第三章-高斯混合聚类读书笔记
高斯混合聚类——《数据挖掘(主编:吕欣 王梦宁)》读书笔记
发布者:omx同学
1. 聚类与高斯混合模型简介
聚类是一种无监督学习方法,它在没有类别标签的情况下,根据样本之间的相似性自动发现数据内部结构。常见聚类方法包括 K-Means、层次聚类、DBSCAN 和高斯混合聚类等。
高斯混合模型(Gaussian Mixture Model, GMM)是一种基于概率模型的聚类方法。它认为总体数据不是由单一分布产生的,而是由多个高斯分布按一定权重混合生成。每个高斯分布可以看作一个潜在簇。
与 K-Means 不同,GMM 属于软聚类方法。K-Means 会将每个样本直接分配给一个簇,而 GMM 会给出样本属于每个簇的概率。例如,一个客户可能有 60% 的概率属于高消费群体,35% 的概率属于中等消费群体,这种表达更符合现实中类别边界模糊的情况。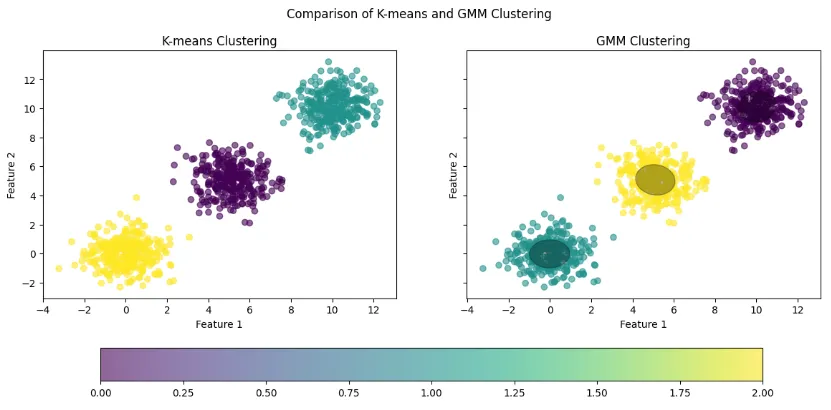
2. 高斯分布回顾
一维高斯分布的概率密度函数为:
f(x)=12πσ2exp(−(x−μ)22σ2) f(x)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) f(x)=2πσ21exp(−2σ2(x−μ)2)
其中,μ\muμ 表示均值,决定分布中心;σ2\sigma^2σ2 表示方差,决定分布离散程度。
多维高斯分布可以表示为:
N(x∣μ,Σ)=1(2π)d/2∣Σ∣1/2exp[−12(x−μ)TΣ−1(x−μ)] \mathcal{N}(x|\mu,\Sigma)=\frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}} \exp\left[-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)\right] N(x∣μ,Σ)=(2π)d/2∣Σ∣1/21exp[−21(x−μ)TΣ−1(x−μ)]
其中,Σ\SigmaΣ 是协方差矩阵。协方差矩阵不仅描述各特征方差,还描述特征之间的相关关系,因此 GMM 可以识别椭圆形、方向不同、规模不同的簇。

3. GMM 的数学表达
GMM 假设数据由 KKK 个高斯分布混合生成:
p(x)=∑k=1KπkN(x∣μk,Σk) p(x)=\sum_{k=1}^{K}\pi_k\mathcal{N}(x|\mu_k,\Sigma_k) p(x)=k=1∑KπkN(x∣μk,Σk)
其中:
