AGI 需要身体:从 Manus 到企业 Agent Runtime
AGI 需要身体:从 Manus 到企业 Agent Runtime

如果 base model 是 AGI 的大脑,那么 Agent Runtime 就是 AI 进入真实世界的身体。
1. 一个越来越清晰的判断
最近我对 Agent 方向有一个越来越强的感受:
大模型本身当然重要,但下一阶段真正拉开应用差距的,可能不只是 base model,而是围绕模型构建出来的 Agent Runtime。
换句话说,base model 解决的是“能不能思考”,Agent Runtime 解决的是“能不能做事”。
如果 base model 是 AGI 的大脑,那么 Manus 这类通用 Agent Runtime,就是 AGI 在电脑里的身体;而企业 Agent Runtime,则是 AGI 在企业业务系统里的身体。
这不是一个纯比喻。它背后对应的是一整套工程系统:上下文、记忆、检索、工具调用、任务状态、权限控制、过程追踪、质量评测和人工审批。
2. 只有大脑是不够的
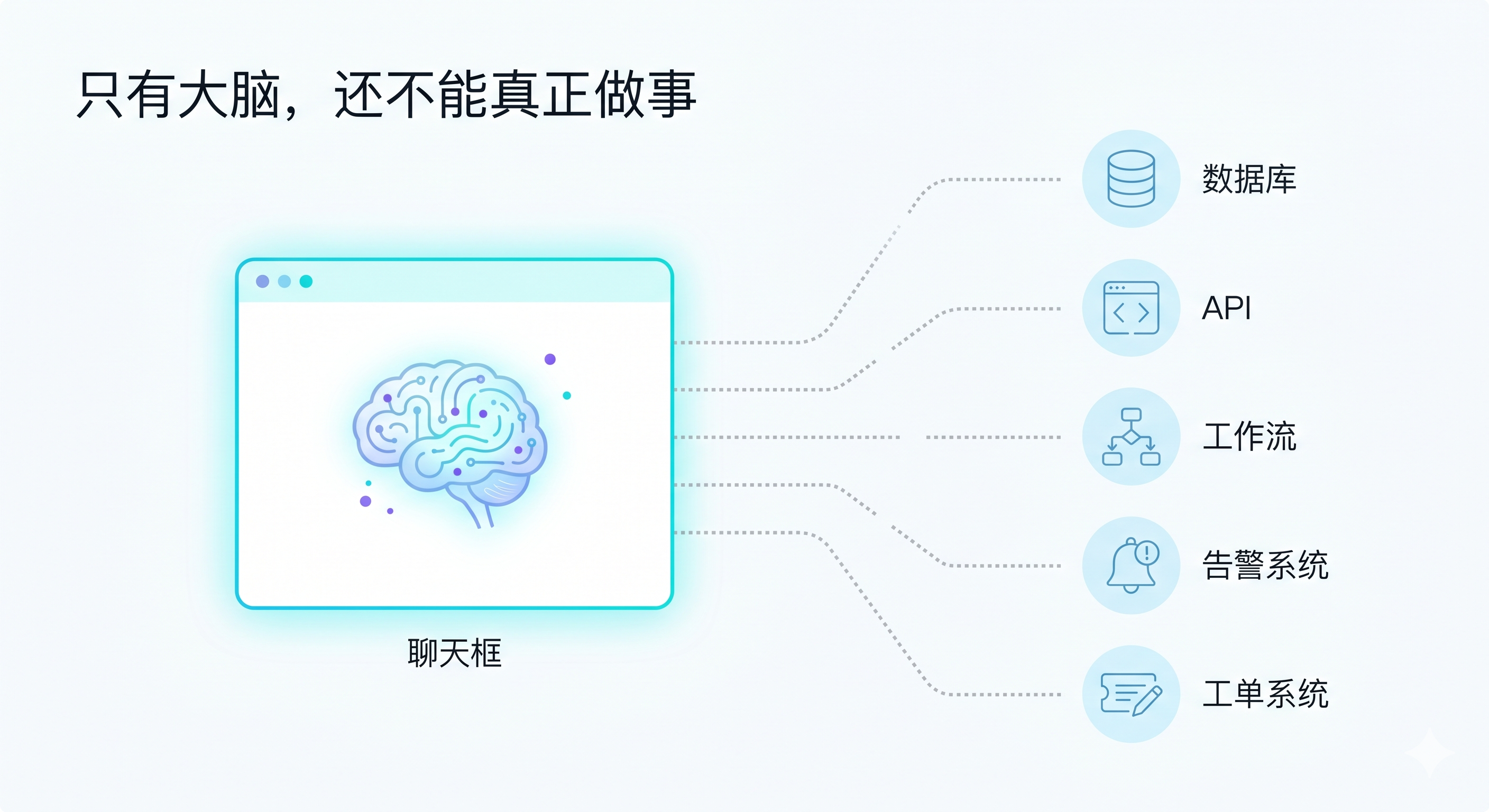
过去一年,大家对 base model 的关注非常高。模型会不会推理、会不会写代码、会不会多模态、上下文窗口有多长、工具调用能力有多强,这些当然都是核心指标。
但从工程落地角度看,一个再强的模型,如果只能停留在聊天框里,它仍然只是一个“会说话的大脑”。
