《SAP S/4HANA Architecture》——清洁核心:ERP的下一站(上)
回顾
在这本书中,我们了解了业务流程参考模型的原始思想,理解了SAP为何如此组织业务流程。书中的参考模型既是方法论、也是知识库和工具,其中EPC方法论和四个核心问题(做什么、何时做、谁做、需要什么信息)更是理解后续SAP产品的钥匙。虽然出版较早,但是设计理念依然具有持久的生命力。
带着前面的理念和框架,《The Architecture of SAP ERP》带我们深入软甲内部。这本书是从SAP软件架构师Jochen Boder的视角,用了96幅架构图图揭示了SAP ERP的设计原理和运行机制,它解释了软件为何这样设计。
在前面了解了经典ERP设计后,今天分享《SAP S/4 HANA Architecture》来看看SAP新一代产品如何演变。

这本书讲什么?
这本书将讲解了S/4 HANA如何例如用SAP HANA内存数据库实现数据模型优化、实时分析、Fiori体验等创新。
书本分为三部分:
Part I. 介绍了现代ERP软件在架构方面所面临的挑战,阐述了SAP S/4 HANA的技术基础。介绍了虚拟数据模型,以及它如何被分析功能、搜索功能、用户界面和如何拓展性架构;
Part II. 阐述了SAP S/4 HANA核心应用的业务架构,包括销售、服务、采购、生菜、仓库管理以及财务会计等领域。另外还包括HANA中主数据的结构变化,如物料主数据、BOM、Busines partner。
Part III. 重点介绍了S/4 HANA Cloud公有版。阐述了实现预期的云服务特性而设计的各项架构理念,并详细说明了将SAP S/4 HANA Cloud作为SaaS进行运行的相关要点。
这些结构都很官方,但好像不是特别容易理解和记忆。我个人觉得书本内容其实可以用一条主线串起来理解和记忆。即,在面对当代ERP面临的各种挑战(数字时代的速度/适应性/升级/用户体验/智能/云/安全等),作为下一代的S/4 HANA如何在不牺牲性化的前提下,让ERP系统技能持续升级,又能保持稳定,同时还能适应云、实时性等新时代的要求?
S/4 HANA给出的答案是:清洁核心(Clean Core)!
S/4 HANA清洁核心不是一句口号,而是一套完整的技术架构体系。它通过四层次的变革,将ERP从“可修改代码堆”变成了“可扩展的服务平台”:
-
数据层:用VDM统一数据模型,让数据不再散落在千张表里
-
逻辑层:用RAP隔离个性化逻辑,让标准代码永不修改
-
连接层:用标准API开放能力,让S/4成为集成枢纽而非孤岛
-
交付层:用Fiori和云运维,让用户体验从“操作功能”变成“完成任务”
这四层的内容主要来自书本的P1和P3部分,他们属于共性的内容。而P2则偏主要针对不同模块分别展开论述,比较适合各个模块的顾问深入分析研究。这里我们主要探讨架构上的、共性的内容。
下面,结合个人理解对书中内容进行重构和梳理。
===============================
第一层:数据层——从“表”到“对象”
在ECC时代,数据散落在几千张表里(VBAK、VBAP、KNA1……),如果要写一个报表,开发者得先弄清楚这些表之间的关联关系,然后用ABAP代码把它们拼接起来。这套模式运行了几十年,它的问题是:数据被“技术化”了。你想问的是“销售订单”,但系统回答的是“VBAK和VBAP怎么关联”。
业务语言和技术实现之间,隔着一道鸿沟!
