Linux io_uring讲解
io_uring:Linux 为什么需要另一套异步 I/O 机制
io_uring 是近几年 Linux 内核里最值得关注的 I/O 基础设施之一。它不是对 read、write、epoll 做一次小修小补,而是试图重新定义“用户态如何把 I/O 工作高效地交给内核”这件事。
如果只看表面,很多人会把 io_uring 理解成“更快的异步 I/O API”。这个说法不算错,但不够准确。io_uring 真正要解决的问题,并不只是某一个系统调用慢,而是 Linux 传统 I/O 模型在高并发、低延迟场景下,已经暴露出了一整套结构性问题。
这篇文章试着从工程视角回答几个核心问题:
- 为什么会出现
io_uring - 它究竟是在解决什么问题
- 它的核心原理是什么
- 它适合什么场景,又不适合什么场景
一、为什么会出现 io_uring
要理解 io_uring,必须先看 Linux 之前的 I/O 路线为什么越来越吃力。
1. 传统同步 I/O 的问题
最经典的 I/O 调用方式就是:
read(fd, buf, size);
write(fd, buf, size);
它的问题非常直接:线程发起调用后,通常要等内核把事情做完,调用才返回。哪怕底层设备很快,这个模型仍然意味着:
- 每次 I/O 都要进入一次内核
- 每次调用都要有系统调用开销
- 线程可能阻塞,调度器要参与上下文切换
- 在大量并发连接下,线程模型会迅速膨胀
这套模式在低并发时代完全够用,但当服务端开始面对成千上万个连接、频繁的小包收发、海量磁盘请求时,开销会逐渐从“设备慢”变成“软件栈本身太重”。
2. 非阻塞 I/O + epoll 也不是终点
后来 Linux 逐步形成了另一条主流路线:non-blocking fd + epoll。
它解决了一个非常重要的问题:线程不再需要为每个连接阻塞等待,应用可以通过事件通知来处理“哪个 fd 现在可读、哪个可写”。
这已经比“一连接一线程”先进很多,但它仍然有几个根本限制:
epoll解决的是“事件通知”,不是“异步执行 I/O”- 应用仍然要在收到事件后自己调用
read/write - 一次完整处理通常仍然包含多次系统调用
- 业务代码需要维护复杂的状态机
- 小请求场景下,系统调用和状态切换成本依然明显
换句话说,epoll 提供的是 readiness model,也就是“告诉你现在差不多可以做了”;但它并没有把“做这件事”本身也异步化。
3. Linux AIO 历史上并不好用
Linux 不是没有做过异步 I/O。内核早就有过 libaio/Linux AIO。
但它一直没有成为通用应用层的主角,原因很现实:
- 接口不够统一,使用体验差
- 语义偏底层,编程复杂
- 对文件 I/O 之外的支持不理想
- 与网络 I/O、超时、轮询等场景缺乏统一抽象
很多开发者最终还是回到了 epoll + non-blocking + 线程池 这条路上。
这说明业界真正需要的,不是“某种局部的异步接口”,而是一套统一、可扩展、足够高性能的 I/O 提交与完成框架。
io_uring 就是在这个背景下出现的。
二、io_uring 试图解决什么问题
io_uring 的目标,不只是“让 I/O 更快”,而是让用户态和内核之间的 I/O 协作方式发生变化。
它主要解决四类问题。
