处理器——流水线概述
文章目录
流水线
流水线(pipelining)技术是一种在处理器设计和其他领域中广泛采用的并行处理技术,其核心思想是在程序执行期间,通过将指令处理过程分解为多个连续的阶段(如取指、译码、执行、访存和写回等),使得多条指令能够在不同阶段上同时执行,尽管每个单独的指令仍然按照顺序完成这些阶段。这种重叠执行的方式显著提高了处理器的吞吐量和效率,允许在一个时钟周期内启动多条指令的不同部分,从而加速了整体的计算过程。
:::
流水线结构
基于基本的指令处理步骤(取指、译码、执行、访存和写回),可以构建一个简单的流水线结构,各阶段对应与各步骤。
⚠️实际处理器的流水线可能更加复杂,包括更多预取、分支预测等高级功能,但这里专注于基础概念。
| 阶段名称 | 核心定义与执行过程 | 核心功能 |
|---|---|---|
| 1. 取指 (Instruction Fetch, IF) | 处理器从内存中读取下一条指令。通常,处理器会有一个程序计数器(PC),它指向当前正在执行指令的下一条指令的地址。处理器根据PC的值从内存中取出指令,并将其放入指令缓存或队列中准备解码。 | 从内存中读取下一条指令。 |
| 2. 译码/寄存器读取 (Instruction Decode/Register Fetch, ID) | 处理器在这一阶段对取指阶段获取的指令进行解码,确定指令的操作类型(如加法、减法、跳转等)、操作数以及目标寄存器。同时,如果指令需要用到寄存器中的数据,这一阶段还会从寄存器文件中读取这些数据作为操作数。 | 解析取出的指令,确定操作类型、操作数等信息。 |
| 3. 执行 (Execution, EX) | 根据指令的操作类型,实际的运算在这个阶段执行。例如,如果是加法指令,ALU(算术逻辑单元)会执行加法运算。如果指令包含条件转移或逻辑运算,相应的逻辑处理也会在此阶段完成。 | 根据指令执行相应的算术逻辑运算。 |
| 4. 存储器访问 (Memory Access, MEM) | 如果指令涉及内存访问,比如加载(LOAD)或存储(STORE)操作,这一阶段会与内存交互。对于LOAD指令,从内存中读取数据;对于STORE指令,则是将数据写入内存。并非所有指令都需要这一阶段,比如纯粹的寄存器到寄存器操作就不需要访问内存。 | 对于涉及内存访问的指令,进行读/写操作。 |
| 5. 写回 (Write Back, WB) | 在最后一个阶段,计算或加载得到的结果会被写回到寄存器文件中,或者在某些情况下(如STORE指令执行后),确认数据已正确写入内存。这个阶段标志着指令执行的完成,之后处理器可以开始处理下一条指令。 | 将执行或访存阶段的结果写入寄存器或更新PC(对于分支指令)。 |
计算流水线
单周期模型 vs 流水线模型
1. 硬件延迟基础设定
- 存储器访问: $ 200,\text{ps} $
- ALU操作: $ 200,\text{ps} $
- 寄存器读写: $ 100,\text{ps} $
基于此,不同指令在单周期非流水线下的总耗时(时延)如下:
- 载入指令 (lw): 取指($ 200 ) + 译码 ( ) + 译码( )+译码( 100 ) + A L U ( ) + ALU( )+ALU( 200 ) + 访存 ( ) + 访存( )+访存( 200 ) + 写回 ( ) + 写回( )+写回( 100 $) = $ 800,\text{ps} $
- 分支指令 (beq): 取指($ 200 ) + 译码 ( ) + 译码( )+译码( 100 ) + A L U ( ) + ALU( )+ALU( 200 $) = $ 500,\text{ps} $
单周期痛点: 时钟周期由最慢的指令(如
lw的 $ 800,\text{ps} $)决定。即使执行只需 $ 500,\text{ps} $ 的beq,也必须等待满 $ 800,\text{ps} $,导致严重的资源浪费。
2. 流水线模型改造
将指令执行划分为 5 级流水线(IF, ID, EX, MEM, WB)。根据木桶效应,流水线的时钟周期由耗时最长的那一级(瓶颈阶段)决定。
- 图中各阶段的最长耗时为 200 ps 200\,\text{ps} 200ps。
- 因此,该流水线的**时钟周期被锁定为 200 ps 200\,\text{ps} 200ps。
流水线性能核心公式
流水线的目标是用更短的时钟周期换取更高的吞吐量(Throughput),虽然单条指令的延迟(Latency)可能会因为流水线寄存器的引入而略微增加。
通用执行时间公式
在一个包含 $ k $ 级流水线的处理器中,执行 $ n $ 条指令的总时间 $ T $ 为:
T = [ 流水线填满时间 ] + [ 后续指令执行时间 ] = ( k − 1 ) × τ + n × τ T = [\text{流水线填满时间}] + [\text{后续指令执行时间}] = (k - 1) \times \tau + n \times \tau T=[流水线填满时间]+[后续指令执行时间]=(k−1)×τ+n×τ
其中 τ \tau τ 为流水线时钟周期。
在图片实例中( k = 5 k = 5 k=5 级, τ = 200 ps \tau = 200\,\text{ps} τ=200ps):
- 填满流水线需要: ( 5 − 1 ) × 200 = 800 ps (5 - 1) \times 200 = 800\,\text{ps} (5−1)×200=800ps
- 当执行 n = 1,000,000 条指令时:
T 流水线 = 4 × 200 + 1 , 000 , 000 × 200 = 200 , 001 , 400 ps T_{\text{流水线}} = 4 \times 200 + 1,000,000 \times 200 = 200,001,400\,\text{ps} T流水线=4×200+1,000,000×200=200,001,400ps
加速比与极限性能分析
1. 实际加速比计算
