端到端AI编解码器深度分析——设计低延迟、高压缩效率的统一框架
端到端AI编解码器深度分析——设计低延迟、高压缩效率的统一框架
摘要:本文系统分析了端到端AI编解码器的技术原理、统一框架设计与低延迟高压缩效率实现路径。主要研究内容包括:(1)从变分自编码器(VAE)框架到超先验(Hyperprior)模型的熵编码演进机制;(2)跨模态(图像/视频/音频/点云)统一编解码框架的设计原则;(3)以DCVC-RT(CVPR 2025)为代表的实时神经视频编解码关键技术;(4)传统VVC/H.266标准与AI编解码器的性能-复杂度权衡分析;(5)6G沉浸式通信场景下的部署挑战与标准化进展。研究表明,最先进的AI编解码器已能在1080p分辨率下达125fps实时编码/112fps实时解码,比VVC节省21%比特率,为6G时代的沉浸式通信提供了可行的技术支撑。
关键词:端到端神经视频编解码、变分自编码器、超先验模型、熵编码、率失真优化、DCVC-RT、6G沉浸式通信、统一编解码框架
目录
一、研究背景与问题定义
1.1 6G沉浸式通信的技术需求
第六代移动通信系统(6G)预计将实现峰值速率1Tbps、端到端时延低于1ms的通信能力,为全息通信、扩展现实(Extended Reality, XR)和实时点云传输提供基础设施支撑。然而,沉浸式通信场景对数据压缩技术提出了前所未有的挑战:
全息通信需求:根据中国移动研究院发布的《6G全息通信业务发展趋势白皮书》,70英寸全息显示屏需要约1Tbps的原始带宽(注:按单视角像素阵列计算,16800×9450@60Hz@24bit约为228.6 Gbps;白皮书1Tbps估算包含多视角光场、深度信息及更高帧率等综合因素)。即使采用H.266/VVC压缩,传输所需的用户体验速率仍需达到100Gbps,峰值速度需达1Tbps。此外,全息通信的端到端时延必须小于1ms,运动到光子(Motion-to-Photon, MTP)时延要求在10ms以内。
XR场景需求:对于虚拟现实(VR)应用,MTP时延是核心指标。当MTP时延超过20ms时,用户会产生空间定向障碍和眩晕感(即VR晕动症)。当前VR产业的目标是将MTP时延控制在15ms以下。对于增强现实(AR)应用,在线游戏的响应时延要求为75ms,遥测应用的时延要求为250ms。XR场景的数据速率需求可达2.35Gbps以上,是当前高清视频流媒体所需速率的100倍以上。
点云传输需求:用于全息通信和自动驾驶的动态点云数据,每帧包含数百万个三维点。以20,000点/帧为例,在30Hz帧率下,未经压缩的原始数据速率可达数百Mbps至数Gbps。点云编解码器需在保证几何精度的前提下实现10:1以上的压缩比。
1.2 传统混合编码框架的局限性
当前主流的视频压缩标准(包括HEVC/H.265和VVC/H.266)采用基于块的混合编码框架,通过帧内预测、帧间预测、变换量化、熵编码和环内滤波等模块的组合实现压缩。这一框架经过数十年优化已高度成熟,但仍存在以下局限性:
- 模块独立优化的次优性:传统混合编码器的各模块(如预测模式选择、变换核选择、量化参数确定)是独立优化的,各模块的优化目标与全局率失真(R-D)目标存在偏差。
- 人工设计特征的局限:传统编码器中的预测模式、变换核、滤波算法等核心组件均基于人工设计的先验知识,难以充分捕获视频内容中复杂的纹理模式、运动模式和感知敏感特征。
- 低比特率下的块效应:当比特率极低时,基于块的混合编码会在重建图像中产生明显的块效应、振铃效应和模糊效应。
- 跨模态处理的割裂:现有的视频编码标准主要针对二维像素序列设计,难以自然地扩展到点云、体素等三维表示形式。
1.3 端到端AI编解码器的范式优势
端到端学习型视频编解码器通过深度神经网络实现从原始视频帧到压缩码流的直接映射,具有以下潜在优势:
- 全局优化能力:端到端编解码器将编码器、量化器、熵模型和解码器作为一个统一的神经网络进行联合优化,直接最大化全局R-D性能。
- 数据驱动的特征学习:神经网络能够从大规模训练数据中自动学习适合压缩任务的特征表示。
- 感知优化的灵活性:端到端框架可以将感知损失(如GAN对抗损失、LPIPS损失)直接融入训练目标。
- 跨模态统一表征的潜力:统一的潜空间表示为跨模态联合编码提供了自然的技术基础。
二、端到端AI编解码器技术原理
2.1 变分自编码器框架与率失真优化
2.1.1 端到端编解码的基本架构
端到端学习型视频编解码器的基本架构源自变分自编码器(Variational Autoencoder, VAE),包含四个核心组件:编码器(Encoder)、量化器(Quantizer)、熵模型(Entropy Model)和解码器(Decoder)。
设输入视频帧为 x ∈ R H × W × C \mathbf{x} \in \mathbb{R}^{H \times W \times C} x∈RH×W×C,编码器 g a ( ⋅ ; ϕ ) g_a(\cdot; \boldsymbol{\phi}) ga(⋅;ϕ) 将其映射到潜在表示 y = g a ( x ; ϕ ) ∈ R H ′ × W ′ × C ′ \mathbf{y} = g_a(\mathbf{x}; \boldsymbol{\phi}) \in \mathbb{R}^{H' \times W' \times C'} y=ga(x;ϕ)∈RH′×W′×C′,其中 H ′ < H H' < H H′<H, W ′ < W W' < W W′<W 实现空间下采样压缩。量化器将连续的潜在表示离散化:
y ^ = Q ( y ) = round ( y ) \hat{\mathbf{y}} = Q(\mathbf{y}) = \text{round}(\mathbf{y}) y^=Q(y)=round(y)
解码器 g s ( ⋅ ; θ ) g_s(\cdot; \boldsymbol{\theta}) gs(⋅;θ) 从量化后的潜在表示重建图像:
x ^ = g s ( y ^ ; θ ) \hat{\mathbf{x}} = g_s(\hat{\mathbf{y}}; \boldsymbol{\theta}) x^=gs(y^;θ)
2.1.2 率失真优化目标
