【Dify】提示词和知识库
在大模型(LLM)的应用开发中,提示词(Prompt)和知识库(Knowledge Base / RAG)是决定模型输出质量的两个核心要素。如果把大模型比作一个“极其聪明但没有长期记忆的专家”,那么提示词就是你对他的工作指令,而知识库则是你塞给他的参考资料。
一、 提示词 (Prompt)
提示词是你输入给大模型的文本,用来指导它如何思考和输出。好的提示词能够挖掘出大模型更深层的推理能力。
1. 提示词的核心构成要素
一个结构严谨的生产级提示词,通常包含以下部分:
- 角色 (Role/Persona):赋予模型一个身份。(例如:“你是一个资深的软件架构师…”)
- 任务 (Task):清晰定义需要解决的问题。(例如:“请审查以下代码的安全性…”)
- 上下文 (Context):提供必要的背景信息。
- 约束条件 (Constraints):限制输出范围。(例如:“只能用中文回答”、“回答不要超过200字…”)
- 输出格式 (Format):指定返回的结构。(例如:“请用 Markdown 表格返回结果”)
2. 常用提示词高级技巧
- Few-Shot (少样本提示):在提示词里给模型提供 1~2 个“输入-输出”的正确示例,模型会模仿示例的风格和逻辑进行回答。
- CoT (思维链提示):在提示词中加入“请一步步思考”,促使模型把复杂的推理过程写出来,能显著提高数学、逻辑题的准确率。
二、 知识库 (Knowledge Base / RAG)
大模型虽然聪明,但它有两个致命弱点:有知识盲区(不知道企业内部数据或最新资讯)和会胡说八道(幻觉)。知识库就是为了解决这两个问题而存在的。
在技术上,围绕知识库构建的应用通常被称为 RAG(检索增强生成,Retrieval-Augmented Generation)。
1. 知识库的工作原理
当用户提问时,系统并不是直接把问题丢给大模型,而是经历以下三步:
- 检索 (Retrieve):系统先去你的知识库(PDF、Word、网页等文档)里,把与用户问题最相关的几个片段(Chunk)找出来。
- 增强 (Augment):把这几段找出来的“参考资料”和用户的“原始问题”拼接在一起,组装成一个临时的、信息丰富的提示词。
- 生成 (Generate):大模型阅读这些参考资料,然后基于资料回答用户的问题。
2. 为什么需要知识库?
- 消除幻觉:强迫大模型“照书上说的答”,不知道的就说不知道,不再瞎编。
- 数据私密:无需将企业敏感数据拿去重新训练/微调大模型,数据只在本地或专属向量数据库中检索。
- 低成本更新:如果业务数据变了,只需更新知识库文档即可,无需花费高昂的代价去训练模型。
三、 两者的协同关系
在 Dify、LangChain 等 AI 应用开发平台上,提示词和知识库是相辅相成的:
| 维度 | 提示词 (Prompt) | 知识库 (Knowledge Base) |
|---|---|---|
| 扮演角色 | 决定模型的**“灵魂与行为”**(语气、逻辑、格式、流程控制) | 提供模型的**“粮仓与子弹”**(专业事实、业务数据、特定文档) |
| 解决问题 | 怎么说?(How to say) | 说什么?(What to say) |
| 典型应用 | 规定模型:“你必须用温柔的语气、以表格形式回答…” | 告诉模型:“关于我们公司的退换货政策,具体条款在《2026版售后手册.pdf》里…” |
四,在Dify中的使用
1.创建知识库
在Dify中,点击知识库按钮,可以直接新建一个知识库。
数据源通常选择导入已有文本。你可以让ai随便生成一个文件,比如通用测试知识库文档。
然后导入。
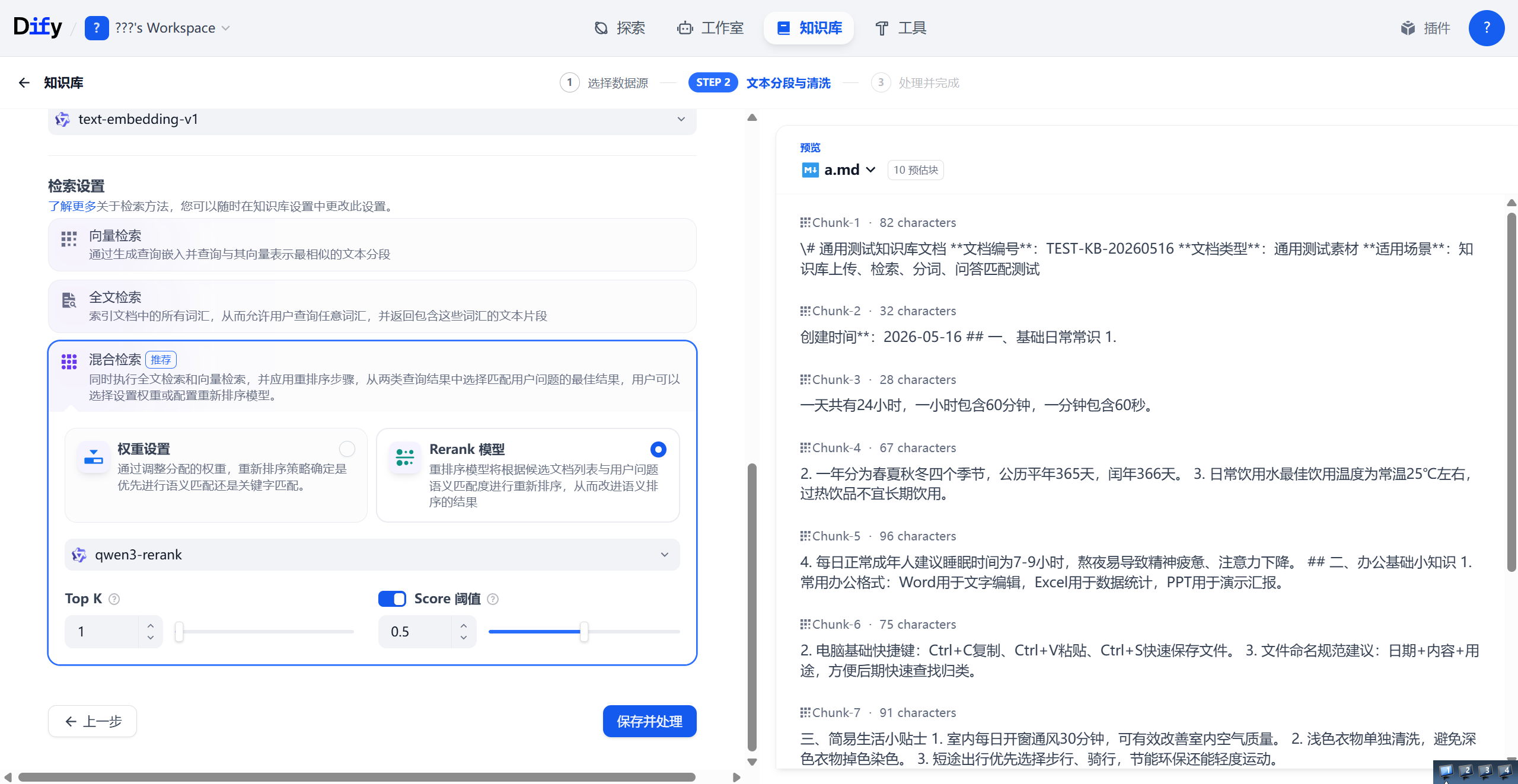
以下是有关知识库参数的相关说明。
| 环节 | 参数 | 简化说明 |
|---|---|---|
| 分段设置(如何拆分文档) | 分段标识符 | 遇到什么符号(如空行 \n\n)就切开,避免乱切 |
