【Dify】环境配置和接入大模型
文章目录
Dify 是一个非常强大且流行的开源大语言模型(LLM)应用开发平台(通常被称为 LLMOps 平台)。
其核心目的在于:让开发者(甚至是不懂代码的业务人员)能够以极快的速度,把复杂的 AI 模型变成真正可落地的应用程序。
一、 环境配置概述
具体的安装步骤可以参考官方文档或网络教程。本章节重点在于帮助你理清:为了运行 Dify,我们下载的这些核心组件到底是在帮我们做什么?
1. Docker:大名鼎鼎的“集装箱”技术
Docker 是一个应用容器引擎,它的核心作用是:解决“在我的电脑上运行得好好的,为什么到你的电脑上就报错”的环境不一致问题。
💡 它的三大核心特性
- 📦 打包一切: 它把一个软件,以及运行这个软件所需的全部依赖(比如特定版本的 Python、数据库、系统插件等)全部打包在一起,做成一个静态的“镜像”(Image)。
- 🌍 到处运行: 只要你的电脑上安装了 Docker,你就可以直接运行这个镜像,它会变成一个独立的“容器”(Container)。无论是 Windows、Mac 还是 Linux 服务器,运行效果完全一模一样。
- 🔒 完全隔离: 每个容器都是独立的。你可以在电脑上同时运行 10 个不同版本的数据库,它们绝不会发生冲突,安全且干净。
Docker 的三大核心概念
| 核心概念 | 本质定义 | 形象比喻 | 状态特征 |
|---|---|---|---|
| 镜像 (Image) | 包含运行软件所需一切的只读模板。包括精简操作系统、环境配置、代码等。 | 月饼模具 或 建筑设计图纸 | 静态的、死的东西。不能直接运行,无法直接与之交互。 |
| 容器 (Container) | 镜像的运行实例。在镜像上加了一个“可写层”,是真正跑起来的程序。 | 压出来的月饼 或 照着图纸盖好的房子 | 动态的、活的。可启动、停止、删除。容器间彼此独立,修改容器不影响镜像。 |
| 镜像仓库 (Registry) | 存放和分享各类镜像的集中营。 | 手机 App Store 或 模具批发市场 | 托管服务。可以从中拉取(Pull)别人做好的镜像,或推送(Push)自己的镜像。 |
🌐 知名仓库: Docker Hub 是全球最大的官方公开仓库。国内常用的有阿里云、腾讯云等提供的镜像加速仓库。
Docker 的运行底层与架构对比
Docker 容器直接运行在宿主机(也就是你的物理电脑或服务器)的操作系统内核上,它与传统的虚拟机有着本质的区别。
❌ 传统虚拟机架构(笨重、资源浪费)
如果你在 Windows 上通过 VMware 装了一个 Ubuntu 虚拟机,它的层级是:
物理电脑 ➔ Windows 系统 ➔ VMware 软件 ➔ 虚拟出的硬件 ➔ 完整的 Ubuntu 操作系统(含独立内核) ➔ 你的程序
- 缺点: 哪怕你只想跑一个 10MB 的小程序,你都要为它虚拟出一整套完整的操作系统,白白浪费几个 GB 的内存和大量的 CPU 资源。启动它就像重新开一次机一样慢。
✅ Docker 容器架构(轻量、极致高效)
Docker 极其聪明,它不虚拟任何硬件,也不自带操作系统内核。它直接共享(复用)你物理电脑的操作系统内核:
物理电脑 ➔ 宿主机操作系统(如 Linux) ➔ Docker 引擎(利用 Namespaces 隔离与 Cgroups 限制) ➔ 容器(程序 + 零碎依赖)
- 优点: Docker 只是在你的系统里“圈了一块地”来实现环境隔离,不虚拟硬件,不重写内核。因此,容器启动只需要 0.几秒,且几乎不消耗额外的内存!
❓ Windows / Mac 怎么用 Linux 内核?