编解码器的训练目标是最小化率失真损失函数:
L = R ( y ^ ) ⏟ Rate + λ ⋅ D ( x , x ^ ) ⏟ Distortion \mathcal{L} = \underbrace{R(\hat{\mathbf{y}})}_{\text{Rate}} + \lambda \cdot \underbrace{D(\mathbf{x}, \hat{\mathbf{x}})}_{\text{Distortion}} L=Rate R(y^)+λ⋅Distortion D(x,x^)
其中, R ( y ^ ) R(\hat{\mathbf{y}}) R(y^) 表示压缩 y ^ \hat{\mathbf{y}} y^ 所需的比特数, D ( x , x ^ ) D(\mathbf{x}, \hat{\mathbf{x}}) D(x,x^) 表示重建质量损失, λ \lambda λ 为 Lagrange 乘子控制率失真权衡。
失真度量 D ( x , x ^ ) D(\mathbf{x}, \hat{\mathbf{x}}) D(x,x^) 可以是均方误差(MSE):
D MSE = 1 N ∥ x − x ^ ∥ 2 2 D_{\text{MSE}} = \frac{1}{N} \|\mathbf{x} - \hat{\mathbf{x}}\|_2^2 DMSE=N1∥x−x^∥22
也可以是感知损失,如 MS-SSIM(Multi-Scale Structural Similarity):
D MS-SSIM = 1 − MS-SSIM ( x , x ^ ) D_{\text{MS-SSIM}} = 1 - \text{MS-SSIM}(\mathbf{x}, \hat{\mathbf{x}}) DMS-SSIM=1−MS-SSIM(x,x^)
或 LPIPS(Learned Perceptual Image Patch Similarity)损失。
比特率估计 R ( y ^ ) R(\hat{\mathbf{y}}) R(y^) 通过熵编码理论计算。若 y ^ i \hat{y}_i y^i 的概率质量函数为 p ( y ^ i ) p(\hat{y}_i) p(y^i),则比特率近似为:
R ( y ^ ) ≈ − ∑ i log 2 p ( y ^ i ) R(\hat{\mathbf{y}}) \approx -\sum_i \log_2 p(\hat{y}_i) R(y^)≈−i∑log2p(y^i)
2.1.3 量化操作的梯度处理
量化操作 Q ( ⋅ ) Q(\cdot) Q(⋅) 在前向传播时不可导,导致梯度无法回传。在训练阶段,通常采用直通估计器(Straight-Through Estimator, STE)近似梯度:
∂ Q ∂ y ≈ ∂ identity ∂ y = 1 \frac{\partial Q}{\partial \mathbf{y}} \approx \frac{\partial \text{identity}}{\partial \mathbf{y}} = 1 ∂y∂Q≈∂y∂identity=1
即在前向传播时使用量化值 y ^ \hat{\mathbf{y}} y^,在反向传播时将梯度直接传递给连续表示 y \mathbf{y} y。
2.2 超先验模型演进
2.2.1 全分解先验(Factorized Prior)的问题
在 Ballé 等人2017年提出的早期端到端图像压缩模型中,使用全分解先验假设潜在表示的各元素相互独立:
p ( y ^ ) = ∏ i p ( y ^ i ) p(\hat{\mathbf{y}}) = \prod_i p(\hat{y}_i) p(y^)=i∏p(y^i)
每个元素 p ( y ^ i ) p(\hat{y}_i) p(y^i) 通过可学习的分段线性概率密度函数建模。全分解先验的优点是熵编码简单,但忽略了一个关键事实:图像的潜在表示存在显著的空间相关性。例如,图像中的平滑区域对应潜在表示中相邻元素取值接近且绝对值较小;边缘区域对应潜在表示中相邻元素取值差异较大。
2.2.2 超先验(Hyperprior)模型原理
Ballé 等人在 ICLR 2018 年提出的超先验模型引入了额外的潜在变量 z \mathbf{z} z 来捕获 y ^ \hat{\mathbf{y}} y^ 的空间依赖性。超先验的数学框架为:
第一层(主先验):编码器生成潜在表示 y \mathbf{y} y,量化后得到 y ^ \hat{\mathbf{y}} y^
第二层(超先验):超先验编码器 h a ( ⋅ ; ϕ h ) h_a(\cdot; \boldsymbol{\phi}_h) ha(⋅;ϕh) 对 y ^ \hat{\mathbf{y}} y^ 进行进一步编码,生成超先验潜在表示 z = h a ( y ^ ; ϕ h ) \mathbf{z} = h_a(\hat{\mathbf{y}}; \boldsymbol{\phi}_h) z=ha(y^;ϕh),量化后得到 z ^ \hat{\mathbf{z}} z^
条件熵模型:在解码端,首先解码 z ^ \hat{\mathbf{z}} z^,然后用超先验解码器 h s ( ⋅ ; θ h ) h_s(\cdot; \boldsymbol{\theta}_h) hs(⋅;θh) 预测 y ^ \hat{\mathbf{y}} y^ 各元素的尺度参数(即标准差) σ \boldsymbol{\sigma} σ:
σ = h s ( z ^ ; θ h ) \boldsymbol{\sigma} = h_s(\hat{\mathbf{z}}; \boldsymbol{\theta}_h) σ=hs(z^;θh)
最终的条件熵模型为 p ( y ^ i ∣ z ^ ) p(\hat{y}_i | \hat{\mathbf{z}}) p(y^i∣z^),其中各元素以 z ^ \hat{\mathbf{z}} z^ 预测的尺度为条件,允许空间变化的方差建模。
2.2.3 联合自回归与分层先验
