黑马ai大模型笔记(自用,比较粗糙)
以补充知识点回看为主,比较简略。赶时间不整序号了(就很混乱),等找到实习回来就标,就更好看了。
----
目录
1. 通用提示词 (Zero-Shot PromptTemplate)
2. 少样本提示词 (FewShotPromptTemplate)
4. 聊天提示模板 (ChatPromptTemplate)
对话历史记忆 (RunnableWithMessageHistory)(短期存储)
附加历史记录功能(RunnableWithMessageHistory)
一、基于文件的长期会话记忆(FileChatMessageHistory)
使用示例(结合 RunnableWithMessageHistory)
补充:文本分割器(RecursiveCharacterTextSplitter)
1 llm核心概念
-
LLM 大语言模型:处理纯文本字符串的输入与输出
-
Chat 聊天模型:处理结构化消息对象(
SystemMessage/HumanMessage/AIMessage) -
Embedding 文本嵌入模型:将文本转换为向量,用于相似度检索
大语言模型 & 聊天模型
支持阿里云千问、本地 Ollama 两种接入方式;聊天模型支持字典简化写法、官方规范消息类两种结构化消息格式。
# 1. 阿里云千问 LLM(纯文本大语言模型)
from langchain_community.llms.tongyi import Tongyi
model = Tongyi(model="qwen-max")
res = model.invoke(input="你好")
print(res)
# 2. 本地 Ollama LLM
from langchain_ollama import OllamaLLM
ollama_model = OllamaLLM(model="llama3")
res = ollama_model.invoke(input="你好")
print(res)
# 3. 阿里云千问 Chat(聊天模型)
from langchain_community.chat_models.tongyi import ChatTongyi
chat_model = ChatTongyi(model="qwen3-max")
res = chat_model.invoke(input="你好")
print(res.content) # 聊天模型必须提取 content 字段
# 4. 本地 Ollama Chat
from langchain_ollama import ChatOllama
chat_ollama = ChatOllama(model="llama3")
res = chat_ollama.invoke("你好")
print(res.content)
结构化消息格式(两种写法)
# 写法1:字典格式(无需导入消息类,简化写法)
messages = [
{"role": "system", "content": "你是一个贴心的AI助手"},
{"role": "user", "content": "你好"}
]
# 写法2:官方规范消息类(推荐,统一对话格式)
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
messages = [
SystemMessage(content="你是一个专业的Python助手,回答简洁清晰"),
HumanMessage(content="什么是列表推导式?"),
AIMessage(content="列表推导式是Python快速创建列表的语法")
]
文本嵌入模型 (Embedding)
核心方法:embed_query(单次字符串转换)、embed_documents(批量列表转换);兼容阿里云千问、本地 Ollama 模型。
# 阿里云千问嵌入模型
from langchain_community.embeddings import DashScopeEmbeddings
embed_model = DashScopeEmbeddings(model="text-embedding-v1")
# 单次文本嵌入
vec = embed_model.embed_query("我喜欢你")
# 批量文本嵌入
vecs = embed_model.embed_documents(["我喜欢你", "我讨厌你"])
# 本地 Ollama 嵌入模型
from langchain_ollama import OllamaEmbeddings
embed = OllamaEmbeddings(model="qwen3-embedding")
print(embed.embed_query("我喜欢你"))
print(embed.embed_documents(['我喜欢你', '晚上吃啥']))
模型接入 API 汇总表
| 方式 | LLMs 大语言模型 | 聊天模型 | 文本嵌入模型 |
|---|---|---|---|
| 阿里云千问 | from langchain_community.llms.tongyi import Tongyi | from langchain_community.chat_models.tongyi import ChatTongyi | from langchain_community.embeddings import DashScopeEmbeddings |
| Ollama 本地模型 | from langchain_ollama import OllamaLLM | from langchain_ollama import ChatOllama | from langchain_ollama import OllamaEmbeddings |
| 核心调用方法 | invoke (批量) /stream (流式) | invoke (批量) /stream (流式) | embed_query (单次) /embed_documents (批量) |
二、模型调用方式 (Invoke & Stream)
所有模型统一调用接口:
invoke:一次性调用,返回完整结果stream:流式输出,逐块返回结果(打字机效果)
from langchain_community.chat_models.tongyi import ChatTongyi
model = ChatTongyi(model="qwen3-max")
# 1. invoke 一次性调用
res = model.invoke("你好")
print("invoke 结果:", res.content)
# 2. stream 流式输出
print("stream 结果:", end="")
for chunk in model.stream("你好"):
print(chunk.content, end="")
三、提示词工程 (Prompt Engineering)
1. 通用提示词 (Zero-Shot PromptTemplate)
支持模板变量注入、链式调用;无需示例,直接让模型完成任务。
from langchain_core.prompts import PromptTemplate
from langchain_community.llms.tongyi import Tongyi
