「有凭有据」:第一个会说“为什么“的说话人验证大模型
Speech AI · FRONTIER — 第 001 期精读
SpeakerLLM:让大语言模型读懂"谁在说话"
📄 原文:SpeakerLLM: A Speaker-Specialized Audio-LLM for Speaker Understanding and Verification Reasoning
👥 作者:KiHyun Nam, Jungwoo Heo, Siu Bae, Ha-Jin Yu, Joon Son Chung(KAIST · 首尔市立大学)
📅 日期:2026-05-14 | 🏷️ 来源:arXiv 2605.15044(cs.SD / eess.AS)
📌 一句话总结
SpeakerLLM 是首个专为"说话人分析"设计的音频语言模型——它不仅能回答"这两段录音是同一个人吗",还能告诉你"为什么:他们的音色相似但年龄判断存在矛盾"。
🤔 这篇论文要解决什么问题?
随着音频优先的智能体(机器人、可穿戴耳机、智能家居)快速落地,说话人感知变得至关重要——你需要系统不仅识别出"这是 Alice",还要能回答"这段录音里的人声音听起来疲惫吗"“录音环境是不是很嘈杂”。
然而,现有技术存在三条明显裂缝:
痛点一:传统说话人验证只输出一个分数。 经典的说话人验证(Speaker Verification, SV)系统将两段录音映射为嵌入向量、计算余弦相似度,最终给出一个"0.87"。这个数字能判断"是不是同一人",但无法解释依据——发生错误时工程师束手无策,用户更无从理解。
痛点二:通用 Audio-LLM 缺乏说话人专业理解。 Qwen2.5-Omni、Audio Flamingo 等通用模型虽然能处理各类音频任务,但它们接受说话人层面的问答时表现平庸:本文实验显示,Qwen2.5-Omni-7B 在说话人验证准确率仅 65.2%,在音高(Pitch)属性分类上仅 22.7%,与随机猜测相差无几。
痛点三:说话人证据分布在多个粒度,单一表示难以全捕。 说话人身份体现在嵌入级别(整段语音的全局特征),而音色细节、录音环境则藏在帧级别(局部动态特征)。使用单一粒度的表示,必然损失另一维度的信息。
SpeakerLLM 的切入点:用层次化 Tokenizer 同时捕获多粒度说话人证据,再接入 LLM 让模型学会"带着理由"做验证决策。
🏗️ 核心方法
整体架构
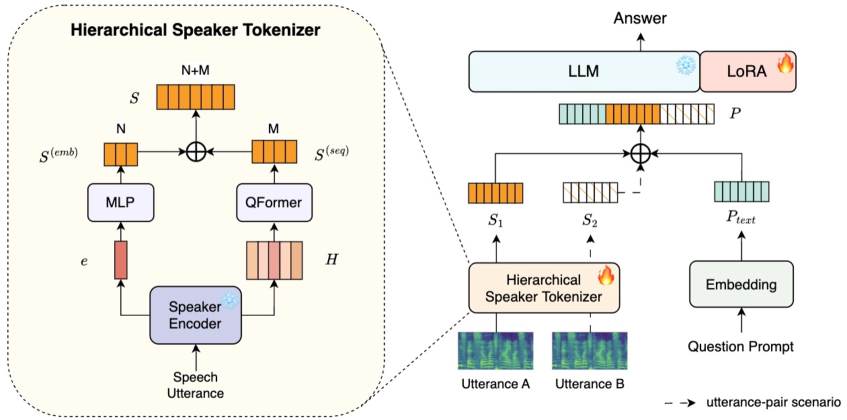
▲ 架构图详解:
整个系统的数据流分三段:
① 特征提取(Frozen Encoder):使用预训练并完全冻结的 ReDimNet-B3 作为说话人编码器。对于输入语音,编码器同时输出两路特征:全局说话人嵌入 e(utterance-level embedding,编码整体身份信息)和帧级特征矩阵 H(frame-level features,保留局部时序动态)。冻结编码器的设计避免了对已有说话人判别能力的破坏。
② 层次化 Speaker Tokenizer:这是本文的核心模块,负责将两路特征转换为 LLM 可理解的 token 序列。两路处理并行进行:
- MLP 分支(Embedding-level):将全局嵌入 e 经多层感知机映射,生成 16 个 embedding-level speaker token,主要编码说话人身份和侧写信息。
- Q-Former 分支(Sequence-level):以 H 作为 Key/Value,通过可学习的 Query 动态聚合帧级信息,生成 32 个 sequence-level speaker token,擅长捕获音高、音色亮度、混响等局部声学描述子。
- 两路合并后每句话产生 48 个 speaker token,插入 LLM 的提示词固定槽位中。
③ LLM 推理(Qwen2.5-1.5B-Instruct + LoRA):48 个 speaker token 作为上下文条件,配合自然语言问题,驱动 LLM 生成结构化的自然语言回答。LoRA 参数设置为 rank=16、alpha=32、dropout=0.05,以极低参数量完成领域适配。
任务体系设计
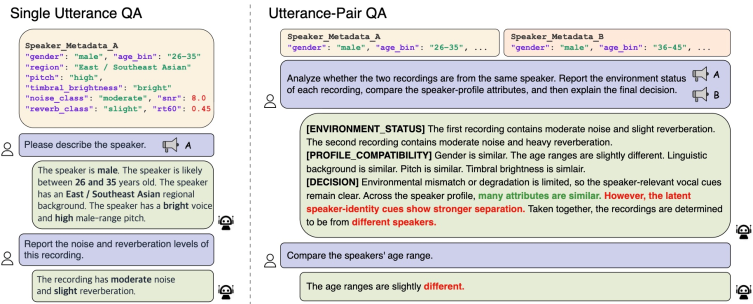
▲ 任务图详解:
这张图展示了 SpeakerLLM 支持的完整任务体系,分两大类:
单句任务(Single-Utterance):输入单段录音,回答关于说话人本身的问题。
