硅基流动用了半个月,我帮你们测出了这些模型的“真实面目”
大家好,我是笨熊哥。
代金券快用完了,说说哪个模型值得充钱,哪个是“吞金兽”
半个月前,我写了那篇《VS Code零成本接入DeepSeek大模型》,顺便薅了硅基流动的16元代金券。
然后我就开始了“疯狂测试”模式:写代码、总结文本、做小功能、问各种奇葩问题……
今天代金券用得差不多了,我打开账单一看——
好家伙,原来这些模型的路子这么野。
⚠️ 写在前面:以下内容纯属个人使用体验,不构成任何投资建议。模型性能受任务类型、提示词质量、网络环境等多因素影响,你觉得好用就继续用,觉得我在胡扯就当看个乐子。你的钱包你做主。
一、薅羊毛一条龙:从领券到开干(新手必看)
测了半个月,代金券用完了。但我猜,很多朋友可能还没开始——甚至不知道硅基流动有免费代金券,或者领了券不知道咋用。
别慌,我给你们准备了“一条龙服务”:
📌 第一步:先把羊毛薅到手
👉 《硅基流动-免费代金券》(点击跳转)
用我的邀请链接注册,你和我各得 16 元代金券。这是前提,没券后面都白搭。
🔧 第二步:把 Claude Code 配置好
👉 《把 Claude Code 玩明白:VS Code 零成本接入 DeepSeek 大模型》
手把手教你用硅基流动的 API,让 VS Code 里的 AI 编程助手真正跑起来。
🚀 第三步:用我这篇的推荐组合干活
就是你现在看的这篇。哪个模型写代码最省钱?哪个是吞金兽?看完你就有数了。
三篇文章,从“领券”到“配置”到“选模型”,全齐了。
如果你还没领券,先去领;如果你领了但没配置,去看教程;如果你都搞定了,按我这篇的建议开干。
好了,闭环结束。下面开始聊正经的账单和模型。
二、先看账单:半个月我干了什么?
从5月1日到5月16日,我一共用了6个模型,总代金券抵扣¥34.73
有图有真相,给你们上数据和分析。如果你也在纠结“硅基流动到底用哪个模型划算”,这篇文章应该能帮你省点钱。
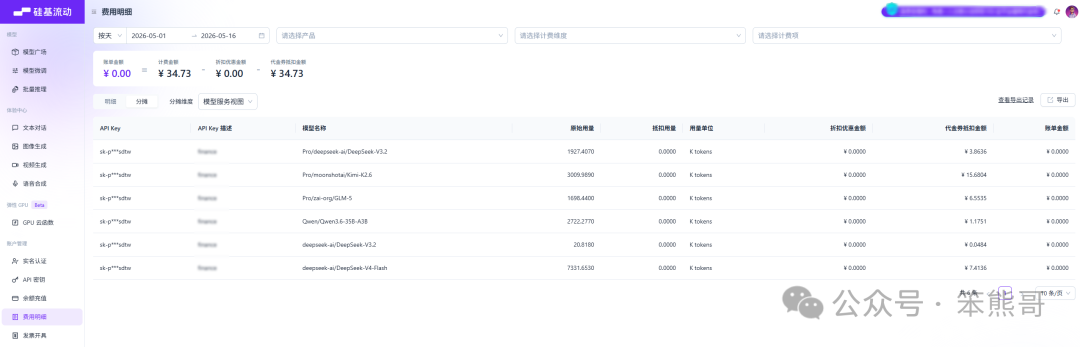
账单简化版(用量 + 花费):
|
模型
|
消耗
|
用途
|
| — | — | — |
|
Pro/deepseek-ai/DeepSeek-V3.2
|
用量 ~1948K tokens,抵扣 ¥3.86
|
文本总结、逻辑推理
|
|
Pro/moonshotai/Kimi-K2.6
|
用量 ~3010K tokens,抵扣 ¥15.68
|
写一个小功能(没成功)
|
|
Pro/zai-org/GLM-5
|
用量 ~1698K tokens,抵扣 ¥6.55
|
代码生成、问答
|
|
Qwen/Qwen3.6-35B-A3B
|
用量 ~2722K tokens,抵扣 ¥1.18
|
日常写代码、注释、重构
|
|
deepseek-ai/DeepSeek-V3.2(普通版)
|
用量 ~21K tokens,抵扣 ¥0.05
|
小测试
|
|
deepseek-ai/DeepSeek-V4-Flash
|
用量 ~7332K tokens,抵扣 ¥7.41
|
批量处理文本、快速问答
|
看到没有?同样的用量,价格能差十几倍。
下面我一个一个说。
三、各模型“人设”大起底
1. Pro/deepseek-ai/DeepSeek-V3.2 —— “性价比之王”
我的感受:
平常做文本总结的时候,非常快。给一段长文档,它能在几秒内输出清晰的结构化总结,逻辑不乱,废话不多。
优点:
速度快,几乎感觉不到延迟
总结能力强,适合处理长文本
