LangChain03
1、模型
# 加载环境变量 from dotenv import load_dotenv load_dotenv()一定不要忘加载
1、1初始化模型
1、1、1自动推断---------根据模型名称自动推断模型、仅限于LangChain支持的模型
# 导入Langchain的初始化模型的函数
from langchain.chat_models import init_chat_model
# 调用init_chat_model函数初始化模型
# 参数model用来指定模型名称,Langchain会根据模型名字自动设定base_url,并从环境变量中获取api_key
model = init_chat_model(model="deepseek-chat")1、1、2手动配置推断--------使用的是openai实际上是 openai调用的底层ai
# 我们收到加载环境变量中的base_url和api_key
import os
base_url = os.getenv("DASHSCOPE_BASE_URL")
api_key = os.getenv("DASHSCOPE_API_KEY")
model = init_chat_model(
model="qwen-max", # 模型名称,这里可以自定义,我们用的是阿里的qwen-max
model_provider="openai", # 如果是Langchain不支持的模型,需要指定模型提供者(虽然我们用的是阿里,但是阿里兼容openai,所以这里用openai)
base_url=base_url,
api_key=api_key
)1、1、3当openai不兼容时使用model类
from langchain_community.chat_models.tongyi import ChatTongyi
# 使用Model类初始化模型
model = ChatTongyi(
model="qwen-max"
# 其它模型参数...
)1、2调用模型
1、2、1、invoke---模型全部生成才返回
# 通过invoke函数访问模型,需要阻塞等待模型生成结果
response = model.invoke("你是谁?")
# 调用invoke函数,传入消息数组
response = model.invoke([
{"role": "system", "content": "你扮演火箭队的武藏,以武藏的性格口吻回答用户的问题。"},
{"role": "user", "content": "你是谁?"}
])1、2、2、stream
invoke阻塞式调用需要等待较长时间才能看到AI返回的结果,而stream则是流式调用,可以实时看到AI返回的一个个词。
# 通过.stream函数实现流式访问
stream = model.stream("你是谁?")1、2、3、在智能体中使用模型
I创建智能体
from langchain.agents import create_agent
# 1.使用初始化好的model创建Agent
agent = create_agent(model=model)# 2.指定Model名称,由LangChain自动初始化模型
agent = create_agent(model="deepseek-chat")II调用智能体
response = agent.invoke({
"messages": [{"role": "user", "content": "你是谁?"}]
})
# 通过stream函数实现流式访问
messages = agent.stream(
{"messages": [{"role": "user", "content": "你是谁?"}]},
stream_mode="messages"
)2、消息Message
在LangChain中,发送给LLM的消息、LLM返回的消息都统一被封装为BaseMessage,它是Agent中基本的上下文单元。
在LangChain中,我们并不需要自己创建BaseMessage对象,LangChain已经把常见消息根据角色(Role)创建了对应的BaseMessage的子类:
- SystemMessage:role是system,代表系统消息,用于设定模型角色和交互背景
- HumanMessage:role是user,代表用户输入的消息
- AIMessage:role是assistant,代表LLM生成的响应,包含:文本、工具调用、元数据
- ToolMessage:role是tool,代表工具调用时产生的结果
我们可以直接使用这些Messages类型来发送消息。
from langchain.agents import create_agent
from langchain.tools import tool
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
# 定义工具
@tool
def get_weather(location: str) -> str:
"""
Get the weather in a given location.
Args:
location: city name or coordinates
"""
return f"Current weather in {location} is sunny"
# 创建Agent
agent = create_agent(model="deepseek-chat", tools=[get_weather])
# 调用Agent,发送消息
response = agent.invoke({
"messages": [
SystemMessage("请使用工具来获取天气信息。"),
HumanMessage("你好,我是龙哥."),
AIMessage("你好,虎哥,很高兴认识你."),
HumanMessage("北京今天天气如何?")
