RLHF 概述:从人类反馈到大模型对齐
1. 定义
RLHF(Reinforcement Learning from Human Feedback)中文通常译为基于人类反馈的强化学习。它是一套用于大模型对齐(alignment)的训练流程,核心思想是:先让模型具备语言和指令跟随能力,再把人类对回答质量的偏好转化为奖励信号,最后用强化学习或偏好优化方法继续调整模型行为。
重点:RLHF 不是单个算法
RLHF 是一条训练管线,不等同于 PPO、奖励模型或人工标注本身。经典 RLHF 通常包含监督微调、奖励模型训练、强化学习优化三个阶段;PPO(Proximal Policy Optimization)只是第三阶段常用的一种策略优化算法。
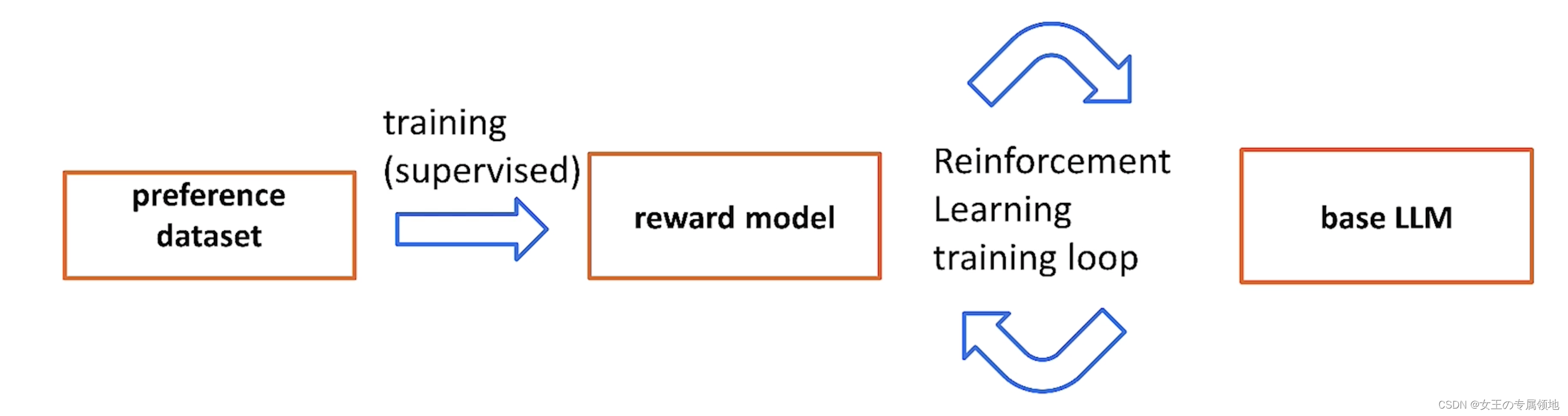
2. 先分清 RLHF、PPO、DPO 的层级
RLHF、PPO、DPO 不是同一层级的概念。为了避免混淆,本文采用如下层级:
| 概念 | 所在层级 | 准确理解 |
|---|---|---|
| RLHF | 训练流程 | 经典含义是“先训练奖励模型,再用强化学习优化语言模型”的整套对齐流程 |
| PPO | RLHF 流程中的优化算法 | PPO 是经典 RLHF 最后一阶段常用的强化学习算法 |
| DPO | PPO 式 RLHF 的替代路线 | DPO 直接用偏好对训练模型,通常不训练奖励模型,也不使用 PPO |
从层级上看,可以写成:
偏好对齐
├── PPO 式 RLHF
│ ├── SFT:先学会基本指令回答
│ ├── RM:训练奖励模型,把人类偏好变成分数
│ └── PPO:用奖励分数继续优化策略模型
└── DPO
├── SFT:先学会基本指令回答
└── DPO:直接用偏好对优化模型,不显式训练 RM,也不使用 PPO
重点:最容易混淆的地方
PPO 是经典 RLHF 内部的一个算法;DPO 不是 PPO 的下一步,而是另一条偏好优化路线。
3. 为什么需要 RLHF
预训练语言模型的基本目标通常是预测下一个 token。这个目标可以让模型学到语言统计规律、知识片段和一定推理模式,但它并不等价于“生成对人类真正有用的回答”。
