上下文越大越好吗?聊得越久,AI 真的越懂你吗?
上下文越大越好吗?聊得越久,AI 真的越懂你吗?
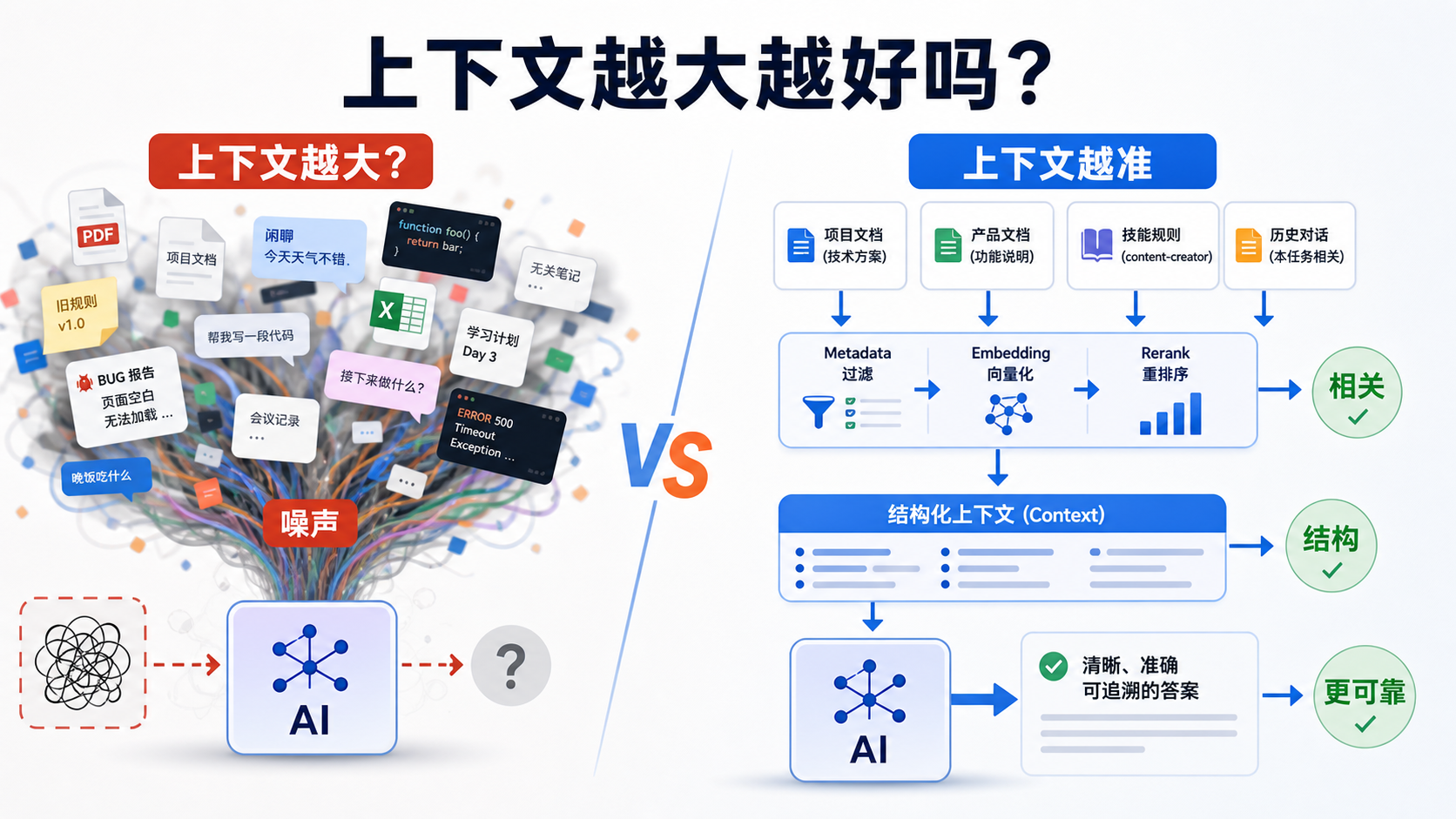
很多人刚开始做 RAG 时,会有一个很自然的想法:
既然大模型需要资料,那我把相关文档都塞进去,是不是效果最好?
还有一个很常见的直觉:
同一个 session 里聊得越久,AI 是不是就越懂我?