1. 降低系统调用次数
传统模型里,一次 I/O 经常意味着:
- 应用等待事件
- 事件来了,发起系统调用
- 系统调用返回结果
高频场景下,系统调用本身就是成本。io_uring 把“提交请求”和“获取完成结果”改造成共享环形队列,尽量减少反复陷入内核的次数。
2. 降低上下文切换和调度开销
如果线程因为 I/O 阻塞,就会涉及调度;如果依赖线程池兜底异步,也会增加线程管理成本。
io_uring 的设计方向是:尽可能把更多工作变成“队列驱动”,而不是“线程睡眠再唤醒”。这对低延迟系统尤其重要。
3. 统一异步操作模型
io_uring 并不只想做“异步读写”。它试图把很多操作放进同一个提交-完成框架里,包括:
- 文件读写
- 网络收发
acceptconnect- 超时控制
poll- 文件关闭、打开等辅助操作
这样一来,应用不必在 epoll、线程池、定时器、各种特定接口之间来回切换,而是可以围绕一种统一的 I/O 编排模型来写。
4. 给内核更多优化空间
一旦用户态不再只是“发一个系统调用,等一个返回值”,而是改成“批量提交一组请求,由内核统一处理”,内核就有更多机会做优化:
- 批处理
- 请求合并
- 减少锁竞争
- 少做不必要的唤醒
- 更好地贴近设备队列模型
这也是 io_uring 名字里 uring 的含义所在:它借用了现代高性能设备常见的 ring buffer 思路。
三、io_uring 的核心原理
io_uring 的核心思想可以概括成一句话:
用户态和内核共享两组环形队列,一组用来提交请求,一组用来接收完成结果。
这和传统“每次做事都发一个系统调用”的模式有本质不同。
1. 两个环:SQ 和 CQ
io_uring 中最核心的结构是两组 ring:
SQ:Submission Queue,提交队列CQ:Completion Queue,完成队列
应用把要做的事情放进 SQ,内核处理完成后把结果放进 CQ。
它们通常通过 mmap 映射到用户态,因此用户态和内核可以围绕同一块共享内存协作,而不是每次都靠参数拷贝和系统调用返回值交流。
2. SQE 和 CQE
队列里的元素也有明确分工:
SQE:Submission Queue Entry,描述“你要我做什么”CQE:Completion Queue Entry,描述“我做完了,结果是什么”
比如你要发一个异步读请求,就在 SQE 里填入:
- 操作类型,例如
READV - 文件描述符
- 缓冲区地址
- 长度
- 偏移
- 用户自定义数据
user_data
内核处理完后,会在 CQE 里返回:
- 结果码
- 完成状态
- 原样带回
user_data
这个 user_data 很关键。它让应用可以在大量并发请求完成时,快速知道“这个结果对应的是哪个业务上下文”。
3. 提交和完成是解耦的
传统同步 I/O 是“调用即执行,执行即返回”。
io_uring 则把整个过程拆成了两步:
- 提交请求
- 稍后收取完成事件
这个解耦带来的价值非常大:
- 可以一次提交多个请求
- 可以按批次收割结果
- 可以把多个操作串起来
- 可以减少调用边界上的来回切换
从架构角度看,它更像是内核提供了一个轻量级 I/O 工作队列,而不是一组孤立的系统调用。
4. 为什么它能更高效
io_uring 的效率并不来自某一个魔法优化,而是来自几个因素叠加:
- 共享内存队列减少了数据交换成本
- 批量提交减少了系统调用次数
- 批量完成减少了事件处理成本
- 队列化模型降低了调度和状态切换频率
- 接口统一后,应用层可以少维护一堆分裂的 I/O 机制
在高 IOPS、高连接数、小包、低延迟这些场景里,这些细节叠加起来会非常可观。
5. io_uring 里最关键的数据结构
如果只是理解概念,知道 SQ 和 CQ 就够了;但如果要真正写代码,必须理解它背后的核心数据结构。
先说结论:io_uring 用户态最常接触的结构,主要有四类:
struct io_uringstruct io_uring_sqestruct io_uring_cqestruct io_uring_params
如果使用 liburing,你平时接触最多的也是这几组抽象。
struct io_uring
struct io_uring 不是内核 UAPI 里暴露给应用直接操作的原始布局,而是 liburing 在用户态封装出来的“ring 上下文对象”。
它的职责是把一整个 io_uring 实例组织起来,包括:
- 提交队列状态
- 完成队列状态
- ring fd
- ring 映射后的内存信息
- 一些特性和标志位
从工程上看,你可以把它理解成:
“一个进程内可操作的 io_uring 句柄”
典型使用方式大致是:
struct io_uring ring;
io_uring_queue_init(256, &ring, 0);
初始化之后,后续的提交和收割完成事件,基本都围绕这个 ring 对象展开。
struct io_uring_sqe
SQE 是 Submission Queue Entry,也就是“提交描述符”。每一个 SQE 代表一项准备交给内核去做的工作。
可以把它理解成一张任务单,里面至少要说明:
- 这是哪一种操作
- 作用于哪个文件描述符
- 缓冲区在哪里
- 长度是多少
- 偏移是多少
- 附带哪个业务上下文
简化理解时,可以记住它的几个核心字段:
struct io_uring_sqe {
__u8 opcode;
__u8 flags;
__u16 ioprio;
__s32 fd;
__u64 off;
__u64 addr;
__u32 len;
union {
__kernel_rwf_t rw_flags;
__u32 poll_events;
__u32 sync_range_flags;
__u32 msg_flags;
__u32 timeout_flags;
__u32 accept_flags;
__u32 cancel_flags;
__u32 open_flags;
__u32 statx_flags;
__u32 fadvise_advice;
__u32 splice_flags;
__u32 rename_flags;
__u32 unlink_flags;
__u32 hardlink_flags;
};
__u64 user_data;
};
这里最值得重点理解的是几个字段:
opcode
表示操作类型,例如读、写、收、发、超时、轮询等。fd
表示本次操作关联的文件描述符。off
表示文件偏移。对 socket 这类流式 fd,通常不强调这个字段。addr
指向用户缓冲区,或者某个参数结构。len
本次 I/O 长度,或者相关参数个数。user_data
