[AVSR]MultiAVSR: Robust Speech Recognition via SupervisedMulti-Task Audio–Visual Learning论文精读
MultiAVSR 论文解读:用 18% 的计算量,拿下多任务语音识别 SOTA
一、论文背景介绍
- 论文标题:MultiAVSR: Robust Speech Recognition via Supervised Multi-Task Audio–Visual Learning
- 发表期刊:Electronics (2025, 14, 2310)
- 所有作者均来自美国杨百翰大学(Brigham Young University)电气与计算机工程系的计算机视觉与机器学习实验室。
本文与 2024 年的 USR(Unified Speech Recognition)、2024 年的 SyncVSR 是同期竞争性工作,三者都在 2025 年前后发表,且都聚焦于统一多任务语音识别。但 MultiAVSR 以仅 18% 的计算量取得了更好的性能,成为 3000 小时公开数据内的 SOTA。
二、Abstract — 摘要
AVSR 视觉语音识别任务(唇读)存在准确率低、标注数据稀缺的问题,现有研究方向中常见的自监督方法还存在计算成本高、真实场景泛化差的缺陷。该领域长期存在以下共识:
- 唇读数据太少,必须靠复杂的自监督预训练才能做好。
- 音频和视觉是完全不同的模态,必须用两个独立的编码器分别处理。
- 多任务学习一定要精心设计不同任务的损失权重。
- 唇读模型必须外挂一个大语言模型才能用。
针对这些认知,文章提出了纯监督多任务统一框架 MultiAVSR,研究探讨了这些认识是否正确,最后证明它们全都是错的,反而:
- 只要让三个任务共享同一个核心编码器,纯监督多任务就能比所有自监督方法效果好,计算量还只有它们的 18%。
- 根本不需要调任务权重——唇读任务最难,收敛最慢,它会天然主导整个训练过程。
- 多任务训练会让模型自己学会语言规律,对外部语言模型的依赖度只有 2.8%,甚至在真实场景里不用语言模型效果更好。
三、方法介绍
3.1 整体框架
为了充分利用音频数据,测试不同模态之间的作用,本文提出了一种有监督多任务框架,即训练所用的数据是人为标注的,同时该框架可以同时处理 ASR、VSR 和 AVSR 三种任务。MultiAVSR 是基于当前在音视频识别任务中 SOTA 的 Auto-AVSR 模型提出和优化的。模型框架如下:
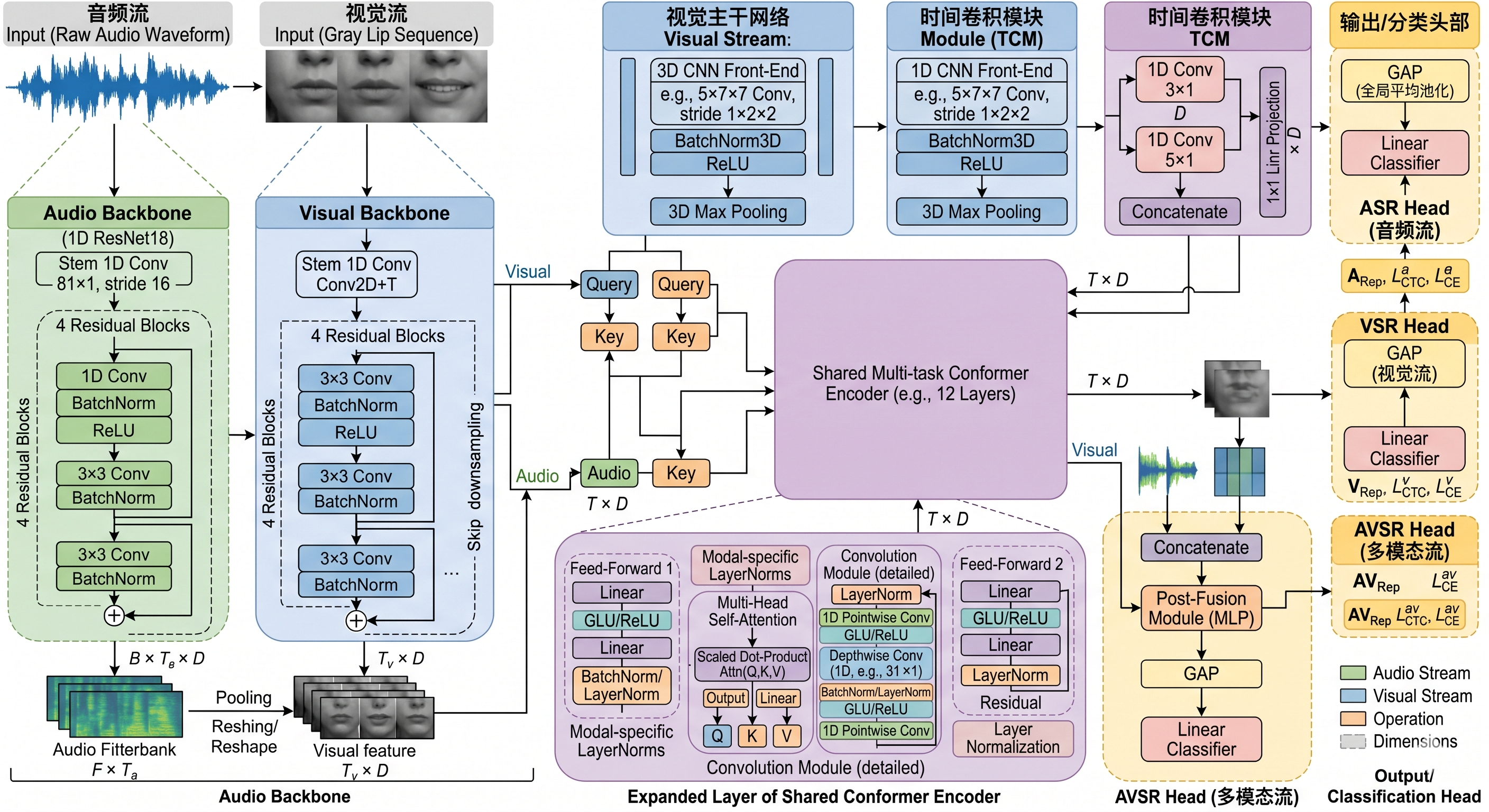
图-1 MultiAVSR 模型框架图(来源:原论文 Figure 1)
其中,音频的 Backbone 骨干网络使用 1D-ResNet18,视频的 Backbone 骨干网络使用 3D-CNN 网络结合 2D-ResNet18。各模态特征经过各自的 Backbone 提取后,送入共享的 Conformer Encoder 生成任务特定的特征表示。对于 AVSR 任务,音频和视觉特征会通过 AV MLP Fusion 模块融合后再送入编码器。最终,三个任务的特征分别进入共享的 CTC Projection Layer 和共享的 Transformer Decoder 计算损失和预测文本。
3.2 共享编码器:为什么要让三个任务用同一个 Conformer?
传统的 AVSR 架构(如 Auto-AVSR)通常会为音频和视觉分别设计两个独立的 Conformer Encoder。MultiAVSR 做了一个看似"反直觉"的决定:让 ASR、VSR、AVSR 三个任务共享同一个 Conformer 编码器。