- VDM & CDS --> 封装和翻译数据
在S/4 HANA中,通过VDM(Virtual Data Model,虚拟数据模型)把这套“表”的逻辑,抽象成了“对象”的逻辑,即把技术语言翻译成业务语言。
VDM是一个设计理念、方法论,具体是通过CDS(Core Data Service, 核心数据服务)作为工具来实现的。CDS视图将数据库的表和字段有机组合打包,CDS有不同类型的视图并分别对应不同的用途,这些可以在命名规则上体现出来。
常用的命名规则总结:

例如,当你取I_SalesOrder时,你拿到的是一个完整的销售订单对象;当你取C_SalesOrderItemCube时,你拿到的是一个按行项目聚合的分析数据集。
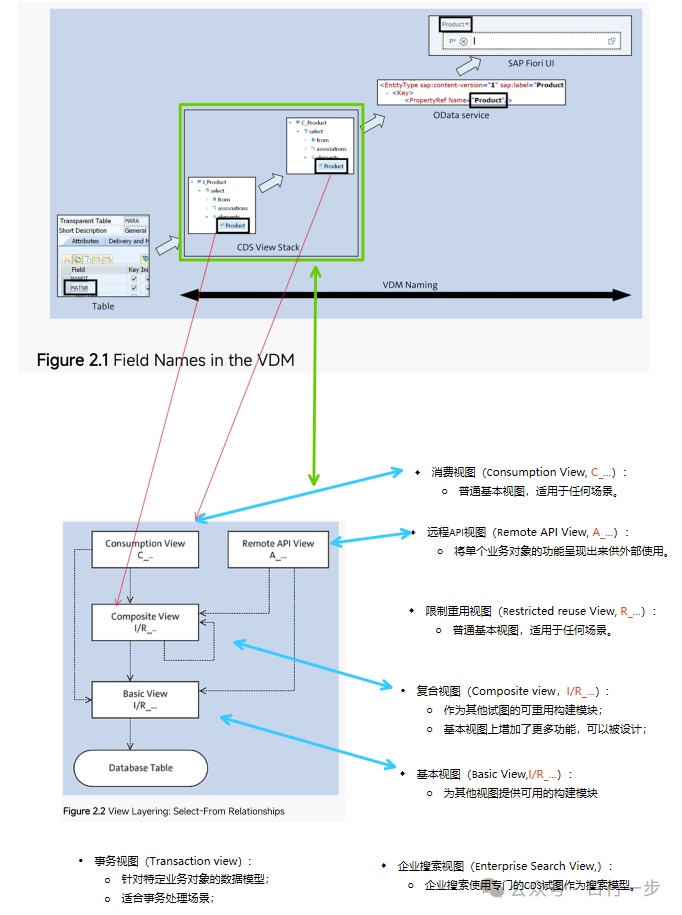
需要注意,CDS视图有层级关系。下面这个图更直观:为某分析和某事务代码“组装”的视图结构。
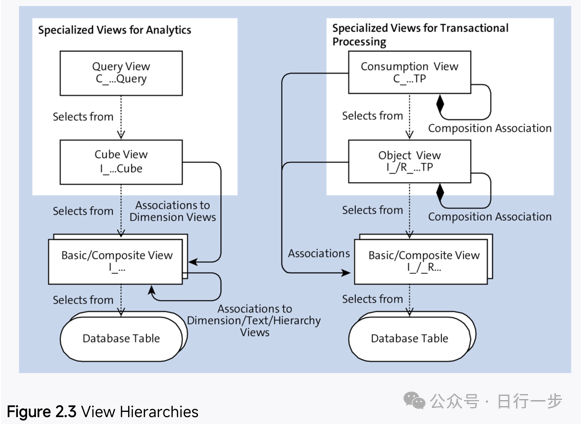
Q: 至此,数据按业务对象“封装”好,但是这些视图“只能读不能写”,没有业务逻辑,那它能做什么?
2. 业务对象 --> 让数据“活起来”
所谓“活起来”,就是给这些数据定义行为,定义这些数据可以做什么,例如创建、更新、删除等等。
如果在ECC时代的话,很多时候会在标准程序里写增强(User Exit、BAdI)实现,甚至修改标准代码,但这样又会遇到老问题:升级是会冲突不断,不易管理。S/4 HANA的核心要求是清洁核心(Clean Core)- 标准代码永不修改,那问题就来了:不修改代码,怎么实现这些业务逻辑?