]
})
print(response)
{'messages': [SystemMessage(content='请使用工具来获取天气信息。', additional_kwargs={}, response_metadata={}, id='e377ae65-f552-4730-8f75-12baa71a1600'), HumanMessage(content='你好,我是龙哥.', additional_kwargs={}, response_metadata={}, id='a1ddfca6-f369-4e00-a1a6-42300e206f6e'), AIMessage(content='你好,虎哥,很高兴认识你.', additional_kwargs={}, response_metadata={}, id='dde71568-a66f-40e8-be29-8dab9b8b2443', tool_calls=[], invalid_tool_calls=[]), HumanMessage(content='北京今天天气如何?', additional_kwargs={}, response_metadata={}, id='5171a6a3-b4e2-4222-a6e6-3e898b82c502'), AIMessage(content='好的,我来查一下北京今天的天气情况。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 53, 'prompt_tokens': 316, 'total_tokens': 369, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 256}, 'prompt_cache_hit_tokens': 256, 'prompt_cache_miss_tokens': 60}, 'model_provider': 'deepseek', 'model_name': 'deepseek-v4-flash', 'system_fingerprint': 'fp_8b330d02d0_prod0820_fp8_kvcache_20260402', 'id': '80d1a543-c772-43f0-bac1-18e4d6e7c8a5', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--019e2cb6-7827-7281-ba10-e8d47f119330-0', tool_calls=[{'name': 'get_weather', 'args': {'location': '北京'}, 'id': 'call_00_ihW86R8C59zw5gJqhYgb6852', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 316, 'output_tokens': 53, 'total_tokens': 369, 'input_token_details': {'cache_read': 256}, 'output_token_details': {}}), ToolMessage(content='Current weather in 北京 is sunny', name='get_weather', id='c62c7730-3bfb-4d1a-b635-40ab59b4943a', tool_call_id='call_00_ihW86R8C59zw5gJqhYgb6852'), AIMessage(content='虎哥,北京今天天气是**晴天**☀️,阳光明媚,是个好天气!适合出去走走逛逛。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 26, 'prompt_tokens': 388, 'total_tokens': 414, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 256}, 'prompt_cache_hit_tokens': 256, 'prompt_cache_miss_tokens': 132}, 'model_provider': 'deepseek', 'model_name': 'deepseek-v4-flash', 'system_fingerprint': 'fp_8b330d02d0_prod0820_fp8_kvcache_20260402', 'id': '8859d88d-0eb9-4761-9447-a219f35c392d', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--019e2cb6-7c53-7393-8331-9139de391b8e-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 388, 'output_tokens': 26, 'total_tokens': 414, 'input_token_details': {'cache_read': 256}, 'output_token_details': {}})]}
for message in response['messages']:
message.pretty_print()
================================ System Message ================================
请使用工具来获取天气信息。
================================ Human Message =================================
你好,我是龙哥.
================================== Ai Message ==================================
你好,虎哥,很高兴认识你.
================================ Human Message =================================
北京今天天气如何?
================================== Ai Message ==================================
好的,我来查一下北京今天的天气情况。
Tool Calls:
get_weather (call_00_ihW86R8C59zw5gJqhYgb6852)
Call ID: call_00_ihW86R8C59zw5gJqhYgb6852
Args:
location: 北京
================================= Tool Message =================================
Name: get_weather
Current weather in 北京 is sunny
================================== Ai Message ==================================
2、1、多模态消息
2、1、1线上图片