作者的逻辑是:共享参数可以让音频和音视频任务中学到的知识"迁移"到更难的唇读任务中去。反过来,VSR 任务也会迫使编码器提取更鲁棒的特征,从而提升 ASR 和 AVSR 在噪声环境下的表现——这是一个双向受益的过程。
消融实验清晰地展示了共享编码器的效果:
| 配置 | VSR WER | ASR WER | AVSR WER |
|---|---|---|---|
| 单任务 VSR(基线) | 42.0% | — | — |
| 多任务 + 独立编码器 | 41.2%(↓2%) | — | — |
| 多任务 + 共享编码器 + ASR + AVSR | 31.1%(↓26%) | 2.4% | 2.5% |
真正起作用的不是"多任务"本身,而是多任务 + 共享参数的组合。代价是 ASR 和 AVSR 的 WER 分别从 2.3% 略微上升到 2.4%/2.5%,但这个代价完全可以接受——ASR 和 AVSR 本身已经足够强,而 VSR 获得了质的飞跃。
3.3 损失函数:极简设计,吊打复杂方案
损失函数的设计是这篇论文最具启发性的点之一。此前的多任务语音识别工作(USR、RAVEn、BRAVEn 等)无不叠加了大量复杂机制——学生-教师网络、跨模态掩码预测、任务权重调度……MultiAVSR 的做法简单到令人意外:
直接把三个任务的 Hybrid CTC/Attention Loss 加在一起,不设任何任务权重。
公式如下:
Ltotal=λLCTC+(1−λ)LCEL_{total} = \lambda L_{CTC} + (1 - \lambda) L_{CE}Ltotal=λLCTC+(1−λ)LCE
其中:
LCTC=∑i∈{v,a,av}−logpCTC(y∣x(i))L_{CTC} = \sum_{i \in \{v, a, av\}} -\log p_{CTC}(y \mid x^{(i)})LCTC=i∈{v,a,av}∑−logpCTC(y∣x(i))
LCE=∑i∈{v,a,av}−logpCE(y∣x(i))L_{CE} = \sum_{i \in \{v, a, av\}} -\log p_{CE}(y \mid x^{(i)})LCE=i∈{v,a,av}∑−logpCE(y∣x(i))
符号说明:
- x(v),x(a),x(av)x^{(v)}, x^{(a)}, x^{(av)}x(v),x(a),x(av) 分别代表视觉、音频、音视频三种输入的编码特征;
- yyy 为真实文本标注序列,所有任务共享;
- λ=0.1\lambda = 0.1λ=0.1,沿用 Auto-AVSR 的设置。
作者还特意做了权重消融实验——尝试给 ASR 和 AVSR 的损失降权,让 VSR 损失主导训练,结果发现对最终效果几乎没有影响。原因非常深刻:
ASR 和 AVSR 任务简单、收敛快,梯度在训练早期就自然衰减了;而 VSR 任务最难、收敛最慢,它的梯度天然主导了整个优化过程。所以根本不需要手工调权重。
这个洞见揭示了一个优雅的"免费午餐":多任务学习中,任务难度的差异本身就是一种隐式的权重调节机制。
四、实验设置
4.1 数据集
| 数据集 | 时长 | 说明 |
|---|---|---|
| LRS3-TED | 438h(训练+验证) | TED 演讲片段,学术基准 |
| LRS2 | 223h | BBC 电视广播 |
| VoxCeleb2 | 1307h(伪标签) | 原始为说话人识别数据集,用 Whisper large-v3 自动转录 |