常规交叉熵损失关注的是“下一个词是否像训练语料”,而真实应用更关心回答是否有帮助、是否诚实、是否安全、是否遵循指令、是否符合上下文语境。两者之间存在目标不一致问题。
大型语言模型常见的不对齐表现包括以下几类:
- 指令跟随不足:没有准确执行用户给出的任务约束。
- 幻觉:生成看似合理但事实错误或不存在的信息。
- 有害输出:复现训练数据中的偏见、攻击性内容或危险建议。
- 评价困难:开放式生成没有唯一标准答案,BLEU、ROUGE 等规则指标难以衡量真实偏好。
- 风格不稳定:同一任务下回答格式、语气、详略程度波动较大。
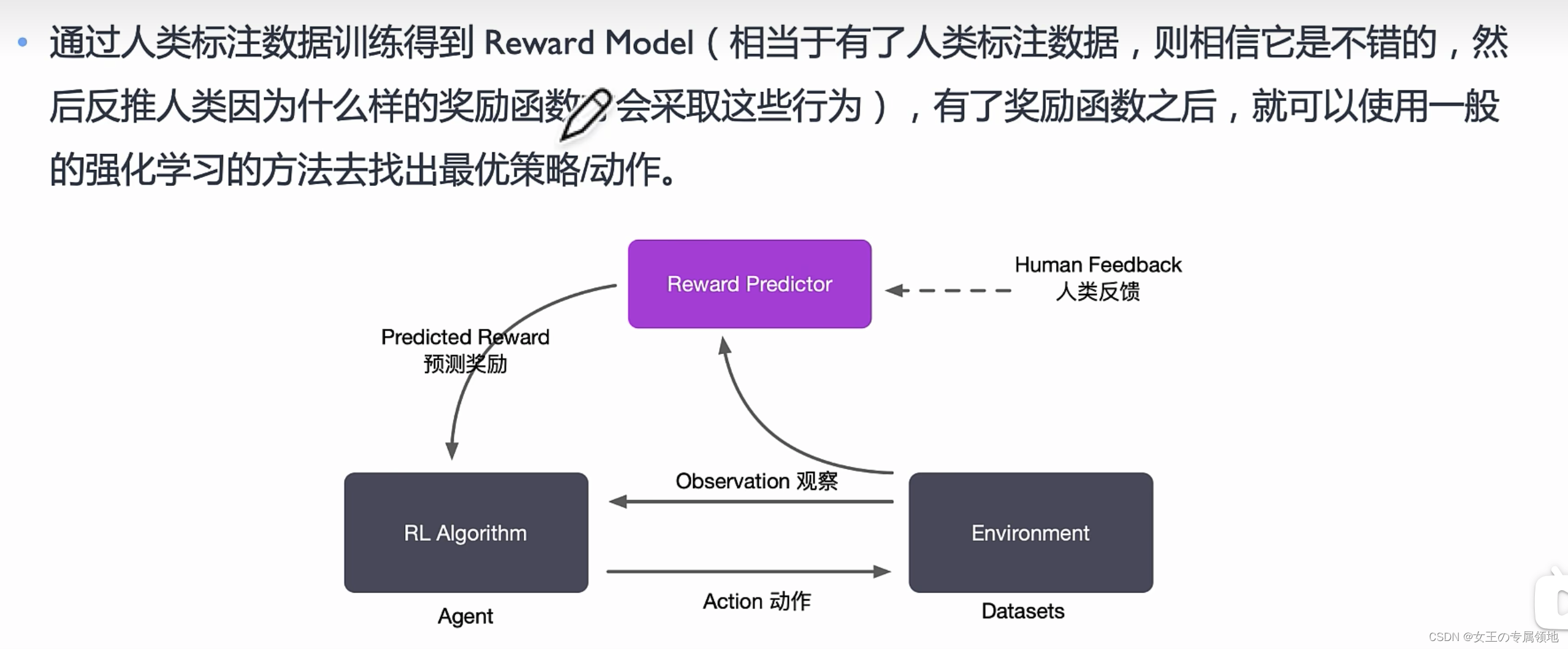
因此,RLHF 试图把“人类更喜欢哪种回答”显式引入训练过程。它不是单纯提升模型知识量,而是调整模型的行为策略,使模型更接近人类期望的助手形态。
4. RLHF 的整体训练路线
经典 PPO 式 RLHF 可以理解为四个连续环节:预训练模型、监督微调模型、奖励模型、PPO 强化学习后的策略模型。

| 阶段 | 输入数据 | 训练对象 | 目标 |
|---|---|---|---|
| 预训练 | 海量通用文本 | 基础语言模型 | 学习语言、知识和通用模式 |
| 监督微调 SFT | 人工示范问答 | SFT 模型 | 学会按指令回答 |
| 奖励模型训练 RM | 同一 prompt 下多个回答的偏好排序 | 奖励模型 | 学会判断回答质量 |
| 强化学习优化 | prompt、策略模型回答、RM 奖励 | 策略模型 | 生成更符合人类偏好的回答 |
SFT(Supervised Fine-Tuning)负责建立“会按格式回答”的基础,RM(Reward Model)负责把偏好变成可优化信号,PPO 负责在奖励约束下更新策略模型。
为了保持理解连贯,后文统一使用“电商客服助手”作为贯穿例子。目标是训练一个能回答退货、退款、物流、发票等问题的客服模型。这个模型既要准确遵守平台政策,也要保持礼貌、简洁和安全。
| PPO 式 RLHF 阶段 | 同一个客服助手例子 |
|---|---|
| 预训练 | 模型从通用网页、书籍、论坛和百科文本中学到语言能力,也知道“退货”“快递”“发票”等词语的大致含义 |
| SFT | 人工提供标准客服问答,让模型学会“先确认订单状态,再说明处理步骤”的回答格式 |
