(论文速读)STMNet: 基于单时间掩模的自监督高光谱变化检测网络
论文题目:STMNet: Single-Temporal Mask-based Network for Self-Supervised Hyperspectral Change Detection(基于单时间掩模的自监督高光谱变化检测网络)
期刊:IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING(TGRS)
摘要:多时相高光谱图像以其丰富的光谱特征和图像细节被广泛应用于不同地表覆盖的变化检测。然而,双颞叶hsi对的比对和标记是劳动密集型的。本文从检测掩码变化的新角度出发,提出了一种基于单时间掩码的自监督HSI CD网络(STMNet)。STMNet通过处理附着在单时间HSI上的人工构造掩模作为变化区域来实现自我监督。为此,我们设计了一种多尺度掩模变化模拟策略(MMCS)来生成更接近真实情况的伪秒-时间HSI。同时,提出了一种全局-局部特征聚合网络,增强了远距离和局部空间光谱特征提取。据我们所知,这是在HSI CD领域的第一个使用单时间HSI的工作,消除了对样本的标记和配对的需要,缓解了多时间HSI标注的困难问题。在三个HSI数据集上的可视化和定量实验结果表明,所提出的STMNet优于目前最先进的HSI CD方法。代码可在https://github.com/Zhoutya/ChangeDetection-STMNet上获得。
STMNet:首个基于单时相图像的自监督高光谱变化检测网络
一、研究背景与问题
高光谱图像(Hyperspectral Image, HSI)由于其丰富的光谱信息和图像细节,被广泛应用于土地覆盖变化检测(Change Detection, CD)任务,涵盖城市规划、环境监测、农业调查和灾害评估等多个领域。然而,现有方法在落地应用中面临一系列严峻挑战。
1.1 双时相HSI获取与标注之困
传统CD方法依赖同一地区不同时间点的配对双时相图像。获取这些数据不仅需要进行辐射校正和几何配准等繁琐预处理,还必须通过人工实地考察来确保标注的精确性。当需要对同一区域进行长期多时序监测时,问题更加突出——所有时序图像都需要同时对齐并打标签,耗时耗力。