# 创建提示词模板
prompt_template = PromptTemplate.from_template(
"我的邻居姓{lastname},刚生了{gender},帮忙起名字,请简略回答。"
)
# 变量注入,生成最终提示词
prompt_text = prompt_template.format(lastname="张", gender="女儿")
# 调用模型生成结果
model = Tongyi(model="qwen-max")
res = model.invoke(input=prompt_text)
print(res)
2. 少样本提示词 (FewShotPromptTemplate)
结构:前缀说明 + 示例数据 + 后缀问题;通过示例引导模型按指定格式回答。
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
# 1. 定义单个示例的模板
example_template = PromptTemplate.from_template("单词: {word}, 反义词: {antonym}")
# 2. 准备示例数据
examples = [{"word": "上", "antonym": "下"}, {"word": "左", "antonym": "右"}]
# 3. 构建少样本提示词模板
few_shot_template = FewShotPromptTemplate(
example_prompt=example_template,
examples=examples,
prefix="告知我单词的反义词,我提供如下示例:",
suffix="基于前面的示例,{input_word}的反义词是?",
input_variables=["input_word"]
)
# 调用并打印最终提示词
print(few_shot_template.invoke({"input_word": "左"}).to_string())
3. 模板类 format 和 invoke 方法\
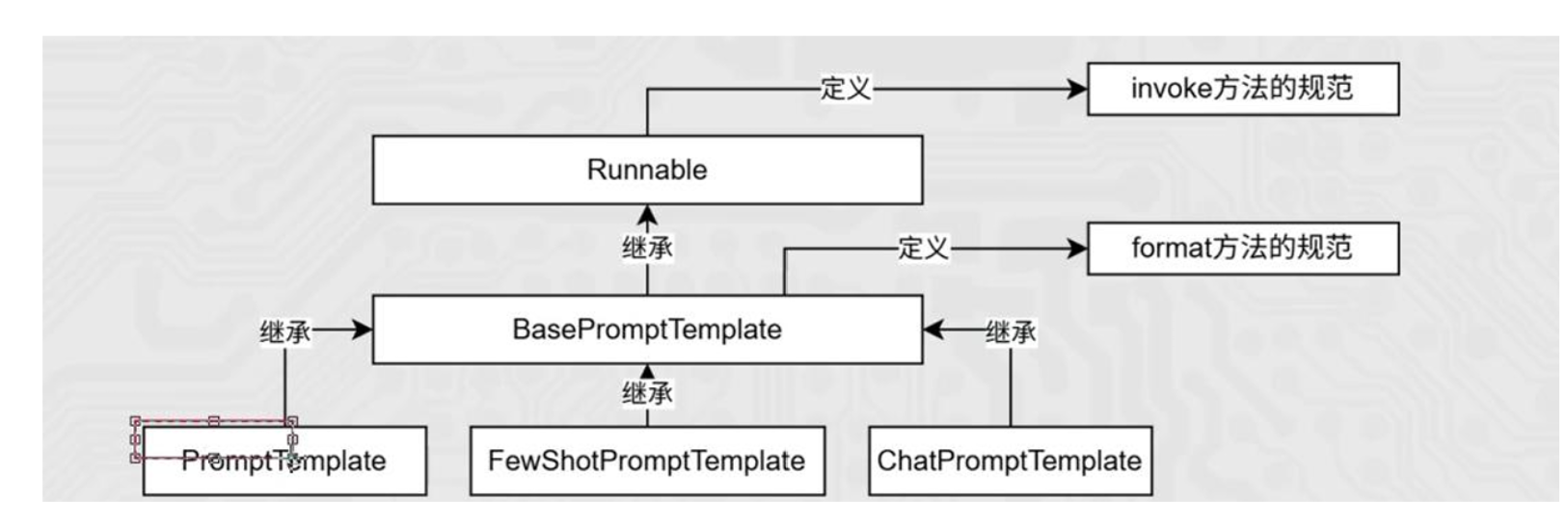
format():纯字符串替换,返回字符串invoke():Runnable 标准接口,返回PromptValue 对象(更适配链式调用)
from langchain_core.prompts import PromptTemplate
# 创建模板
template = PromptTemplate.from_template("帮我为姓{lastname}的{gender}起个名字")
# format 方法:返回字符串
str_prompt = template.format(lastname="张", gender="女儿")
print("format 结果:", str_prompt, type(str_prompt))
# invoke 方法:返回 PromptValue 对象
prompt_value = template.invoke({"lastname": "张", "gender": "女儿"})
print("invoke 结果:", prompt_value.to_string(), type(prompt_value))其中:
| 区别 | format | invoke |
|---|---|---|
| 功能 | 纯字符串替换,解析占位符生成提示词 | Runnable 接口标准方法,解析占位符生成提示词 |
| 返回值 | 字符串 | PromptValue 类对象(可通过.to_string()方法转换为字符串) |
| 传参 | .format(k=v, k=v, ...)(关键字参数) |
.invoke({"k":v, "k":v, ...})(必须传入字典) |
| 解析 | 仅支持解析{}基础占位符 |
支持解析{}基础占位符 和 MessagesPlaceholder结构化占位符 |
from langchain_core.prompts import PromptTemplate
template = PromptTemplate.from_template("帮我为姓{lastname}的{gender}起个名字")
# 使用 format (返回字符串)
str_prompt = template.format(lastname="张", gender="女儿")
# 使用 invoke (返回 PromptValue)
prompt_value = template.invoke({"lastname": "张", "gender": "女儿"})4. 聊天提示模板 (ChatPromptTemplate)
专门用于处理多轮对话历史。
-
特点:支持
MessagesPlaceholder(创建类方法),提供history(对象)作为占位的key,可以动态注入历史消息列表。 -
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder # from_messages 接收一个消息列表,支持结构化占位符 chat_prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个起名专家"), MessagesPlaceholder(variable_name="history"), # 动态历史记录 ("human", "{input}") ]) #之后必须使用invoke,format无法注入。链式调用 (Chain)
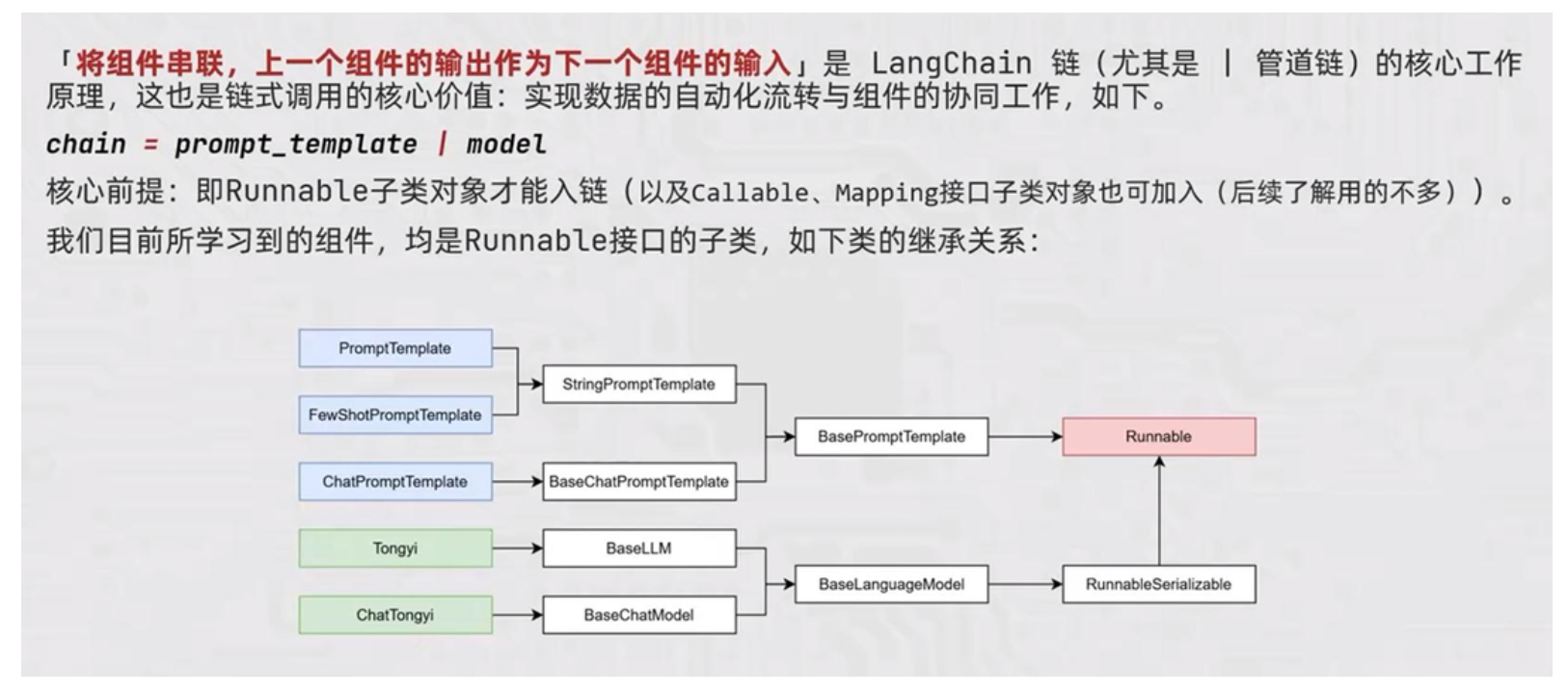
1. 基础链式调用 (| 管道符)
利用 | 运算符(类比 Linux 管道符)将 LangChain 组件串联,前一个组件的输出自动作为后一个组件的输入;使用前提:所有组件必须是 Runnable 接口的子类;StrOutputParser
作用:将模型输出的 AIMessage 对象转换为纯字符串,适配下游组件。
from langchain_core.prompts import PromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.output_parsers import StrOutputParser
# 定义核心组件
prompt = PromptTemplate.from_template("翻译成英文: {text}")
model = ChatTongyi(model="qwen3-max")
parser = StrOutputParser()
# 管道符组建链式调用
chain = prompt | model | parser
# 执行链
result = chain.invoke({"text": "你好"})
print(result)
2. 复杂链式编排与数据转换
链式调用中常出现数据格式不匹配问题:模型输出是 AIMessage 对象,但下游提示词模板需要 dict 字典格式输入。
提供两种标准解决方案:
解决方案 A:使用 RunnableLambda 包装函数
from langchain_core.runnables import RunnableLambda
from langchain_core.prompts import PromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