from langchain.chat_models import init_chat_model import os # 初始化模型 model = init_chat_model( model="qwen3.5-plus", # 模型名称,这里选择qwen3.5-plus,这是一个多模态模型,支持图片、文本、音频、视频 model_provider="openai", base_url=os.getenv("DASHSCOPE_BASE_URL"), api_key=os.getenv("DASHSCOPE_API_KEY") )# 创建Agent agent = create_agent(model=model) # 准备多模态消息 message = HumanMessage([ {"type": "text", "text": "描述以下这张图片的内容."}, {"type": "image", "url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"}, ]) stream = agent.stream( {"messages": [message]}, stream_mode="messages" ) for chunk, metadata in stream: if chunk.content: ---这句话是判断是否有值 print(chunk.content, end="", flush=True) ====================================================================================== 这张图片捕捉了一个非常温馨、治愈的瞬间,主要包含以下内容: **1. 主体人物与动作:** * **一位年轻女性**:她侧身坐在沙滩上,留着长发,身穿黑白格纹的衬衫和深色长裤(裤脚卷起)。她脸上洋溢着开心的笑容,正伸出右手。 * **一只金色的狗**(看起来像拉布拉多或金毛寻回犬):它乖巧地坐在女子对面,身上戴着带有彩色图案的胸背带。它抬起一只前爪,正在与女子进行“击掌”(High-five)或者握手的互动。 * **互动**:两者的动作非常同步,展现了人与宠物之间亲密无间的默契和快乐。 **2. 环境与背景:** * **地点**:显然是在海边沙滩上。前景是细腻的沙子,上面有一些脚印。 * **大海**:背景是平静的大海,可以看到白色的浪花正在轻轻拍打着海岸。 * **光线**:阳光从画面右侧照射过来(可能是日落或日出时的“黄金时刻”),光线非常柔和且温暖。这束光给女子的头发和侧脸,以及狗狗的背部都镀上了一层金色的轮廓光,营造出一种梦幻、宁静的氛围。 **3. 细节:** * 狗的红色牵引绳随意地散落在沙地上,说明他们正在放松地玩耍。 * 女子的手腕上戴着一只白色的手表或手环。 总的来说,这是一张展现人与动物和谐相处、享受海边美好时光的照片。
2、1、2本地图片
首先先添加上传图片的工具
from ipywidgets import FileUpload from IPython.display import display uploader = FileUpload(accept='*', multiple=False) display(uploader)LangChain规定必须是base64格式
# 读取图片,转为base64字符串 import base64 # 获取第一个(也是唯一一个)上传的文件 uploaded_file = uploader.value[0] # 获取其内存视图 content_mv = uploaded_file["content"] # 转换内存视图->字节 img_bytes = bytes(content_mv) # or content_mv.tobytes() # base64编码 img_b64 = base64.b64encode(img_bytes).decode("utf-8")# 组织多模态消息 multimodal_question = HumanMessage(content=[ { "type": "image", "base64": img_b64, "mime_type": "image/jpeg", }, {"type": "text", "text": "给我讲讲图片中的颜色"} ]) for chunk, metadata in agent.stream( {"messages": [multimodal_question]}, stream_mode="messages" ): print(chunk.content, end="", flush=True) 我们可以从上到下把颜色拆解来看: 1. **顶部(亮部):** * 最上方是**极淡的米白色**或**奶油色**,带有一点点暖黄色的倾向。这看起来像是阳光照射下来的感觉,或者是天空的高光部分。 2. **中上部(过渡区):** * 颜色开始慢慢变成**淡黄绿色**和**薄荷绿**。这些颜色非常柔和、透亮,给人一种轻盈、透气的感觉。 3. **中部(主体区):** * 这里进入了明显的**青绿色(Teal)**和**翡翠绿**区域。这是图片的主色调,既有绿色的生机,又有蓝色的冷静。这种颜色通常让人联想到清澈的浅海湖水。 4. **底部(暗部):** * 颜色逐渐加深,变成了**深蓝绿色**、**孔雀蓝**,最底部甚至接近**深海军蓝**或**午夜蓝**。这部分提供了视觉上的重量感,让画面显得稳重。 **总结来说:** 这张图使用了一个**垂直的色彩渐变**,从顶部的“光”过渡到底部的“深海”。这种配色方案(Analogous colors,类似色搭配)非常经典,常用于科技背景、网页设计或作为让人放松的壁纸,因为它模拟了自然界中从天空到海洋或森林的层次感。
3、提示词
提示词(Prompts)
发送给大模型的所有消息都可以称为**提示词(Prompt)**,它直接影响模型的输出结果。
系统提示词
在所有发送给LLM的消息中,System Message最为重要,它设定了模型的角色和聊天的背景。会影响到后续所有的对话。我们将其称之为**系统提示词(System Prompt)**。在创建智能体时,就可以直接指定系统提示词。
from langchain.agents import create_agent from langchain.messages import HumanMessage # 创建智能体 agent = create_agent( model = "deepseek-chat", system_prompt="你以海盗的口吻来回答用户问题。"----------系统提示词 ) # 调用智能体 for token, metadata in agent.stream( {"messages": [HumanMessage(content="你是谁?")]}, stream_mode="messages" ): print(token.content, end="", flush=True)系统提示词(System Prompt)
会包含以下几个部分
- **身份角色(Identity)**:描述AI的职责、沟通风格和总体目标。
- **指令说明(Instructions)**:请指导模型如何生成所需的响应。它应该遵循哪些规则?模型应该做什么,以及模型绝对不能做什么?