这是应用侧最重要的字段之一。它是一个 64 位用户自定义值,内核不会解释它,只会在完成时原样带回。
实际开发里,user_data 经常被用来存放:
- 请求 ID
- 指针地址
- 连接对象编号
- 状态机上下文句柄
这样当 CQE 回来时,应用就能快速把结果路由回对应业务对象。
struct io_uring_cqe
CQE 是 Completion Queue Entry,也就是“完成描述符”。每一个 CQE 代表一项已经完成的请求结果。
它比 SQE 简单很多,核心就是“谁完成了,结果如何”:
struct io_uring_cqe {
__u64 user_data;
__s32 res;
__u32 flags;
};
这三个字段非常关键:
user_data
来自你提交时填入的SQE.user_data。res
操作结果。成功时通常是返回值,例如读了多少字节;失败时通常是负的错误码。flags
描述补充完成状态,例如是否有额外信息。
这里 res 的语义很像传统系统调用返回值,只不过它不是同步返回,而是在完成队列里异步返回。
struct io_uring_params
这个结构主要用于 ring 初始化阶段。应用在创建 io_uring 时,可以通过它告诉内核“我希望怎么建这个 ring”,同时内核也会通过它把 ring 的一些布局信息回填给用户态。
它的职责包括:
- 指定创建标志
- 获取 SQ/CQ ring 的偏移信息
- 获取支持特性
- 告知应用 mmap 布局
可以把它理解成:
“创建 io_uring 时的协商结构”
它不是每次 I/O 都要碰,但理解它有助于你明白:io_uring 之所以能高效运行,是因为创建阶段就已经把共享内存和 ring 布局约定好了。
SQ ring 和 CQ ring 的头尾指针
除了上面三个业务上最常见的结构,真正驱动 ring 运转的还有一组非常关键的共享元数据:
headtailring_maskring_entries
它们分别存在于提交队列和完成队列中。
可以这样理解:
tail往前推进,表示生产者放入了更多项head往前推进,表示消费者已经取走了更多项ring_mask常用于把递增下标映射回环形数组位置ring_entries表示 ring 的容量
一个最基本的 ring 下标计算通常类似这样:
index = tail & ring_mask;
这就是典型的环形缓冲区写法。只要 ring 容量是 2 的幂,就可以用按位与高效地完成取模。
为什么这些结构设计得这么“扁平”
从内核工程的角度看,io_uring 的这些结构有一个很明显的特点:字段直白、内存布局稳定、便于共享和批量处理。
原因很简单,这不是一个面向“优雅对象模型”的接口,而是一个面向高性能路径的数据平面接口。
它优先考虑的是:
- 跨用户态和内核态的低成本协作
- 尽量少拷贝
- 尽量少解释
- 尽量适合批处理
所以 io_uring 的数据结构看上去更像设备队列接口,而不像传统高级 API。
SQ线程
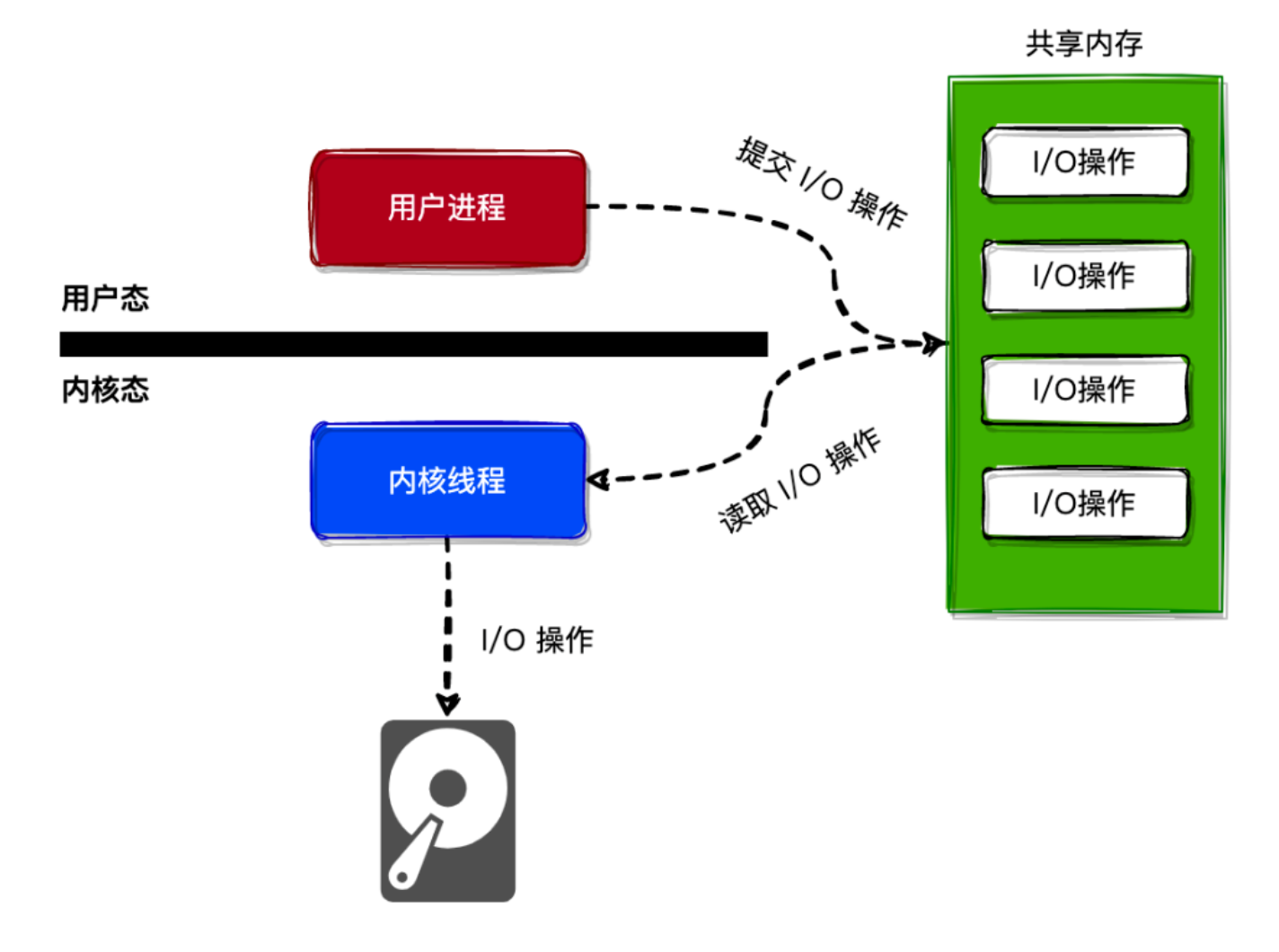
前面介绍了 io_uring怎么通过共享 提交队列 和 完成队列 来避免不必要的系统调用,但应用程序将 I/O 操作提交到 提交队列 后,内核什么时候从 提交队列 中获取要进行的 I/O 操作,并且发起 I/O 请求呢?
