day25_人工神经网络_优化器与正则化方法
神经网络优化器与正则化方法
一、梯度下降优化算法
1.为什么需要优化器
标准梯度下降在训练神经网络时经常会遇到三类问题:
- 平缓区域:梯度值绩效,参数几乎原地踏步,训练卡住不动
- 鞍点:梯度为0,参数迭代停止
- 局部最小值:继续训练损失值反而更高,以为已经是最优解,实则还有全局更优解
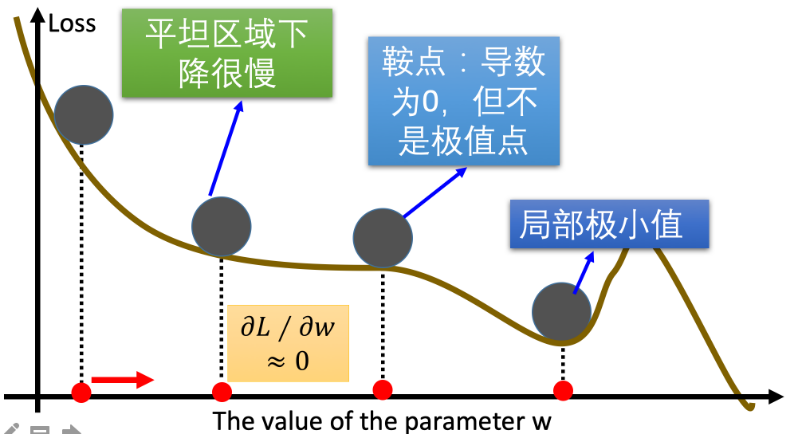
为了优化以上问题,Momentum(动量法)、AdaGrad(自适应梯度算法)、RMSProp(均方根传播)、Adam(自适应矩估计)等优化算法应运而生。
2.指数加权平均(EWA)
在讲具体的算法之前,需要先搞懂什么是指数加权平均(Exponentially Weighted Average)。
核心思想:当我们在预测明天的气温的时候,不能只看几天的气温,还要看之前的。只不过,距离今天越远的,对结果的影响就越小。
St=β⋅St−1+(1−β)⋅YtS_t = \beta \cdot S_{t-1} + (1-\beta) \cdot Y_tSt=β⋅St−1+(1−β)⋅Yt
- StS_tSt:t时刻的加权平均值(可以理解为平滑后的梯度)
- YtY_tYt:t时刻的真实观测值(当前梯度)
- β\betaβ:权重系数,越大曲线越平缓,通常取0.9
import torch
import matplotlib.pyplot as plt
# 用来正常显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
ELEMENT_NUMBER = 30
# 1 模拟随机波动的温度
torch.manual_seed(0)
# 生成30天的气温
temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10
# 生成1~30的一维张量
days = torch.arange(start=1, end=ELEMENT_NUMBER + 1, step=1)
# 绘制原始数据的折线图
plt.plot(days, temperature, color="r", label="原始数据")
# 绘制原始数据的散点图
plt.scatter(days, temperature, color="r")
# 2 指数加权平均
beta = 0.9
exp_weight_avg = []
for idx, temp in enumerate(temperature, 1):
"""
enumerate()用于在遍历可迭代对象(如列表、元组、字符串等)时
同时获取元素及其对应的索引
"""
if idx == 1:
# 第一个元素的指数加权平均就是他自己,不用计算
exp_weight_avg.append(temp)
continue
# 指数加权平均
new_temp = exp_weight_avg[-1] * beta + (1 - beta) * temp
exp_weight_avg.append(new_temp)
# 绘制指数加权平均后的折线图
plt.plot(days, exp_weight_avg, color="b", label=f"EWA(beta={beta})")
plt.legend()
plt.show()
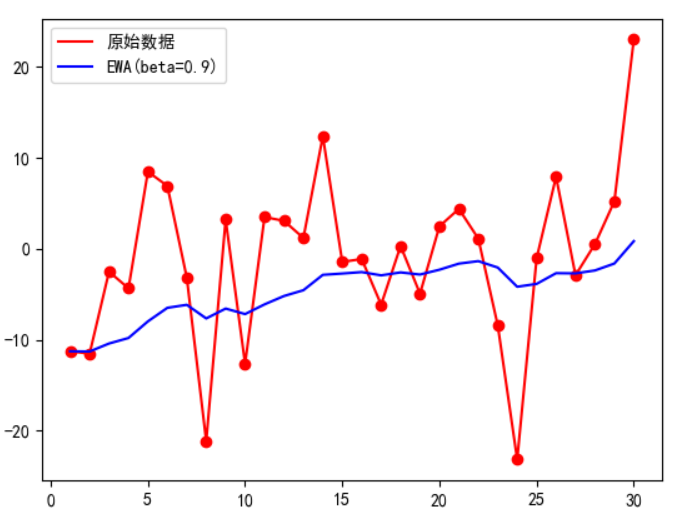
β\betaβ越大,曲线越平缓;β\betaβ越小,曲线越贴近原始数据。
3.Momentum—动量法
普通的SGD(随机梯度下降)只用当前时刻的梯度方向更新参数,而动量法会把历史梯度也考虑进来。
动量法:
st=βst−1+(1−β)gts_t = \beta s_{t-1} + (1-\beta) g_tst=βst−1+(1−β)gt
