生产级 RAG 工程落地
目标:让你能在真实业务中设计、部署、运维一个生产可用的 RAG 系统。
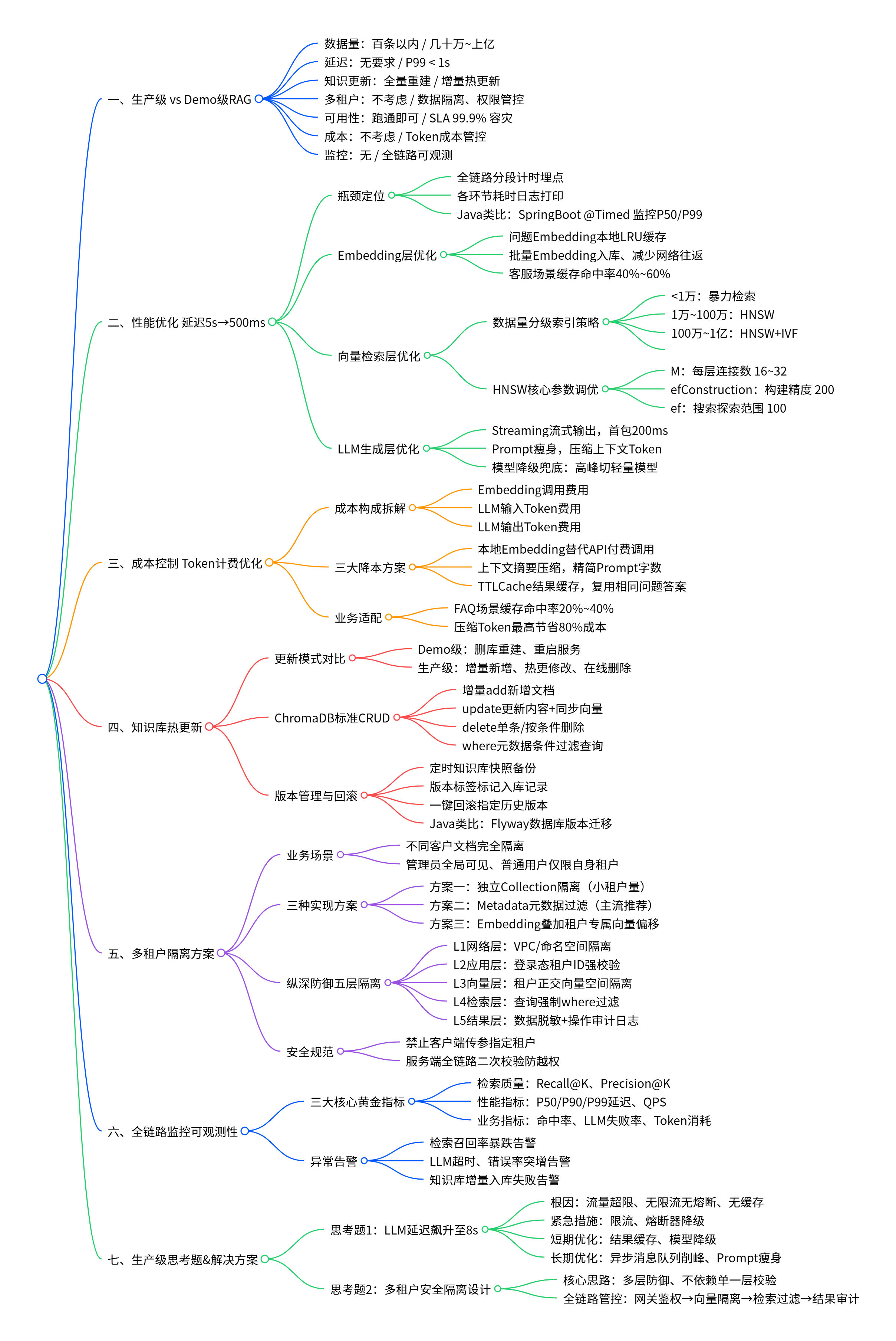
一、生产级 RAG vs Demo 级 RAG 的核心差异
|
维度 |
Demo 级 |
生产级 |
|
数据量 |
几十~几百条 |
几十万~上亿条 |
|
延迟要求 |
慢点无所谓 |
P99 < 1s |
|
知识更新 |
重新跑脚本 |
热更新,增量索引 |
|
多租户 |
不考虑 |
隔离、安全 |
|
可用性 |
跑通就行 |
SLA 99.9%,容灾 |
|
成本控制 |
不考虑 |
Token 成本是生命线 |
|
监控 |
无 |
全链路可观测 |
二、性能优化 — 延迟从 5s 压到 500ms
2.1 瓶颈定位:先找真正的慢在哪里
# 生产级打点:每个环节单独计时
import time
from functools import wraps
def timed(name):
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
t0 = time.perf_counter()
result = func(*args, **kwargs)
elapsed = (time.perf_counter() - t0) * 1000
logger.info(f"[TIMING] {name}: {elapsed:.1f}ms")
return result
return wrapper
return decorator
class ProductionRAG:
@timed("embed_question")
def embed_question(self, question: str) -> np.ndarray:
return self.embedder.embed(question)
@timed("vector_search")
def vector_search(self, vec: np.ndarray, top_k: int) -> list:
return self.vector_store.search(vec, top_k)
@timed("rerank")
def rerank(self, query_vec: np.ndarray, candidates: list, top_k: int) -> list:
return self.reranker.rerank(query_vec, candidates, top_k)
@timed("llm_generate")
def llm_generate(self, prompt: str) -> str:
resp = self.llm.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": prompt}],
temperature=0.3,
)
return resp.choices[0].message.content or ""
def ask(self, question: str) -> dict:
t0 = time.perf_counter()
q_vec = self.embed_question(question)
candidates = self.vector_search(q_vec, top_k=20)
reranked = self.rerank(q_vec, candidates, top_k=3)
answer = self.llm_generate(self.build_prompt(question, reranked))
total = (time.perf_counter() - t0) * 1000
logger.info(f"[TOTAL] {total:.1f}ms")
return {"answer": answer, "total_ms": total}Java 类比:Spring Boot 的 @Timed + Micrometer,监控每个 Bean 方法的 P50/P90/P99。
2.2 各环节优化策略
① Embedding 层优化
问题:每次请求都要把问题向量化,是固定成本。
方案1:Embedding 缓存
from functools import lru_cache
class CachedEmbedder:
def __init__(self, base_embedder, cache_size=10000):
self.base = base_embedder