| 分段最大长度 | 每个文本块的最大字数,超了就强制切断 | |
| 分段重叠长度 | 相邻块之间保留几个字,防止断句丢上下文 | |
| 文本预处理 | 自动清理多余空格、换行,或把 FAQ 的问答打包成一块 | |
| 索引方式(如何存储与理解) | 通用分段 vs 父子分段 | 普通切块 vs 先切小块搜,再给大块内容,兼顾精确和完整 |
| 高质量 vs 经济索引 | 语义理解(推荐) vs 纯关键词匹配(Ctrl+F) | |
| Embedding 模型 | 把文字转成语义向量的模型,决定了“懂不懂人话” | |
| 检索设置(如何找出答案) | 检索模式 | 向量(语义)、全文(关键词)、混合(两者结合,推荐) |
| Rerank 模型 | 对初步召回结果二次排序,把最相关的放前面 | |
| Top K | 最终喂给大模型的文本块数量,越大越全但越贵 | |
| Score 阈值 | 设置相关度及格线,低于此分的直接扔掉 |
我们还可以在旁边的窗口看到文档经过这些处理之后的样子。
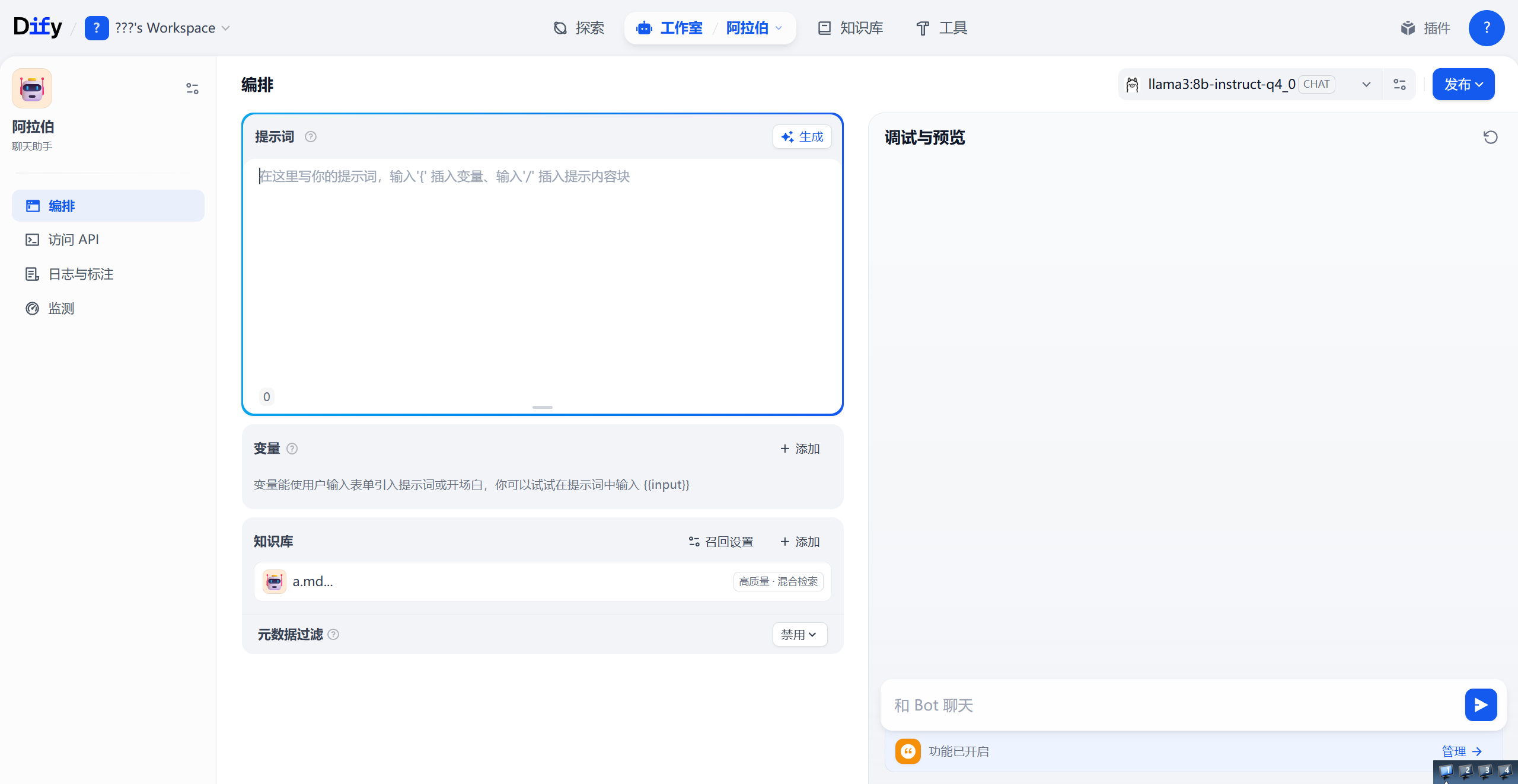
等待它处理完之后,我们可以在工作室新建一个新手适用的聊天助手。
在知识库一栏就可以导入我们刚刚的知识库。
再问的时候,Dify 等系统会把用户的问题转化为向量,然后去你之前建好的知识库里搜索最相关的文档片段(Chunk)。系统会在后台把用户的问题和刚刚捞出来的参考资料,像拼积木一样拼进一个预设好的模板(Prompt)里,变成一个长段落。系统再把这组装好的长文本整体发送给大模型(如 Llama、Qwen 等)。最后再由大模型来整理最终回答,对它来说就是看书作答,有关ai幻觉的问题就会减轻很多。
在这里,点击提示词窗口右上角的生成,还可以根据我们的简略的提示词来生成更好的提示词。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)