为什么 Agent 不只是大模型:从 chunk、metadata 到上下文召回设计
为什么 Agent 不只是大模型:从 chunk、metadata 到上下文召回设计
最近在学习 RAG 和 Agent Runtime 时,我越来越明显地感觉到一件事:
一个 Agent 好不好用,不只取决于 Base Model 有多强,还取决于它外面那层上下文工程、工具系统和产品工作流设计。
同样一份 skill 文档,在不同 AI IDE 或 Agent 产品里,表现可能完全不同。不是因为文档本身突然变强或变弱,而是因为不同系统对上下文的召回、筛选、组织和执行能力不一样。
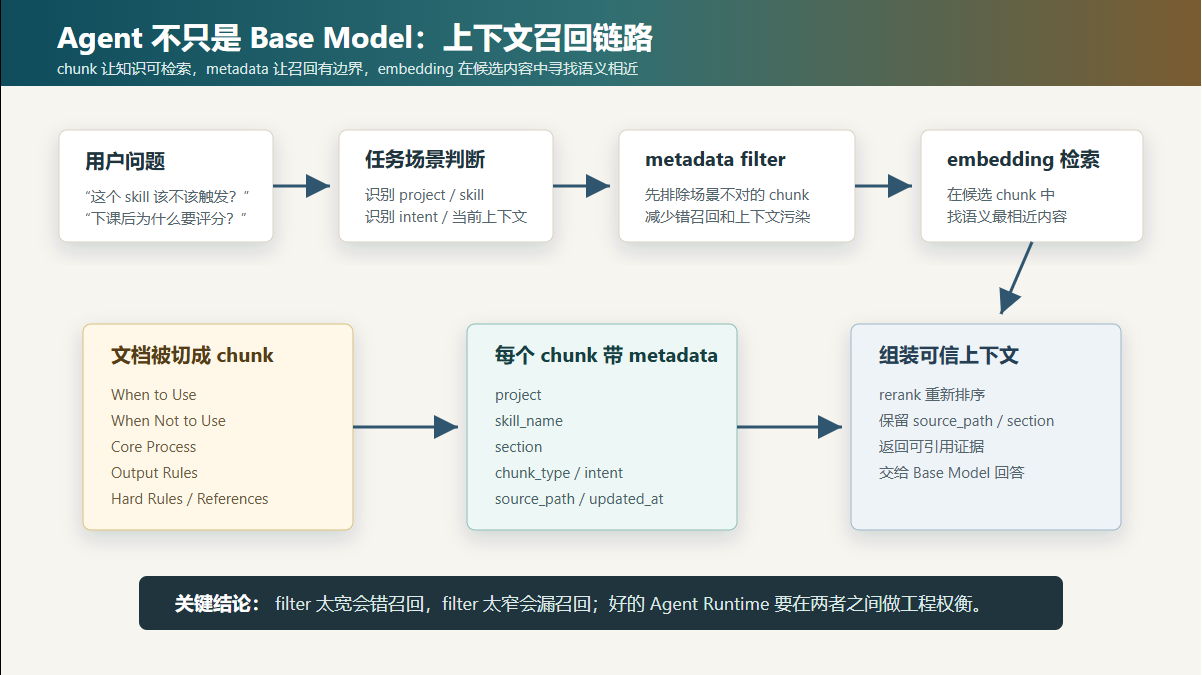
这篇文章整理一下我今天学到的几个核心概念:chunk、metadata、metadata filter 和 embedding。
1. Agent 不只是 Base Model
很多人讨论 Agent 时,容易只看模型能力:
- 模型会不会写代码
- 推理强不强
- 能不能理解复杂需求
- 工具调用是否稳定
这些当然重要,但它们只是第一层。
真正让 Agent 好用的,通常是一个完整系统:
| 层次 | 作用 |
|---|---|
| Base Model | 负责理解、推理、生成 |
| Context / Retrieval | 负责找到正确资料 |
| Tool System | 负责读文件、改代码、跑测试、查日志 |
| Workflow | 负责什么时候确认、什么时候继续、什么时候停止 |
| Eval / Trace | 负责判断结果是否可靠、失败在哪里 |
所以,Agent 的竞争不是单纯的“模型竞争”,而是:
模型 + 上下文工程 + 工具系统 + 工作流设计 + 验证机制 的整体竞争。
2. chunk:把文档切成可用的知识单元
chunk 可以理解为:把一个文件切成可以被检索、可以被模型理解的小块知识单元。
比如一个 SKILL.md 文档里可能有这些部分:
When to UseWhen Not to UseCore ProcessOutput RulesHard RulesReferences
如果把整个文件都作为一个 chunk,用户只问“这个 skill 该不该触发?”,系统却把流程、输出规则、参考文件都一起塞给模型,噪音就会很大。
如果切得太碎,比如只切一句话,模型又可能不知道这句话属于哪个 skill、哪个场景、哪个流程阶段。
所以好的 chunk 不是简单按字数切,而是要按语义边界切。
一个好的 chunk 应该满足三个条件:
- 可独立理解
- 边界清楚
- 能回答一种具体问题
比如用户问“用了这个 skill 后第一步做什么?”,最应该召回的是 Core Process 或 Workflow 相关 chunk,而不是整个 skill 文档。
3. metadata:给 chunk 加上工程边界
如果说 chunk 是知识单元,那么 metadata 就是这个知识单元的标签。
它可以描述:
- 这个 chunk 来自哪个项目
- 属于哪个 skill
- 来自哪个 section
- 是规则、流程、例子还是参考资料
- 适合回答什么意图的问题
- 更新时间是什么
- 原始文件路径在哪里
比如一个 skill 文档 chunk 可以有这样的 metadata:
{
"project": "learning-companion-skills",
"skill_name": "learning-companion",
"section": "Daily Protocol",
"chunk_type": "workflow_step",
"intent": "close_out_review",
"source_path": "learning-companion/SKILL.md",
"updated_at": "2026-05-16"
}
这些字段不是装饰,而是召回质量的关键。
4. metadata filter:减少错召回
embedding 负责语义相似,metadata filter 负责场景边界。
这是我今天最重要的理解之一。
比如用户问:
这个 skill 该不该触发?