💡 实际场景痛点:在卫星轨道上进行实时处理时,受限于星上算力,对新图像进行标注和微调的流程极为繁琐,严重制约了自动化与智能化水平。
1.2 现有自监督方法的局限
现有自监督HSI变化检测方法大致可分为两类:
(1)伪标签类方法:利用SSIM、CVA等传统方法快速生成伪标签作为监督信息。代表性工作包括Li et al. [21]、Ou et al. [22]、Wu et al. [23]、BCG-Net [24]、S3Net [25]等。核心缺陷:伪标签质量上限决定了模型性能上限,初始伪标签的错误会持续误导训练。
(2)对比学习类方法:通过构建特征间的相似性约束来训练网络,如HyperNet [26]、DSConvAEs [27]、TRAMNet [28]、UA-GSSL [29]等。核心缺陷:需要构建大量负样本对;部分方法仍需少量标注样本进行下游微调;且上述两类方法都需要预先配对好的同地双时相图像作为训练输入。
1.3 MAE类掩码预训练与CD任务的目标偏差
MAE、SimMIM等经典掩码自编码器以重建掩码区域为预训练目标,而CD任务的目标是检测变化区域。两者目标不一致,导致预训练特征提取器难以直接适配下游CD任务,微调困难。
1.4 单时相方法在HSI领域的空白
高空间分辨率遥感图像(HSR)领域已有单时相CD探索,如ChangeStar [30]和I3PE [31],但这些方法仍依赖部分标注样本。更重要的是,在HSI变化检测领域,利用单时相图像进行无标注CD的方法尚属空白。
二、STMNet整体框架
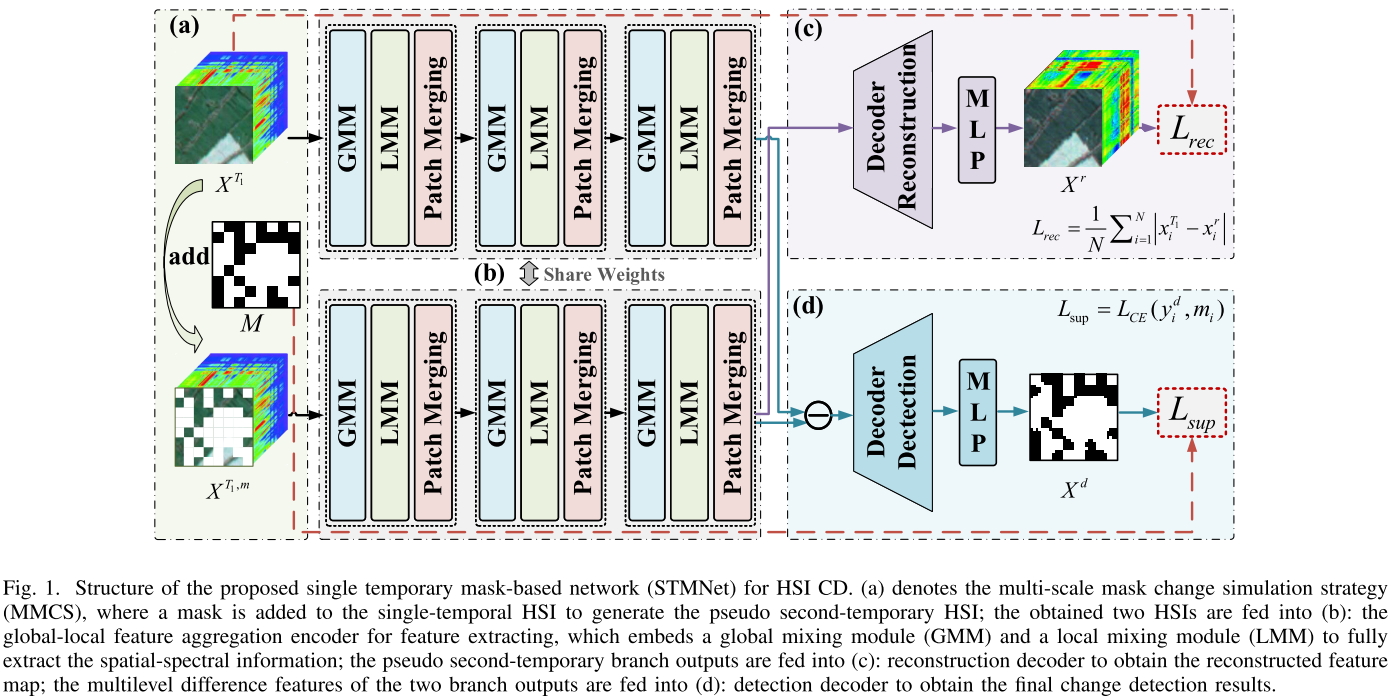
【配图:图1 — STMNet整体架构图】
针对上述问题,作者提出了 STMNet(Single-Temporal Mask-based Network),其核心思路是:将人工构造的掩码视为"变化区域",从而把CD任务转化为"检测掩码在哪里"的自监督学习问题,彻底绕开了双时相配对和样本标注的需求。
整个框架由三个核心部分组成:
单时相HSI ──→ [MMCS掩码策略] ──→ 伪第二时相HSI
│ │
└──→ [共享权重的全局-局部特征聚合编码器] ←──┘
│
┌─────────────┴─────────────┐
↓ ↓
[重建解码器] [检测解码器]
重建原始HSI 输出变化图
(Lrec损失) (Lsup损失)
训练阶段:仅需单时相无标注HSI,经过MMCS生成伪第二时相图像,二者共同送入编码器提取特征,分别由重建解码器和检测解码器约束训练。
测试阶段:将真实的双时相HSI直接送入编码器和检测解码器,输出二值变化检测图。
三、核心创新模块详解
3.1 多尺度掩码变化模拟策略(MMCS)

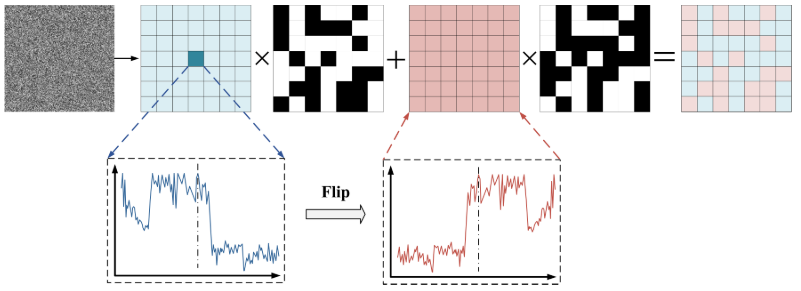
【配图:图2 — 三种尺度掩码示意图(masksize=2/4/8)】
【配图:图3 — MMCS策略可视化流程图】
MMCS(Multi-scale Mask Change Simulation Strategy) 是STMNet得以工作的关键。其设计哲学是:生成一张尽可能接近真实第二时相HSI的"伪变化图像"。具体策略包含三个要点:
(1)多尺度掩码设计
不同地物特征具有不同的尺度特性,因此设置了三种掩码基本单元尺寸:2×2、4×4、8×8,三种掩码以等概率随机混合生成最终掩码 m。掩码比例在 20%~80% 之间随机设置,以适应变化区域分布不均匀的真实场景。
(2)光谱翻转填充(核心)
掩码区域的光谱值填充方式至关重要。作者提取原始patch中心像素的光谱,对其进行横向翻转(lateral flip)作为变化像素的光谱值。翻转后的光谱与patch中任何其他像素的光谱都不同,能有效模拟真实变化样本。数学表达为:
其中 为加高斯噪声后的原始HSI,
为翻转后的光谱值,
表示未掩码区域。
相比0初始化或随机初始化,光谱翻转填充能生成更接近真实第二时相HSI的伪变化图像。消融实验也证实了这一设计的必要性(见第五节)。
(3)高斯噪声添加
对未掩码区域添加随机噪声,模拟传感器采样误差,使伪第二时相图像更贴近真实成像条件。
3.2 全局-局部特征聚合模块