# 定义模板
first_prompt = PromptTemplate.from_template("为{lastname}的{gender}起名字")
second_prompt = PromptTemplate.from_template("解析名字{name}的含义")
model = ChatTongyi(model="qwen3-max")
# 构建链:用RunnableLambda转换数据格式
chain = first_prompt | model | RunnableLambda(lambda ai_msg: {"name": ai_msg.content}) | second_prompt | model
解决方案 B:直接传入函数(自动转换)
| 运算符原生支持可调用对象(Callable),会自动包装为 RunnableLambda,代码更简洁:
from langchain_core.prompts import PromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
# 定义模板
first_prompt = PromptTemplate.from_template("为{lastname}的{gender}起名字")
second_prompt = PromptTemplate.from_template("解析名字{name}的含义")
model = ChatTongyi(model="qwen3-max")
# 直接使用lambda函数,无需手动包装
chain = first_prompt | model | (lambda x: {"name": x.content}) | second_prompt | model

对话历史记忆 (RunnableWithMessageHistory)(短期存储)
1. 核心概念
RunnableWithMessageHistory:LangChain 包装器,为普通链添加对话历史记忆能力InMemoryChatMessageHistory:基于内存的对话历史存储,通过session_id区分不同用户会话- 核心作用:实现多轮对话,让模型记住上下文信息
- 提示词中必须添加
MessagesPlaceholder作为历史消息占位符 - 实现
get_session_history函数,根据会话 ID 获取 / 创建历史记录 - 调用时通过
config传入session_id,实现会话隔离
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
# 1. 定义模型和输出解析器
model = ChatTongyi(model="qwen-turbo")
parser = StrOutputParser()
# 2. 构建提示词模板:必须包含 MessagesPlaceholder 用于存放历史消息
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个友好的助手"),
MessagesPlaceholder(variable_name="chat_history"), # 历史消息占位符
("human", "{input}") # 用户输入占位符
])
# 3. 基础链:不含历史记录功能的普通链
base_chain = prompt | model | parser
# 4. 内存存储与获取历史记录的函数
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
"""根据会话ID获取或创建历史记录对象"""
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 5. 包装为带历史记忆的链
conversation_chain = RunnableWithMessageHistory(
base_chain,
get_session_history,
input_messages_key="input", # 提示词中用户输入的占位符名
history_messages_key="chat_history" # 提示词中历史记录的占位符名
)
# 6. 多轮对话演示
config = {"configurable": {"session_id": "user_001"}}
# 第一轮:告诉模型名字
response1 = conversation_chain.invoke(
{"input": "你好,我叫小明"},
config=config
)
print("助手1:", response1)
# 第二轮:询问名字(模型会通过历史记录记住之前的信息)
response2 = conversation_chain.invoke(
{"input": "我叫什么名字?"},
config=config
)
print("助手2:", response2)
# 第三轮:一个全新的会话(session_id 不同),应该没有记忆
config_new = {"configurable": {"session_id": "user_002"}}
response3 = conversation_chain.invoke(
{"input": "我叫什么名字?"},
config=config_new
)
print("助手3 (新会话):", response3)多模型链的标准处理流程
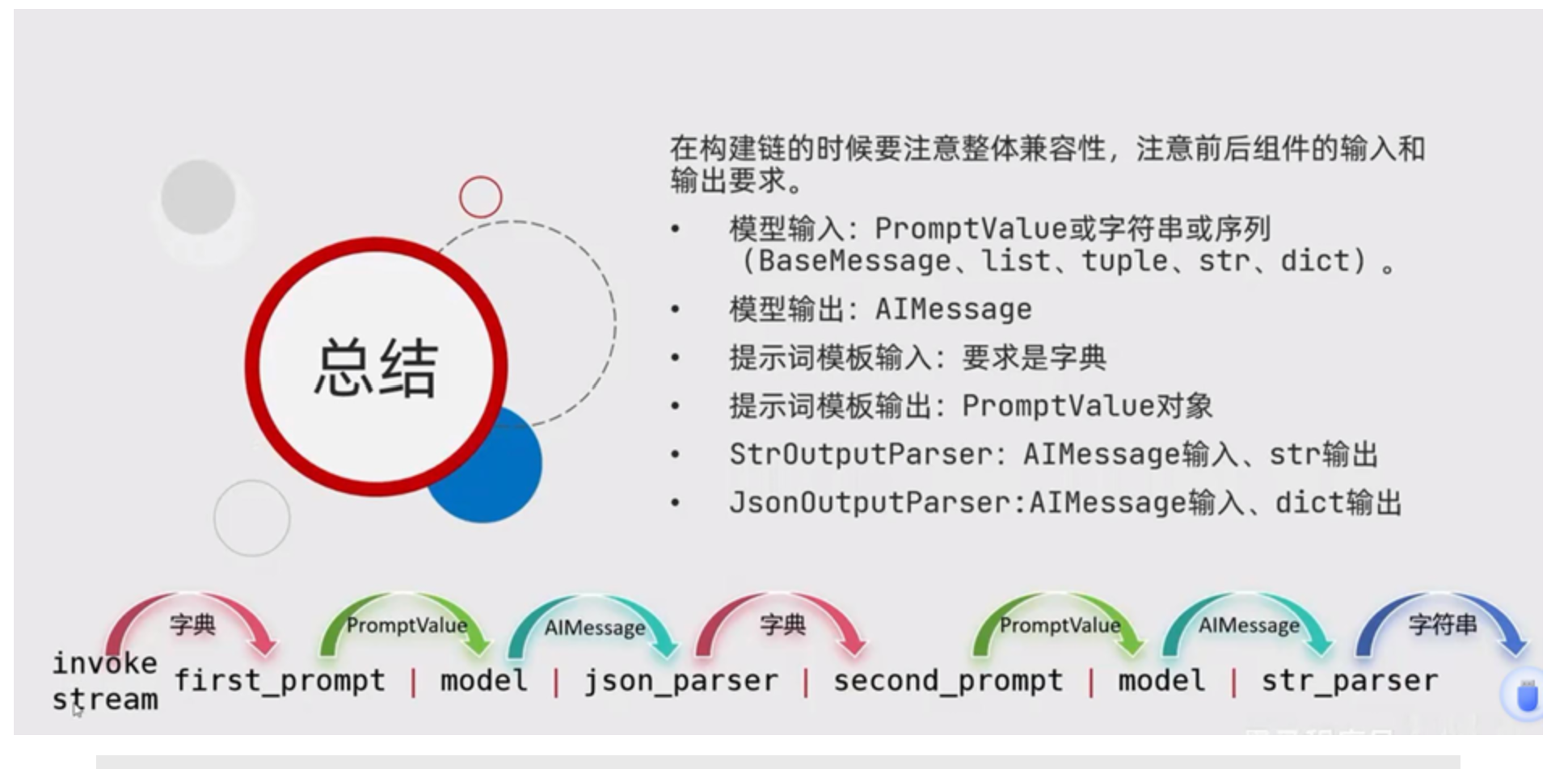
当我们需要多个模型依次处理数据时,最简单的想法是将模型直连:prompt | model | model。但这不符合规范,因为前一个模型的输出是 AIMessage 对象,而第二个模型期望的输入是 PromptValue、str 或 Sequence[MessageLikeRepresentation]。
标准做法是:在模型之间插入数据转换环节,将上游输出整理成下游提示词模板需要的格式,即:
初始输入 → 提示词模板 → 模型 → 数据处理 → 提示词模板 → 模型 → 解析器 → 最终结果
这样,上一个模型的输出经过处理后成为下一个提示词模板的变量,实现了清晰、可维护的链式调用。
代码示例(错误链 vs 正确链)
from langchain_core.prompts import PromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.output_parsers import StrOutputParser
# 错误示例:prompt | model | model 会因为类型不匹配而失败
prompt = PromptTemplate.from_template("请为{product}写一句广告语")
model = ChatTongyi(model="qwen-turbo")
# chain = prompt | model | model # 第二个 model 收到的是 AIMessage,会报错
# 正确示例:加入解析器和二次提示词模板
first_prompt = PromptTemplate.from_template("我邻居姓: {lastname}, 刚生了{gender}, 请起名, 仅告知我名字")
