Agent 开发框架
一、目的
- 理解 Agent 的底层逻辑与核心思想,明确其能解决哪些问题、提升哪些效率,从而精准识别团队中适合落地 Agent 的业务场景。
- Skill 与 Agent 的核心区别,在确定可应用 AI 的项目后,能够合理判断该选用 Skill 还是 Agent 进行技术实现。
二、Agent 概率与核心技术栈
2.1 AI Agent 是什么?
AI Agent(人工智能代理)是一个能够自主行动的软件程序,通过感知环境、收集数据、并基于这些数据来执行自我决定的任务,以实现预定目标。LLMs(大模型)是现代 AI 代理的核心,因为它们提供了最关键的推理层,并且可以方便地衡量性能。其关键特点包括自主性
2.2 ReAct 启发 Agent 早期范式(ICLR 2023)
ReAct 是一种实践代理模型的高级框架,通过将大语言模型(LLMs)的推理和执行行动的能力结合起来,增强了它们在处理复杂任务时的决策能力、适应性和与外部环境的交互。ReAct 包括许多关键组件,如 LLMs、用于外部交互的工具(Tools)、多种代理类型(Agent Types)、思维链(Chain-of-Thought, CoT)Prompting 和 ReAct Prompting。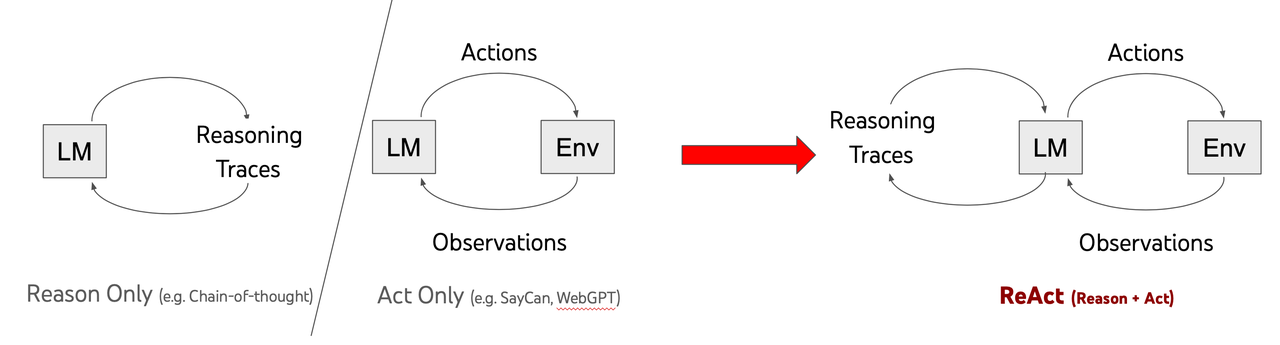
论文原文(PDF):https://arxiv.org/pdf/2210.03629.pdf
官方代码仓库:https://github.com/ysymyth/ReAct
项目主页:https://react-lm.github.io/
举个例子:
ReAct 是边想边做:让思考和行动循环协同形成一个闭环。
1、LM先做推理:会先看订单的状态,然后在看运价规则,判断是不是可以改签。
2、调用工具:查订单接口和运价规则;
3、工具把结果结果给到大模型,比如这个结果就是订单已经出票,运价规则是起飞前两小时可退。
4、LM基于这个结果继续进行推理,根据当前订单的起飞时间判断可以退,就告诉LM调用退票接口。
5、就这样一直循环,直到问题解决。
2.3 最简AI Agent 核心组建
Agents 通过传感器(Sensors)收集各类数据(Percepts),借助推理引擎(Reasoning Engine)提出合理解决方案(Rational Solutions),并通过控制系统(Actuators)执行动作(Action),以此提升能力。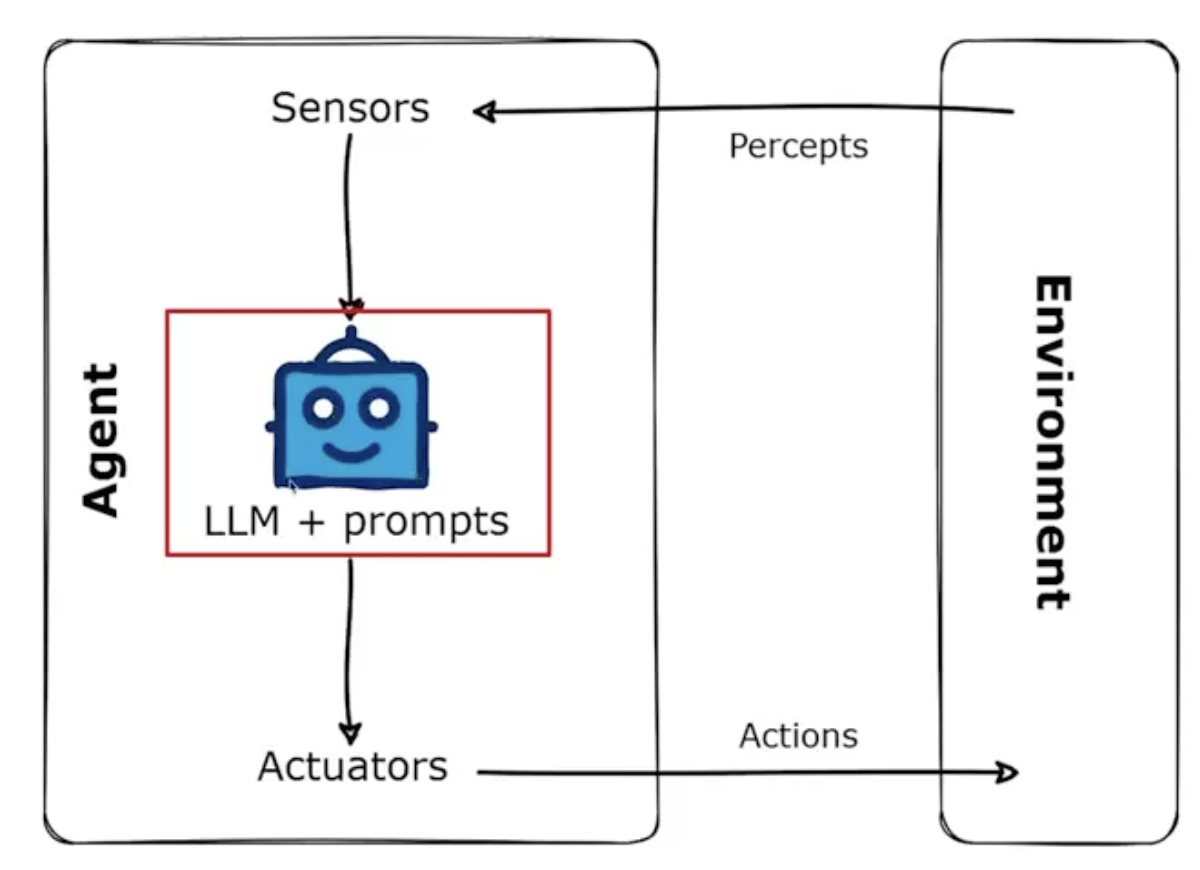
| 架构原图概念 | 类比 | 业务场景解释 |
|---|---|---|
| Environment (环境) | 航空公司 / 供应商的 GDS 系统 | 比如:航旅纵横、携程主站。它是环境,一直在变,有实时的航班库存、价格、退改签规则。 |
| Sensors (传感器) | 接口请求 + 数据库监控 | 传感器就是程序。负责盯着环境(GDS),随时抓取数据。例:每秒轮询供应商接口,获取某航班的 base_price(净价)和 availability(库存)。 |
| Percepts (感知数据) | 接口返回的 JSON 数据 | 传感器收集到的具体信息。例:{“flight”:“MU5101”, “price”:1200, “seat”:“Y”}。 |
| LLM + Prompts (大脑 / 指令) | 供应商开发的业务逻辑 + Prompt | 这是 Agent 的核心。LLM:负责理解复杂情况(如:遇到超售怎么办?)。Prompts:你们写的规则脚本(如:价格超过 1500 自动拦截,低于 1000 自动锁价)。 |
| Reasoning Engine (推理引擎) | 价格计算模块 / 风控逻辑 | 大脑里负责 “想” 的部分。例:“收到净价 1200,加上我们的佣金 200,应该卖给客户 1400。但今天是周五,需求旺,是不是可以加价?我要算一下利润。” |
| Actuators (执行器) | 下单接口 / 锁库接口 / 退款接口 | 负责把 “想法” 变成实际动作。例:推理完决定下单,执行器直接调用供应商的 book API,完成出票。 |
| Actions (行动) | 锁定库存 & 生成订单 | 最终对环境产生的影响。例:成功锁住 MU5101 的一个座位,生成了 T20240328XXX 的订单号。 |
LangChain Academy 的 Agent 示例:核心在 module-1/agent.ipynb 是官方最标准、最贴近 ReAct 思想的极简教学版,完全基于 LangGraph 实现。
官方链接:https://github.com/langchain-ai/langchain-academy/blob/main/module-1/agent.ipynb
依赖安装:langgraph(Agent 执行引擎)、langchain_openai(LLM 接入)
%%capture --no-stderr
%pip install --quiet -U langchain_openai langchain_core langgraph langgraph-prebuilt
- LangGraph:核心调度器,实现 Agent 的「思考—行动—观察」循环,控制整个业务流程。
- langchain_openai:推理能力,提供大模型能力,做业务理解、规则判断、决策。
- langchain_core:基础协议层,统一接口规范,让模型、工具。
定义 Tools(对应供应商接口):这是 Agent 的 “手脚”
from langchain_core.tools import tool
# 1. 航班查询工具(对应你们调用航司GDS接口)
@tool
def search_flights(departure: str, arrival: str, date: str) -> list:
"""查询指定航线、日期的航班信息(净价+库存)
Args:
departure: 出发城市(如SHA)
arrival: 到达城市(如PEK)
date: 日期(如2026-03-29)
Returns: 航班列表[{"flight_no": "MU5101", "base_price": 1200, "availability": 5}]
"""
# 模拟调用航司接口(你们真实代码:requests.post(gds_url, params))
return [
{"flight_no": "MU5101", "base_price": 1200, "availability": 5},
{"flight_no": "CA1501", "base_price": 1180, "availability": 3}
]
# 2. 价格计算工具(对应你们的佣金/税费计算逻辑)
@tool
def calculate_final_price(base_price: int) -> int:
"""计算最终售价(净价+佣金+税费)
Args: base_price: 航司净价
Returns: 最终售价
"""
commission = 200 # 佣金
tax = 100 # 机建燃油
return base_price + commission + tax
# 工具列表(Agent 可用的所有接口)
tools = [search_flights, calculate_final_price]
初始化 LLM(绑定工具)
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o", temperature=0) # 温度0=更稳定决策
llm_with_tools = llm.bind_tools(tools) # 让LLM知道可用哪些工具
定义 Agent 节点(LangGraph 核心)
from langgraph.graph import MessagesState, StateGraph, END
from langchain_core.messages import HumanMessage, SystemMessage
# 系统提示(给Agent的业务规则)
sys_prompt = SystemMessage(content="""
你是携程机票供应商智能Agent,严格按以下规则执行:
1. 先调用search_flights获取航班净价与库存
2. 筛选最低价航班
3. 调用calculate_final_price计算最终售价
4. 仅返回最终结果,不要多余解释
""")
# 核心节点:Agent 思考+行动
def agent_node(state: MessagesState):
# 拼接系统提示+历史消息
messages = [sys_prompt] + state["messages"]
# LLM 推理(决定是否调用工具)
response = llm_with_tools.invoke(messages)
return {"messages": [response]}
# 工具执行节点:调用接口并返回结果
def tool_node(state: MessagesState):
# 获取最后一条工具调用消息
last_msg = state["messages"][-1]
# 执行工具
tool_msgs = []
for tool_call in last_msg.tool_calls:
tool = {t.name: t for t in tools}[tool_call["name"]]
result = tool.invoke(tool_call["args"])
tool_msgs.append(ToolMessage(content=str(result), tool_call_id=tool_call["id"]))
return {"messages": tool_msgs}
# 判断是否继续循环(是否需要再调用工具)
def should_continue(state: MessagesState):
last_msg = state["messages"][-1]
# 如果有工具调用 → 走工具节点;否则结束
if last_msg.tool_calls:
return "tools"
else:
return END
构建 Agent 执行图(LangGraph 工作流)
# 初始化图
workflow = StateGraph(MessagesState)
# 添加节点
workflow.add_node("agent", agent_node)
workflow.add_node("tools", tool_node)
# 设置入口
workflow.set_entry_point("agent")
# 添加条件边(Agent → Tools 或 END)
workflow.add_conditional_edges("agent", should_continue)
# Tools → Agent(循环)
workflow.add_edge("tools", "agent")
# 编译图
agent = workflow.compile()# 初始化图
workflow = StateGraph(MessagesState)
# 添加节点
workflow.add_node("agent", agent_node)
workflow.add_node("tools", tool_node)
# 设置入口
workflow.set_entry_point("agent")
# 添加条件边(Agent → Tools 或 END)
workflow.add_conditional_edges("agent", should_continue)
# Tools → Agent(循环)
workflow.add_edge("tools", "agent")
# 编译图
agent = workflow.compile()
运行效果(机票场景真实输出)
输入(用户查询)
# 模拟用户请求:查上海→北京明天最低价
user_query = "帮我查上海到北京2026-03-29的最低价机票"
response = agent.invoke({"messages": [HumanMessage(content=user_query)]})
# 打印结果
print(response["messages"][-1].content)
输出
> 进入 Agent 循环...