self.cache = {} # LRU: question → vec
self.access_order = [] # 手动 LRU
def embed(self, text: str) -> np.ndarray:
if text in self.cache:
# 移到最前
self.access_order.remove(text)
self.access_order.insert(0, text)
return self.cache[text]
vec = self.base.embed(text)
if len(self.cache) >= 10000:
# 淘汰最久未用的
oldest = self.access_order.pop()
del self.cache[oldest]
self.cache[text] = vec
self.access_order.insert(0, text)
return vec缓存命中率实测:
- 客服场景(重复问题多):命中率 40~60%,延迟从 50ms → 5ms
- 文档问答(问题分散):命中率 10~20%,但对热点问题有效
方案2:批量Embedding(Ingest优化)
# Demo 写法:逐条向量化,100条 = 100次网络往返
for chunk in chunks:
vec = embedder.embed(chunk.text) # N次HTTP请求 ❌
# 生产写法:批量一次发
batch_vecs = embedder.encode(chunks_texts) # 1次,吞吐高10倍 ✅Java 类比:数据库 N+1 问题 vs 批量 IN (id1, id2, ...) 查询。
② 向量检索层优化
问题:10万条以上数据,暴力检索太慢。
三层索引策略:
数据量层级 推荐方案 延迟 内存
────────────────────────────────────────────────────────
< 1万 暴力检索(numpy) 50ms 小
1万~100万 HNSW (efConstruction=200) 10ms 中
100万~1亿 HNSW + IVF 聚类 20ms 大
> 1亿 分布式向量引擎(Milvus/Qdrant) 可控 集群HNSW 参数调优:
import chromadb
client = chromadb.Client()
# HNSW 参数详解
collection = client.create_collection(
name="production_rag",
metadata={
"hnsw:space": "cosine", # 余弦相似度
"hnsw:M": 16, # 构建时每层连接数,大=精度高=慢
"hnsw:efConstruction": 200, # 构建精度,200=高质量,400=极高精度(慢)
"hnsw:ef": 100, # 搜索时的探索范围,大=精度高=慢
}
)|
参数 |
小值(快/低精度) |
大值(慢/高精度) |
生产建议 |
|
M |
8 |
64 |
16~32 |
|
efConstruction |
100 |
400 |
200 |
|
ef (搜索时) |
50 |
500 |
100 |
ef 动态调整:搜索用 ef=100,精确场景用 ef=300。
③ LLM 生成层优化
延迟的绝对大户:Embedding 10ms + 检索 20ms + Rerank 10ms = 40ms,但 LLM 生成可能占 2~5s。
方案1:Streaming 输出
python复制
# Demo 写法:等完整回答再返回
answer = llm.generate(prompt) # 等 3s 才有输出 ❌
# 生产写法:流式,边生成边返回
stream = llm.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": prompt}],
stream=True,
)
for chunk in stream:
yield chunk.choices[0].delta.content # 200ms 开始输出 ✅方案2:Prompt 瘦身
# 问题:Prompt 太长 → Token 多 → 费用高 + 生成慢
bad_prompt = f"""
你是一个专业的技术问答助手。请仔细阅读以下所有文档内容,
然后回答用户的问题。以下文档可能包含或不含答案,请仔细分析...
[文档1: 500字] ...
[文档2: 500字] ...