| 奖励模型训练 | 标注者比较多个客服回答,选择更准确、更礼貌、更符合平台政策的回答 |
| PPO 强化学习优化 | 策略模型不断生成客服回答,奖励模型给出分数,PPO 让模型更倾向生成高分回答 |
如果改用 DPO 路线,则会保留 SFT 和偏好数据,但跳过“训练奖励模型 + PPO 强化学习”这两个步骤,改为直接使用偏好对优化模型。
5. 阶段一:预训练与监督微调
5.1 预训练语言模型
预训练模型通过大规模文本学习语言建模能力。它通常已经掌握大量知识和语言模式,但并不天然知道开放式任务中什么回答更合适。
在 RLHF 流程中,预训练模型是起点。基础模型越强,后续对齐越容易产生高质量结果。RLHF 更像是在已有能力上调整行为方向,而不是从零开始教会模型语言能力。
以电商客服助手为例,预训练后的模型可能已经知道“七天无理由退货”“物流单号”“开发票”等常见表达,也能写出通顺句子。但它不一定知道某个平台的具体售后规则,也不一定会按客服流程回答。例如,面对“鞋子穿了一天还能退吗”,预训练模型可能只给出泛泛解释,无法稳定区分“质量问题”“个人原因”“已影响二次销售”等关键条件。

5.2 监督微调 SFT
SFT 使用人工编写或筛选的高质量指令数据训练模型。数据通常形如“prompt + 理想回答”。模型通过模仿示范答案,学习回答格式、任务边界、语气风格和基本安全规范。
SFT 的作用可以概括为三点:
- 把通用语言模型转换成指令跟随模型。
- 给后续奖励模型和强化学习阶段提供较好的初始策略。
- 降低 PPO 阶段的探索难度,避免策略从质量很差的回答开始优化。
仍以电商客服助手为例,SFT 数据可以写成如下形式:
| prompt | 人工示范回答 |
|---|---|
| 订单已经发货,还能修改地址吗? | 如果订单已发货,地址通常无法直接修改。建议先查看物流状态;若快递尚未派送,可联系快递公司尝试改派;若改派失败,可在包裹退回后重新下单。 |
| 商品收到后发现破损,怎么处理? | 可以先保留外包装、商品照片和快递面单,再在售后页面提交破损凭证。平台审核通过后,会根据规则提供退货、换货或退款处理。 |
经过 SFT 后,模型学会了客服回答的基本结构:先说明规则,再给出操作步骤,最后补充注意事项。这一步还没有直接比较多个回答的好坏,只是在模仿标准答案。