Thought: 用户需要查询上海到北京2026-03-29的最低价机票,我需要先调用search_flights工具获取航班信息。
Action: search_flights(departure="SHA", arrival="PEK", date="2026-03-29")
Observation: [{"flight_no": "MU5101", "base_price": 1200, "availability": 5}, {"flight_no": "CA1501", "base_price": 1180, "availability": 3}]
Thought: 已获取航班信息,最低价是CA1501的1180元,需要调用calculate_final_price计算最终售价。
Action: calculate_final_price(base_price=1180)
Observation: 1480
Thought: 已计算出最终售价1480元,任务完成,返回结果。
Final Answer: 上海到北京2026-03-29的最低价机票为CA1501,最终售价1480元,剩余库存3张。
> 结束循环
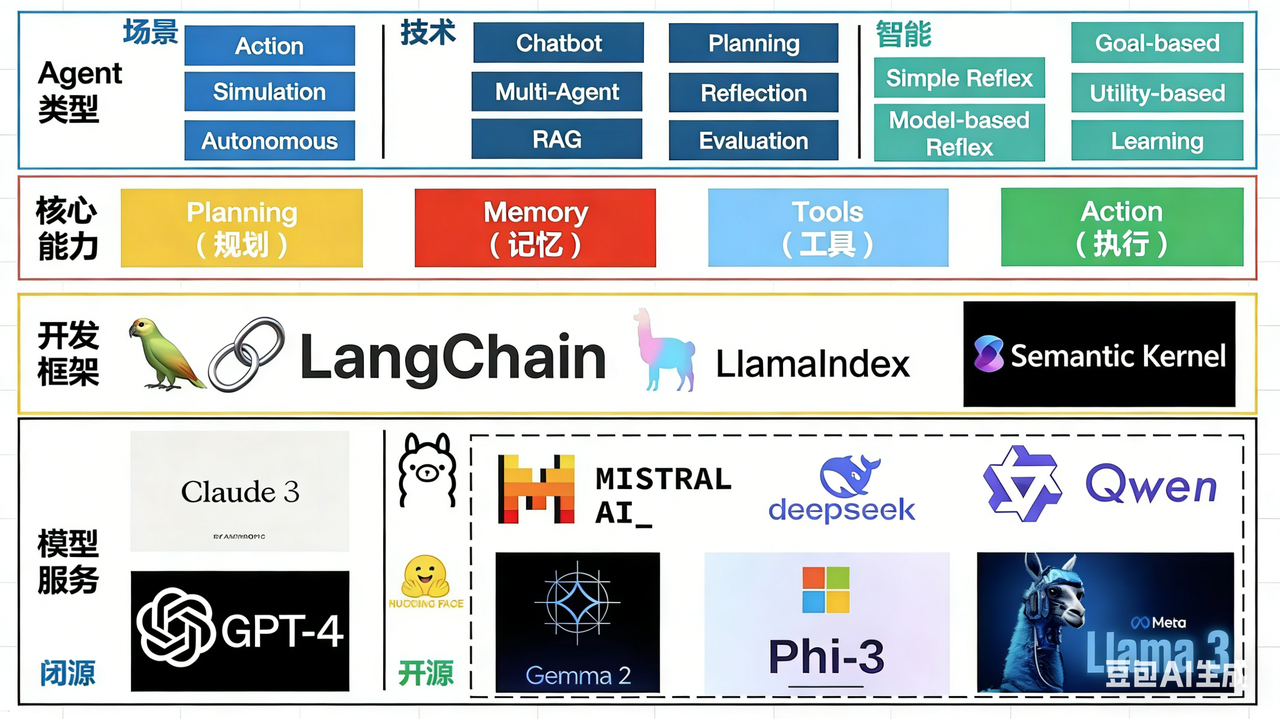
2.4 Agent 核心技术栈
3. Agent 开发典型范式
3.1 场景分类
-
行动代理(Action agents):旨在决定行动序列(工具使用)(例如 OpenAI Function Call,ReAct)。
Action Agent 示例:NL2SQL:来源:https://github.com/DjangoPeng/openai-quickstart/blob/main/openai_api/function_call.ipynbFunction Calling—— 这是 LLM 从 “只会聊天” 到 “能做事” 的核心能力。
比如:问 GPT “上海今天天气”,它不再瞎编,而是调用天气 API 给你真实数据;Function Calling 到底是什么?
- 本质:给 GPT 一个「函数清单」,让它能根据用户问题,决定要不要调用函数、调用哪个、传什么参数;
- 关键:GPT 只负责 “生成调用指令”,不执行函数 —— 执行需要我们自己写代码(比如调用天气 API、执行 SQL);
# 创建一个空的消息列表
messages = []
# 向消息列表中添加一个系统角色的消息,内容是 "Answer user questions by generating SQL queries against the Chinook Music Database."
messages.append({"role": "system", "content": "Answer user questions by generating SQL queries against the Chinook Music Database."})
# 向消息列表中添加一个用户角色的消息,内容是 "Hi, who are the top 5 artists by number of tracks?"
messages.append({"role": "user", "content": "Hi, who are the top 5 artists by number of tracks?"})
# 使用 chat_completion_request 函数获取聊天响应
chat_response = chat_completion_request(messages, functions)
# 从聊天响应中获取助手的消息
assistant_message = chat_response.json()["choices"][0]["message"]
# 将助手的消息添加到消息列表中
messages.append(assistant_message)
# 如果助手的消息中有功能调用
if assistant_message.get("function_call"):
# 使用 execute_function_call 函数执行功能调用,并获取结果
results = execute_function_call(assistant_message)
# 将功能的结果作为一个功能角色的消息添加到消息列表中
messages.append({"role": "function", "name": assistant_message["function_call"]["name"], "content": results})
# 使用 pretty_print_conversation 函数打印对话
pretty_print_conversation(messages)
- 模拟代理(Simulation agents):通常设计用于角色扮演,在模拟环境中进行(例如生成式智能体,CAMEL)。
斯坦福的虚拟小镇:- 论文 PDF:https://arxiv.org/pdf/2304.03442.pdf
- GitHub 代码:https://github.com/joonspk-research/generative_agents
- 项目主页:https://realtalk.cs.stanford.edu/
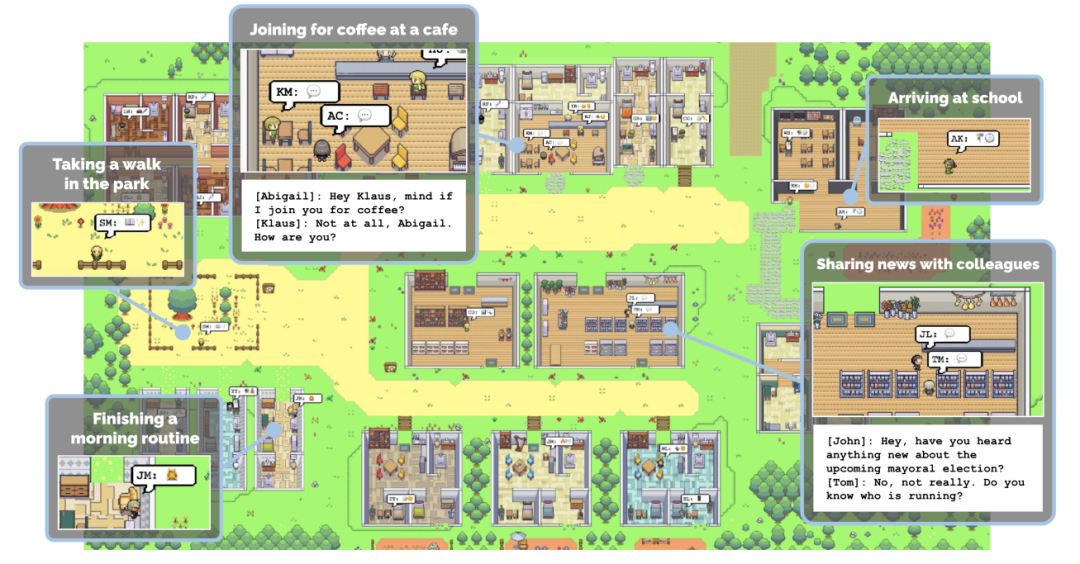
给 Agent 设定一个身份 / 性格 / 记忆,把它放进一个虚拟世界里,让它像真人一样生活、互动、做决策。
它的核心不是做游戏,而是验证一个终极问题:大模型能不能让 AI 拥有「长期记忆、自主决策、社交互动」,像真实人类一样过完一天?
- 自主智能体(Autonomous agent):旨在独立执行以实现长期目标(例如 Auto-GPT,BabyAGI)。给它一个长期目标,它能自己想办法、自己循环、自己完成,全程不用人插手。
实例化自主智能体 Auto-GPT:来源:https://github.com/DjangoPeng/openai-quickstart/blob/main/langchain/jupyter/autogpt/autogpt.ipynb
from langchain_experimental.autonomous_agents import AutoGPT
from langchain_openai import ChatOpenAI
# 1. 初始化自主智能体(机票价格监控助手)
agent = AutoGPT.from_llm_and_tools(
ai_name="PriceGuardian", # 名字:价格守护者
ai_role="机票价格监控与采购助手",
tools=tools, # 【权限】:包含查询API、锁舱API、告警API
llm=ChatOpenAI(model_name="gpt-4", temperature=0, verbose=True),
memory=vectorstore.as_retriever( # 给它“记忆”:记住之前查的价格、是否锁过舱
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.8}
),
)
# 2. 启动自主执行:目标是自动采购低价票
agent.run([
"监控上海浦东(SHA)到北京首都(PEK)的航班,"
"当2026年4月1日的航班价格低于1000元时,"
"自动锁定库存并生成订单,"
"同时发送企业微信通知给采购经理。"
])
只需要告诉它「最终目标」,不用教它 “第一步查价、第二步判断、第三步锁舱”—— 它自己会拆解步骤,而且是「长期循环」:
- 比如监控一天:它会每 10 分钟查一次价格,不用你催;
- 比如价格没到阈值:它会继续查,直到时间结束或价格达标;
- 比如价格达标了:它会自动调用锁舱 API,再发通知,全程无人干预。
| Action Agent 行动智能体 | Simulation Agent 仿真智能体 | Autonomous Agent 自主智能体 |
|---|---|---|
| 完成单个明确动作 | 模拟角色行为、真实社交 | 完成长期复杂目标 |
| 短,用完即走 | 持续运行,无“结束” | 直到目标完成才停 |
| 简单步骤 | 日常规划、日程行为 | 复杂自主多步规划 |
| 短期上下文 | 长期记忆 + 关系网 | 长期记忆 + 反思 |
| 少量固定工具 | 环境交互(走路、聊天) | 大量工具自主选择 |
| 低(你指挥) | 中(自主生活) | 最高(自主决策) |
| 查航班、调接口 | 斯坦福小镇 AI | AutoGPT、自动购票助手 |
3.2 Agent 类型
3.2.1 技术Agent

| Agent 类型(基于技术实现) | 子类型 | 描述 |
|---|---|---|
| Chatbots | Customer Support | 构建用于管理航班、酒店预订、汽车租赁等任务的客户支持聊天机器人。 |
| Prompt Generation from User Requirements | 构建用于信息收集的聊天机器人。 | |
| Code Assistant | 构建用于代码分析和生成的助手。 | |
| Multi-Agent Systems | Collaboration | 使两个智能体协作完成任务。 |
| Supervision | 使用大语言模型(LLM)来协调并委派给各个智能体。 | |
| Hierarchical Teams | 协调嵌套的智能体团队以解决问题。 | |
| RAG | Adaptive RAG | 动态调整检索策略,根据查询的特性和检索结果优化信息的获取。通常用于处理复杂或模糊的查询,确保获取最相关的数据。 |
| Agentic RAG | 智能体自主进行查询重组和与检索工具的互动,逐步优化检索结果,特别适合需要多次检索以获得最准确结果的场景。 | |
| Corrective RAG | 通过迭代反馈机制对生成的响应进行评估和修正,减少错误或幻觉的产生,确保最终输出的准确性。 | |
| Self-RAG | 集成记忆功能,保留并回忆相关的过去交互信息,增强系统在多个对话之间保持上下文和连续性的能力。 | |
| Planning Agents | Plan-and-Execute | 实现一个基本的规划与执行智能体。 |
| Reasoning without Observation | 通过将观察结果保存为变量来减少重新规划的次数。 | |
| LLMCompiler | 从规划器中流式传输并急切地执行任务的 DAG。 | |
| Reflection & Critique | Basic Reflection | 提示智能体反思并修改其输出。 |
| Reflexion | 批判遗漏和多余的细节以指导下一步行动。 | |
| Language Agent Tree Search | 通过反思和奖励驱动智能体树的搜索。 | |
| Self-Discover Agent | 分析一个能够学习自身能力的智能体。 | |
| Evaluation | Agent-based | 通过模拟用户交互评估聊天机器人。 |
| In LangSmith | 在 LangSmith 中通过对话数据集评估聊天机器人。 |
它们都解决了传统 RAG「检索不准、容易瞎编」的痛点,但反思的时机、范围和纠错逻辑完全不同。
RAG 示例:Corrective RAG (CRAG)
纠正性 RAG(CRAG)是一种用于 RAG 的策略,它包括对检索文档进行自我反思 / 自我评分。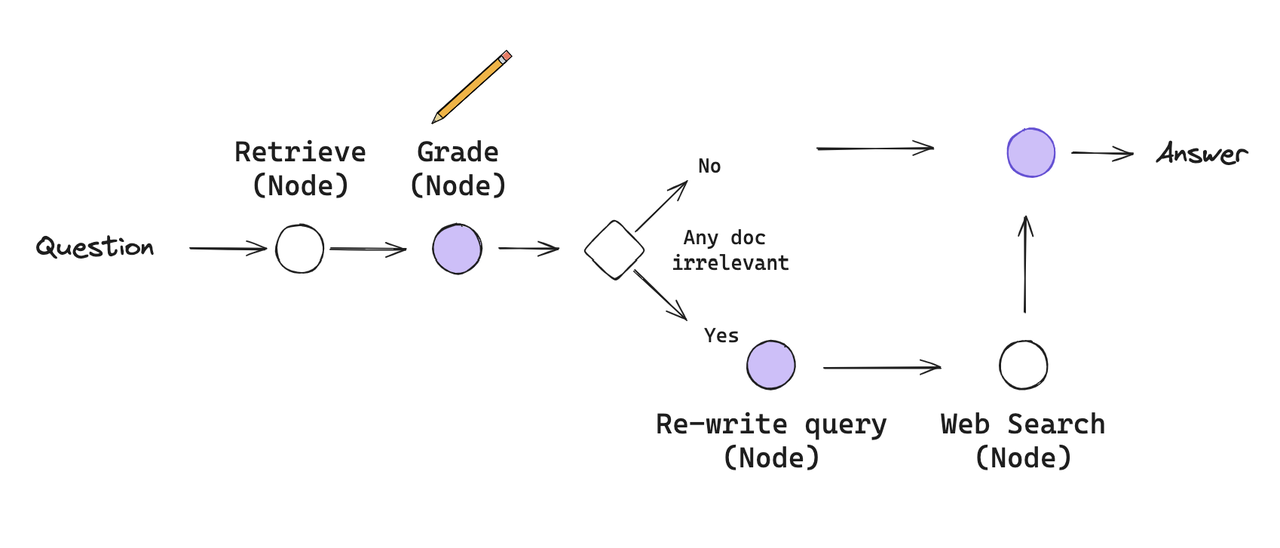
核心逻辑
第一步:用户提问题 → 从知识库检索 Top-K 文档第二步:用 LLM 给每篇文档打分(Grade),判断「是否有任何一篇无关(Any doc irrelevant?)」
- No(无无关文档):直接用检索结果生成答案
- Yes(有无关文档):重写查询语句 → 全网搜索补充信息 → 合并知识库 + 全网结果生成答案
核心特点
- 反思对象:只针对「检索文档的相关性」
- 纠错方式:发现杂质 → 去全网补信息
- 业务场景:知识库不完美、需要实时补全的场景(比如机票退改签规则、新闻资讯)
https://github.com/langchain-ai/langgraph/blob/fbcb8a9/examples/rag/langgraph_crag.ipynb
场景介绍
Create Index
from langchain.text_splitter import RecursiveCharacterTextSplitter # 文本切片工具,把长文章切成小段
from langchain_community.document_loaders import WebBaseLoader #网页抓取工具,能把网页文章爬下来