second_prompt = PromptTemplate.from_template("姓名{name}, 请解析含义")
json_parser = StrOutputParser() # 简单字符串解析器,后文会详细说明
chain = first_prompt | model | json_parser | second_prompt | model | StrOutputParser()
result = chain.invoke({"lastname": "张", "gender": "女儿"})
print(result)
StrOutputParser 字符串输出解析器
StrOutputParser 是最简单的输出解析器,它将模型的输出对象(如 AIMessage)转换为其文本内容(content 字段)。在多步骤链中,它经常被用来从第一个模型的应答中提取纯文本,然后填入下一个提示词模板。
从 LangChain 的源码看,模型的 invoke 方法要求输入是 PromptValue | str | Sequence[MessageLikeRepresentation],而 AIMessage 并不是这些类型,所以直接传会失败。引入 StrOutputParser 就可以把 AIMessage 变成 str,满足下游要求。
from langchain_core.output_parsers import StrOutputParser
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.prompts import PromptTemplate
model = ChatTongyi(model="qwen-turbo")
prompt = PromptTemplate.from_template("为产品 {product} 想一句广告语")
parser = StrOutputParser()
chain = prompt | model | parser
result = chain.invoke({"product": "智能手表"})
print(result, type(result)) # 输出为 str
拓展:重写_or_
在 LangChain 中,Runnable 对象可以通过 | 运算符串联成链。其底层是通过实现 __or__ 方法来返回一个新的 RunnableSequence 对象。
为了更好地理解链式调用,我们可以用纯 Python 类模拟这一行为:定义一个类,重写 __or__,让 a | b | c 等价于依次组合。这个机制正是 LangChain 链式调用的核心:每次使用 |,都在创建一个新的、包含所有前序步骤的组合对象。
代码示例(模拟管道运算符)
class Step:
def __init__(self, name):
self.name = name
def __or__(self, other):
# 返回一个包含自身和下一个步骤的列表(模拟链式组合)
if isinstance(other, Step):
return Pipeline([self, other])
elif isinstance(other, Pipeline):
return Pipeline([self] + other.steps)
else:
return NotImplemented
class Pipeline:
def __init__(self, steps):
self.steps = steps
def __or__(self, other):
if isinstance(other, Step):
return Pipeline(self.steps + [other])
elif isinstance(other, Pipeline):
return Pipeline(self.steps + other.steps)
else:
return NotImplemented
def run(self, data):
result = data
for step in self.steps:
print(f"执行 {step.name}")
# 实际处理逻辑...
return result
a = Step("A")
b = Step("B")
c = Step("C")
pipeline = a | b | c # 等价于 Pipeline([a, b, c])
pipeline.run("初始数据")
4. RunnableLambda:自定义函数加入链
除了内置解析器,我们经常需要在链中执行自定义的数据转换,比如从模型中提取部分信息、修改格式等。RunnableLambda 可以将任意普通函数或 Lambda 表达式包装成 Runnable 对象,从而直接通过 | 嵌入链中。它让链条中的数据处理完全自由定制。
RunnableLambda(函数对象)包装后的对象即可作为链中的一环,其输入来自上游,输出传递给下游。
from langchain_core.runnables import RunnableLambda
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_community.chat_models.tongyi import ChatTongyi
model = ChatTongyi(model="qwen-turbo")
first_prompt = PromptTemplate.from_template(
"我邻居姓: {lastname}, 刚生了{gender}, 请起名, 仅告知我名字"
)
second_prompt = PromptTemplate.from_template(
"姓名{name}, 请帮我解析含义。"
)
# 自定义函数:将模型的 AIMessage 转为字典,键为 name
def extract_name(ai_msg):
# ai_msg 是 AIMessage 类型,取其 content
return {"name": ai_msg.content}
# 包装为 RunnableLambda
name_extractor = RunnableLambda(extract_name)
chain = first_prompt | model | name_extractor | second_prompt | model | StrOutputParser()
result = chain.invoke({"lastname": "张", "gender": "女儿"})
print(result)
5. 直接使用 Lambda 函数(自动转换)
在组链时,| 运算符的 __or__ 方法不仅接受 Runnable 对象,还接受可调用对象(Callable)。也就是说,你可以直接写 model | (lambda ai_msg: {"name": ai_msg.content}),LangChain 会自动将普通函数转为 RunnableLambda。这减少了显式包装的代码,让链的定义更加简洁。
代码示例(省略 RunnableLambda)
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_community.chat_models.tongyi import ChatTongyi
model = ChatTongyi(model="qwen-turbo")