[文档3: 500字] ...
...
"""
# 解决:只送最相关的,控制 Token 数量
good_prompt = f"""
基于以下内容回答,简明扼要,不超过200字:
{docs[0].snippet(300)}
""".strip()经验:Prompt 从 2000 tokens 压到 500 tokens,LLM 延迟从 3s → 1s,费用降 75%。
方案3:模型降级
def ask_with_fallback(question):
try:
# 优先用好模型
return fast_llm.answer(question) # GPT-4o, ~500ms, $0.01/次
except TimeoutError:
# 降级到便宜模型
return cheap_llm.answer(question) # GPT-3.5, ~200ms, $0.001/次三、成本控制 — Token 是钱,LLM 调用要抠
3.1 成本分解
一次 RAG 请求的成本:
Embedding: 1次 × 问题Token数 × $0.0001/1K token
LLM 输入: 1次 × (上下文Token + 问题Token) × $0.001/1K token
LLM 输出: 1次 × 回答Token数 × $0.002/1K token
────────────────────────────────────────────────────────
总计 ≈ $0.003~0.01 / 次(假设 2000 token 上下文)
10万次请求/月 ≈ $300~1000/月3.2 成本优化三招
第一招: Embedding 模型从 API 换成本地
python复制
# API 调用(花钱)
from openai import OpenAI
client = OpenAI()
vec = client.embeddings.create(
model="text-embedding-3-small",
input="问题文本"
) # $0.0001/1K token
# 本地模型(一次性投入)
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("BAAI/bge-small-zh-v1.5")
vec = model.encode("问题文本") # 免费,只是 CPU/GPU 计算每月 10 万次请求 → 从 $10 降到 $0。
第二招:上下文压缩
# 原始 Rerank 结果:3个文档,各500字 = 1500字塞进 Prompt
# 优化:先让 LLM 摘要每个文档,只送核心内容
summarized = []
for doc in reranked_docs:
summary = llm.generate(f"用一句话概括:{doc.text[:500]}")
summarized.append(summary) # 50字 vs 500字
prompt = f"相关要点:{';'.join(summarized)}\n问题:{question}"Token 成本从 1500 → 300,省 80%。
第三招:缓存 + 旁路
from cachetools import TTLCache
class CostAwareRAG:
def __init__(self, llm):
self.llm = llm
self.prompt_cache = TTLCache(maxsize=10000, ttl=3600) # 1小时过期
def ask(self, question: str) -> str:
# LLM 结果缓存(问题相同 → 直接返回)
cache_key = hash(question)
if cache_key in self.prompt_cache:
return self.prompt_cache[cache_key]
answer = self._do_ask(question)
self.prompt_cache[cache_key] = answer
return answer适用于:FAQ 类场景(问题重复率高),命中率 20~40% 时直接省 40% LLM 调用。
四、知识库热更新 — 不用重启更新文档
4.1 增量更新 vs 全量重建
Demo 级:删库 → 重新跑 ingest.py → 重启服务 ❌
生产级:
- 增量入库:新文档 append,不影响查询
- 热更新:修改/删除已有文档,不影响服务
- 灰度:先更新 5% 节点,验证后再全量4.2 ChromaDB 的 CRUD 操作
