BERT 学习笔记
BERT
BERT 是 Google 2018 年提出的预训练语言模型,全称:Bidirectional Encoder Representations from Transformers,是基于 Transformer 编码器的双向语言表征模型。
输入嵌入层(Embedding)
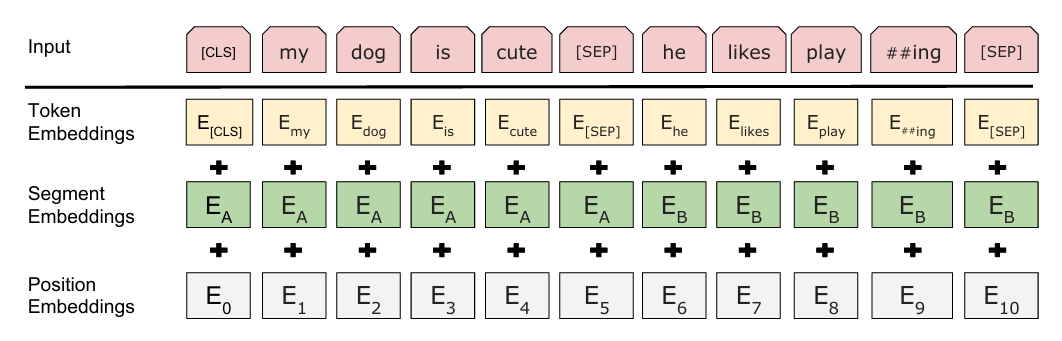
Token Embedding 词嵌入
作用:把离散的字符转换成连续低维向量
实现方式:
- 构建词表(vocab):每个字符(包括 [CLS],[SEP] 等)对应一个数字 id。
- 初始化可训练词嵌入矩阵:对于中文 BERT,嵌入矩阵形状为 [21128,768],即中文字符共 21128 个,每个字符由 1*768 的向量表示
- 查表映射:输入句子根据词表转换成 id 序列,查找嵌入矩阵对应位置的向量作为该字符的特征向量。
Segment Embedding 句段嵌入
作用:区分两个句子
实现方式:
- 标识输入:将输入句子转换成0/1编码(主要目的是区别两句话,如00000111)。
- 初始化可训练句段嵌入矩阵:嵌入矩阵形状固定为 2*768,“2”表示两句话的语义特征。
- 查表映射:输入句子的0/1编码作为索引查找嵌入矩阵对应向量,于是转化为8*768的矩阵(前5行元素对应相同)。
Position Embedding 位置嵌入
作用:Transformer 没有时序、没有循环,不知道单词先后顺序,位置嵌入就是给每个位置编号,告诉模型第 1 个字、第 2 个字…… 分别在哪。
实现方式:
- 标识输入:输入句子按 token 的下标标识。
- 初始化可训练位置嵌入矩阵:嵌入矩阵形状为 512*768,“512”表示最大输入句子长度,每行向量描述了句子的语序、远近关系、语法位置信息等。
- 查表映射:按下标查表转换为位置向量。
嵌入矩阵逐元素相加(本质是特征融合):
Input Embedding=Token Embedding+Segment Embedding+Position Embedding
Transformer Encoder
Multi-Head Attention 多头自注意力机制
作用:让输入句子里的每个字都能理解全局语义信息。
实现方式:
- 输入向量 X [seq_len,768],将其分别于三个可训练参数 Wq、Wk、Wv 相乘映射到三个空间。
- Q = XWq,K = XWk,V = X*Wv。形状均为 [seq_len,768]。
- “多头”就是将每个空间拆分为多个子空间,每个子空间表示不同的信息(比如语法关系、上下文语义、指代关系等)。即 Q —> Qi,形状为 [seq_len,64](12个头的话64=768/12)。
- 根据公式 $Attention(Q,K,V) = softmax(QK^T/\sqrt{d})V$计算注意力输出,再合并头。(该公式本质是先计算Q和K的相似度,转化为概率分数后,与V相乘表示每个 token 与其他 token 的关系。
Add & Norm 残差连接和层归一化
作用:Add:减缓反向传播时导致的梯度消失以及深层网络的退化现象 Norm:让训练更稳定。
