还有,接着再打,打完为止。
边缘触发 (Edge Triggered, ET)
仅在 IO 状态发生变化的那一瞬间通知一次——从"无数据"变成"有数据"时通知你,此后不再重复通知。这意味着你必须在这一次通知中把数据全部读完(循环调用 read() 直到返回 EAGAIN),否则剩余的数据可能就再也没机会被通知了,因为不会再触发"变化"。
继续用那个比喻:快递员李师傅,你所有包裹到了只打一次电话,取不取是你的事,过时不候。
该选哪个?
| 模式 | 编程难度 | 系统调用次数 | 适用场景 |
|---|---|---|---|
| LT | 低,代码简单,不易出错 | 相对较多(可能重复通知) | 通用开发、业务逻辑复杂场景 |
| ET | 高,需循环读完数据,需处理半包 | 相对较少(一次通知批量处理) | 高并发、极致性能 |
ET 模式下应用层必须循环读取直到 EAGAIN,while ((n = read(fd, buf, sizeof(buf))) > 0),以确保证不会被"通知丢失"。
五、事件循环 (Event Loop):从内核通知到业务响应
epoll 单独工作时,你依然要自己写出一个循环来处理通知。这个循环统一被称为"事件循环",是高性能网络编程中极其经典的模式。
最基本的伪代码结构如下:
c
int epfd = epoll_create(...);
// 将 listen_fd 加入监控
struct epoll_event ev;
ev.events = EPOLLIN; // 关注读事件
ev.data.fd = listen_fd;
epoll_ctl(epfd, EPOLL_CTL_ADD, listen_fd, &ev);
while (1) {
// 阻塞等待,直到有 fd 就绪
int nfds = epoll_wait(epfd, events, MAX_EVENTS, -1);
for (int i = 0; i < nfds; i++) {
if (events[i].data.fd == listen_fd) {
// 新连接到达
int conn_fd = accept(listen_fd, ...);
setnonblocking(conn_fd);
epoll_ctl(epfd, EPOLL_CTL_ADD, conn_fd, &ev);
} else {
// 数据就绪,读取并处理
int fd = events[i].data.fd;
read(fd, buf, size);
handle(buf);
}
}
}
Redis 采用单线程事件循环,利用 epoll_wait 一次性获取所有活跃连接,逐个处理,不需要额外线程协调。
Nginx 的 worker 进程通过 epoll_wait 实现连接管理,在 10 万并发连接下 CPU 占用率较 select 模式降低 80% 以上。
六、epoll 的局限性(与协程模型的对比)
epoll 本身很好,但它没有解决高并发编程中所有的问题。
1. 回调地狱 (Callback Hell)
使用 epoll 时,一个连接的完整生命周期往往需要拆成若干个回调函数:新连接时干什么、数据到达时干什么、连接关闭时干什么。业务逻辑的阅读难度和状态维护成本会随系统规模快速上升。
2. 状态管理复杂
协程模型下,一个连接的处理逻辑可以被写成顺序执行的"阻塞"代码,状态自然地保留在协程栈中。而 epoll 模型下,状态需要显式地存储在结构体中,在多个回调之间手动传递。
3. 编程心智负担
与 Go 的 go 关键字、Java 虚拟线程的 Thread.startVirtualThread() 相比,epoll 模式要求开发者必须理解非阻塞 IO、事件驱动、状态机等概念,上手门槛较高。
这正是 Go 协程出现的原因——保留 epoll 的性能优势,同时让开发者用同步思维写出异步代码,把数据"喂"给 epoll,再通过协程调度将其包装成看起来像阻塞的调用。协程与 I/O hook、epoll 事件循环的整合,使得底层仍然使用 epoll 与非阻塞 I/O,但业务逻辑可以写成"看起来是阻塞、实际上不会阻塞"的同步风格。
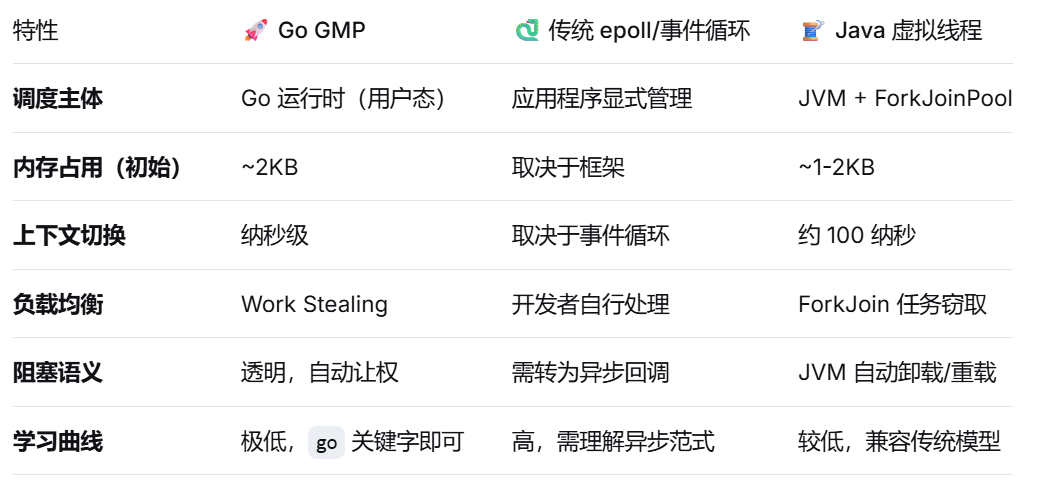
七、总结
| 模型 | 并发单元 | 调度者 | 代码风格 | 学习曲线 |
|---|---|---|---|---|
| epoll + 回调 | 单线程 | 开发者手动管理 | 异步/回调 | 陡峭 |
| Go GMP | Goroutine | 运行时自动调度 | 同步/顺序 | 平缓 |
| Java 虚拟线程 | 虚拟线程 | JVM 调度 | 同步/顺序 | 平缓 |
epoll 是 Linux 内核的高性能 API,Nginx、Redis 都跑在它上面。但写好基于 epoll 的服务,你得自己拆分回调、管理状态。协程模型保留了 epoll 的性能优势,同时通过运行时调度把高并发复杂度降低了一个数量级。这刚好印证了——技术演进的核心,往往不是发明新轮子,而是把底层的能力,用更优雅的抽象呈现给开发者。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)