大模型|大模型的简单认知
🌞欢迎来到人工智能的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
📆首发时间:🌹2026年5月16日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!

大模型的认知
LLM是什么
大模型全称为大语言模型,英文为 Large Language Model,缩写 LLM。它是一类基于机器学习与
自然语言处理技术构建的深度模型,通过学习海量文本数据,习得人类语言的语义理解、上下文推
理及文本生成能力,能够完成问答、对话、文本创作、指令遵循等任务。
Chat GPT是对话的产品(就是我们在网上看到的内容),里面的模型使用的GPT-3.5。(相当于里
面的发动机)。
| 国家 | 对话产品 | 大模型 | 链接 |
| 美国 | OpenAI ChatGPT | GPT-3.5、GPT-4 | https://chat.openai.com/ |
| 美国 | Microsoft Copilot | GPT-4 和未知 | https://copilot.microsoft.com/ |
| 美国 | Google Bard | PaLM 和 Gemini | https://bard.google.com/ |
| 中国 | 百度文心一言 | 文心 | https://yiyan.baidu.com/ |
| 中国 | 讯飞星火 | 星火 | https://xinghuo.xfyun.cn/ |
| 中国 | 智谱清言 | ChatGLM | https://chatglm.cn/ |
| 中国 | 月之暗面 Kimi Chat | Moonshot | https://kimi.moonshot.cn/ |
| 中国 | MiniMax 星野 | abab | https://www.xingyeai.com/ |
常见大模型的版本区分
| 标签 / 术语 | 含义解释 |
| 通义千问2.5 | 这是通义千问第2.5代通用模型 |
| 版本编号 (如0314、2025-03-05) | 这些数字通常代表模型的发布或修订日期。 |