S/4 HANA给出的答案是RAP。
RAP的全称是ABAP RESTful应用程序编程模型。名字听起来很技术,但它的本质可以概括为一句话:RAP是SAP官方提供的、用于在S/4HANA中“标准化构建业务对象”的编程框架。在CDS视图基础上,用RAP定义行为(Create/Update/Delete…),其文件后缀名“.bdef”,这样就能让数据“活”起来,让它变成一个完整的“业务对象”。
-
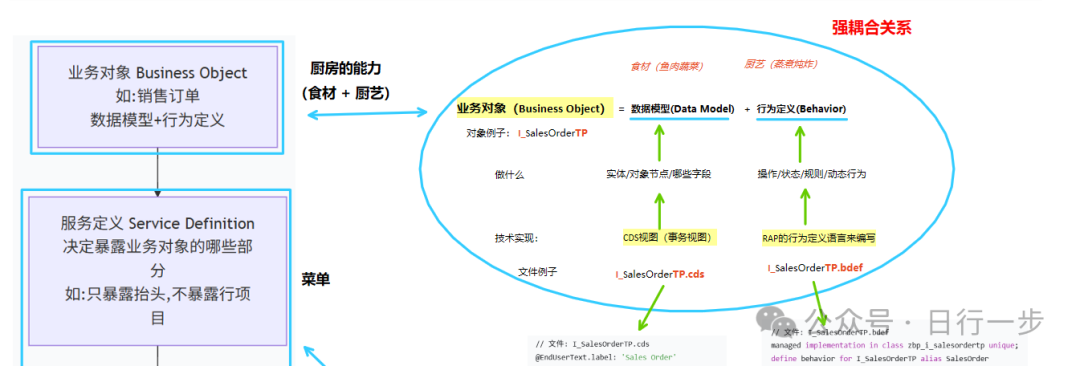
所以,一个完整的业务对象,应该包含数据模型和行为,包含两个同名文件(不同文件后缀)
业务对象=数据模型(CDS视图)+ 行为定义(Behavior, RAP实现)
举例,
I_SalesOrderTP (业务对象)= I_SalesOrderTP.cds (CDS视图文件)+I_SalesOrderTP.bdef(定义行为文件)
文件内容实例:


Q: 至此,数据“活起来”了、有能力了,但是还“关在SAP内部”外界不知道也调用不了,那怎么样可以安全地把能力开放给外界呢?
3. 业务服务 --> 让外界可以通过API调用业务对象
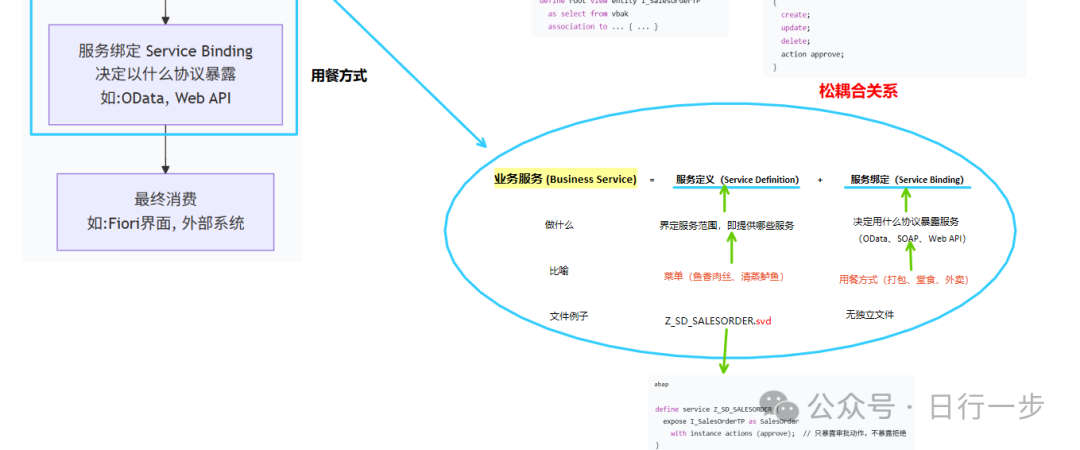
1). 服务定义 (裁剪能力和信息)
业务对象信息和能力有很多,但是不是所有的能力和信息都全部暴露给每个API的,因此,这些对象的能力需要做裁剪,而这个裁剪是通过“服务定义(.svd)”实现。相当于根据不同API的不同,服务定义客制化地限定了它能调用业务对象的哪些信息、做哪些操作。
2). 服务绑定(确定通信协议)
能力信息裁剪和过滤之后,下一步就是确定用什么“语言”跟外部体统进行沟通。企业的IT环境是一个“多语言”的世界,例如ECC通常用RFC/Idoc; 电商平台用JSON; S/4 HANA用OData等。因此需要服务绑定来约定使用哪一种语言通信,从而生成一个可调用的API端点。
所以,业务服务包含了限定了能力和信息(服务定义)、通信的方式(服务绑定)。
业务服务=服务定义+ 服务绑定
至此,S/4 HANA数据层的整合就完成了,从表/字段到数据模型、业务对象、以及可调用API的一个完整链条。
试着类比和画图的方式整理他们之间的关系和关键信息,总结:
Q: S/4 HANA一直强调清洁核心(Clean Core),即标准代码不允许修改。但是业务逻辑、个性化需求怎么实现呢?
