Java 程序员第 17 阶段:大模型会话持久化:Redis 存储多轮对话实战
引言
在人工智能应用领域,大模型(Large Language Model,LLM)已经成为对话系统、智能助手、客服机器人等应用的核心技术。然而,大模型的上下文窗口(Context Window)是有限的,如何在有限的上下文中实现真正的多轮对话,同时保证用户体验的流畅性,成为了一个关键的技术挑战。
本文将深入探讨如何使用 Redis 实现大模型会话的持久化存储,从数据结构选型、存储结构设计、Spring Boot 集成、性能优化到安全加固,全方位解析多轮对话系统的后端存储架构。
一、为什么需要会话持久化
1.1 用户体验的必然要求
在传统 Web 应用中,用户的会话状态通常存储在服务器内存或 Session 中。但对于大模型对话场景,用户的对话历史可能包含数十轮甚至上百轮的交互内容,每轮对话的 Token 消耗可能达到数千甚至上万。如果每次用户发起新请求都需要重新加载完整的对话历史,那么:
首轮响应延迟问题:每次请求都需要重新构建上下文,导致首轮响应时间过长。根据业界数据,一个包含 20 轮对话历史的上下文构建可能需要消耗 100-500ms 的额外时间。
用户体验断层:如果对话历史因为服务器重启、服务扩容等原因丢失,用户将被迫重新开始对话,导致体验严重下降。特别是对于复杂问题的多轮解答场景,用户可能需要重复描述背景信息,造成极大的不便。
对话连贯性缺失:真正有价值的对话往往是多轮迭代的,用户可能会中途提问相关问题、澄清需求、补充信息等。如果会话无法持久化,系统就无法保持对话的连贯性和上下文的完整性。
1.2 系统架构解耦的需求
在大规模分布式系统中,会话持久化不仅是用户体验的问题,更是系统架构合理性的体现:
无状态服务的需要:现代微服务架构强调服务的无状态性。将会话状态外部化到 Redis,可以使得应用服务器随时进行水平扩展,而不需要考虑 Session 粘性或 Session 复制的问题。当用户下一次请求被路由到不同的服务器时,依然能够通过 Session ID 从 Redis 中获取完整的对话历史。
故障恢复能力:没有持久化的会话存储意味着服务器重启将导致所有会话数据丢失。通过将会话数据存储在 Redis 中,即使应用服务器发生故障,只要 Redis 集群本身高可用,用户的对话历史就不会丢失,系统可以快速恢复服务。
跨设备同步:现代用户可能同时使用多个设备访问服务。将会话数据存储在中央 Redis 集群中,可以轻松实现跨设备同步,用户在手机上开始的对话,可以在电脑上无缝继续。
资源合理利用:大模型的 Token 计算成本高昂,如果每次请求都重复发送完整的对话历史,将造成严重的资源浪费。持久化的会话存储允许我们只传输必要的上下文引用,由大模型服务自行从 Redis 中获取完整历史,实现资源的合理利用。
二、Redis 数据结构选型
图2:对话历史存储结构设计
Redis 提供了丰富的数据结构,选择合适的数据结构来存储会话数据是设计高效会话系统的关键。常见的可选方案包括 String、Hash、List 三种主要结构。
2.1 String 结构
String 是 Redis 最基本的数据结构,可以存储任意字符串,包括序列化的 JSON 对象。对于会话存储,String 结构的典型使用方式是将整个会话对象序列化为 JSON 后存储。
优势分析:
- 操作简单:SET/GET 操作语义清晰,代码实现简洁
- 功能丰富:支持 SETEX 的原子性设置带过期时间,支持 SETNX 的分布式锁场景
- 序列化灵活:可以使用 JSON、MessagePack、Protocol Buffers 等多种序列化方式
- 内存效率:对于小型会话数据,String 结构的内存开销相对较低
局限性:
- 更新粒度粗:每次更新都需要序列化/反序列化整个对象,当对话历史较长时性能开销大
- 读取效率低:获取会话中的某个字段(如只读取最后一条消息)需要反序列化整个对象
- 不支持部分更新:无法单独对会话中的某条消息进行更新或删除
2.2 Hash 结构
Hash 结构是 Redis 中用于存储对象的天然选择,它将一个 Redis Key 映射到一个字段-值的映射表,非常适合存储结构化的会话数据。
优势分析:
- 字段级操作:可以单独对会话的某个字段进行 GET/SET,如单独更新 user_id 或追加消息
- 内存优化:Redis 对 Hash 结构有特殊的内存优化(ziplist 和 hashtable 两种编码),在字段数量较少时内存效率很高
- 原子性保证:HSET、HGET 等操作是原子的,适合并发场景
- 查询友好:支持 HGETALL 获取所有字段,也支持 HKEYS、HVALS 获取键或值的列表
局限性:
- 字段数量限制:当 Hash 字段数量过多(超过一定阈值,通常是几百个)时,内存效率会下降
- 过期策略限制:Redis 的 Key 过期策略作用于整个 Key,不能单独为 Hash 中的某个字段设置过期时间
2.3 List 结构
List 结构是 Redis 中用于存储有序列表的数据结构,对于多轮对话这种每轮对话有序追加的场景非常契合。
优势分析:
- 消息追加高效:LPUSH/RPUSH 操作时间复杂度为 O(1),适合高频的对话消息追加
- 范围查询支持:LRANGE 可以方便地获取指定范围的对话消息
- 消息队列友好:适合实现消息的先进先出或先进后出模式
- 原子性操作:LPUSH 和 RPUSH 都是原子操作,支持并发安全
局限性:
- 随机访问效率低:LINDEX 操作时间复杂度为 O(N),不适合随机访问大量消息
- 不支持直接修改:无法直接修改 List 中的某个元素,需要通过 LSET 或 LREM 实现
- 内存开销:List 结构的每个元素都是独立的 Redis Object,内存开销比 String + JSON 略高
2.4 数据结构对比与选型建议
|
特性 |
String |
Hash |
List |
|
适用场景 |
完整会话对象存储 |
结构化会话字段存储 |
消息流式追加 |
|
更新效率 |
低(全量序列化) |
中(字段级更新) |
高(尾部追加) |
|
读取效率 |
高(整体读取) |
高(指定字段) |
中(范围读取) |
|
内存效率 |
中 |
高(字段少时) |
低(元素多时) |
|
会话长度 |
短对话(<20轮) |
中等对话(20-100轮) |
长对话(>100轮) |
|
过期策略 |
Key级别 |
Key级别 |
Key级别 |
综合建议:对于大多数场景,推荐采用 Hash + List 混合方案:
- 使用 Hash 存储会话元数据(user_id、session_id、创建时间、最后更新时间等)
- 使用 List 存储对话消息序列(每条消息作为一个独立元素)
- 关键会话信息使用 String 类型存储热点会话的摘要数据
三、对话历史的 JSON 结构设计
3.1 会话 Key 命名规范
良好的 Key 命名规范是构建可维护系统的基础。对于会话存储,推荐采用以下命名模式:
# 基础会话 Key
session:user:{userId}:conversation:{convId}
# 会话元数据
session:meta:{sessionId}
# 对话消息列表
session:messages:{sessionId}
# 用户上下文缓存
session:context:{sessionId}
# Token 计数缓存
session:token:{sessionId}
这种命名模式的优势在于:
- 层次清晰:通过冒号分隔不同级别的信息,便于阅读和理解
- 便于归类:可以使用 Redis 的 SCAN 命令配合模式匹配批量操作相关 Key
- 避免冲突:通过用户 ID 和会话 ID 的组合,避免不同用户会话的 Key 冲突
- 支持前缀扫描:生产环境应避免使用 KEYS 命令,使用 SCAN 结合前缀匹配更加安全
3.2 会话元数据结构
会话元数据 Hash 结构应该包含以下核心字段:
{
"session_id": "sess_abc123def456",
"user_id": "user_10001",
"conversation_id": "conv_20260515001",
"title": "Java并发编程问题咨询",
"model": "gpt-4",
"system_prompt": "你是一位资深的Java技术专家...",
"created_at": "2026-05-15T10:30:00Z",
"updated_at": "2026-05-15T14:22:35Z",
"last_active_at": "2026-05-15T14:22:35Z",
"message_count": 24,
"total_tokens": 15832,
"status": "active",
"expires_at": "2026-05-22T14:22:35Z"
}
关键字段的设计考量:
session_id:全局唯一标识,建议使用 UUID 或雪花算法生成,确保分布式环境下不会冲突。
status 状态机:会话应具有明确的状态流转。常见状态包括 active(活跃)、idle(空闲超过阈值)、archived(已归档)、deleted(已删除)。状态机的合理设计有助于实现会话的自动清理和归档策略。
expires_at:基于 updated_at 计算的过期时间点,每次会话更新时刷新。这个字段允许我们快速判断会话是否需要保留,避免扫描大量会话数据。
3.3 消息 JSON 结构
单条消息的结构设计需要考虑以下几个方面:
{
"role": "user",
"content": "如何解决Java并发编程中的死锁问题?",
"timestamp": 1715766155000,
"message_id": "msg_unique_id",
"metadata": {
"attachments": [],
"references": ["doc_001", "doc_002"],
"intent": "technical_question"
}
}
role 字段:大模型消息的标准角色包括 system(系统指令)、user(用户消息)、assistant(助手回复)。建议在系统设计中预留扩展角色,如 tool(工具调用)、function(函数调用)等。
timestamp 字段:使用毫秒级时间戳而非日期字符串,可以简化时间比较和范围查询的实现。同时支持分布式的多实例生成单调递增的时间戳。
metadata 扩展字段:预留 metadata 字段用于存储消息的附加信息,如附件列表、引用文档、用户意图识别结果等。这种设计使得消息结构具有良好的扩展性,未来可以方便地添加新的元数据而不需要修改现有代码。