编码器阶段由三个下采样单元组成,每个单元包含 GMM → LMM → Patch Merging 三步。
3.2.1 全局混合模块(GMM)
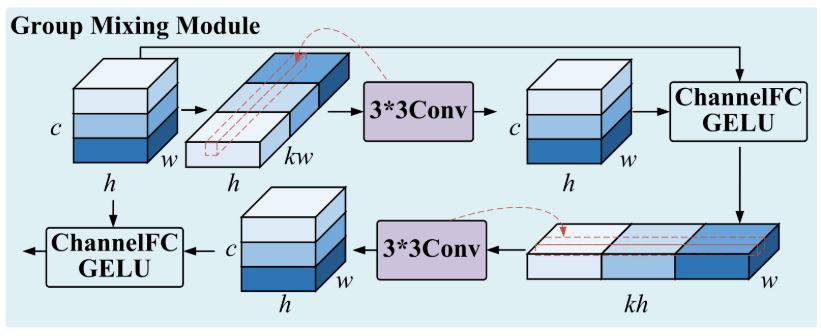
【配图:图4 — GMM结构示意图】
HSI中像素之间存在复杂的长距离依赖关系,而传统卷积受感受野限制难以有效捕获。GMM(Global Mixing Module)的核心思想是:通过将特征图在行列方向上切片重组,使原本空间上相距较远的像素"物理靠近",再通过3×3卷积实现交互。
具体操作:
- 给定输入特征
,沿通道维度分成 k 块,沿列方向拼接得到
;
- 对此特征图施加3×3卷积后还原维度,并通过Channel FC + GELU与原始特征融合;
- 再沿行方向切片拼接,重复上述过程,捕获行方向的长距离依赖。
3.2.2 局部混合模块(LMM)
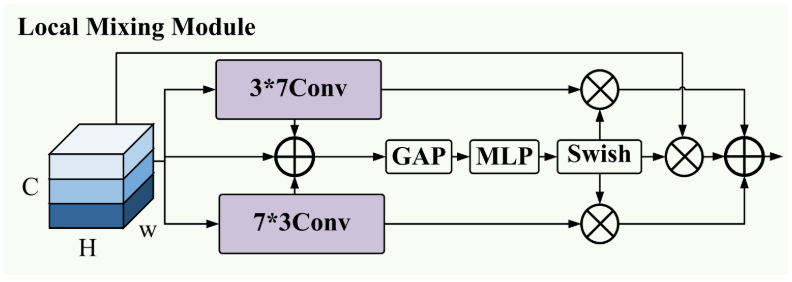
【配图:图5 — LMM结构示意图】
HSI具有丰富的空间-光谱三维结构,需要对局部空谱特征进行精细聚合。LMM(Local Mixing Module)的设计思路:
Step 1 — 非对称卷积提取多方向局部特征:
分别使用 3×7 和 7×3 卷积核提取水平和垂直方向的局部空间特征,与原始特征相加融合。
Step 2 — 通道注意力自适应加权:
先通过GAP压缩空间维度,再通过MLP提取通道特征,使用 Swish激活函数(,相比Sigmoid导数恒大于0,优化效果更好)自适应地强调有用区域、抑制冗余特征。
3.3 双解码器设计与损失函数
检测解码器:将双时相分支的多尺度特征图做逐元素差分,经多层反卷积上采样还原至原始输入尺寸,输出变化概率图 $x^d$。
重建解码器:对掩码分支的输出进行重建,监督网络学习真实HSI的特征表示,防止网络退化。
总损失函数:
其中:
- 监督损失
:以掩码
作为变化标签,用交叉熵损失约束检测结果:
- 重建损失
:用L1损失约束掩码分支对原始单时相HSI的重建质量:
四、实验设置
4.1 数据集