它可以回答问题,可以写计划,可以生成代码,也可以模拟专家分析。但它不能天然知道企业系统里的实时状态,不能直接查询数据库,不能访问告警系统,不能创建工单,也不能在高风险操作前自动接入审批流程。
所以真实应用里会出现一个很关键的分层:
| 层次 | 主要解决的问题 |
|---|---|
| Base Model | 语言理解、推理、生成、泛化 |
| Context / RAG | 让模型拿到当前任务需要的知识和事实 |
| Tool Runtime | 让模型能够访问外部系统和执行动作 |
| Orchestrator | 决定下一步该检索、调用工具、追问还是生成 |
| Permission / Audit | 控制边界,留下过程记录 |
| Eval / Observability | 判断结果质量,支撑持续改进 |
从这个角度看,Agent 不是简单的 LLM + Tools。工具调用只是其中一环,真正难的是让模型在一个可控、可追踪、可评测的环境里持续做事。
3. Manus 类产品的本质:给模型一个电脑里的身体
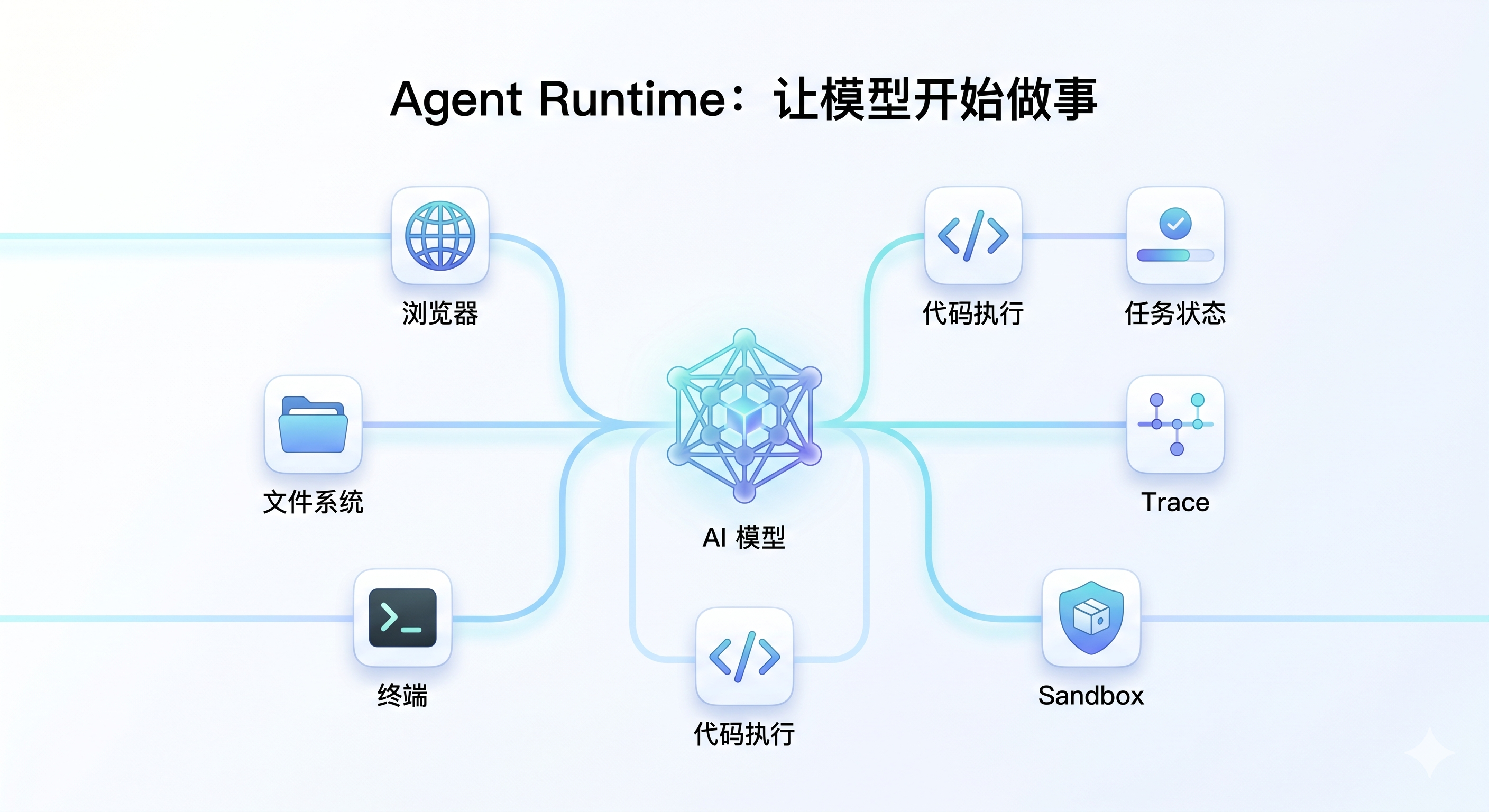
Manus 这类产品让人兴奋的地方,不只是“模型回答更聪明”,而是它把模型放进了一个可执行环境。
在这个环境里,浏览器、文件系统、Shell、代码执行环境、任务状态、trace、sandbox 这些能力组合在一起,让模型开始具备“在电脑里做事”的能力。
可以把它理解成下面这条链路:
这个 Runtime 的价值在于:模型不再只是一次性回答,而是可以围绕目标持续推进任务。
例如:
- 检索资料
- 阅读网页
- 整理文件
- 编写代码
- 运行脚本
- 观察执行结果
- 根据错误调整方案
- 最终生成报告或交付物
这就是从“回答者”到“执行者”的变化。
4. 什么是 Agent Runtime?
我理解的 Agent Runtime,不是某个模型,也不是某个单独的工具调用框架。
它是一套让模型 可执行、可控、可观察、可评测 的运行系统。
一个相对完整的 Agent Runtime,通常至少包含这些部分:
| 能力 | 说明 |
|---|---|
| Memory | 记录用户、项目、任务状态和长期偏好 |
| RAG | 从外部知识库检索与当前问题相关的资料 |
| Context Builder | 把检索结果、任务状态和约束组装成上下文 |
| Tool Runtime | 调用 API、数据库、浏览器、Shell、内部系统 |
| Orchestrator | 进行意图识别、步骤规划、工具路由和失败恢复 |
| Permission | 控制模型能看什么、能调用什么、能不能执行写操作 |
| Trace | 记录每一步输入、检索、工具调用、输出和异常 |
| Eval | 判断回答质量、引用质量、工具调用质量和业务正确性 |
| Human Approval | 在高风险动作前引入人工确认 |
这里面最容易被低估的是 Context Builder、Trace 和 Eval。