这个想法看起来合理,但在真实系统里往往会出问题。
因为大模型不是只会“记住更多”,它也会被无关内容、旧规则、冲突信息影响。
上下文变大,确实给了模型更多资料;但如果这些资料没有经过筛选和组织,它也可能让模型更容易跑偏。
RAG 的关键不是“塞更多上下文”,而是“在有限上下文里放对内容”。同一个 session 的价值,也不是越长越好,而是要看留下来的内容是否仍然和当前任务相关。
要理解这件事,必须先搞清楚三个基础概念:
tokencontext windowembedding
这三个概念看起来偏基础,但它们直接决定了 RAG 系统为什么要做文档切分、metadata、rerank、Context Builder,也解释了为什么“越聊越久”有时不是变准,而是被污染。
一、Token:上下文预算的基本单位
Token 是模型处理文本的基本单位。
它不完全等于中文里的“字”,也不完全等于英文里的“单词”。可以先把它理解成模型内部处理文本时的一小块单位。
对工程实现来说,最重要的不是 token 的切分细节,而是:
token 是上下文预算。
一次模型调用里,很多东西都会占 token:
| 内容 | 是否占 token |
|---|---|
| system / developer 规则 | 是 |
| 用户问题 | 是 |
| 历史对话 | 是 |
| RAG 检索结果 | 是 |
| Memory 召回内容 | 是 |
| Tool 返回结果 | 是 |
| 模型最终回答 | 是 |
所以,当我们说“这个模型上下文很大”时,不代表所有空间都可以拿来放 RAG 文档。
它还要同时容纳规则、用户输入、历史对话、工具结果、memory,以及模型输出空间。
这也是为什么 RAG 系统必须控制输入内容。
二、Context Window:模型一次能看到多少资料
Context window 是模型一次调用时可以处理的最大 token 范围。
可以把它理解成:
模型这一次思考时能摊在桌面上的资料总量。
桌面越大,确实能放更多资料。
但问题是,资料放得越多,不代表模型理解得越好。
如果把所有项目文档、历史对话、排障记录、学习笔记、旧规则、新规则都塞进去,模型可能会遇到几个问题。
| 问题 | 说明 |
|---|---|
| 噪声增加 | 相关信息被大量无关信息淹没 |
| 冲突增加 | 旧规则、新规则、不同项目规则混在一起 |
| 成本增加 | input token 更多,调用更贵、更慢 |
| 注意力稀释 | 模型可能抓错重点 |
| 上下文污染 | 不该参与本次任务的信息影响了回答 |
所以,RAG 里有一个很重要的判断:
context window 大,不等于应该无脑塞满。
真正好的 RAG 系统,要把有限的 context window 当成稀缺资源。
三、Context Pollution:为什么越聊越久也可能越跑偏
Context pollution 指的是:
不该参与当前任务的信息,被放进了上下文,并影响了模型的判断或输出。
举个实际例子。
我希望 content-creator 帮我写一篇关于 RAG / Agent Knowledge Runtime 的 CSDN 技术文章。
这时上下文里真正应该出现的是:
- RAG 的核心概念
- Agent Knowledge Runtime 的定义
- content-creator 的 CSDN 技术平台规则
- 文章目标读者和主线
- 相关项目案例
但如果 Context Builder 同时把这些内容也放进来:
- FPV 图传排障记录
- ZLM 录像导致网络抖动的问题
- 学习计划 Day 3 的进度记录
- 与当前文章无关的历史对话
模型就可能被污染。
表现可能是:
- 文章突然混入视频码率、ping、RTSP、ZLM 等无关内容。
- 明明是 CSDN 文章,却写成学习记录。
- 明明要讲 RAG,却把重点带偏到浏览器自动化或其他 bug 排查。
- 文章结构受无关上下文影响,变得杂乱。
这不是模型“完全不聪明”,而是上下文组织出了问题。
模型只能基于当前看到的信息工作。如果你给它放了不该放的内容,它就可能认真地把噪声也当成信号。
这也解释了为什么同一个 session 不是越聊越准。
如果这个 session 一直围绕同一个任务推进,而且保留的都是有效上下文,它确实可能越来越懂你的目标。
但如果一个 session 里混入了多个互不相关的任务,比如一会儿写 RAG 文章,一会儿排查 ZLM 录像,一会儿讨论 FPV 码率,一会儿又回到 content-creator 的 CSDN 子模式,那么上下文就会变得越来越杂。
这时模型不是更懂你,而是更容易被混合上下文影响。
四、Embedding:让系统能按语义检索
Embedding 是把文本转成向量。
也就是把一段文本变成一组数字坐标,让系统可以比较语义相似度。
比如下面几个问题,字面不完全一样:
conversation-review 是做什么的?这个 skill 如何复盘对话?failure case 和 eval gap 怎么识别?
它们在语义上都可能和 conversation-review 相关。
Embedding 的作用就是让系统知道:这些表达虽然文字不同,但可能指向相近的语义空间。
在 RAG 里,embedding 通常用于两个对象:
| 对象 | 作用 |
|---|---|
| 用户问题 | 转成 query vector |
| 文档 chunk | 转成 document vector |
然后系统比较 query vector 和 document vector 的相似度,召回语义上接近的 chunk。
这就是向量检索的基础。
五、Ingestion、Embedding、Metadata Filter 的顺序
这里有一个容易混淆的点:
Ingestion 不是发生在 embedding 和 metadata filter 之间。
更准确地说,RAG 通常分成两个阶段。
1. 建库阶段
建库阶段发生在用户提问之前,目标是把原始资料变成可检索资产。
每一步做的事情不同。
| 阶段 | 作用 |
|---|---|
| 原始数据 | Markdown、PDF、HTML、代码、Excel、数据库记录 |
| Ingestion | 读取、解析、清洗、去重、格式统一 |
| Chunking | 把长文档切成适合检索的小片段 |
| Metadata 生成 | 给 chunk 标注 project、file、heading、skill、权限、时间等 |
| Embedding | 把 chunk 转成向量 |
| 写入索引库 | 存入向量库、全文索引或数据库 |
所以 ingestion 发生在 embedding 之前。
metadata 通常也在 embedding 前后生成,并和 chunk、向量一起存储。
2. 查询阶段
查询阶段发生在用户提问时,目标是找到本次任务真正需要的内容。
这里的 metadata filter 使用的是建库阶段生成好的 metadata。
比如用户问:
content-creator 的 CSDN 子模式有什么问题?