当用户使用 SQPOLL模式(指定了 IORING_SETUP_SQPOLL标志)创建 io_uring时,内核将会创建一个名为 io_uring-sq的内核线程(称为 SQ线程),此内核线程会不断从 提交队列 中读取 I/O 操作,并且发起 I/O 请求。
当 I/O 请求完成以后,SQ 线程将会把 I/O 操作的结果写入到 完成队列 中,应用程序就可以从 完成队列 中读取 I/O 操作的结果。
如下图所示:
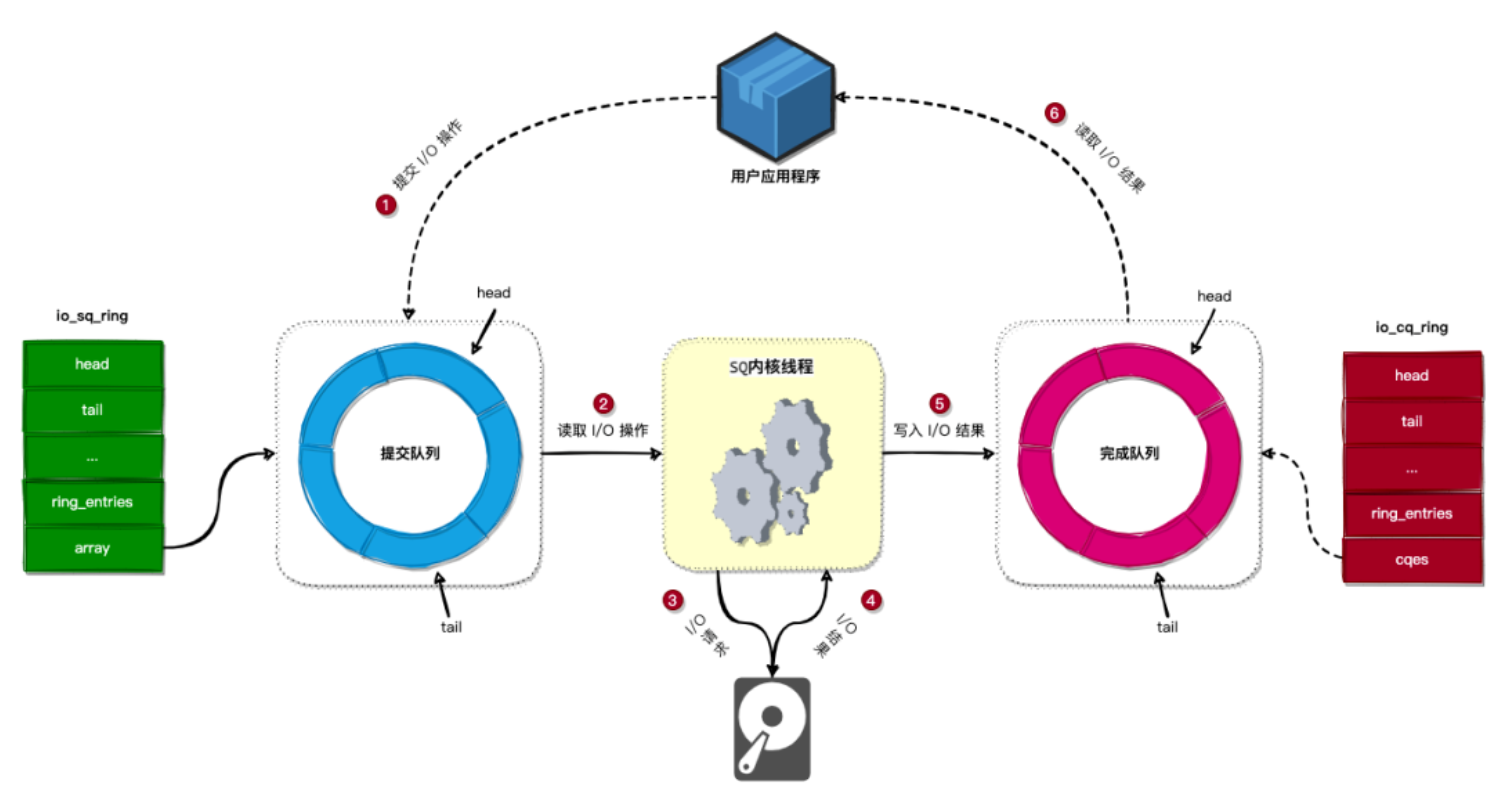
我们简单总结下 io_uring 的操作步骤:
- 第一步:应用程序通过向
io_uring的 提交队列 提交 I/O 操作。 - 第二步:SQ内核线程从 提交队列 中读取 I/O 操作。
- 第三步:SQ内核线程发起 I/O 请求。
- 第四步:I/O 请求完成后,SQ内核线程会将 I/O 请求的结果写入到
io_uring的 完成队列 中。 - 第五步:应用程序可以通过从 完成队列 中读取到 I/O 操作的结果。
四、它为什么叫 io_uring
很多人第一次看到这个名字会觉得奇怪。其实它的命名非常直白:
io:I/Ouring:userspace ring buffer
也就是说,这套机制的核心就是“围绕用户态可见的环形队列来组织 I/O”。
这种设计思路并不是凭空出现的。现代存储和网络设备本来就大量依赖 queue/ring 模型。io_uring 某种程度上是把这种高性能队列化思想,进一步往通用 Linux I/O 抽象里推进。
五、io_uring 能解决什么实际问题
说完原理,再落回工程实践。
io_uring 适合解决的问题,通常都具有以下特征。
1. 高频 I/O 场景下的系统调用开销
如果你的应用每秒要处理大量读写请求,且请求粒度不大,那么系统调用成本、上下文切换成本、事件循环调度成本会非常显眼。
这时候 io_uring 的批处理和共享队列优势就很容易体现出来。
2. 文件 I/O 和网络 I/O 的统一异步化
传统服务端架构里,网络 I/O 往往由 epoll 管,磁盘 I/O 则可能依赖同步调用或线程池。两者模型不统一,代码很容易分裂。
io_uring 提供了一种更一致的方式,让文件和网络相关操作都能进入同一种提交-完成框架。