SGD:
wt=wt−1−ηstw_t = w_{t-1} - \eta s_twt=wt−1−ηst
想象一个下山的过程:普通SGD像一个每一步都重新判断方向的人,而动量法想一个带“惯性”的人。即使当前坡度为0,由于之前积累的速度,动量法依然能凭借惯性冲出鞍点或局部最小值。
为什么动量法能跨过鞍点?
在鞍点处梯度为0,参数本应停止更新。但是动量法的计算方法会考虑到历史的梯度值——而不是仅参考当前梯度值,因此,动量法可以凭借历史的梯度值跨过鞍点。
为什么动量法能减少震荡?
mini-batch由于每次随机获取样本的一批数据,梯度方向波动大。动量法通过指数加权移动平均平滑了前进方向,训练过程更稳更快。
import torch
import torch.nn as nn
# 初始化权重 w = [1.0],损失函数 = w²/2
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
loss = ((w ** 2) / 2.0).sum()
# 使用带动量的SGD,beta=0.9
optimizer = torch.optim.SGD([w], lr=0.01, momentum=0.9)
# 第1次更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'第1次: 梯度={w.grad.item():.6f}, 更新后w={w.detach().item():.6f}')
# 第2次更新(用更新后的w重新算loss)
loss = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'第2次: 梯度={w.grad.item():.6f}, 更新后w={w.detach().item():.6f}')
输出示例:第1次: 梯度=1.000000, 更新后w=0.990000;第2次: 梯度=0.990000, 更新后w=0.971100
4.AdaGrad—自适应学习率开山之作
AdaGrad的核心思路:每个参数都有自己的学习率,梯度大的参数步子小一点,梯度小的参数步子大一点
AdaGrad通过累计历史梯度的平方来调整学习率:
st=st−1+gt⊙gts_t = s_{t-1} + g_t \odot g_tst=st−1+gt⊙gt
ηt=ηst+σ\eta_t = \frac{\eta}{\sqrt{s_t} + \sigma}ηt=st+ση
wt=wt−1−ηt⊙gtw_t = w_{t-1} - \eta_t \odot g_twt=wt−1−ηt⊙gt
缺点:由于StS_tSt单调递增,导致模型训练到后面,学习率越来越小,模型就渐渐学不动了。
import torch
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
loss = ((w ** 2) / 2.0).sum()
optimizer = torch.optim.Adagrad([w], lr=0.01)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'第1次: 梯度={w.grad.item():.6f}, 更新后w={w.detach().item():.6f}')
loss = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'第2次: 梯度={w.grad.item():.6f}, 更新后w={w.detach().item():.6f}')
5.RMSProp—AdaGrad的进化版
AdaGrad的问题是StS_tSt单调递增,导致学习率早衰。RMSProp借鉴了EWA的思路,用指数加权平均替代简单累加:
