Transformer
Transformer架构
Transformer 架构是 2017 年由 Google Brain 团队在其开创性论文《Attention Is All You Need》中提出的深度学习模型。它彻底摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),完全依赖于自注意力机制(Self-Attention Mechanism),一举解决了序列建模中的长距离依赖和并行计算效率两大核心瓶颈,成为当今大模型时代的基石。
整体架构
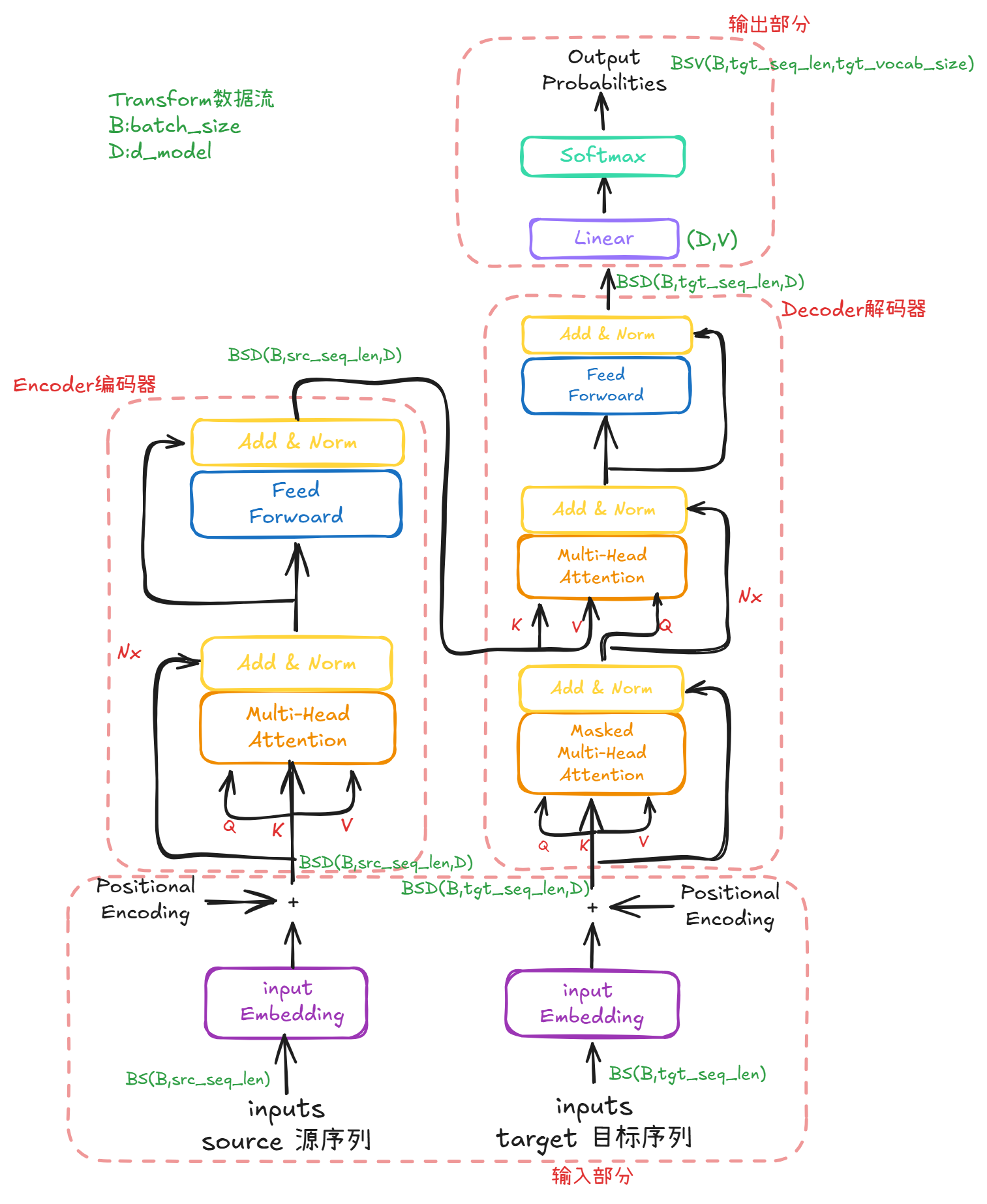
标准的 Transformer 采用经典的编码器-解码器(Encoder-Decoder)结构。原始论文中的模型由 6 个相同的编码器层和 6 个相同的解码器层堆叠而成。
- 编码器 (Encoder):负责“理解”输入。它接收输入序列,并从中提取出包含丰富上下文信息的全局语义特征。
- 解码器 (Decoder):负责“生成”输出。它基于编码器的输出和已生成的部分序列,自回归地(即一个接一个地)生成目标序列。
整个数据处理流程如下:
- 输入处理:输入和输出的文本序列首先被转换为词嵌入向量,并叠加位置编码(Positional Encoding)以注入序列的顺序信息。
- 编码阶段:处理后的输入序列进入编码器堆栈,经过多层变换,最终输出一个包含完整输入上下文信息的语义编码矩阵。
- 解码阶段:解码器堆栈接收编码器的输出,并结合目标序列的前缀信息,逐步生成最终的输出序列。
- 输出映射:解码器的输出通过一个线性层和一个 Softmax 函数,被映射为词表中每个词的概率分布,从而生成下一个词。
架构详解
输入部分
1.分词:从文本到数字索引
模型无法直接理解人类语言,因此第一步是将文本切分成更小的单元,称为“词元”,并映射为数字索引。
- 处理流程:原始文本 → 词元化 → 查表 → 索引序列。
- 主流算法:目前主流模型(如 GPT、BERT)多采用 Byte-Pair Encoding 或 WordPiece算法。
- 这些算法在“词表大小”和“序列长度”之间取得了平衡。
- 它们能将生僻词拆解为常见的子词单元。例如,单词 “transformer” 可能会被拆解为 “trans” 和 “former”。
- 这种机制极大地降低了词表大小,同时有效解决了未登录词的问题。
2.词嵌入(Input Embedding):赋予数字语义
获得索引序列后,模型通过一个可学习的查找表,将这些离散的数字索引转换为连续的稠密向量。
- 定义:假设词表大小为 VVV ,嵌入维度为 dmodeld_{model}dmodel,则嵌入矩阵的形状为 V×dmodelV×d_{model}V×dmodel。
- 作用:每个索引对应矩阵中的一行向量。这个向量不仅是词的 ID,更蕴含了词的语义信息。在训练过程中,语义相近的词(如“猫”和“狗”),其向量在空间中的距离也会非常接近。
3.位置编码(Positional Encoding):注入顺序信息
这是 Transformer 输入部分最独特的设计。由于 Transformer 架构本身不包含循环或卷积结构,它是排列不变的。这意味着,如果不加处理,输入 “I love you” 和 “you love I” 对模型来说是完全一样的。
为了解决这个问题,必须在输入中显式地加入位置信息。
-
绝对位置编码
原始论文《Attention Is All You Need》中提出了一种基于正弦和余弦函数的固定位置编码。
计算公式:对于位置 pospospos 和维度 iii ,编码值计算如下:
PE(pos,2i)=sin(pos100002i/dmodel)PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)PE(pos,2i)=sin(100002i/dmodelpos)
PE(pos,2i+1)=cos(pos100002i/dmodel)PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)PE(pos,2i+1)=cos(100002i/dmodelpos)
原理:这种设计使得模型能够通过线性变换轻松地学习到相对位置关系
最终输入:词嵌入向量与位置编码向量相加,形成最终的输入表示:
Input=Embeddingtoken+EmbeddingpositionInput=Embedding_{token}+Embedding_{position}Input=Embeddingtoken+Embeddingposition
-
现代演进:可学习位置编码与 RoPE
虽然原始的正弦位置编码很经典,但在现代大模型中,我们看到了更多的演进:
- 可学习位置编码:像 BERT 那样,直接将位置编码作为一个可训练的向量参数,与词嵌入相加。
- 旋转位置编码:这是目前 LLaMA 等主流大模型广泛采用的技术。它不再将位置信息直接加到输入上,而是通过旋转矩阵作用于注意力机制中的查询和键向量上。这种方法能更好地处理长序列,并具有更好的外推性(即处理比训练时更长的文本)。
总结:输入部分的流水线
- 文本 (“Hello World”)
↓ - 分词器 (将文本切分为索引,如 [101, 7592, 2088, 102])
↓ - 词嵌入查找 (将索引转换为向量 EtokenE_{token}Etoken )
↓ - 位置编码生成 (生成位置向量 EposE_{pos}Epos )
↓ - 相加 ( X=Etoken+EposX=E_{token}+E_{pos}X=Etoken+Epos )
↓ - 输入模型 (张量 XXX 进入第一层编码器或解码器)
PyTorch代码
import torch
import torch.nn as nn
import math
# ==========================================
# 1. 简易分词器 (Tokenizer)
# ==========================================
class SimpleTokenizer:
"""
一个简单的词表映射类,用于将文本转换为索引。
在实际项目中,通常使用 HuggingFace 的 transformers 库中的 tokenizer。
"""
def __init__(self, word2idx):
self.word2idx = word2idx
self.idx2word = {i: w for w, i in word2idx.items()}
self.vocab_size = len(word2idx)
def encode(self, text):
# 简单的按空格分词,实际应使用 BPE 或 WordPiece
words = text.lower().split()
# 将词转换为索引,未知词用 <UNK> 的索引代替
return [self.word2idx.get(w, self.word2idx['<UNK>']) for w in words]
def decode(self, indices):
return ' '.join([self.idx2word[i] for i in indices])
# ==========================================
# 2. 词嵌入层 (Token Embedding)
# ==========================================
class InputEmbeddings(nn.Module):
def __init__(self, d_model: int, vocab_size: int):
super().__init__()
self.d_model = d_model
self.vocab_size = vocab_size
# PyTorch 的 Embedding 层本质上是一个查找表
self.embedding = nn.Embedding(vocab_size, d_model)
def forward(self, x):
"""
x: (batch_size, seq_len) - 包含词索引的张量
返回: (batch_size, seq_len, d_model) - 稠密向量
"""
# 论文建议:Embedding 乘以 sqrt(d_model) 以放大数值,
# 防止与位置编码相加时被淹没
return self.embedding(x) * math.sqrt(self.d_model)
# ==========================================
# 3. 位置编码层 (Positional Encoding)
# ==========================================
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, max_seq_len: int = 5000, dropout: float = 0.1):
super().__init__()
self.d_model = d_model
self.dropout = nn.Dropout(dropout)
# 创建位置编码矩阵 PE (max_seq_len, d_model)
pe = torch.zeros(max_seq_len, d_model)
# 创建位置向量 pos (max_seq_len, 1)
position = torch.arange(0, max_seq_len, dtype=torch.float).unsqueeze(1)
# 计算分母项 div_term: 10000^(2i/d_model)
# 这里的 exp 和 log 运算等价于 1 / 10000^(2i/d_model)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 应用正弦函数到偶数维度
pe[:, 0::2] = torch.sin(position * div_term)
# 应用余弦函数到奇数维度
pe[:, 1::2] = torch.cos(position * div_term)
# 增加 batch 维度,变为 (1, max_seq_len, d_model),方便广播
pe = pe.unsqueeze(0)
# 注册为 buffer,意味着它不是模型参数(不会被梯度更新),
# 但会随模型一起保存和加载
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: (batch_size, seq_len, d_model)
返回: (batch_size, seq_len, d_model)
"""
# 截取与输入序列长度对应的位置编码,并与输入相加
# x.requires_grad_(False) 确保位置编码不参与梯度计算
x = x + self.pe[:, :x.shape[1], :].requires_grad_(False)
return self.dropout(x)