3.4 分层存储策略
对于大型对话系统,单个会话可能包含数百甚至上千条消息。建议采用分层存储策略来优化性能:
热数据层:最近 20-50 条消息保持在 Redis List 的头部,这些是当前对话上下文的核心内容,访问频率最高。
温数据层:历史消息(50-200 条)存储在同一 Redis Key 的 List 尾部,当对话轮次增加时,渐进式地将早期消息移出上下文窗口但保留完整记录。
冷数据层:超过 200 条的早期对话可以异步归档到数据库(如 PostgreSQL 或 MongoDB),在需要时通过懒加载方式恢复。这种分层策略可以有效控制 Redis 的内存使用,同时保证历史数据的持久性和可查询性。
四、Spring Data Redis 集成与会话操作封装
4.1 依赖配置
在 Spring Boot 项目中使用 Redis,首先需要添加相关依赖:
<dependencies>
<!-- Spring Data Redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- Redis Connection Pool -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!-- JSON Processing -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<!-- Lombok for boilerplate reduction -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
4.2 配置文件
spring:
redis:
host: localhost
port: 6379
password: ${REDIS_PASSWORD:}
database: 0
timeout: 5000ms
lettuce:
pool:
max-active: 50
max-idle: 20
min-idle: 5
max-wait: 3000ms
jackson:
serialization:
write-dates-as-timestamps: false
default-property-inclusion: non_null
# 会话配置
session:
default-ttl: 30m
max-message-count: 500
context-window-size: 20
cleanup-cron: "0 0 2 * * ?"
4.3 会话实体类设计
@Data
@Builder
public class ChatSession {
private String sessionId;
private String userId;
private String conversationId;
private String title;
private String model;
private String systemPrompt;
private LocalDateTime createdAt;
private LocalDateTime updatedAt;
private LocalDateTime lastActiveAt;
private Integer messageCount;
private Long totalTokens;
private SessionStatus status;
private LocalDateTime expiresAt;
}
public enum SessionStatus {
ACTIVE, IDLE, ARCHIVED, DELETED
}
@Data
@Builder
public class ChatMessage {
private String messageId;
private MessageRole role;
private String content;
private Long timestamp;
private Map<String, Object> metadata;
}
public enum MessageRole {
SYSTEM, USER, ASSISTANT, TOOL, FUNCTION
}
4.4 会话服务封装
@Service
@RequiredArgsConstructor
public class RedisSessionService {
private final StringRedisTemplate redisTemplate;
private final ObjectMapper objectMapper;
private static final String SESSION_KEY_PREFIX = "session:meta:";
private static final String MESSAGE_KEY_PREFIX = "session:messages:";
private static final Duration DEFAULT_TTL = Duration.ofMinutes(30);
/**
* 创建新会话
*/
public ChatSession createSession(String userId, String systemPrompt) {
String sessionId = UUID.randomUUID().toString();
LocalDateTime now = LocalDateTime.now();
ChatSession session = ChatSession.builder()
.sessionId(sessionId)
.userId(userId)
.createdAt(now)
.updatedAt(now)
.lastActiveAt(now)
.expiresAt(now.plus(DEFAULT_TTL))
.status(SessionStatus.ACTIVE)
.systemPrompt(systemPrompt)
.messageCount(0)
.totalTokens(0L)
.build();
String key = SESSION_KEY_PREFIX + sessionId;
redisTemplate.opsForValue().set(key, session, DEFAULT_TTL);
return session;
}
/**
* 获取会话元数据
*/
public Optional<ChatSession> getSession(String sessionId) {
String key = SESSION_KEY_PREFIX + sessionId;
String json = redisTemplate.opsForValue().get(key);
if (json == null) {
return Optional.empty();
}
try {
return Optional.of(objectMapper.readValue(json, ChatSession.class));
} catch (JsonProcessingException e) {
log.error("Failed to deserialize session: {}", sessionId, e);
return Optional.empty();
}
}
/**
* 追加消息到会话
*/
public void appendMessage(String sessionId, ChatMessage message) {
String metaKey = SESSION_KEY_PREFIX + sessionId;
String msgKey = MESSAGE_KEY_PREFIX + sessionId;
// 使用 Pipeline 批量操作
redisTemplate.executePipelined((RedisCallback<Object>) connection -> {
// 序列化消息
byte[] msgBytes = objectMapper.writeValueAsBytes(message);
// RPUSH 到消息列表
connection.listCommands().rPush(msgKey.getBytes(), msgBytes);
// 更新元数据
String metaJson = connection.stringCommands().get(metaKey.getBytes());
if (metaJson != null) {
ChatSession session = objectMapper.readValue(metaJson, ChatSession.class);
session.setMessageCount(session.getMessageCount() + 1);
session.setUpdatedAt(LocalDateTime.now().toString());
session.setLastActiveAt(LocalDateTime.now().toString());
// 重新计算过期时间
long ttlSeconds = DEFAULT_TTL.getSeconds();
connection.stringCommands().setEx(metaKey.getBytes(),
objectMapper.writeValueAsBytes(session), ttlSeconds);
}
return null;
});
}
/**
* 获取最近 N 条消息
*/
public List<ChatMessage> getRecentMessages(String sessionId, int count) {
String msgKey = MESSAGE_KEY_PREFIX + sessionId;
// LRANGE 获取最后 count 条消息
List<byte[]> messages = redisTemplate.opsForList().range(msgKey.getBytes(), -count, -1);
if (messages == null || messages.isEmpty()) {
return Collections.emptyList();
}
return messages.stream()
.map(bytes -> {
try {
return objectMapper.readValue(bytes, ChatMessage.class);