- **对话示例(Examples)**:提供可能的输入示例,以及模型期望的输出。
- **背景信息(Context)**:向模型提供生成响应所需的任何额外信息,例如RAG的额外知识库数据,或您认为特别相关的任何其他数据。system_prompt = """ # 身份 - 你是一个编程助手,你帮助用户编写Python代码。 # 指令 - 定义变量时,使用snake case命名法,而不是camel case命名法。 ---用下划线而不是驼峰 - 不要返回markdown格式说明,仅仅返回代码即可。 ---更简洁节省token """ # 创建智能体 agent = create_agent( model = "deepseek-chat", system_prompt=system_prompt ) for token, metadata in agent.stream( {"messages": [HumanMessage(content="怎样定义string变量记录学校名字,例如`黑马程序员`")]}, stream_mode="messages" ): print(token.content, end="", flush=True)省钱技巧---对系统提示词更加详细
对话示例(Few-Shot examples)
Few-shot示例是一种为模型提供多个示例的方法,以便它可以学习行为模式并生成更准确的响应。
system_prompt = """ # 身份 - 你是一个科幻作家,根据用户的要求创建一个太空之都。 # 示例 user:月球的首都是什么? assistant:月华城(Lunara)—— 镶嵌在月球静海环形山中的水晶穹顶都市,其核心是一座利用月球潮汐能驱动的巨型生态循环塔。 user:火星的首都是什么? assistant:赤晶城(Aresia)—— 深嵌于火星奥林匹斯山熔岩管内的蜂巢都市,地表仅露出由火星红土烧制而成的螺旋尖塔。 """ # 创建智能体 agent = create_agent( model = "deepseek-chat", system_prompt=system_prompt ) for token, metadata in agent.stream( {"messages": [HumanMessage(content="金星的首都是什么?")]}, stream_mode="messages" ): print(token.content, end="", flush=True) --------------------------------------------------------------------------------------- **云冕城(Aphrodia)**——悬浮于金星硫酸云层上空的浮岛集群都市,由反重力引擎与太阳帆阵列共同维持,其核心是一座能将大气二氧化碳转化为钻石穹顶的巨型催化塔。结构化输出----基于提示词的结构化输出----自定义
模型擅长自然语言交流和非结构化数据识别,但是传统程序识别结构化的数据会更加方便。所以有时候我们希望模型也能输出固定结构的内容,方便我们解析。这可以通过系统提示词来实现,我们可以在提示词中指定模型的输出格式,从而使模型的输出更易于解析和使用。
system_prompt = """ # 身份 - 你是一个科幻作家,根据用户的要求创建一个太空之都。 # 指令 - 请务必以JSON格式输出,不要加任何markdown样式。 # 示例: user: 月球的首都是什么? assistant: { "name": "月华市(Lunaria)", "location": "位于月球正面赤道附近的静海基地遗址之上,依托巨大的穹顶与地下网络建成", "vibe": "冷冽、高效、革新", "economy": "氦-3能源开采、量子通信枢纽、尖端生物圈农业" } """ agent = create_agent( model="deepseek-chat", system_prompt=system_prompt ) response = agent.invoke( {"messages": [HumanMessage(content="金星的首都是什么?")]}, ) print(response['messages'][-1].content) --------------------------------------------------------------------------------------- { "name": "硫磺城(Sulfura)", "location": "悬浮于金星浓厚大气层中距地表约50公里的高空,由巨大的反重力浮空平台群构成", "vibe": "高压、炽热、坚韧", "economy": "大气资源提炼(二氧化碳、硫酸)、极端环境材料制造、太阳能巨型阵列" }基于Model的结构化输出---LangChain简化版
在LangChain中,实现结构化输出会更加简单。我们无需自己在提示词中添加描述实现结构化输出,而仅仅是两步即可:
1- 定义一个数据类型(基于pydantic)from pydantic import BaseModel # 首先,我们定义一个类,用来封装模型要输出的数据: class CapitalInfo(BaseModel): name: str location: str vibe: str economy: str
2- 创建智能体,设置输出格式
# 我们可以创建智能体时设置结构化输出的格式,LangChain会自动帮我们完成提示词改造和响应结果解析。 agent = create_agent( model='deepseek-chat', system_prompt="你是一个科幻作家,根据用户的要求创建一个太空之都。", response_format=CapitalInfo # 设置结构化输出的格式 ) response = agent.invoke( {"messages": [HumanMessage(content="月球的首都是什么?")]