# ==========================================
# 4. 整合输入模块
# ==========================================
class TransformerInput(nn.Module):
def __init__(self, vocab_size, d_model, max_seq_len, dropout=0.1):
super().__init__()
self.token_embed = InputEmbeddings(d_model, vocab_size)
self.pos_encoding = PositionalEncoding(d_model, max_seq_len, dropout)
def forward(self, indices):
# 1. 索引 -> 词嵌入
embedded = self.token_embed(indices)
# 2. 词嵌入 + 位置编码
final_input = self.pos_encoding(embedded)
return final_input
# ==========================================
# 5. 测试代码
# ==========================================
if __name__ == "__main__":
# --- 模拟数据 ---
# 假设我们有一个很小的词表
vocab = {
"<PAD>": 0, "<UNK>": 1, "hello": 2, "world": 3,
"transformer": 4, "is": 5, "powerful": 6
}
tokenizer = SimpleTokenizer(vocab)
# 输入文本
text = "hello world transformer is powerful"
# 转换为索引
indices = tokenizer.encode(text)
print(f"原始文本: {text}")
print(f"词索引: {indices}")
# 转换为 PyTorch 张量,增加 batch 维度 (1, seq_len)
input_tensor = torch.tensor([indices], dtype=torch.long)
# --- 模型参数 ---
d_model = 512 # 嵌入维度
max_len = 100 # 最大序列长度
vocab_size = len(vocab)
# --- 构建输入模块 ---
model_input = TransformerInput(vocab_size, d_model, max_len)
# --- 前向传播 ---
output = model_input(input_tensor)
print("-" * 30)
print(f"输入张量形状: {input_tensor.shape}")
print(f"输出张量形状: {output.shape}")
print(f"输出含义: (Batch=1, SeqLen={len(indices)}, D_model={d_model})")
print("-" * 30)
# 验证位置编码是否生效
# 如果位置编码生效,同一个词在不同位置的向量表示应该是不同的
vec_pos_0 = output[0, 0, :] # "hello" 的向量
vec_pos_1 = output[0, 1, :] # "world" 的向量
# 计算余弦相似度(这里只是简单验证它们不相等)
if not torch.equal(vec_pos_0, vec_pos_1):
print("验证成功:位置编码已注入,不同位置的向量表示不同。")
else:
print("验证失败:向量完全相同。")
代码核心细节解析
1.为什么要乘以 dmodel\sqrt{d_{model}}dmodel?
在 InputEmbeddings 中,我们将嵌入结果乘以了 dmodel\sqrt{d_{model}}dmodel。
- 原因:位置编码的值域在 [−1,1][−1,1][−1,1]之间,幅度较小。而词嵌入向量经过 Xavier 初始化后,其数值幅度通常较大(与 dmodel\sqrt{d_{model}}dmodel 成正比)。
- 目的:为了让两者相加时,位置编码的信息不会被词嵌入的巨大数值“淹没”,从而保证模型能同时重视语义信息和位置信息。
register_buffer 的作用
在 PositionalEncoding 中,我们使用 self.register_buffer('pe', pe) 而不是直接定义 self.pe = pe。
- 区别:
buffer是模型状态字典(state_dict)的一部分,它会随模型保存和加载,但它不是模型的参数,不会参与梯度下降更新。 - 必要性:位置编码是固定的数学公式计算出来的,不需要学习,所以必须注册为 buffer。
2.维度变换
- 输入:
(Batch, Seq_Len)—— 纯数字索引。 - 嵌入后:
(Batch, Seq_Len, D_Model)—— 稠密语义向量。 - 加位置编码:
(Batch, Seq_Len, D_Model)—— 包含位置信息的最终输入。
Encoder编码器
编码器由 NNN 个完全相同的层堆叠而成(论文中 N=6N=6N=6)。每一层包含两个主要子模块:
- 多头自注意力机制:负责“理解”上下文关系。
- 前馈神经网络:负责“加工”特征。
每个子模块周围都有残差连接,并且后面紧跟着层归一化,来保证训练的稳定性和效率。
数据流向:输入 → [子层1:Multi-Head Self-Attention] → 残差连接 & 层归一化 → [子层2:FFN] → 残差连接 & 层归一化 → 输出
1.多头自注意力机制 (Multi-Head Self-Attention)
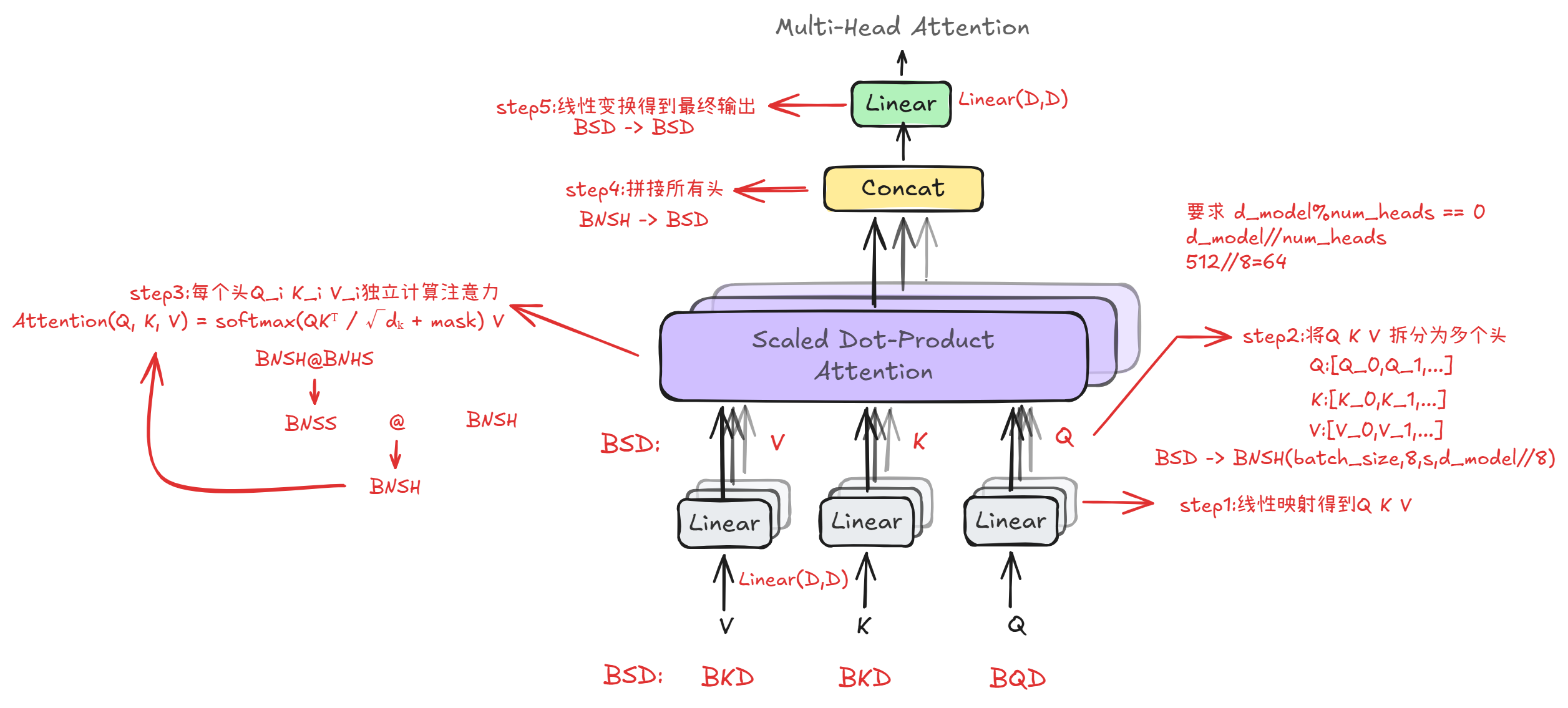
它允许序列中的每个词元都与序列中的所有其他词元(包括它自己)进行交互,从而计算出每个词元对于当前上下文的重要性权重
-
自注意力 (Self-Attention)
核心思想是为每个词元生成三个向量:查询向量(Query, Q)、键向量(Key, K)和值向量(Value, V)。通过计算 Q 和 K 的点积来衡量相关性,然后用这个相关性作为权重对 V 进行加权求和,得到包含上下文信息的新表示。
-
多头 (Multi-Head)
模型会将 Q、K、V 向量拆分成多个“头”(例如8个),让每个头在不同的子空间里独立计算注意力。这使得模型可以同时从不同角度(如语法、语义、指代关系等)捕捉信息,极大地丰富了模型的表达能力。最后,所有头的输出会被拼接起来,并通过一个线性层进行融合。
2.前馈神经网络 (Feed-Forward Network, FFN)
这是一个简单的两层全连接网络,中间通常使用 ReLU 或 GELU 等非线性激活函数。
- 作用: 对自注意力层输出的特征进行逐点的非线性变换和增强,提升模型的抽象和表达能力。
- 特点: 它对序列中的每个位置独立且相同地进行处理,不依赖序列的顺序。
3.残差连接 (Residual Connection) 与 层归一化 (Layer Normalization)
这两个技术被应用在每一个子层之后,是训练深层网络的关键。
- 残差连接: 将子层的输入
x直接加到其输出SubLayer(x)上,即x + SubLayer(x)。这为梯度提供了一条“高速公路”,有效缓解了深层网络中的梯度消失问题。 - 层归一化 (LayerNorm): 对每个样本的特征维度进行归一化,使其均值为0,方差为1。这可以稳定训练过程中的数值分布,加速模型收敛。
4.多层堆叠
编码器的强大之处在于其深度。通过将多个(如6个)编码器层堆叠起来,模型能够逐层提炼和抽象特征。
- 堆叠方式: 第
l层编码器的输出,会作为第l+1层编码器的输入。 - 信息流: 底层编码器可能捕捉到局部的语法结构,而高层编码器则能整合更全局的语义和篇章信息。
PyTorch代码
import torch
import torch.nn as nn
import math
# ==========================================
# 1. 多头自注意力机制
# ==========================================
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int, dropout: float = 0.1):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
# 确保 d_model 能被 num_heads 整除
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_k = d_model // num_heads # 每个头的维度
# 定义 Q, K, V 的线性变换矩阵
# 我们将 Q, K, V 投影到 d_model 维度,以便后续拼接
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model) # 输出线性变换
self.dropout = nn.Dropout(dropout)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
"""
计算缩放点积注意力
Q, K, V shape: (batch_size, num_heads, seq_len, d_k)
"""
# 1. 计算 Q 和 K 的转置的点积
# (batch, h, seq_len, d_k) @ (batch, h, d_k, seq_len) -> (batch, h, seq_len, seq_len)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# 2. 应用掩码(如果有)
if mask is not None:
# 将掩码为0的位置填充为负无穷,Softmax后变为0
scores = scores.masked_fill(mask == 0, -1e9)
# 3. Softmax 归一化
attention_weights = torch.softmax(scores, dim=-1)
attention_weights = self.dropout(attention_weights)
# 4. 加权求和 V
# (batch, h, seq_len, seq_len) @ (batch, h, seq_len, d_k) -> (batch, h, seq_len, d_k)
output = torch.matmul(attention_weights, V)
return output
def forward(self, x, mask=None):
batch_size, seq_len, _ = x.shape
# 1. 线性变换并拆分多头
# (batch, seq_len, d_model) -> (batch, seq_len, d_model)
Q = self.w_q(x)