} catch (JsonProcessingException e) {
log.error("Failed to deserialize message", e);
return null;
}
})
.filter(Objects::nonNull)
.collect(Collectors.toList());
}
/**
* 更新会话状态
*/
public void updateSessionStatus(String sessionId, SessionStatus status) {
String key = SESSION_KEY_PREFIX + sessionId;
redisTemplate.opsForHash().put(key, "status", status.name());
redisTemplate.expire(key, DEFAULT_TTL);
}
/**
* 刷新会话过期时间
*/
public void refreshSessionTTL(String sessionId) {
String key = SESSION_KEY_PREFIX + sessionId;
redisTemplate.expire(key, DEFAULT_TTL);
}
/**
* 删除会话(软删除)
*/
public void deleteSession(String sessionId) {
updateSessionStatus(sessionId, SessionStatus.DELETED);
}
}
4.5 会话操作最佳实践
Pipeline 批量操作:如上述代码所示,追加消息时应该使用 Pipeline 批量执行 Redis 命令,减少网络往返次数(Round Trip Time)。假设单次 RTT 为 1ms,追加消息需要执行 3 个命令(RPUSH + GET + SETEX),使用 Pipeline 可以将 3ms 降低到 1ms。
连接池配置:合理配置 Redis 连接池参数对于高并发场景至关重要。建议 max-active 设置为 CPU 核心数的 2-3 倍,max-idle 设置为 max-active 的 60-80%,确保在高并发时有足够的连接可用,同时避免过多的空闲连接浪费资源。
异常处理策略:Redis 操作应该设置合理的超时时间,并实现重试机制。建议使用 Spring Retry 或 Resilience4j 实现重试,同时记录详细的日志便于问题排查。对于关键的会话操作,可以使用分布式锁保证操作的原子性。
五、大模型上下文注入:如何从 Redis 恢复对话历史
5.1 上下文注入的原理
大模型的上下文注入(Context Injection)是将历史对话信息传递给模型的过程。不同的大模型 API(如 OpenAI GPT、Claude、国产大模型等)可能有不同的上下文管理机制,但核心原理是相似的:
对话格式构建:将历史消息按照特定的格式组织成 Prompt。常见的格式包括 ChatML(OpenAI)、JSON Messages(Claude)等。
Token 计数与截断:每个模型都有最大上下文长度(如 4K、8K、16K、128K tokens),需要根据模型能力计算可用空间,超出部分需要截断早期消息。
系统提示词注入:系统级指令(如角色设定、安全边界等)通常需要放在对话的最前面,在空间不足时最后才考虑截断。
5.2 上下文恢复服务实现
@Service
@RequiredArgsConstructor
@Slf4j
public class ContextInjectionService {
private final RedisSessionService sessionService;
private final TokenCounterService tokenCounter;
private static final Map<String, Integer> MODEL_MAX_TOKENS = Map.of(
"gpt-3.5-turbo", 4096,
"gpt-4", 8192,
"gpt-4-32k", 32768,
"claude-3-opus", 200000,
"claude-3-sonnet", 200000,
"ernie-4", 8192
);
/**
* 为指定会话构建完整的上下文 Prompt
*/
public String buildContextPrompt(String sessionId, String model) {
ChatSession session = sessionService.getSession(sessionId)
.orElseThrow(() -> new SessionNotFoundException(sessionId));
// 获取模型最大 Token 数
int maxTokens = MODEL_MAX_TOKENS.getOrDefault(model, 4096);
// 预留空间:系统提示词 + 模型回复 + 安全边界
int reservedTokens = 1000;
int availableTokens = maxTokens - reservedTokens;
// 构建消息列表
List<ChatMessage> messages = buildMessageList(session, availableTokens);
// 转换为模型特定格式
return formatMessages(messages, session.getSystemPrompt(), model);
}
/**
* 构建消息列表,根据 Token 限制进行截断
*/
private List<ChatMessage> buildMessageList(ChatSession session, int availableTokens) {
List<ChatMessage> allMessages = sessionService.getAllMessages(session.getSessionId());
// 计算系统提示词的 Token 数
int systemPromptTokens = tokenCounter.count(session.getSystemPrompt());
int tokensForMessages = availableTokens - systemPromptTokens;
// 从最新消息开始,逆向选择消息直到 Token 用完
List<ChatMessage> selectedMessages = new ArrayList<>();
int currentTokens = 0;
for (int i = allMessages.size() - 1; i >= 0 && currentTokens < tokensForMessages; i--) {
ChatMessage msg = allMessages.get(i);
int msgTokens = tokenCounter.count(msg.getContent());
if (currentTokens + msgTokens <= tokensForMessages) {
selectedMessages.add(0, msg); // 头部插入以保持顺序
currentTokens += msgTokens;
} else {
break; // Token 超出限制,停止添加
}
}
return selectedMessages;
}
/**
* 格式化消息为模型特定的格式
*/
private String formatMessages(List<ChatMessage> messages, String systemPrompt, String model) {
// 根据模型类型选择格式化方式
if (model.startsWith("gpt-")) {
return formatChatML(messages, systemPrompt);
} else if (model.startsWith("claude-")) {
return formatClaude(messages, systemPrompt);
} else {
return formatGeneric(messages, systemPrompt);
}
}
private String formatChatML(List<ChatMessage> messages, String systemPrompt) {
StringBuilder sb = new StringBuilder();
sb.append("<|im_start|>system\n").append(systemPrompt).append("<|im_end|>\n");
for (ChatMessage msg : messages) {
String roleName = msg.getRole().name().toLowerCase();
sb.append("<|im_start|>").append(roleName).append("\n");
sb.append(msg.getContent()).append("<|im_end|>\n");
}
return sb.toString();
}
private String formatClaude(List<ChatMessage> messages, String systemPrompt) {
StringBuilder sb = new StringBuilder();
sb.append("\n\nHuman: ").append(systemPrompt).append("\n\n");
for (ChatMessage msg : messages) {
String role = msg.getRole() == MessageRole.ASSISTANT ? "Assistant" : "Human";
sb.append(role).append(": ").append(msg.getContent()).append("\n\n");
}
sb.append("Assistant:");
return sb.toString();
}
}
5.3 Token 计数服务
@Service
public class TokenCounterService {
// GPT-2 分词器的 Java 实现(简化版)
