工业级大模型学习之路014:RAG零基础入门教程(第九篇):系统性能与资源优化
一、本地 RAG 的性能瓶颈与优化方向
1.1 本地 RAG 三大性能瓶颈深度解析
本地 RAG 与云服务 RAG 的性能瓶颈完全不同,云服务的瓶颈主要在网络和并发,而本地 RAG 的瓶颈全部集中在单机资源上。
瓶颈 1:内存瓶颈(最致命)
一个完整的本地 RAG 系统需要同时加载:
- BGE 嵌入模型:~1GB(FP16)
- BGE 重排序模型:~2GB(FP16)
- 7B 大模型:~13GB(FP16)
- 向量库索引:~1GB/10 万分块
- 系统和其他应用:~4-5GB
结论:如果不做任何优化,16G 内存绝对会爆内存,系统会卡死或闪退。这也是为什么我们必须使用 4bit 量化的根本原因。
瓶颈 2:计算瓶颈(最影响体验)
本地 CPU 的推理速度远低于 GPU,一个 7B 模型在普通 CPU 上的生成速度只有 5-10 tokens/s,而一次完整的 RAG 请求需要:
- 嵌入计算:~100ms
- 向量检索:~50ms
- 重排序:~200ms
- 查询优化:~1s
- 回答生成:~2-5s
结论:总响应时间在 3-6 秒以上,用户体验很差。
瓶颈 3:IO 瓶颈(最容易被忽略)
- 模型加载时间:首次加载 7B 模型需要 10-30 秒
- 向量库加载时间:10 万分块需要 5-10 秒
- 磁盘读写速度:机械硬盘会比固态硬盘慢 10 倍以上
结论:首次启动和首次查询的等待时间过长,严重影响用户体验。
1.2 量化技术全解(本地环境专属)
量化是将模型的权重从高精度(FP16/FP32)转换为低精度(4bit/8bit)的技术,可以在几乎不损失效果的前提下,大幅降低内存占用和提升推理速度。
本地环境最优选择:bitsandbytes 4bit 量化
- 对 CPU 的支持最好
- 效果损失最小
- 不需要额外的模型转换步骤
- 可以直接加载 Hugging Face 上的原生模型
量化的核心原理
量化不是简单的数值截断,而是通过量化感知训练(QAT)或后训练量化(PTQ),将权重映射到低精度空间,同时保留模型的语义信息。bitsandbytes 使用的是 **NF4(Normalized Float 4bit)** 数据类型,这是目前效果最好的 4bit 量化格式。
1.3 缓存机制设计原理
缓存是提升系统性能最有效的方法之一,它可以避免重复计算,将响应时间从秒级降低到毫秒级。
RAG 系统的可缓存点
| 缓存对象 | 计算耗时 | 缓存命中率 | 优化效果 |
|---|---|---|---|
| 嵌入向量 | 高 | 高 | 非常显著 |
| 检索结果 | 中 | 中 | 显著 |
| 查询优化结果 | 高 | 中 | 显著 |
| 常见问题回答 | 低 | 低 | 一般 |
多级缓存体系设计
工业界标准的 RAG 缓存体系采用三级结构:
- L1 内存缓存:使用 LRU 算法缓存最近最常使用的数据,访问速度极快(微秒级),但容量有限
- L2 磁盘缓存:使用 SQLite 或 LevelDB 缓存不常使用的数据,访问速度较快(毫秒级),容量大
- L3 预计算缓存:提前计算所有文档的嵌入向量和常见查询的结果,访问速度最快,但更新成本高
LRU 缓存淘汰算法
LRU(Least Recently Used)算法的核心思想是:最近最少使用的数据最先被淘汰。它非常适合 RAG 系统,因为用户的查询往往具有时间局部性,最近查询过的内容很可能会再次被查询。
1.4 本地模型推理加速技术
除了量化之外,还有几种可以显著提升本地模型推理速度的技术:
1. CPU 指令集优化
现代 CPU 支持 AVX2、AVX512 等高级指令集,可以大幅提升矩阵运算的速度。PyTorch 2.0 以上版本会自动检测并使用这些指令集。
2. ONNX Runtime 加速
ONNX Runtime 是微软开发的跨平台推理引擎,可以将 PyTorch 模型转换为 ONNX 格式,并进行各种优化,推理速度可以提升 30%-50%。
3. 批量处理优化
将多个请求合并成一个批量进行处理,可以大幅提升系统的吞吐量。对于 RAG 系统来说,嵌入计算和重排序是最适合批量处理的环节
二、核心代码实现
2.1 BGE 系列模型 4bit 量化加载
对于 BGE 这种小模型(BGE-large-zh-v1.5 只有 1.3GB),完全不需要量化!原生加载也只需要 1.5GB 左右内存
2.2 实现多级缓存机制
我们将实现一个两级缓存系统:内存缓存(LRU)+ 磁盘缓存(SQLite),并为嵌入计算、检索结果、查询重写添加缓存。
2.2.1 实现通用缓存工具类
新建文件cache_utils.py,复制以下代码:
import json
import sqlite3
from functools import lru_cache, wraps
from pathlib import Path
import hashlib
import time
class CacheManager:
def __init__(self, cache_dir="./cache", max_memory_cache_size=1000, ttl=86400):
"""
初始化缓存管理器
:param cache_dir: 缓存目录
:param max_memory_cache_size: 内存缓存最大条目数
:param ttl: 缓存过期时间(秒),默认24小时
"""
self.cache_dir = Path(cache_dir)
self.cache_dir.mkdir(exist_ok=True)