K = self.w_k(x)
V = self.w_v(x)
# 2. 改变形状以进行多头计算
# (batch, seq_len, d_model) -> (batch, seq_len, num_heads, d_k) -> (batch, num_heads, seq_len, d_k)
Q = Q.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# 3. 计算注意力
# (batch, num_heads, seq_len, d_k)
attention_output = self.scaled_dot_product_attention(Q, K, V, mask)
# 4. 合并多头结果
# (batch, num_heads, seq_len, d_k) -> (batch, seq_len, num_heads, d_k) -> (batch, seq_len, d_model)
attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
# 5. 最终线性变换
output = self.w_o(attention_output)
return output
# ==========================================
# 2. 前馈神经网络
# ==========================================
class FeedForwardNetwork(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float = 0.1):
super().__init__()
# 两个线性层,中间加激活函数
# 通常 d_ff = 4 * d_model
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.activation = nn.ReLU() # 论文中使用 ReLU
def forward(self, x):
# (batch, seq_len, d_model) -> (batch, seq_len, d_ff) -> (batch, seq_len, d_model)
x = self.linear1(x)
x = self.activation(x)
x = self.dropout(x)
x = self.linear2(x)
return x
# ==========================================
# 3. 层归一化与残差连接
# ==========================================
class SublayerConnection(nn.Module):
"""
残差连接 + 层归一化
注意:这里采用的是 Pre-LN 还是 Post-LN 取决于具体实现
论文中是:LayerNorm(x + Sublayer(x))
"""
def __init__(self, d_model: int, dropout: float = 0.1):
super().__init__()
self.norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
# x + Dropout(Sublayer(LayerNorm(x))) -> 这种是 Pre-LN,训练更稳定
# 或者 LayerNorm(x + Dropout(Sublayer(x))) -> 这种是 Post-LN,符合原论文
# 这里演示 Post-LN 结构
return self.norm(x + self.dropout(sublayer(x)))
# ==========================================
# 4. 单个编码器层
# ==========================================
class EncoderLayer(nn.Module):
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.1):
super().__init__()
self.self_attention = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = FeedForwardNetwork(d_model, d_ff, dropout)
self.norm1 = SublayerConnection(d_model, dropout)
self.norm2 = SublayerConnection(d_model, dropout)
def forward(self, x, src_mask):
# 1. 自注意力子层
x = self.norm1(x, lambda x: self.self_attention(x, src_mask))
# 2. 前馈网络子层
x = self.norm2(x, self.feed_forward)
return x
# ==========================================
# 5. 编码器堆叠
# ==========================================
class Encoder(nn.Module):
def __init__(self, num_layers: int, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.1):
super().__init__()
# 使用 ModuleList 堆叠 N 个编码器层
self.layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)
])
self.norm = nn.LayerNorm(d_model) # 最后的层归一化
def forward(self, x, src_mask):
# 依次通过每一层
for layer in self.layers:
x = layer(x, src_mask)
return self.norm(x)
# ==========================================
# 6. 测试代码
# ==========================================
if __name__ == "__main__":
# 模拟参数
batch_size = 2
seq_len = 10
d_model = 512
num_heads = 8
d_ff = 2048
num_layers = 6
# 模拟输入 (来自输入部分:词嵌入 + 位置编码)
# shape: (batch_size, seq_len, d_model)
input_tensor = torch.randn(batch_size, seq_len, d_model)
# 模拟源掩码 (全1表示可见,用于填充掩码)
# shape: (batch_size, 1, 1, seq_len) 或 (batch_size, seq_len)
# 这里假设没有填充,全为1
src_mask = torch.ones(batch_size, 1, 1, seq_len)
# 构建编码器
encoder = Encoder(num_layers, d_model, num_heads, d_ff)
# 前向传播
output = encoder(input_tensor, src_mask)
print(f"输入形状: {input_tensor.shape}")
print(f"输出形状: {output.shape}")
print(f"编码器处理完成!输出张量包含完整的上下文信息。")
代码核心细节解析
1.多头注意力的“分头”与“合并”
在 MultiHeadAttention 中,最复杂的操作是维度的变换:
- 分头:
view(batch, seq_len, num_heads, d_k).transpose(1, 2)。我们将一个大的 dmodeld_{model}dmodel向量切分成num_heads个小的 dkd_kdk 向量。 - 并行计算:PyTorch 的广播机制允许我们一次性对所有头进行矩阵乘法,无需写循环。
- 合并:计算完注意力后,我们需要
transpose回来,并用contiguous().view将所有头的结果拼回 dmodeld_{model}dmodel维度。
2.掩码的作用
在编码器中,src_mask 通常用于填充掩码。
- 如果输入序列长度不一,我们会用
<PAD>补齐。 src_mask会将这些<PAD>位置的注意力分数设为 −∞−∞−∞,确保模型在计算上下文时忽略这些无意义的填充符号。
3.残差连接与层归一化
SublayerConnection 类实现了 x + Dropout(Sublayer(x)) 的结构。
- 残差连接:让梯度可以直接流向浅层,解决了深层网络难以训练的问题。
- 层归一化:将特征缩放到均值为 0、方差为 1 的分布,加速收敛。
4.前馈网络
这是一个简单的两层全连接网络,但它对序列中的每个位置独立地进行相同的变换。它的作用是引入非线性,增加模型的表达能力,类似于卷积神经网络中的 1×11×11×1 卷积。
这个编码器模块就是 Transformer 的“大脑皮层”,它通过层层叠加,将简单的词向量转化为了富含深层语义的上下文表示。
Decoder解码器
解码器同样由 NNN 个层堆叠而成(通常 N=6N=6N=6 ),但每一层内部包含三个子层,而不是编码器的两个:
- 掩码多头自注意力:让解码器关注已生成的单词。
- 交叉注意力:连接编码器和解码器的桥梁。
- 前馈神经网络:与编码器中的完全相同,用于特征变换。
同样,残差连接 (Residual Connection) 和 层归一化 (Layer Normalization) 也被应用在每一个子层之后,以确保深层网络的稳定训练。
数据流向:输入 → [子层1:Masked Multi-Head Self-Attention] → 残差连接 & 层归一化 → [子层2:Encoder-Decoder Attention] → 残差连接 & 层归一化 → [子层3:FFN] → 残差连接 & 层归一化 → 输出
1.掩码多头自注意力机制 (Masked Multi-Head Self-Attention)
这个子层与编码器的自注意力机制非常相似,但增加了一个至关重要的“掩码”(Mask)。
- 作用: 让解码器能够关注到已经生成的词元,理解已生成部分的上下文关系。
- 掩码 (Mask) 的目的: 在训练和推理时,解码器在生成第
i个词时,只能看到第1到i-1个已经生成的词,而不能“偷看”未来的词。这保证了生成过程的因果性(Autoregressive)。 - 实现方式: 通过在计算注意力分数时,将未来位置的分数设置为负无穷大(
-inf),这样在经过 Softmax 函数后,这些位置的权重就变为0,从而实现信息屏蔽。