from langchain_community.vectorstores import Chroma #轻量级向量数据库,存文本 + 向量
from langchain_openai import OpenAIEmbeddingsurls #OpenAI 嵌入模型,把文字变成向量
urls = ["https://lilianweng.github.io/posts/2023-06-23-agent/", #AI Agent 智能体
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/", #提示词工程
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/", #LLM 对抗攻击
]
docs = [WebBaseLoader(url).load() for url in urls] #一行行爬取 3 个网页的内容
docs_list = [item for sublist in docs for item in sublist] #把爬出来的文章整理成一个文档列表,现在 docs_list 就是 3 篇完整文章
#长文章不能直接给 LLM 看,必须切成小块才能检索。
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0 #chunk_size=250:每 250 个 token 切一段 chunk_overlap=0:片段之间不重叠
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma", #库名
embedding=OpenAIEmbeddings(), #把每段文字变成向量
)
retriever = vectorstore.as_retriever() #创建一个 “检索器”(给后面 CRAG 使用)
RAG 的最终回答生成环节:把检索到的资料 + 用户问题 → 交给 LLM → 生成最终答案。
### Generate
from langchain import hub #提示词仓库
from langchain_core.output_parsers import StrOutputParser #把 LLM 返回的内容变成干净的字符串
# Prompt - 拉取一个官方标准 RAG 提示词,只根据提供的资料回答,不知道就说不知道,不要瞎编。”
#你是一个回答问题的助手。
#请仅使用提供的上下文资料进行回答。
#如果你不知道答案,就说不知道。
#保持回答简洁。
#问题:{question}
#资料:{context}
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Post-processing - 多个文档片段 拼接成一段干净的文字
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"context": docs, "question": question})print(generation)
把用户的问题重写成更适合网络搜索的更好问题
### Question Re-writer
# LLM
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
# Prompt
system = """ 你是一个问题重写器。 把输入的问题,改成**更适合网络搜索**的优化版本。 理解问题背后的真实意图,再改写。 """
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human","Here is the initial question: \n\n {question} \n Formulate an improved question.",
),
]
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})
定义一个 “公共盒子”,让 CRAG 流程里所有小 Agent 都能往里存东西、取东西。这个盒子叫 GraphState(流程图状态)。
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
web_search: whether to add search
documents: list of documents
"""
question: str
generation: str
web_search: str
documents: List[str]
CRAG 的核心大脑:CRAG 流程图里的所有节点(Node)和判断逻辑(Edge)
检索 → 打分 → 判断 → 重写 → 搜索 → 生成
from langchain.schema import Document
def retrieve(state): #从向量库检索相关文档
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}
def generate(state): #根据资料生成最终回答
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state): #文档打分 —— CRAG 核心
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
web_search = "No"
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
web_search = "Yes"
continue
return {"documents": filtered_docs, "question": question, "web_search": web_search}
def transform_query(state): #问题重写
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
return {"documents": documents, "question": better_question}
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
documents.append(web_results)
return {"documents": documents, "question": question}
### Edges
def decide_to_generate(state): #判断决策 —— 流程图的菱形
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
web_search = state["web_search"]
state["documents"]
if web_search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
CRAG 的总流程图
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generate
workflow.add_node("transform_query", transform_query) # transform_query
workflow.add_node("web_search_node", web_search) # web search
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "web_search_node")
workflow.add_edge("web_search_node", "generate")
workflow.add_edge("generate", END)
# Compile
app = workflow.compile()
RAG 示例:Self-RAG
Self-RAG 是 RAG 的一种策略,它包括对检索到的文档和生成内容进行自我反思 / 自我评分。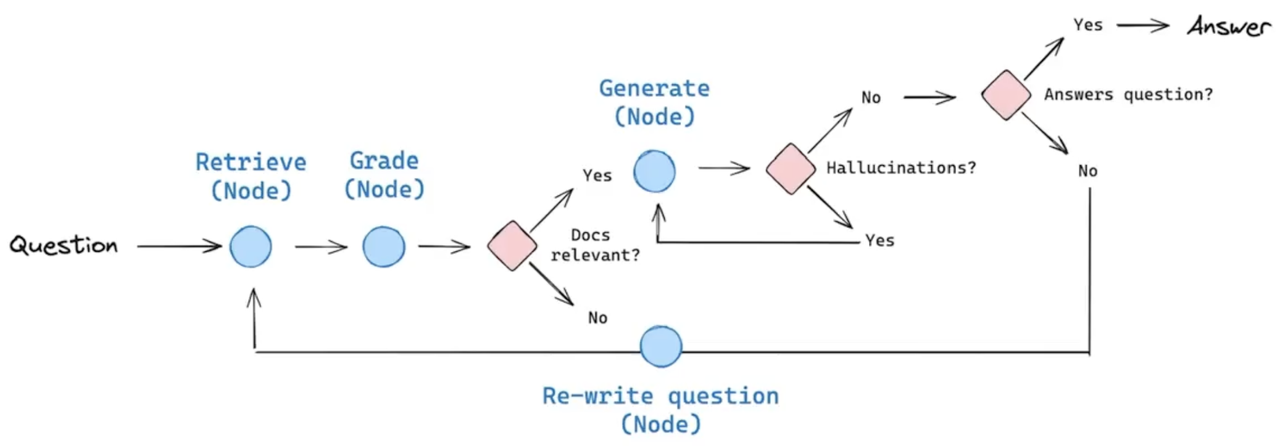
Self-RAG 完整流程
- Question → Retrieve → Grade
- 先检索知识库,再用 LLM 打分判断:Docs relevant?
- No(有无关文档) → 回到最开始,重新检索(图里箭头指回 Retrieve)
- Yes(全部相关) → 进入生成环节
- Generate(生成草稿回答)
- 用所有相关文档生成一个内部草稿
- 第一轮自检:Hallucinations?(有没有瞎编?)
- Yes(有幻觉 / 不被文档支撑) → 回到 Generate,重写草稿
- No(无幻觉) → 进入下一轮自检
- 第二轮自检:Answers question?(有没有答到点上?)
- No(答非所问 / 没用) → 回到最开始,重新检索 + 重新提问(图里箭头指回最顶端的 Question/Retrieve)
- Yes(有用且准确) → 输出最终 Answer
Planning Agents 示例
LLMCompiler:LLMCompiler 是一种代理架构,解决了传统 Agent 串行执行、多次调用 LLM、Token 成本高的痛点,核心是把任务拆成 DAG,并行执行,还能省 Token。
https://github.com/AlphaFrank/langgraph/blob/main/examples/reflexion/reflexion.ipynb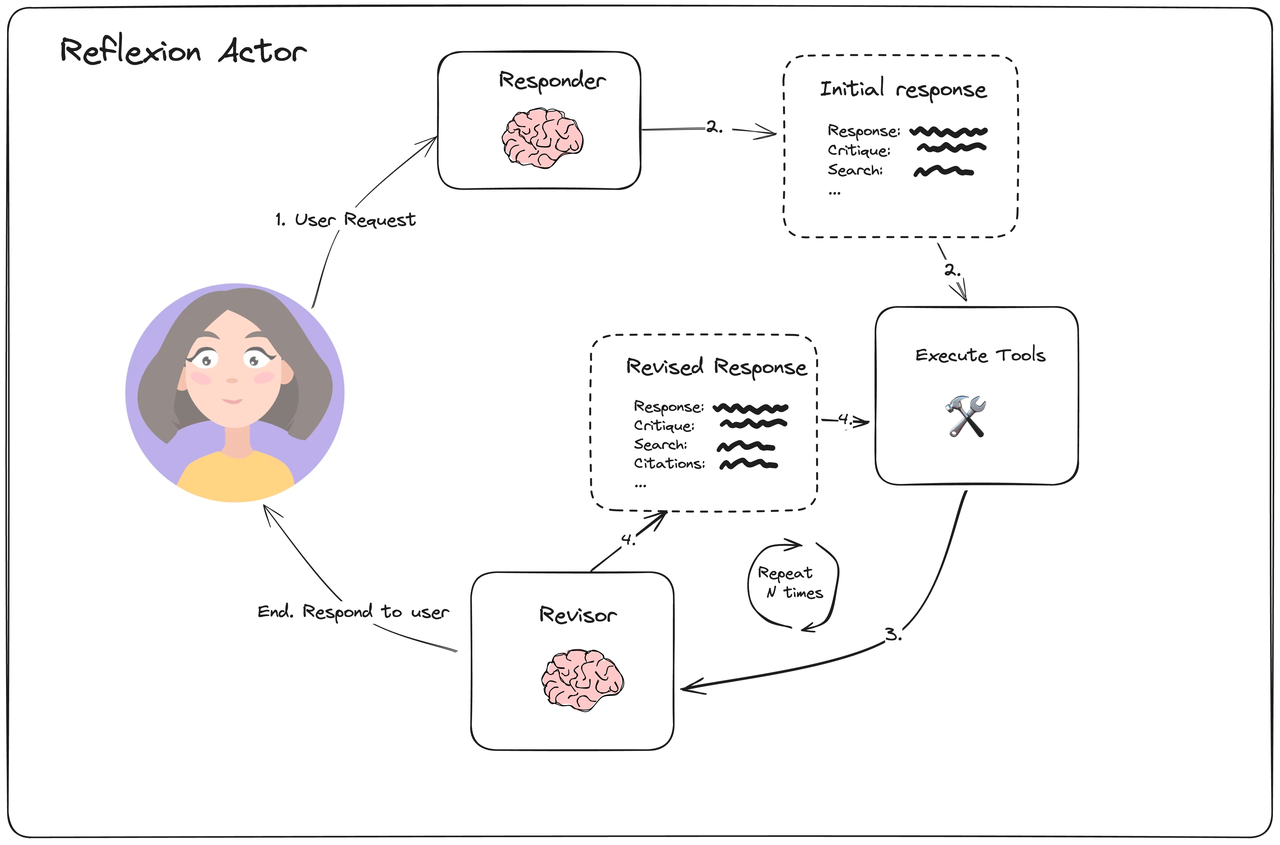
3 个主要组件:
- 规划器:流式 DAG 任务。接收用户请求 → 生成有序步骤列表 → 形成流式 DAG 任务
// 定义规划输出结构:步骤列表(代表DAG任务流)
const planObject = z.object({
steps: z.array(z.string()).describe("有序执行步骤"),
});
// 规划提示词:让LLM生成多步计划(DAG流)
const plannerPrompt = ChatPromptTemplate.fromTemplate(
`For the given objective, come up with a simple step by step plan.
生成有序步骤,确保可以独立执行。
{objective}`
);
// LLM + 结构化输出 = 规划器
const model = new ChatOpenAI({ modelName: "gpt-4-0125-preview" })
const structuredModel = model.withStructuredOutput(planObject);
const planner = plannerPrompt.pipe(structuredModel);
// 规划节点:生成任务计划(DAG任务流)
async function planStep(state: PlanExecuteState.State) {
// 调用LLM生成步骤列表(DAG)
const plan = await planner.invoke({ objective: state.input });
// 返回计划,存入state
return { plan: plan.steps };
}
- 任务获取单元:安排并执行任务,一旦可执行即立即执行。
// 执行器:使用ReactAgent执行单个任务
const agentExecutor = createReactAgent({
llm: new ChatOpenAI({ model: "gpt-4o" }),
tools: [new TavilySearch({ maxResults: 3 })], // 工具
});
// 任务执行节点:一旦任务可执行,立即运行
async function executeStep(
state: PlanExecuteState.State,
config?: RunnableConfig
): Promise<Partial<PlanExecuteState.State>> {
// 取出当前可执行的任务(第一个任务)
const task = state.plan[0];
// 立即执行任务
const { messages } = await agentExecutor.invoke({
messages: [new HumanMessage(task)],
}, config);
// 找出所有【无依赖、可执行】任务
const runnableTasks = state.plan.filter(t => !t.dependsOn)
// 并行一起执行!
