【深度解析】腾讯开源 【TencentDB Agent Memory】:Mermaid 任务画布 + 上下文卸载,长任务 Token 直降 61%,复杂 Agent 可以直接抄作业
【深度解析】腾讯开源 【TencentDB Agent Memory】:Mermaid 任务画布 + 上下文卸载,长任务 Token 直降 61%,复杂 Agent 可以直接抄作业
作者:技术博主 | 更新时间:2026-05-14 | 阅读时长:约 18 分钟
来源:腾讯云数据库团队,2026-05-14 正式开源
仓库:https://github.com/Tencent/TencentDB-Agent-Memory
标签:Agent Memory上下文卸载MermaidToken压缩长任务开源OpenClawSQLite

🔥 一句话定位:Agent 做长任务,最头疼的是上下文窗口被工具日志塞满,Token 成本爆表、任务状态丢失。腾讯这套方案的核心思路是:把"要记住的东西"分成两类——当前需要 Agent 感知的结构化状态(用 Mermaid 画布表示,极省 Token)和可能需要追溯的原始证据(卸载到外部存储,按需调取)。实测 Token 消耗最高降 61%,任务成功率相对提升 51%,全程可追溯。
目录
- 一、问题:长任务 Agent 为什么会"满"?
- 二、整体架构:短期压缩 + 长期个性化
- 三、短期记忆压缩:三层架构 + Mermaid 任务画布
- 四、上下文卸载:把大的扔出去,留小的在身边
- 五、长期记忆:L0-L3 四层语义金字塔
- 六、核心实验数据
- 七、快速集成:五分钟接入现有 Agent
- 八、与同类方案的对比
- 九、值得关注的设计细节
一、问题:长任务 Agent 为什么会"满"?
在简单问答场景里,Agent 几乎不需要记忆系统——几轮对话,上下文窗口绰绰有余。
但一旦 Agent 进入代码开发、网页研究、持续分析这类长任务,一个 50 步的任务可能是这样的:
Step 1: 调用搜索工具,返回 8K tokens 的搜索结果
Step 2: 调用搜索工具(补充),再来 6K tokens
Step 3: 读取代码文件,5K tokens
Step 4: 执行代码,报错日志 3K tokens
Step 5: 再次搜索解决方案,7K tokens
...
Step 30: 上下文窗口已用 95%,LLM 开始"失忆"
问题有三个:
① Token 成本线性增长。每步工具返回的内容都塞进上下文,50 步任务可能消耗几十万 Token,成本在快速放大。
② 任务状态丢失。当上下文装不下时,早期的任务背景、已完成的步骤被截断。Agent 不知道自己走到了哪里,开始重复劳动或走错方向。
③ 推理稳定性下降。超长上下文中的噪声信息(已过期的搜索结果、中间错误日志)会干扰 LLM 对当前任务的判断。
随着 Agent 在代码开发、网页搜索、研究分析等场景中的任务链路持续变长,大量工具调用、网页内容和中间结果会快速占满上下文窗口,导致 Token 成本上升、任务状态丢失以及推理稳定性下降。
二、整体架构:短期压缩 + 长期个性化
TencentDB Agent Memory 的完整公式:
Agent Memory = 短期记忆压缩 ⏟ 解决"当前任务窗口满了" + 长期个性化记忆 ⏟ 解决"跨会话失忆" \text{Agent Memory} = \underbrace{\text{短期记忆压缩}}_{\text{解决"当前任务窗口满了"}} + \underbrace{\text{长期个性化记忆}}_{\text{解决"跨会话失忆"}} Agent Memory=解决"当前任务窗口满了" 短期记忆压缩+解决"跨会话失忆" 长期个性化记忆
TencentDB Agent Memory = 符号化短期记忆 + 分层长期记忆。符号化短期记忆将繁重的工具日志卸载并压缩为紧凑的 Mermaid 符号,降低 Token 消耗并提升任务成功率。分层长期记忆将碎片化的对话蒸馏为结构化的用户画像和场景块,而非扁平的向量堆。