// 生产环境建议使用 tiktoken-java 或 sentence-transformers
/**
* 估算文本的 Token 数量
* 经验公式:中文约 2 字符 ≈ 1 Token,英文约 4 字符 ≈ 1 Token
*/
public int count(String text) {
if (text == null || text.isEmpty()) {
return 0;
}
// 简化的估算方法
int chineseChars = 0;
int englishChars = 0;
for (char c : text.toCharArray()) {
if (Character.UnicodeBlock.of(c) == Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS) {
chineseChars++;
} else if (c < 128) {
englishChars++;
}
}
// 经验公式
return (int) Math.ceil(chineseChars / 2.0) + (int) Math.ceil(englishChars / 4.0);
}
/**
* 计算消息列表的总 Token 数
*/
public int countMessages(List<ChatMessage> messages) {
return messages.stream()
.mapToInt(msg -> count(msg.getContent()))
.sum();
}
}
5.4 与大模型 API 的集成
@Service
@RequiredArgsConstructor
@Slf4j
public class LLMChatService {
private final ContextInjectionService contextService;
private final RedisSessionService sessionService;
private final TokenCounterService tokenCounter;
private final RestTemplate restTemplate;
/**
* 发送消息并获取回复
*/
public ChatMessage chat(String sessionId, String userMessage, String model) {
// 1. 保存用户消息
ChatMessage userMsg = ChatMessage.builder()
.messageId(UUID.randomUUID().toString())
.role(MessageRole.USER)
.content(userMessage)
.timestamp(System.currentTimeMillis())
.build();
sessionService.appendMessage(sessionId, userMsg);
// 2. 构建上下文
String contextPrompt = contextService.buildContextPrompt(sessionId, model);
// 3. 调用大模型 API(此处以 OpenAI 兼容格式为例)
String response = callLLMApi(contextPrompt, userMessage, model);
// 4. 保存助手回复
ChatMessage assistantMsg = ChatMessage.builder()
.messageId(UUID.randomUUID().toString())
.role(MessageRole.ASSISTANT)
.content(response)
.timestamp(System.currentTimeMillis())
.build();
sessionService.appendMessage(sessionId, assistantMsg);
// 5. 更新 Token 统计
updateTokenStats(sessionId, userMessage, response);
return assistantMsg;
}
private String callLLMApi(String context, String newMessage, String model) {
// 调用大模型 API 的实现(省略具体实现)
// ...
return "这是模拟的回复内容";
}
private void updateTokenStats(String sessionId, String userMessage, String response) {
int promptTokens = tokenCounter.count(userMessage);
int completionTokens = tokenCounter.count(response);
int totalTokens = promptTokens + completionTokens;
// 更新 Redis 中的 Token 统计
sessionService.updateTokenCount(sessionId, totalTokens);
}
}
六、会话过期策略与自动清理机制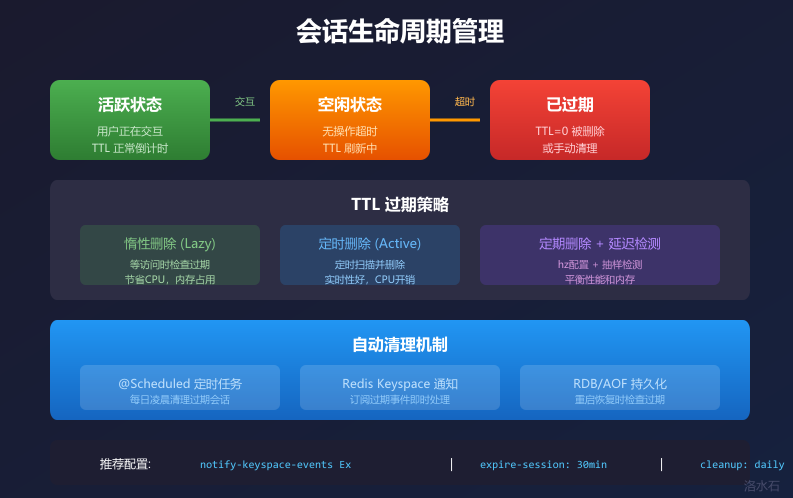
图4:会话生命周期管理
6.1 Redis 过期策略原理
Redis 提供了两种主要的 Key 过期策略:
惰性删除(Lazy Expiration):当访问某个 Key 时,Redis 检查它是否已过期,如果过期则删除。这种策略的优点是节省 CPU 资源,不需要定时扫描所有 Key。缺点是如果过期的 Key 长期不被访问,将一直占用内存。
定期删除(Active Expiration):Redis 每隔一段时间(通过 hz 配置,默认 10)会随机检查一部分 Key,删除其中过期的 Key。检查的数量受 hz 配置和 Key 数量的共同影响。这种策略是惰性删除的补充,用于平衡内存和 CPU。
6.2 会话 TTL 设计
# 会话 TTL 配置
session:
default-ttl: 30m # 默认会话过期时间
max-ttl: 7d # 最大会话存活时间
idle-warning: 10m # 空闲警告阈值
idle-kick: 30m # 空闲踢出阈值
动态 TTL 计算:会话的实际过期时间应该根据用户活跃度动态调整。当用户处于活跃状态时(频繁发送消息),可以适度延长 TTL;当用户空闲一段时间后,应该缩短 TTL以释放资源。
public Duration calculateSessionTTL(ChatSession session) {
long idleMinutes = Duration.between(session.getLastActiveAt(), LocalDateTime.now()).toMinutes();
if (idleMinutes < 5) {
// 活跃状态,保持正常 TTL
return DEFAULT_TTL;
} else if (idleMinutes < 30) {
// 轻度空闲,缩短 TTL
return DEFAULT_TTL.multipliedBy(0.5);
} else if (idleMinutes < 60) {
// 中度空闲,进一步缩短
return DEFAULT_TTL.multipliedBy(0.25);
} else {
// 长时间空闲,只保留较短时间
return Duration.ofMinutes(5);
}
}
6.3 自动清理机制实现
6.3.1 定时任务清理
@Component
@RequiredArgsConstructor
public class SessionCleanupScheduler {
private final RedisSessionService sessionService;
private final RedisTemplate<String, Object> redisTemplate;
private static final Logger log = LoggerFactory.getLogger(SessionCleanupScheduler.class);
/**
* 每日凌晨清理过期会话元数据
* 配置:0 0 2 * * ? 每天凌晨2点执行
*/
@Scheduled(cron = "${session.cleanup-cron:0 0 2 * * ?}")
public void cleanupExpiredSessions() {
log.info("Starting scheduled session cleanup...");
long startTime = System.currentTimeMillis();
int cleanedCount = 0;
// 使用 SCAN 遍历所有会话元数据 Key
Set<String> sessionKeys = scanKeys("session:meta:*");
for (String key : sessionKeys) {
try {
Boolean hasExpired = redisTemplate.hasKey(key);
if (Boolean.FALSE.equals(hasExpired)) {
// Key 已自动过期,清理关联数据
String sessionId = extractSessionId(key);
cleanupSessionData(sessionId);
cleanedCount++;
}
} catch (Exception e) {
log.error("Failed to cleanup session: {}", key, e);
}
}
long duration = System.currentTimeMillis() - startTime;
log.info("Session cleanup completed. Cleaned {} sessions in {}ms", cleanedCount, duration);
}
/**
* 定期刷新活跃会话的 TTL
* 配置:*/5 * * * * ? 每5分钟执行
*/
@Scheduled(fixedRate = 300000)
public void refreshActiveSessionsTTL() {
// 查找状态为 ACTIVE 但即将过期的会话
// 延长其 TTL 以保持活跃
// ...