- 说话人侧写 QA:包括性别(2类)、年龄(10个区间,从"1-7岁"到"76岁以上")、地区(8类)、音高(5级:very low → very high)、音色亮度(5级:muted → brilliant)。
- 录音环境 QA:噪声等级(5级,按 SNR 划分,≥20dB 为 clean,<0dB 为 extreme)、混响等级(5级,按 RT60 划分,≤0.3s 为 minimal,>1.5s 为 extreme)。
跨句对比任务(Utterance-Pair):输入两段录音,完成以下任务:
- 标准说话人验证(SV):判断是否同一人(短答模式)。
- 属性兼容性 QA:两段录音的侧写属性是否一致?
- 三段式验证推理(SV-R):最复杂的任务,强迫模型按
environment_status → profile_compatibility → decision的三块格式输出,先说环境、再说侧写线索、最后给出验证结论。
这套任务体系设计精心——越简单的任务越有利于训练早期稳定收敛,越复杂的推理任务在后期再引入,体现了课程式的训练哲学。
关键技术点
技术点一:层次化 Speaker Tokenizer
是什么:一个双分支适配器,MLP 处理全局嵌入(输出 16 token),Q-Former 处理帧级特征(输出 32 token),两路 concat 共 48 token。
为什么有效:论文的消融实验(Table 3)给出了直接证据——单用 MLP 时说话人验证准确率为 86.5%,单用 Q-Former 为 84.7%,而两者结合达到 95.6%。关键分歧在于细粒度任务:MLP 在音高分类上只有 57.4%,Q-Former 达到 70.0%——Q-Former 的时序聚合能力使它更擅长捕捉音高等动态特征。两者互补,缺一不可。
与已有方法的区别:以往 Audio-LLM(如 Qwen2.5-Omni)通常用单一线性层或简单 MLP 对接音频特征,缺乏针对说话人多粒度证据的专门设计。即使是 SA-TinyLLaMA 等说话人专用模型,也仅停留在单一适配器层面。
技术点二:三块式验证推理目标(SV-R)
是什么:强制 LLM 按照固定格式输出验证推理过程:
[ENVIRONMENT] 两段录音的环境状态描述
[PROFILE] 侧写相似性分析(涵盖性别/年龄/音高等)
[DECISION] 最终同一人/不同人判断
为什么有效:这种设计迫使模型显式分离"环境因素"和"声纹因素",避免混响/噪声干扰导致的误判。实验中,在"侧写相似却是不同人"这类最难的"反转样本"上,SV-R 比普通 SV 准确率高 +1.47%(78.53% → 80.00%)。
与已有方法的区别:传统 SV 只给分数,不给理由。即使是 GPT-4o 这类大模型,也无法保证输出格式的结构化。SpeakerLLM-VR 的格式合法率达到 100%,侧写属性基础率达到 72.7%。
技术点三:两阶段渐进式训练
Stage 1:说话人理解训练,分两小阶段。
- 第一阶段(126k steps):冻结编码器和 LLM,仅训练 Tokenizer,用简短问答目标做热身(warm-up)。
- 第二阶段(83k steps):引入 LoRA,解冻 LLM 适配器,使用更复杂的句子级目标。
Stage 2:验证推理精调(221k steps),专注三块式推理格式和属性兼容性 QA,同时以 Stage 1 任务做回放(replay),防止灾难性遗忘。
消融结果(Table 6)证明 warm-up 至关重要:没有 warm-up 时 SV 准确率仅 91.20%,有 warm-up 后提升到 96.05%。顺序训练而非立即混合也带来 SV-R 从 91.71% 提升到 97.12%。
📊 实验结果
说话人理解任务对比(VoxCeleb1-O + LibriTTS-R)
| 任务 | SpeakerLLM-Base(1.5B) | Qwen2.5-Omni-7B | Audio Flamingo3 |
|---|---|---|---|
| 说话人验证(SV) | 96.1% | 65.2% | 54.5% |
| 性别 | 99.9% | 99.8% | 99.9% |
| 年龄 | 39.8% | 17.5% | 23.2% |
| 地区 | 83.1% | 76.0% | 59.8% |
| 音高 | 72.4% | 22.7% | 22.1% |
| 音色亮度 | 54.2% | 25.0% | 38.3% |
| 噪声等级 | 52.7% | 20.4% | 21.2% |
| 混响等级 | 51.7% | 20.2% | 21.0% |