重点:SFT 是 RLHF 的地基
如果 SFT 模型本身不能稳定生成基本合格的回答,奖励模型和 PPO 往往只能在低质量输出之间做局部修正。
6. 阶段二:奖励模型训练
奖励模型的任务是把人类偏好转化成一个可计算的标量奖励。它通常接收 prompt 和回答,输出一个分数,分数越高表示该回答越符合标注者偏好。

6.1 为什么不直接让人打分
开放式回答很难直接给出绝对分数。不同标注者对“8 分回答”和“9 分回答”的尺度理解可能不同,直接打分会引入较强噪声。
更常见的做法是排序或成对比较。例如,同一个 prompt 下生成 A、B、C、D 四个回答,标注者只需要判断哪个更好。相对偏好通常比绝对分数更稳定。
以电商客服助手为例,同一个问题可以生成多个候选回答:
| prompt | 候选回答 | 标注判断 |
|---|---|---|
| 商品拆封后还能退吗? | A:可以退,直接申请即可。 | 过于绝对,忽略商品类型和平台规则 |
| 商品拆封后还能退吗? | B:是否支持退货需要看商品类型、拆封状态和是否影响二次销售。建议在订单售后页查看可申请的服务,并按页面要求提交凭证。 | 更准确,风险更低,更适合作为偏好回答 |
| 商品拆封后还能退吗? | C:不能退,拆封后一律不支持。 | 过于绝对,可能与实际规则冲突 |
标注者不需要给 A、B、C 分别打 70 分、90 分、60 分,只需要判断 B 优于 A 和 C。这样的偏好排序更容易保持一致。
6.2 奖励模型如何学习
奖励模型学习的是“哪个回答更可能被人类选择”。设同一 prompt 下有两个回答 yw 和 yl,其中 yw 是更受偏好的回答,yl 是较差回答。奖励模型需要让 R(x, yw) 大于 R(x, yl)。
常见训练目标可以直观理解为:
R(x, 好回答) 应该高于 R(x, 差回答)
其中 x 表示 prompt,R 表示奖励模型输出的分数。训练完成后,RM 就成为后续强化学习阶段的“偏好裁判”。
在客服助手例子中,奖励模型学到的不是“退货政策全文”,而是“哪种回答更像合格客服回答”。当输入“商品拆封后还能退吗?+ 候选回答 B”时,奖励模型应输出较高分;当输入“商品拆封后还能退吗?+ 候选回答 A”时,奖励模型应输出较低分。后续 PPO 会利用这个分数继续调整策略模型。