chain = (
PromptTemplate.from_template("我邻居姓: {lastname}, 刚生了{gender}, 请起名, 仅告知我名字")
| model
| (lambda ai_msg: {"name": ai_msg.content}) # 直接写 lambda
| PromptTemplate.from_template("姓名{name}, 请解析含义")
| model
| StrOutputParser()
)
result = chain.invoke({"lastname": "张", "gender": "女儿"})
print(result)
附加历史记录功能(RunnableWithMessageHistory)
在多轮对话中,模型需要 “记住” 之前的交流。LangChain 提供了 RunnableWithMessageHistory,它可以为一个已有的基础链(Runnable)添加历史记忆能力。
- 需要提供一个 历史记录存储,例如
InMemoryChatMessageHistory(基于内存)。 - 需要一个 获取会话历史的函数,根据
session_id返回对应的BaseChatMessageHistory对象。 - 指定提示词模板中用于插入 用户输入 和 历史消息 的占位符名称(
input_messages_key和history_messages_key)。
新生成的 conversation_chain 在每次调用时,会自动加载历史、生成提示词、调用模型、存储本轮对话。调用时需通过 config 传入 session_id 以区分不同会话。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.output_parsers import StrOutputParser
# 1. 基础链:提示词包含 {input} 和 {chat_history} 占位符
model = ChatTongyi(model="qwen-turbo")
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个助手"),
MessagesPlaceholder(variable_name="chat_history"), # 历史消息占位符
("human", "{input}") # 用户输入占位符
])
base_chain = prompt | model | StrOutputParser()
# 2. 历史存储与获取函数
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 3. 创建带历史的链
conversation_chain = RunnableWithMessageHistory(
base_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history"
)
# 4. 调用时通过 config 指定 session_id
config = {"configurable": {"session_id": "user001"}}
response1 = conversation_chain.invoke({"input": "你好,我叫小明"}, config=config)
print("第一轮:", response1)
response2 = conversation_chain.invoke({"input": "我叫什么名字?"}, config=config)
print("第二轮:", response2)
注意:调用
invoke时只需提供input对应的值,历史消息由系统根据session_id自动获取和填充。无需手动传chat_history。
在链中插入调试 / 打印逻辑
知识点介绍有时我们需要在链的执行过程中打印某些中间结果(例如提示词内容),但又不能破坏数据的正常传递。可以编写一个简单的函数,接收输入、打印需要的信息,然后原封不动返回输入。将其包装为 RunnableLambda(或直接写 Lambda)插入链中,即可实现无副作用的调试。
代码示例
from langchain_core.runnables import RunnableLambda
from langchain_core.prompts import PromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
model = ChatTongyi(model="qwen-turbo")
def debug_print(data):
print("调试:当前传入下一环的数据为:", data)
return data # 原样返回,不改变数据
chain = (
PromptTemplate.from_template("写一首关于{topic}的诗")
| model
| RunnableLambda(debug_print) # 在模型输出后打印
| (lambda ai_msg: ai_msg.content)
)
result = chain.invoke({"topic": "春天"})
print("最终结果:", result)
这里 debug_print 函数打印了上游传递的 AIMessage 对象,然后将其原样交给下游的 Lambda 处理,整个过程不改变业务逻辑。
一、基于文件的长期会话记忆(FileChatMessageHistory)
核心设计思路
LangChain 默认的InMemoryChatMessageHistory仅将会话记录存储在内存中,程序重启后数据会全部丢失。FileChatMessageHistory通过文件系统实现持久化长期记忆,核心思路:
- 以
session_id作为文件名,不同会话对应独立的 JSON 文件,实现会话隔离 - 继承官方抽象类
BaseChatMessageHistory,必须实现 3 个核心同步方法:add_messages:添加多条消息到历史记录messages:获取所有历史消息(使用@property装饰器伪装成属性访问)clear:清空当前会话的所有历史记录
- 使用 LangChain 内置工具函数
message_to_dict/messages_from_dict实现消息对象与 JSON 字典的互相序列化 / 反序列化
完整实现代码
import json
import os
from typing import Sequence, List
# 导入LangChain核心消息类与序列化工具
from langchain_core.messages import BaseMessage, messages_from_dict, message_to_dict
from langchain_core.chat_history import BaseChatMessageHistory
class FileChatMessageHistory(BaseChatMessageHistory):
"""基于文件系统的持久化聊天消息历史管理器"""
# 类型注解
storage_path: str # 历史文件存储根目录
session_id: str # 当前会话ID
file_path: str # 当前会话对应的完整文件路径
