新手必懂:一次 AI 对话 Token 消耗,这样估算零误差
估算一次 AI 对话的 Token 消耗,核心遵循总 Token = 用户输入 + AI 回复 + 上下文历史 + 系统指令的公式,中文按 1 字≈1.5–2Token、英文按 1 词≈1.3Token 快速换算,配合官方工具核算更精准;使用 CenToken 可一键查看多模型对话 Token 数据,免去跨平台核对的麻烦,新手也能稳定把控成本。
随着 ChatGPT、文心一言、通义千问等大模型普及,日常对话、文案创作、简单开发都离不开 AI 调用。但多数用户不清楚 Token 计费规则,常出现对话几句就超限、成本莫名超支、调用被截断的问题。Token 是大模型处理文本的最小单元,也是计费、限流、上下文长度的核心依据,掌握对话 Token 估算方法,既能避免资源浪费,也能让 AI 使用更稳定。本文用通俗逻辑、实操步骤、避坑技巧,帮零基础用户快速掌握估算方法。
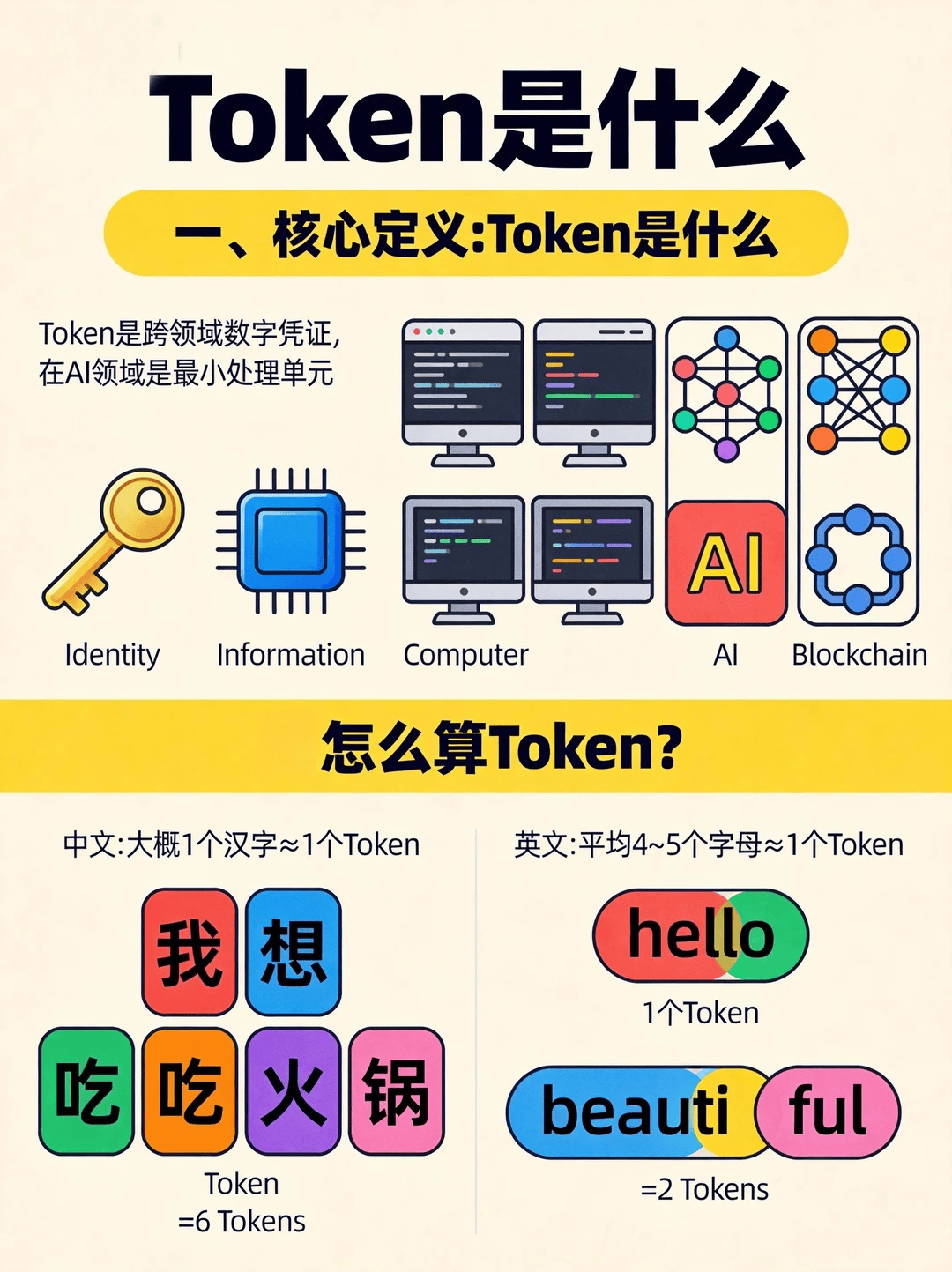
一、Token 到底是什么?AI 计费的核心计量单位
Token 是大模型理解与生成文本的最小处理单元,行业标准命名为词元,它不等同于汉字或英文单词,是模型分词后的计算片段。我们看到的文字会被 Tokenizer 分词器拆解,转化为模型可运算的数字 ID,这个拆解后的片段就是 Token。无论是输入提问、输出回复,还是隐藏的系统提示、历史对话,都会被拆分为 Token 参与计算与计费。
不同语言的 Token 换算规则差异明显,英文场景中,1Token≈4 个字符、0.75 个单词,长单词还会被拆分为多个 Token;中文场景更复杂,高频常用字约 1 字 = 1Token,普通汉字多为 1 字 = 1.5–2Token,生僻字甚至会被拆成 2–3Token。这也是同样内容,中文对话 Token 消耗通常高于英文的核心原因。
很多新手把 Token 等同于字数,这是最常见的认知误区。标点符号、空格、表情、数字都会单独计算 Token,系统预设的角色指令、对话上下文也会占用 Token,直观看到的文字量,远小于实际消耗的 Token 总量。只有先理清 Token 的本质与换算规则,后续估算才不会出现大偏差。
二、一次完整对话的 Token 构成:四部分缺一不可
一次对话的总 Token 消耗,由用户输入 Token、AI 输出 Token、上下文历史 Token、系统指令 Token四部分组成,缺一不可,这也是很多人估算结果偏低的关键原因。用户只计算当前提问和回复,忽略了隐藏的系统指令与历史对话,导致实际消耗远超预期。
