yolov10的注意力机制改进:坐标注意力(CoordinateAttention)
一、简介
Coordinate Attention(坐标注意力)是CVPR 2021提出的一种面向移动网络的高效注意力机制。它通过将通道注意力(Channel Attention)巧妙地分解为沿水平与垂直两个空间方向的1D特征编码过程,有效解决了传统通道注意力(如SENet)因使用2D全局池化而丢失位置信息的问题。具体而言,给定输入特征图,Coordinate Attention会分别使用尺寸为 (H,1) 和 (1,W) 的池化核沿垂直与水平方向对每个通道进行编码,得到一对方向感知的特征图。这些特征图经过卷积变换和非线性激活后,被编码成一对方向感知和位置敏感的注意力图。这些注意力图能互补的应用到输入特征图上,使模型在捕获通道间依赖关系和长程空间交互的同时,保留精确的位置信息,从而帮助模型(如MobileNetV2、MobileNeXt和EfficientNet)更准确地关注和定位目标,例如在图像分类、目标检测及语义分割等任务中都观察到了性能提升,且几乎不增加计算开销。
二、Coordinate Attention的实现代码
代码源地址:https://github.com/Andrew-Qibin/CoordAttention/blob/main/models/coord_att.py
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out三、在yolov10中改进
以下改进均在yolov10s.yaml文件中修改
3.1 改进:
改进方法:直接嵌入到骨干网络(backbone)中,将模块放入到C2fCIB模块和SPPF模块之间
四、修改操作:
4.1 模块导入
在yolov10的ultralytics/nn目录中新建一个文件夹AddAttention(名字自定义),在AddAttention中建立CoordinateAttention.py,并将CoordinateAttention的实现的代码放入其中,然后再在AddAttention中再新建_init_.py,并在该文件中写入:
from .CoordinateAttention import *
用于将模块导出,如图:

4.2 修改