6.3 奖励模型的关键风险
奖励模型并不等于真实人类价值,它只是从有限偏好数据中拟合出的近似函数。因此它会受到数据来源、标注规则、标注者群体、排序方式和模型容量的影响。
一个常见问题是奖励黑客(reward hacking):策略模型可能学会生成某些能骗过奖励模型、但并不真正高质量的回答。为降低该风险,PPO 阶段通常会加入 KL(Kullback-Leibler)惩罚,限制策略模型不要偏离原始 SFT 模型太远。
在客服助手例子中,如果奖励模型过度偏好“语气礼貌”,策略模型可能学会生成大量客气套话,但实际没有解决售后问题;如果奖励模型过度偏好“回答简短”,策略模型可能省略关键限制条件。这说明奖励模型必须同时覆盖准确性、合规性、帮助性和表达质量。
7. 阶段三:用强化学习优化策略模型
在 RLHF 中,语言模型可以被建模为强化学习里的策略(policy)。给定 prompt,策略模型逐 token 生成回答;每个 token 的选择可以看作动作;完整回答会被奖励模型评分。
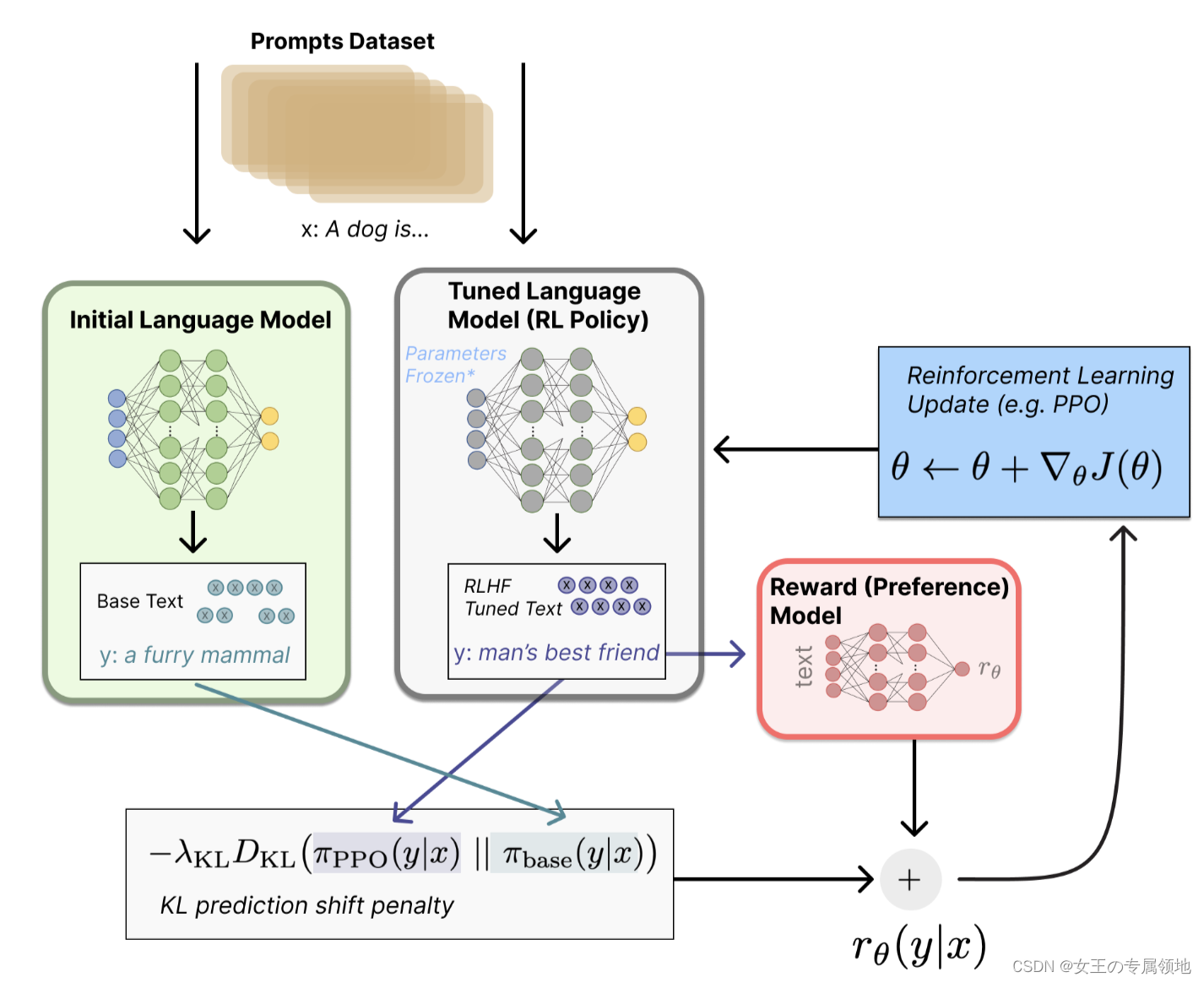
| 强化学习概念 | 在语言模型中的含义 |
|---|---|
| 状态或观察 | 输入 prompt 和已经生成的上下文 |
| 动作 | 从词表中选择下一个 token |
| 策略 | 语言模型给出下一个 token 概率分布 |
| 奖励 | 奖励模型对完整回答给出的偏好分数 |
| 约束 | 与 SFT 初始模型之间的 KL 距离 |
7.1 PPO 的作用
PPO(Proximal Policy Optimization)是一种常用的策略梯度算法。它的核心目标是在提升奖励的同时限制策略更新幅度,避免一次更新过大导致模型行为崩坏。
在 RLHF 中,PPO 通常从 SFT 模型初始化策略模型,再让策略模型生成回答,交给奖励模型打分,然后根据奖励更新策略。
更完整的奖励形式可以理解为:
最终奖励 = 奖励模型分数 - λ × KL 惩罚
其中 λ 是控制惩罚强度的系数。KL 惩罚用于约束当前策略不要过度偏离 SFT 模型。这样既鼓励模型迎合人类偏好,又避免模型为了刷高奖励而输出异常文本。
在客服助手例子中,PPO 阶段可以这样理解:
- 输入 prompt:“商品拆封后还能退吗?”