论文进行了三个规模实验:438h(仅 LRS3-TED)、661h(加入 LRS2)、1968h(再加入 VoxCeleb2)。
测试集:
- LRS3-TED test(0.9h):学术标准评测集。
- WildVSR(4.8h):YouTube 真实场景视频,包含更大的词汇量、多样的录音条件和说话人种族,专门用于检验模型是否过拟合 LRS3。
4.2 模型规模与训练细节
| 组件 | 参数量 |
|---|---|
| 1D-ResNet18(音频骨干) | 4M |
| 3D-CNN + 2D-ResNet18(视觉骨干) | 11M |
| AV MLP Fusion | 19M |
| Shared Conformer Encoder(12 层) | 170M |
| Shared Transformer Decoder(6 层) | 64M |
| Shared CTC Projection | 4M |
| 总计 | 274M |
Conformer Encoder 配置:12 层,768 输入维度,3072 前馈维度,12 个注意力头。
Transformer Decoder 配置:6 层。
训练流程(两阶段):
- 课程学习预训练:在 LRS3-TED 小于 4 秒的短片段上训练 75 epoch,lr = 7×10⁻⁵。
- 全时长微调:在完整视频上训练 75 epoch,lr = 1×10⁻³。
硬件:8 × A100 GPU,优化器 AdamW + cosine 学习率调度 + 5 epoch warm-up。
4.3 数据预处理与增强
- 视觉:RetinaFace 人脸检测 → 裁剪唇部区域(96×96)→ 灰度化 → 随机裁剪至 88×88(训练)/ 中心裁剪(推理)→ 自适应时间掩码。
- 音频:使用原始波形,不做预处理。训练时施加自适应时间掩码,并从 NOISEX 数据集添加不同信噪比(-5dB 至 20dB)的 babble 噪声。
4.4 外部语言模型
评测时可选用一个预训练的 Transformer LM(54M 参数,在 1.66 亿字符的文本语料上训练),通过 shallow fusion 方式融合解码:
y^=argmaxy∈Y^{λlogpCTC(y∣x)+(1−λ)logpCE(y∣x)+βlogpLM(y)}\hat{y} = \arg\max_{y \in \hat{Y}} \left\{ \lambda \log p_{CTC}(y \mid x) + (1 - \lambda) \log p_{CE}(y \mid x) + \beta \log p_{LM}(y) \right\}y^=argy∈Y^max{λlogpCTC(y∣x)+(1−λ)logpCE(y∣x)+βlogpLM(y)}
其中 β=0.2\beta = 0.2β=0.2(经消融实验确定)。
五、实验结果与分析
5.1 VSR 性能:3000 小时公开数据内的 SOTA
MultiAVSR 在 LRS3-TED 测试集上达到 21.0% WER,在所有使用少于 3000 小时公开数据的模型中排名第一:
| 方法 | 训练数据 | WER (%) |
|---|---|---|
| Auto-AVSR (baseline) | 1759h | 22.3 |
| SyncVSR | 1992h | 21.5 |
| USR (semi-supervised multi-task) | 1968h | 21.6 |
| MultiAVSR | 1968h | 21.0 |
与 USR 的正面 PK 尤为精彩:
- WER:21.0% vs 21.6%(MultiAVSR 胜出)