对比非流水线(执行 1 , 000 , 000 1,000,000 1,000,000 条指令,按平均每条指令 800 ps 800\,\text{ps} 800ps 的保守或最坏情况计算):
- T 非流水线 = 1 , 000 , 000 × 800 ps + 微小偏差 = 800 , 002 , 400 ps T_{\text{非流水线}} = 1,000,000 \times 800\,\text{ps} + \text{微小偏差} = 800,002,400\,\text{ps} T非流水线=1,000,000×800ps+微小偏差=800,002,400ps
- 加速比(Speedup):
Speedup = T 非流水线 T 流水线 = 800 , 002 , 400 200 , 001 , 400 ≈ 4 \text{Speedup} = \frac{T_{\text{非流水线}}}{T_{\text{流水线}}} = \frac{800,002,400}{200,001,400} \approx \mathbf{4} Speedup=T流水线T非流水线=200,001,400800,002,400≈4
2. 理想极限与现实鸿沟
从公式可以推导,当指令数量 n → ∞ n\to\infty n→∞ 时,加速比的理论极限等于流水线级数 $ k $(本例中为 $ 5 $)。然而,图中实际算出的加速比为 4 4 4,并未达到理想的 5 5 5。
为什么无法达到完美加速比?(流水线的现实挑战)
- 阶段不均衡(Stage Mismatch): 流水线各阶段的延迟不可能完全相同(如寄存器读写只需 100 ps 100\,\text{ps} 100ps,但必须被迫等待 200 ps 200\,\text{ps} 200ps),这导致了硬件内部的“气泡”。
- 流水线冒险(Hazards):
- 数据冒险:后一条指令需要前一条指令尚未写回的数据。
- 控制冒险:分支指令(如
beq)预测失败时,必须清空流水线(Flush),导致之前的工作全部白费,严重拉低实际吞吐量。
- 寄存器开销(Overhead): 流水线各级之间需要插入暂存数据的锁存器,这些硬件本身会带来额外的延迟开销。
流水线局限性
不一致的划分
在理想的流水线模型中,每个阶段的延迟是完全相等的。但在实际硬件设计中,不同硬件单元(如译码器、ALU、内存访问)的物理延迟有着天壤之别。 流水线的时钟周期(Clock Cycle)由耗时最长的那一个阶段(即瓶颈阶段)决定。这意味着,即使其他阶段执行速度再快,也必须等待最慢的阶段完成后,流水线寄存器才能同步统一更新。
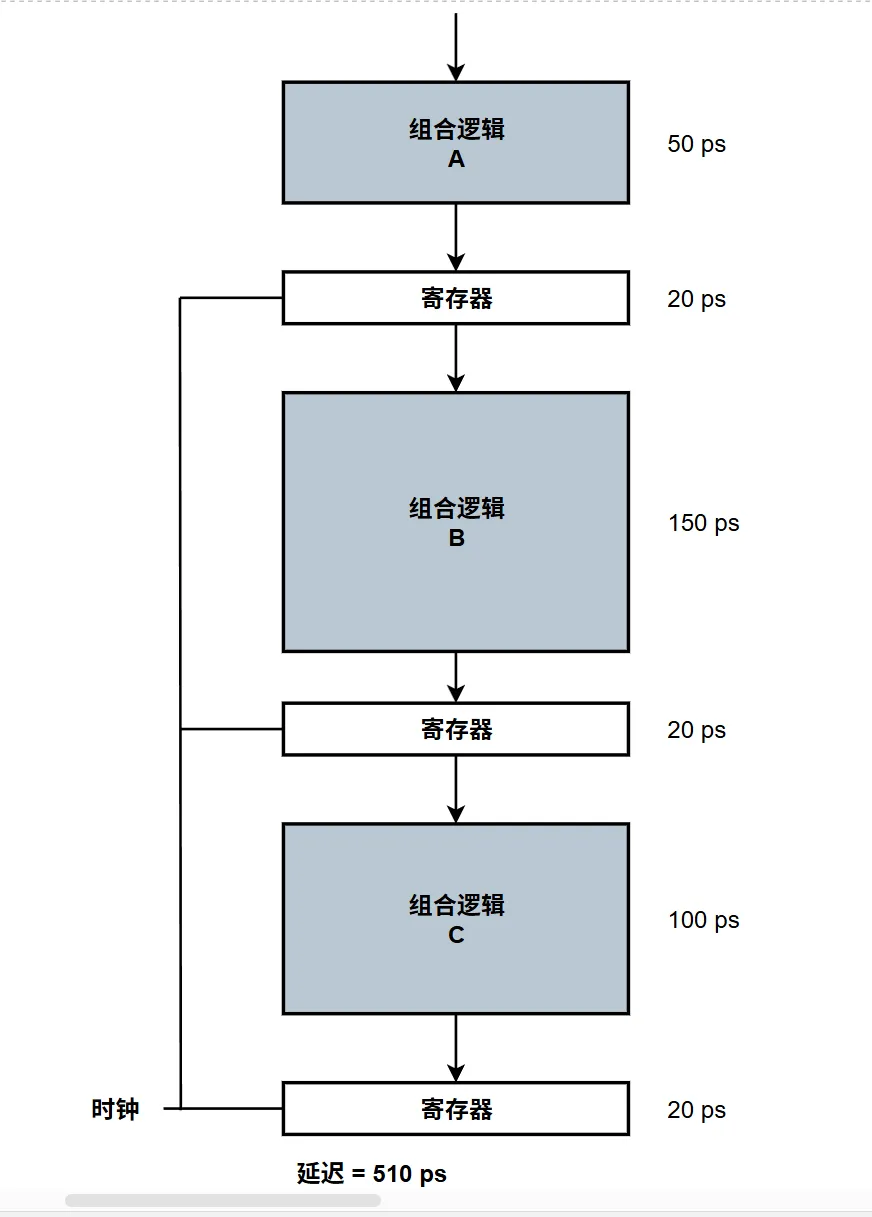
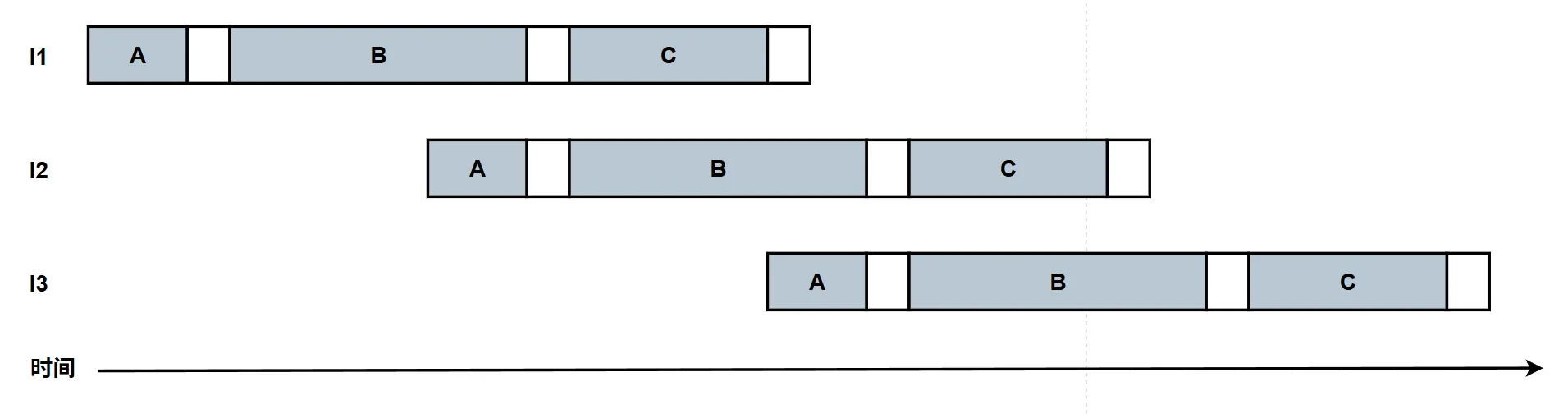
流水线过深,收益反而下降
既然增加流水线级数($ k $)可以压缩时钟周期、提升主频,那为什么现代 CPU(如 Intel Core 或 AMD Ryzen)的流水线级数普遍控制在 14~19 级左右,而不是无限切分到 50 级甚至 100 级呢?