self.max_memory_cache_size = max_memory_cache_size
self.ttl = ttl
# 初始化磁盘缓存数据库
self.db_path = self.cache_dir / "cache.db"
self._init_db()
def _init_db(self):
"""初始化SQLite数据库"""
conn = sqlite3.connect(self.db_path)
c = conn.cursor()
c.execute('''
CREATE TABLE IF NOT EXISTS cache (
key TEXT PRIMARY KEY,
value TEXT,
timestamp INTEGER
)
''')
conn.commit()
conn.close()
def _get_key(self, *args, **kwargs):
"""生成缓存键"""
key_str = str(args) + str(sorted(kwargs.items()))
return hashlib.md5(key_str.encode()).hexdigest()
def memory_cache(self, func):
"""内存缓存装饰器"""
@lru_cache(maxsize=self.max_memory_cache_size)
@wraps(func)
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
return wrapper
def disk_cache(self, func):
"""磁盘缓存装饰器"""
@wraps(func)
def wrapper(*args, **kwargs):
key = self._get_key(func.__name__, *args, **kwargs)
# 先查内存缓存
if hasattr(wrapper, 'memory_cache'):
result = wrapper.memory_cache.get(key)
if result is not None:
return result
# 再查磁盘缓存
conn = sqlite3.connect(self.db_path)
c = conn.cursor()
c.execute('SELECT value, timestamp FROM cache WHERE key = ?', (key,))
row = c.fetchone()
conn.close()
if row is not None:
value, timestamp = row
# 检查是否过期
if time.time() - timestamp < self.ttl:
result = json.loads(value)
# 存入内存缓存
if hasattr(wrapper, 'memory_cache'):
wrapper.memory_cache[key] = result
return result
# 缓存未命中,执行函数
result = func(*args, **kwargs)
# 存入磁盘缓存
conn = sqlite3.connect(self.db_path)
c = conn.cursor()
c.execute(
'REPLACE INTO cache (key, value, timestamp) VALUES (?, ?, ?)',
(key, json.dumps(result), int(time.time()))
)
conn.commit()
conn.close()
# 存入内存缓存
if hasattr(wrapper, 'memory_cache'):
wrapper.memory_cache[key] = result
return result
# 初始化内存缓存字典
wrapper.memory_cache = {}
return wrapper
def clear_expired(self):
"""清理过期缓存"""
conn = sqlite3.connect(self.db_path)
c = conn.cursor()
c.execute('DELETE FROM cache WHERE timestamp < ?', (int(time.time()) - self.ttl,))
deleted = c.rowcount
conn.commit()
conn.close()
print(f"✅ 清理了 {deleted} 条过期缓存")
def clear_all(self):
"""清空所有缓存"""
conn = sqlite3.connect(self.db_path)
c = conn.cursor()
c.execute('DELETE FROM cache')
conn.commit()
conn.close()
# 清空内存缓存
self.memory_cache.cache_clear()
print("✅ 所有缓存已清空")
# 全局缓存管理器实例
cache_manager = CacheManager()2.2.2 为核心功能添加缓存
现在我们为最耗时的三个功能添加缓存:
1. 为嵌入计算添加缓存
在QuantizedBGEEmbedding类的__call__方法上添加缓存装饰器:
from cache_utils import cache_manager
@cache_manager.disk_cache