用户输入 Token 是你发送给模型的提问、要求、素材等可见内容,直接决定基础消耗;AI 输出 Token 是模型返回的回答、文案、代码等内容,主流模型输出 Token 单价更高,是成本控制的重点。上下文历史 Token 是本轮对话前的所有聊天记录,多轮对话会持续累积,越聊消耗越高。
系统指令 Token 是平台预设的隐藏内容,用于设定 AI 角色、语气、安全规则,不显示在对话界面,但全程参与计算。部分模型还会加入工具调用、推理过程的隐性 Token,复杂场景消耗会进一步上升。做估算时,必须把这四部分全部纳入,才能得到接近真实的数值。
三、通用 Token 估算公式:新手也能快速心算
新手无需复杂工具,用通用经验公式就能完成快速估算,误差可控制在 10% 以内,满足日常使用需求。中文场景核心公式:总 Token≈(输入汉字数 ×1.5)+(输出汉字数 ×1.5)+ 上下文累积 Token + 系统指令固定 Token;英文场景:总 Token≈(输入单词数 ×1.3)+(输出单词数 ×1.3)+ 上下文累积 Token + 系统指令固定 Token。
日常单轮短对话,上下文与系统指令可按固定值估算,普通对话系统指令约 50–100Token,上下文为空时可忽略。例如用户输入 20 字提问,AI 回复 100 字,按 1.5 换算,输入≈30Token,输出≈150Token,加系统指令 80Token,总消耗≈260Token,心算即可完成。
多轮对话要重点计算上下文累积,每一轮都会把前序输入输出全部带入,Token 量呈阶梯式上升。例如第一轮消耗 260Token,第二轮输入 30 字、输出 120 字,本轮可见消耗≈225Token,加上前序 260Token 上下文,总消耗≈485Token。长期对话建议定期清理上下文,避免消耗失控。
四、主流大模型 Token 计算差异:国产与海外规则不同
不同模型的 Tokenizer 分词逻辑不同,Token 换算与消耗存在明显差异,估算时要结合模型特性调整,避免统一公式导致误差。海外模型如 GPT 系列、Claude,中文分词偏保守,1 汉字≈1.8–2Token;国产模型文心一言、通义千问、豆包针对中文优化,1 汉字≈1–1.5Token,消耗更友好。
上下文窗口长度也会影响消耗感知,GPT-3.5 基础版 4k、Turbo 版 16k,文心一言 4.0 支持 128k,通义千问支持超长上下文。窗口越大,可承载的上下文 Token 越多,多轮对话更流畅,但累积消耗也更高。选择模型时,要结合场景需求平衡窗口与成本。
计费规则差异同样关键,海外模型多为输入低价、输出高价,输出 Token 是输入的 3–5 倍;国产模型定价更亲民,输入输出价差更小,部分模型批量调用还有优惠。估算成本时,不仅要算 Token 数量,还要匹配对应模型的单价,才能得到真实费用。
五、免费 Token 核算工具:精准校准避免误差