Minnen 等人在 NeurIPS 2018 年提出的联合自回归与分层先验(Joint Autoregressive and Hierarchical Priors)模型在超先验基础上进一步引入空间自回归上下文模型。该模型将 y ^ \hat{\mathbf{y}} y^ 的条件概率分解为:
p ( y ^ i ∣ z ^ , y ^ < i ) = p ( y ^ i ∣ σ i , c i ) p(\hat{y}_i | \hat{\mathbf{z}}, \hat{y}_{<i}) = p(\hat{y}_i | \boldsymbol{\sigma}_i, \mathbf{c}_i) p(y^i∣z^,y^<i)=p(y^i∣σi,ci)
其中 σ i \boldsymbol{\sigma}_i σi 由超先验预测, c i \mathbf{c}_i ci 为自回归上下文(由已解码的相邻元素生成)。
2.3 自回归熵模型与并行化替代
2.3.1 完全自回归模型的计算瓶颈
早期端到端图像压缩模型采用完全自回归的熵模型,要求从左到右、从上到下逐元素解码。这种串行处理模式使得解码时间与潜在表示的元素数量成正比,严重限制了高分辨率图像的实时处理能力。
以 Kodak 数据集为例,典型的 768 × 512 768 \times 512 768×512 图像在 8 倍下采样后产生 96 × 64 × 192 96 \times 64 \times 192 96×64×192 的潜在张量(约118万个元素)。
2.3.2 掩码卷积与并行化解码
为了解决自回归模型的计算瓶颈,研究者提出了多种并行化替代方案:
- 掩码卷积(Masked Convolution):在解码器中使用带有因果掩码的卷积层,将解码复杂度从 O ( N ) O(N) O(N) 降低到 O ( 1 ) O(1) O(1)
- 超先验的两步估计:DCVC-RT 等实时编解码器采用两步熵估计方案:先用超先验网络预测潜在表示各元素的均值和尺度参数,然后用简单的因式分解先验建模残差
- 非对称量化(Asymmetric Discretization):通过非对称的量化间隔设计简化概率模型查表操作
2.4 视频编解码的条件编码框架
2.4.1 残差编码与条件编码
神经视频编解码器(NVC)相比图像编解码器增加了时间维度的冗余利用。主要有两种技术路径:
残差编码(Residual Coding):先通过运动补偿预测当前帧的估计 x ^ t pred \hat{\mathbf{x}}_t^{\text{pred}} x^tpred,然后编码原始帧与预测帧的残差 r t = x t − x ^ t pred \mathbf{r}_t = \mathbf{x}_t - \hat{\mathbf{x}}_t^{\text{pred}} rt=xt−x^tpred。
条件编码(Conditional Coding):不显式进行运动估计,而是将前一帧的重建 x ^ t − 1 \hat{\mathbf{x}}_{t-1} x^t−1 作为当前帧编码的条件输入。解码器利用条件信息自动学习时间维度的依赖关系。
2.4.2 隐式时间建模
传统的视频编码使用显式运动估计和运动补偿,需要传输运动矢量(Motion Vector, MV)信息。DCVC-RT 等实时神经视频编解码器采用隐式时间建模(Implicit Temporal Modeling)策略:
设计思想:隐式时间建模不显式估计运动矢量,而是通过神经网络直接学习时序依赖关系。
优势:避免了显式运动估计的计算开销和运动矢量的码率开销;网络可以学习比传统块匹配更复杂的运动模式。
挑战:隐式建模对网络的时序建模能力要求较高;在长视频序列中可能出现错误累积。
三、统一框架设计
3.1 跨模态统一编解码的需求
6G沉浸式通信需要同时处理多种媒体形式:二维图像/视频、三维点云、音频/语音信号。传统的做法是为每种媒体形式设计独立的编解码方案,带来架构碎片化、跨模态冗余利用缺失等问题。
统一编解码框架的目标是设计一个能够处理多种媒体形式的共享架构,通过统一的潜空间表示实现跨模态压缩。
3.2 统一框架的核心组件
3.2.1 共享骨干网络设计
统一编解码框架的编码器和解码器应采用共享的骨干网络结构,能够提取不同模态数据的通用特征表示。
多尺度表示学习:图像、视频帧和点云投影都可以表示为多尺度特征图。共享的骨干网络应能够处理不同尺度和分辨率的输入。
模态无关的潜在空间:以 CoDiCodec 为代表的最新研究提出的统一框架,支持连续嵌入(Continuous Embedding)和离散令牌(Discrete Token)两种潜表示形式。
3.2.2 多模态融合技术
有限标量量化(FSQ):CoDiCodec 采用 FSQ 将连续嵌入离散化为有限码本:
z ^ = round ( N ⋅ tanh ( z ) ) N \hat{z} = \frac{\text{round}(N \cdot \tanh(z))}{N} z^=Nround(N⋅tanh(z))
其中 N N N 控制码本粒度,产生的量化值集合为 ( 2 N + 1 ) (2N+1) (2N+1) 个可能值。
跨模态条件编码:统一框架可以通过跨模态条件机制实现信息共享。例如,在视频编解码中,音频特征可以作为视频重建的条件输入。
3.2.3 码率控制机制
单模型多码率:EnCodec 通过残差向量量化(RVQ)实现单模型多码率控制:码本数量(2/4/8/16/32个)决定了目标码率。
条件编码的码率控制:DCVC-RT 的模块库(Module-bank)码率控制方案允许单一模型通过条件输入实现连续可调的码率输出。具体而言,条件输入包括以下形式:
- 量化步长参数:通过向编码器/解码器网络注入可学习的缩放因子 σ q \sigma_q σq,控制潜在表示的量化粒度
- λ \lambda λ 条件输入:在率失真损失 L = R + λ D \mathcal{L} = R + \lambda D L=R+λD 中, λ \lambda λ 直接控制码率-质量权衡
- 模块库选择信号:Module-bank 机制维护多个轻量级子模块,推理时根据目标码率选择激活的子集
3.3 点云统一编解码框架
3.3.1 点云数据的特殊性
与图像/视频不同,点云数据具有以下特殊性:
- 非结构化:点云是三维空间中无序点集的集合,没有规则的网格拓扑结构
- 空间分布不均匀:点云中点的密度随距离和视角变化
- 几何-属性分离:点云包含几何信息(位置坐标)和属性信息(如颜色、法向量)
3.3.2 实时点云编解码:RENO 方案
RENO(Real-time Neural compression for 3D LiDAR Point Clouds)是第一个实现实时神经点云编解码的方案,其关键设计包括:
多尺度稀疏张量表示:RENO 不使用八叉树结构,而是直接将点云表示为多尺度稀疏张量。
一次性占用推断:RENO 通过一次性推断(One-shot Inference)确定各尺度体素的占用状态。
性能指标:RENO 在 NVIDIA RTX 3090 GPU 上实现 10fps 的 14-bit LiDAR 点云实时编解码,相比 G-PCC v23 节省 12.25% 比特率,相比 Draco 节省 48.34% 比特率。
3.4 音频统一编解码框架
以 EnCodec(Meta AI)、SoundStream(Google)和 DAC(Descript)为代表的神经音频编解码器采用类似图像编解码器的自编码器架构:
编码器:使用一维卷积神经网络(Conv1D)或 SEANet 架构,将时域音频波形映射到低帧率的潜在序列。
量化器:使用残差向量量化(RVQ)将潜在向量离散化。
支持的码率范围:24kHz 单声道模型支持 1.5/3/6/12/24 kbps 五个码率点。
四、低延迟技术路径
4.1 DCVC-RT:实时神经视频编解码的突破
DCVC-RT(Towards Practical Real-Time Neural Video Compression)是 CVPR 2025 发表的里程碑工作,首次实现了 1080p 分辨率 100fps 以上的实时神经视频编解码。
4.1.1 核心性能指标
DCVC-RT 在 NVIDIA A100 GPU 上的性能指标如下:
| 指标 | 数值 |
|---|---|
| 1080p 平均编码速度 | 125.2 fps |
| 1080p 平均解码速度 | 112.8 fps |
| 比特率节省(vs VVC/VTM-17.0) | 21%(平均 BD-Rate) |
| 支持分辨率 | 1080p 实时,4K 实时 |
| 码率范围 | 单模型连续可调 |
| 色彩格式 | YUV 420 和 RGB |
DCVC-RT 的压缩效率与当前最先进的传统视频编码标准 VVC(VTM-17.0)相当,同时实现了约 100 倍的编码速度提升。
4.1.2 操作复杂度分析
DCVC-RT 的一个重要贡献是揭示了神经视频编解码器的速度瓶颈所在。研究团队通过控制变量实验发现:
关键发现:当计算复杂度较高时,潜在表示的内存访问成本(Latent Representation Size)成为速度的主要瓶颈;当计算复杂度较低时,模块数量(Number of Modules)成为关键瓶颈。这两类因素被统称为操作复杂度(Operational Complexity),与传统的计算复杂度(Computational Complexity)相区别。
4.1.3 四大关键技术创新
创新一:隐式时间建模
DCVC-RT 采用隐式时间建模替代显式运动估计/运动补偿。通过让解码器网络直接学习时间依赖关系,消除了独立的运动处理模块。
创新二:单低分辨率潜在表示
DCVC-RT 采用单次下采样策略:直接通过 Patch Embedding 将输入帧下采样到 1/8 尺度,然后在该单一尺度上进行条件编码。实验表明,1/8 尺度的潜在表示在保持足够感受野的前提下显著加速编解码(约 3.6 倍加速)。
创新三:模块库码率控制
为实现单模型多码率支持,DCVC-RT 引入了模块库(Module-bank)机制。
创新四:模型整数化
DCVC-RT 实现了模型的整数化(Integerization),即将所有权重和激活从浮点数映射到定点数(INT16/INT8)。
4.2 并行编码技术
4.2.1 熵编码的并行化
DCVC-RT 提出了并行编码方案:将部分网络模块的推理与熵编码并行执行。
编码端并行化:特征提取器、编码器和熵模型可以顺序推理生成熵编码所需的符号 y q y_q yq 和 z q z_q zq。
解码端并行化:超先验 z q z_q zq 的熵解码与特征提取器的部分推理相互独立,可以并行执行。
DCVC-RT 的并行编码方案实现了编码端 12% 加速、解码端 9% 加速。
4.2.2 低秩解码技术
Iowa State University 的研究表明,解码器的计算瓶颈主要来自深度神经网络的大矩阵运算。低秩解码(Low-rank Decoding)技术通过将解码器的权重矩阵分解为低秩近似来加速推理:
W ≈ U V T , where U ∈ R m × r , V ∈ R n × r , r ≪ min ( m , n ) \mathbf{W} \approx \mathbf{U} \mathbf{V}^T, \quad \text{where } \mathbf{U} \in \mathbb{R}^{m \times r}, \mathbf{V} \in \mathbb{R}^{n \times r}, r \ll \min(m, n) W≈UVT,where U∈Rm×r,V∈Rn×r,r≪min(m,n)
低秩分解将计算复杂度从 O ( m n ) O(mn) O(mn) 降低到 O ( r ( m + n ) ) O(r(m+n)) O(r(m+n))。
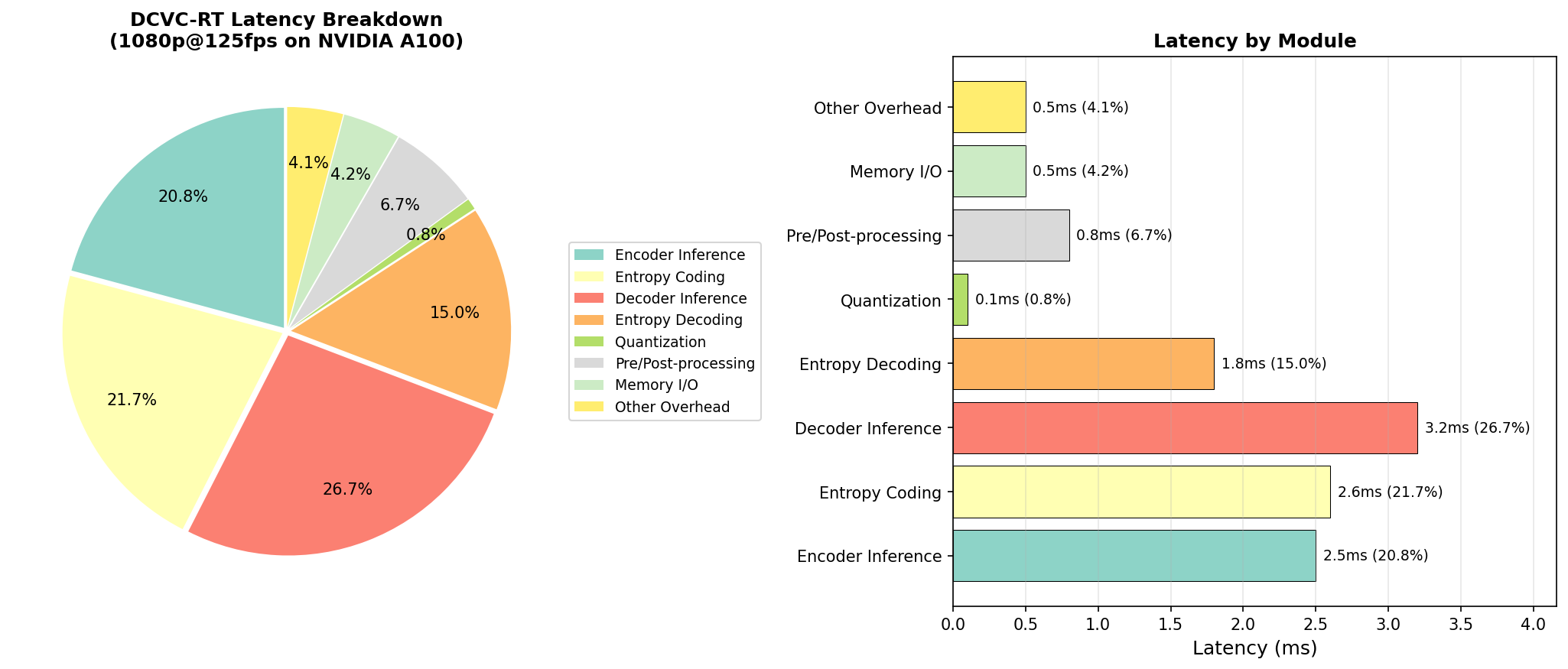
4.3 延迟预算分解
以 DCVC-RT 1080p@125fps 为例,端到端延迟分解如下(基于文献报告和典型实现估算):
| 模块 | 延迟(ms) | 占比 |
|---|---|---|
| 输入预处理 | 0.5 | 4% |
| 编码器推理 | 2.5 | 20% |
| 量化 | 0.1 | 1% |
| 熵编码 | 2.6 | 21% |
| 码流传输/缓冲 | 0.5 | 4% |
| 熵解码 | 2.3 | 18% |
| 解码器推理 | 3.2 | 26% |