- KKK:高斯成分数量,也可理解为簇的数量;
- πk\pi_kπk:第 kkk 个高斯成分的权重,满足 ∑k=1Kπk=1\sum_{k=1}^{K}\pi_k=1∑k=1Kπk=1;
- μk\mu_kμk:第 kkk 个高斯成分的均值向量;
- Σk\Sigma_kΣk:第 kkk 个高斯成分的协方差矩阵。
在聚类解释中,πk\pi_kπk 表示第 kkk 类在总体中的比例,μk\mu_kμk 表示该类中心位置,Σk\Sigma_kΣk 表示该类形状与扩散程度。
4. 隐变量思想
GMM 引入隐变量 zzz 表示样本来自哪个高斯成分。由于真实数据中并不知道每个样本的类别,因此类别标签是隐含的。模型需要根据样本特征反推每个样本属于各个簇的概率。
对于样本 xix_ixi,其属于第 kkk 个簇的后验概率为:
γik=πkN(xi∣μk,Σk)∑j=1KπjN(xi∣μj,Σj) \gamma_{ik}=\frac{\pi_k\mathcal{N}(x_i|\mu_k,\Sigma_k)} {\sum_{j=1}^{K}\pi_j\mathcal{N}(x_i|\mu_j,\Sigma_j)} γik=∑j=1KπjN(xi∣μj,Σj)πkN(xi∣μk,Σk)
γik\gamma_{ik}γik 又称为责任度,表示第 kkk 个高斯成分对样本 xix_ixi 的解释程度。
5. EM 算法
GMM 的参数通常通过 EM 算法估计。EM 算法适合处理含有隐变量的最大似然估计问题。
5.1 初始化
先设定簇数 KKK,并初始化各高斯成分的均值、协方差矩阵和混合权重。实际应用中常用 K-Means 的结果初始化均值,以提高收敛速度。
5.2 E 步
根据当前模型参数,计算每个样本属于每个簇的后验概率,即责任度 γik\gamma_{ik}γik。
5.3 M 步
根据 E 步得到的责任度重新估计参数:
Nk=∑i=1nγik N_k=\sum_{i=1}^{n}\gamma_{ik} Nk=i=1∑nγik
μk=1Nk∑i=1nγikxi \mu_k=\frac{1}{N_k}\sum_{i=1}^{n}\gamma_{ik}x_i μk=Nk1i=1∑nγikxi
Σk=1Nk∑i=1nγik(xi−μk)(xi−μk)T \Sigma_k=\frac{1}{N_k}\sum_{i=1}^{n}\gamma_{ik}(x_i-\mu_k)(x_i-\mu_k)^T Σk=Nk1i=1∑nγik(xi−μk)(xi−μk)T
πk=Nkn \pi_k=\frac{N_k}{n} πk=nNk