当流水线过深时,有两个致命因素会导致性能不升反降:流水线寄存器的固有开销 (Latch Overhead) 和 控制冒险(Control Hazards)造成的惩罚激增。
物理局限:流水线寄存器的开销上限
为了在各阶段之间传递数据,每一级流水线之间必须插入流水线寄存器。
- 这些寄存器本身存在建立时间和传输延迟,合称为寄存器延迟 $ \delta $。
- 假设一个总延迟为 $ T $ 的逻辑,被切分为 $ k $ 级,那么实际的时钟周期为:$ \tau = \frac{T}{k} + \delta $
当 k k k 变得极大(流水线极深)时, T k \frac{T}{k} kT确实变得很小,但硬件寄存器的固有延迟 δ \delta δ 是固定不变的。此时,时钟周期将完全被寄存器开销统治,硬件纯粹在为搬运数据浪费功耗,加速比走向边际效应递减
逻辑局限:控制冒险(分支预测失败)的灾难
在执行分支跳转指令(如 if-else` 语句)时,处理器需要预测接下来执行哪段代码。
- 浅流水线(如 5 级): 分支指令在第 3 级(EX)就能确定结果。如果预测失败,只需要清空(Flush)前 2 级的指令,损失 2 个时钟周期。
- 深流水线(如 30 级): 分支指令可能要到第 15 级甚至更深才能确定结果。一旦预测失败,整个流水线中已经处于前 14 级的指令全部失效,必须彻底清空,损失高达 14 个以上的时钟周期!
随着流水线加深,每一次分支预测失败带来的时钟周期浪费呈指数级拉升,直接抵消了主频提升带来的所有收益。
:::
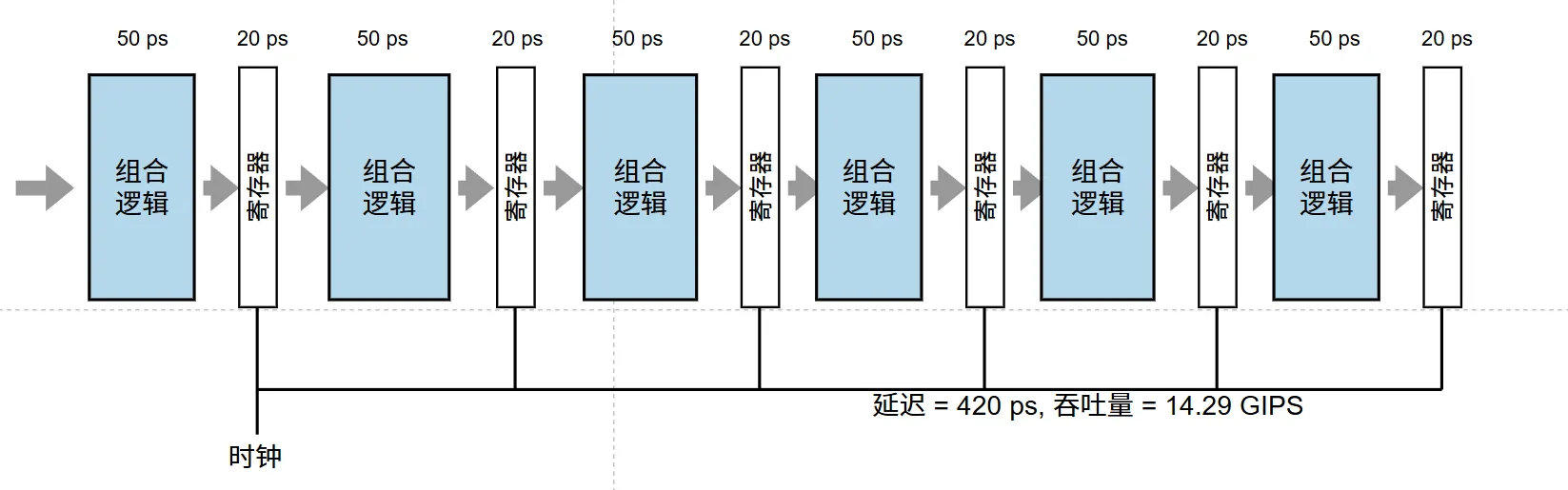
由开销造成的流水线技术的局限性。在组合逻辑被分成较小的块时,由寄存器更新引起的延迟就称为了限制因素

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)