const results = await Promise.all(
runnableTasks.map(task => agentExecutor.invoke({
messages: [new HumanMessage(task.content)]
}))
)
// 获取执行结果
const result = messages[messages.length - 1].content.toString();
// 从计划中移除已完成任务,并保存结果
return {
pastSteps: [[task, result]],
plan: state.plan.slice(1),
};
}
- 连接器:响应用户或触发第二计划。
// 重规划提示词:检查是否完成,或继续规划
const replannerPrompt = ChatPromptTemplate.fromTemplate(
`根据目标、已完成步骤、剩余步骤,判断是否完成。
若完成 → 直接回复用户
未完成 → 更新剩余计划
...`
);
// 重规划器(Joiner)
const replanner = replannerPrompt
.pipe(new ChatOpenAI({ model: "gpt-4o" }).bindTools([planTool, responseTool]))
.pipe(new JsonOutputToolsParser());
// 重规划节点:连接器核心逻辑
async function replanStep(state: PlanExecuteState.State) {
const output = await replanner.invoke({
input: state.input,
plan: state.plan.join("\n"),
pastSteps: state.pastSteps.map(([s, r]) => `${s}: ${r}`).join("\n"),
});
const toolCall = output[0];
// ==========================
// 完成 → 响应用户
// ==========================
if (toolCall.type == "response") {
return { response: toolCall.args?.response };
}
// ==========================
// 未完成 → 触发第二轮计划
// ==========================
return { plan: toolCall.args?.steps };
}
Reflection & Critique 示例
Language Agent Tree Search(LATS):语言代理树搜索(LATS),是一种通用的 LLM 代理搜索算法,它结合了反思 / 评估和搜索(具体来说是蒙特卡洛树搜索)以实现比类似技术如 ReACT、Reflection 或 Tree of Thoughts 更好的整体任务性能。解决了 ReAct等方案容易走偏、搜索效率低的问题。
边试错、边反思、边打分,最后找到最优解
https://github.com/lapisrocks/LanguageAgentTreeSearch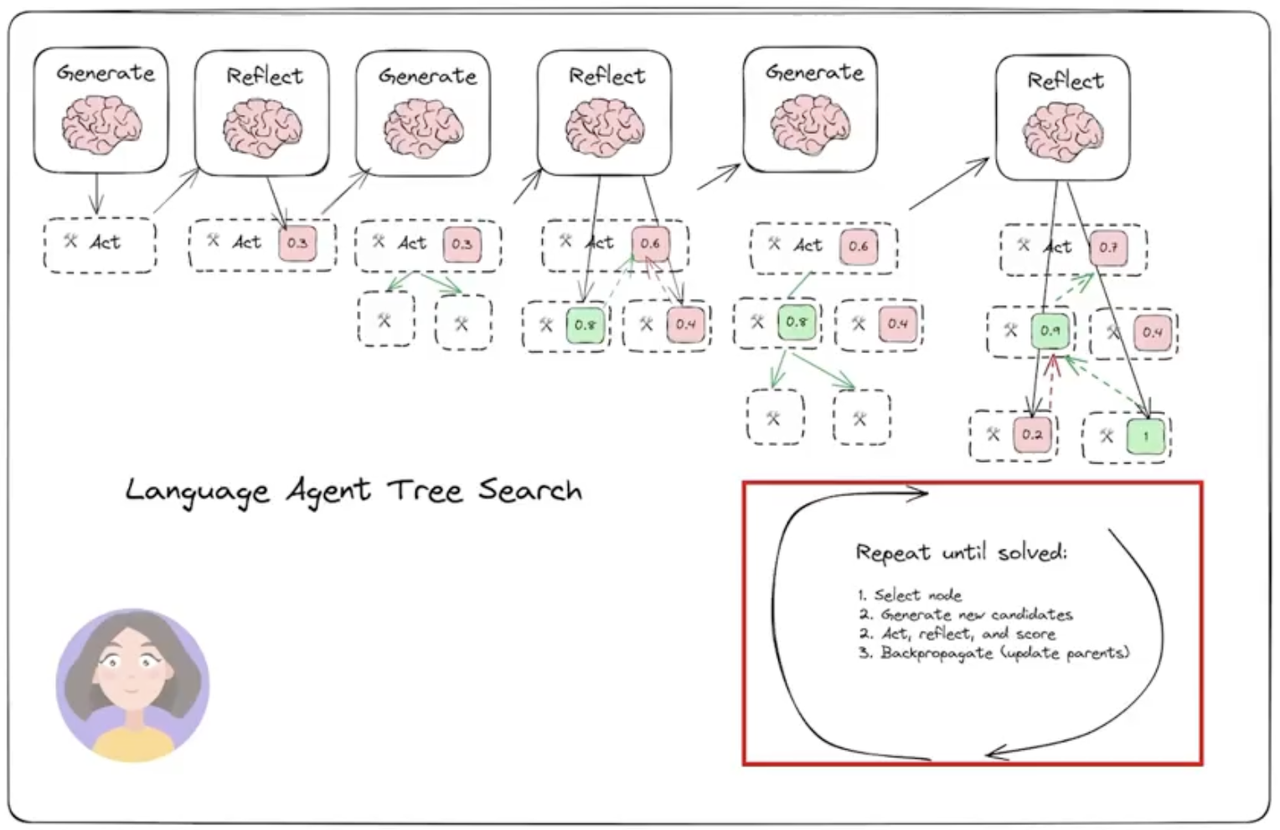
3.2.1.1.1 左侧:Generate → Act → Reflect → Score 循环
这是单个节点的探索逻辑,对应图里的「生成 - 行动 - 反思 - 打分」:
- Generate(生成):LLM 生成下一步可能的行动(比如机票场景里「查价格」「查准点率」)
- Act(执行):执行这个行动,拿到结果(比如查到航班价格是 500 元)
- Reflect(反思):LLM 自我复盘:
- 这个行动有没有帮我接近答案?
- 有没有错误 / 幻觉?
- 下一步该往哪走?
- Score(打分):给这个行动 / 节点打一个 0~1 的分数(比如图里的 0.3、0.8、0.9),分数越高说明这个方向越有希望
3.2.1.1.2 中间:决策树的生长与探索
这是多分支并行探索的过程,对应图里的树状结构:
- 每个带分数的方块就是一个节点(代表一个行动 / 状态)
- 绿色节点 = 高分(有希望的方向),红色节点 = 低分(没用 / 错误的方向)
- 箭头代表依赖关系:子节点的分数会影响父节点的选择
- 比如图里:
- 一开始打 0.3 分的节点,探索后长出了 0.8 分的高分子节点
- 高分节点会被优先继续探索,低分节点慢慢被放弃
3.2.1.1.3 右侧红框:核心循环流程(Repeat until solved)
这是 LATS 的总控逻辑,直到问题解决才停止:
- Select node(选择节点):
- 从当前树里,根据总分选最有潜力的节点继续探索
- 高分节点优先,低分节点暂时搁置
- 如果已经找到答案,或达到最大深度,就结束流程
- Generate new candidates & Act, reflect, score(扩展 + 评估):
- 给选中的节点,生成多个候选行动(比如 5 个)
- 并行执行这些行动,然后逐一反思 + 打分
- Backpropagate(回传):
- 把子节点的分数向上传递,更新父节点、根节点的总分
- 让整个树都知道「哪条分支更优」,为下一轮选择提供依据
- 比如图里最右下角的 1 分节点,会把分数往上传给父节点,让父节点变成更优选择
https://github.com/AlphaFrank/langgraph/blob/main/examples/reflexion/reflexion.ipynb
Multi-agent 示例:2 Agents Collaboration
单 Agent 即使由 gpt-4 这样强大的模型驱动,在使用许多工具时仍可能效果较差。因此,处理复杂任务时可以通过 “分而治之” 的方式,为每个任务或领域创建一个专门的代理,并将任务路由到正确的 “专家”。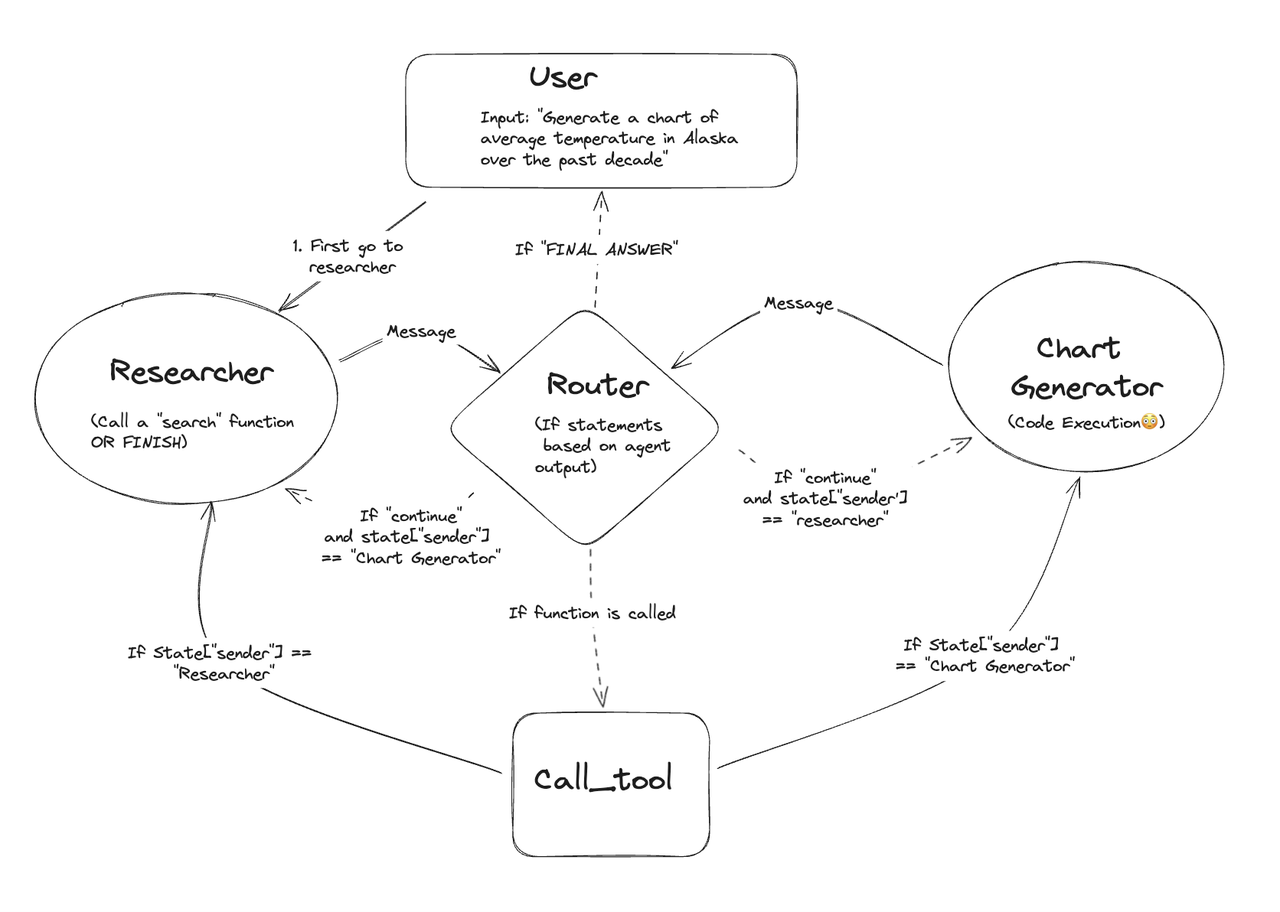
核心角色:
- User:提需求
- Router:总调度器,根据消息来源和内容决定下一步派给谁
import { AIMessage } from "@langchain/core/messages";
// Either agent can decide to end
function router(state: typeof AgentState.State) {
const messages = state.messages;
const lastMessage = messages[messages.length - 1] as AIMessage;
// 判断1:如果需要调用工具
if (lastMessage?.tool_calls && lastMessage.tool_calls.length > 0) {
return "call_tool";
}
// 判断2:如果输出 FINAL ANSWER → 结束
if (
typeof lastMessage.content === "string" &&
lastMessage.content.includes("FINAL ANSWER")
) {