Feed Forward 前馈网络
作用:特征加工
实现方式:输入向量 —> 全连接层1 —> GELU 激活函数 —> 全连接层2(Transformer 原文为ReLU)
输出层
由于BERT是一个预训练模型,因此最终的输出层是根据下游任务不同而变化的。下图是BERT原文中展示的几个下游任务以及BERT是怎么做的。
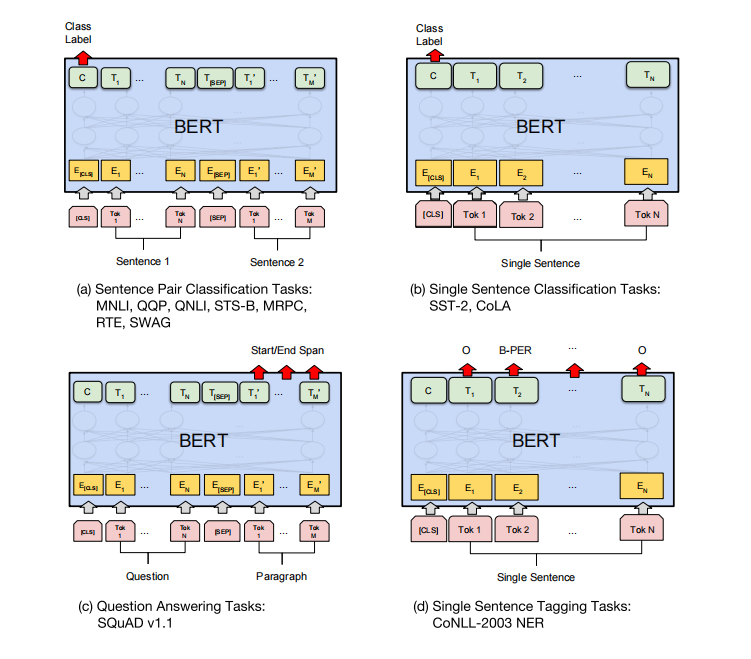
(a)句子对分类任务和(b)单句分类任务
通过 [CLS] 字符输出 Class Label,一般用全连接层将输入向量转换为目标分类维数,再接 Softmax 函数转换为概率分布,从而完成分类。
(c) 问答任务(其实是阅读理解)
本质是用段落里每个字的向量预测哪个 token 作为答案开始,哪个 token 作为答案结束。
实现方式:
- 经过12层 Encoder 后输出向量形状为 [seq_len,768]。
- 设置两个可训练参数矩阵(即两个独立线性层),形状都是 [768,1]。
- 对每一个 token 的向量乘以两个权重矩阵,得到一个 Start 分数向量和一个 End 分数向量。
- 对两个向量序列做 Softmax 转换为概率分布。
- 选 Start 概率最大的位置就是答案起点,选 End 概率最大且在起点之后的位置就是答案终点,截取起点到终点之间所有字,就是模型输出的答案。
(d)单句标注任务
对句子中每个 token 的词性或者其他属性进行标注,因此需要对每个 token 都经过线性层输出从而预测标签(如人名、地名等)。
预训练
MLM 掩码语言模型
简单来说,这个预训练任务就是一个完型填空的任务,即通过上下文判断出某一位置应该是什么词。
实现方式:
- 随机掩码:在一句话里随机选择15%的 Token 做掩码,其中80%之间换成 [MASK],10%随机换成另一个无关字,10%保持原字不变。
- 计算损失:经过12层 Encoder,每个字都转换成1*768向量,对掩码向量×输出层(Token Embedding 中的词嵌入矩阵,形状为 [21128,768],转置一下),计算出词表里每个字的概率p,和原字计算交叉熵损失。
- 反向传播:更新三种嵌入矩阵、12层 Encoder 的所有 QKV、FFN 权重。
注:计算交叉熵损失:原字符根据 id 转换成 one-hot 编码(比如狗的 id 是7842,则构造一个21128维的标签向量y,只有第7842位为1,其余全是0),将其与每个字的概率相乘并取负对数-ln(p*y)即是损失。
NSP 下一句预测任务
此任务是让模型预测下一个句子是否真的是当前句子的下一句。
实现方式:
- 取出一对句子 A+B 顶层 [CLS] 的1*768向量。
- 接一个线性层,转换成1*2向量。
- Softmax 输出概率 [p1,p2] 分别表示 B 是(不是) A 的下一句的概率。
- 和真实标签算损失(是下一句:[1,0] 或不是下一句:[0,1]),同样反向传播,一起更新整个 BERT 参数。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)