- 参数量:274M vs 503M(仅 54%)
- 训练计算量:47 vs 253 exaFLOPS(仅 18%)
更少的参数、更少的计算、更简单的训练流程,反而拿到了更好的性能。
当然,使用了数万小时专有数据的超大模型仍占优(如 Makino et al. 在 90,000h 上做到 12.8% WER),但 MultiAVSR 在同等数据规模下已是毫无疑问的最强。
5.2 语言模型依赖度:从"必需品"降级为"锦上添花"
这是整篇论文最具实践意义的发现之一。长期以来,VSR 社区对外部 LM 形成了强依赖——几乎每篇论文都会挂一个 LM 来提升预测的语言一致性。但 MultiAVSR 显示,多任务训练让这种依赖大幅降低:
| 方法 | 无 LM WER | 有 LM WER | 相对提升 |
|---|---|---|---|
| SyncVSR (661h) | 30.4 | 28.1 | 7.6% |
| SynthVSR (7100h) | 18.2 | 16.9 | 7.1% |
| USR (1759h) | 22.3 | 21.5 | 3.6% |
| MultiAVSR (1968h) | 21.6 | 21.0 | 2.8% |
MultiAVSR 对 LM 的依赖度仅为 2.8%,而单任务模型的依赖度普遍超过 7%。
这意味着什么?对于实时 VSR 系统,LM 是推理延迟的大头——它占了总参数的 18%,却贡献了 44% 的解码计算量。去掉 LM 可以减少 40% 的推理时间。MultiAVSR 的 2.8% 依赖度意味着:你几乎可以不损失精度地砍掉 LM,从而实现实时唇读。
作者的解释是:多任务训练让模型在 ASR/AVSR 任务中内化了语言规律(因为音频信号包含了完整的语言信息),不再需要外部 LM 来"纠错"。
5.3 WildVSR 泛化性:真实场景的试金石
LRS3-TED 来自 TED 演讲——正式、标准、发音清晰。但真实世界不是 TED。WildVSR 数据集包含了 YouTube 上的真实说话场景,录音条件、口音、词汇变化都更大,是检验模型泛化能力的更好指标。
MultiAVSR 在 WildVSR 上达到 44.7% WER,超越了所有同等数据规模的模型。
更惊人的发现是:MultiAVSR 是首个在 WildVSR 上不加 LM 比加 LM 效果更好的模型(44.7% vs 46.0%,加了 LM 反而涨了 1.3 个百分点)。这对 VSR 领域的长期假设(“外挂 LM 总是有益的”)构成了根本性挑战——当模型通过多任务训练学得足够"聪明",外部 LM 在分布外数据上反而成了干扰。
5.4 噪声鲁棒性:VSR 训练反哺 ASR 和 AVSR
虽然提升 VSR 是 MultiAVSR 的主攻方向,但噪声实验显示多任务训练也让 ASR 和 AVSR 变得更抗噪。实验使用白噪声和粉红噪声,在多种 SNR 条件下对比 MultiAVSR 与 Auto-AVSR 单任务模型:
在 -7.5 dB SNR(噪声强度超过信号)的白噪声条件下:
- MultiAVSR 的 AVSR:14.7% WER
- Auto-AVSR 单任务模型的 AVSR:24.2% WER
MultiAVSR 甚至做到了在 -7.5 dB 噪声下的 AVSR(14.7%)比纯 VSR(21.6%)更好——此时视觉信息已成为主信号。而传统单任务模型在同样的极端条件下已经崩溃(24.2% > 其 VSR 的 19.1%)。
平均来看,MultiAVSR 在全部噪声条件下:
- ASR 相对提升 16%
- AVSR 相对提升 31%