st=βst−1+(1−β)(gt⊙gt)s_t = \beta s_{t-1} + (1-\beta)(g_t \odot g_t)st=βst−1+(1−β)(gt⊙gt)
ηt=ηst+σ\eta_t = \frac{\eta}{\sqrt{s_t} + \sigma}ηt=st+ση
wt=wt−1−ηt⊙gtw_t = w_{t-1} - \eta_t \odot g_twt=wt−1−ηt⊙gt
这样StS_tSt不再单调递增,而是受一段时间内的梯度强度影响,越近的梯度影响越大。
import torch
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
loss = ((w ** 2) / 2.0).sum()
optimizer = torch.optim.RMSprop([w], lr=0.01, alpha=0.9)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'第1次: 梯度={w.grad.item():.6f}, 更新后w={w.detach().item():.6f}')
loss = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'第2次: 梯度={w.grad.item():.6f}, 更新后w={w.detach().item():.6f}')
6.Adam—Momentum + RMSProp的集大成者
Adam(Adaptive Moment Estimation)把两条路线合在一起:
- Momentum路线:用EWA修正梯度方向(一阶距)
- RMSProp路线:用EWA修正学习率(二阶距)
mt=β1mt−1+(1−β1)gt(梯度的一阶矩)m_t = \beta_1 m_{t-1} + (1-\beta_1) g_t \quad \text{(梯度的一阶矩)}mt=β1mt−1+(1−β1)gt(梯度的一阶矩)
st=β2st−1+(1−β2)(gt⊙gt)(梯度的二阶矩)s_t = \beta_2 s_{t-1} + (1-\beta_2)(g_t \odot g_t) \quad \text{(梯度的二阶矩)}st=β2st−1+(1−β2)(gt⊙gt)(梯度的二阶矩)
由于 m 和 s 初始化为 0,开始几步会有偏差,所以需要偏差校正:
mt^=mt1−β1t,st^=st1−β2t\hat{m_t} = \frac{m_t}{1 - \beta_1^t}, \quad \hat{s_t} = \frac{s_t}{1 - \beta_2^t}mt^=1−β1tmt,st^=1−β2tst
wt=wt−1−ηmt^st^+σw_t = w_{t-1} - \eta \frac{\hat{m_t}}{\sqrt{\hat{s_t}} + \sigma}wt=wt−1−ηst^+σmt^
Adam相当于同时拥有了“方向感(Momentum)”和“步伐感(RMSProp)”,是比较常用的优化器。
import torch
w = torch.tensor([1.0], requires_grad=True)
loss = ((w ** 2) / 2.0).sum()
# betas = (beta1, beta2),分别控制一阶、二阶矩的EWA系数
optimizer = torch.optim.Adam([w], lr=0.01, betas=[0.9, 0.99])
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'第1次: 梯度={w.grad.item():.6f}, 更新后w={w.detach().item():.6f}')