2.编码器-解码器注意力机制 (Encoder-Decoder Attention)
这是解码器独有的、连接编码器和解码器的桥梁,也常被称为交叉注意力(Cross-Attention)。
- 作用: 让解码器在生成当前词时,能够动态地关注输入序列中最相关的部分。
- 实现方式:
- 查询 (Query, Q): 来自上一层(掩码自注意力层)的输出,代表解码器当前的生成状态。
- 键 (Key, K) 和 值 (Value, V): 来自编码器的最终输出。这包含了输入序列的完整上下文信息。
- 意义: 通过这种方式,解码器将“已生成内容的信息”(Q)与“原始输入内容的信息”(K, V)结合起来,从而生成一个既符合上下文又忠实于原文的新词。
- 源掩码(交叉注意力中也有Mask):
-
- 它通常来自编码器,用于屏蔽输入序列中的填充符号。
- 目的:防止解码器关注输入序列中无意义的填充部分
3.前馈神经网络 (Feed-Forward Network, FFN)
这个子层与编码器中的前馈神经网络完全相同。
- 作用: 对交叉注意力层输出的特征进行逐点的非线性变换和增强,提升模型的表达能力。它独立地处理序列中的每个位置。
PyTorch代码
import torch
import torch.nn as nn
import math
# ==========================================
# 1. 复用之前的组件
# ==========================================
# 这里复用之前定义的 FeedForwardNetwork, SublayerConnection, MultiHeadAttention
# 为了代码完整性,这里简单定义一下(实际使用时请引用之前的代码)
class FeedForwardNetwork(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.activation = nn.ReLU()
def forward(self, x):
return self.linear2(self.dropout(self.activation(self.linear1(x))))
class SublayerConnection(nn.Module):
def __init__(self, d_model, dropout=0.1):
super().__init__()
self.norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
return self.norm(x + self.dropout(sublayer(x)))
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.1):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
assert d_model % num_heads == 0
self.d_k = d_model // num_heads
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention_weights = torch.softmax(scores, dim=-1)
attention_weights = self.dropout(attention_weights)
return torch.matmul(attention_weights, V)
def forward(self, q, k, v, mask=None):
batch_size = q.shape[0]
# 线性变换
Q = self.w_q(q)
K = self.w_k(k)
V = self.w_v(v)
# 拆分多头
Q = Q.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 计算注意力
attention_output = self.scaled_dot_product_attention(Q, K, V, mask)
# 合并多头
attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
return self.w_o(attention_output)
# ==========================================
# 2. 单个解码器层
# ==========================================
class DecoderLayer(nn.Module):
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.1):
super().__init__()
# 1. 掩码自注意力
self.self_attention = MultiHeadAttention(d_model, num_heads, dropout)
# 2. 交叉注意力 (Encoder-Decoder Attention)
self.cross_attention = MultiHeadAttention(d_model, num_heads, dropout)
# 3. 前馈网络
self.feed_forward = FeedForwardNetwork(d_model, d_ff, dropout)
# 三个残差连接
self.norm1 = SublayerConnection(d_model, dropout)
self.norm2 = SublayerConnection(d_model, dropout)
self.norm3 = SublayerConnection(d_model, dropout)
def forward(self, x, encoder_output, src_mask, tgt_mask):
# --- 子层 1: 掩码自注意力 ---
# Q, K, V 都来自解码器输入 x
x = self.norm1(x, lambda x: self.self_attention(x, x, x, tgt_mask))
# --- 子层 2: 交叉注意力 ---
# Q 来自解码器 x, K, V 来自编码器输出
x = self.norm2(x, lambda x: self.cross_attention(x, encoder_output, encoder_output, src_mask))
# --- 子层 3: 前馈网络 ---
x = self.norm3(x, self.feed_forward)
return x
# ==========================================
# 3. 解码器堆叠
# ==========================================
class Decoder(nn.Module):
def __init__(self, num_layers: int, d_model: int, num_heads: int, d_ff: int, dropout: float = 0.1):
super().__init__()
self.layers = nn.ModuleList([
DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)
])
self.norm = nn.LayerNorm(d_model)
def forward(self, x, encoder_output, src_mask, tgt_mask):
# 依次通过每一层
for layer in self.layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return self.norm(x)
# ==========================================
# 4. 测试代码
# ==========================================
if __name__ == "__main__":
# 模拟参数
batch_size = 2
src_seq_len = 10 # 输入序列长度
tgt_seq_len = 8 # 目标序列长度
d_model = 512
num_heads = 8
d_ff = 2048
num_layers = 6
# 模拟输入
# 解码器输入 (来自上一步的生成结果或目标标签)
decoder_input = torch.randn(batch_size, tgt_seq_len, d_model)
# 编码器输出
encoder_output = torch.randn(batch_size, src_seq_len, d_model)
# 模拟掩码
# src_mask: 屏蔽输入中的 PAD (形状通常广播为 batch, 1, 1, src_len)
src_mask = torch.ones(batch_size, 1, 1, src_seq_len)
# tgt_mask: 这是一个下三角矩阵,用于防止解码器偷看未来
# 形状: (1, tgt_len, tgt_len) 或 (batch, 1, tgt_len, tgt_len)
# 注意:这里生成的是布尔掩码,1表示可见,0表示遮挡
tgt_mask = torch.tril(torch.ones(1, tgt_seq_len, tgt_seq_len))
# 构建解码器
decoder = Decoder(num_layers, d_model, num_heads, d_ff)
# 前向传播
output = decoder(decoder_input, encoder_output, src_mask, tgt_mask)
print(f"解码器输入形状: {decoder_input.shape}")
print(f"编码器输出形状: {encoder_output.shape}")
print(f"解码器输出形状: {output.shape}")
print(f"掩码形状: {tgt_mask.shape}")
print("解码器处理完成!")
代码核心细节解析
1.为什么需要两个掩码?
在 DecoderLayer 的 forward 方法中,我们传入了两个不同的掩码:
tgt_mask(目标掩码):- 用于自注意力层。
- 它是一个下三角矩阵。
- 目的:确保位置 ii 的预测只能依赖于位置 <i<i 的已知输出。这是自回归生成的铁律。
src_mask(源掩码):- 用于交叉注意力层。
- 它通常来自编码器,用于屏蔽输入序列中的填充符号。
- 目的:防止解码器关注输入序列中无意义的填充部分。
2.交叉注意力的数据流向
这是解码器中最神奇的一步。请注意 self.cross_attention(x, encoder_output, encoder_output, src_mask) 中的参数顺序:
- Query:来自解码器当前的状态 xxx 。这意味着解码器在问:“基于我当前生成的进度,我应该关注输入句子的哪些部分?”