系统不应该召回 Output Rules,因为输出规则回答的是“触发后怎么写答案”,不是“该不该触发”。
更合适的 filter 是:
{
"chunk_type": ["trigger_rule", "boundary_rule"],
"section": ["When to Use", "When Not to Use"]
}
再比如用户问:
用了这个 skill 之后,第一步应该做什么?
这时最应该召回的是:
{
"chunk_type": ["workflow_step", "process"],
"section": ["Core Process", "Workflow"]
}
这就是 metadata filter 的价值:它让系统先排除场景不对的内容,再去做语义检索。
5. embedding:在候选内容里找语义相近
embedding 的作用不是判断所有事情,而是在候选 chunk 里找语义最接近的内容。
一个比较合理的检索流程大概是:
- 用户提出问题
- 系统判断当前任务场景
- 生成 metadata filter
- 先过滤掉明显不相关的 chunk
- 再用 embedding similarity 找语义相近内容
- rerank
- 返回带引用的上下文
- 模型基于这些上下文回答
也就是说:
metadata filter 决定“哪些内容有资格参与检索”,embedding 决定“这些候选里哪个最像”。
6. filter 太宽和太窄都会出问题
metadata filter 不是越多越好,也不是越少越好。
如果 filter 太少,容易错召回。
比如用户问 coding skill 的触发规则,但系统把 learning companion 的学习提醒规则也召回了,这就是错召回。
如果 filter 太窄,容易漏召回。
比如用户问“为什么下课后要评分,而不是直接进入下一天?”,答案可能同时需要:
learning-companion/SKILL.md里的Daily Protocolscoring-and-review.md里的Mastery Scale/Progress Strategy
如果只过滤 section = Daily Protocol,就可能漏掉评分标准。
所以好的 filter 应该是:
够窄,能减少错召回;但不能窄到挡住必要证据。
7. 为什么这件事影响 Agent 产品体验
这也解释了为什么同一份 skill,在不同 AI IDE 或 Agent 产品里效果可能不同。
skill 文档只是知识,真正让它发挥作用的是:
- 能不能在正确时机触发
- 能不能读到正确 section
- 能不能区分规则、流程、例子和边界
- 能不能避免召回不相关上下文
- 能不能在执行后验证结果
Coding Agent 在这方面有天然优势,因为代码世界有很多结构化信号:
- 文件路径
- 类名 / 函数名
- git diff
- 测试失败日志
- 编译错误
- README
- package/module 结构
- 调用关系
这些都可以变成 metadata 或检索信号。
所以一个强 coding agent,不只是“模型会写代码”,而是它能利用代码仓库本身的结构,把上下文找准、用准、验证准。
8. 今天的总结
今天我对 chunk、metadata、embedding 的理解可以压缩成三句话:
chunk负责把文档切成可检索、可独立理解的知识单元。metadata filter负责先排除场景不对的 chunk,减少错召回。embedding负责在候选 chunk 中找到语义最相近的内容。
更大的启发是:
Agent 好不好用,不只是 Base Model 能力问题,而是 Agent Runtime 的整体设计问题。
Base Model 再强,如果外层没有把正确上下文送进去,它也只能聪明地读错材料。
这也是我继续学习 Agent Knowledge Runtime 的原因:不是只学怎么调用 LLM,而是学习怎么把 LLM 变成一个可靠、可追溯、可验证的工程系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)