def __init__(self, session_id: str, storage_path: str = "./chat_history"):
"""
初始化文件聊天历史
:param session_id: 会话唯一标识
:param storage_path: 历史文件存储根目录,默认./chat_history
"""
self.session_id = session_id
self.storage_path = storage_path
self.file_path = os.path.join(self.storage_path, self.session_id)
# 确保存储目录存在,不存在则自动创建
os.makedirs(os.path.dirname(self.file_path), exist_ok=True)
@property
def messages(self) -> List[BaseMessage]:
"""获取当前会话的所有历史消息(属性访问)"""
try:
# 读取JSON文件并反序列化为消息对象列表
with open(self.file_path, "r", encoding="utf-8") as f:
messages_data = json.load(f)
return messages_from_dict(messages_data)
except FileNotFoundError:
# 首次会话文件不存在,返回空列表
return []
def add_messages(self, messages: Sequence[BaseMessage]) -> None:
"""
添加多条消息到历史记录
:param messages: 消息对象序列(BaseMessage是SystemMessage、AIMessage等的父类)
"""
# 1. 获取已有消息 + 合并新消息
all_messages = list(self.messages)
all_messages.extend(messages)
# 2. 将所有消息对象序列化为字典列表
serialized = [message_to_dict(message) for message in all_messages]
# 3. 写入文件(覆盖原文件)
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump(serialized, f, ensure_ascii=False, indent=2)
def clear(self) -> None:
"""清空当前会话的所有历史记录"""
# 写入空列表覆盖原文件
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump([], f)
使用示例(结合 RunnableWithMessageHistory)
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.output_parsers import StrOutputParser
# 1. 定义基础对话链
model = ChatTongyi(model="qwen-turbo")
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个贴心的助手,会记住用户说过的话"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}")
])
base_chain = prompt | model | StrOutputParser()
# 2. 定义获取会话历史的函数
def get_session_history(session_id: str) -> BaseChatMessageHistory:
return FileChatMessageHistory(session_id=session_id)
# 3. 创建带持久化记忆的对话链
conversation_chain = RunnableWithMessageHistory(
base_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history"
)
# 4. 测试多轮对话(重启程序后历史依然存在)
config = {"configurable": {"session_id": "user_001"}}
print("第一轮:", conversation_chain.invoke({"input": "我叫张三,今年25岁"}, config=config))
print("第二轮:", conversation_chain.invoke({"input": "我叫什么名字,今年多大?"}, config=config))
# 清空历史(可选)
# get_session_history("user_001").clear()
文档加载器(Document Loaders)
文档加载器是 LangChain RAG 系统的入口,提供统一标准接口,将不同来源(CSV、PDF、JSON、TXT 等)的数据转换为 LangChain 统一的Document格式,确保无论数据来源如何,后续处理逻辑保持一致。
- Document 类:LangChain 内文档的统一载体,核心包含两个字段:
page_content:文档的纯文本内容metadata:文档元数据(字典格式,如来源、页码、作者、创建时间等)
- BaseLoader 抽象类:所有文档加载器的父类,必须实现两个核心方法:
load():一次性加载全部文档,返回List[Document],适合小文件lazy_load():延迟流式加载文档,返回生成器对象,适合大文件,避免内存溢出
CSVLoader
用于加载 CSV 格式文件,支持自定义分隔符、引号字符、字段名等解析参数。
- 依赖:
pip install langchain-community
from langchain_community.document_loaders.csv_loader import CSVLoader
# 1. 基础用法(默认逗号分隔,第一行为表头)
loader = CSVLoader(file_path="./students.csv", encoding="utf-8")
documents = loader.load()
print("基础加载结果数量:", len(documents))
print("第一条文档内容:", documents[0].page_content)
print("第一条文档元数据:", documents[0].metadata)
# 2. 自定义解析参数
loader = CSVLoader(
file_path="./students.csv",
encoding="utf-8",
csv_args={
"delimiter": ",", # 指定分隔符
"quotechar": '"', # 指定字符串的引号包裹符
"fieldnames": ["姓名", "年龄", "性别"] # 手动指定字段名(无表头时使用)
}
)
documents = loader.load()
# 3. 流式加载(适合大CSV文件)
for doc in loader.lazy_load():
print(doc.page_content)
JSONLoader