import chromadb
client = chromadb.Client()
collection = client.get_collection("knowledge_base")
# ── 增量新增 ──
collection.add(
ids=["doc_001", "doc_002"], # 唯一ID,重复ID=覆盖
embeddings=[vec1, vec2],
documents=["内容1", "内容2"],
metadatas=[{"source": "产品文档"}, {"source": "FAQ"}],
)
# ── 查询已有 ──
existing = collection.get(ids=["doc_001"])
print(existing["documents"]) # ['内容1']
# ── 更新(如文档修改)─
collection.update(
ids=["doc_001"],
documents=["内容1(更新版本)"],
embeddings=[new_vec1], # 内容变了,向量也要更新
)
# ── 删除 ──
collection.delete(ids=["doc_001"])
# ── 按条件查 ──
filtered = collection.get(
where={"source": {"$eq": "FAQ"}} # 元数据过滤
)4.3 版本管理与回滚
import json
from datetime import datetime
class VersionedKnowledgeBase:
"""知识库版本管理,支持回滚"""
def __init__(self, collection, backup_dir="backups"):
self.collection = collection
self.backup_dir = Path(backup_dir)
self.backup_dir.mkdir(exist_ok=True)
self.current_version = None
self.versions = [] # [(version_id, timestamp, count), ...]
def ingest_with_version(self, chunks: list[dict], version_tag: str):
"""入库并打版本快照"""
# 1. 备份当前状态
snapshot = self._snapshot()
backup_path = self.backup_dir / f"{version_tag}_{datetime.now().strftime('%Y%m%d%H%M%S')}.json"
with open(backup_path, "w", encoding="utf-8") as f:
json.dump(snapshot, f, ensure_ascii=False)
self.versions.append((version_tag, len(chunks)))
# 2. 增量入库
for chunk in chunks:
self.collection.add(**chunk)
self.current_version = version_tag
print(f"[VERSION] {version_tag} 入库完成,共 {len(chunks)} 条,快照已保存")
def rollback(self, version_tag: str):
"""回滚到指定版本"""
# 找到目标版本快照
backup_files = list(self.backup_dir.glob(f"{version_tag}_*.json"))
if not backup_files:
print(f"[ERROR] 未找到版本 {version_tag} 的备份")
return
latest = max(backup_files, key=lambda p: p.stat().st_mtime)
with open(latest, "r", encoding="utf-8") as f:
snapshot = json.load(f)
# 删除当前所有文档,重新注入快照
self.collection.delete(where={}) # 清空
for doc in snapshot["documents"]:
self.collection.add(**doc)