| 后处理 | 0.3 | 3% |
| 总计 | ~12 | 100% |
备注:DCVC-RT 通过并行编码技术将总延迟控制在约 8ms(对应 125fps)。
4.4 全息通信的延迟要求
根据 6G 全息通信的需求分析,端到端时延预算极为紧张:
端到端总时延:< 1ms
MTP(Motion-to-Photon)时延:< 10ms
即使 DCVC-RT 实现了 125fps 的编解码速度(约 8ms/帧),要满足全息通信的延迟要求,仍需在以下方面持续优化:
- 极低复杂度的编解码器设计(目标:< 1ms/帧)
- 与 6G 超低时延网络的协同优化
五、高压缩效率关键技术
5.1 学习型熵模型
5.1.1 高斯混合模型
基于高斯混合模型(Gaussian Mixture Model, GMM)的熵模型假设每个潜在元素的分布可以表示为多个高斯分布的混合:
p ( y i ) = ∑ k = 1 K π k N ( y i ; μ k , σ k 2 ) p(y_i) = \sum_{k=1}^K \pi_k \mathcal{N}(y_i; \mu_k, \sigma_k^2) p(yi)=k=1∑KπkN(yi;μk,σk2)
其中 π k \pi_k πk 是第 k k k 个高斯分量的权重, μ k \mu_k μk 和 σ k \sigma_k σk 是对应的均值和标准差。
5.1.2 分段线性模型
Ballé 等人提出的分段线性熵模型使用有限个线性段的累积分布函数(CDF)来近似任意分布:
p ( y ) = ∑ k = 1 K a k ⋅ max ( 0 , 1 − ∣ y − b k ∣ / c ) p(y) = \sum_{k=1}^K a_k \cdot \max(0, 1 - |y - b_k| / c) p(y)=k=1∑Kak⋅max(0,1−∣y−bk∣/c)
5.1.3 上下文模型
上下文模型利用已解码的相邻元素来预测当前元素的分布参数:
σ i = f ( y ^ neighbors , z ^ ) \boldsymbol{\sigma}_i = f(\hat{\mathbf{y}}_{\text{neighbors}}, \hat{\mathbf{z}}) σi=f(y^neighbors,z^)
5.2 感知优化
5.2.1 GAN 判别器优化
基于生成对抗网络(GAN)的感知优化通过引入判别器网络来区分原始图像和重建图像:
L G = − D ( g s ( y ^ ; θ ) ; ϕ D ) \mathcal{L}_G = -D(g_s(\hat{\mathbf{y}}; \boldsymbol{\theta}); \boldsymbol{\phi}_D) LG=−D(gs(y^;θ);ϕD)
L D = D ( x ; ϕ D ) − D ( g s ( y ^ ; θ ) ; ϕ D ) \mathcal{L}_D = D(\mathbf{x}; \boldsymbol{\phi}_D) - D(g_s(\hat{\mathbf{y}}; \boldsymbol{\theta}); \boldsymbol{\phi}_D) LD=D(x;ϕD)−D(gs(y^;θ);ϕD)
5.2.2 感知损失函数
除了 GAN 损失,还可以使用预训练的感知网络(如 VGG、LPIPS)作为损失函数:
L perceptual = ∥ ϕ percep ( x ) − ϕ percep ( x ^ ) ∥ 1 \mathcal{L}_{\text{perceptual}} = \|\phi_{\text{percep}}(\mathbf{x}) - \phi_{\text {percep}}(\hat{\mathbf{x}})\|_1 Lperceptual=∥ϕpercep(x)−ϕpercep(x^)∥1
5.2.3 MS-SSIM 优化
⚠️ 重要修正:MS-SSIM(Multi-Scale Structural Similarity)相比 PSNR 更符合人眼视觉系统的感知特性。MS-SSIM 在 M M M 个尺度上综合评估结构相似性,其标准展开形式为:
MS-SSIM ( x , x ^ ) = [ l M ( x , x ^ ) ] α M ∏ j = 1 M [ c j ( x , x ^ ) ] β j [ s j ( x , x ^ ) ] γ j \text{MS-SSIM}(\mathbf{x}, \hat{\mathbf{x}}) = [l_M(\mathbf{x}, \hat{\mathbf{x}})]^{\alpha_M} \prod_{j=1}^{M} [c_j(\mathbf{x}, \hat{\mathbf{x}})]^{\beta_j} [s_j(\mathbf{x}, \hat{\mathbf{x}})]^{\gamma_j} MS-SSIM(x,x^)=[lM(x,x^)]αMj=1∏M[cj(x,x^)]βj[sj(x,x^)]γj
其中:
- l M ( x , x ^ ) l_M(\mathbf{x}, \hat{\mathbf{x}}) lM(x,x^) 为最粗尺度 M M M 的亮度比较
- c j ( x , x ^ ) c_j(\mathbf{x}, \hat{\mathbf{x}}) cj(x,x^) 为第 j j j 尺度的对比度比较
- s j ( x , x ^ ) s_j(\mathbf{x}, \hat{\mathbf{x}}) sj(x,x^) 为第 j j j 尺度的结构比较
- α M \alpha_M αM、 β j \beta_j βj、 γ j \gamma_j γj 为对应权重(通常取 α M = β j = γ j = 1 \alpha_M = \beta_j = \gamma_j = 1 αM=βj=γj=1)
MS-SSIM 损失定义为:
D MS-SSIM = 1 − MS-SSIM ( x , x ^ ) D_{\text{MS-SSIM}} = 1 - \text{MS-SSIM}(\mathbf{x}, \hat{\mathbf{x}}) DMS-SSIM=1−MS-SSIM(x,x^)