return "end";
}
// 判断3:否则继续切换 Agent
return "continue";
}
- Researcher:数据研究员,负责调用搜索工具查原始数据
- Chart Generator:图表生成器,负责写代码把数据可视化
- Call_tool:工具调用层,执行搜索 / 代码执行等实际操作
https://github.com/langchain-ai/langgraph/blob/main/examples/multi_agent/multi_agent_collaboration.ipynb
import { END, START, StateGraph } from "@langchain/langgraph";
// 1. Create the graph
const workflow = new StateGraph(AgentState)
// 2. Add the nodes; these will do the work
.addNode("Researcher", researchNode)
.addNode("ChartGenerator", chartNode)
.addNode("call_tool", toolNode);
// 3. Define the edges. We will define both regular and conditional ones
// After a worker completes, report to supervisor
workflow.addConditionalEdges("Researcher", router, {
// We will transition to the other agent
continue: "ChartGenerator",
call_tool: "call_tool",
end: END,
});
workflow.addConditionalEdges("ChartGenerator", router, {
// We will transition to the other agent
continue: "Researcher",
call_tool: "call_tool",
end: END,
});
workflow.addConditionalEdges(
"call_tool",
// Each agent node updates the 'sender' field
// the tool calling node does not, meaning
// this edge will route back to the original agent
// who invoked the tool
(x) => x.sender,
{
Researcher: "Researcher",
ChartGenerator: "ChartGenerator",
},
);
workflow.addEdge(START, "Researcher");
const graph = workflow.compile();
Multi-agent 示例:Agent Supervisor
代理监督员(Supervisor):当 Agents 数量上升后,使用 LLM 来决策和路由不同的 Agent 是一种更高效的方式。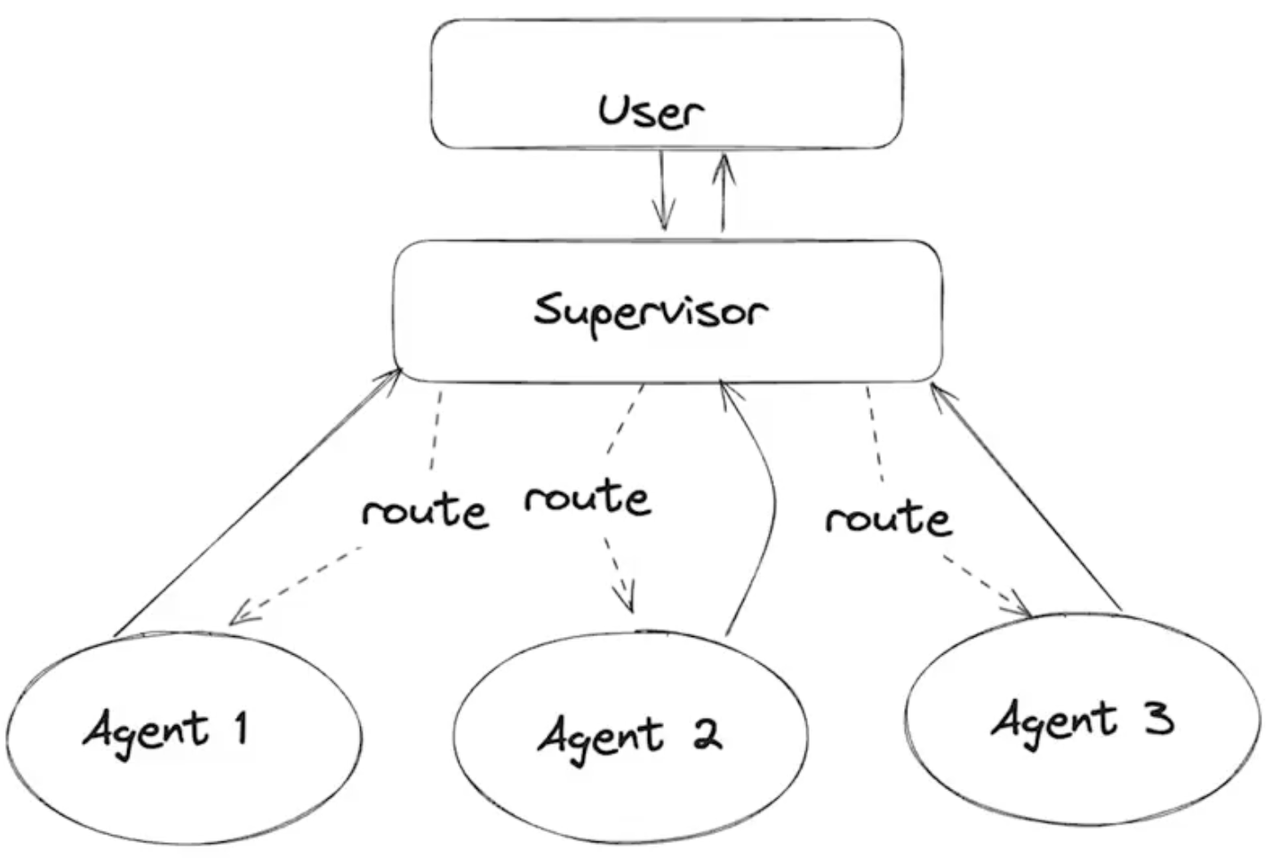
核心角色
- User:提需求
- Supervisor:超级管理员 / 监督员,由 LLM 驱动,负责:
- 理解用户需求
- 把任务拆成子任务
- 路由给对应的专家 Agent
- Agent 1/2/3:领域专家,比如「机票查询专家」「退改签规则专家」「客服话术专家」
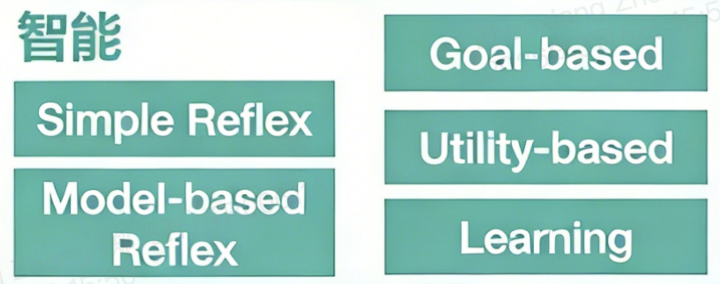
3.2.2 智能Agent
AI Agent 典型分类(基于智能程度)
Simple Reflex agent
简单反射代理(Simple Reflex Agent):最简单的代理类型,基于当前感知做出决策,忽略所有先前的感知历史。这些代理适用于完全可观察的环境,并且是基于条件 - 动作规则的,例如只有当房间里有灰尘时,房间清洁代理才会工作。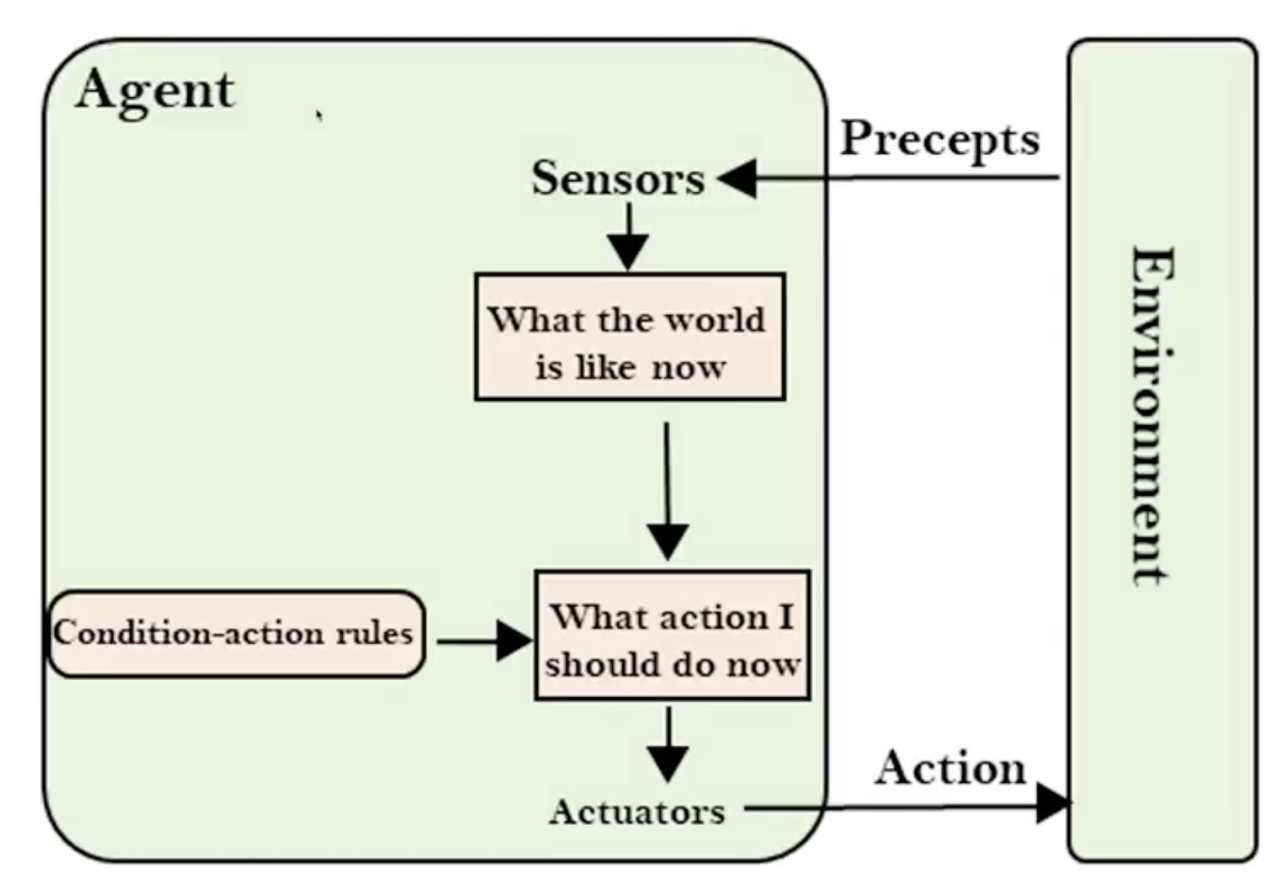
流程对照图:
- Sensors:获取当前环境感知
- What the world is like now:只记录当前瞬间状态
- Condition-action rules:匹配「如果… 就…」规则
- What action I should do now:输出动作
- Actuators:执行动作
Model-based reflex agent
基于模型的反射代理(Model-based Reflex Agent):这类代理能够在部分可观察的环境中工作,并跟踪情况。它们拥有模型和内部状态,模型是关于世界如何运作的知识,内部状态是基于感知历史的当前状态的表示。
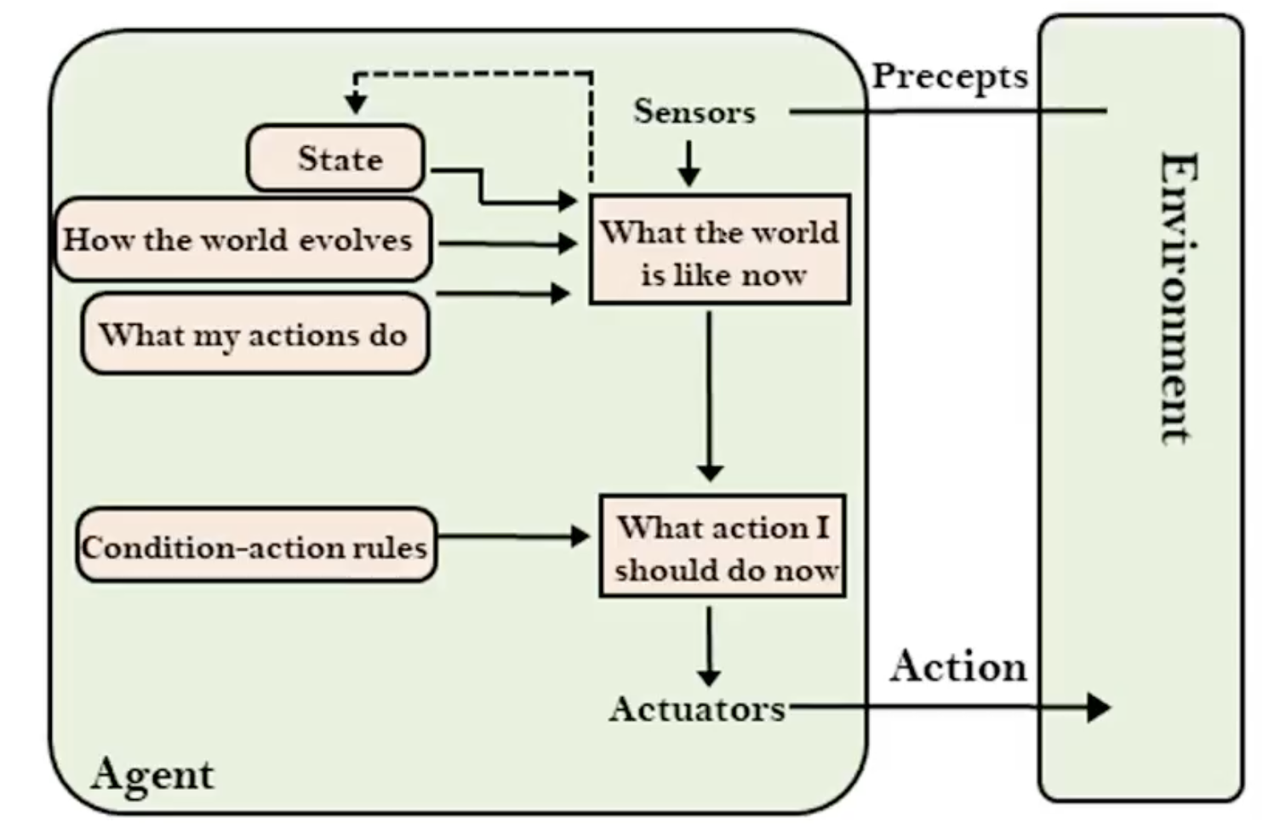
关键新增模块:
- State:记录感知历史,维护当前世界状态
- Model:包含两块知识
- How the world evolves:世界自身变化规律
- What my actions do:我的行动对世界的影响
Goal-based agents
目标型代理(Goal-based Agents):这些代理需要知道它们的目标,即描述理想情况的信息。它们通过考虑长序列可能的动作来扩展基于模型的代理的能力,这种考虑被称为搜索和规划(Planning)。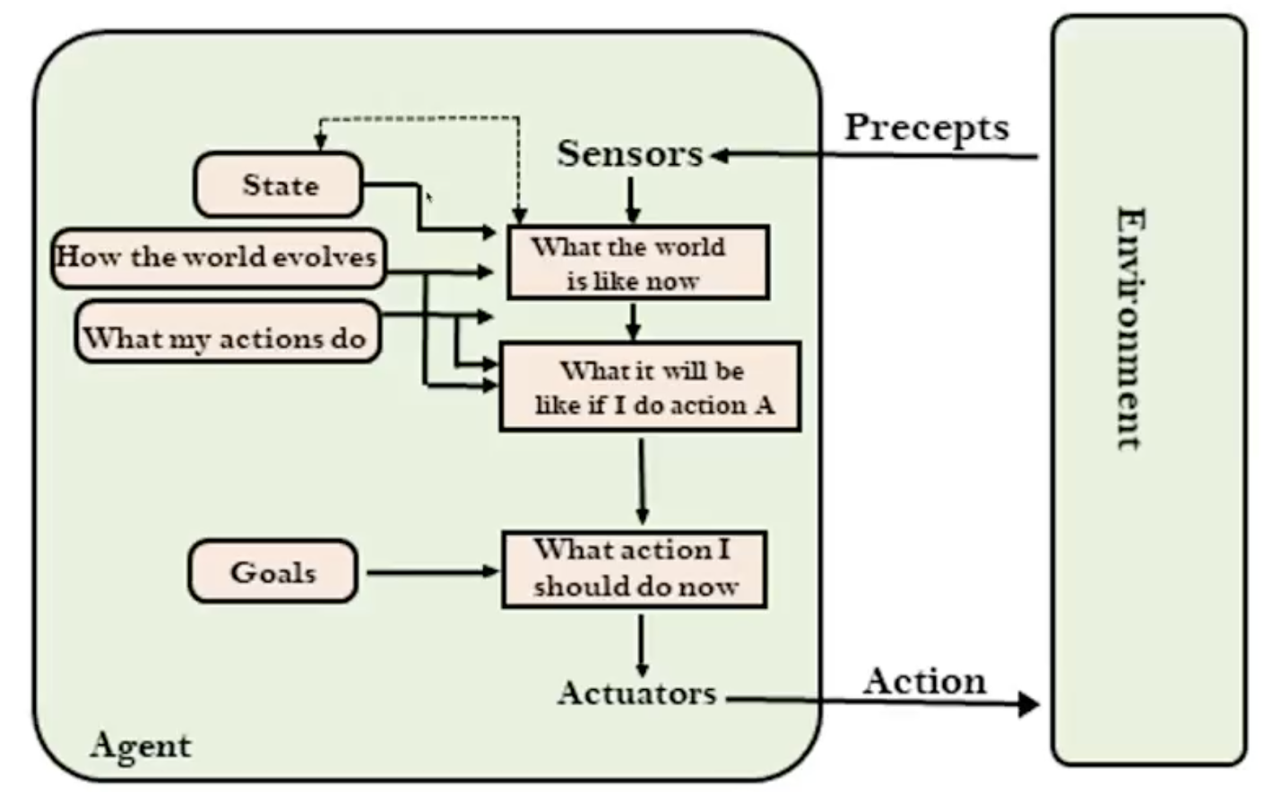
关键新增模块:
- Goals:描述理想状态
- What it will be like if I do action A:模拟行动后的未来状态,做前向搜索 / 规划
Utility-based agents
效用型代理(Utility-based Agent):这些代理不仅考虑目标,还考虑实现目标的最佳方式。它们在有多个可能的选择时特别有用,并且有一个效用函数来衡量每个状态如何有效地实现目标。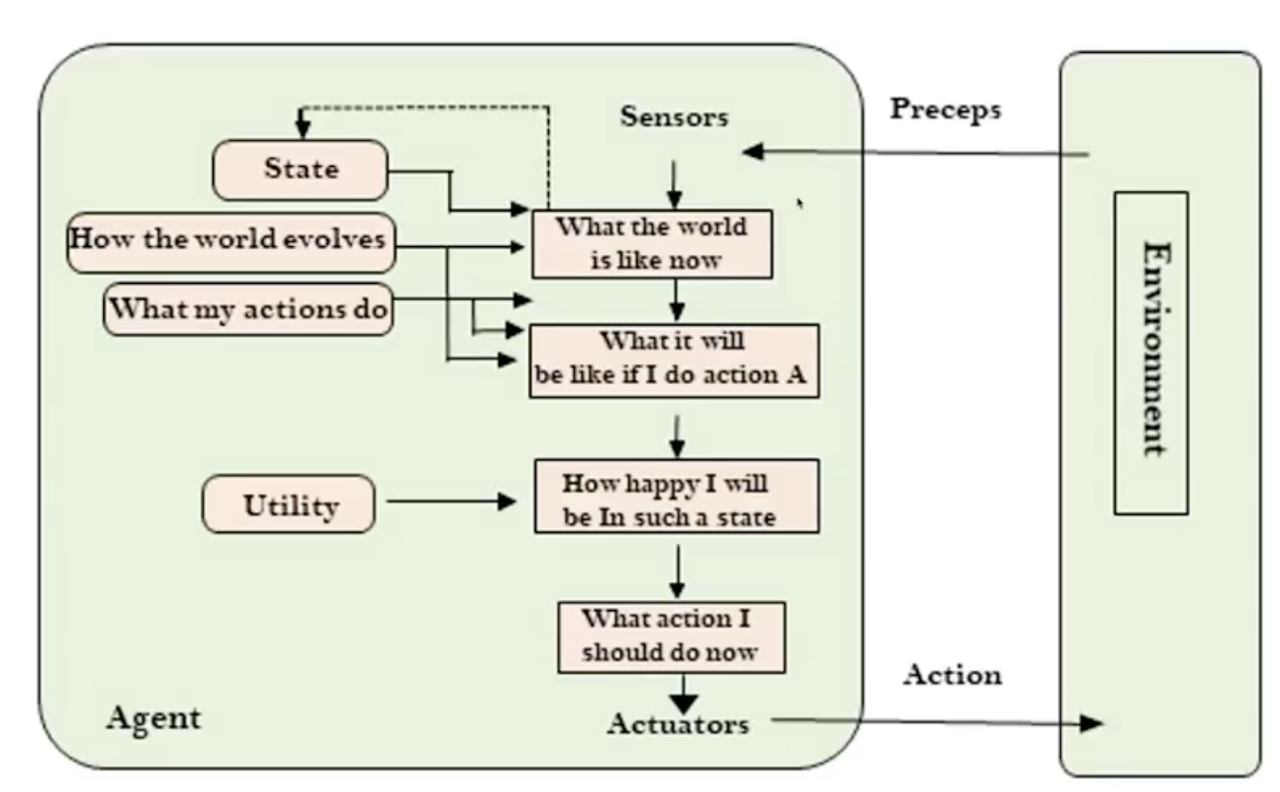
关键新增模块:
- Utility:给每个状态打分(0~1 分),衡量「这个状态有多好」
- How happy I will be in such a state:评估每个未来状态的效用值
Learning Agents
学习型代理(Learning Agent):学习型代理能够从过去的经验中学习,随着时间的推移提高其性能。它们有四个主要组成部分:学习元素、评论员、性能元素和问题生成器。学习元素负责通过学习来改进,评论员提供反馈以衡量性能,性能元素选择外部动作,问题生成器建议导致新颖和有教育意义的经验的动作。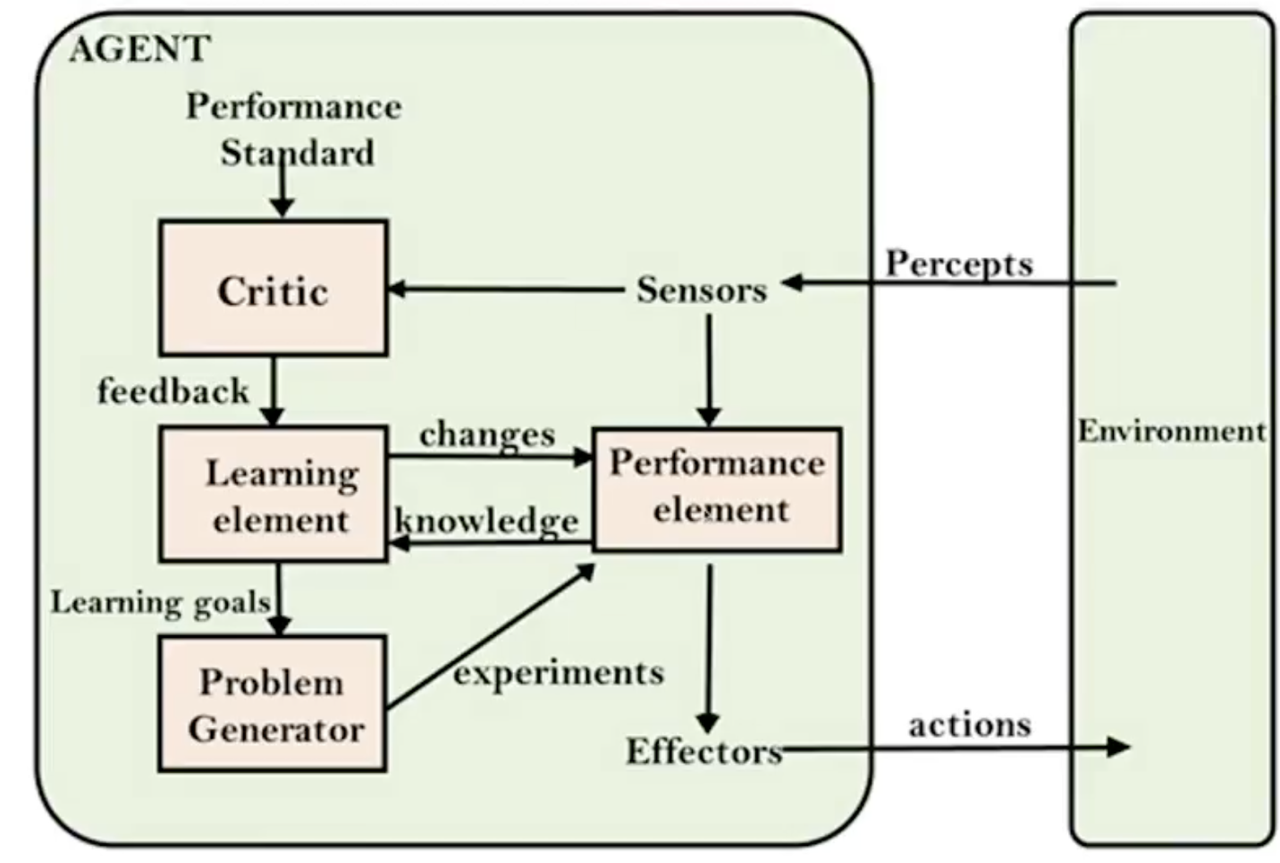
四大核心组件:
- Performance element:相当于前面 4 种 Agent 的执行器,负责选动作。
- Critic(评论员):根据Performance Standard(性能标准)给当前表现打分,提供反馈
- Learning element:根据反馈,修改 Performance element 的规则 / 模型