3. 减少线程池依赖
很多所谓的“异步”程序,本质上只是把阻塞调用塞进线程池。
这在功能上可行,但规模上往往不优雅:
- 线程数需要控制
- 队列需要调度
- 栈内存会膨胀
- 上下文切换会增多
io_uring 的一个重要价值,就是在部分场景下把“靠线程池模拟异步”替换成“真正由内核队列驱动的异步”。
4. 更灵活的 I/O 编排
io_uring 支持链式提交、超时、取消、轮询等能力,这意味着应用可以把多个 I/O 步骤编排成更紧凑的执行序列。
例如:
- 先接收连接
- 再读取请求
- 再写回响应
- 设置超时保护
这些动作可以被更系统化地组织,而不必全靠用户态状态机拼装。
六、它是不是 epoll 的替代品
这是一个很常见的问题。
严格来说,io_uring 不只是 epoll 的替代品。它覆盖的范围更大,因为它不是单独的事件通知机制,而是一套更完整的异步操作框架。
更准确的说法是:
epoll解决的是“我该什么时候去做 I/O”io_uring解决的是“我怎样把 I/O 本身提交出去,并在完成后高效收回结果”
在某些网络场景里,io_uring 确实能承担过去 epoll + nonblocking read/write 的角色。
但工程上不能简单说“有了 io_uring 就不需要 epoll 了”。原因有两个:
- 不同内核版本、不同操作类型、不同驱动路径上的成熟度并不完全一致
- 某些应用已经围绕
epoll建立了很稳定的系统,迁移成本未必划算
因此,一个更工程化的结论是:
io_uring是 Linux 高性能异步 I/O 的新主线,但是否替代epoll,要看你的业务模型、内核版本和收益预期。
七、它的代价和边界是什么
任何高性能机制都不是免费的,io_uring 也一样。
1. 编程复杂度更高
相比直接调用 read/write,io_uring 的编程模型明显更复杂。你要管理:
- 提交队列
- 完成队列
- 缓冲区生命周期
- 请求与结果对应关系
- 错误处理和取消逻辑
如果业务本身并不高并发,这种复杂性可能得不偿失。
2. 不同场景收益差异很大
io_uring 并不是所有程序都能“无脑提速”。
如果应用瓶颈在:
- CPU 计算