两者解决的是不同时间维度的问题:
短期记忆压缩:
问题范围:同一次长任务执行期间(一个 Session 内的 50 步)
核心目标:让 Agent 在更少 Token 里知道"当前任务走到哪了"
长期个性化记忆:
问题范围:跨会话、跨天(用户重新开 session)
核心目标:让 Agent 记住用户的习惯、偏好、历史背景
不需要用户重复自我介绍
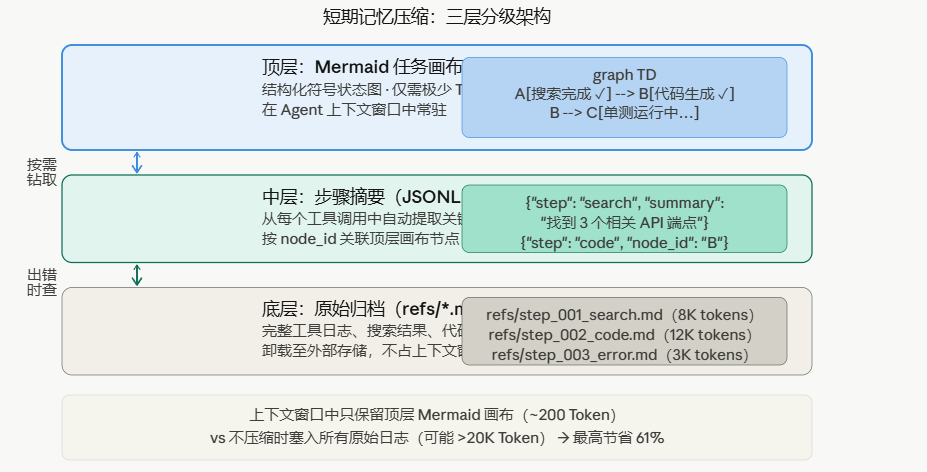
三、短期记忆压缩:三层架构 + Mermaid 任务画布
如上图一所示。
这是本次开源的核心能力。腾讯把短期记忆设计成三层:
3.1 底层:原始归档(refs/*.md)
工具返回的所有原始内容——搜索结果、代码输出、错误日志——都被完整存入外部文件(本地 SQLite 或文件系统)。
关键设计:不做有损压缩。这些内容从不被丢弃或摘要覆盖,永远保留原始形态,通过 node_id 与中层和顶层关联。
3.2 中层:步骤摘要(JSONL)
每次工具调用完成后,系统自动提取"这一步的关键结论",存成一条 JSONL 记录:
{"step": 1, "node_id": "A", "action": "web_search", "summary": "找到 3 个相关 API 端点,其中 /v2/users 最相关", "status": "done"}
{"step": 2, "node_id": "B", "action": "code_gen", "summary": "生成了调用 /v2/users 的 Python 代码,使用 requests 库", "status": "done"}
{"step": 3, "node_id": "C", "action": "test_run", "summary": "单测失败,原因:缺少 auth header", "status": "error", "ref": "refs/step_003_error.md"}
中层内容仍然不进入 Agent 的上下文窗口,只在需要"某步的详细信息"时按 node_id 调取。
3.3 顶层:Mermaid 任务画布
顶层将状态压缩为轻量的 Mermaid 画布。Agent 只需在上下文中关注顶层结构,在发生错误时通过 node_id 向下钻取到更低层。
Mermaid 是一种用文本表达结构图的语言,极度精简——同样的任务状态,Mermaid 表示只需约 200 Token,而完整的工具日志可能需要 20K Token。
一个实际的任务画布示例:
Agent 在执行时,上下文里持有的就是这张画布:
- 已完成的步骤(✓):不需要重新思考,只需知道结果
- 当前出错的步骤(✗):需要关注,可按 node_id 调取底层原始错误日志
- 待执行的步骤:清晰的执行路径
Mermaid 符号图:我们用高密度的 Mermaid 语法编码任务状态转换,而不是冗长的散文或扁平 JSON——对 LLM 解析足够精确,对人类阅读足够简洁。
四、上下文卸载:把大的扔出去,留小的在身边
上下文卸载(Context Offloading)是短期记忆压缩的执行机制,分三个触发级别:
L1 轻量压缩(上下文占比 < 60%):
→ 工具输出自动摘要化,原始内容移出上下文
→ Agent 读到的是摘要,完整内容存底层
L2 中度压缩(上下文占比 60%-80%):
→ 清理已完成步骤的中间内容
→ 保留 Mermaid 画布 + 未完成步骤的摘要
L3 深度压缩(上下文占比 > 80%):
→ 触发"激进压缩":清理所有已完成旧任务的消息
→ 仅保留当前任务的关键状态
紧急压缩(上下文占比 > 95%):
→ 一次性将上下文降至 60% 以下
→ 防止 OOM 或 API 报错中断任务
全程可追溯是这套设计的重要承诺。