}
private Set<String> scanKeys(String pattern) {
Set<String> keys = new HashSet<>();
ScanOptions options = ScanOptions.scanOptions().match(pattern).count(1000).build();
try (Cursor<String> cursor = redisTemplate.scan(options)) {
while (cursor.hasNext()) {
keys.add(cursor.next());
}
}
return keys;
}
private String extractSessionId(String key) {
return key.substring("session:meta:".length());
}
private void cleanupSessionData(String sessionId) {
// 清理消息列表
String msgKey = "session:messages:" + sessionId;
redisTemplate.delete(msgKey);
// 清理其他关联数据
// ...
}
}
6.3.2 Redis Keyspace 通知
Redis 支持发布/订阅过期事件(Keyspace Notifications),可以实时监听 Key 的过期:
@Configuration
public class RedisKeyspaceConfig {
@Bean
public RedisMessageListenerContainer keyExpirationListener(RedisConnectionFactory factory) {
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(factory);
// 配置过期事件监听
container.addMessageListener((message, pattern) -> {
String expiredKey = new String(message.getBody());
if (expiredKey.startsWith("session:")) {
handleSessionExpired(expiredKey);
}
}, new PatternTopic("__keyevent@0__:expired"));
return container;
}
}
6.4 归档策略
对于有价值的会话数据,建议实施归档策略而不是直接删除:
@Service
@RequiredArgsConstructor
public class SessionArchivalService {
private final RedisSessionService sessionService;
private final JdbcTemplate jdbcTemplate;
/**
* 归档已完成的会话
*/
public void archiveSession(String sessionId) {
// 1. 获取完整会话数据
ChatSession session = sessionService.getSession(sessionId)
.orElseThrow(() -> new SessionNotFoundException(sessionId));
List<ChatMessage> messages = sessionService.getAllMessages(sessionId);
// 2. 写入数据库归档
String sql = "INSERT INTO session_archive (session_id, user_id, messages, archived_at) VALUES (?, ?, ?, ?)";
jdbcTemplate.update(sql,
session.getSessionId(),
session.getUserId(),
new ObjectMapper().writeValueAsString(messages),
LocalDateTime.now()
);
// 3. 更新 Redis 状态
sessionService.updateSessionStatus(sessionId, SessionStatus.ARCHIVED);
}
}
七、Redis 集群下的会话分布式存储
7.1 集群架构设计
在大规模生产环境中,单机 Redis 往往无法满足高并发和大容量存储的需求。Redis Cluster 提供了分布式存储能力,但也会带来一些设计上的挑战。
会话路由策略:Redis Cluster 将 Key 分散到多个槽(Slot)中,每个槽归属于一个主节点。对于会话存储,需要决定是将会话的所有数据存储在同一个节点(推荐)还是分散到多个节点。
一致性保证:在集群环境下,需要考虑数据一致性问题。Redis Cluster 使用异步复制,存在主从同步延迟。对于会话这类需要高可靠性的数据,建议使用 READONLY 命令从从节点读取,但写入操作必须路由到主节点。
7.2 集群友好 Key 设计
@Configuration
public class ClusterAwareSessionKeyGenerator {
/**
* 生成集群友好的 Key
* 确保同一会话的所有 Key 落在同一个 Slot
*/
public String generateSessionSlotKey(String sessionId) {
// Redis Cluster 的 hash tags 机制允许我们指定 Key 的某个部分用于计算 Slot
// 使用大括号 {} 包裹的部分将用于计算 Slot
return String.format("{%s}", sessionId);
}
// 生成各类型的 Key,都使用相同的 hash tag
public String sessionMetaKey(String sessionId) {
return String.format("{session:%s}:meta", sessionId);
}
public String sessionMessagesKey(String sessionId) {
return String.format("{session:%s}:messages", sessionId);
}
public String sessionContextKey(String sessionId) {
return String.format("{session:%s}:context", sessionId);
}
}
7.3 哨兵模式 vs 集群模式选择
Redis Sentinel(哨兵模式):
- 适用场景:读多写少、数据量适中(一主多从架构)
- 优点:配置简单、自动故障转移、客户端支持好
- 缺点:只有一个主节点可写,扩展性有限
Redis Cluster(集群模式):
- 适用场景:大规模数据、高并发写入、数据分片
- 优点:水平扩展能力强、数据自动分片、高可用
- 缺点:管理复杂、某些操作不支持跨 Slot、客户端需要支持 Cluster 协议
对于会话存储场景的推荐:
- 小规模应用(< 10万并发用户):使用 Sentinel 模式足够了
- 中等规模(10万-100万并发用户):使用 Cluster 模式,建议 6 节点(3主3从)
- 大规模(> 100万并发用户):使用 Cluster 模式并配合读写分离
7.4 跨数据中心部署
对于需要跨地域部署的系统,会话同步是一个挑战:
本地读取策略:用户请求优先路由到最近的数据中心,本地 Redis 存储会话数据。对于跨地域的用户,通过异步复制将数据同步到其他数据中心。
全局会话 ID 策略:使用全局唯一的会话 ID,而不考虑具体的存储位置。读操作先查本地缓存,未命中则查询远程数据中心。
@Service
@RequiredArgsConstructor
public class DistributedSessionService {
private final RedisTemplate<String, Object> localRedisTemplate;
private final RestTemplate remoteRestTemplate;
private static final Map<String, String> DC_ENDPOINTS = Map.of(
"dc-east", "http://redis-east.internal/api",
"dc-west", "http://redis-west.internal/api",
"dc-central", "http://redis-central.internal/api"
);
/**
* 获取会话,优先本地,远程兜底
*/
public Optional<ChatSession> getSession(String sessionId) {
// 先查本地
String localKey = "session:meta:" + sessionId;
ChatSession session = (ChatSession) localRedisTemplate.opsForValue().get(localKey);
if (session != null) {
return Optional.of(session);
}
// 本地未命中,查询远程数据中心
for (Map.Entry<String, String> entry : DC_ENDPOINTS.entrySet()) {
try {
ChatSession remoteSession = fetchFromRemote(entry.getValue(), sessionId);
if (remoteSession != null) {
// 回填本地缓存
localRedisTemplate.opsForValue().set(localKey, remoteSession, Duration.ofMinutes(5));
return Optional.of(remoteSession);
}
} catch (Exception e) {
log.warn("Failed to fetch session from {}", entry.getKey(), e);
}
}
return Optional.empty();
}
}
八、实战:Spring Boot + Redis + 大模型多轮对话
8.1 项目结构
src/main/java/com/example/chat/
├── ChatApplication.java