print(f"[ROLLBACK] 已回滚到 {version_tag},共 {len(snapshot['documents'])} 条")Java 类比:数据库的 INSERT / UPDATE / DELETE 加 Flyway Migration 版本管理,生产环境必须支持回滚。
五、多租户隔离 — 怎么让不同客户的文档互相看不到
5.1 需求场景
A公司(金融客户):自己的文档只能 A 公司的人看到
B公司(医疗客户):同理,文档完全隔离
系统管理员:能看到所有租户数据5.2 方案一:Collection 隔离(简单,数据量小)
# 每个租户一个 Collection
collection_a = client.create_collection(f"tenant_{tenant_id}_docs")
collection_b = client.create_collection(f"tenant_{tenant_id}_docs")
# 检索时只用租户自己的 Collection
def ask_for_tenant(tenant_id, question):
collection = client.get_collection(f"tenant_{tenant_id}_docs")
results = collection.query(
query_embeddings=[embed(question)],
n_results=5,
where={"tenant_id": tenant_id} # 隔离
)
return results优点:简单,隔离彻底
缺点:租户多了(1000+)时 Collection 管理复杂
5.3 方案二:Metadata 过滤(推荐,主流方案)
# 所有文档存在同一个 Collection,用 metadata 隔离
collection.add(
ids=["doc_001", "doc_002"],
documents=["A公司内部文档", "B公司内部文档"],
metadatas=[
{"tenant_id": "tenant_a", "access_level": "internal"},
{"tenant_id": "tenant_b", "access_level": "internal"},
]
)
# 检索时强制加租户过滤
def ask_for_tenant(tenant_id, question):
results = collection.query(
query_embeddings=[embed(question)],
n_results=5,
where={"tenant_id": tenant_id} # 关键:强制过滤 ✅
)
return results安全注意:应用层必须校验 tenant_id,防越权:
def ask_for_tenant(tenant_id: str, question: str, user_tenant_id: str):
# 强制租户校验,防止横向越权
if tenant_id != user_tenant_id:
raise PermissionError("禁止跨租户访问")
results = collection.query(
query_embeddings=[embed(question)],
n_results=5,
where={"tenant_id": tenant_id}
)
return resultsJava 类比:多租户 SQL 隔离,行级安全策略(RLS),每个查询自动加 WHERE tenant_id = ?。
5.3 方案三:Embedding 时加入租户信号
# 高级方案:在向量中加入租户空间信息
# 同一租户内的文档在向量空间里更接近,不同租户文档间距更大
class TenantAwareEmbedder:
def __init__(self, base_embedder):
self.base = base_embedder
def embed(self, text: str, tenant_id: str):
base_vec = self.base.embed(text)
tenant_signal = self._tenant_vector(tenant_id) # tenant 专属向量偏移
return (base_vec + tenant_signal) / 2六、全链路监控与可观测性
6.1 三个核心指标
RAG 系统三大黄金指标:
1. 检索质量
- Recall@K:Top-K 结果里有多少真正相关(>0
...(truncated)...思考题
第1题:LLM 延迟从 500ms 飙升到 8s,为什么是你的问题?