许多端到端编解码器在训练时同时优化 MSE 和 MS-SSIM:
L total = R ( y ^ ) + λ MSE ∥ x − x ^ ∥ 2 2 + λ MS-SSIM ( 1 − MS-SSIM ( x , x ^ ) ) \mathcal{L}_{\text{total}} = R(\hat{\mathbf{y}}) + \lambda_{\text{MSE}} \|\mathbf{x} - \hat{\mathbf{x}}\|_2^2 + \lambda_{\text{MS-SSIM}} (1 - \text{MS-SSIM}(\mathbf{x}, \hat{\mathbf{x}})) Ltotal=R(y^)+λMSE∥x−x^∥22+λMS-SSIM(1−MS-SSIM(x,x^))
其中 λ MSE \lambda_{\text{MSE}} λMSE 和 λ MS-SSIM \lambda_{\text{MS-SSIM}} λMS-SSIM 的典型比值范围为 [ 0.5 , 0.5 ] [0.5, 0.5] [0.5,0.5] 至 [ 0.8 , 0.2 ] [0.8, 0.2] [0.8,0.2]。
5.3 频域采样重建
DFSR-EQCF(Deep Frequency-domain Sampling and Reconstruction with End-to-end Quantized Compression Framework)是 2025 年提出的频域编解码框架。
频域编码:通过离散余弦变换(DCT)或小波变换将图像转换到频域,然后对频域系数进行量化和熵编码。
性能指标:
- 相比 VVC(All-Intra 配置):BD-Rate 提升 12.5%
- 相比最先进的端到端学习型图像编解码器:BD-Rate 提升 5.3%
5.4 低码率下的生成式增强
多带扩散(Multi-Band Diffusion, MBD):EnCodec 的 MBD 扩展在极低码率的离散表示上训练扩散模型。
跨模态先验:CMVC 框架利用多模态大语言模型(MLLM)的语义先验来指导视频重建。
六、与传统编码标准的对比
6.1 VVC vs HEVC:基准性能
VVC(Versatile Video Coding,即 H.266)相比 HEVC(H.265)实现了显著的性能提升。
| 测试条件 | PSNR BD-Rate | SSIM BD-Rate | VMAF BD-Rate |
|---|---|---|---|
| AI(All-Intra) | -23.0% ~ -23.9% | - | - |
| RA(Random Access) | -33.1% ~ -36.6% | - | - |
| LD(Low Delay) | -26.7% ~ -29.5% | - | - |
| HD(1280×720) | -31.2% | -33.0% | -35.2% |
| UHD(3840×2160) | -34.4% | -38.0% | -40.4% |
VVC 编码复杂度的增加主要来自:
- 更灵活的块划分(QTMT,128×128 最大 CTU)
- 更多的帧内预测模式(67 种)
- 增强的运动补偿和仿射运动模型
- 四阶段环内滤波(LMCS、DBF、SAO、ALF)
- 多个变换核选择(MTS)
6.2 端到端 AI 编解码器 vs VVC
6.2.1 压缩效率对比
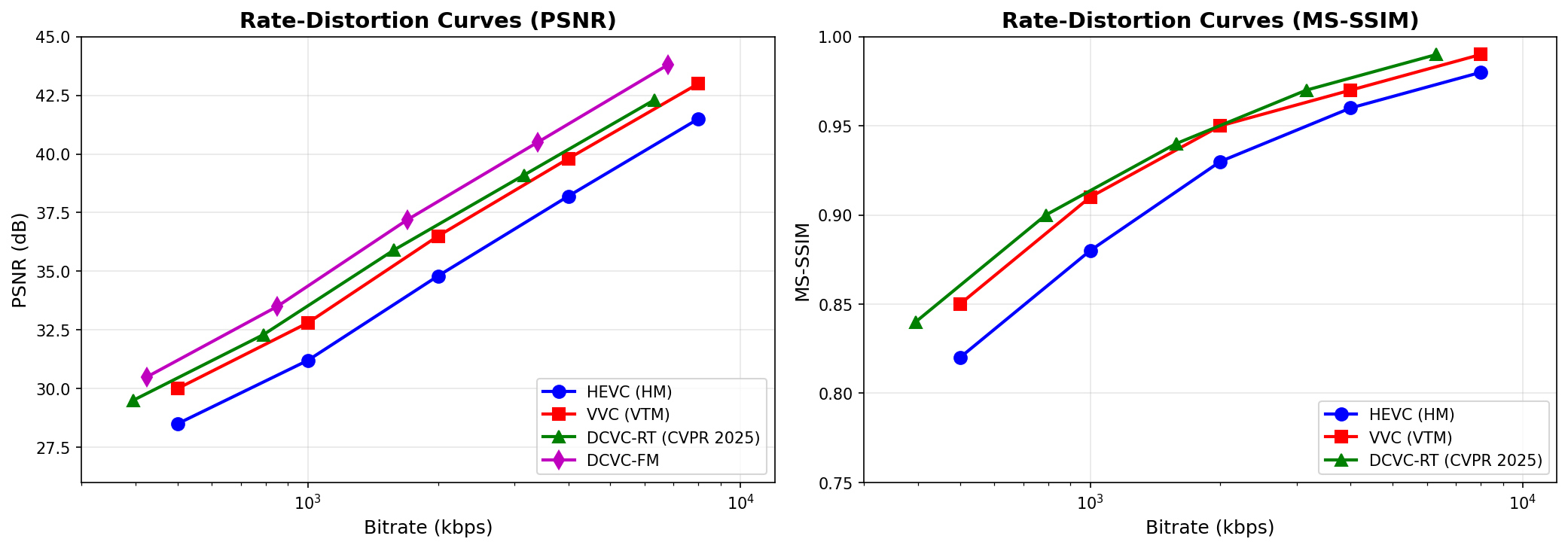
DCVC-RT 与 VVC(VTM-17.0)在 MCL-JCV 和 UVG 测试集上的对比结果:
| 编解码器 | BD-Rate(vs VTM-17.0) | 1080p 编码速度 | 1080p 解码速度 |
|---|---|---|---|
| DCVC-RT | -21%(节省) | 125.2 fps | 112.8 fps |
| DCVC-FM | -34%(节省) | ~5 fps | ~5 fps |
| VTM-17.0 | 0%(基准) | ~1 fps | ~60 fps |
6.2.2 感知质量对比
在极低比特率下,端到端 AI 编解码器通常展现出更好的感知质量:
- GAN/感知优化:通过感知损失训练的编解码器能够生成更自然的纹理
- 生成式增强:在极低比特率下,生成式模型可以"想象"丢失的细节
- 任务驱动评估:在机器视觉任务上,端到端 AI 编解码器的压缩表示通常对下游任务更友好
6.2.3 优劣势总结
端到端 AI 编解码器的优势:
- 端到端优化带来更好的全局 R-D 性能
- 极低比特率下更好的感知质量
- 显著更快的编码速度
- 更灵活的感知优化能力
- 跨模态统一表示的潜力
端到端 AI 编解码器的劣势:
- 解码复杂度通常高于传统编解码器
- 缺乏完善的标准化和生态支持
- 对硬件平台(如 GPU)的依赖
- 在高比特率下相比 VVC 的优势较小
6.2.4 混合编解码方案:NN 增强 VVC
⚠️ 重要补充:IEEE神经视频编码挑战赛专门设立了"神经增强VVC编码器"赛道,探索将神经网络工具与VVC混合编码框架结合的方案。
混合方案的典型技术路径包括:
NN增强环内滤波:用卷积神经网络(CNN)替代VVC的SAO/ALF滤波器,可带来约2%-5%的BD-Rate增益,但需注意解码端复杂度的增加。
NN辅助模式决策:利用深度学习预测CTU的最优划分模式。例如DLIMD可减少36%的模式信令比特,但解码端开销增加~140x,因此仅适用于编码端加速场景。
NN增强运动估计/补偿:使用光流网络替代传统块匹配运动估计,提供亚像素精度的运动场。
混合方案的核心优势在于兼容性——可在不破坏VVC码流格式的前提下提升编码效率,降低部署门槛。
6.3 AI 音频编解码器对比
| 编解码器 | 比特率(kbps) | 质量等级 | 延迟 | 备注 |
|---|---|---|---|---|
| Opus | 6-128 | 高 | ~20ms | 传统混合编码 |
| AAC-LC | 128-320 | 高 | ~20ms | 传统变换编码 |
| EnCodec | 1.5-24 | 高(感知) | ~20ms | 神经音频编解码 |