- Problem Generator:主动探索新场景,避免陷入局部最优。
| 智能体类型 | 决策依据 (Action) | 记忆 (Memory) | 规划能力 (Planning) | 学习能力 (Learning) | 示例行为 |
|---|---|---|---|---|---|
| Simple Reflex Agents(简单反射型智能体) | 当前感知 | 无 | 无 | 无 | 仅根据当前情况做出反应,不考虑过去的事件。 |
| Model-based Reflex Agents(基于模型的反射型智能体) | 当前感知 + 转换模型 | 有(跟踪状态) | 有限(基于转换模型) | 无 | 使用过去的感知更新内部状态,以便做出当前决策。 |
| Goal-based Agents(基于目标的智能体) | 实现特定目标 | 有(状态和目标) | 有(规划行动) | 无 | 规划一系列行动以实现特定目标。 |
| Utility-based Agents(基于效用的智能体) | 预期效用 | 有(状态、目标和效用) | 有(最大化效用) | 无 | 选择那些能最大化整体预期效用的行动,考虑各种权衡。 |
| Learning Agents(学习型智能体) | 环境反馈 | 有(状态、目标和效用) | 有(随学习不断改进) | 有(随时间改进) | 根据反馈和经验不断优化行为与决策。 |
Agent 核心能力与开发框架

4.1 AI Agent 基本框架
OpenAI 的研究主管 Lilian Weng 曾经写过一篇博客叫做《LLM Powered Autonomous Agents》,其中就很好的介绍了 Agent 的设计框架,她提出了 Agent = LLM + 规划 + 记忆 + 工具使用 的基础架构,其中大模型 LLM 扮演了 Agent 的 “大脑”。
4.1.1 核心组成部分
4.1.1.1 Planning(规划)
规划主要做两件事:任务拆解 + 反思改进
- 任务拆解把一个复杂大任务,拆成一步步能执行的小任务。比如用户说:“帮我买一张上海到北京、价格不超过 1000 的机票。”
- Agent 不会直接去下单,它会拆成:查航班 → 筛选直飞 → 查价格 → 查库存 → 计算总价 → 判断是否符合预算 → 锁舱。
- 反思与改进就是 Agent 能自我复盘:上一步为什么没查到合适航班?是不是条件太严?要不要放宽时间?相当于自己给自己 “查错、优化”。
在我们供应商系统里,这就非常有用:比如查不到票时,Agent 能自动调整策略,而不是直接返回失败。
4.1.1.2 Memory(记忆)
记忆分两种:短期记忆和长期记忆。
- 短期记忆就是当前对话的上下文。比如你前面说 “要早上的航班”,后面 Agent 要记得这个偏好,不会给你推晚上的。本质就是模型的上下文窗口。
- 长期记忆存大量历史信息,比如:用户常买的航线、供应商历史价格波动、某航司常见的超售规律、退改签规则等。一般存在向量数据库里,需要时快速检索。
放到我们业务里:Agent 能记住 “某供应商经常下午放低价票”,到点自动去查,这就是长期记忆的价值。
4.1.1.3 Tools(工具)
LLM 本身是 “死知识”,不知道实时航班、不知道当前库存、不会调用接口。所以必须给它装 “工具”。
工具就是外部 API:
- 查航班接口
- 查价格接口
- 查库存接口
- 锁舱接口
- 计算价格、税费、佣金的工具
- 甚至查询退改签规则的知识库
Agent 通过调用工具,才能拿到实时、真实、外部系统的数据。
没有工具,LLM 就是个只会吹牛的大脑,干不了实际业务。
4.1.1.4 Action(动作)
最后一步是 Action:真正动手做事。
大脑(LLM)根据:
- 用户的问题 Query
- 规划好的步骤 Planning
- 历史记忆 Memory
- 工具返回的结果 Tools
综合判断,最终决定做什么动作: - 调用查询
- 调用锁舱
- 生成订单
- 推送消息
- 或者告诉用户无满足条件的票
这就是 Agent 最终输出的 “行为”。
4.2 开发框架
4.2.1 LangChain
首个覆盖了从 Agent 开发、测试到部署全生命周期的应用框架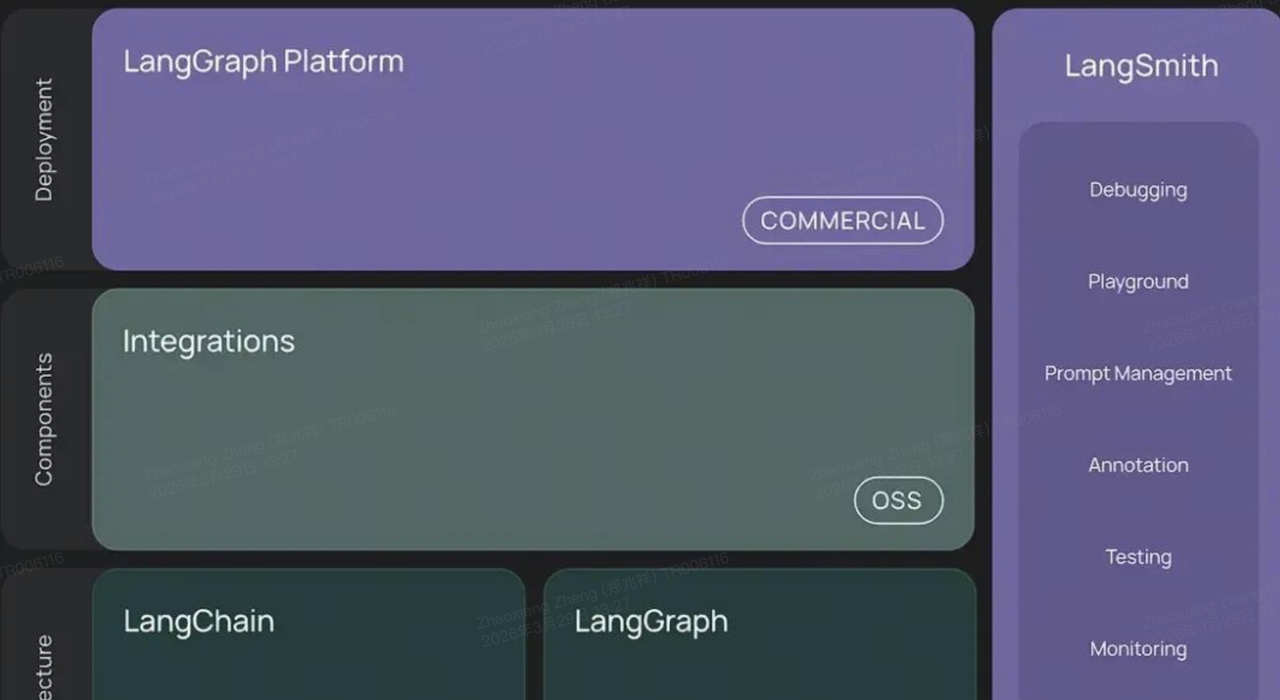
英文原版:https://docs.langchain.com/oss/python/langgraph/overview
中文镜像:https://docs.langchain.org.cn/oss/python/langgraph/overview
对应的 GitHub 生态汇总:https://github.com/von-development/awesome-langgraph
LangChain 生态拆成了三层,从下到上是「基础架构 → 组件能力 → 部署平台」:
- Architecture(底层架构):
- LangChain:传统的链 / 工具 / 提示词抽象,是对接供应商接口、封装业务逻辑的基础。
- LangGraph:核心 Agent 引擎,用「图结构」管理「思考 - 行动 - 观察」循环,是实现机票自动查价 / 锁库 / 下单的关键。
- Components(中间组件):
- Integrations:开源(OSS)的第三方集成,比如对接航司 GDS、支付系统、消息队列等,你们的供应商接口都可以封装成这里的工具。
- Deployment(上层部署):
- LangGraph Platform:商业版部署平台,用来把 Agent 上线、扩容、管理,适合你们把机票 Agent 做成生产服务。
- 右侧工具链(LangSmith):
- 全生命周期工具:Debug、Playground、Prompt 管理、测试、监控,是你们排查 Agent 决策问题、优化业务规则的利器。
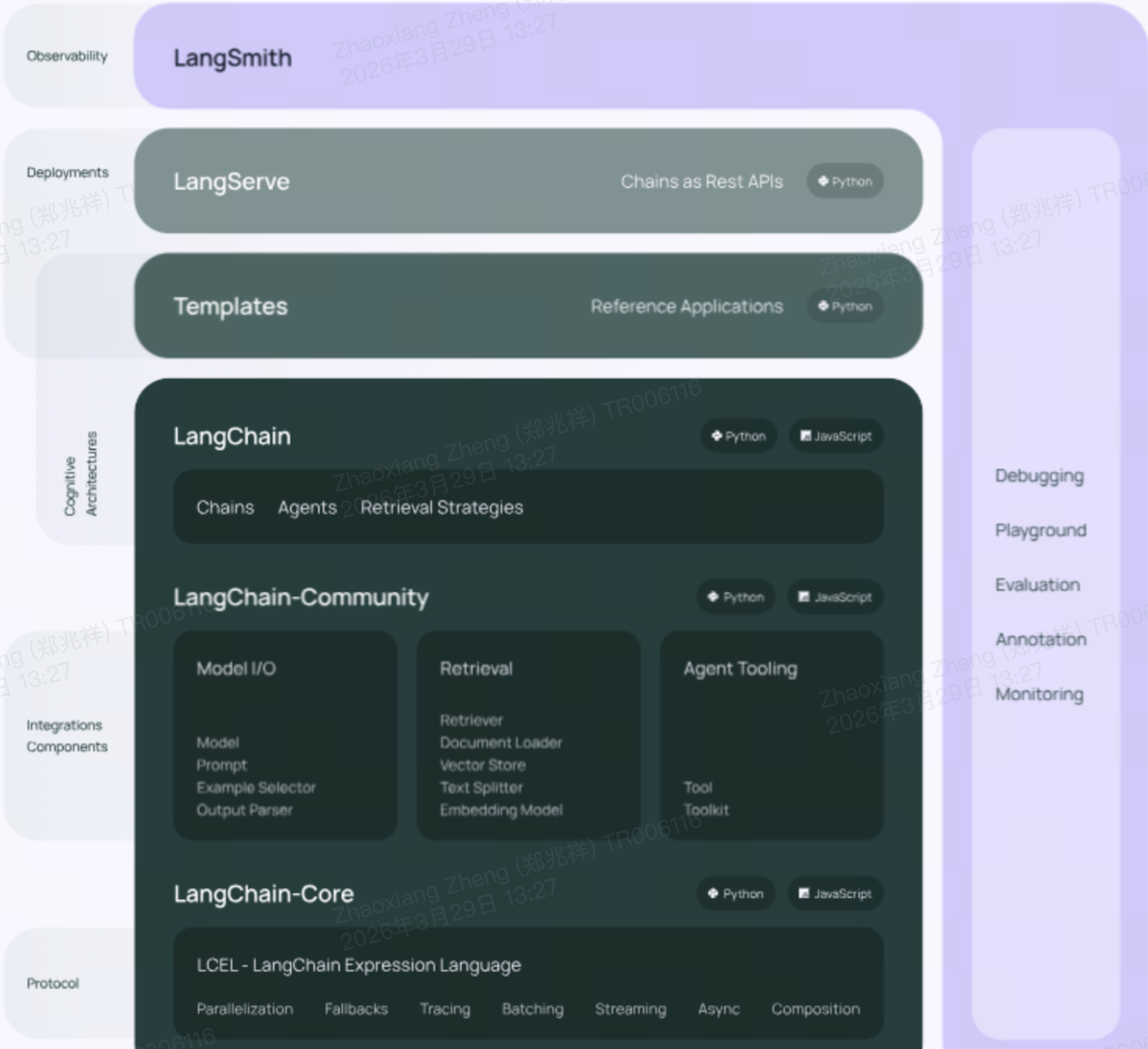
- 全生命周期工具:Debug、Playground、Prompt 管理、测试、监控,是你们排查 Agent 决策问题、优化业务规则的利器。
4.2.2 LangGraph
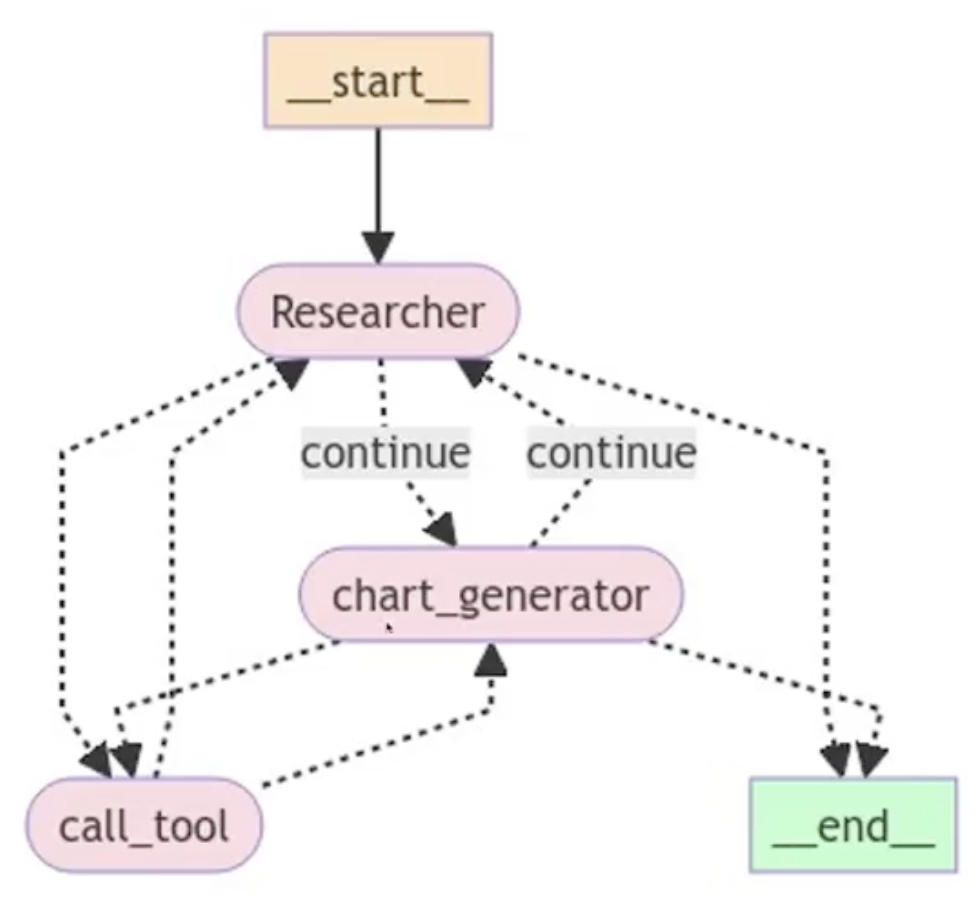
使用 LangGraph 构建两个 Agent 协作流程
workflow = StateGraph(AgentState)
workflow.add_node("Researcher", research_node)
workflow.add_node("chart_generator", chart_node)
workflow.add_node("call_tool", tool_node)
workflow.add_conditional_edges(
"Researcher",
router,
{"continue": "chart_generator", "call_tool": "call_tool", "__end__": END},
)
workflow.add_conditional_edges(
"chart_generator",
router,
{"continue": "Researcher", "call_tool": "call_tool", "__end__": END},
)
workflow.add_conditional_edges(