压缩的最大风险是为了节省 Token 而丢失证据。TencentDB Agent Memory 因此不把历史折叠为不可逆的摘要——它保留从高层抽象回溯到原始证据的清晰路径。
无论压缩了多少,任意一步的原始输出都可以通过 node_id 链路完整还原:
顶层 Mermaid 节点 → node_id → 中层 JSONL 摘要 → ref 路径 → 底层 refs/*.md 原文
五、长期记忆:L0-L3 四层语义金字塔
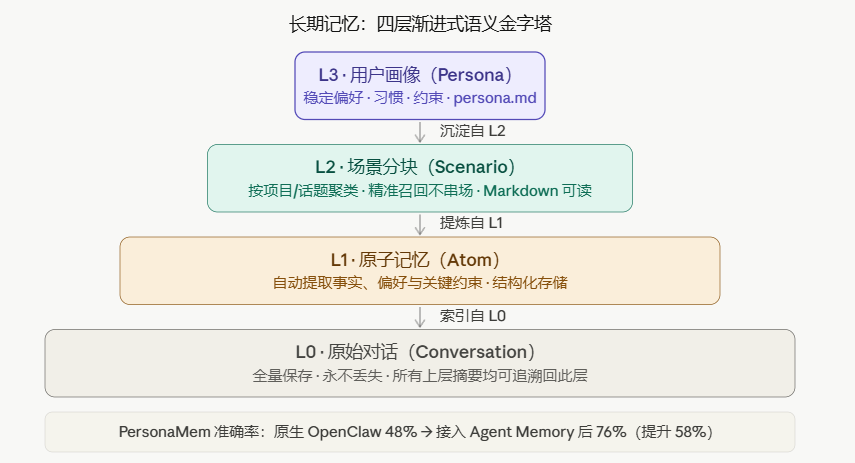
如上图二所示。
长期记忆在上月已上线免费使用,解决的是"跨 Session 失忆"问题。
腾讯云引入独创的四层渐进式记忆架构:L0 原始对话——全量保存,确保原始对话信息不丢失;L1 原子记忆——自动提取事实、偏好与关键约束;L2 场景分块——按项目聚类,记忆带着上下文精准召回,不串场;L3 用户画像——形成稳定的用户画像,让 AI 适应你的习惯。
为什么要四层,而不是一个向量数据库?
向量数据库方案的问题是"召回错了没有解释"——只能看到相似度分数,无法知道结果为什么不对。四层架构的每一层都是可读的文件:
L3 Persona(persona.md):人类可读的用户偏好文档
↑ 沉淀自 L2
L2 Scenario(scenario_*.md):按项目分块的 Markdown 文档
↑ 提炼自 L1
L1 Atom(atoms.jsonl):结构化的原子事实
↑ 索引指向 L0
L0 Conversation:全量原始对话记录
L2 场景块是纯 Markdown——打开即可检查。L3 用户画像存于 persona.md,并追溯至生成它的场景块。这让召回错误时可以完整排查,而不是只看到一堆向量分数。
六、核心实验数据
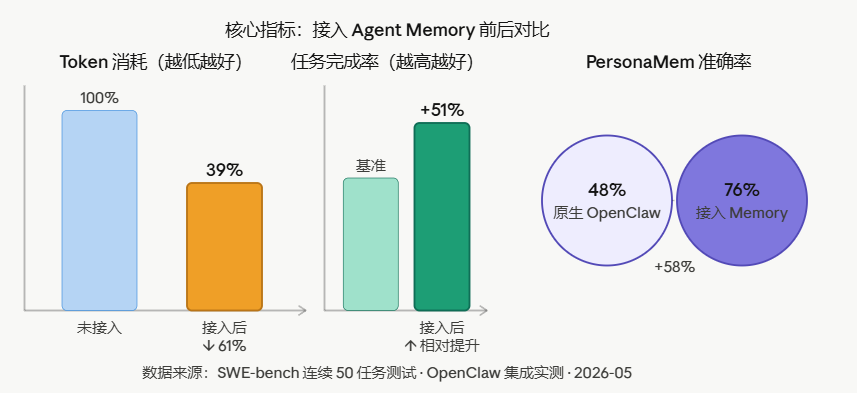
如上图三所示。
测试条件:SWE-bench 连续 50 任务 / Session(模拟真实长任务的上下文积累压力),覆盖代码生成、长难任务、网页搜索、文章分析四大场景,共 1540 道测试题。
在覆盖代码生成、长难任务、网页搜索、文章分析四大场景的 1540 道测试题中,这套机制将任务完成率提升 12%-35%,同时 Token 消耗降低 33%-64%——效果更好的同时,成本更低。
与 OpenClaw 集成后,Token 消耗最高降低 61.38%,通过率相对提升 51.52%,PersonaMem 准确率从 48% 提升至 76%。这些结果在连续长周期 Session 中测量,而非孤立的单轮对话。
关键数据汇总:
| 指标 | 未接入 | 接入后 | 变化 |
|---|---|---|---|
| Token 消耗(连续长任务) | 基准 100% | 最低 39% | ↓ 61% |
| 任务完成率(pass rate) | 基准 | +51.52%(相对) | 显著提升 |
| PersonaMem 准确率 | 48% | 76% | +58% |
| 任务成功率(四场景均值) | 基准 | +12%–35% | 全面提升 |
七、快速集成:五分钟接入现有 Agent
7.1 OpenClaw 一键集成
# 安装插件
openclaw plugins install @tencentdb-agent-memory/memory-tencentdb
# 或通过"虾马"控制台一键开启
# 路径:ClawPro 管控端 → 左侧"记忆管理" → 开启
7.2 Python SDK 接入
from tencent_agent_memory import AgentMemory
# 初始化(本地 SQLite,零依赖)
memory = AgentMemory(
storage="sqlite",
db_path="./agent_memory.db",
user_id="user_001",
)