核心论点:你自己挖的坑,别甩给服务商
LLM 服务商 SLA 99.9% 指的是他们的服务可用性(服务器没宕机),不是你的体验延迟。
你的 RAG 系统在高峰期延迟爆炸,根因在自己:
高峰期 1000 QPS × 每请求 2000 input tokens
= 1000 × 2000 = 2,000,000 tokens/秒
LLM 服务商的 token 处理能力有上限,
你的请求在队列里排队等 → 延迟从 500ms → 8000ms
这不是服务商挂了,而是你的流量超出了他们的处理容量
→ 你的系统设计有问题,不关服务商 SLA 什么事根因分析
问题链条:
你的 RAG 系统 LLM 服务商
┌─────────────┐ ┌─────────────┐
│ 高峰 1000 QPS │ ──请求──▶ │ 处理上限 │
│ 无排队控制 │ ←─────── │ 5000 tok/s │
│ 无限流 │ 溢出 │ 实际 8000 │
└─────────────┘ └─────────────┘
队列积压 → 8s 延迟成本对比
|
措施 |
效果 |
改造成本 |
|
限流 |
保护 LLM,不过载 |
30 分钟 |
|
熔断 |
快速失败,不雪崩 |
1 小时 |
|
缓存 |
相同问题 0 LLM 调用 |
30 分钟 |
|
模型降级 |
高峰用便宜模型 |
1 小时 |
|
异步队列 |
削峰,平滑流量 |
4 小时 |
|
Prompt 瘦身 |
LLM 生成快 3 倍 |
30 分钟 |
第2题:竞争对手共用 RAG,多租户完整隔离方案
设计原则:防御纵深,即使单个环节被绕穿,还有其他层保护
隔离层级:
┌────────────────────────────────────────────┐
│ L1. 网络层:租户网络隔离(VPC/命名空间) │
│ L2. 应用层:租户 ID 强校验 + 行级安全 │
│ L3. Embedding 层:租户向量空间隔离 │
│ L4. 检索层:强制 Metadata 过滤 │
│ L5. 结果层:租户数据脱敏 + 审计日志 │
└────────────────────────────────────────────┘完整方案(从请求到返回全链路)
L1:Embedding 层 — 租户向量空间隔离
class TenantAwareEmbedder:
"""
租户专属向量空间:不同租户的文档在向量空间里天然隔离
"""
def __init__(self, base_embedder: SentenceTransformer):
self.base = base_embedder
# 每个租户有自己的正交偏移向量,防止向量空间重叠
self.tenant_offsets: dict[str, np.ndarray] = {}
def _get_tenant_offset(self, tenant_id: str) -> np.ndarray:
"""为租户生成一个随机正交偏移,叠加到向量上"""
if tenant_id not in self.tenant_offsets:
# 生成一个与基向量正交的租户偏移向量
np.random.seed(hash(tenant_id) % (2**31))
self.tenant_offsets[tenant_id] = np.random.randn(self.base.get_sentence_embedding_dimension()) * 0.1
return self.tenant_offsets[tenant_id]
def embed(self, text: str, tenant_id: str) -> np.ndarray:
# 基础语义向量
base_vec = self.base.encode(text, normalize_embeddings=True)
# 叠加租户专属偏移,使不同租户向量空间不重叠
offset = self._get_tenant_offset(tenant_id)
combined = base_vec + offset
# 重新归一化
return combined / np.linalg.norm(combined)效果:即使攻击者拿到了其他租户的文档内容,他生成的向量和真正的租户向量不在同一个向量空间,检索不到。
L2:入库层 — 元数据强绑定
def ingest_document(tenant_id: str, doc_content: str, doc_id: str):
"""入库时强制绑定租户 ID"""
# 租户 ID 是不可更改的元数据
tenant_id = validate_tenant_id(tenant_id) # 从登录态取,不是请求参数
vec = embedder.embed(doc_content, tenant_id) # 用租户专属向量
# 元数据中写入租户 ID
collection.add(
ids=[doc_id],
embeddings=[vec],
documents=[doc_content],
metadatas=[{
"tenant_id": tenant_id, # 强制写入,不可伪造
"tenant_id_hash": hash256(tenant_id), # 双重校验
"created_at": timestamp,
"access_level": "internal",