├── config/
│ ├── RedisConfig.java
│ ├── LLMConfig.java
│ └── AppConfig.java
├── controller/
│ └── ChatController.java
├── service/
│ ├── RedisSessionService.java
│ ├── ContextInjectionService.java
│ ├── LLMChatService.java
│ └── SessionCleanupScheduler.java
├── model/
│ ├── ChatSession.java
│ ├── ChatMessage.java
│ └── SessionStatus.java
├── repository/
│ └── SessionRepository.java
├── exception/
│ ├── SessionNotFoundException.java
│ └── GlobalExceptionHandler.java
└── dto/
├── ChatRequest.java
└── ChatResponse.java
8.2 核心配置类
@Configuration
@EnableConfigurationProperties
@ConfigurationProperties(prefix = "app")
public class AppConfig {
private String defaultModel = "gpt-4";
private int defaultContextWindow = 20;
private Duration sessionTtl = Duration.ofMinutes(30);
private String watermark = "洛水石";
// getters and setters
}
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
// 使用 Jackson 序列化器
Jackson2JsonRedisSerializer<Object> serializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper mapper = new ObjectMapper();
mapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
serializer.setObjectMapper(mapper);
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(serializer);
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(serializer);
template.afterPropertiesSet();
return template;
}
@Bean
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory factory) {
return new StringRedisTemplate(factory);
}
}
8.3 对话控制器
@RestController
@RequestMapping("/api/chat")
@RequiredArgsConstructor
@Slf4j
public class ChatController {
private final LLMChatService chatService;
private final RedisSessionService sessionService;
/**
* 创建新会话
*/
@PostMapping("/session")
public ResponseEntity<ChatResponse.CreateSessionResponse> createSession(
@RequestBody ChatRequest.CreateSession request) {
ChatSession session = chatService.createSession(
request.getUserId(),
request.getSystemPrompt()
);
return ResponseEntity.ok(ChatResponse.CreateSessionResponse.builder()
.sessionId(session.getSessionId())
.createdAt(session.getCreatedAt())
.build());
}
/**
* 发送消息
*/
@PostMapping("/session/{sessionId}/message")
public ResponseEntity<ChatResponse.SendMessageResponse> sendMessage(
@PathVariable String sessionId,
@RequestBody ChatRequest.SendMessage request) {
log.info("Received message for session: {}, content length: {}",
sessionId, request.getContent().length());
ChatMessage response = chatService.chat(
sessionId,
request.getContent(),
request.getModel()
);
return ResponseEntity.ok(ChatResponse.SendMessageResponse.builder()
.messageId(response.getMessageId())
.content(response.getContent())
.timestamp(response.getTimestamp())
.build());
}
/**
* 获取会话历史
*/
@GetMapping("/session/{sessionId}/history")
public ResponseEntity<ChatResponse.HistoryResponse> getHistory(
@PathVariable String sessionId,
@RequestParam(defaultValue = "50") int limit) {
List<ChatMessage> messages = sessionService.getRecentMessages(sessionId, limit);
return ResponseEntity.ok(ChatResponse.HistoryResponse.builder()
.sessionId(sessionId)
.messages(messages)
.count(messages.size())
.build());
}
/**
* 删除会话
*/
@DeleteMapping("/session/{sessionId}")
public ResponseEntity<Void> deleteSession(@PathVariable String sessionId) {
sessionService.deleteSession(sessionId);
return ResponseEntity.noContent().build();
}
}
8.4 完整对话流程时序
用户请求 → ChatController.sendMessage()
↓
验证会话是否存在
↓
保存用户消息到 Redis (RPUSH)
↓
构建上下文 Prompt (ContextInjectionService)
↓
调用大模型 API (LLMChatService)
↓
保存助手回复到 Redis (RPUSH)
↓
更新会话元数据 (HSET)
↓
返回响应给用户
九、会话存储的性能优化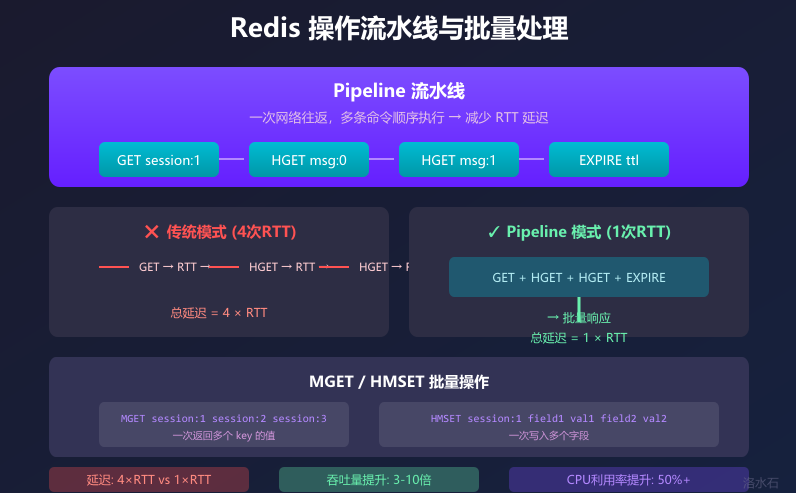
图3:Redis操作流水线与批量处理
9.1 Pipeline 批量操作优化
Redis 的 Pipeline 机制允许客户端将多个命令打包成一个请求发送,大幅减少网络往返次数:
@Service
@RequiredArgsConstructor
public class PipelineOptimizedSessionService {
private final RedisTemplate<String, Object> redisTemplate;
/**
* Pipeline 批量写入消息
*/
public void batchAppendMessages(String sessionId, List<ChatMessage> messages) {
String msgKey = "session:messages:" + sessionId;
redisTemplate.executePipelined((RedisCallback<Object>) connection -> {
for (ChatMessage msg : messages) {
try {
byte[] msgBytes = new ObjectMapper().writeValueAsBytes(msg);
connection.listCommands().rPush(msgKey.getBytes(), msgBytes);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
return null;
});
}
/**
* Pipeline 批量读取会话列表
*/
public Map<String, ChatSession> batchGetSessions(List<String> sessionIds) {
List<String> keys = sessionIds.stream()
.map(id -> "session:meta:" + id)
.collect(Collectors.toList());
List<Object> results = redisTemplate.executePipelined((RedisCallback<Object>) connection -> {
for (String key : keys) {
connection.stringCommands().get(key.getBytes());
}
return null;
});
Map<String, ChatSession> sessions = new HashMap<>();