很多系统一开始只关注“模型能不能调用工具”,但真正上线后会发现,问题往往出在:
- 检索结果不对
- 上下文拼接不稳定
- 工具参数缺失
- 权限边界不清晰
- 出错后无法复盘
- 不知道回答质量到底有没有变好
这些问题都不是简单换一个更强的 base model 就能完全解决的。
5. 企业 Agent Runtime:AI 在业务系统里的身体
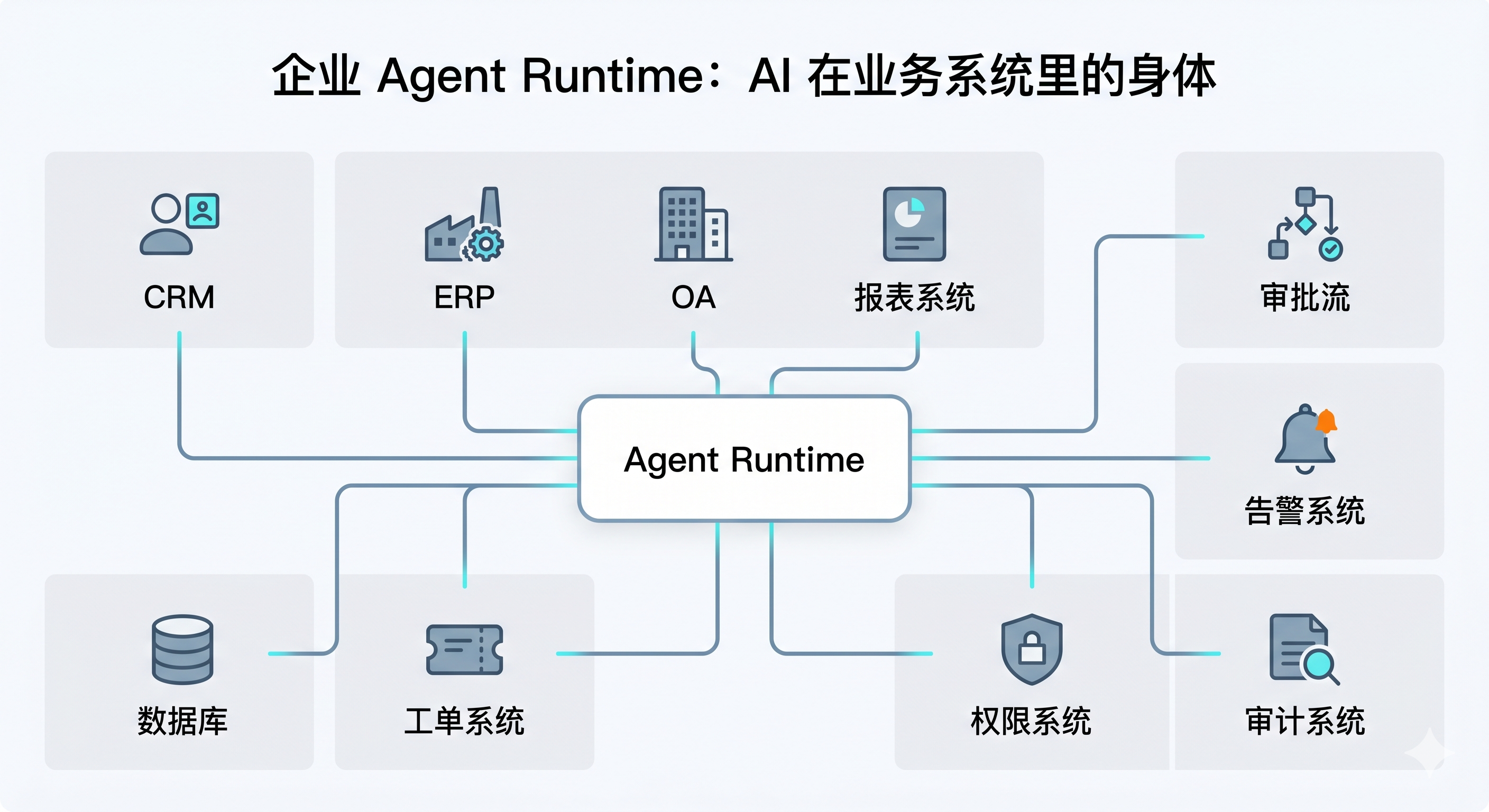
通用 Agent Runtime 操作的是电脑,企业 Agent Runtime 操作的是业务世界。
企业里的“身体”要复杂得多。它不是只有浏览器、文件和 Shell,而是要连接企业自己的业务系统:
- CRM
- ERP
- OA
- 工单系统
- 告警系统
- 数据库
- 报表系统
- 审批流
- 权限系统
- 审计系统
以一个监测报警平台为例。
用户问:
今天有哪些高优先级告警?
裸模型无法直接回答,因为答案不在模型参数里,而在实时业务系统里。一个企业 Agent Runtime 需要做的是:
- 判断这是业务数据查询,不是普通知识问答。
- 检查当前用户是否有查询权限。
- 调用告警查询 API 或数据库查询服务。
- 获取今天的实时告警数据。
- 必要时检索告警规则、指标口径和处理 SOP。
- 组织成用户能理解的结果。
- 记录工具调用、引用来源、输入输出和 trace。
如果用户继续问:
为什么今天 CPU 相关告警这么多?