- 当前策略模型生成一个回答。
- 奖励模型判断该回答是否准确、礼貌、符合售后规则。
- 如果回答优于普通 SFT 输出,策略模型获得较高奖励。
- 如果回答虽然得分高但明显偏离 SFT 模型的正常表达,KL 惩罚会降低最终奖励。
经过多轮更新后,策略模型会更倾向于生成类似“需要结合商品类型、拆封程度、二次销售影响和售后页面规则判断”的回答,而不是生成“一定能退”或“一律不能退”这类绝对化回答。
更多 PPO 细节可继续阅读:[PPO 原理](/Users/mac/Documents/cherry 导出/03_训练与对齐/02_RLHF/PPO 原理.md)。
7.2 为什么 RLHF 难训练
RLHF 的难点不只在算法本身,也在系统工程和数据闭环。
- 策略模型、奖励模型、参考模型需要同时参与训练,显存和算力压力较大。
- 奖励模型质量直接决定优化方向,偏好数据噪声会被放大。
- PPO 对超参数敏感,训练过程可能不稳定。
- 奖励过度优化会带来回答模板化、迎合标注偏好或事实性下降。
- 人类偏好本身并不完全一致,难以形成唯一标准。
8. DPO:PPO 式 RLHF 的替代路线
DPO(Direct Preference Optimization)是一种常见的偏好优化方法。更严格地说,DPO 不是经典 PPO 式 RLHF 的一个阶段,而是它的替代路线。它仍然使用人类偏好数据,但不再显式训练奖励模型,也不再通过 PPO 与环境交互式采样来优化策略。
DPO 的核心思想是:偏好数据中已经包含“好回答应比差回答概率更高”的监督信号,因此可以直接用分类式损失优化模型,使模型提高被偏好回答的概率,降低不被偏好回答的概率。
在客服助手例子中,DPO 可以直接使用这样的偏好对:
| prompt | 被偏好的回答 | 不被偏好的回答 |
|---|---|---|
| 商品拆封后还能退吗? | 是否支持退货需要看商品类型、拆封状态和是否影响二次销售。建议在订单售后页查看可申请的服务,并按页面要求提交凭证。 | 可以退,直接申请即可。 |
DPO 的训练目标是让模型在看到同类 prompt 时,更容易生成左侧回答,而不是右侧回答。它不需要先训练一个奖励模型,也不需要让策略模型在 PPO 过程中反复采样和更新,因此工程流程更短。
| 对比项 | PPO 式 RLHF | DPO |
|---|---|---|
| 层级关系 | 一条完整的经典偏好对齐流程 | 替代 PPO 式 RLHF 的偏好优化算法 |
| 典型流程 | SFT → 奖励模型 → PPO | SFT → 偏好对 → DPO |
| 是否训练奖励模型 | 需要 | 不需要显式奖励模型 |
| 是否使用强化学习采样 | 需要 | 不需要 |
| 工程复杂度 | 较高 | 较低 |
| 训练稳定性 | 对超参数敏感 | 通常更稳定 |
| 主要优势 | 接近经典 RLHF 设定,灵活性强 | 实现简单,计算成本较低 |
| 主要限制 | 系统复杂、成本高 | 表达能力受偏好数据形式影响 |