- Key & Value:来自编码器的输出。这意味着编码器已经把输入句子的所有信息都准备好了,等待解码器来查询。
3.推理时的“作弊”与“真实”
- 训练时:我们拥有完整的目标句子(Ground Truth)。我们可以一次性把整个目标句子输入解码器,利用
tgt_mask来模拟“逐步生成”的过程,从而实现并行训练。 - 推理时:我们没有目标句子。我们必须先输入一个起始符,生成第一个词,然后把第一个词拼接到输入中,再生成第二个词……如此循环。
输出部分
1.线性变换 (Linear Layer)
解码器输出的向量通常包含丰富的语义信息(例如维度为 512 或 768),但它本身并不是一个词。为了得到词,我们需要通过一个全连接层(Linear Layer)
- 输入:形状为
[batch_size, seq_len, d_model]的张量。 - 变换:通过一个权重矩阵 WWW ,将维度从 dmodeld_{model}dmodel 映射到词表大小 Vocab_sizeVocab\_sizeVocab_size 。
- 输出(Logits):形状变为
[batch_size, seq_len, vocab_size]。
这里的输出被称为 Logits,它们代表了模型对词表中每个词的“打分”,分数越高代表该词出现的可能性越大,但此时它们还不是概率。
2. Softmax 归一化
为了让模型输出具体的预测结果,我们需要将这些 Logits 转化为概率。这通过 Softmax 函数实现。
- 作用:将 Logits 归一化,使得所有词的预测分数加起来等于 1,且每个分数都在 0 到 1 之间。
- 结果:得到一个概率分布。例如,模型可能预测下一个词是 “apple” 的概率是 0.8,是 “orange” 的概率是 0.1,其余词概率极低。
3.选择词元
通常会选择概率最高的词元作为最终的输出,或者通过束搜索(Beam Search)等策略来选择。
权重共享
在 Transformer(特别是现代实现如 GPT)中,有一个重要的技巧:输入嵌入层和输出线性层的权重是共享的。
- 原因:输入嵌入(Input Embedding)和输出投影(Output Projection)本质上都是在“词向量空间”和“独热编码空间”之间做转换。共享权重可以减少参数量,并提高模型的泛化能力。
PyTorch 代码
import torch
import torch.nn as nn
# ==========================================
# 1. 输出层模块
# ==========================================
class OutputLayer(nn.Module):
def __init__(self, d_model: int, vocab_size: int):
super().__init__()
# 线性层:将 d_model 映射到 vocab_size
self.linear = nn.Linear(d_model, vocab_size)
def forward(self, x):
"""
x: (batch, seq_len, d_model) - 来自解码器的输出
返回: (batch, seq_len, vocab_size) - 每个词的概率分布
"""
# 这里的 linear 层会自动应用到序列的每个位置
return self.linear(x)
# ==========================================
# 2. 整合:完整的 Transformer 模型
# ==========================================
# 假设我们已经定义了 Encoder 和 Decoder 类 (参考之前的代码)
# 这里为了演示输出部分,我们构建一个简化的完整模型类
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, src_pos, tgt_pos, vocab_size):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
# 输出层
self.output_layer = OutputLayer(encoder.layers[0].self_attention.d_model, vocab_size)
# 【关键技巧】权重共享
# 将输出层的权重初始化为输入嵌入层的权重
# 这样可以显著减少参数量并提升效果
self.output_layer.linear.weight = self.tgt_embed.embedding.weight
def forward(self, src, tgt, src_mask, tgt_mask):
# 1. 输入处理
src_embedded = self.src_pos(self.src_embed(src))
tgt_embedded = self.tgt_pos(self.tgt_embed(tgt))
# 2. 编码
encoder_output = self.encoder(src_embedded, src_mask)
# 3. 解码
decoder_output = self.decoder(tgt_embedded, encoder_output, src_mask, tgt_mask)
# 4. 输出投影
# 此时 decoder_output 形状为 (batch, seq_len, d_model)
# 经过 output_layer 后变为 (batch, seq_len, vocab_size)
return self.output_layer(decoder_output)
# ==========================================
# 3. 测试输出部分
# ==========================================
if __name__ == "__main__":
# 模拟解码器输出 (batch=1, seq_len=5, d_model=512)
# 假设我们生成了5个时间步的特征
mock_decoder_output = torch.randn(1, 5, 512)
# 模拟词表大小
vocab_size = 10000
# 实例化输出层
output_layer = OutputLayer(d_model=512, vocab_size=vocab_size)
# 前向传播
logits = output_layer(mock_decoder_output)
# 计算概率 (Softmax)
# dim=-1 表示在词表维度上进行归一化
probabilities = torch.softmax(logits, dim=-1)
print(f"解码器输出形状: {mock_decoder_output.shape}")
print(f"Logits 形状: {logits.shape}")
print(f"概率分布形状: {probabilities.shape}")
# 获取预测结果
# 取概率最大的词的索引
predicted_indices = torch.argmax(probabilities, dim=-1)
print(f"预测的词索引: {predicted_indices}")
print(f"第一个位置概率最大的词: {predicted_indices[0, 0].item()}")
代码核心细节解析
维度变换
- 输入:解码器输出的是特征向量,形状为 (Batch,Seq_Len,dmodel)(Batch,Seq\_Len,d_{model})(Batch,Seq_Len,dmodel) 。
- 输出:经过线性层后,形状变为 (Batch,Seq_Len,Vocab_Size)(Batch,Seq\_Len,Vocab\_Size)(Batch,Seq_Len,Vocab_Size) 。这意味着对于序列中的每一个位置,模型都给出了词表中每个词的可能性。
权重共享
代码中 self.output_layer.linear.weight = self.tgt_embed.embedding.weight 这一行非常重要。
- 意义:它强制模型在“理解词”(输入嵌入)和“生成词”(输出投影)时使用同一套向量表示。
- 效果:这不仅减少了显存占用,还让模型在训练时能更有效地学习词向量。
推理过程
在实际使用(推理)时,流程是这样的:
- 解码器输出特征向量。
- 输出层将其映射为 Logits。
- Softmax 计算概率。
- ArgMax 取出概率最大的词的索引。
- 将该索引对应的词嵌入作为下一步的输入,循环往复。
PyTorch nn.Transformer
import torch
import torch.nn as nn
# 1. 定义参数
d_model = 512 # 词向量维度
nhead = 8 # 多头注意力的头数
num_encoder_layers = 6
num_decoder_layers = 6
# 2. 实例化模型
# PyTorch 会自动初始化编码器和解码器堆栈
transformer = nn.Transformer(
d_model=d_model,
nhead=nhead,
num_encoder_layers=num_encoder_layers,
num_decoder_layers=num_decoder_layers,
batch_first=True # 【重要】设置为 True,输入形状为 (Batch, Seq, Feature),更符合直觉
)
# 3. 准备模拟数据
batch_size = 32
src_seq_len = 10
tgt_seq_len = 20
# 输入数据 (Batch, Seq_Len, Feature)
src = torch.rand(batch_size, src_seq_len, d_model)
tgt = torch.rand(batch_size, tgt_seq_len, d_model)
# 4. 前向传播
# 注意:实际使用时必须传入掩码,否则解码器会“偷看”未来
output = transformer(src, tgt)
print(f"输入形状: {src.shape}")
print(f"输出形状: {output.shape}") # [32, 20, 512]
🌰基于 PyTorch 的机器翻译模型
完整的翻译流程:
- 模型封装:集成了 Embedding、位置编码、Transformer 核心和输出层。
- 掩码管理:自动处理源端填充掩码和目标端因果掩码。
- 训练循环:模拟了数据输入和梯度更新。
- 推理函数:实现了自回归生成(即训练好后如何逐字翻译)。
import torch
import torch.nn as nn
import torch.optim as optim
import math
from torch.utils.data import DataLoader, Dataset
# ==========================================
# 1. 模型定义部分
# ==========================================
class PositionalEncoding(nn.Module):
"""位置编码模块"""
def __init__(self, d_model, dropout=0.1, max_len=5000):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
# 初始化位置编码矩阵
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
# x shape: (Batch, Seq_Len, Dim)
x = x + self.pe[:, :x.size(1), :]
return self.dropout(x)
class TranslationModel(nn.Module):
"""封装后的 Transformer 翻译模型"""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, nhead=8, num_layers=6):
super().__init__()
self.d_model = d_model
# 1. 词嵌入层
self.src_embed = nn.Embedding(src_vocab_size, d_model)
self.tgt_embed = nn.Embedding(tgt_vocab_size, d_model)
# 2. 位置编码
self.pos_encoder = PositionalEncoding(d_model)
self.pos_decoder = PositionalEncoding(d_model)
# 3. 核心 Transformer (使用 PyTorch 官方封装)
self.transformer = nn.Transformer(
d_model=d_model,
nhead=nhead,
num_encoder_layers=num_layers,
num_decoder_layers=num_layers,
dim_feedforward=2048,
dropout=0.1,
batch_first=True # 设置为 True,输入为 (Batch, Seq, Dim)
)
# 4. 输出投影层
self.out = nn.Linear(d_model, tgt_vocab_size)
# 权重初始化 (重要!)
self._init_weights()
def _init_weights(self):
for p in self.parameters():
if p.dim() > 1:
# Xavier 均匀分布初始化
# 用于确保深层神经网络中的权重处于合适的数值范围,从而保证训练的稳定性
nn.init.xavier_uniform_(p)
def generate_square_subsequent_mask(self, sz):
"""生成因果掩码 (防止解码器看未来)"""
return nn.Transformer.generate_square_subsequent_mask(sz)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
"""
前向传播
src: 源序列索引 (Batch, Src_Len)
tgt: 目标序列索引 (Batch, Tgt_Len)
"""
# 1. 嵌入 + 位置编码
src_embed = self.pos_encoder(self.src_embed(src))
tgt_embed = self.pos_decoder(self.tgt_embed(tgt))
# 2. 自动处理掩码
if src_mask is None:
pass # 假设没有 Padding
if tgt_mask is None:
tgt_mask = self.generate_square_subsequent_mask(tgt.shape[1]).to(src.device)
# 3. Transformer 前向传播
# 注意:PyTorch nn.Transformer 期望 mask 形状为 (Batch, Seq) 或 (Seq, Seq)
output = self.transformer(src_embed, tgt_embed, src_mask=src_mask, tgt_mask=tgt_mask)
# 4. 输出层
return self.out(output)
def translate(self, src_sentence, start_token, end_token, max_len=50, device='cpu'):
"""
推理函数:自回归生成翻译
src_sentence: 源句子索引列表
start_token: 目标语言起始符索引 (如 <sos>)
end_token: 目标语言结束符索引 (如 <eos>)
"""
self.eval()
src_tensor = torch.LongTensor([src_sentence]).to(device)
# 初始化解码器输入,只包含起始符
tgt_input = torch.LongTensor([[start_token]]).to(device)
with torch.no_grad():
for _ in range(max_len):
# 1. 准备掩码
src_mask = None
tgt_mask = self.generate_square_subsequent_mask(tgt_input.shape[1]).to(device)
# 2. 前向传播
output = self.forward(src_tensor, tgt_input, src_mask, tgt_mask)
# 3. 获取最后一个词的概率分布
next_word_logits = output[0, -1, :] # 取最后一个位置
next_word = next_word_logits.argmax(dim=-1).item()
# 4. 拼接结果
tgt_input = torch.cat([tgt_input, torch.LongTensor([[next_word]]).to(device)], dim=1)
# 5. 如果生成结束符,停止
if next_word == end_token:
break
return tgt_input[0, 1:].tolist() # 去掉起始符返回
# ==========================================
# 2. 模拟数据与训练配置
# ==========================================
# 假设参数
SRC_VOCAB = 5000
TGT_VOCAB = 5000
BATCH_SIZE = 16
EPOCHS = 5
LEARNING_RATE = 1e-4
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 实例化模型
model = TranslationModel(SRC_VOCAB, TGT_VOCAB, d_model=512).to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
criterion = nn.CrossEntropyLoss(ignore_index=0) # 忽略 Padding 的 Loss
print(f"模型已加载到 {DEVICE}")
# 模拟一个简单的数据集
class DummyDataset(Dataset):
def __init__(self, size=1000, seq_len=20):
self.size = size
self.seq_len = seq_len
def __len__(self):
return self.size
def __getitem__(self, idx):
# 随机生成源序列和目标序列 (1~4999, 0 是 padding)
src = torch.randint(1, SRC_VOCAB, (self.seq_len,))
tgt = torch.randint(1, TGT_VOCAB, (self.seq_len,))
return src, tgt
dataset = DummyDataset()
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
# ==========================================
# 3. 训练循环
# ==========================================
print("开始训练...")