【配图:图6 — Farmland数据集(双时相图像+Ground Truth)】
【配图:图7 — Hermiston数据集(双时相图像+Ground Truth)】
【配图:图8 — Bay数据集(双时相图像+Ground Truth)】



| 数据集 | 传感器 | 时间 | 空间尺寸 | 波段数 | 主要变化类型 |
|---|---|---|---|---|---|
| Farmland | EO-1 Hyperion | 2006/2007 | 450×140 | 155 | 农田变化 |
| Hermiston | EO-1 Hyperion | 2013/2014 | 307×241 | 154 | 农田覆盖变化 |
| Bay | AVIRIS | 2013/2015 | 600×500 | 224 | 农田与建筑变化 |
4.2 评估指标
使用总体精度(OA)、Kappa系数(KC)、精确率(Pr)、召回率(Re)和F1分数(F1)五项指标进行综合评估。可视化结果中,TP(正确检测变化)显示为白色,TN(正确检测未变化)显示为红色,FP(误检变化)显示为绿色,FN(漏检变化)显示为黑色。
4.3 实现细节
- 硬件:NVIDIA GeForce RTX 3090(24G显存)
- 框架:PyTorch
- 输入patch尺寸:32×32
- 优化器:SGD,weight decay=5e-3
- 初始学习率:1e-4,每10个epoch衰减0.1倍
- 训练轮数:50 epochs,batch size=128
- 训练样本:从数据集中随机抽取20%无标注样本用于训练,其余用于测试
五、实验结果
5.1 Farmland数据集
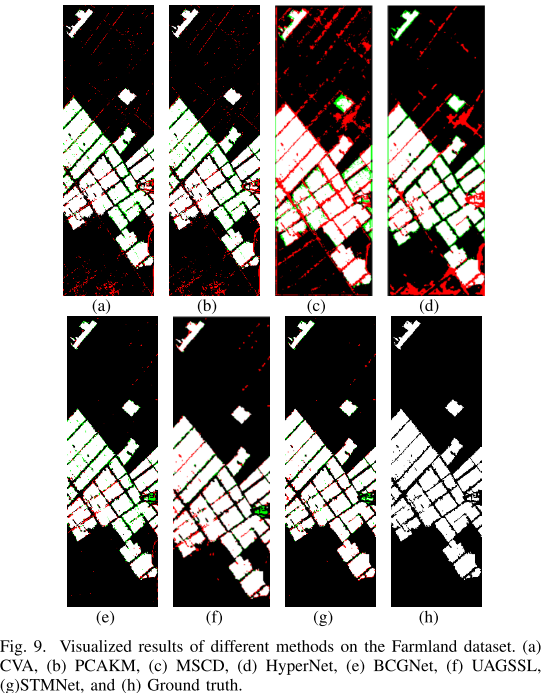
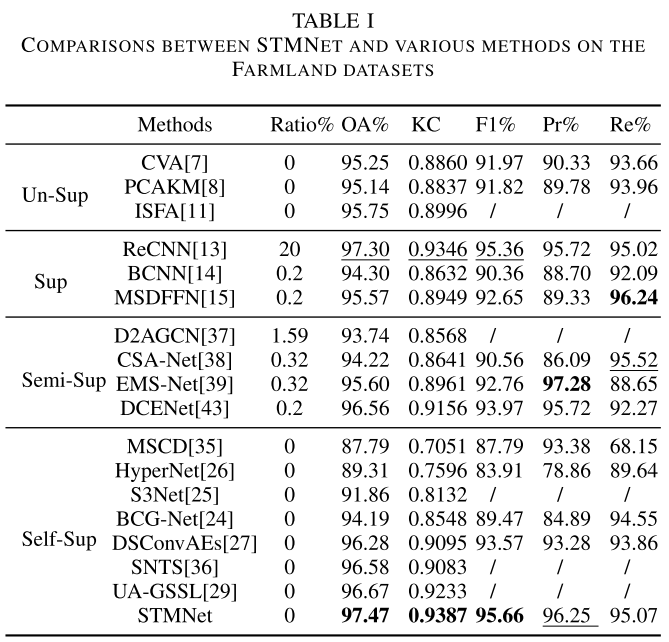
【配表:表I — Farmland数据集各方法对比结果】
【配图:图9 — Farmland数据集可视化结果对比】
在Farmland数据集上,STMNet取得了OA=97.47%、KC=0.9387、F1=95.66%的成绩,在所有参与对比的方法中排名第一。