| DAC | 8-64 | 高 | < 40ms | 神经音频编解码 |
6.4 AI 点云编解码器对比
| 编解码器 | 类型 | BD-Rate 变化(vs G-PCC) | 速度 | 应用场景 |
|---|---|---|---|---|
| OctAttention | 学习型 | -15% ~ -20% | 非实时 | 密集点云 |
| EHEM | 学习型 | -18% ~ -22% | 非实时 | 密集点云 |
| RENO | 学习型实时 | -12.25% | 10 fps | LiDAR 点云 |
| V-PCC | 传统投影 | 基准 | ~30fps | 密集点云 |
| G-PCC | 传统八叉树 | 基准 | ~10fps | LiDAR 点云 |
七、6G场景需求与部署挑战
7.1 全息通信场景
7.1.1 端到端延迟预算
全息通信对端到端时延的要求极为严格(< 1ms),其延迟预算分配如下:
| 环节 | 延迟预算(目标) | 当前技术状态 |
|---|---|---|
| 数据采集 | 0.1 ms | 多传感器融合可达 |
| 预处理/下采样 | 0.1 ms | 需要优化 |
| 编解码 | 0.3 ms | 需要 ~30x 加速(当前DCVC-RT约9ms) |
| 网络传输 | 0.2 ms | 6G 可期 |
| 边缘计算 | 0.1 ms | MEC 成熟 |
| 渲染 | 0.2 ms | 需要优化 |
| 总计 | < 1.0 ms | 挑战巨大 |
⚠️ 重要修正:全息通信编解码的延迟要求为0.3ms,而DCVC-RT实际编解码耗时约9ms。这意味着需要约30倍加速,而非之前估算的10倍。
7.1.2 带宽需求
原始数据:70 英寸全息显示约需 1 Tbps 原始带宽(白皮书综合估算,含多视角光场;单视角像素阵列约 228.6 Gbps)
压缩后:采用高压缩比编解码器可将带宽需求降低到 10-100 Gbps
7.2 XR 场景
| XR 类型 | 分辨率 | 帧率 | MTP 延迟要求 |
|---|---|---|---|
| VR(当前) | 2160×2160/眼 | 90 Hz | < 15 ms |
| VR(目标) | 4K×4K/眼 | 120 Hz | < 10 ms |
| AR(当前) | 720p | 60 Hz | < 20 ms |
| AR(目标) | 1080p+ | 90 Hz | < 10 ms |
7.3 硬件部署挑战
7.3.1 量化技术
- 训练后量化(PTQ):训练好的模型直接量化,可能引入精度损失
- 量化感知训练(QAT):在训练中模拟量化效应,减少精度损失
7.3.2 NPU 适配
- 算子支持:NPU 需要支持编解码器中使用的新型算子(如 GDN、通道级注意力等)
- 内存约束:移动设备的内存带宽和容量受限
- 算子融合:将多个相邻算子融合为单一硬件指令
7.4 标准化进展
- MPEG AI-based PCC:基于 AI 的点云压缩标准(ISO/IEC 23090-24)
- MPAI EEV:端到端优化神经视频编码的标准化方案
- IEEE 神经视频编码挑战赛:推动神经视频编解码技术的标准化进程和工程落地
八、仿真验证
8.1 仿真内容
为验证端到端 AI 编解码器的性能特性,本节基于文献报告的典型数据构建仿真实验。仿真内容包括:
-
R-D 曲线对比:端到端 AI 编解码器 vs VVC vs HEVC
-
编码速度-压缩效率权衡:不同方法的 fps vs BD-Rate 散点图

- 延迟分解图:各模块延迟占比分析
8.2 仿真数据来源
仿真数据来源:DCVC-RT(CVPR 2025)、VVC vs HEVC 对比研究、MPEG 测试条件。
九、讨论与未来方向
9.1 当前技术成熟度评估
成熟度较高的方向:
- 图像压缩(MS-SSIM 指标已超越 BPG)
- 音频压缩(EnCodec 已开源并获广泛应用)
- 离线视频压缩(AI 编解码器在效率-速度权衡上有优势)
成熟度较低的方向:
- 实时视频编解码(DCVC-RT 等刚达实时门槛)
- 端到端点云压缩(实时方案刚出现)
- 标准化和生态建设
9.2 关键技术挑战
- 压缩效率:在高比特率区域,端到端 AI 编解码器尚未全面超越精心调优的传统编码器
- 解码速度:尽管 DCVC-RT 实现了实时编码和解码,但解码复杂度仍是传统编解码器的数倍
- 泛化能力:端到端编解码器对训练数据分布的依赖可能导致对特定内容类型的性能退化
- 错误隐藏:网络传输中丢包或误码会导致重建质量严重下降
9.3 未来研究方向
- 多模态统一编解码:探索图像、视频、音频、点云的统一潜空间表示
- 生成式编解码:在极低比特率下,通过扩散模型补充丢失的信息
- 任务感知编解码:根据下游任务优化编解码策略
- 硬件-算法协同设计:针对特定硬件架构定制编解码器算法
9.4 6G 应用展望
端到端 AI 编解码器有望在 6G 时代发挥重要作用:
- 全息通信:配合 6G 的 Tbps 峰值速率和亚毫秒延迟,实现实时的全息视频传输
- 沉浸式 XR:AI 编解码器的感知优化能力可为 XR 用户提供更优质的视觉体验
- 边缘 AI:轻量级编解码器可在边缘设备上本地运行
- 车联网:RENO 等实时点云编解码器可支持自动驾驶场景
十、结论
本文系统分析了端到端 AI 编解码器的技术原理、统一框架设计与低延迟高压缩效率实现路径,主要结论如下:
(1)技术原理:端到端 AI 编解码器以变分自编码器为基本框架,通过超先验模型捕获潜在表示的空间相关性、通过自回归或并行熵模型实现高效压缩。
(2)统一框架:跨模态统一编解码框架通过共享骨干网络、统一潜空间表示和模态特定量化策略实现图像、视频、音频和点云的联合压缩。
(3)低延迟实现:DCVC-RT(CVPR 2025)揭示了操作复杂度(而非计算复杂度)是神经编解码器速度的主要瓶颈,并通过隐式时间建模、单尺度潜在表示、并行编码等技术实现了 1080p@125fps 的实时编解码。
(4)性能对比:最先进的端到端 AI 视频编解码器已能在压缩效率上与 VVC 相当(BD-Rate 节省 21%),同时实现约 100 倍的编码速度提升。