===============================
第二层:逻辑层——隔离个性化
在ECC时代,满足个性化需求的手段,可以用一句话概括:“改”。改标准程序、改表结构、改用户出口。SAP提供了多种增强技术(User Exit、Customer Exit、BAdI、隐式增强),甚至允许直接修改标准代码(Modification)。这种方式非常灵活,几乎能实现任何需求,但代价是却很大:
- 升级噩梦:改了标准代码,每次升级都要手动比较、调整、测试。很多企业因此长期停留在旧版本。
- 知识孤岛:每个客户的系统都是“独一无二”的,顾问的经验难以复用,新顾问接手困难。
- 隐性成本:修改越多,测试越复杂,系统越脆弱。一次简单的升级可能变成数月的项目。
S/4HANA的清洁核心理念,彻底改变了游戏规则:“标准代码永不修改,个性化通过扩展实现”。下表对比了两代系统在个性化需求满足上的核心差异:
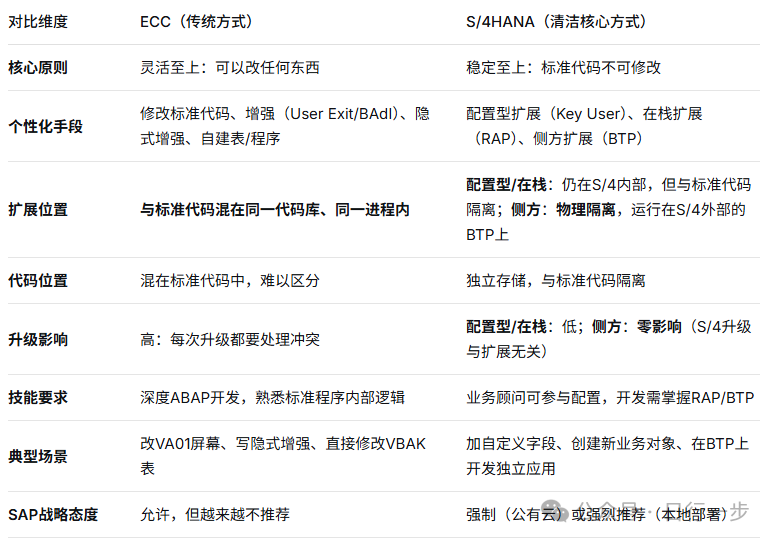
这个转变的本质,是把个性化从“对核心的侵蚀”变成了“对核心的补充”。ECC时代,个性化像在房子里敲墙改结构;S/4HANA时代,个性化像在旁边加盖新房,用走廊连接。房子本身永远保持原样,加盖再多也不影响主体安全。
1. S/4 HANA提供了三种扩展方式
- 配置型扩展(Key User Extensibility)
方式:通过 Fiori 界面,直接添加自定义字段、调整 UI 布局、修改业务规则,完全不写代码。
例子:销售订单界面加一个“客户等级”字段,下拉选项从“黄金”“白银”“青铜”中选。关键用户(Key User)自己就能完成,不需要 ABAP 顾问。
风险:零风险。因为配置存在独立的存储表里,不修改任何标准代码。
B. 在栈扩展(In-Stack Developer Extensibility)
方式:在 S/4HANA 内部,用 RAP(ABAP RESTful 编程模型) 创建新的业务对象,或者给现有对象增加行为(比如给销售订单加一个“催办”动作)。代码和标准代码运行在同一个堆栈(Stack),但不修改标准代码——只是新建对象或扩展预留的增强点。
例子:开发一个自定义的“返利计算”业务对象,它读取销售订单数据,算出返利金额,然后通过 API 暴露给外部系统。整个过程没有改动一行标准销售订单的代码。