} ) # 输出结果 print(response) ----------------------------------------------------------------------------------------- {'messages': [HumanMessage(content='月球的首都是什么?', additional_kwargs={}, response_metadata={}, id='bdc4c411-a8d5-4351-939a-d6f6e5689a54'), AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 134, 'prompt_tokens': 355, 'total_tokens': 489, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 320}, 'prompt_cache_hit_tokens': 320, 'prompt_cache_miss_tokens': 35}, 'model_provider': 'deepseek', 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_eaab8d114b_prod0820_fp8_kvcache_new_kvcache', 'id': '668ea94a-cfd7-4547-8039-f82b22edf755', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--019d230e-e690-7652-ad8b-87703c39fbb5-0', tool_calls=[{'name': 'CapitalInfo', 'args': {'name': '月宫', 'location': '月球南极-艾特肯盆地边缘', 'vibe': '未来主义与古典东方美学融合,低重力环境下的优雅建筑,透明穹顶下的花园城市', 'economy': '氦-3开采与精炼、月球旅游、零重力制造、科学研究、稀有金属贸易'}, 'id': 'call_00_i68mFAfCzaCGVA8POKixhIxO', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 355, 'output_tokens': 134, 'total_tokens': 489, 'input_token_details': {'cache_read': 320}, 'output_token_details': {}}), ToolMessage(content="Returning structured response: name='月宫' location='月球南极-艾特肯盆地边缘' vibe='未来主义与古典东方美学融合,低重力环境下的优雅建筑,透明穹顶下的花园城市' economy='氦-3开采与精炼、月球旅游、零重力制造、科学研究、稀有金属贸易'", name='CapitalInfo', id='00a81454-bed9-487f-b49f-6296c21923b1', tool_call_id='call_00_i68mFAfCzaCGVA8POKixhIxO')], 'structured_response': CapitalInfo(name='月宫', location='月球南极-艾特肯盆地边缘', vibe='未来主义与古典东方美学融合,低重力环境下的优雅建筑,透明穹顶下的花园城市', economy='氦-3开采与精炼、月球旅游、零重力制造、科学研究、稀有金属贸易')}city = response['structured_response']----返回值中会有这个结构化的变量对它处理 printf -------------------------------------------------------- CapitalInfo(name='月宫', location='月球南极-艾特肯盆地边缘', vibe='未来主义与古典东方美学融合,低重力环境下的优雅建筑,透明穹顶下的花园城市', economy='氦-3开采与精炼、月球旅游、零重力制造、科学研究、稀有金属贸易')print(f"{city.name}位于{city.location},是一座{city.vibe}的城市,其主要产业包括{city.economy}。") ----------------------------------------------------------------------------------------- 月宫位于月球南极-艾特肯盆地边缘,是一座未来主义与古典东方美学融合,低重力环境下的优雅建筑,透明穹顶下的花园城市的城市,其主要产业包括氦-3开采与精炼、月球旅游、零重力制造、科学研究、稀有金属贸易。
4、工具
一个完整的Agent至少要包含两个关键的部分:
- **模型**:是Agent的大脑,负责推理、分析,规划任务步骤
- **工具**:是Agent的手脚,负责执行任务,与外界交互
因此,定义带有工具的Agent的基本流程如下:
- 定义工具
- 初始化模型
- 初始化Agent,绑定模型和工具
1.自定义工具
所谓的**工具(Tool)**,本质就是一个可调用的**函数**,但是这个函数不是我们自己去调用,而是给模型调用。因此除了定义函数外,我们还需要清晰描述这个工具,让模型知道这个工具如何使用。包括下列信息:
- 工具名
- 工具的作用
- 工具需要的参数
1---基于tool描述工具
在LangChain中,定义工具需要用到@tool装饰器,我们可以通过装饰器来定义工具名、工具的作用:
from langchain_core.tools import tool
@tool("square_root", description="Calculate the square root of a number")
def tool1(x: float) -> float:
return x ** 0.5.2----使用函数名和文档注释描述工具---推荐
如果不@tool装饰器没有定义工具名和作用描述,此时:
- 工具名:默认就是函数名
- 工具所需的参数:默认就是函数的参数列表
- 工具作用的描述:默认就是函数的文档注释
from langchain_core.tools import tool
# 通过tool装饰器定义工具
@tool
def square_root(x: float) -> float:
"""Calculate the square root of a number"""
return x ** 0.5# 定义一个查询天气的tool
@tool
def get_weather(location: str, units: str = "celsius", include_forecast: bool = False) -> str:
"""
Get current weather and optional forecast.