loss = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'第2次: 梯度={w.grad.item():.6f}, 更新后w={w.detach().item():.6f}')
| 优化器 | 核心机制 | 优点 | 缺点 |
|---|---|---|---|
| SGD | 标准梯度 | 简单可控 | 易卡在鞍点/局部最小,震荡大 |
| Momentum | 梯度 EWA | 跨鞍点、减少震荡 | 仍需手动调学习率 |
| AdaGrad | 自适应学习率 | 无需手动调学习率 | 学习率早衰,后期无力 |
| RMSProp | 梯度平方 EWA | 自适应学习率 + 不早衰 | 收敛仍较慢 |
| Adam | Momentum + RMSProp | 收敛快、自适应、鲁棒 | 容易过拟合(默认参数偏大) |
二、学习率衰减策略
训练前期大步快跑,训练后期小步微调——这是学习率衰减的核心策略
1.等间隔衰减StepLR
每走过step_size个epoch,学习率乘以gamma:
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
LR = 0.1
max_epoch = 200
iteration = 10
w = torch.tensor([1.0], requires_grad=True)
y_true = torch.tensor([0])
x = torch.tensor([1.0])
optimizer = optim.SGD([w], lr=LR, momentum=0.9)
# 每50个epoch,学习率乘以0.5
scheduler_lr = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5)
lr_list, epoch_list = [], []
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_last_lr()[0])
epoch_list.append(epoch)
for i in range(iteration):
loss = ((w * x - y_true) ** 2) / 2.0
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler_lr.step()
plt.plot(epoch_list, lr_list, label="Step LR (step=50, gamma=0.5)")
plt.xlabel("Epoch")
plt.ylabel("Learning Rate")
plt.legend()
plt.show()
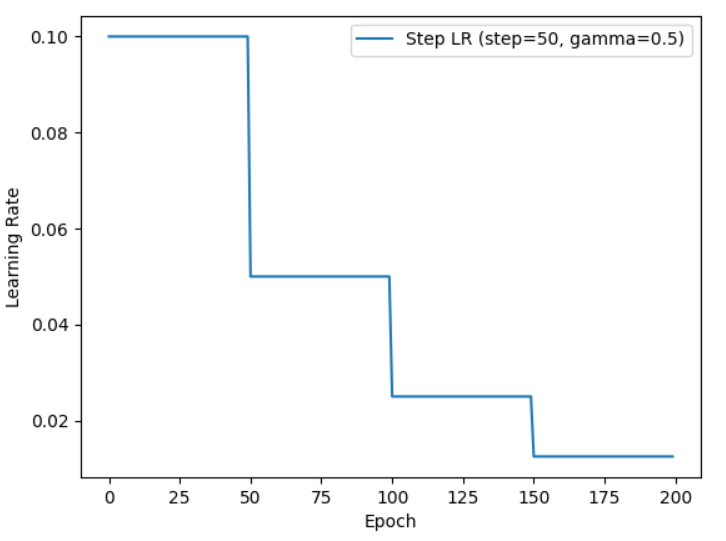
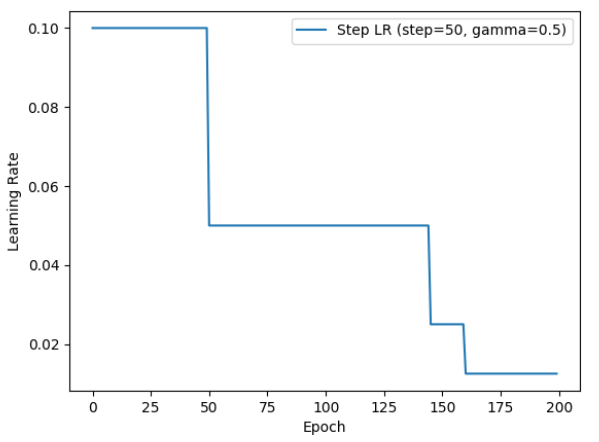
3.指定间隔衰减MultiStepLR
不是均匀衰减,只在指定的epoch节点才调整:
scheduler_lr = optim.lr_scheduler.MultiStepLR(
optimizer, milestones=[50, 145, 160], gamma=0.5
)
适用于我们知道模型在哪些节点需要降低学习率的场景,比等间隔更灵活
3.指数衰减ExponentialLR
每个epoch都衰减:
lrt=lr0×γepochlr_{t} = lr_{0} \times \gamma^{epoch}lrt=lr0×γepoch
scheduler_lr = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
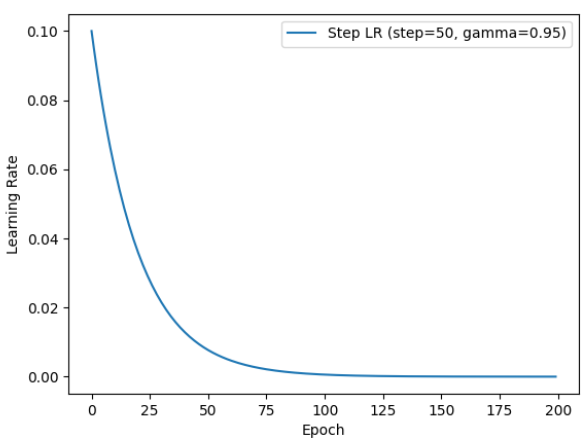
gamma越接近1,衰减越慢;越接近0,衰减越快。
三、正则化方法
1.什么是正则化?