"call_tool",
# Each agent node updates the 'sender' field
# the tool calling node does not, meaning
# this edge will route back to the original agent
# who invoked the tool
lambda x: x["sender"],
{
"Researcher": "Researcher",
"chart_generator": "chart_generator",
},
)
workflow.add_edge(START, "Researcher")
graph = workflow.compile()
4.2.3 LlamaIndex
LlamaIndex (GPT Index) 是一个为 LLM 应用程序量身打造的数据框架,它提供了数据连接器、数据结构化工具、高级检索接口,以及与外部应用框架的集成能力,使企业能够将其数据资产高效地集成和转换为生产级别的智能应用。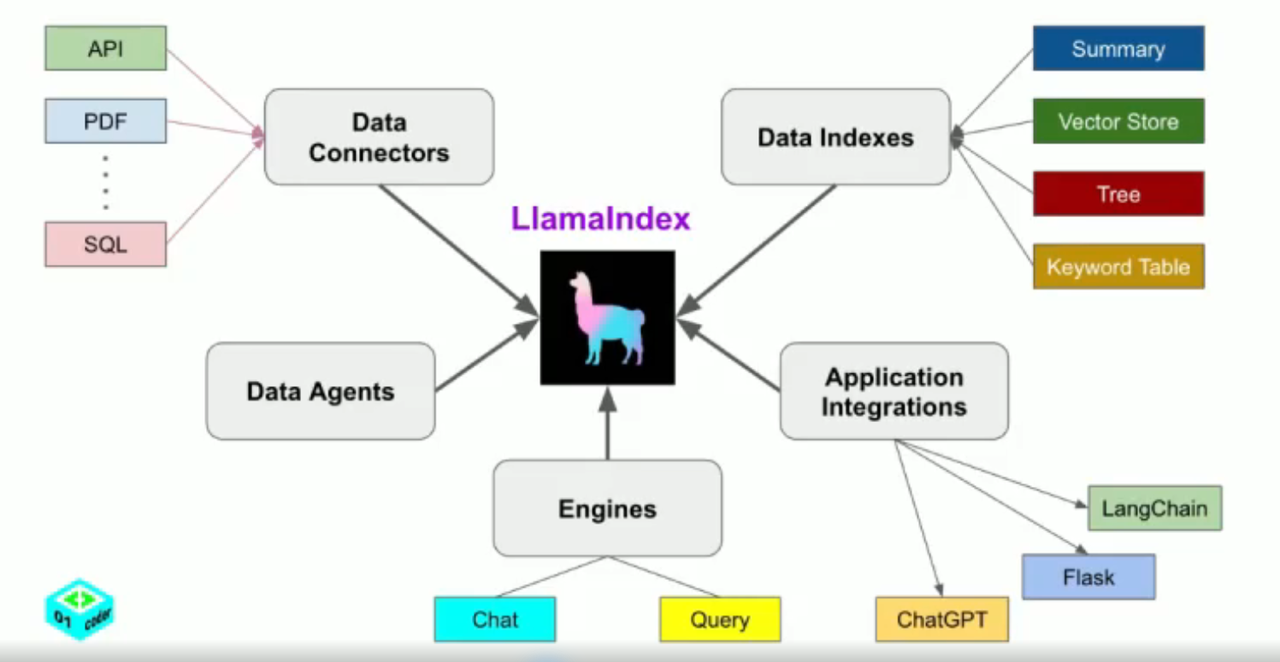
4.2.4 Semantic Kernel
Semantic Kernel 是一个由 Microsoft 开源的,旨在帮助开发者轻松集成和使用 LLMs 等 AI 技术的开发框架,从而提升应用程序的智能交互和处理能力。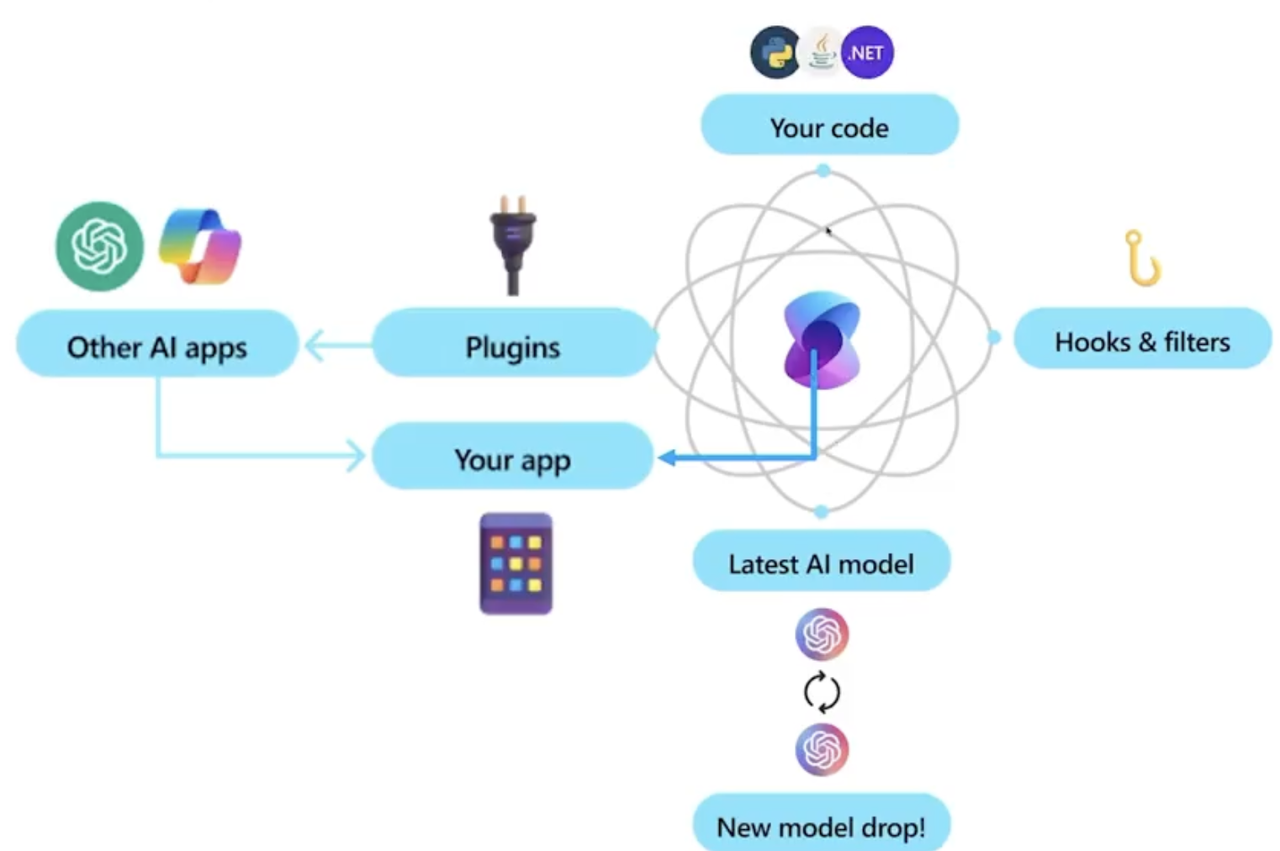
5. Agent 生产部署平台
5.1 Agent Hosting:Ollama
Ollama 开源项目提供了一套用于下载、运行和管理 LLMs 的工具和服务,是 Hosting 领域最受关注的项目之一。
5.1.1 命令行(CLI)方式
这是最常用的方式,直接在终端中执行命令来管理和运行模型:
| 操作 | 命令示例 | 说明 |
|---|---|---|
| 创建模型 | ollama create mymodel -f ./Modelfile |
从一个 Modelfile 文件创建自定义模型 |
| 拉取模型 | ollama pull llama3.1 |
下载或更新模型,仅拉取差异部分以节省带宽 |
| 移除模型 | ollama rm llama3.1 |
删除本地已下载的模型 |
| 复制模型 | ollama cp llama3.1 my-model |
复制一个已有的模型 |
| 启动服务 | ollama serve |
启动 Ollama 服务,用于后台运行模型 |
| 运行模型 | ollama run llama3.1 |
直接在终端中与模型进行交互对话 |
| 多行输入 | 使用 """""" 包裹文本 |
支持多行输入,例如:>>> """Hello,... world!""" |
5.1.2 REST API 方式
Ollama 提供了 RESTful API,可以通过 HTTP 请求来远程调用和管理模型:
| 操作 | API 示例 | 说明 |
|---|---|---|
| 生成响应 | curl http://localhost:11434/api/generate -d '{<br> "model": "llama3.1",<br> "prompt": "Why is the sky blue?"<br>}' |
向模型发送提示并获取生成的文本响应 |
| 聊天交互 | curl http://localhost:11434/api/chat -d '{<br> "model": "llama3.1",<br> "messages": [<br> { "role": "user", "content": "Why is the sky blue?" }<br> ]<br>}' |
以多轮对话的方式与模型交互 |
| 本地构建运行 | 1. ./ollama serve2. ./ollama run llama3.1 |
先启动服务,再在独立终端中运行模型 |
5.1.3 核心区别
- CLI 方式:适合本地开发、调试和快速测试,操作直观。
- REST API 方式:适合将 Ollama 集成到其他应用或服务中,实现远程调用和自动化流程。
5.2 Agent Hosting:LangServe
LangServe 提供了将 LangChain 应用快速部署为 REST API 的能力,同时集成了 FastAPI 和 pydantic 数据验证功能。
LLM Server(服务端)
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes
# 初始化 FastAPI 应用
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple api server using Langchain's Runnable interfaces",
)
# 1. 部署 OpenAI 模型为 API
add_routes(
app,
ChatOpenAI(model="gpt-3.5-turbo-0125"),
path="/openai",
)
# 2. 部署 Anthropic Claude 模型为 API
add_routes(
app,
ChatAnthropic(model="claude-3-haiku-20240307"),
path="/anthropic",
)
# 3. 部署自定义链(提示词 + 模型)为 API
model = ChatAnthropic(model="claude-3-haiku-20240307")
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes(
app,
prompt | model, # 组合提示词和模型
path="/joke",
)
# 启动服务
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
客户端调用事例
from langchain.schema import SystemMessage, HumanMessage
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langserve import RemoteRunnable
# 连接远程服务
openai = RemoteRunnable("http://localhost:8000/openai/")
anthropic = RemoteRunnable("http://localhost:8000/anthropic/")
joke_chain = RemoteRunnable("http://localhost:8000/joke/")
# 1. 同步调用远程链
joke_chain.invoke({"topic": "parrots"})
# 2. 异步调用远程链
await joke_chain.ainvoke({"topic": "parrots"})
# 3. 流式输出
prompt = [
SystemMessage(content='Act like either a cat or a parrot.'),
HumanMessage(content='Hello!')