价格适中(3000多K tokens只花3块多)
缺点:
创意生成偏保守,不太敢“放飞自我”
复杂推理时偶尔会绕圈子
适合场景:文档总结、信息提取、代码注释生成、常规问答
💡 笨熊哥个人观点(仅供参考):我个人的习惯是,凡是需要“读懂”的任务,优先用 DeepSeek Pro。比如读论文、看长文档、分析日志。它给我的感觉是“理解力在线,不乱加戏”。如果你是做内容整理、知识库问答的,这个模型值得重点考虑。但别指望它给你写段子。
2. Pro/moonshotai/Kimi-K2.6 —— “吞金兽本兽”
我的感受:
我只是做了一个很小的功能(一个简单的Vue组件),它反复思考、反复输出、最后还没完成。我一看消耗,好家伙,3000多K tokens,花了15块多,我赶紧取消了。
优点:
推理链条长,适合复杂逻辑(比如多步数学推导)
对上下文理解较深
缺点:
太费token了。同样一个功能,别的模型可能几百K搞定,它能给你跑出几倍
速度偏慢
有时候思考过度,简单问题复杂化
适合场景:如果你有预算、不介意等、且问题真的极其复杂,可以试试。日常用?建议绕道。
💡 笨熊哥个人观点(仅供参考):Kimi 我是真的怕了。 不是说它不好,它可能确实聪明,但就像请了个每小时收费500块的顾问来帮你改PPT——活能干,但你心疼。我那个小功能最后用 Qwen 几分钟就搞定了,token消耗不到 200K。我的建议是:除非你的问题真的难到其他模型都搞不定,否则别碰 Kimi。 省下来的钱买杯咖啡不香吗?
3. Qwen/Qwen3.6-35B-A3B —— “写代码的老黄牛”
我的感受:
平常我写代码的时候,用它最多。生成函数、写注释、重构逻辑、解释报错……基本都能搞定。消耗也不大,2700多K tokens只花了1块多,简直良心。
优点:
代码生成质量高,尤其擅长前端(Vue/React)
速度快,响应及时
性价比极高,几乎是DeepSeek-V3.2的三分之一价格
对中文指令理解好
缺点:
在非代码任务上(如写文章、创意文案)表现一般
推理深度不如DeepSeek-V3.2
适合场景:日常写代码、调试、重构、代码解释。如果你是开发者,这可能是你的主力模型。
💡 笨熊哥个人观点(仅供参考):Qwen 是我目前的主力,没有之一。 我每天写代码、改 bug、加注释,90% 的任务都丢给它。价格便宜到可以忽略不计,而且响应快,不打断思路。我的建议是:如果你是开发者,优先把 Qwen 设为默认模型。 只有遇到它搞不定的复杂逻辑,再换 DeepSeek Pro。这样最省钱、最高效。
4. Pro/zai-org/GLM-5 —— “均衡型选手”
我的感受:
使用感受不是特别好。写代码能写,总结能做,问答能答,但跟其他模型比起来,总感觉差了点什么。我也说不出哪里不对,就是不太想用它。
我去查了一下网上其他人的评价,发现我不是一个人。
优点:
-
综合能力均衡,没有明显短板
-
参数量达到744B,在SWE-bench等编程榜单上表现不错,编程能力逼近Claude Opus 4.5
-
价格适中(和DeepSeek-V3.2差不多)
缺点:
-
“吃token”大户。官方自己都承认,GLM-5高峰期消耗是普通模型的3倍、非高峰期2倍,上线后大量用户反馈“消耗变快了”
-
价格优势不明显。官方提价后,性价比更低
-
轻量级任务用GLM-5性价比很低,官方建议日常简单任务优先用GLM-4.7
适合场景:复杂系统工程、长程智能体任务,但不适合日常轻量级开发
💡 笨熊哥个人观点(仅供参考):