这时系统就不能只查数据了。它还需要把真实告警数据和知识库里的规则、指标定义、处理 SOP 结合起来,生成一个可追溯的分析结果。
这类场景说明,企业 Agent Runtime 的核心不是“让模型会聊天”,而是让模型在企业权限、流程和审计边界内连接业务系统。
6. 从 AI 知识库到企业业务 Agent
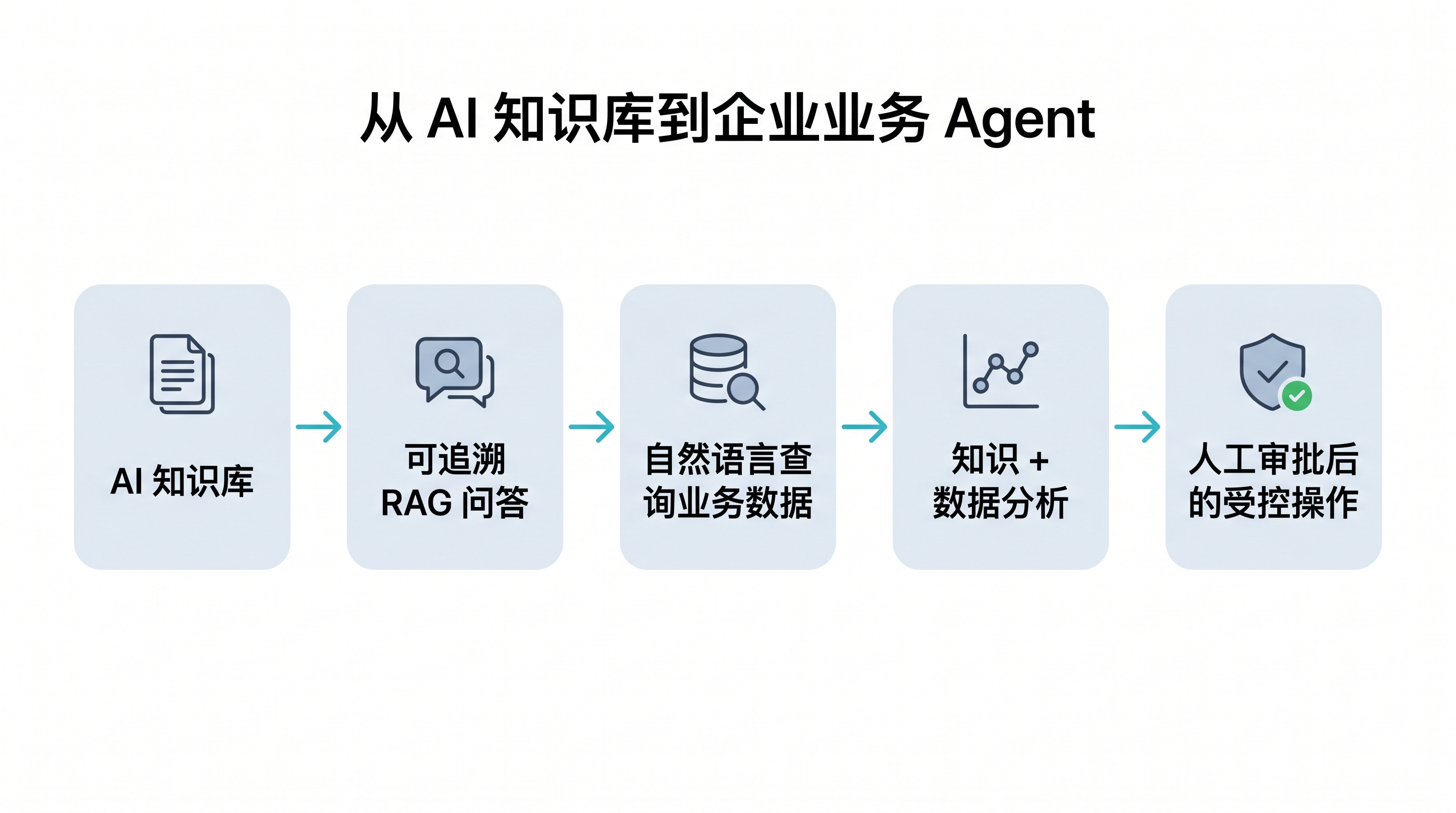
很多企业做 AI 应用,会从知识库问答开始。这是合理的,因为知识库问答风险较低,边界清晰,也容易验证。
但如果只停留在知识库问答,AI 的价值会被限制在“解释文档”这一层。
我更倾向于把它看成一条演进路径:
第一阶段,用户问“这个告警是什么意思?”系统通过 RAG 找到规则和文档,然后生成回答。
第二阶段,用户问“今天有哪些告警?”系统需要查询真实业务数据。
第三阶段,用户问“为什么某类告警突然增多?”系统需要结合业务数据、指标定义、历史趋势和处理 SOP 做分析。
第四阶段,用户说“帮我生成处理建议,必要时创建工单。”系统就需要进入受控操作阶段,高风险动作必须经过权限判断和人工审批。
这条路径里,RAG 是第一块拼图,但不是终点。后面一定会引入 Tool Runtime、Orchestrator、Permission、Trace、Eval 和 Human Approval。
7. 一个更工程化的 Agent Runtime 架构
如果把企业 Agent Runtime 抽象成架构,它大概会长这样:
这里有几个关键点:
第一,知识问答和业务操作要分层。
知识问答主要处理文档、规则、SOP、FAQ。业务操作则涉及实时数据、业务 API、状态变更和审批流程。两者可以协同,但不能混成一个不可控的大 prompt。
第二,工具调用前必须有权限判断。
企业场景里,读操作和写操作的风险完全不同。查询告警、生成建议、创建工单、关闭告警、触发审批,这些动作应该有不同的权限等级。
第三,Trace 是生产级 Agent 的基础设施。
没有 trace,就不知道模型检索了什么、调用了什么工具、为什么生成这个答案、错误发生在哪一步。系统一旦进入业务操作,trace 就不是可选项。
第四,Eval 不能只靠模型自评。
业务正确性、权限合规、工具调用结果、引用来源完整性,很多都可以通过规则或人工样本集来评测。LLM-as-judge 可以辅助,但不应该成为唯一裁判。
8. 为什么护城河不只是 base model