ObjectMapper mapper = new ObjectMapper();
for (int i = 0; i < sessionIds.size(); i++) {
if (results.get(i) != null) {
try {
ChatSession session = mapper.readValue(
((RedisFuture<byte[]>) results.get(i)).get(),
ChatSession.class
);
sessions.put(sessionIds.get(i), session);
} catch (Exception e) {
log.error("Failed to deserialize session: {}", sessionIds.get(i), e);
}
}
}
return sessions;
}
}
9.2 数据压缩优化
对于大型会话系统,消息内容的压缩可以显著节省内存:
@Service
@RequiredArgsConstructor
public class CompressionService {
private final Deflater compressor = new Deflater();
private final Inflater decompressor = new Inflater();
/**
* 压缩字符串
*/
public byte[] compress(String data) {
if (data == null || data.isEmpty()) {
return new byte[0];
}
byte[] input = data.getBytes(StandardCharsets.UTF_8);
compressor.setInput(input);
compressor.finish();
ByteArrayOutputStream output = new ByteArrayOutputStream(input.length);
byte[] buffer = new byte[1024];
while (!compressor.finished()) {
int count = compressor.deflate(buffer);
output.write(buffer, 0, count);
}
compressor.reset();
return output.toByteArray();
}
/**
* 解压缩字符串
*/
public String decompress(byte[] compressed) {
if (compressed == null || compressed.length == 0) {
return "";
}
decompressor.setInput(compressed);
ByteArrayOutputStream output = new ByteArrayOutputStream(compressed.length);
byte[] buffer = new byte[1024];
try {
while (!decompressor.finished()) {
int count = decompressor.inflate(buffer);
output.write(buffer, 0, count);
}
decompressor.reset();
} catch (DataFormatException e) {
throw new RuntimeException("Failed to decompress data", e);
}
return output.toString(StandardCharsets.UTF_8);
}
}
9.3 分片存储策略
当单个会话的数据量超过 Redis 单个 Value 的大小限制(512MB)时,需要实施分片策略:
@Service
@RequiredArgsConstructor
public class ShardedSessionService {
private final List<RedisTemplate<String, Object>> redisTemplates;
private final int shardCount;
/**
* 根据会话 ID 选择分片
*/
private RedisTemplate<String, Object> getShard(String sessionId) {
int hash = Math.abs(sessionId.hashCode());
int shardIndex = hash % shardCount;
return redisTemplates.get(shardIndex);
}
/**
* 分片追加消息
*/
public void appendMessageSharded(String sessionId, ChatMessage message) {
String msgKey = "session:messages:" + sessionId;
RedisTemplate<String, Object> shard = getShard(sessionId);
try {
byte[] msgBytes = new ObjectMapper().writeValueAsBytes(message);
shard.opsForList().rightPush(msgKey, msgBytes);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
/**
* 分片范围查询
*/
public List<ChatMessage> getMessagesSharded(String sessionId, long start, long end) {
String msgKey = "session:messages:" + sessionId;
RedisTemplate<String, Object> shard = getShard(sessionId);
List<Object> rawMessages = shard.opsForList().range(msgKey, start, end);
return rawMessages.stream()
.map(obj -> {
try {
byte[] bytes = (byte[]) obj;
return new ObjectMapper().readValue(bytes, ChatMessage.class);
} catch (Exception e) {
log.error("Failed to deserialize message", e);
return null;
}
})
.filter(Objects::nonNull)
.collect(Collectors.toList());
}
}
9.4 缓存层次化
@Service
@RequiredArgsConstructor
public class CachedSessionService {
private final RedisSessionService redisSessionService;
private final CacheManager cacheManager;
private static final String CACHE_NAME = "sessions";
private static final Duration CACHE_TTL = Duration.ofMinutes(5);
/**
* 三级缓存获取会话
* L1: Caffeine 本地缓存
* L2: Redis 分布式缓存
* L3: Redis 持久化存储
*/
public Optional<ChatSession> getSession(String sessionId) {
// L1: 本地缓存
Cache<String, ChatSession> cache = cacheManager.getCache(CACHE_NAME);
ChatSession session = cache.getIfPresent(sessionId);
if (session != null) {
return Optional.of(session);
}
// L2: Redis
session = redisSessionService.getSession(sessionId).orElse(null);
if (session != null) {
cache.put(sessionId, session);
return Optional.of(session);
}
return Optional.empty();
}
}
十、安全性考虑:敏感对话数据的加密存储
10.1 数据加密方案
对于包含敏感信息的对话内容,需要实施加密存储:
@Service
@RequiredArgsConstructor
public class EncryptedSessionService {
private final RedisTemplate<String, Object> redisTemplate;
private final EncryptionService encryptionService;
/**
* 加密存储会话数据
*/
public void saveSessionEncrypted(String sessionId, ChatSession session) {
String key = "session:meta:" + sessionId;
// 序列化后加密
try {
String json = new ObjectMapper().writeValueAsString(session);
String encrypted = encryptionService.encrypt(json);
redisTemplate.opsForValue().set(key, encrypted);
} catch (JsonProcessingException e) {
throw new RuntimeException("Failed to serialize session", e);
}
}
/**
* 解密读取会话数据
*/
public Optional<ChatSession> getSessionDecrypted(String sessionId) {
String key = "session:meta:" + sessionId;
Object encrypted = redisTemplate.opsForValue().get(key);