| 72B | 指大模型的内部参数量,比如还有DeepSeek满血版DeepSeek-671B,1个B为10亿。 |
| 1M (含32k等) | 这个标签通常指的是模型处理文本时的最大token数(或“上下文窗口”大小)。32k意味着模型能够在一个实例中处理最多32,000个token。这对于处理长文本特别有用。 |
| Turbo | 这可能指的是模型的一个优化版本,旨在提高速度和效率,可能在保持生成质量的同时减少了资源消耗。 |
| Preview | 这通常意味着该模型是供早期访问、测试或预览的版本。它可能不是最终的商业版本,但提供了对即将发布功能的早期查看。 |
| 带V字 | 这意味着模型被设计或优化以处理视觉数据,比如图像或视频 |
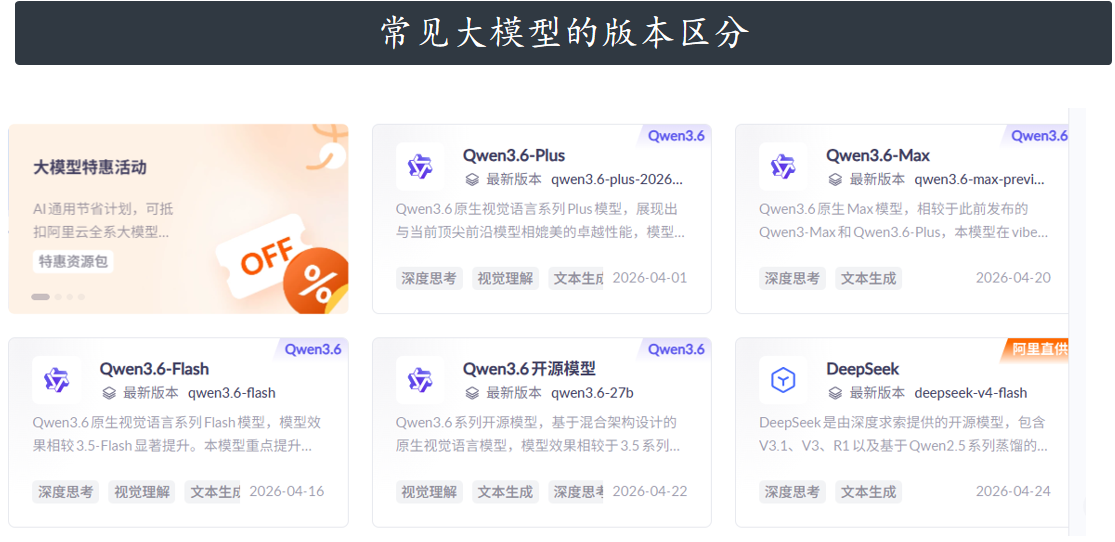
ChatGPT的技术原理
大模型的训练整体上分为三个阶段:预训练、SFT(监督微调)、基于人类反馈的强化学习
(RLHF)
预训练 (Pre-training)
模型像海绵一样阅读互联网上的海量文章,学习语言规律和世界常识。
监督微调 (SFT)
人类给它示范标准的“一问一答”,手把手教它怎么理解指令、怎么回答问题。
强化学习 (RLHF)
人类做裁判给它的回答打分,它根据分数不断调整,揣摩人类喜好。
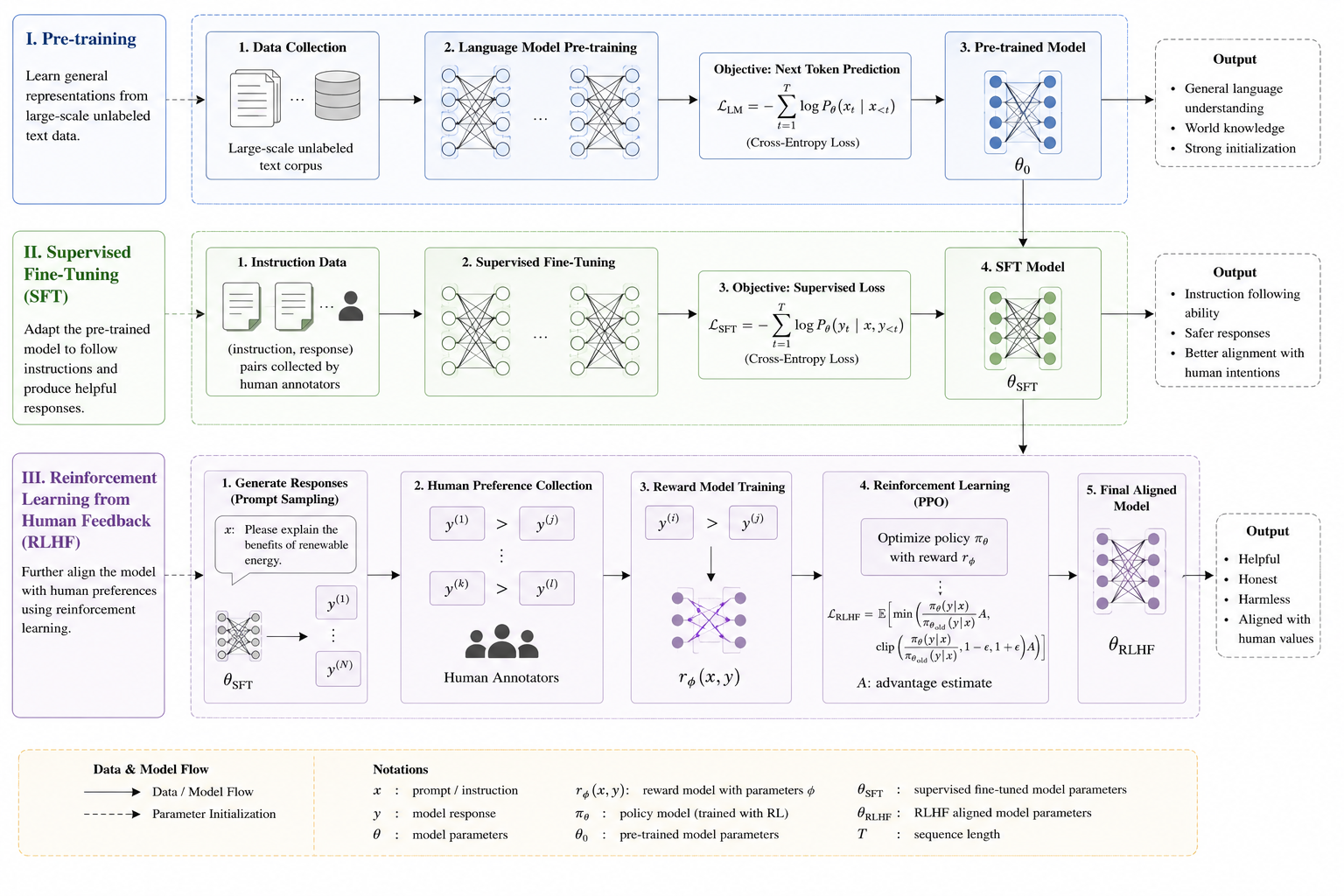
Token是什么?
Token 是大语言模型(LLM)处理和理解人类语言的“最小基本单位”。
英文单词: 常见的短单词通常就是 1 个 Token(比如 apple, run)。
较长或罕见的单词可能会被切碎成几个 Token(比如 hamburger 可能会被切成 ham、bur、ger
三块)。在英文中,大约 1 个 Token 约等于 0.75 个单词(或者说 100 个 Token 约等于 75 个英文
单词)。
中文字符:在早期的模型中,一个汉字往往对应 1 个甚至多个 Token(因为汉字编码复杂)。
现在的中文大模型经过优化,常用的词组(如“苹果”、“中国”)可能会被打包算作 1 个 Token,但
很多时候一个汉字依然算作 0.5 到 1 个 Token。在中文里,通常 1 个 Token 约等于 0.5 到 1 个汉
字。
标点符号和空格: 它们也算 Token!
