深度学习篇---梯度消失与梯度爆炸
梯度消失和梯度爆炸是训练深层神经网络时常遇到的“拦路虎”。它们本质上是一个问题的两个极端表现,根源都在于反向传播时,梯度在深层网络中连续相乘所导致的不稳定性。
🧠 背景:训练网络就是“下楼梯找山脚”
为了理解这两个概念,我们先做个比喻:
把训练网络想象成在一个大雾天的崇山峻岭里蒙眼下山,目标是走到山脚(损失最小点)。你每一步的方向和大小,都由脚下的“梯度”(斜率)决定。
-
梯度就是你脚下的路况信息,告诉你哪个方向最陡峭,该往哪走、迈多大的步子。
所谓反向传播,就是从山顶(输出层)往山脚(输入层),一层一层地把“路况信息”(误差信号)往回传,让每一层都知道该如何调整自己的参数。
📉 梯度消失:路况信息越来越弱,寸步难行
通俗理解:从山顶往山脚传路况信息,结果消息传着传着就衰减没了。越靠近山脚的层,越收不到任何有效的路况信息。它们根本不知道该往哪走,也无法更新自己,整个网络的训练就停滞了。
原因:
主要是由特定的激活函数和不恰当的权重初始化造成的。典型的“元凶”是 Sigmoid 和 Tanh 这类饱和激活函数。
-
Sigmoid函数:它的导数最大值也只有 0.25。在反向传播的链式法则中,每经过一层Sigmoid,梯度就要乘以一个小于0.25的数。当网络很深时,几十上百个这样的小数连乘,梯度就会指数级地衰减,最终无限趋近于0。
-
类比:就像古代的驿站传信,每过一个驿站,信的内容就丢失四分之三。经过几十个驿站后,最终到达的信件只剩一张白纸了。
📈 梯度爆炸:路况信息急剧失控,地震山崩
通俗理解:与消失相反,路况信息在往回传时,被一层层地无限放大。越靠近山脚的层,收到的信号越离谱(比如10000倍的正常斜率)。这会导致模型参数被巨大地更新,引发数值溢出或剧烈震荡,模型像遭受了“地震”一样崩溃。
原因:
主要由不恰当的权重初始化或过高的学习率造成。
-
如果网络权重的初始值太大(比如都大于1),那么在链式法则的连乘过程中,一个大数乘以一个大数,梯度就会指数级地暴涨。
-
类比:还是驿站传信,但这次每个驿站都脑洞大开,把信的内容添油加醋放大十倍。经过几十个驿站,一封简单的信就变成了一部情节离奇的鸿篇巨著,完全失真了。