风险:中低风险。因为不修改标准代码,升级时基本不受影响。但因为是“在栈”,如果 SAP 升级改了某些底层接口,你的扩展可能需要微调。
C. 侧方扩展(Side-by-Side Extensions)
方式:把扩展做到 S/4HANA 外部——通常部署在 SAP BTP(业务技术平台) 上。S/4HANA 只通过标准 API 暴露数据,扩展应用在 BTP 上独立运行,通过 API 与 S/4 交互。
例子:一个复杂的“销售预测”应用,它需要调用历史订单数据、市场指数等,然后训练模型。这个应用完全跑在 BTP 上,S/4 只负责提供订单数据的 API。两者之间是松耦合。
风险:零风险。扩展和核心在物理上分离,S/4 升级不影响扩展,扩展出问题也不影响 S/4 的正常业务。
三种方式对比总结:
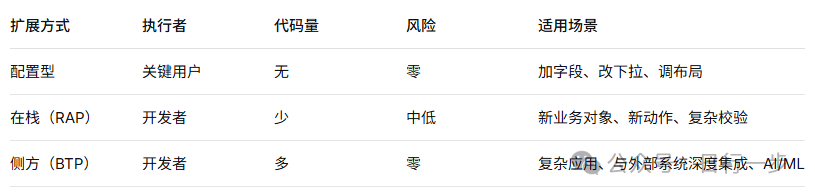
在 S/4HANA Cloud(公有云)中,SAP 的推荐次序是:优先配置型,其次侧方扩展,只有在万不得已时才用在栈扩展。
仔细想想,发现其实拓展方式都跟前面第一层的数据封装关系密切:
-
配置型拓展:自定义字段,存放的位置就是CDS视图;
-
在栈拓展(RAP): 业务对象的数据模型是CDS视图,行为定义也是针对CDS视图;
-
侧方拓展: BTP的应用通过API获取数据,正是基于OData服务(服务绑定)、服务定义,以及业务对象。
所以前面第一层是第二层的前提和地基。没有统一的数据模型,拓展容易乱成一锅粥。
2. 不同部署方式对拓展方式的支持
部署方式决定了你“能选什么”。三种不同的部署方式,对不同扩展方式的支持:

那应该选用何种部署方式呢?参考:

S/4鼓励扩展似乎是SAP架构从私有封闭走向开放标准的一个标志,同时也意味着商业模式的一个调整。以前客户买断了之后自己想怎么改怎么改,升级客户自己负责管理,而未来可能会向订阅方向推、由SAP负责升级和运维。显然清洁核心代码对系统运维和升级都非常友好和方便,同时订阅的方式又可以为SAP增收。
至此,前两层讲完。数据统一了,逻辑也隔离了。S/4HANA的清洁核心地基已经筑牢。但系统不能是孤岛——它要能开门迎客、要让人用得顺手。
下一篇,我们聊第三层“连接”与第四层“交付”。如果觉得这个系列对你有帮助,欢迎转发。谢谢!
更多文章在WX: 日行一步

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)