- 上层协议处理
- 数据库查询
- 业务锁竞争
那么单纯换成 io_uring,收益可能非常有限。
3. 内核路径与生态成熟度要考虑
io_uring 很强,但它终究强依赖内核实现。线上落地时要看:
- 你的内核版本是否足够新
- 目标操作是否已经很好支持
- 所用语言运行时或框架封装是否成熟
- 运维团队是否能处理相关问题
高性能接口的价值,从来不只取决于 API 设计,也取决于它在你的生产环境里是否“稳定可控”。
八、从内核工程角度看,io_uring 真正重要的地方
如果站在资深内核工程师的视角看,io_uring 最重要的意义并不是“又多了一个 API”,而是它代表了 Linux I/O 设计的一次方向调整。
过去很多接口的思路是:
- 用户态发起一次调用
- 内核当场处理
- 立即返回结果
而 io_uring 的思路是:
- 用户态先把工作描述出来
- 内核按队列消费这些工作
- 完成后再把结果异步返回
这更接近现代高性能系统的基本形态:队列化、批处理、异步完成、尽量减少边界来回切换。
因此,io_uring 的价值不只是“优化了几种 I/O 操作”,而是给 Linux 提供了一种更适合未来高并发工作负载的通用交互模式。
九、总结
io_uring 出现的根本原因,是传统 Linux I/O 模型在高并发、低延迟场景下,越来越难同时满足性能、统一性和编程效率。
它要解决的问题包括:
- 系统调用次数过多
- 阻塞和上下文切换开销高
epoll只能通知事件,不能统一异步执行 I/O- 线程池式异步成本高
- 文件和网络 I/O 模型分裂
它的核心原理是:
- 用共享内存中的两组 ring buffer
- 让用户态提交
SQE - 让内核异步完成后返回
CQE - 用提交/完成解耦、批处理和队列化模型来提升效率
从结果看,io_uring 并不是“所有程序都该立刻迁移”的银弹,但在高性能 I/O 场景里,它已经成为 Linux 无法绕开的关键技术。
如果你只记住一句话,我建议记住这一句:
io_uring的本质,不是把read变快,而是把 Linux I/O 从“调用驱动”推向“队列驱动”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)