📌 关键数据:SpeakerLLM-Base(仅 1.5B 参数)在 SV 上以 96.1% 碾压 7 倍大的 Qwen2.5-Omni-7B(65.2%),说明说话人专业化设计远比模型规模更关键。
适配器消融:为什么层次化 Tokenizer 不可缺(Table 3)
| 适配器设计 | SV | 性别 | 年龄 | 地区 | 音高 | 亮度 | 噪声 | 混响 |
|---|---|---|---|---|---|---|---|---|
| Linear | 49.1% | 77.3% | 16.3% | 49.5% | 17.3% | 18.1% | 23.9% | 22.8% |
| 仅 MLP | 86.5% | 99.1% | 30.2% | 78.1% | 57.4% | 41.3% | 32.6% | 32.5% |
| 仅 Q-Former | 84.7% | 99.3% | 32.2% | 74.4% | 70.0% | 51.0% | 48.9% | 45.6% |
| MLP + Q-Former(本文) | 95.6% | 99.7% | 39.5% | 79.8% | 72.3% | 53.1% | 47.7% | 50.0% |
验证推理准确率:按样本类型细分(Table 5)
| 子集类型 | SV(无推理) | SV-R(有推理) | 差值 |
|---|---|---|---|
| 整体 | 96.79% | 97.12% | +0.33% |
| 不同说话人 | 94.25% | 95.20% | +0.96% |
| 相同说话人 | 99.32% | 98.03% | -0.30% |
| 侧写相似→实为不同人(最难) | 78.53% | 80.00% | +1.47% |
| 侧写冲突→实为同人 | 99.11% | 98.58% | -0.53% |
消融实验亮点
Tokenizer Warm-Up 的影响(Table 6a):不做热身的 SV 准确率为 91.20%,做热身后为 96.05%,提升 +4.85%。热身阶段让 Tokenizer 在 LLM 的语言空间中"找到锚点",是后续训练稳定的基础。
顺序训练 vs 立即混合(Table 6b):在说话人理解任务上立即混入推理目标(immediate mixing)会导致 SV-R 仅 91.71%;而先完成 Stage 1 再进入 Stage 2 的顺序课程,SV-R 达到 97.12%,提升 +5.41%,代价是整体 SV 略降 0.30%(可接受的权衡)。
💡 个人点评
优势:设计极其专注——不试图做"通用大模型",而是把说话人验证这件事做深做透。层次化 Tokenizer 的双分支设计思路清晰,消融实验充分,结论可信。在 SV 上以 1.5B 参数模型压倒 7B 的通用模型,工程价值明确。
局限:目前只在 VoxCeleb1(英语为主,录音棚条件)和 LibriTTS-R(朗读风格)上评测,真实场景的鲁棒性(电话信道、方言、多人重叠语音)尚未验证。论文也坦承,推理链的"忠实性"依赖有监督的 schema 约束,并不代表模型真正理解了因果关系。
工程价值:三块式输出格式(环境→侧写→决策)对工业落地极有参考价值——当系统给出错误判断时,工程师可以直接定位是"环境问题"还是"声纹本身相似",大幅降低排查成本。适配器部分(MLP + Q-Former)可单独移植到其他 Audio-LLM 中,无需重新训练整个模型。
未来方向:论文已指出多个值得追进的方向:扩展到多语言和口音、引入真实噪声远场录音、研究隐私保护推理(无需暴露原始音频)。另一个有趣的扩展是将三块式推理链用于主动学习——模型输出置信度低的推理链可自动标注为"需人工审核"样本。
🔗 资源链接
- 📄 论文链接:arxiv.org/abs/2605.15044
- 💾 代码/数据集:论文承诺将开源数据集和目标构建代码,尚未发布
- 🎯 相关论文推荐:
- ReDimNet(本文使用的说话人编码器):arxiv.org/abs/2406.07946
- Q-Former 原始论文 BLIP-2:arxiv.org/abs/2301.12597
- SA-TinyLLaMA(另一说话人专用 LLM,可对比):arxiv.org/abs/2408.10879
Speech AI · FRONTIER · 论文精读系列 · 第 001 期
关注公众号获取最新语音 AI 论文解读
本文由 AI 辅助整理,论文解读与技术点评由作者完成。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)