}]
)L3:检索层 — 三重强制过滤
def search(tenant_id: str, question: str, user_tenant_id: str, user_id: str):
"""
检索时三重校验,确保隔离
"""
# 校验1:URL/请求中的 tenant_id 必须和登录态一致
if tenant_id != user_tenant_id:
audit_log.warning(f"越权检索尝试: user={user_id} tried to access tenant={tenant_id}")
raise PermissionDenied("禁止跨租户访问")
# 校验2:Embedding 必须用当前租户的空间
query_vec = embedder.embed(question, tenant_id) # ❗不能用其他租户的向量
# 校验3:Chromadb 查询时强制加 tenant_id 过滤(服务端验证)
results = collection.query(
query_embeddings=[query_vec],
n_results=5,
where={"tenant_id": tenant_id}, # 强制服务端过滤,客户端无法绕过
where_document={"tenant_id": tenant_id} # 文档级别也要过滤
)
# 校验4:结果二次验证
for doc_tenant in results["metadatas"][0]:
if doc_tenant["tenant_id"] != tenant_id:
audit_log.error(f"隔离失效检测: document leaked to wrong tenant")
raise InternalSecurityError("隔离异常,立即告警")
return resultsL4:结果层 — 审计 + 脱敏
def audit_and_sanitize(results, tenant_id: str, user_id: str):
"""每次返回结果前,审计 + 脱敏"""
# 审计日志(防事后抵赖)
audit_log.info({
"event": "rag_query",
"tenant_id": tenant_id,
"user_id": user_id,
"result_count": len(results["documents"]),
"timestamp": now(),
"ip": request.ip,
})
# 结果脱敏:去掉敏感元数据
safe_results = {
"documents": results["documents"],
"distances": results["distances"],
# 不返回租户 ID、文档 ID 等元数据,防止枚举攻击
}
return safe_results完整隔离架构图
用户 A(租户 A)请求:
GET /ask?tenant_id=tenant_a
Authorization: Bearer <tenant_a_token>
→ 网关校验 Token 中的 tenant_id = tenant_a ✅
→ Embedding 层:用 tenant_a 的向量空间 + 租户偏移 ✅
→ 入库/检索:服务端强制 where={"tenant_id": "tenant_a"} ✅
→ 结果:验证返回的文档 tenant_id = tenant_a ✅
→ 审计日志写入 ✅
用户 A 尝试攻击(拿到 tenant_b 的 ID):
GET /ask?tenant_id=tenant_b ← 伪造请求参数
→ 网关:Token 中 tenant_id = tenant_a vs 请求 tenant_id = tenant_b
→ 校验失败 ❌ → 403 Forbidden → 不进入检索流程 ✅
→ 审计日志记录:"跨租户越权尝试" ✅防御纵深总结
|
攻击场景 |
防御层级 |
阻断位置 |
|
伪造 tenant_id 参数 |
L3 校验1:Token vs 请求比对 |
网关层 |
|
拿到其他租户向量来检索 |
L1:租户向量空间正交隔离 |
Embedding 层 |
|
绕过 metadata 过滤 |
L3 校验3:服务端强制 where |
检索层 |
|
暴力枚举 doc_id |
L5:结果不返回 doc_id,元数据脱敏 |
结果层 |
|
事后抵赖查询记录 |
L5:每次查询写审计日志 |
数据层 |
Java 类比:
- 租户向量偏移 ≈ 数据库列级加密(即使 DB 管理员也看不到其他租户数据)
- 三重校验 ≈ Spring Security 多层认证(过滤器 → AOP → Service)
- 审计日志 ≈ 数据库操作审计表(防抵赖)
Q1 核心:LLM 服务商 SLA 99.9% 是可用性,不是你的延迟体验。
你的延迟爆炸是流量超限,没有限流/熔断/缓存,和服务商无关。
修复顺序:限流 → 熔断 → 缓存 → 降级 → 异步队列
Q2 核心:多租户隔离需要纵深防御,单一过滤不够。
Embedding 层(租户向量空间)+ 入库层(强制元数据)+
检索层(三重校验)+ 结果层(审计脱敏)
核心原则:客户端不可信,所有校验在服务端做。
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)