值得关注的是:STMNet(无标注)甚至超过了使用20%标注样本进行监督训练的ReCNN(OA=97.30%),充分验证了单时相掩码策略的有效性。
从可视化结果来看:
- 无监督方法CVA和PCAKM在变化区域边缘和小目标周围存在大量误分类;
- 自监督方法MSCD和HyperNet在未变化区域存在较多误检(黑色区域),前者未考虑HSI丰富光谱信息,后者缺乏长程连接的提取;
- STMNet的误分类点最少,对图像中右侧中间小目标区域的检测细节显著优于BCG-Net和UA-GSSL。
5.2 Hermiston数据集
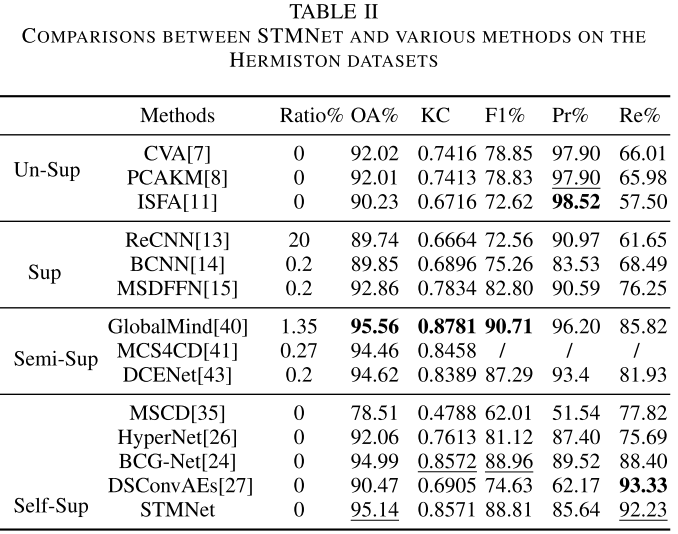

【配表:表II — Hermiston数据集各方法对比结果】
【配图:图10 — Hermiston数据集可视化结果对比】
Hermiston数据集具有更复杂的边缘结构,分类难度更高。STMNet取得OA=95.14%、KC=0.8571、F1=88.81%,在自监督方法中排名最优,并超越了部分半监督方法(如DCENet的OA=94.62%,使用了0.2%标注样本)。
唯一未能超越的是使用1.35%标注样本的GlobalMind(OA=95.56%),这也说明少量标注信息在复杂数据集上仍有其价值,但STMNet已在零标注条件下取得接近效果。
5.3 Bay数据集
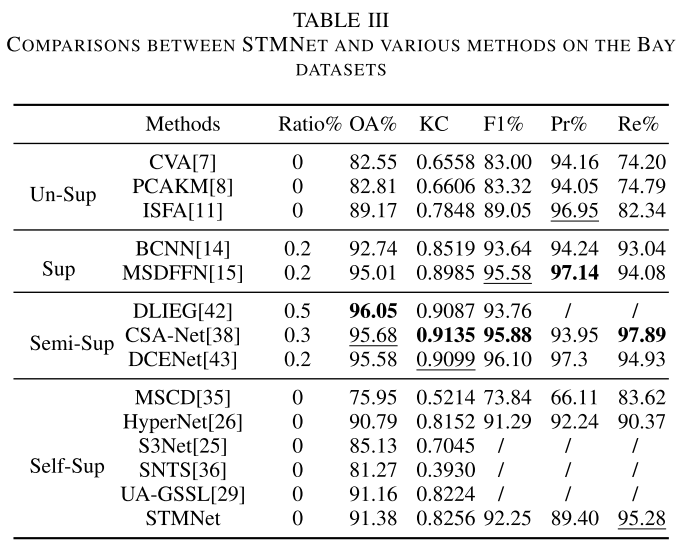
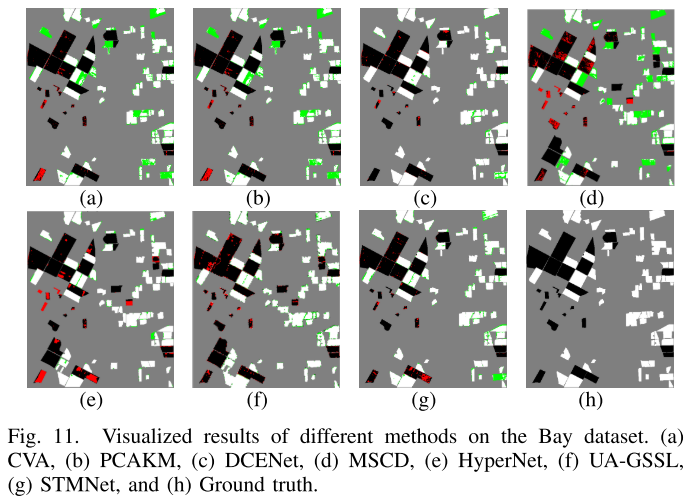
【配表:表III — Bay数据集各方法对比结果】
【配图:图11 — Bay数据集可视化结果对比】
Bay数据集含有大量未标注区域(图中灰色部分),这对传统无监督方法干扰严重。STMNet取得OA=91.38%、KC=0.8256、F1=92.25%,在所有自监督方法中取得最优结果,超过UA-GSSL(OA=91.16%)和HyperNet(OA=90.79%)。
在可视化对比中,MSCD误分类点最多;HyperNet和UA-GSSL虽然误分类点较少,但仍存在大区域边缘丢失问题;STMNet能够检测出所有大区域,可视化性能最优。
