SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
目录
Background
- 为什么要从历史轨迹中总结经验?
大模型能通在特定环境中完成复杂任务,但每次交互都是从零开始。历史轨迹可以为后续交互提供成功经验和失败教训,提高效率和生成质量。 - Memory \texttt{Memory} Memory 也面向了“从过往交互中获取经验”,为什么还要使用 Skill \texttt{Skill} Skill?
基于记忆的方法主要通过将原始轨迹保存到外部数据库,信息嘈杂。近期研究尝试在训练过程中动态压缩记忆并更新记忆库,但只是模仿过去的方案,没有提炼核心规则。有效的经验转化需要更高层次的提炼摘要。
|
|
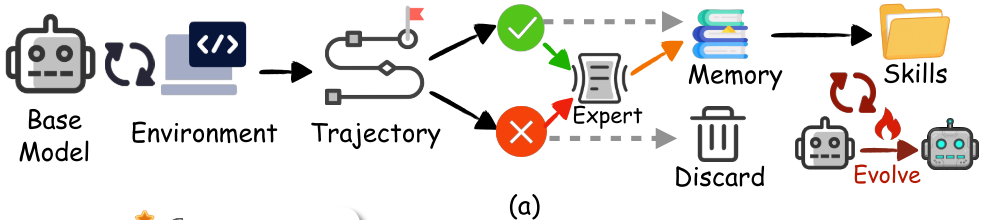
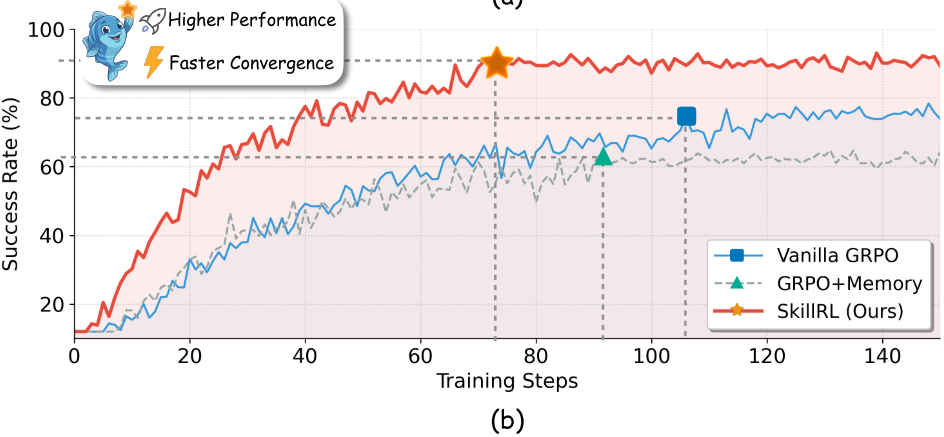
SkillRL:将agent的原始轨迹蒸馏构建分层skill库,通过递归演化让技能库和策略模型在强化学习中协同进化。
Method
Experience-based Skill Distillation
引入一个教师模型 M T \mathcal{M}_T MT(OpenAI o3),从成功轨迹 T + = { τ i : r ( τ i ) = 1 } \mathcal{T}^+=\{\tau_i:r(\tau_i)=1\} T+={τi:r(τi)=1}中提炼出决策模式、正确行动背后的逻辑;从失败轨迹 T − = { τ i : r ( τ i ) = 0 } \mathcal{T}^-=\{\tau_i:r(\tau_i)=0\} T−={τi:r(τi)=0}提炼失败的教训,明确(1)失败的环节(2)错误的推理或行为(3)本应采取的措施(4)防止类似失败的一般原则。
s + = M T ( τ + , d ) , s − = M T ( τ − , d ) s^+=\mathcal{M}_T(\tau^+,d),\quad s^-=\mathcal{M}_T(\tau^-,d) s+=MT(τ+,d),s−=MT(τ−,d)
Hierarchical Skill Library Construction
将提炼出来的知识组织为一个层次化的技能库SKILLBANK。
- General Skills S g \mathcal{S}_g Sg:跨任务的通用策略。通常包括探索策略(例如,系统化的搜索模式、优先访问未访问的地点)、状态管理(例如,在执行操作前验证前提条件),目标跟踪启发式方法(例如,维护进度计数器、仅在完成验证后才终止)。
- Task-Specific Skills S k \mathcal{S}_k Sk:专门为任务类别 k 编码的专门的知识。涵盖了特定领域的动作序列、任务特有的前提条件和约束、该任务类型特有的常见故障模式等。通过在收集过程中按任务类型对轨迹进行组织,能够提取出精细的、特定任务类别的策略。
SKILLBANK = S g ∪ ⋃ k = 1 K S k \texttt{SKILLBANK}=\mathcal{S}_g\cup \bigcup_{k=1}^K \mathcal{S}_k SKILLBANK=Sg∪k=1⋃KSk
每个skill包括一个简洁的名称(如“系统性探索”)、策略描述,以及何时应用。便于快速检索,同时也能为应用提供清晰的指导。
在推理过程中,对给定任务描述 d d d,智能体会检索相关的技能以扩充其现有情境。通用技能 S g \mathcal{S}_g Sg通常作为基础指导内容予以包含。针对特定任务的技能则通过语义相似度检索:
S ret = TopK ( { s ∈ S k : sim ( e d , e s ) > δ } , K ) \mathcal{S}_\text{ret}=\text{TopK}(\{s\in\mathcal{S}_k:\text{sim}(e_d,e_s)>\delta\},K) Sret=TopK({s∈Sk:sim(ed,es)>δ},K)
策略模型随后的动作依赖引入的技能库:
a t ∼ π θ ( a t ∣ o ≤ t , d , S g , S ret ) a_t\sim \pi_\theta(a_t|o_{\leq t},d,\mathcal{S}_g,\mathcal{S}_\text{ret}) at∼πθ(at∣o≤t,d,Sg,Sret)

Recursive Skill Evolution
静态技能库无法覆盖所有领域,随着模型能力的提升和向新领域的拓展,原有的技能已经无法提供有效指导。
- cold start SFT:用教师模型 M T \mathcal{M}_T MT生成示范轨迹,指导模型如何使用技能。
- Recursive Skill Evolution
- 每个验证轮次后监控各任务类别 C \mathcal{C} C的成功率 Acc ( C ) \text{Acc}(\mathcal{C}) Acc(C)
- 当成功率低于阈值 δ δ δ 时触发演化
- 收集失败轨迹;为确保采样的失败案例覆盖足够广泛,使用多样性感知的分层采样:将轨迹按类别分组,根据失败的严重程度(负奖励值)进行排序,并通过循环抽样来选择轨迹,以保持类别熵(保持类别间的平衡,防止某类任务被过度代表或忽略)。
- 教师模型分析失败模式,生成新技能或改进现有技能: S new = M T ( T val − , SKILLBANK ) \mathcal{S}_\text{new}=\mathcal{M}_T(\mathcal{T}^-_\text{val},\text{SKILLBANK}) Snew=MT(Tval−,SKILLBANK)
- 更新技能库: SKILLBANK ← SKILLBANK ∪ S new \text{SKILLBANK} ← \text{SKILLBANK} ∪ S_\text{new} SKILLBANK←SKILLBANK∪Snew
每条轨迹得到一个标志任务成功与否的二进制奖励 r ( τ ( i ) ) ∈ { 0 , 1 } r(\tau^{(i)})\in\{0,1\} r(τ(i))∈{0,1};使用GRPO(Group Relative Policy Optimization)优化技能增强的策略。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)