正则化的目标只有一个:提升模型在新样本上的泛化能力,也就是减少过拟合。
神经网络在参数多,数据少的情况下,过拟合是常态。常用的正则化策略有:
- 范数惩罚(L1/L2)
- Dropout(随机失活)
- Batch Normalization(批量归一化)
2.Dropout——随机杀死神经元
在训练时:每个神经元有概率ppp被关闭(激活值置为0),存活下来的神经元缩放11−p\frac{1}{1-p}1−p1。
在测试时:所有神经元都工作,但输出需要乘(1−p)(1-p)(1−p)(PyTorch默认训练时做了缩放,所以测试时无需额外处理)
import torch
import torch.nn as nn
dropout = nn.Dropout(p=0.4) # 40% 的神经元被失活
inputs = torch.randint(0, 10, size=[1, 4]).float()
layer = nn.Linear(4, 5)
y = layer(inputs)
print("未失活 FC 层输出:", y)
y = dropout(y)
print("失活后 FC 层输出:", y)
"""
未失活 FC 层输出: tensor([[ 3.7053, -6.0588, 2.4036, 1.0904, 1.6961]],
grad_fn=<AddmmBackward0>)
失活后 FC 层输出: tensor([[ 6.1754, -10.0980, 0.0000, 1.8173, 2.8268]],
grad_fn=<MulBackward0>)
"""
3.Batch Normalization(BN层)
BN的操作分两步:
- 标准化:把输入变成均值0,方差1的分布
- 重构:再做一个线性变换(缩放+平移),让模型自己学习最优的分布
y=x−E(x)Var(x)+ϵ⋅λ+βy = \frac{x - E(x)}{\sqrt{Var(x) + \epsilon}} \cdot \lambda + \betay=Var(x)+ϵx−E(x)⋅λ+β
其中 λ\lambdaλ(weight)和 β\betaβ(bias)是可学习参数。
import torch
import torch.nn as nn
# BatchNorm2d 用于 2D 特征图(卷积层后),num_features = 通道数
m = nn.BatchNorm2d(2, eps=1e-05, momentum=0.1, affine=True)
input = torch.randn(1, 2, 3, 4)
output = m(input)
print("input:", input)
print("output:", output)
BN层为什么有效?
- 每一层输入的分布被拉回标准正态分布,避免梯度消失/爆炸
- 相当于给每层输入做了一次预处理,让深层网络更容易训练
- 在计算机视觉领域使用较多
四、总结
| 知识点 | 一句话总结 |
|---|---|
| 指数加权平均 | 距离越远权重越小,用来平滑序列数据 |
| Momentum | 对梯度做 EWA,赋予模型"下山惯性" |
| AdaGrad | 对每个参数自适应学习率,但易早衰 |
| RMSProp | 用 EWA 替代累加,修复 AdaGrad 早衰问题 |
| Adam | Momentum + RMSProp,当代默认首选 |
| StepLR | 每 N 个 epoch 固定比例衰减学习率 |
| MultiStepLR | 在指定 epoch 节点衰减,更灵活 |
| ExponentialLR | 每个 epoch 连续指数衰减 |
| Dropout | 随机失活神经元,防止协同依赖 |
| BN 层 | 标准化 + 可学习仿射变换,稳定训练 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)