用于加载 JSON 和 JSON Lines 格式文件,基于jq语法灵活提取指定字段。
- 依赖:
pip install langchain-community jq
核心参数说明
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
file_path |
str | 是 | JSON 文件路径 |
jq_schema |
str | 是 | jq 解析语法,指定要提取的数据结构 |
text_content |
bool | 否 | 提取的是否是纯字符串,默认 True |
json_lines |
bool | 否 | 是否是 JSON Lines 格式(每行一个 JSON 对象),默认 False |
jq 基础语法
.:表示整个 JSON 对象(根节点)[]:表示数组.name:从根节点提取name字段的值.hobby[1]:提取hobby数组的第二个元素.[].name:提取数组中所有对象的name字段
代码示例
from langchain_community.document_loaders import JSONLoader
# 1. 加载普通JSON文件
# 示例JSON结构:[{"name":"张三","age":25},{"name":"李四","age":24}]
loader = JSONLoader(
file_path="./users.json",
jq_schema=".[].name", # 提取所有用户的姓名
text_content=True
)
documents = loader.load()
# 2. 加载JSON Lines文件(每行一个JSON对象)
# 示例JSON Lines结构:
# {"name":"张三","age":25}
# {"name":"李四","age":24}
loader = JSONLoader(
file_path="./users.jsonl",
jq_schema=".",
json_lines=True
)
documents = loader.load()
TextLoader
用于加载纯文本文件(.txt),将整个文件内容封装为一个Document对象。
- 依赖:
pip install langchain-community
代码示例
from langchain_community.document_loaders import TextLoader
# 基础用法
loader = TextLoader(file_path="./article.txt", encoding="utf-8")
documents = loader.load()
print("文本文件加载结果数量:", len(documents)) # 输出:1
print("文本内容:", documents[0].page_content)
补充:文本分割器(RecursiveCharacterTextSplitter)
纯文本文件通常较大,直接传入向量数据库会导致检索精度下降。LangChain 官方推荐使用RecursiveCharacterTextSplitter按自然段落分割文本:
2.5 PyPDFLoader
用于加载 PDF 格式文件,默认按页拆分文档(每页对应一个Document对象)。
- 依赖:
pip install langchain-community pypdf
代码示例
from langchain_community.document_loaders import PyPDFLoader
# 基础用法
loader = PyPDFLoader(
file_path="./report.pdf",
mode="page", # 读取模式:page(按页拆分)/ single(整个PDF为一个Document)
password="" # 加密PDF的密码
)
# 一次性加载所有页
documents = loader.load()
print("PDF总页数:", len(documents))
print("第1页内容:", documents[0].page_content)
print("第1页元数据(包含页码):", documents[0].metadata)
# 流式加载(适合大PDF文件)
for page in loader.lazy_load():
print(f"第{page.metadata['page']+1}页:", page.page_content[:100])向量存储基础概念
核心概述
向量存储是 RAG(检索增强生成)系统的核心组件,负责将文档的向量化表示(Embedding)进行持久化存储,并提供高效的相似度检索能力。LangChain 内置了多种向量存储实现,最常用的两种:
- InMemoryVectorStore:纯内存向量存储,程序重启后数据丢失,适合快速原型开发和测试
- Chroma:轻量级嵌入式向量数据库,支持本地文件持久化,适合生产环境中小规模数据
通用 API 接口
所有向量存储类均继承自VectorStore抽象基类,提供 3 个核心通用接口:
add_documents(documents: List[Document]):添加文档对象到向量存储delete(ids: Optional[List[str]] = None):根据 ID 删除向量存储中的文档similarity_search(query: str, k: int = 4):根据查询文本进行相似度检索,返回最相关的 k 个文档
RAG 整体工作流程
RAG 系统分为索引阶段(存储)和查询阶段(检索) 两个核心流程:
【索引阶段】
原始文档 → 文档加载器 → 文本分割器 → 嵌入模型 → 向量存储(保存嵌入向量)
【查询阶段】
用户查询 → 嵌入模型 → 查询向量 → 相似度检索 → Top-k相关文档 → 提示词模板(用户查询+参考资料) → 大模型 → 最终回答
基础 RAG 流程实现(手动检索版)
知识点介绍
这是最直观的 RAG 实现方式,步骤清晰可控:
- 初始化大模型、嵌入模型和提示词模板
- 创建向量存储并添加知识库文本
- 接收用户查询,手动调用
similarity_search检索相关文档 - 将用户查询和检索到的参考资料拼接成完整提示词
- 调用大模型生成回答
该方式适合调试和理解 RAG 原理,缺点是步骤繁琐,无法与 LangChain 的链式调用体系无缝整合。
2.2 完整可运行代码
# 安装依赖:pip install langchain langchain-community dashscope
import os
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 设置通义千问API密钥(替换为自己的密钥)
os.environ["DASHSCOPE_API_KEY"] = "your-dashscope-api-key"
# 1. 初始化核心组件
model = ChatTongyi(model="qwen3-max")
embedding = DashScopeEmbeddings(model="text-embedding-v4")
# 2. 定义RAG提示词模板
prompt = ChatPromptTemplate.from_messages([