def __call__(self, texts):
# 原有代码不变2. 为检索功能添加缓存
在HybridRetriever类的semantic_search和bm25_search方法上添加缓存装饰器:
from cache_utils import cache_manager
@cache_manager.disk_cache
def semantic_search(self, query, top_k=20):
# 原有代码不变
@cache_manager.disk_cache
def bm25_search(self, query, top_k=20):
# 原有代码不变3. 为查询重写添加缓存
在QueryOptimizer类的rewrite_query和generate_multiple_queries方法上添加缓存装饰器:
from cache_utils import cache_manager
@cache_manager.disk_cache
def rewrite_query(self, query: str) -> str:
# 原有代码不变
@cache_manager.disk_cache
def generate_multiple_queries(self, query: str, num_queries: int = 4) -> list:
# 原有代码不变2.3 模型按需加载与自动卸载
为了进一步节省内存,我们实现模型的懒加载和自动卸载功能,只有在使用模型时才将其加载到内存,空闲一段时间后自动卸载。
2.3.1 实现懒加载装饰器
在cache_utils.py中添加以下代码:
import threading
def lazy_load(func):
"""懒加载装饰器:只有在第一次调用时才加载模型"""
@wraps(func)
def wrapper(self, *args, **kwargs):
# 检查模型是否已经加载
model_attr = f"_{func.__name__}_model"
if not hasattr(self, model_attr) or getattr(self, model_attr) is None:
print(f"正在懒加载模型:{func.__name__}")
model = func(self, *args, **kwargs)
setattr(self, model_attr, model)
# 启动自动卸载线程
if not hasattr(self, '_unload_timer'):
self._unload_timer = None
self._last_access_time = time.time()
def auto_unload():
while True:
time.sleep(60) # 每分钟检查一次
if time.time() - self._last_access_time > 300: # 5分钟空闲
if hasattr(self, model_attr) and getattr(self, model_attr) is not None:
print(f"自动卸载模型:{func.__name__}")
delattr(self, model_attr)
# 强制垃圾回收
import gc
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
time.sleep(1)
threading.Thread(target=auto_unload, daemon=True).start()
# 更新最后访问时间
self._last_access_time = time.time()
return getattr(self, model_attr)
return wrapper2.3.2 改造大模型客户端
修改llm_client.py,使用懒加载装饰器:
from cache_utils import lazy_load
class LLMClient:
def __init__(self, model_path: str = LLM_MODEL_PATH, device: str = "cpu"):
self.model_path = Path(model_path)
self.device = device
self.tokenizer = None
self._generate_model = None # 模型属性改为私有,带下划线
@lazy_load
def _generate_model(self):
"""懒加载大模型"""
try:
print(f"正在加载本地大模型:{self.model_path.resolve()}")
tokenizer = AutoTokenizer.from_pretrained(
str(self.model_path.resolve()),
trust_remote_code=True
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
str(self.model_path.resolve()),
torch_dtype=torch.float32,
load_in_4bit=True,
trust_remote_code=True
).to(self.device)
print("✅ 本地大模型加载成功!")
return (tokenizer, model)
except Exception as e:
print(f"❌ 本地大模型加载失败!")