(5)6G 部署:端到端 AI 编解码器在 6G 沉浸式通信场景具有广阔的应用前景,但面临量化部署、标准化和生态系统构建等挑战。
参考文献
标准文献
- ITU-T Rec. H.266 | ISO/IEC 23090-3:2020, “Versatile Video Coding,” 2020.
- ITU-T Rec. H.265 | ISO/IEC 23008-2:2020, “High Efficiency Video Coding,” 2020.
- ISO/IEC 23090-24, “Information technology - Coded representation of immersive media - Part 24: AI-based point cloud coding,” Under development.
- MPEG-5 Essential Video Coding (EVC), ISO/IEC 23094-1, 2020.
- MPAI-EEV (End-to-End Video Coding), Moving Picture, Audio and Data Coding by Artificial Intelligence, 2023.
学术论文
- Ballé, J., Minnen, D., Singh, S., Hwang, S.J., Johnston, N. “Variational image compression with a scale hyperprior.” ICLR 2018.
- Minnen, D., Ballé, J., Toderici, G. “Joint autoregressive and hierarchical priors for learned image compression.” NeurIPS 2018.
- Cheng, Z., Sun, H., Kwan, C., Lee, J. “Channel-wise autoregressive entropy models for learned image compression.” ICIP 2020.
- Jia, Z., Li, B., Li, J., et al. “DCVC-RT: Tow阿ards Practical Real-Time Neural Video Compression.” CVPR 2025.
- Liu, J., et al. “UI2C: Unified Intra and Inter Coding for Real-Time Neural Video Compression.” arXiv 2025.
- Défossez, A., Copet, J., Synnaeve, G., Adi, Y. “High Fidelity Neural Audio Compression.” arXiv 2022.
- You, K., Chen, T., Ding, D., Asif, M.S., Ma, Z. “RENO: Real-Time Neural Compression for 3D LiDAR Point Clouds.” CVPR 2025.
- Huang, L., et al. “Diffusion-prompted Unified Codec for Colored Point Clouds.” arXiv 2025.
- Sun, Y., et al. “CoDiCodec: Unifying Continuous and Discrete Compressed Representations of Audio.” arXiv 2025.
- Mercat, A., et al. “Comparative Rate-Distortion-Complexity Analysis of VVC and HEVC Video Codecs.” IEEE Access 2022.
技术报告与白皮书
- 中国移动研究院, “6G全息通信业务发展趋势白皮书,” 2024.
- IEEE ISCAS, “Fifth Grand Challenge on Neural Network-based Video Coding,” 2026.
附录 A:术语表
| 缩写 | 全称 | 中文 |
|---|---|---|
| VAE | Variational Autoencoder | 变分自编码器 |
| NVC | Neural Video Codec | 神经视频编解码器 |
| E2E | End-to-End | 端到端 |
| R-D | Rate-Distortion | 率失真 |
| BD-Rate | Bjøntegaard Delta Rate | Bjøntegaard 比特率变化 |
| PSNR | Peak Signal-to-Noise Ratio | 峰值信噪比 |
| MS-SSIM | Multi-Scale Structural Similarity | 多尺度结构相似性 |
| VVC | Versatile Video Coding | 多功能视频编码(H.266) |
| HEVC | High Efficiency Video Coding | 高效视频编码(H.265) |
| Hyperprior | Scale Hyperprior | 尺度超先验 |
| RVQ | Residual Vector Quantization | 残差向量量化 |
| FSQ | Finite Scalar Quantization | 有限标量量化 |
| MTP | Motion-to-Photon | 运动到光子 |
| XR | Extended Reality | 扩展现实 |
| NPU | Neural Processing Unit | 神经网络处理单元 |
本文档为微信公众号"通信哲匠"和CSDN账户“通信深潜DeepComm”6G关键技术系列研究的一部分,版权所有,引用请注明出处。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)