重点:DPO 不是否定 RLHF
DPO 和 PPO 式 RLHF 的共同目标都是偏好对齐;区别在于,PPO 式 RLHF 先学奖励模型再用 PPO 优化,DPO 直接从偏好对优化模型。
9. PEFT 在 RLHF 中的位置
PEFT(Parameter-Efficient Fine-Tuning)中文常译为参数高效微调。它不是 RLHF 的必要组成部分,但在工程实践中经常用于降低 SFT、奖励模型训练或偏好优化阶段的成本。
| 方法 | 在 RLHF 中的典型位置 | 作用 |
|---|---|---|
| LoRA | SFT、奖励模型训练、DPO、部分 PPO 场景 | 只训练低秩增量矩阵,降低显存开销 |
| QLoRA | 单卡或显存受限场景 | 量化基础模型后训练 LoRA 参数 |
| Adapter | SFT 或任务适配 | 插入小模块,只训练新增参数 |
| Prefix Tuning | 轻量实验或风格控制 | 训练连续前缀向量影响生成 |
| IA3、DoRA、AdaLoRA | 研究或特定工程优化 | 进一步提高参数效率或控制更新方式 |
需要注意的是,PEFT 解决的是“如何低成本更新模型参数”,RLHF 解决的是“用什么偏好目标更新模型”。详见[PEFT 参数高效微调学习笔记](/Users/mac/Documents/cherry 导出/03_训练与对齐/PEFT 参数高效微调学习笔记.md)。两者属于不同层面的概念。
10. 一个完整例子:客服助手对齐
假设目标是训练一个客服助手。
预训练模型已经具有语言能力,但可能回答冗长、格式混乱、语气不稳定,也可能编造公司政策。
SFT 阶段使用人工整理的客服问答数据,让模型学会标准答复结构,例如先确认问题,再给出处理步骤,最后说明必要限制。
奖励模型训练阶段,让标注者比较多个客服回答。更受偏好的回答通常应当更准确、更礼貌、更符合流程、更少承诺无法保证的结果。
偏好优化阶段有两条常见路线:PPO 式 RLHF 会先训练奖励模型,再用 PPO 更新客服模型;DPO 会直接用“好回答、差回答”的偏好对训练客服模型。
这个例子说明,RLHF 不是简单让模型“变聪明”,而是让模型在开放式任务中更稳定地选择符合人类偏好的行为。
11. RLHF 的局限性
RLHF 提升了模型的指令跟随和偏好对齐能力,但并不能彻底解决大模型可靠性问题。
| 局限 | 具体表现 | 影响 |
|---|---|---|
| 标注偏差 | 标注者群体不能代表所有用户 | 模型会偏向特定偏好 |
| 奖励模型误差 | RM 只是偏好的近似 | 可能错误奖励低质量回答 |
| 奖励黑客 | 模型学会迎合 RM 的漏洞 | 输出看似合格但实际不可靠 |
| 成本较高 | 需要高质量示范和偏好数据 | 数据采集与训练成本高 |
| 事实性仍有限 | 模型可能继续幻觉 | 需要检索、引用和验证机制配合 |
| 安全边界不完整 | 新场景可能绕过已学规则 | 需要持续评估和红队测试 |