for epoch in range(EPOCHS):
model.train()
total_loss = 0
for src_batch, tgt_batch in dataloader:
src_batch = src_batch.to(DEVICE)
tgt_batch = tgt_batch.to(DEVICE)
# 准备数据
# 解码器输入是 tgt 去掉最后一个词
# 期望输出是 tgt 去掉第一个词
tgt_input = tgt_batch[:, :-1]
tgt_target = tgt_batch[:, 1:]
optimizer.zero_grad()
# 前向传播
# 注意:这里我们手动传入了 tgt_mask,src_mask 默认为 None (无 Padding)
tgt_mask = model.generate_square_subsequent_mask(tgt_input.shape[1]).to(DEVICE)
output = model(src_batch, tgt_input, src_mask=None, tgt_mask=tgt_mask)
# 计算 Loss
# output: (Batch, Seq_Len-1, Vocab_Size)
# target: (Batch, Seq_Len-1)
loss = criterion(output.reshape(-1, TGT_VOCAB), tgt_target.reshape(-1))
loss.backward()
# 梯度裁剪 (防止梯度爆炸,Transformer 训练常用技巧)
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}/{EPOCHS}, Loss: {total_loss/len(dataloader):.4f}")
# ==========================================
# 4. 推理测试
# ==========================================
print("\n开始推理测试...")
# 模拟一个源句子 (索引列表)
dummy_src_sentence = [10, 20, 30, 40, 50]
# 假设 1 是 <sos>, 2 是 <eos>
translated_indices = model.translate(dummy_src_sentence, start_token=1, end_token=2, device=DEVICE)
print(f"源句子索引: {dummy_src_sentence}")
print(f"翻译结果索引: {translated_indices}")
print("完整流程演示结束!")
代码核心细节解析
1.为什么使用 batch_first=True?
PyTorch 的 Transformer 默认输入形状是 (Seq_Len, Batch, Dim),这非常反直觉。我在代码中开启了 batch_first=True,这样输入就变成了标准的 (Batch, Seq_Len, Dim),处理起来方便得多。
2.训练时的输入输出对齐
这是新手最容易晕的地方。假设目标句子是 [<sos>, A, B, C, <eos>]:
- 解码器输入:
[<sos>, A, B, C](我们要喂给模型已知的部分) - 期望输出:
[A, B, C, <eos>](我们要模型预测的部分) - 代码中通过
tgt_batch[:, :-1]和tgt_batch[:, 1:]来实现这种错位。
3.掩码的生成
- 训练时:我们一次性输入整个句子,所以必须用
generate_square_subsequent_mask生成一个下三角矩阵,遮住未来的词。 - 推理时:我们在循环中每次只输入一个词,虽然不需要遮未来的词(因为没有未来),但为了保持接口一致,我们依然传入了掩码。
4.梯度裁剪
torch.nn.utils.clip_grad_norm_ 是训练 Transformer 时的标配。由于 Transformer 层数深,容易出现梯度爆炸,将梯度范数限制在 1.0 可以让训练更稳定。
核心灵魂:自注意力机制
自注意力机制是 Transformer 的核心,它让模型在处理序列中的任何一个元素时,都能直接“关注”到序列中的所有其他元素,从而高效地捕捉全局依赖关系。
1. 自注意力计算原理
其计算过程可以概括为以下几步,核心公式为:Attention(Q, K, V) = softmax(QKᵀ / √dₖ) V
- 向量投影:将输入向量
X分别通过三个可学习的线性变换,投影成查询(Query, Q)、键(Key, K)和值(Value, V)三个矩阵。 - 相似度计算:计算
Q和K的点积,得到序列中各元素间的关联分数。除以√dₖ(dₖ是K的维度)是为了防止点积结果过大,导致 Softmax 函数进入梯度极小的区域。 - 权重归一化:通过 Softmax 函数将关联分数转换为 0 到 1 之间的权重分布,代表每个词对其他词的关注程度。
- 信息聚合:使用上一步得到的权重对
V进行加权求和,得到最终的输出。这个过程聚合了与当前词相关的所有上下文信息。
2. 多头自注意力 (Multi-Head Attention)
为了增强模型的表达能力,Transformer 采用了“多头”机制。它将 Q、K、V 切分成多个头(heads),让每个头在低维空间中独立地进行自注意力计算。这样,模型就能从不同角度、不同子空间并行地捕捉多种类型的语义关联(如语法、指代、长距离依赖等),最后将所有头的输出拼接起来并进行一次线性变换。
🔍Transformer 的并行性
Transformer 的并行性体现在两个层面:
- 算法层面:Transformer 架构本身(特别是编码器)允许在一个序列内部进行并行计算,这与 RNN 有本质区别。
- 工程层面:为了训练千亿级参数的大模型,我们需要利用“模型并行”、“数据并行”等技术将模型切分到成百上千张 GPU 上。
一、 算法层面的并行性:为什么 Transformer 比 RNN 快?
在 Transformer 出现之前,主流的 RNN(循环神经网络)是串行的。它必须算完第 t−1t−1t−1 个词,才能算第 ttt 个词,就像接力赛一样,无法加速。
Transformer 的突破在于:
- 编码器(Encoder)的完全并行:在编码器中,输入序列的所有 Token 是同时进入模型的。通过自注意力机制(Self-Attention),模型可以一次性计算序列中任意两个词之间的关联,不需要等待前一个时间步的结果。
- 解码器(Decoder)的训练与推理:
- 训练时:虽然解码器是生成式的,但在训练时我们可以利用“教师强制(Teacher Forcing)”技巧。因为目标序列(Ground Truth)是已知的,我们可以使用**掩码(Mask)**遮住未来的词,从而让解码器也能并行计算整个序列的 Loss。
- 推理时:这是真正的串行过程。生成第 ttt 个词必须依赖前 t−1t−1t−1 个已生成的词,所以推理阶段通常是一个接一个地吐字(除非使用类似 Speculative Decoding 的加速技术)。
二、 工程层面的并行策略:如何训练千亿参数模型?
当模型大到显存装不下(例如 GPT-3 或 LLaMA),或者序列长度极长时,单张 GPU 甚至单机都无法处理。这时就需要组合多种并行策略。
目前主流的并行方案主要有以下几种,通常组合使用(称为 3D 并行或混合并行):
1. 数据并行 (Data Parallelism, DP)
- 原理:把模型完整复制 NNN 份到 NNN 张 GPU 上,然后把训练数据切分成 NNN 份,每张卡处理一部分数据。
- 适用场景:模型较小,单张卡能装下,但为了加快训练速度。
- 缺点:显存占用没有减少,模型太大时无法使用。
2. 张量并行 (Tensor Parallelism, TP)
- 原理:把矩阵乘法切分。例如一个巨大的全连接层矩阵 WWW,将其按列或行切分到不同的 GPU 上。每个 GPU 计算一部分矩阵乘法,最后通过通信(All-Reduce)汇总结果。
- 适用场景:模型非常大,单层参数都超过了单张 GPU 的显存。
- 特点:通信量非常大,通常只在同一个计算节点内(NVLink 连接)的 GPU 之间进行,以减少延迟。
3. 流水线并行 (Pipeline Parallelism, PP)
- 原理:把模型像切香肠一样,按层切分。例如,GPU 0 跑第 1-10 层,GPU 1 跑第 11-20 层。数据像流水线一样流动。
- 挑战:会出现“气泡(Bubble)”,即某些 GPU 在等待上游数据时处于空闲状态。现代框架(如 DeepSpeed, Megatron-LM)通过微批次(Micro-batching)调度来减少这种空闲。
4. 序列并行 (Sequence Parallelism, SP)
- 原理:这是针对 Transformer 特有结构的优化。它将输入序列的长度维度进行切分,通常与张量并行结合使用,用于分摊 LayerNorm 和 Dropout 等操作的显存占用。
三、 并行策略对比总结
| 并行策略 | 核心逻辑 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|---|
| 数据并行 (DP) | 数据分片,模型复制 | 实现简单,通信开销相对小 | 显存受限,无法训练超大模型 | 小模型加速训练 |
| 张量并行 (TP) | 矩阵运算切分 | 解决单层显存不足问题 | 通信极其频繁,跨节点效率低 | 超大模型的层内计算 |
| 流水线并行 (PP) | 模型层级切分 | 显存利用率高,扩展性好 | 存在流水线气泡(空闲等待) | 跨节点训练超大规模模型 |
| 序列并行 (SP) | 序列长度切分 | 降低长序列显存占用 | 增加了通信复杂度 | 超长上下文(Context)训练 |
四、 进阶:最新的优化趋势
- 混合并行 (Hybrid Parallelism):
像 DeepSeek 或 NVIDIA NeMo 这样的框架,通常不会只用一种。它们会结合 TP、PP 和 SP。例如:在节点内用 TP 切分矩阵,跨节点用 PP 切分层,同时用 SP 处理长序列。 - 上下文并行 (Context Parallelism, CP):
随着视频生成或长文本(如 100k token)需求的增加,针对“上下文长度”的并行变得越来越重要。它专门解决超长序列在自注意力计算时的显存爆炸问题。 - 选择性激活重计算 (Selective Activation Recompute):
这是一种用“计算换显存”的策略。为了省下显存存中间结果(用于反向传播),系统在反向传播时选择性地重新计算部分算子。这能让显存占用大幅降低,从而支持更大的 Batch Size。
关键补充
掩码张量mask
掩码机制是 Transformer 能够正确处理序列数据和变长输入的基础。主要有两种类型的掩码:填充掩码 (Padding Mask) 和 序列掩码 (Sequence Mask),也常被称为前瞻掩码 (Look-Ahead Mask)。
填充掩码 (Padding Mask)
填充掩码的作用是过滤掉无效的填充信息。
为什么需要它?