print(traceback.format_exc())
raise RuntimeError("本地大模型加载失败") from e
def generate(self, prompt: str, max_new_tokens: int = 512, temperature: float = 0.1) -> str:
# 获取懒加载的模型和tokenizer
tokenizer, model = self._generate_model()
inputs = tokenizer(
prompt,
return_tensors="pt",
truncation=True,
max_length=2048
).to(self.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
do_sample=False,
pad_token_id=tokenizer.pad_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response[len(prompt):].strip()三、性能测试与调优
3.1 基准性能测试
首先,建立优化前的性能基准线。创建文件performance_test.py:
# _*_ coding : utf-8 _*_
# @Time : 2026/5/17 10:11
# @Author : 田恩辉
# @File : performance_test_20260517
# @Project : LLM
import time
import psutil
import json
from 完整的混合检索技术_20260505 import HybridRetriever
from rag_core import RAGSystem
def load_chunks():
chunks = []
with open("processed_chunks.jsonl", 'r', encoding='utf-8') as f:
for line in f:
chunks.append(json.loads(line))
return chunks
def measure_performance(func, *args, **kwargs):
"""测量函数的执行时间和内存占用"""
process = psutil.Process()
start_memory = process.memory_info().rss / 1024 / 1024 # MB
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
end_memory = process.memory_info().rss / 1024 / 1024 # MB
duration = end_time - start_time
memory_used = end_memory - start_memory
return result, duration, memory_used
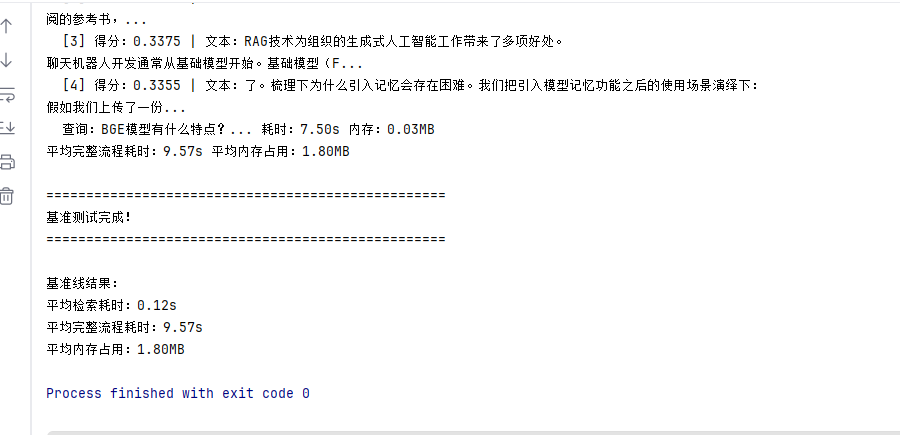
def run_benchmark():
print("=" * 50)
print("RAG系统性能基准测试")
print("=" * 50)
chunks = load_chunks()
print(f"测试数据集:{len(chunks)} 个文档分块")
# 测试查询集
test_queries = [
"什么是RAG技术?",
"RAG的工作流程是什么?",
"如何优化RAG系统的性能?",
"什么是向量检索?",
"BGE模型有什么特点?"
]
print("\n1. 测试检索性能")
retriever = HybridRetriever(chunks, device="cpu")
total_retrieval_time = 0
total_retrieval_memory = 0
for query in test_queries:
_, duration, memory = measure_performance(
retriever.advanced_search, query, top_k=5
)
total_retrieval_time += duration
total_retrieval_memory += memory
print(f" 查询:{query[:30]}... 耗时:{duration:.2f}s 内存:{memory:.2f}MB")
avg_retrieval_time = total_retrieval_time / len(test_queries)
avg_retrieval_memory = total_retrieval_memory / len(test_queries)
print(f"平均检索耗时:{avg_retrieval_time:.2f}s 平均内存占用:{avg_retrieval_memory:.2f}MB")
print("\n2. 测试完整RAG流程性能")
rag = RAGSystem()
total_rag_time = 0
total_rag_memory = 0
for query in test_queries:
_, duration, memory = measure_performance(
rag.query, query, top_k=5
)
total_rag_time += duration
total_rag_memory += memory
print(f" 查询:{query[:30]}... 耗时:{duration:.2f}s 内存:{memory:.2f}MB")
avg_rag_time = total_rag_time / len(test_queries)
avg_rag_memory = total_rag_memory / len(test_queries)
print(f"平均完整流程耗时:{avg_rag_time:.2f}s 平均内存占用:{avg_rag_memory:.2f}MB")
print("\n" + "=" * 50)
print("基准测试完成!")
print("=" * 50)
return {
"avg_retrieval_time": avg_retrieval_time,
"avg_retrieval_memory": avg_retrieval_memory,
"avg_rag_time": avg_rag_time,
"avg_rag_memory": avg_rag_memory
}
if __name__ == "__main__":
baseline = run_benchmark()
print("\n基准线结果:")
print(f"平均检索耗时:{baseline['avg_retrieval_time']:.2f}s")
print(f"平均完整流程耗时:{baseline['avg_rag_time']:.2f}s")
print(f"平均内存占用:{baseline['avg_rag_memory']:.2f}MB")3.2 优化效果验证
依次实现优化措施,每实现一个就运行一次基准测试,记录优化效果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)