对模块进行参数设置,在ultralytics/nn/tasks.py的parse_model函数中添加如下代码在添加代码前,在tasks.py文件中对AddAttention里的模块进行导入,即在task.py文件中写入
from .AddAttention import *
):
-
ch[f]:代表当前CoordAtt层的输入通道数,它从前一层(索引为f)的输出通道数ch[f]中获取,确保了网络中各层间通道数的连贯性 -
c2 = args[0]:从配置参数中读取预设的输出通道数,这是模型设计时指定的目标输出维度 -
通道数优化:通过
make_divisible(min(c2, max_channels) * width, 8)对输出通道数进行三重调整:-
min(c2, max_channels):限制最大通道数,防止模型过大 -
* width:应用宽度乘子,支持不同尺寸的模型变体 -
make_divisible(..., 8):确保通道数能被8整除,优化硬件计算效率
-
-
参数重构:最终构建的参数列表
[c1, c2, *args[1:]]包含了处理后的输入通道数、优化后的输出通道数以及模块的其他配置参数
elif m in {CoordAtt}:
c1 = ch[f]
c2 = args[0]
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
位置如图所示:
4.1.3 yaml文件的修改
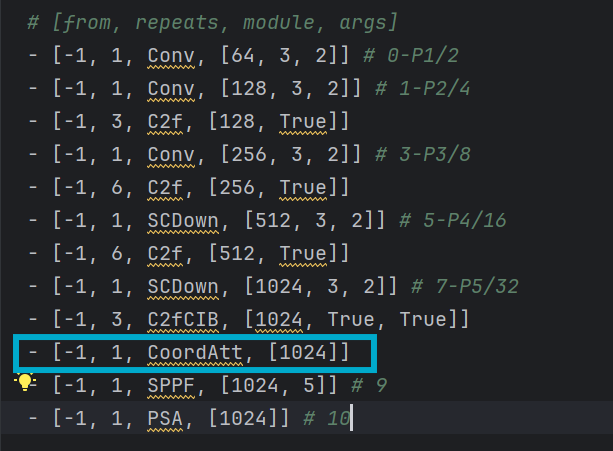
在ultralytics/cfg/models/v10目录下,将该目录下新建yolov10s_CA.yaml(名字自定义,这里CA为简写),并将yolov10s.yaml文件中的内容复制过来,并对其进行修改,在SPPF模块和C2FCIB模块之间添加CoordinateAttention模块,输出通道设为1024,如图:
五、运行结果
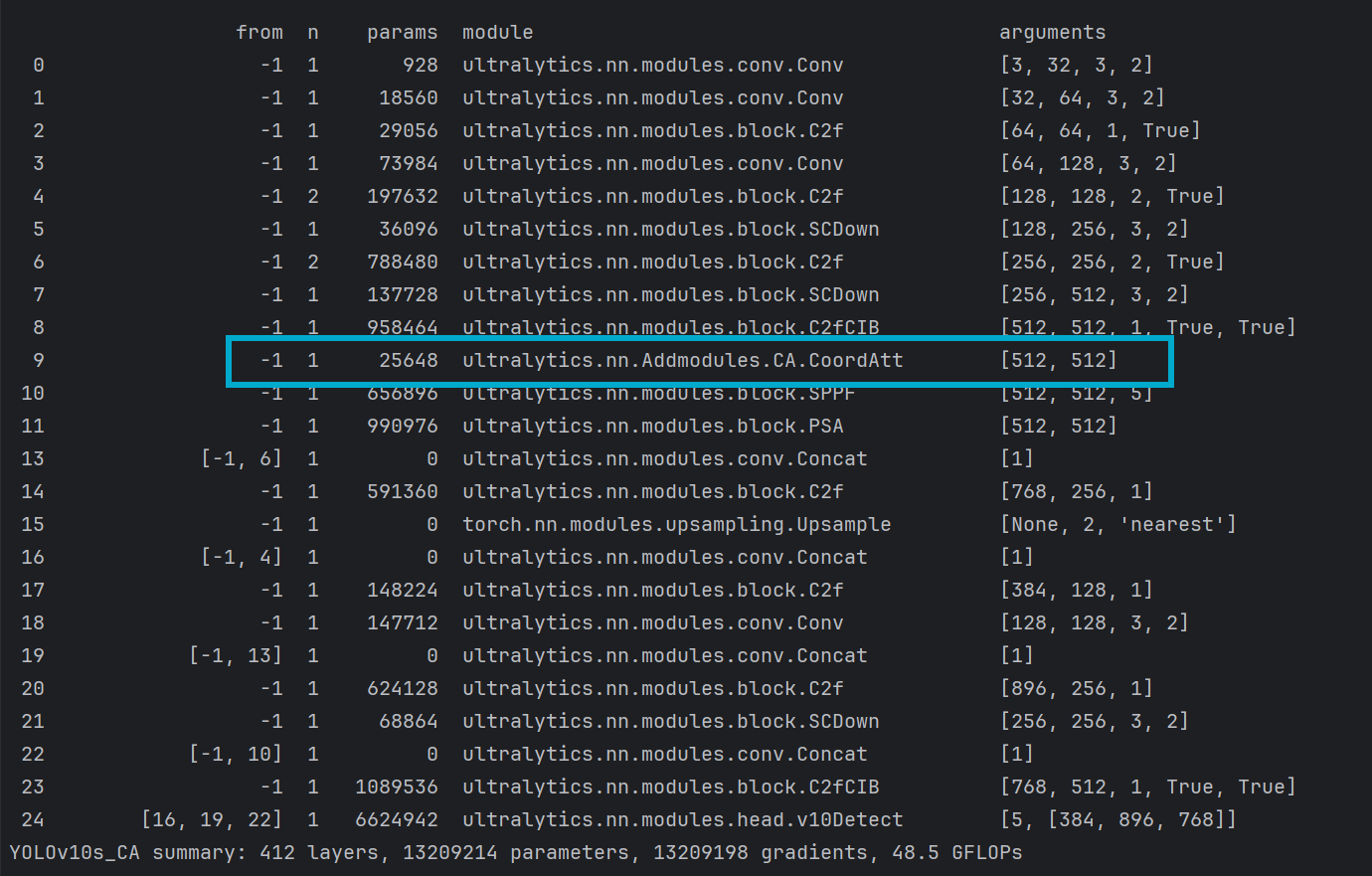
打印网络模型,看到自定义的模块名称出现在网络中即可代表修改成功

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)