# 在 Agent 循环中使用短期记忆压缩
async def agent_step(task_id: str, step: int, tool_result: str):
# 1. 卸载工具输出到底层存储
node_id = await memory.offload(
task_id=task_id,
step=step,
content=tool_result, # 可能是 8K tokens 的搜索结果
action="web_search",
summary="自动摘要:找到 3 个相关 API",
)
# 2. 更新 Mermaid 任务画布
canvas = await memory.update_canvas(
task_id=task_id,
node_id=node_id,
status="done",
next_nodes=["code_gen"],
)
# 3. 返回给 Agent 的上下文只包含轻量画布(~200 tokens)
return canvas.to_mermaid()
# 跨会话:读取长期记忆
async def get_user_context(user_id: str, current_query: str) -> str:
# 按当前任务主题召回相关场景记忆
memory_context = await memory.recall(
user_id=user_id,
query=current_query,
layers=["L3", "L2"], # 先拿 Persona,再按需拿 Scenario
)
return memory_context
# 会话结束后,沉淀长期记忆
async def consolidate(session_id: str):
await memory.consolidate(
session_id=session_id,
# L0 → L1 → L2 → L3 自动逐层蒸馏
)
7.3 MCP 工具接入
如果你的 Agent 通过 MCP 调用工具,可以把 Agent Memory 包装成一个 MCP Server:
# 创建 MCP Server
from mcp.server.fastmcp import FastMCP
from tencent_agent_memory import AgentMemory
mcp = FastMCP("agent-memory")
mem = AgentMemory(storage="sqlite")
@mcp.tool()
async def memory_offload(task_id: str, step: int, content: str, summary: str) -> str:
"""将工具输出卸载到外部存储,返回更新后的 Mermaid 画布"""
canvas = await mem.offload(task_id, step, content, summary=summary)
return canvas.to_mermaid()
@mcp.tool()
async def memory_recall(query: str, user_id: str) -> str:
"""按语义召回相关历史记忆"""
return await mem.recall(user_id, query)
if __name__ == "__main__":
mcp.run()
八、与同类方案的对比
目前主流的 Agent 记忆方案有几种路线:
方案1:向量数据库(Mem0、Zep 等)
原理:把历史对话向量化,按相似度召回
优势:实现简单,适合短对话记忆
劣势:
- 召回错了没有解释(只有相似度分数)
- 不解决当前任务的 Token 爆炸问题
- 长任务任务状态依然丢失
方案2:传统摘要压缩
原理:用 LLM 对历史上下文做摘要,替换原文
优势:减少 Token
劣势:
- 有损!摘要丢失细节,出错后无法追溯