DeepMind 的 Sparrow 工作进一步强调了规则拆解、证据支持和有害性评估的重要性。它说明 RLHF 往往需要和安全规则、事实证据、红队测试共同使用,不能只依赖单一奖励模型。
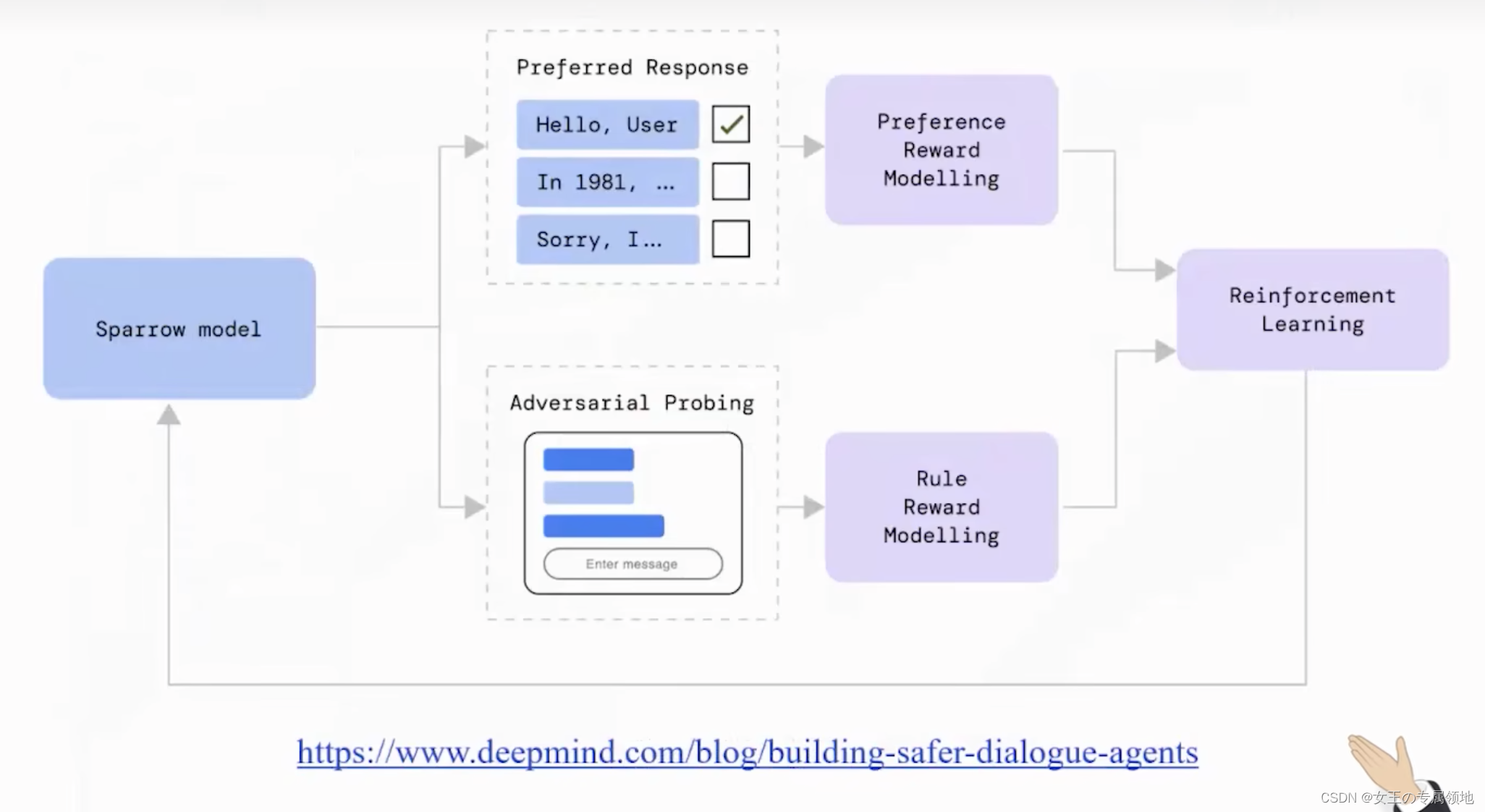
12. 与其他对齐方法的关系
| 方法 | 核心思想 | 与 RLHF 的关系 |
|---|---|---|
| SFT | 模仿高质量示范回答 | 通常是 RLHF 前置阶段 |
| RLAIF | 用 AI 反馈替代或补充人类反馈 | 降低人工标注成本 |
| Constitutional AI | 用规则或原则指导偏好反馈 | 可与 RLHF 或 RLAIF 结合 |
| DPO | 直接从偏好对中优化策略 | 替代 PPO 式 RLHF 的偏好优化路线 |
| IPO、KTO 等 | 改造偏好优化目标 | 属于偏好对齐算法扩展 |
| 检索增强 RAG | 生成前引入外部知识 | 主要改善事实依据,不等同于偏好对齐 |
RLHF 关注的是模型行为与人类偏好的匹配,RAG(Retrieval-Augmented Generation)关注的是回答能否利用外部知识。二者可以结合,但不能互相替代。
13. 复习提纲
- RLHF 的本质是把人类偏好转化为训练信号,用于对齐语言模型行为。
- 经典 PPO 式 RLHF 包括 SFT、奖励模型训练、PPO 强化学习优化。
- PPO 是经典 RLHF 内部的强化学习算法,不是完整对齐流程。
- DPO 是替代 PPO 式 RLHF 的偏好优化路线,不是 PPO 之后的下一阶段。
- 奖励模型通常通过偏好排序训练,而不是直接使用绝对打分。
- PPO 阶段的关键约束是 KL 惩罚,用于限制策略模型偏离 SFT 模型。
- PEFT 是降低训练成本的方法,不是 RLHF 的核心定义。
- RLHF 不能彻底消除幻觉、偏差和安全风险,需要评估、检索、规则和红队测试配合。
14. . 参考资料
- CSDN:RLHF 学习笔记
- Hugging Face:Illustrating Reinforcement Learning from Human Feedback
- Hugging Face 中文版:RLHF 技术分解
- OpenAI InstructGPT 论文:Training language models to follow instructions with human feedback
- DeepMind Sparrow 论文:Improving alignment of dialogue agents via targeted human judgements
- DPO 论文:Direct Preference Optimization

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)