if (encrypted == null) {
return Optional.empty();
}
try {
String json = encryptionService.decrypt(encrypted.toString());
return Optional.of(new ObjectMapper().readValue(json, ChatSession.class));
} catch (Exception e) {
throw new RuntimeException("Failed to deserialize session", e);
}
}
}
10.2 加密服务实现
@Service
@RequiredArgsConstructor
public class EncryptionService {
private final String secretKey = "your-256-bit-secret-key-here"; // 应从配置中心获取
@PostConstruct
public void init() {
// 从密钥管理服务(如 AWS KMS、Vault)获取密钥
// this.secretKey = keyManagementService.getKey("session-encryption-key");
}
/**
* AES-256-GCM 加密
*/
public String encrypt(String plaintext) {
try {
SecretKeySpec key = new SecretKeySpec(secretKey.getBytes(), "AES");
GCMParameterSpec gcmSpec = new GCMParameterSpec(128, generateIV());
Cipher cipher = Cipher.getInstance("AES/GCM/NoPadding");
cipher.init(Cipher.ENCRYPT_MODE, key, gcmSpec);
byte[] ciphertext = cipher.doFinal(plaintext.getBytes(StandardCharsets.UTF_8));
// 拼接 IV + 密文
ByteBuffer buffer = ByteBuffer.allocate(12 + ciphertext.length);
buffer.put(gcmSpec.getIV());
buffer.put(ciphertext);
return Base64.getEncoder().encodeToString(buffer.array());
} catch (Exception e) {
throw new RuntimeException("Encryption failed", e);
}
}
/**
* AES-256-GCM 解密
*/
public String decrypt(String ciphertext) {
try {
byte[] data = Base64.getDecoder().decode(ciphertext);
ByteBuffer buffer = ByteBuffer.wrap(data);
byte[] iv = new byte[12];
buffer.get(iv);
byte[] encrypted = new byte[buffer.remaining()];
buffer.get(encrypted);
SecretKeySpec key = new SecretKeySpec(secretKey.getBytes(), "AES");
GCMParameterSpec gcmSpec = new GCMParameterSpec(128, iv);
Cipher cipher = Cipher.getInstance("AES/GCM/NoPadding");
cipher.init(Cipher.DECRYPT_MODE, key, gcmSpec);
byte[] plaintext = cipher.doFinal(encrypted);
return new String(plaintext, StandardCharsets.UTF_8);
} catch (Exception e) {
throw new RuntimeException("Decryption failed", e);
}
}
private byte[] generateIV() {
SecureRandom random = new SecureRandom();
byte[] iv = new byte[12];
random.nextBytes(iv);
return iv;
}
}
10.3 敏感字段脱敏
@Service
@RequiredArgsConstructor
public class DataMaskingService {
/**
* 敏感字段脱敏
*/
public ChatSession maskSensitiveData(ChatSession session) {
if (session == null) {
return null;
}
return ChatSession.builder()
.sessionId(session.getSessionId())
.userId(maskUserId(session.getUserId()))
.title(session.getTitle())
.createdAt(session.getCreatedAt())
.updatedAt(session.getUpdatedAt())
// 其他非敏感字段照常返回
.build();
}
private String maskUserId(String userId) {
if (userId == null || userId.length() < 4) {
return "****";
}
return userId.substring(0, 2) + "****" + userId.substring(userId.length() - 2);
}
/**
* 消息内容安全过滤
*/
public ChatMessage filterSensitiveContent(ChatMessage message) {
if (message == null) {
return null;
}
String content = message.getContent();
// 过滤敏感词、联系方式、银行卡号等
content = filterPatterns(content);
return ChatMessage.builder()
.messageId(message.getMessageId())
.role(message.getRole())
.content(content)
.timestamp(message.getTimestamp())
.build();
}
}
10.4 审计日志
@Component
@RequiredArgsConstructor
public class SessionAuditLogger {
private final Logger auditLog = LoggerFactory.getLogger("AUDIT");
public void logSessionAccess(String sessionId, String userId, String operation) {
auditLog.info("SESSION_ACCESS | sessionId={} | userId={} | operation={} | timestamp={}",
sessionId, userId, operation, LocalDateTime.now());
}
public void logSensitiveOperation(String sessionId, String userId, String operation, String details) {
auditLog.warn("SENSITIVE_OPERATION | sessionId={} | userId={} | operation={} | details={} | timestamp={}",
sessionId, userId, operation, details, LocalDateTime.now());
}
public void logSecurityEvent(String sessionId, String userId, String event, String ipAddress) {
auditLog.error("SECURITY_EVENT | sessionId={} | userId={} | event={} | ip={} | timestamp={}",
sessionId, userId, event, ipAddress, LocalDateTime.now());
}
}
总结
本文深入探讨了使用 Redis 实现大模型会话持久化的完整方案,涵盖了从数据结构选型、存储结构设计、Spring Boot 集成、上下文注入、过期策略、集群部署到性能优化和安全加固的各个环节。
核心要点回顾:
- 数据结构选择:根据会话规模选择合适的 Redis 数据结构,Hash + List 混合方案适合大多数场景。
- Key 命名规范:采用层次化的命名模式,便于管理和批量操作。
- Spring Data Redis 集成:通过封装统一的服务层,简化会话操作的复杂度。
- 上下文注入:根据模型特性构建合适的 Prompt,合理控制 Token 消耗。
- 过期清理策略:结合惰性删除和定时任务,实现高效的会话生命周期管理。
- 集群部署:根据规模选择 Sentinel 或 Cluster 模式,确保高可用性。
- 性能优化:Pipeline 批量操作、压缩存储、分片策略等多管齐下。
- 安全保障:敏感数据加密存储、字段脱敏、审计日志缺一不可。
通过本文的方案,开发者可以构建一个生产级的大模型多轮对话会话管理系统,为用户提供流畅、安全、可靠的人机交互体验。
附:配套技术图解
Redis 会话存储架构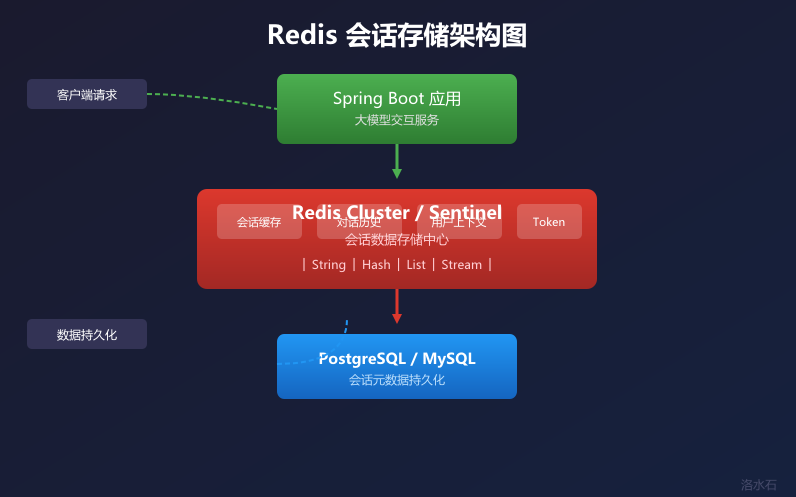
图5:Redis会话存储架构图
对话历史存储结构
图6:对话历史存储结构设计图
Redis 流水线与批量操作
图7:Redis操作流水线与批量处理图
会话生命周期管理

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)