base model 仍然非常重要。它决定了语言能力、推理能力、代码能力和泛化能力。
但在企业应用里,真正难的经常不是“模型会不会说”,而是:
- 能不能拿到正确知识
- 能不能理解企业自己的流程
- 能不能访问正确系统
- 能不能遵守权限边界
- 能不能记录完整过程
- 能不能在错误后被复盘
- 能不能通过 eval 持续改进
这些问题不是单个 base model 能独立解决的。
越强的模型,越需要更强的 runtime。因为模型越强,它能做的事越多;而它能做的事越多,系统就越需要边界、状态、追踪、评测和审批。
一个聪明的大脑,如果没有可靠身体,仍然会被困在聊天框里。
9. 给工程师的落地建议
如果要从工程角度切入企业 Agent,我建议不要一上来就做一个“大而全”的自主 Agent。
更稳的路径是:
- 先做知识库和 RAG 问答,解决文档质量、metadata、权限过滤、引用溯源和 bad case 评测。
- 再做只读业务查询,例如通过自然语言查询告警、工单、报表、指标。
- 然后做分析型 Agent,把业务数据和知识库结合起来,生成可追溯分析。
- 最后再做受控操作,例如创建工单、生成审批草稿、触发流程,但必须有权限和人工确认。
对应的能力建设顺序可以是:
- Knowledge Curation:资料整理、切分、metadata、版本和审核。
- RAG Runtime:检索、rerank、上下文构建、引用和幻觉控制。
- Tool Runtime:API 接入、参数校验、异常处理和幂等控制。
- Orchestrator:意图识别、任务路由、状态机和失败恢复。
- Observability:trace、日志、评测集、线上反馈和质量看板。
- Governance:权限、审批、审计和数据安全。
这个顺序比较适合 Java 后端工程师切入,因为它本质上是一个工程系统,而不是只会调 prompt。
10. 结语
未来的 AI 竞争,不只会是大脑之争,也会是身体之争。
Base Model 是大脑,Agent Runtime 是身体。通用 Agent Runtime 让 AI 能操作电脑,企业 Agent Runtime 让 AI 能进入企业业务系统。
谁能把这个身体做好,谁就能让智能真正进入业务流程。
这也是我认为 Agent Runtime 值得重点关注的原因:它不是一个短期概念,而是大模型从“会回答”走向“能做事”的工程底座。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)