且这些提升是在 MultiAVSR 仅用了 1.75 倍更少训练数据(1968h vs 3448h)的情况下实现的。这说明 VSR 任务的加入迫使模型学到了更鲁棒的音频特征表征。
5.5 训练计算量:47 vs 253 exaFLOPS
| 方法 | 训练范式 | 计算量 (exaFLOPS) |
|---|---|---|
| USR | 自监督预训练 + 半监督微调 | 253 |
| MultiAVSR | 纯监督多任务 | 47 |
MultiAVSR 仅用了 USR 的 18% 计算量,效果还更好。这呼应了 Djilali et al. 的发现:自监督方法不仅计算成本高,在 WildVSR 这类真实场景数据集上的泛化能力反而更差。"大算力堆自监督"不一定是正确方向——巧妙的监督多任务设计可能是更强的范式。
六、讨论与未来方向
作者在论文中坦率地列出了几个有前景的后续方向:
-
利用纯音频数据:当前框架的多任务损失不需要视觉信号也能参与训练。未来可以直接加入海量 ASR 数据(无需合成唇部视频),进一步强化模型的语音理解能力。
-
微调大 ASR 模型:从一个预训练好的大 ASR 模型出发,用 MultiAVSR 的多任务框架进行微调——本质上是给 ASR 模型"装上眼睛"。这与 Afouras et al. “ASR is all you need” 的思路一脉相承,但多任务的方式可以保留更好的泛化性。
-
模型稀疏化:结合网络剪枝或 Mixture-of-Experts,在保持鲁棒性的同时实现真正的实时推理。
-
可解释性分析:多任务训练对网络内部表征的具体影响尚不明确,后续可以通过注意力图可视化等方法深入理解。
七、个人思考与总结
这篇论文改变了什么认知?
读这篇论文最让人舒服的地方在于,它不是靠"堆更多数据、堆更多算力、堆更复杂的训练流程"来刷榜。相反,它是做减法——用共享编码器替掉双编码器,用简单的求和损失替掉复杂的学生-教师框架,用 18% 的算力拿到了更好的效果。
具体来说,它挑战了 VSR 领域的四个默认设定:
| 默认认知 | MultiAVSR 的回应 |
|---|---|
| 唇读数据太少,必须靠自监督预训练 | 把音频数据用好,纯监督多任务就能赢 |
| 音频和视觉必须用两个独立编码器 | 共享编码器 + 多任务训练反而更好 |
| 多任务必须精心调损失权重 | 不需要。任务难度差异就是天然的权重 |
| VSR 必须外挂语言模型 | 可以不挂。多任务训练让模型自己学会语言规律 |
局限性
- 在使用了数万小时专有数据的超大规模模型面前,MultiAVSR 仍有差距(21.0% vs 12.8%),数据量的天花板仍然存在。
- 论文只测试了英语,多语言场景有待验证。
- 共享编码器对 ASR/AVSR 的轻微性能损失(~4-9%),在极端追求 ASR 精度的场景下可能是 concern。
一句话总结
MultiAVSR 用一个共享编码器 + 三个任务求和损失,以 18% 的计算量超越了所有自监督多任务方法,证明了"简单的监督多任务"就是当前 VSR 的最优解。
本博客基于 MultiAVSR 论文(Electronics 2025, 14, 2310)撰写,模型架构图来源于原论文 Figure 1。
码字不易,整理精读更费时间~如果这篇博客对你有收获,麻烦点个赞、收藏、转发支持一下吧!你的鼓励就是我持续更新优质论文精读的动力~
后续还会持续更新更多唇读、AVSR、自监督学习顶会论文精读,欢迎关注不迷路!我们下篇论文见~ 🚀

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)