5.4 收敛判断
重复 E 步和 M 步,直到对数似然函数变化很小或达到最大迭代次数。EM 算法每次迭代都会使似然值不下降,但可能收敛到局部最优,因此初始化很重要。
6. GMM 与 K-Means 对比
| 对比维度 | K-Means | GMM |
|---|---|---|
| 聚类方式 | 硬聚类 | 软聚类 |
| 簇形状 | 偏向球形簇 | 可表示椭圆形簇 |
| 输出结果 | 类别标签 | 类别概率与标签 |
| 距离/概率依据 | 欧氏距离 | 高斯概率密度 |
| 不确定性表达 | 较弱 | 较强 |
K-Means 简单高效,适合簇形状接近圆形且边界清晰的情况。GMM 更灵活,适合簇之间存在重叠、边界模糊或需要概率解释的场景。
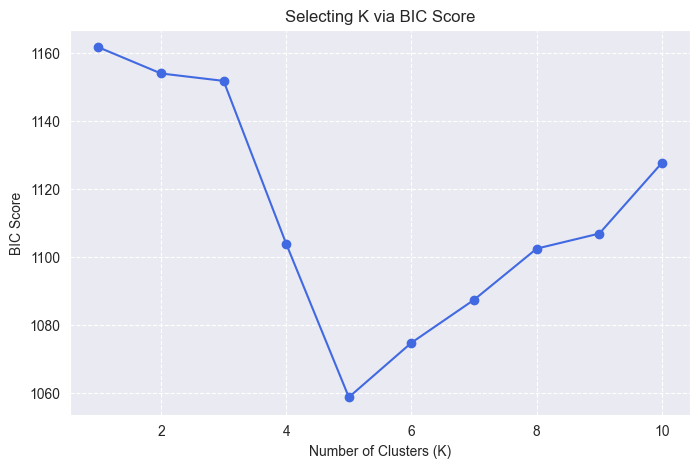
7. 模型选择:AIC 与 BIC
GMM 需要确定高斯成分个数 KKK。如果 KKK 太小,模型会欠拟合;如果 KKK 太大,模型会过拟合。常用的模型选择标准包括 AIC 和 BIC。
AIC 与 BIC 都在拟合效果和模型复杂度之间进行权衡。一般来说,指标越小越好。BIC 对复杂模型惩罚更强,因此在样本量较大时更常用于选择较简洁的模型。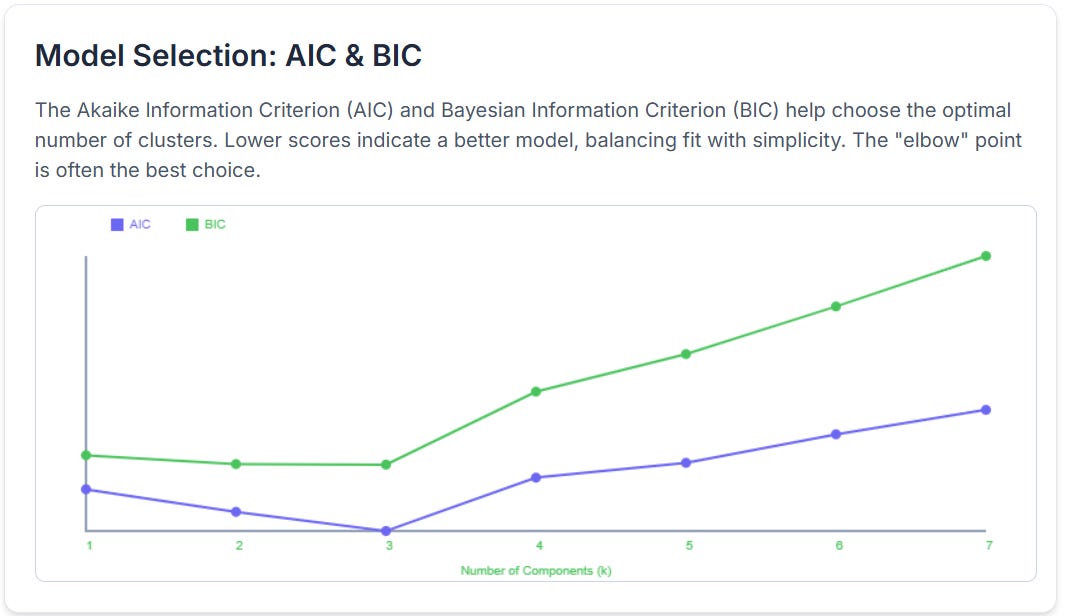
8. 实践应用:消费者细分
将 GMM 应用于零售行业消费者细分时,消费者行为通常具有异质性,不同客户在年龄、收入、消费能力、消费频率等方面存在差异。使用 GMM 可以识别潜在客户群体,并进一步分析每类客户的特征。
与硬聚类相比,GMM 的优势在于能识别“边缘客户”。例如某客户同时具有高收入和中等消费倾向,模型可以用概率表达其类别不确定性。营销人员可以据此制定更灵活的策略,而不是机械地将客户固定在某一类。
GMM 还可以用于图像分割:把像素颜色或纹理特征看作样本,再用多个高斯成分描述不同区域的像素分布。下图展示了 GMM 在图像分割中的直观效果,它说明“聚类”并不局限于表格数据,也可以用于图像和视觉任务。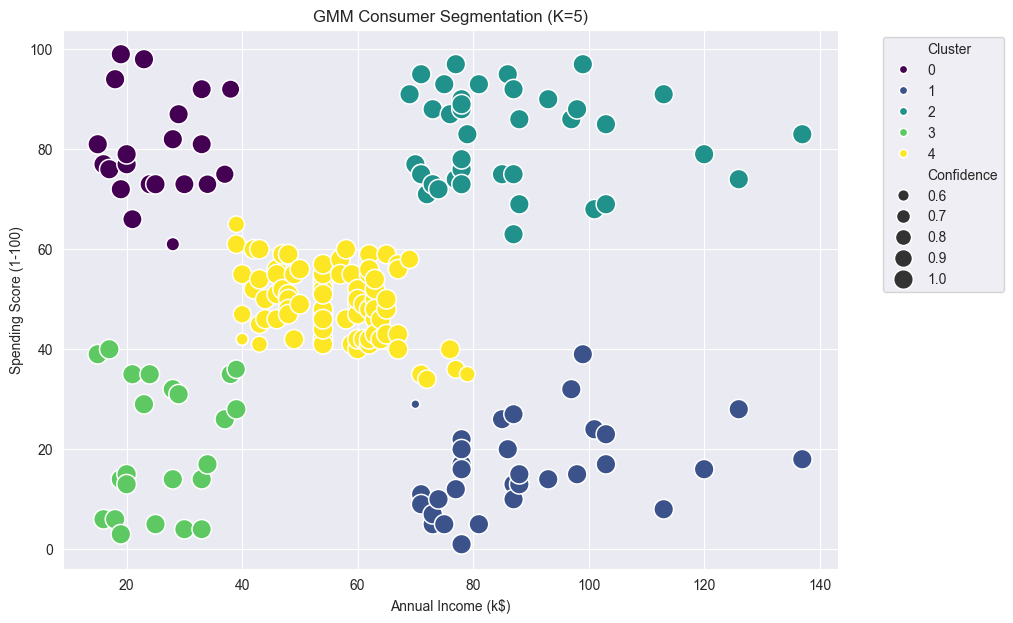
在实践中,需要注意以下问题:
- 数据应先进行标准化,避免量纲较大的变量主导聚类。
- 高维数据可先进行 PCA 降维,减少噪声和冗余。
- 需要结合 AIC、BIC 和业务解释共同选择聚类数。
- 如果数据分布明显不是高斯形态,应谨慎解释聚类结果。
- 聚类结果应通过可视化、轮廓系数或业务指标进行验证。
9. 对协方差类型的理解