大模型为啥叫做大模型?
参数极大(算力底座):参数量十亿起步(如 GPT-3 的1750亿,GPT-4 的1.8万亿),赋予了模
型强大的学习与记忆能力。
数据海量(知识来源):依赖海量的文本、图像、音频等多模态数据进行训练,是模型掌握知识的
基础。
应用高效(赋能生产):AIGC 技术已深入传媒等行业的“采、编、播”全流程,大幅提升了内容生
产的效率、质量与影响力。
简单的大模型应用开发
基本步骤
注册平台用户:前往对应大模型服务平台,完成账号注册与实名认证。
开通大模型调用权限:在个人控制台申请开通大模型 API 调用功能,阅读并同意服务协议。
获取身份凭证 API‑Key:进入密钥管理页面,创建并复制专属 API Key,用于接口身份校验。
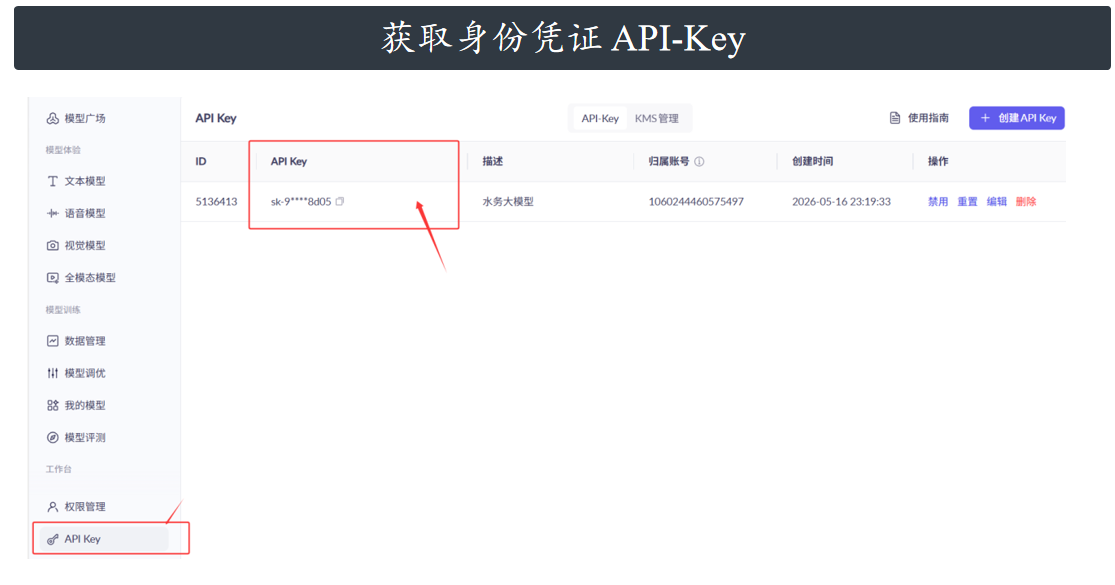
代码调用实现功能:基于 Python 等编程语言,编写调用代码,传入 API‑Key、提示词等参数,向
接口发送请求,接收并解析模型返回结果,实现问答、文本生成等业务功能。
大模型服务平台百炼控制台(使用教程)
配置API Key到环境变量
| 做法 | 做法比喻 | 缺点/优点 |
| 写死在代码里 (Hardcoding) | 把银行卡密码写在银行卡背面 | 极易泄漏;切换环境需改代码;团队协作麻烦。 |
| 配置到环境变量 (Environment Variables) | 密码记在脑子里或存入密码管理器 | 安全(代码中无敏感信息);灵活(一套代码随处运行);专业。 |