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。"),
("user", "用户提问:{input}")
])
# 3. 调试函数:打印完整的提示词(用于排查问题)
def print_prompt(prompt_value):
print("="*50)
print("完整提示词:")
print(prompt_value.to_string())
print("="*50)
return prompt_value # 原样返回,不影响后续流程
# 4. 创建内存向量存储并添加知识库
vector_store = InMemoryVectorStore(embedding=embedding)
# 添加知识库文本(add_texts接收字符串列表,自动转换为Document并向量化)
vector_store.add_texts([
"减肥就是要少吃多练",
"在减脂期间吃东西很重要,请少油控制卡路里摄入并运动起来",
"跑步是很好的运动哦"
])
# 5. 执行RAG流程
input_text = "怎么减肥?"
# 手动检索向量库,返回最相关的2个文档
result = vector_store.similarity_search(input_text, k=2)
# 格式化检索结果为字符串
reference_text = "["
for doc in result:
reference_text += doc.page_content
reference_text += "]"
# 构建链式调用并执行
chain = prompt | print_prompt | model | StrOutputParser()
res = chain.invoke({"input": input_text, "context": reference_text})
print("最终回答:", res)
检索器与链式调用整合(自动化 RAG)
检索器(Retriever)
向量存储提供as_retriever()方法,可以将自身转换为一个实现了Runnable接口的检索器对象:
- 输入:用户查询字符串(
str) - 输出:相似度检索结果(
List[Document]) - 可通过
search_kwargs参数配置检索行为,如{"k": 2}表示返回最相关的 2 个文档
错误写法分析
很多初学者会直接写chain = retriever | prompt | model | StrOutputParser(),这会导致两个严重问题:
- 输入丢失:检索器只接收用户查询作为输入,输出是文档列表,会把原始的用户查询丢弃
- 类型不匹配:提示词模板需要接收包含
input和context两个键的字典,而检索器输出的是List[Document]
解决方案:RunnablePassthrough
RunnablePassthrough是 LangChain 提供的一个特殊 Runnable 对象,作用是原样传递输入数据。通过它可以实现:
- 将用户查询同时传递给检索器和提示词模板
- 构建包含多个键的字典,满足下游提示词模板的输入要求
格式转换函数(format_func)
检索器输出的是List[Document],而提示词模板需要字符串类型的参考资料。因此需要一个格式转换函数,将文档列表拼接成格式化的字符串,同时处理无检索结果的边界情况。
完整可运行代码
# 安装依赖:pip install langchain langchain-community dashscope
import os
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# 设置通义千问API密钥
os.environ["DASHSCOPE_API_KEY"] = "your-dashscope-api-key"
# 1. 初始化核心组件
model = ChatTongyi(model="qwen3-max")
embedding = DashScopeEmbeddings(model="text-embedding-v4")
# 2. 定义RAG提示词模板
prompt = ChatPromptTemplate.from_messages([
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}。"),
("user", "用户提问:{input}")
])
# 3. 调试函数
def print_prompt(prompt_value):
print("="*50)
print("完整提示词:")
print(prompt_value.to_string())
print("="*50)
return prompt_value
# 4. 创建向量存储并添加知识库
vector_store = InMemoryVectorStore(embedding=embedding)
vector_store.add_texts([
"减肥就是要少吃多练",
"在减脂期间吃东西很重要,请少油控制卡路里摄入并运动起来",
"跑步是很好的运动哦"
])
# 5. 将向量存储转换为检索器
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
# 6. 定义文档格式转换函数
def format_func(docs: list):
if not docs:
return "无相关参考资料"
formatted_str = "["
for doc in docs:
formatted_str += doc.page_content
formatted_str += "]"
return formatted_str
# 7. 构建自动化RAG链(核心)
chain = (
{
"input": RunnablePassthrough(), # 原样传递用户查询给prompt的input字段
"context": retriever | format_func # 用户查询传给retriever,结果经format_func后给context字段
}
| prompt
| print_prompt
| model
| StrOutputParser()
)
# 8. 执行查询(只需传入用户查询字符串,无需手动处理检索和格式化)
input_text = "怎么减肥?"
res = chain.invoke(input_text)
print("最终回答:", res)
代码执行流程解析
- 调用
chain.invoke("怎么减肥?"),输入字符串传递给整个链 - 字典中的两个分支并行执行:
"input": RunnablePassthrough():直接返回输入字符串"怎么减肥?""context": retriever | format_func:输入字符串传给 retriever 进行检索,得到List[Document],再传给 format_func 转换为字符串
- 两个分支的结果合并成字典
{"input": "怎么减肥?", "context": "[减肥就是要少吃多练在减脂期间吃东西很重要...]"} - 字典传给 prompt 模板生成完整提示词
- 提示词传给大模型生成回答,最后经 StrOutputParser 解析为字符串输出

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)