六、消融实验分析
6.1 各模块有效性验证
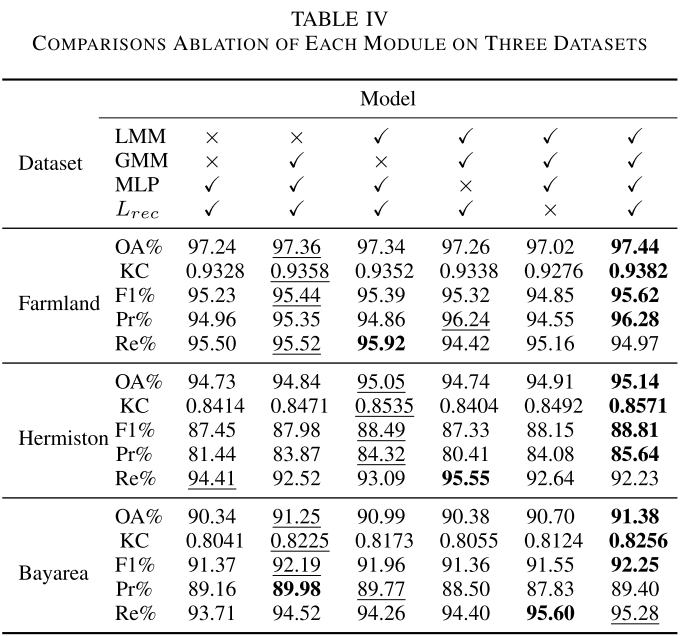
【配表:表IV — 三个数据集上各模块消融实验结果】
作者设计了六组实验,逐一去除LMM、GMM、MLP投影头和重建损失 $L_{rec}$,验证各组件的贡献:
| 去除的模块 | 主要影响 |
|---|---|
| 去除GMM和LMM | 三个数据集精度均下降,说明两模块协同提取空谱特征的有效性 |
| 仅保留GMM或仅保留LMM | 精度介于全模型和无模型之间,说明两者互补 |
| 去除MLP投影头 | 精度下降,MLP有助于将特征投影到更适合重建/检测的空间 |
| 去除重建损失 | 精度下降,说明重建任务赋予了网络学习真实HSI特征的能力 |
📝 注:在Farmland数据集上,各模块增减导致的精度差异相对不明显,这是因为该数据集本身变化特征较容易区分,基线已较高。
6.2 多尺度掩码策略消融
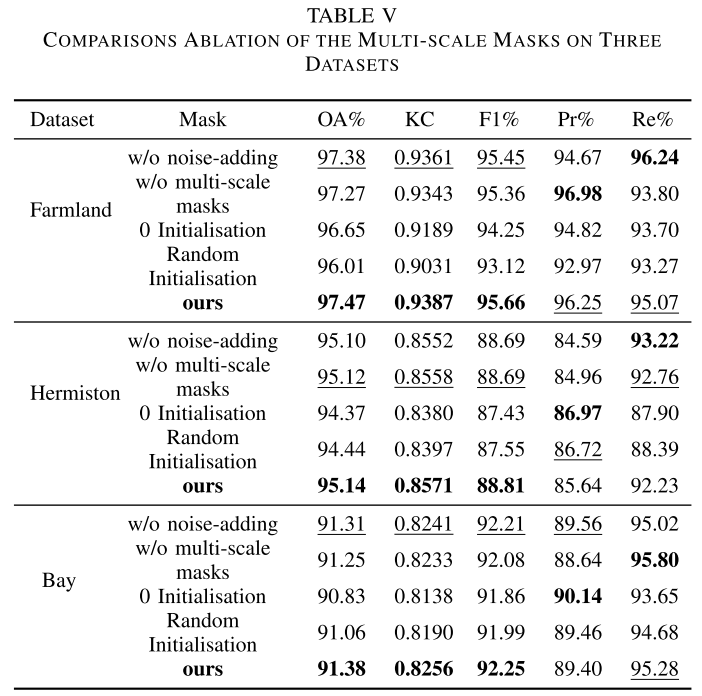
【配表:表V — 多尺度掩码策略消融实验结果】
| 实验设置 | 结论 |
|---|---|
| 不加高斯噪声 | 精度略有下降,说明噪声模拟真实成像差异有一定价值 |
| 仅用单尺度掩码 | 精度下降,验证多尺度设计的必要性 |
| 0初始化填充掩码区域 | 精度明显下降(如Farmland KC从0.9387降至0.9189) |
| 随机初始化填充掩码区域 | 精度进一步下降(Farmland KC=0.9031) |
| 光谱翻转填充(本文方法) | 各数据集最优 |
消融结果清楚说明:光谱翻转填充是MMCS策略的核心,其生成的伪第二时相图像最接近真实变化场景,0初始化和随机初始化均无法达到相同效果。
6.3 掩码比例的影响
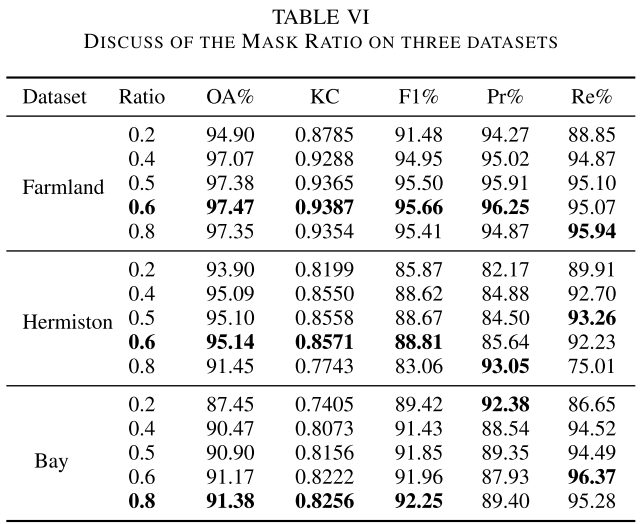
【配表:表VI — 不同掩码比例下的检测结果】
在不同掩码比例(0.2、0.4、0.5、0.6、0.8)下的实验显示:
- 最优掩码比例因数据集而异:Farmland和Hermiston选0.6,Bay选0.8;
- 掩码比例过小时,模拟变化区域过于分散,模型难以适应大面积连续变化的真实场景;
- 掩码比例过大时,模拟变化区域过密,导致大面积未变化区域被误检为变化区域。
6.4 训练样本量的影响
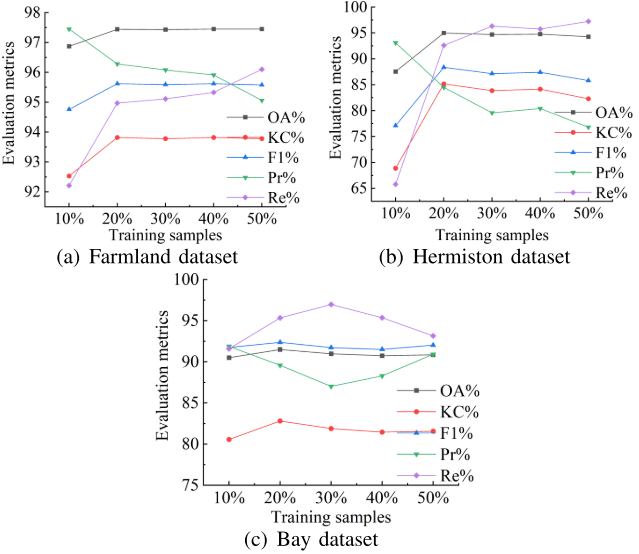
【配图:图12 — 不同训练样本量下的CD结果曲线(三个数据集)】
- Farmland:训练样本达20%后,继续增加样本量收益极为有限;
- Hermiston和Bay:持续增加训练样本反而导致OA和KC下降。
基于此,作者统一选取20%无标注样本作为训练集。这一发现揭示了自监督场景下的一个有趣规律:当已覆盖主要样本类型时,增加更多样本对网络的提升作用有限,而引入过多冗余样本可能反而扰乱学习。
6.5 计算开销
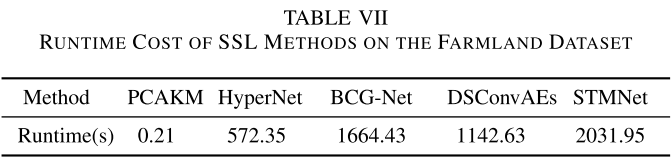
【配表:表VII — 各SSL方法在Farmland数据集上的运行时间对比】
STMNet的训练时间相对较长(约2031.95s),原因在于大量无标注样本结合多种掩码策略的训练开销。但其测试时间仅约1.43s,推理效率较高。作者也指出,后续将探索更高效的训练策略。
七、总结与展望
STMNet的核心贡献可以用一句话概括:将CD任务中"检测变化"与掩码学习中"检测掩码"统一,从而实现了无需配对、无需标注的单时相自监督高光谱变化检测。
三大贡献回顾:
- MMCS策略:多尺度掩码 + 光谱翻转填充 + 高斯噪声,生成接近真实第二时相的伪变化图像;
- 全局-局部特征聚合网络:GMM捕获长距离依赖,LMM精细聚合局部空谱特征;
- 端到端STMNet框架:首次在HSI CD领域实现单时相无标注自监督训练,三个数据集上均达到或超越SOTA。
未来工作方向:作者计划进一步发展无监督模型,增强掩码设计的灵活性,以匹配更丰富多样的地物特征形状,从而在更复杂场景中保持高性能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)