在 Linux 或 macOS 系统中配置永久环境变量的经典操作流程。(以阿里云百炼的
DASHSCOPE_API_KEY 为例)
写入配置文件
echo "export DASHSCOPE_API_KEY='YOUR_DASHSCOPE_API_KEY'" >> ~/.bashrc
让配置立刻生效
source ~/.bashrc检查是否成功
echo $DASHSCOPE_API_KEY代码实现
删除环境变量
大模型赋能行业
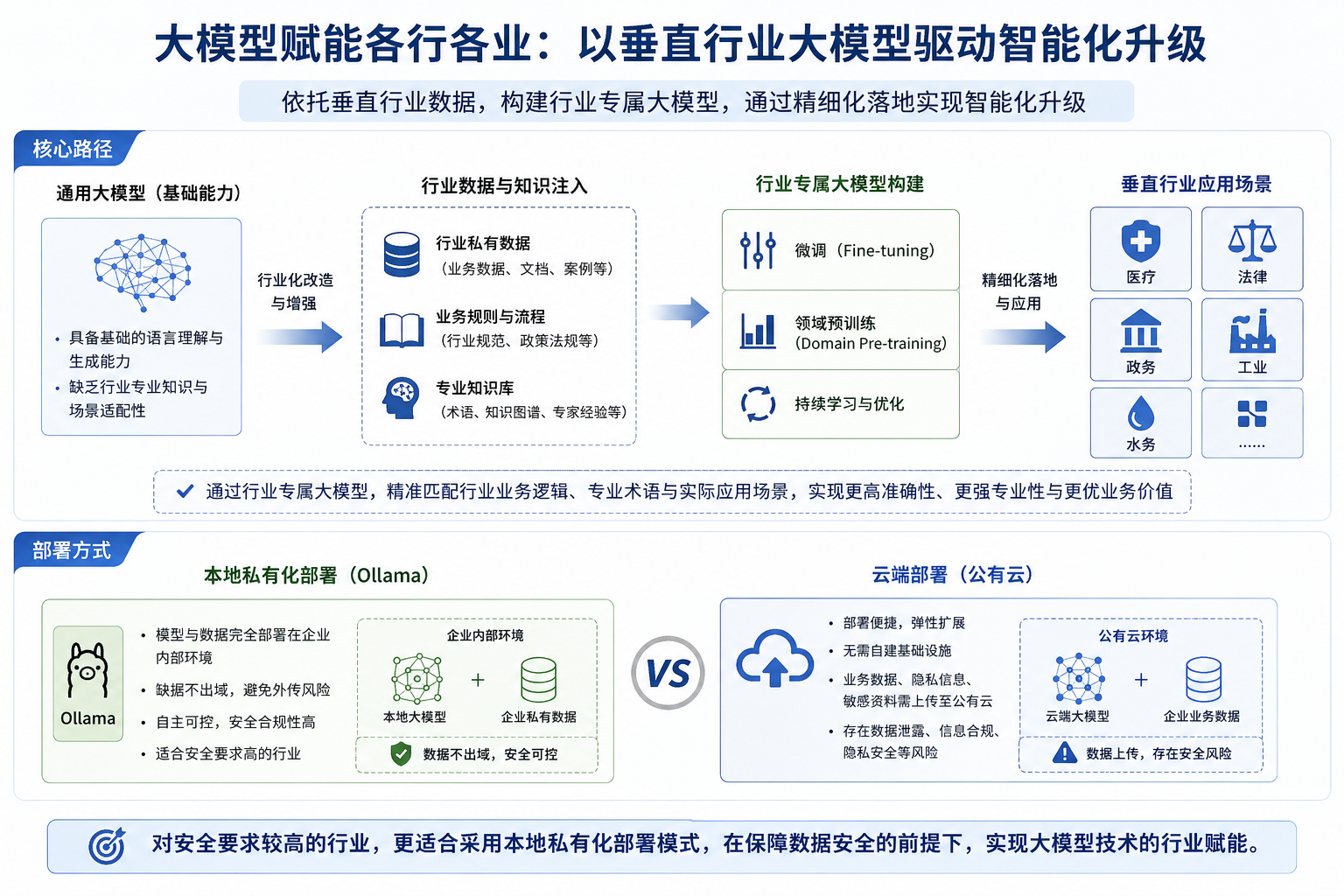
大模型赋能各行各业,核心路径是依托垂直行业数据,构建行业专属大模型,通过精细化落地实现
智能化升级。通用大模型具备基础的语言理解与生成能力,但缺乏行业专业知识与场景适配性,因
此需要针对不同领域,利用行业私有数据、业务规则、专业知识库,通过微调、领域预训练等方
式,打造医疗、法律、政务、工业、水务等垂直领域大模型,使其精准匹配行业业务逻辑、专业术
语与实际应用场景。在部署方式上,可采用本地部署或云端部署两种模式。其中通过 Ollama 实现
本地私有化部署,能够将模型与数据完全部署在企业内部环境,避免数据外传;而云端部署虽然便
捷高效,但企业业务数据、隐私信息、敏感行业资料需上传至公有云,存在数据泄露、信息合规、
隐私安全等风险。因此对安全要求较高的行业,更适合采用本地私有化部署模式,在保障数据安全
的前提下,实现大模型技术的行业赋能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)