在训练时,为了提高计算效率,我们通常会将一个批次(batch)中不同长度的句子通过填充(Padding)处理成相同的长度。例如,用特殊的 <PAD> 标记来补齐较短的句子。这些 <PAD> 标记本身没有实际语义,如果让它们参与注意力计算,会干扰模型对有效内容的理解。
如何工作?
- 生成掩码:根据输入序列,创建一个布尔矩阵。在
<PAD>标记对应的位置设为True(表示需要被屏蔽),其他有效词元位置设为False。 - 应用掩码:在计算注意力分数后、进行 Softmax 之前,将掩码中为
True的位置对应的分数设置为一个极大的负数(如-1e9或-inf)。 - 效果:经过 Softmax 函数后,这些被设置为极大负数的位置的注意力权重会趋近于 0,相当于模型完全忽略了这些填充位置。
序列掩码 / 前瞻掩码 (Sequence Mask / Look-Ahead Mask)
序列掩码是 Transformer 解码器(Decoder)部分的核心,它的作用是强制模型遵守因果律,防止“偷看”未来信息。
为什么需要它?
在序列生成任务(如翻译、写作)中,模型在预测第 i 个词时,只能依赖于它之前已经生成的 i-1 个词,而不能提前知道第 i+1 个及之后的词。这在训练时尤其重要,因为训练是并行进行的,模型一次性接收了整个目标序列,如果没有这个掩码,模型就会“作弊”,直接看到它需要预测的答案。
如何工作?
-
生成掩码:创建一个下三角矩阵。矩阵中,对角线及以下的位置(代表当前词和之前的词)设为 0,而上三角的位置(代表未来的词)设为
-inf。
例如,对于一个长度为 5 的序列,掩码矩阵如下:[ 0, -inf, -inf, -inf, -inf ] [ 0, 0, -inf, -inf, -inf ] [ 0, 0, 0, -inf, -inf ] [ 0, 0, 0, 0, -inf ] [ 0, 0, 0, 0, 0 ] -
应用掩码:同样,在解码器的自注意力层计算分数后,将这个掩码矩阵加到注意力分数上。
-
效果:上三角部分(未来信息)的分数被加上
-inf后变为负无穷,经过 Softmax 后权重为 0。这就强制模型在生成每个词时,只能关注到它自己和它之前的词。
为什么使用 -inf 而不是 0
这是一个关键的技术细节。我们使用 -inf(负无穷)而不是 0 来屏蔽信息,是因为后续的 Softmax 函数。
- Softmax(x) = ex/∑(ex)e^x / \sum (e^x)ex/∑(ex)
- 如果使用
0:e^0 = 1,这意味着被屏蔽位置的注意力权重虽然很小,但仍然是一个非零值,会对最终结果产生微弱的干扰。 - 如果使用
-inf:e^(-inf)趋近于0,这能确保被屏蔽位置的注意力权重完全为 0,实现彻底的信息屏蔽。
| 掩码类型 | 作用 | 应用场景 | 矩阵形态 |
|---|---|---|---|
| 填充掩码 | 忽略无意义的 <PAD> 标记 |
编码器和解码器 | 根据 <PAD> 位置动态生成 |
| 序列掩码 | 防止“偷看”未来信息,保证因果性 | 仅解码器的自注意力层 | 固定的下三角矩阵 |
import torch
import matplotlib
import matplotlib.pyplot as plt
# 设置后端和中文字体
matplotlib.use('TkAgg')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def demo_padding_mask():
"""
演示填充掩码 (Padding Mask)
修正点:
1. 使用 plt.figure() 创建独立窗口
2. 将 bool 转为 float 绘图,以便颜色分明
"""
print("--- 正在生成填充掩码 ---")
torch.manual_seed(20)
batch_size = 16
seq_len = 10
# 初始化全0掩码 (0代表有效,1代表被屏蔽)
padding_mask = torch.zeros(batch_size, seq_len)
# 模拟不同长度的句子
lens = torch.randint(1, seq_len + 1, (batch_size,))
for i in range(batch_size):
# 将超出长度的部分设为1 (被屏蔽)
padding_mask[i, lens[i]:] = 1
# 转为布尔型用于计算
bool_mask = padding_mask.to(dtype=torch.bool)
# --- 绘图修正 ---
plt.figure(figsize=(8, 6)) # 1. 创建新画布
# 2. 使用 float 类型绘图,这样 0 是深色,1 是亮色,对比明显
plt.matshow(bool_mask.float(), cmap='viridis', fignum=1)
plt.title("填充掩码 (黄色区域为被屏蔽的Padding)")
plt.xlabel("序列长度")
plt.ylabel("Batch Size")
plt.colorbar(label="1.0 = 被屏蔽")
plt.show()
def demo_causal_mask():
"""
演示因果掩码/前瞻掩码 (Causal / Look-Ahead Mask)
修正点:
1. 修正了 Softmax 的输入逻辑
2. 分离了各个步骤的图表
"""
print("--- 正在生成因果掩码 ---")
batch_size = 2
seq_len = 10
# 随机生成注意力分数
scores = torch.randn(batch_size, seq_len, seq_len)
# 1. 可视化原始分数
plt.figure(figsize=(6, 5))
plt.matshow(scores[0].numpy(), cmap='coolwarm', fignum=1)
plt.title("1. 原始注意力分数 (无掩码)")
plt.colorbar()
plt.show()
# 2. 生成并应用掩码
# 生成上三角矩阵作为掩码 (True代表未来,需要被屏蔽)
causal_mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).to(dtype=torch.bool)
# 填充负无穷大 (-inf) 而不是 -1e9,这样 Softmax 后严格为 0
scores_masked = scores.masked_fill(causal_mask, float('-inf'))
# 可视化被填充后的分数
# 注意:-inf 在绘图时会显示为底色,我们需要手动处理一下显示效果
display_scores = scores_masked[0].clone()
display_scores[display_scores == float('-inf')] = float('nan') # 将 -inf 设为 NaN 以便绘图留白
plt.figure(figsize=(6, 5))
plt.matshow(display_scores.numpy(), cmap='coolwarm', fignum=1)
plt.title("2. 应用掩码后的分数 (右上空白为被屏蔽的未来)")
plt.colorbar()
plt.show()
# 3. 计算 Softmax (关键修正:必须使用 scores_masked)
attention_weights = torch.softmax(scores_masked, dim=-1)
plt.figure(figsize=(6, 5))
plt.matshow(attention_weights[0].numpy(), cmap='viridis', fignum=1)
plt.title("3. 最终注意力权重 (右上全为0)")
plt.colorbar()
plt.show()
if __name__ == '__main__':
demo_padding_mask()
demo_causal_mask()
LN vs. BN
层归一化(Layer Normalization, LN)和批量归一化(Batch Normalization, BN)都是深度学习中用于稳定训练、加速收敛的关键技术。
最核心的区别在于:它们计算均值和方差的维度不同。
通用归一化公式
x^i=xi−μσ2+ϵ\hat{x}_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}}x^i=σ2+ϵxi−μ
yi=γx^i+βy_i = \gamma \hat{x}_i + \betayi=γx^i+β
xix_ixi:输入值
μ\muμ:均值。
σ2\sigma^2σ2:方差。
ϵ\epsilonϵ:一个极小值,防止分母为零。
γ\gammaγ:缩放参数,用于恢复数据的表达能力。
β\betaβ:表平移参数,用于恢复数据的表达能力。
核心区别
理解这个区别的关键,是看它们沿着哪个方向“取样”来计算统计信息(均值和方差)。
- 批量归一化 (BN) —— “纵向”计算
BN 沿着 批次(Batch) 维度进行。它对一个批次中所有样本的同一个特征进行归一化。- 思想:假设一个批次内的所有样本,它们的同一个特征(例如,图像中的“红色”通道)应该具有相似的分布。
- 计算:收集批次内所有样本在某个特征上的所有值,计算这些值的均值和方差,然后用这个均值和方差来归一化该特征。
- 层归一化 (LN) —— “横向”计算
LN 沿着 特征(Feature) 维度进行。它对单个样本的所有特征进行归一化。- 思想:假设单个样本内部的所有特征(例如,一个句子里的所有词向量)应该具有相似的分布。
- 计算:收集单个样本的所有特征值,计算这些值的均值和方差,然后用这个均值和方差来归一化该样本。
🌰直观例子
假设有一个班级(批次),里面有 N 个学生(样本),每个学生有语文、数学、英语三科成绩(特征)。
- BN 的做法:计算全班 N 个学生的“语文”成绩的平均分和方差,然后用这个统计量来标准化所有学生的语文成绩。接着,再分别对数学和英语成绩重复此操作。
- LN 的做法:计算每个学生自己的“语文、数学、英语”三科成绩的平均分和方差,然后用这个学生自己的统计量来标准化他自己的三科成绩。
对比
| 特性 | 批量归一化 (BN) | 层归一化 (LN) |
|---|---|---|
| 计算维度 | 跨样本,同特征 (N, H, W) | 同一样本,跨特征 (C, H, W) |
| 批次大小依赖 | 强依赖。批次太小时,统计量估计不准,效果差。 | 不依赖。每个样本独立计算,即使批次大小为1也有效。 |
| 训练/推理一致性 | 不一致。训练时用批次统计量,推理时用训练时累积的全局移动平均统计量。 | 完全一致。训练和推理都使用样本自身的统计量,工程实现更简单。 |
| 主要应用场景 | 计算机视觉(CV),如 CNN(ResNet, VGG)。 | 自然语言处理(NLP),如 RNN、Transformer(BERT, GPT)。 |
🤔 为什么 Transformer 使用 LN 而不是 BN?