查询阶段可能是:
- 把用户问题转成 query embedding。
- 向量检索召回一批候选 chunk。
- 使用 metadata filter 限定
project=thinking-skills、skill=content-creator。 - rerank 优先保留 CSDN / Technical Platform Mode 相关段落。
- Context Builder 只把最相关内容放进上下文。
这一步的重点不是“清洗数据”,而是“过滤不该参与当前任务的内容”。
六、为什么只靠 Embedding 不够?
Embedding 很重要,但它不是万能的。
原因是:语义相似不等于任务相关。
比如我问:
content-creator 的 CSDN 子模式有什么问题?
向量检索可能召回这些内容:
- content-creator 的 Technical Platform Mode
- CSDN 文章草稿
- 之前写文章时的失败案例
- 学习计划里关于 CSDN 的记录
- 其他项目里提到“内容创作”的文档
它们在语义上可能都相关。
但本次真正应该进入上下文的,可能只有:
thinking-skills项目里的content-creator/SKILL.md- 和 CSDN 子模式相关的规则段落
- 这次文章生成失败的具体反馈
所以 RAG 通常需要多个步骤配合。
| 步骤 | 解决的问题 |
|---|---|
| Ingestion | 原始资料如何进入系统 |
| Chunking | 长文档如何切成可检索片段 |
| Metadata | 每个 chunk 属于哪个项目、文件、技能、权限范围 |
| Embedding | 如何按语义召回候选内容 |
| Metadata Filter | 如何过滤掉不该参与本次任务的内容 |
| Rerank | 如何重新排序候选内容 |
| Context Builder | 最终哪些内容进入 context window |
这也是现代 RAG 工程比“向量数据库问答”复杂得多的原因。
七、用 thinking-skills 举一个完整例子
假设用户问:
conversation-review 是做什么的?
一个比较合理的 RAG 流程应该是:
- Query embedding:把问题转成向量。
- Vector retrieval:从
thinking-skills文档里召回候选 chunk。 - Metadata filter:限定
project=thinking-skills,优先skill=conversation-review。 - Rerank:优先保留
Purpose、When to Use、Output Format等段落。 - Context Builder:只把最相关片段组织给 LLM,不混入
content-creator或learning-companion的规则。 - LLM answer:基于上下文回答。
- Citation / Eval:检查回答是否引用正确来源,是否覆盖用途、触发场景和边界。
如果 metadata filter 做错了,把 content-creator 的内容也放进来,模型就可能把 conversation-review 误说成“写文章用的 skill”。
如果 Context Builder 做错了,即使 retrieval 找到了正确内容,也可能因为最终上下文放错,导致回答跑偏。
这就是 token、context window、embedding、metadata filter 和 Context Builder 之间的关系。
八、一个实用记忆法
可以用下面这组关系记住:
| 概念 | 一句话 |
|---|---|
| Token | 上下文预算单位 |
| Context Window | 模型一次能看到的最大资料范围 |
| Ingestion | 把原始资料变成可检索资产 |
| Embedding | 把文本变成向量,用来语义召回 |
| Metadata Filter | 查询时过滤不该参与本次任务的内容 |
| Rerank | 对候选结果重新排序 |
| Context Builder | 决定最终哪些内容进入上下文 |
更简洁一点:
Ingestion 负责建库,Embedding 负责召回,Metadata Filter 负责过滤,Context Builder 负责组装。
九、结语:AI 不是越聊越懂,RAG 也不是越塞越准
很多 RAG demo 只展示“用户问问题,系统搜到文档,然后模型回答”。
但真实工程里,难点往往不是能不能搜到,而是:
- 搜到的是不是当前项目的内容?
- 是不是当前 skill 的规则?
- 是不是最新版本?
- 有没有权限使用?
- 会不会和当前任务无关?
- 会不会污染模型判断?
所以,RAG 不是把资料尽可能多地塞给模型。
真正好的 RAG 系统,是在有限 context window 里,放入最相关、最可信、最应该参与本次任务的信息。
同一个 session 也是一样。
如果上下文一直服务于同一个目标,它会形成有效积累。
如果上下文不断混入无关任务,它就会变成污染源。
这也是为什么后续要继续学习 chunk 和 metadata。
因为只有理解了 token、context window 和 embedding,才能真正理解:
RAG 的核心不是“更多上下文”,而是“更好的上下文”。AI 的上下文能力也不是越长越强,而是越相关、越干净、越有结构,才越可靠。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)