🔗 两者关系:一对“难兄难弟”,都源于梯度的不稳定
梯度消失和爆炸是一对“难兄难弟”,它们的核心关联在于:
-
根源相同:都源于深度网络中梯度的链式连乘效应。深层网络的层级结构,放大了参数更新过程中的任何微小偏差,让它要么指数衰减,要么指数增长。
-
阻碍相同:它们都会导致模型无法有效学习。一个是让网络学不动(消失),一个是让网络学崩溃(爆炸),最终都让模型性能变得很差。
-
关注点相同:问题都更容易出现在网络的浅层(靠近输入层)。因为这些层在反向传播的链式法则末端,累积的连乘效应最严重。
-
解决方案共享:很多方法对两者都有效,因为它们都是在修复不稳定的梯度流。比如用ReLU激活函数、更好的权重初始化、批归一化、梯度裁剪等。
🛠️ 解决方法速览
-
换激活函数:用ReLU及其变体(Leaky ReLU, ELU等)替代Sigmoid/Tanh。ReLU在正数区间的导数为1,直接打破了连乘衰减的魔咒,是缓解梯度消失的主流方法。
-
归一化技术:批归一化(Batch Normalization) 能将每层输入强行拉回均值0、方差1的稳定分布,让梯度始终在合理范围内。
-
更好的权重初始化:用Xavier初始化或He初始化,在训练开始时就让每一层的输入输出方差保持一致,避免梯度在初始就过大或过小。
-
梯度裁剪:针对梯度爆炸的“急救措施”,设定一个阈值,当梯度的模长超过这个值时,就强制将其缩放到阈值,防止它“炸”上天。
-
残差连接:ResNet中的“高速公路”,它给梯度提供了一条可以无损反向传播的通道,让原本可能消失的梯度和正常路径“叠加”,确保了深层网络也能有效训练。
📊 Mermaid总结框图
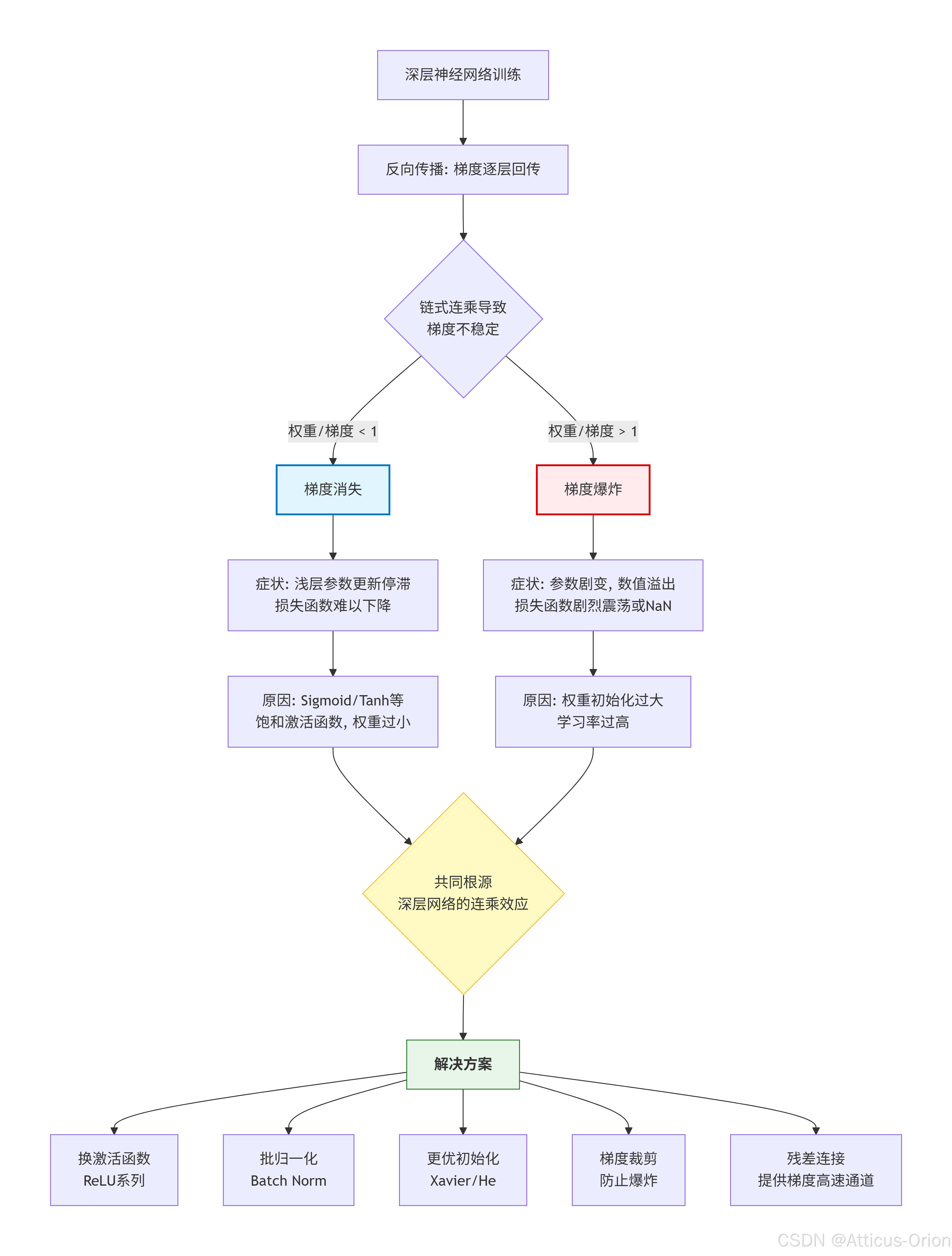
梯度消失和爆炸就像是深层网络训练中的“冰与火之歌”,一个让学习冻结,一个让学习焚毁。而上述的解决方案,正是我们为网络披上的“冰火免疫”装备,让它能稳定地向着最优点一步步前进。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)