- 摘要本身需要 LLM 调用,增加成本和延迟
方案3:TencentDB Agent Memory
原理:三层分级 + Mermaid 符号化 + 上下文卸载
优势:
- 无损:所有原始信息保留于底层,可完整回溯
- Token 降低幅度大(最高 61%)
- 任务状态结构化(Mermaid),Agent 不迷失
- 人类可读(所有文件都是 Markdown/Mermaid)
劣势:
- 集成相对复杂(需要嵌入工具调用循环)
- 对任务结构有要求(无结构化步骤的任务画布意义有限)
九、值得关注的设计细节
9.1 Mermaid 是个精妙的选择
很多 Agent 框架用 JSON 存储任务状态,但 JSON 有一个问题:冗余字段多,人类读起来费劲,LLM 也需要更多 Token 来"理解"结构。
Mermaid 的优势在于:
- 极度紧凑:一个 10 节点的任务图,Mermaid 表示约 150-300 Token,等价 JSON 可能需要 600+ Token
- LLM 原生理解:主流 LLM 都在训练数据中见过大量 Mermaid,无需额外解释语法
- 人类可读:开发者打开文件就能看懂任务走到了哪里,不需要额外工具
- 条件关系支持:
A --> B/A -.-> B(虚线=等待)/A --条件--> B(带标签边),足够表达复杂任务依赖
9.2 “记忆不是把所有东西装进 AI”
记忆不是把所有东西装进 AI 里——而是让人类不需要反复重复自己。在实践中,用户常常要向 Agent 反复重新解释相同的 SOP、项目背景、工具约定和输出格式。
这句话道出了 Agent Memory 的真正价值所在:不是给 LLM 更大的上下文窗口,而是让必要的信息在正确的时间出现。
9.3 完全本地化,零外部 API 依赖
TencentDB Agent Memory 通过四层渐进式管道提供完全本地的长期记忆,无需任何外部 API 依赖。
这对私有化部署场景(企业内部 Agent、涉密数据处理)尤为重要。所有记忆数据存在本地 SQLite,不经过任何云端服务。
总结
TencentDB Agent Memory 解决的问题非常具体:长任务 Agent 的上下文窗口管理。它没有试图用一套万能方案解决所有记忆问题,而是针对"短期任务状态"和"长期用户画像"分别设计了不同的技术路线。
Mermaid 任务画布 + 上下文卸载的组合,本质上是在说:Agent 需要的不是把所有历史信息都装在口袋里,而是一张清晰的"当前在哪、走过哪里、下一步去哪"的地图。
对于正在做复杂 Agent 的开发者,这套方案值得集成的理由有三:
① 无损可追溯:出了问题能找到根源,不是黑箱
② 数字够硬:61% Token 节省不是实验室数字,是 50 步连续任务实测
③ 零外部依赖:本地 SQLite,隐私数据不出本地
💬 你在 Agent 长任务场景里目前用的是什么记忆方案? 欢迎评论区分享!
GitHub 仓库:https://github.com/Tencent/TencentDB-Agent-Memory
如果这篇帮到你,一键三连!
参考资料
- TencentDB-Agent-Memory GitHub:https://github.com/Tencent/TencentDB-Agent-Memory
- 腾讯云开发者社区发布博客:https://developer.cloud.tencent.com/article/2664811
- 中关村在线报道:https://ai.zol.com.cn/1181/11810090.html
- IT之家原文:https://www.ithome.com/0/950/415.htm
本文为原创技术解析,数据来自官方实验和公开报道。最后更新:2026-05-14

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献199条内容
已为社区贡献199条内容

所有评论(0)