这主要是由 NLP 任务的数据特性决定的,BN 在处理序列数据时存在两个根本性障碍:
- 变长序列问题
NLP 中的句子长度各不相同。BN 需要对齐批次中所有样本的同一个位置来计算统计量,这对于变长序列来说非常困难且不自然。而 LN 对每个样本独立处理,天然适应变长序列。 - 序列内分布差异
在一个批次中,不同句子的语义和词汇分布可能差异巨大。BN 假设批次内样本的同一特征是可比配的,这个假设在图像任务中(同一通道的像素分布相似)通常成立,但在 NLP 中不成立。相比之下,LN 假设单个句子内部的词向量分布具有可比性,这个假设更合理。
教师强制(Teacher Forcing)
什么是“教师强制”?
“教师强制”是一种在训练阶段使用的策略。其核心思想是:在预测序列的每一个步骤时,模型接收的输入是上一时刻的真实标签(Ground Truth),而不是它自己上一时刻的预测输出。
你可以把它想象成一位老师在手把手地教学生:无论学生上一步回答得对不对,老师都会直接给出正确答案作为下一步的提示,确保学习过程稳定、高效。
举个🌰:机器翻译
假设我们要将中文“我爱机器学习”翻译成英文“I love machine learning”。
- 训练时(使用教师强制):
- 模型输入
<start>,目标是预测I。 - 无论模型预测出什么,下一步的输入都强制使用真实标签
I,目标是预测love。 - 再下一步,输入强制使用
love,目标是预测machine。 - 以此类推,直到序列结束。
- 模型输入
- 推理时(不使用教师强制):
- 模型输入
<start>,预测出I。 - 将模型自己预测的
I作为下一步的输入,来预测下一个词。 - 再将新预测出的词作为输入,继续预测。
- 这个过程是“自回归”的,模型完全依赖自己之前的输出来生成后续内容。
- 模型输入
🤔 为什么需要“教师强制”?
使用“教师强制”主要为了解决两个关键问题:
- 加速收敛,稳定训练
在训练初期,模型的预测能力很差。如果不使用教师强制,模型会用自己的错误预测作为下一步的输入,导致“一步错,步步错”,误差迅速累积,模型很难学到正确的模式。教师强制通过提供正确的上下文,极大地稳定了训练过程,让模型能更快地收敛。 - 避免误差累积
它切断了错误在时间步之间的传播链条,让模型在每个时间步都能基于正确的历史信息进行学习,而不是在错误的道路上越走越远。
“教师强制”的缺点与解决方案
尽管“教师强制”在训练时非常有效,但它也带来了一个问题:
- 暴露偏差
模型在训练时总是看到“完美”的输入(真实标签),但在实际推理时,它必须面对自己可能产生的“不完美”输出。这种训练与推理环境的不一致,就是“暴露偏差”。当模型在推理时犯了一个小错误,这个错误可能会因为模型从未学习过如何纠正它而被放大,导致后续生成完全偏离轨道。
为了缓解这个问题,一个常用的技巧是“计划采样”。它在训练过程中以一定的概率,随机选择使用真实标签还是模型自己的预测作为下一步的输入。这样可以让模型在训练时就逐渐适应推理时可能遇到的情况,从而提高其在实际应用中的鲁棒性。
BLEU(Bilingual Evaluation Understudy,双语评估替补)指标
BLEU(Bilingual Evaluation Understudy,双语评估替补)是一种用于自动评估机器翻译、文本摘要等自然语言生成任务质量的指标。
BLEU 的核心思想是:机器生成的译文与人工参考译文越相似,其质量就越高。
如何理解 BLEU 分数
BLEU 分数是一个介于 0 到 1 之间的数值(有时也乘以 100 表示为 0 到 100)。
- 分数为 0:表示生成的文本与参考文本没有任何相似之处,翻译质量很低。
- 分数为 1 (或 100):表示生成的文本与参考文本完全一致,是完美的翻译。
- 分数在 0.4 到 0.6 之间:通常被认为代表了高质量的翻译。
分数越高,意味着生成文本的质量越好。
BLEU 是如何计算的
BLEU 的计算主要基于 n-gram 共现(overlap) 的统计方法。n-gram 指的是由 n 个连续词组成的词组。
- n-gram 匹配:BLEU 会统计机器译文和参考译文中共同出现的 n-gram 数量。
- 1-gram (Unigram):匹配单个词,主要衡量翻译的忠实度,即原文中有多少词被翻译了出来。
- 2-gram 及以上 (Bigram, Trigram…):匹配连续的词语,主要衡量翻译的流畅度和可理解度。匹配的 n-gram 阶数越高,说明译文在词组搭配和语序上越接近人类语言习惯。常见的 BLEU-4 指标会综合计算 1-gram 到 4-gram 的匹配情况。
- 长度惩罚 (Brevity Penalty, BP):为了避免模型通过生成非常短的句子来获得较高的 n-gram 匹配率,BLEU 引入了长度惩罚因子。如果机器译文的长度远短于参考译文,其最终得分会被大幅降低。
最终,BLEU 分数是不同阶 n-gram 匹配精度的加权几何平均值,再乘以长度惩罚因子。
使用 BLEU 时的注意事项
- 比较的相对性
BLEU 分数本身没有绝对的“好”或“坏”的标准。它的价值主要体现在相对比较上。只有在相同的测试集、相同的语言对、相同的评估设置下,比较不同模型的 BLEU 分数才有意义。 - 不评估语义和语法
BLEU 是一种基于词汇匹配的指标,它不考虑句子的语法正确性或深层的语义相似度。两个意思完全相同但用词不同的句子,BLEU 分数可能很低。 - 依赖数据分布
BLEU 的结果很大程度上取决于训练数据和测试数据的一致性。如果模型在某个特定领域的数据上训练,并在同领域的数据上测试,通常会得到较高的 BLEU 分数。
与其他指标的关系
除了 BLEU,自然语言处理领域还有其他常用的评估指标,它们各有侧重:
| 指标 | 主要特点 |
|---|---|
| BLEU | 侧重于精确率 (Precision),关注生成文本中有多少内容出现在了参考文本中。 |
| ROUGE | 侧重于召回率 (Recall),关注参考文本中有多少内容被生成文本覆盖了,常用于文本摘要。 |
| METEOR | 在匹配时考虑了同义词和词干,能更好地处理词汇变化,弥补了 BLEU 的不足。 |
BLEU(Bilingual Evaluation Understudy,双语评估替补)是一种用于自动评估机器翻译、文本摘要等自然语言生成任务质量的指标。
BLEU 的核心思想是:机器生成的译文与人工参考译文越相似,其质量就越高。
如何理解 BLEU 分数
BLEU 分数是一个介于 0 到 1 之间的数值(有时也乘以 100 表示为 0 到 100)。
- 分数为 0:表示生成的文本与参考文本没有任何相似之处,翻译质量很低。
- 分数为 1 (或 100):表示生成的文本与参考文本完全一致,是完美的翻译。
- 分数在 0.4 到 0.6 之间:通常被认为代表了高质量的翻译。
分数越高,意味着生成文本的质量越好。
BLEU 是如何计算的
BLEU 的计算主要基于 n-gram 共现(overlap) 的统计方法。n-gram 指的是由 n 个连续词组成的词组。
- n-gram 匹配:BLEU 会统计机器译文和参考译文中共同出现的 n-gram 数量。
- 1-gram (Unigram):匹配单个词,主要衡量翻译的忠实度,即原文中有多少词被翻译了出来。
- 2-gram 及以上 (Bigram, Trigram…):匹配连续的词语,主要衡量翻译的流畅度和可理解度。匹配的 n-gram 阶数越高,说明译文在词组搭配和语序上越接近人类语言习惯。常见的 BLEU-4 指标会综合计算 1-gram 到 4-gram 的匹配情况。
- 长度惩罚 (Brevity Penalty, BP):为了避免模型通过生成非常短的句子来获得较高的 n-gram 匹配率,BLEU 引入了长度惩罚因子。如果机器译文的长度远短于参考译文,其最终得分会被大幅降低。
最终,BLEU 分数是不同阶 n-gram 匹配精度的加权几何平均值,再乘以长度惩罚因子。
使用 BLEU 时的注意事项
- 比较的相对性
BLEU 分数本身没有绝对的“好”或“坏”的标准。它的价值主要体现在相对比较上。只有在相同的测试集、相同的语言对、相同的评估设置下,比较不同模型的 BLEU 分数才有意义。 - 不评估语义和语法
BLEU 是一种基于词汇匹配的指标,它不考虑句子的语法正确性或深层的语义相似度。两个意思完全相同但用词不同的句子,BLEU 分数可能很低。 - 依赖数据分布
BLEU 的结果很大程度上取决于训练数据和测试数据的一致性。如果模型在某个特定领域的数据上训练,并在同领域的数据上测试,通常会得到较高的 BLEU 分数。
与其他指标的关系
除了 BLEU,自然语言处理领域还有其他常用的评估指标,它们各有侧重:
| 指标 | 主要特点 |
|---|---|
| BLEU | 侧重于精确率 (Precision),关注生成文本中有多少内容出现在了参考文本中。 |
| ROUGE | 侧重于召回率 (Recall),关注参考文本中有多少内容被生成文本覆盖了,常用于文本摘要。 |
| METEOR | 在匹配时考虑了同义词和词干,能更好地处理词汇变化,弥补了 BLEU 的不足。 |
| F1 Score | 综合了精确率和召回率,衡量两者之间的平衡。 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)