Args:
location: city name or coordinates
units: unit of degrees
include_forecast: does it include the weather forecast
"""
temp = 22 if units == "celsius" else 72
result = f"Current weather in {location}: {temp} degrees {units[0].upper()}"
if include_forecast:
result += "\nNext 5 days: Sunny"
return result3----定义Pydantic Model描述参数---参数复杂时
如果函数的参数比较多,而且比较复杂,此时建议通过pydantic model来描述参数列表。
# 通过自定义model来约束入参
from pydantic import BaseModel, Field
from typing import Literal
# 例如一个查询天气的tool
class WeatherInput(BaseModel):
"""查询天气的输入参数."""
location: str = Field(description="City name or coordinates")
units: Literal["celsius", "fahrenheit"] ---枚举
= Field(
default="celsius",
description="Temperature unit preference, default is celsius."
)
include_forecast: bool = Field(
default=False,
description="Include 5-day forecast"
)
# 定义一个查询天气的tool
@tool(args_schema=WeatherInput)
def get_weather(location: str, units: str = "celsius", include_forecast: bool = False) -> str:
"""Get current weather and optional forecast."""
temp = 22 if units == "celsius" else 72
result = f"Current weather in {location}: {temp} degrees {units[0].upper()}"
if include_forecast:
result += "\nNext 5 days: Sunny"
return result
from langchain.agents import create_agent
from langchain.messages import HumanMessage
agent = create_agent(
model="deepseek-chat",
tools=[square_root, get_weather],
system_prompt="你可以使用工具回答用户问题,调用工具时尽量使用默认参数,除非用户特别指定。"
)
for token, metadata in agent.stream(
{"messages": [HumanMessage(content="杭州接下来几天天气如何?")]},
stream_mode="messages"
):
print(token.content, end="", flush=True)
----------------------------------------------------------------------------------------
我来帮您查询杭州接下来几天的天气情况。Current weather in 杭州: 22 degrees C
Next 5 days: Sunny根据查询结果,杭州当前的天气是22摄氏度。接下来5天的天气预报显示都是晴天。
看起来天气情况很不错,接下来几天杭州都会是晴朗的天气,温度适宜。建议您可以安排一些户外活动,但也要注意防晒哦!