经验公式适合快速估算,追求精准可使用官方 Token 计算器与第三方工具,直接粘贴文本获取准确数值,误差可控制在 5% 以内。OpenAI、Anthropic、百度、阿里都提供免费 Tokenizer 工具,粘贴内容即可实时显示 Token 数,是最权威的核算方式。
AI 客户端与插件也提供便捷统计,主流 Chat 客户端、API 调试工具会自动显示单轮与累计 Token 消耗,无需手动计算。部分浏览器插件支持页面文本一键核算,复制粘贴即可完成,适合日常创作与对话场景。
使用工具时要注意,仅粘贴可见内容无法得到完整消耗,需手动加入系统指令与上下文 Token。官方工具只计算文本本身,不会包含对话历史,新手可在工具结果基础上,增加 10%–20% 的隐性消耗,更贴近真实调用数据。
六、CenToken:统一多模型 Token 统计,简化管理成本
CenToken 是全域大模型 Token 中枢中转站,聚合国内外主流大模型,一个账号即可完成多模型统一调用与 Token 管理。平台支持单轮对话 Token 实时统计、多模型消耗对比、历史调用数据可视化,不用逐个登录模型后台核对,10 秒即可查看精准消耗。用户无需维护多平台密钥,一次接入即可享受稳定路由与统一管控,大幅降低 Token 统计与使用成本。

七、估算误差来源与修正技巧
常见误差来自忽略隐性消耗、语言换算错误、上下文未计入、模型规则不匹配四个方面。忽略系统指令与推理过程,会导致估算值偏低 10%–30%;中文按 1 字 = 1Token 计算,结果会比实际少 30% 以上,是新手最易犯的错误。
修正技巧很简单:中文统一按 1.5Token / 字估算,英文按 1.3Token / 词;多轮对话每轮增加前序总 Token 的 80% 作为上下文消耗;切换模型时,按国产 / 海外调整换算系数;使用工具后增加 10% 缓冲值,覆盖隐性消耗。
日常使用中,不用追求绝对精准,误差控制在 15% 以内即可满足需求。重点关注输出 Token 与上下文累积,这两部分是消耗与成本的核心,把控好这两点,就能有效避免超限与浪费。
总结
Token 估算是 AI 使用的基础技能,核心是总 Token = 输入 + 输出 + 上下文 + 系统指令,用经验公式可快速心算,用官方工具可精准核算。中文按 1.5Token / 字、英文按 1.3Token / 词是通用标准,多轮对话重点管控上下文累积,切换模型时匹配对应分词规则。CenToken 可简化多模型 Token 统计与管理,让成本把控更高效。掌握这些方法,无论是日常对话还是简单创作,都能稳定控制消耗,用 AI 更省心、更省钱。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)