在实际使用 GMM 时,协方差矩阵类型会影响模型复杂度和聚类形状。常见设置包括 full、tied、diag 和 spherical。
| 协方差类型 | 含义 | 特点 |
|---|---|---|
| full | 每个簇有完整协方差矩阵 | 最灵活,可表示任意椭圆形簇 |
| tied | 所有簇共享一个协方差矩阵 | 参数较少,假设各簇形状相近 |
| diag | 每个簇使用对角协方差矩阵 | 假设特征之间相关性较弱 |
| spherical | 每个簇只有一个方差参数 | 接近 K-Means 的球形簇假设 |
如果数据簇形状复杂,full 协方差更合适,但也更容易过拟合;如果样本量不大,diag 或 tied 可能更稳定。因此,GMM 不仅要选簇数,也要考虑协方差结构。
10. 实践中的完整建模流程
将 GMM 用于真实聚类任务时,可以按如下流程进行:
- 数据清洗:处理缺失值、异常值和重复样本。
- 特征选择:选择能反映样本差异的变量。
- 标准化:消除量纲差异,避免收入、金额等大尺度变量支配聚类。
- 初步可视化:使用散点图、PCA 或 t-SNE 观察样本分布。
- 模型训练:对不同 KKK 和协方差类型训练 GMM。
- 模型选择:结合 AIC、BIC、可视化效果和业务可解释性选择方案。
- 结果解释:分析每一类样本的均值、分布和典型特征。
- 稳定性检验:更换随机种子或采样数据,观察聚类结果是否稳定。
这一流程说明,聚类不是只调用一个算法函数,而是需要在数据理解、模型选择和结果解释之间反复调整。
11. 本章总结
GMM 的核心思想是用多个高斯分布共同解释总体数据,并用概率表示样本的类别归属。它比 K-Means 更复杂,但能够处理边界重叠和簇形状不规则的问题。通过本章学习,我理解到聚类不仅是“分组”,更是对数据潜在结构的建模。GMM 的概率输出使聚类结果更细腻,也更适合管理决策中需要处理不确定性的场景。
补充说明
本文是基于国防科技大学吕欣教授主编的《数据挖掘》一书所整理的读书笔记。该书系统覆盖了数据挖掘的九大核心领域,包括统计描述、相关分析、回归分析、数据降维、关联规则挖掘、分类、聚类、异常检测和集成学习。此外,本书还配有丰富的数字化学习资源和全套教辅材料,构建了理论与实践紧密结合的立体化教学系统。相关学习资料可通过以下链接获取:[https://github.com/XL-lab-bigdata/DataMining.git]

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)