========================================================================================
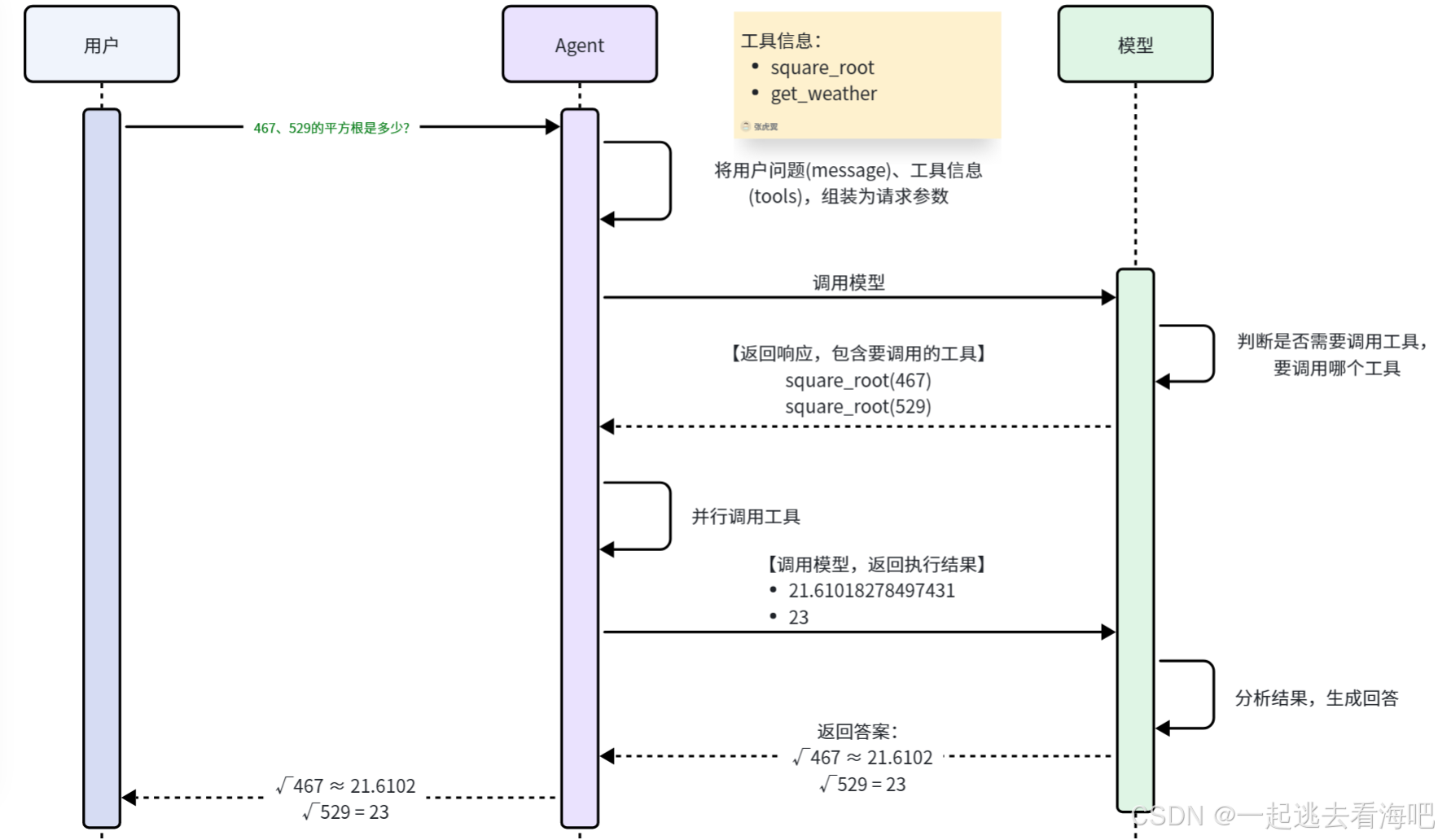
response = agent.invoke(
{"messages": [HumanMessage(content="467和529的平方根是多少?")]},
)
for message in response['messages']:
print(message.pretty_print())
----------------------------------------------------------------------------------------
================================ Human Message =================================
467和529的平方根是多少?
None
================================== Ai Message ==================================
我来帮你计算467和529的平方根。
Tool Calls:
square_root (call_00_aQ0QNpiJNd4qKupaSlDGchGM)
Call ID: call_00_aQ0QNpiJNd4qKupaSlDGchGM
Args:
x: 467
None
================================= Tool Message =================================
Name: square_root
21.61018278497431
None
================================== Ai Message ==================================
Tool Calls:
square_root (call_00_PprajYbdstDClKsLlloiFr0j)
Call ID: call_00_PprajYbdstDClKsLlloiFr0j
Args:
x: 529
None
================================= Tool Message =================================
Name: square_root
23.0
None
================================== Ai Message ==================================
计算结果如下:
- **467的平方根** ≈ 21.6102
- **529的平方根** = 23.0(因为529是23的平方,所以结果是精确的整数)
529是一个完全平方数(23² = 529),所以它的平方根是精确的23。5、记忆

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)