网上一搜,不少开发者吐槽GLM-5“消耗太快”。有开发者花了80刀买了Coding Pro套餐,结果半天跑满限额,bug还没修好。还有个细节很有意思:因为用户投诉太多,智谱官方专门发了道歉信,承认“规则透明度不够”“老用户升级机制设计粗糙”,还给出了退款和补偿方案——这种级别的官方道歉在大模型圈不多见,说明问题不是个例。
一句话总结:GLM-5能力强,但吃得多。你如果跟我一样日常写写代码、做做总结,没必要用它。真要搞复杂系统工程的时候再考虑。
5. deepseek-ai/DeepSeek-V4-Flash —— “快枪手”
我的感受:
用量最大(7332K tokens),但只花了7块多。速度飞快,适合批量处理。
优点:
速度极快,几乎无感
价格便宜
适合高并发、大批量任务
缺点:
输出质量不如Pro版稳定
复杂任务容易出错
适合场景:批量文本分类、关键词提取、简单问答、数据清洗。不适合需要深度推理的任务。
💡 笨熊哥个人观点(仅供参考):V4-Flash 是我的“搬砖工具”。比如我要从 1000 条评论里提取关键词,或者批量给代码加注释,这种重复性高、对质量要求不那么精细的任务,闭着眼睛用 Flash。速度快到飞起,价格便宜到想哭。但千万别用它写核心逻辑,它会在你意想不到的地方翻车。
四、我的推荐组合(省钱又高效)
根据半个月的实测,我现在的“主力配置”是:
|
任务类型
|
推荐模型
|
理由
|
| — | — | — |
| 日常写代码 |
Qwen/Qwen3.6-35B-A3B
|
便宜、快、代码质量高
|
| 文本总结/逻辑推理 |
Pro/deepseek-ai/DeepSeek-V3.2
|
总结能力强,价格合理
|
| 批量快速处理 |
deepseek-ai/DeepSeek-V4-Flash
|
快、便宜,适合机械化任务
|
| 复杂长链推理 |
慎用Kimi,除非预算充足
|
太费token,除非你真的需要
|
| 不想动脑子选 |
Pro/zai-org/GLM-5
|
保底选择,啥都能干一点
|
核心原则:简单任务用Flash,代码用Qwen,总结用DeepSeek Pro,复杂推理尽量少碰。
💡 笨熊哥再次强调:以上组合仅代表我个人习惯,不一定适合所有人。比如你是做数学题、写学术论文的,可能 Kimi 真的更有用。建议你先用小额代金券自己测一测,找到最适合你工作流的模型组合。
五、给新手的一个小建议
如果你刚注册硅基流动,领了16元代金券:
先用Qwen:写代码、问问题、测试功能,消耗小,够你用很久。
别一上来就玩Kimi:除非你钱多,否则你会看到代金券像流水一样消失。
批量任务用Flash:速度快,价格低,适合一次性处理大量简单问题。
DeepSeek Pro留作“高级工具”:遇到需要深度总结、复杂推理的任务再用。
💡 个人观点:别被“Pro”、“最强”这些词忽悠。适合你钱包的,才是最好的。 我见过有人用 Flash 干掉了 90% 的工作,也见过有人非 Kimi 不用结果月底账单爆炸。理性消费,按需选择。
六、最后说一句
半个月测下来,我发现一个道理:
没有最好的模型,只有最适合你钱包和任务的模型。
硅基流动的好处是,你可以自由切换,不用被一家绑定。坏处是,如果你不看账单,可能月底会收到惊喜(或惊吓)。
我的代金券快使用完了,我还会继续用Qwen和DeepSeek Pro——因为他们真的能帮我干活,而且不贵。
你呢?你平时用什么模型?有没有被哪个“吞金兽”坑过?
评论区说真话,我不删评。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)