]
async for msg in anthropic.astream(prompt):
print(msg, end="", flush=True)
# 4. 组合提示词模板
prompt = ChatPromptTemplate.from_messages(
[("system", "Tell me a long story about {topic}")]
)
# 5. 自定义链(同时调用多个远程服务)
chain = prompt | RunnableMap({
"openai": openai,
"anthropic": anthropic,
})
# 6. 批量调用
chain.batch([{"topic": "parrots"}, {"topic": "cats"}])
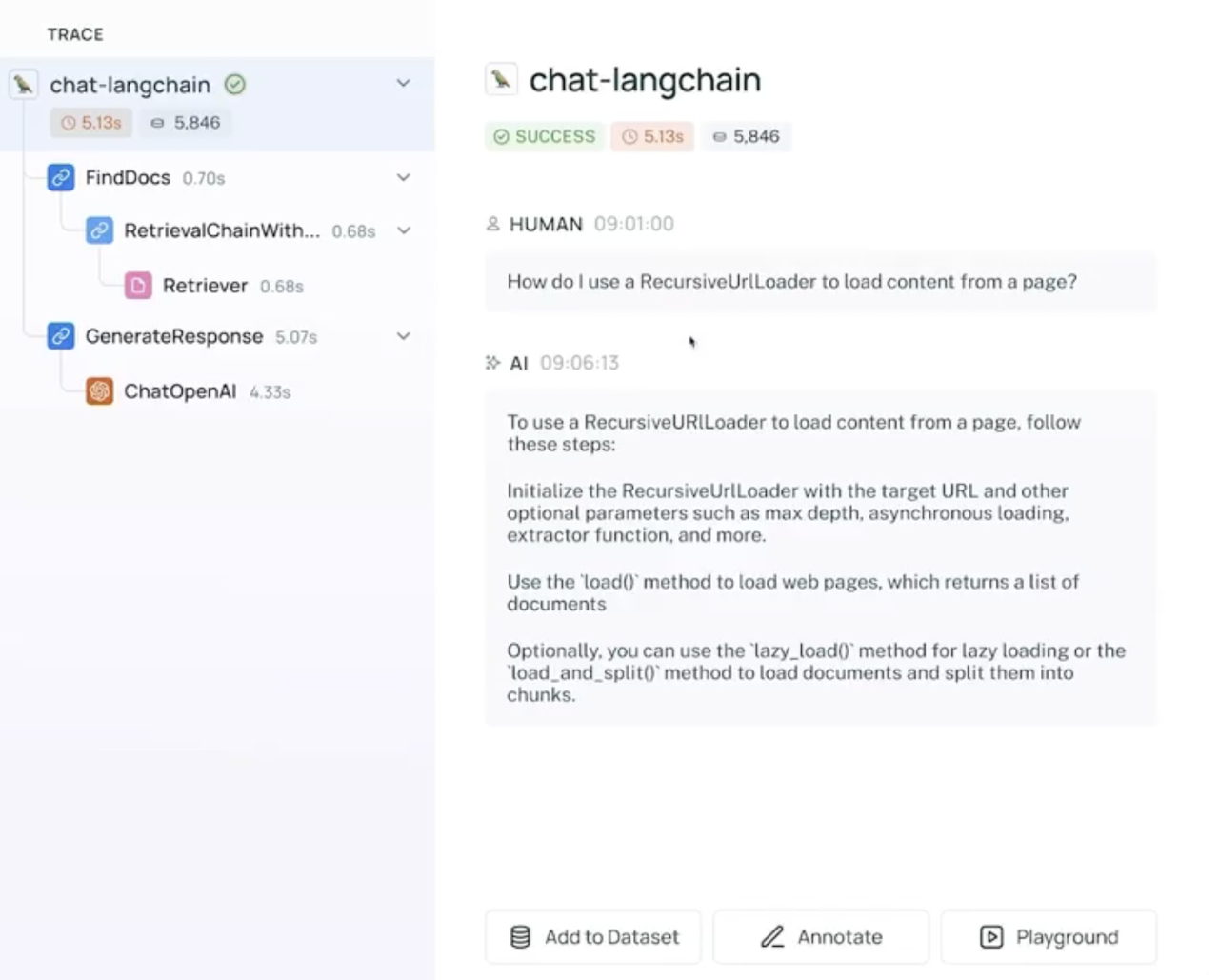
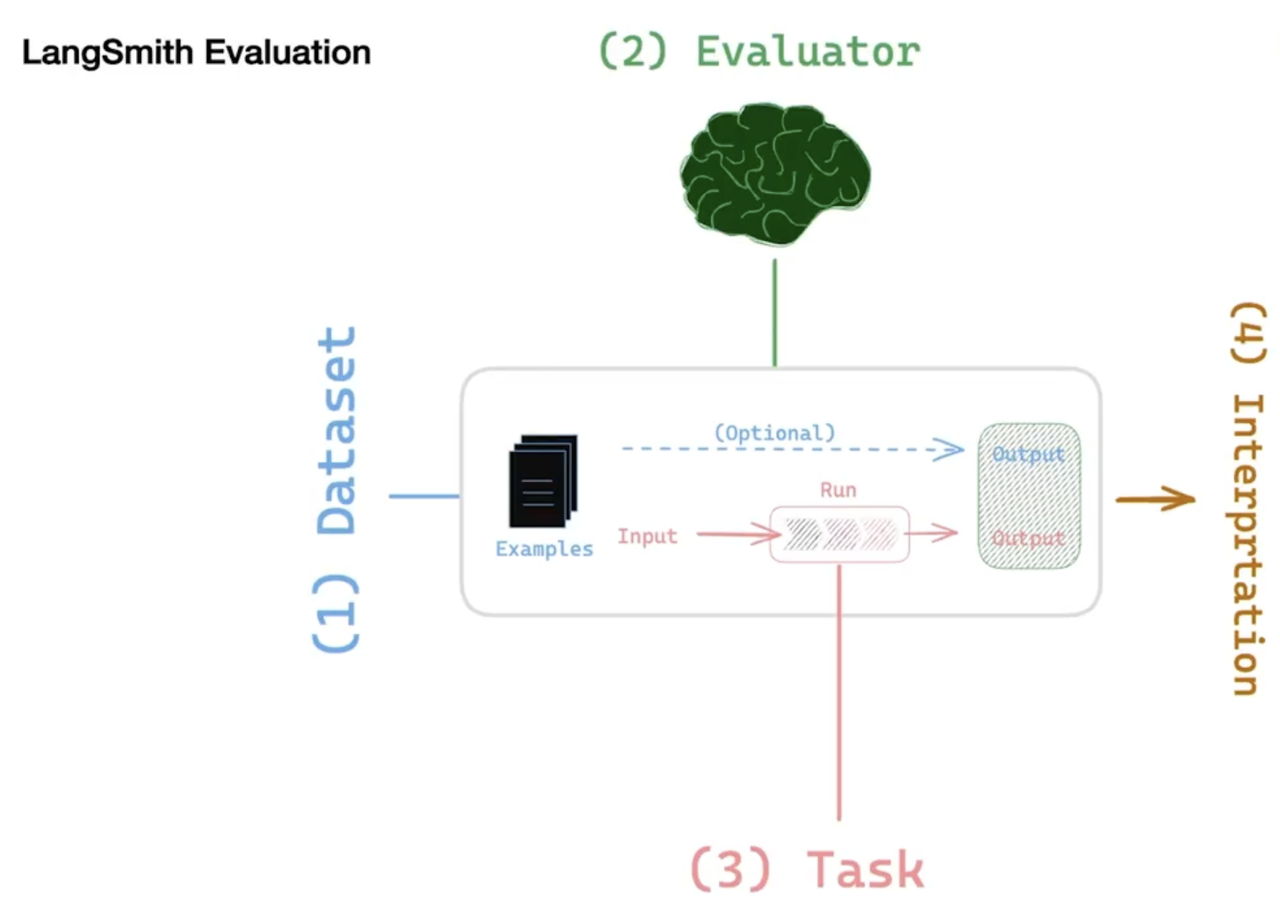
5.3 Evaluation:LangSmith
LangSmith 是一个提供可视化监控和全面评估 LLM 应用的平台,适用于复杂 Agent 的调试和调用链路跟踪,可独立于 LangChain 单独使用。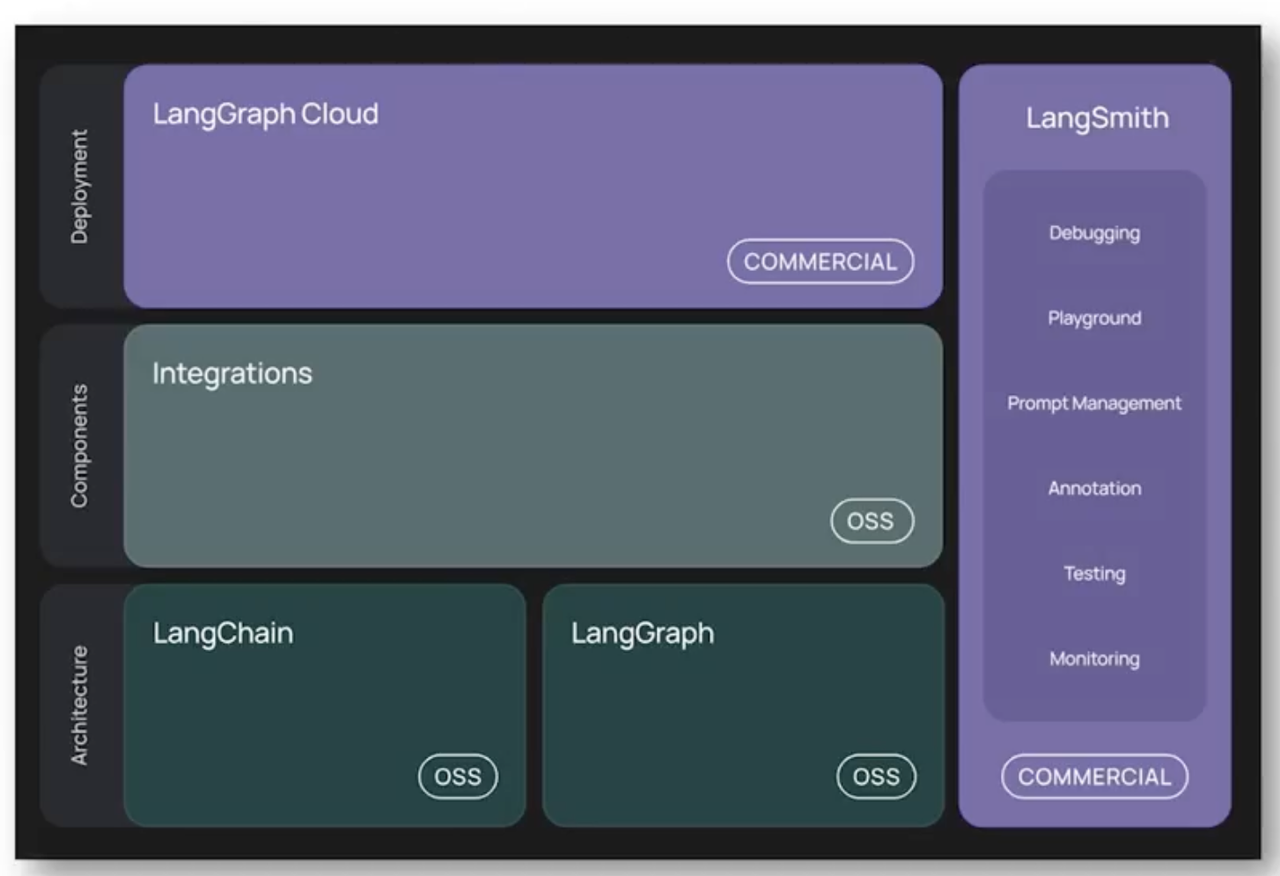

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)