当你安装 Docker Desktop(桌面版)时,Docker 会在后台默默运行一个极其微型的 Linux 虚拟机(只占用极少资源),所有的容器其实都是在这个微型 Linux 上运行的,以此实现跨平台。
常用命令速览
| 分类 | 命令 | 说明 |
|---|---|---|
| 镜像相关 | docker images |
列出本地所有镜像 |
docker pull <镜像名>:<标签> |
从仓库拉取镜像(标签默认 latest) | |
docker push <镜像名>:<标签> |
将镜像推送到远程仓库 | |
docker rmi <镜像ID或名称> |
删除本地镜像 | |
docker build -t <名称>:<标签> <路径> |
根据 Dockerfile 构建镜像 | |
docker tag <源镜像> <目标镜像> |
给镜像打标签 | |
| 容器相关 | docker ps |
列出运行中的容器(加 -a 查看所有) |
docker run <镜像名> |
创建并启动容器(常用参数:-d 后台,-p 端口映射,-v 挂载卷,--name 命名) |
|
docker start/stop/restart <容器名> |
启动/停止/重启容器 | |
docker rm <容器名> |
删除容器(加 -f 强制删除运行中的) |
|
docker exec -it <容器名> <命令> |
在运行中的容器内执行命令(如 bash) |
|
docker logs <容器名> |
查看容器日志(加 -f 实时跟踪) |
|
docker inspect <容器名或镜像名> |
查看容器/镜像的详细信息(JSON 格式) | |
| 仓库相关 | docker login |
登录到 Docker Hub 或私有仓库 |
docker logout |
退出登录 | |
docker search <关键词> |
在 Docker Hub 上搜索镜像 | |
| 系统/清理 | docker version |
显示 Docker 版本信息 |
docker info |
显示 Docker 系统信息 | |
docker system prune |
清理未使用的容器、网络、镜像(加 -a 更彻底) |
|
docker container prune |
删除所有停止的容器 | |
docker image prune |
删除未使用的镜像 | |
| 卷与网络 | docker volume ls |
列出所有卷 |
docker network ls |
列出所有网络 | |
docker network create <名称> |
创建自定义网络 | |
| 组合命令 | docker-compose up -d |
后台启动 docker-compose.yml 定义的服务 |
docker-compose down |
停止并删除服务相关的容器、网络(加 -v 删除卷) |
|
docker-compose logs -f |
查看组合日志 |
💡 提示:大部分命令可通过
--help查看详细参数,例如docker run --help。
🚀 完整运转流程:从一行命令到应用上线
当我们输入一行运行命令时,Docker 底层是如何将上述概念串联起来的?
【 用户输入命令:docker run nginx 】
│
▼
【 1. 本地检查 】
┌─────────────┴─────────────┐
( 否 ) ( 是 ) 硬盘里有 Nginx 镜像吗?
│ │
▼ ▼
【 2. 仓库拉取 】 【 3. 实例化容器 】
从 Docker Hub 下载 以镜像为模具,在内存中
Nginx 镜像到本地 ────────> 瞬间“啪”地捏出一个容器
│
▼
【 4. 应用成功运行 】
网站服务秒级上线!
2.Ollama:本地大模型的“一键运行器”
Ollama 是什么?
如果说前面介绍的 Docker 是“跑任何应用的集装箱”,那 Ollama 就是专门为大语言模型(LLM)打造的“一键运行器”。
Ollama 是一款开源的本地大语言模型部署工具,旨在简化 LLM 的运行和管理。通过简单的命令行操作,你就能在自己的电脑上运行 Llama 3、Qwen(通义千问)、Mistral、DeepSeek 等主流开源大模型,无需复杂的环境配置。它支持 Windows、macOS 和 Linux 跨平台运行,安装后通过 Ollama 内置的 REST API 就能轻松接入其他应用。
为什么选择 Ollama?—— 核心优势
对于想要在本地尝试大模型的开发者来说,Ollama 相比传统部署方式有明显优势:
| 优势 | 说明 |
|---|---|
| 开箱即用 | 无需手动配置 Python 环境、CUDA 或 PyTorch 等深度学习框架,Ollama 内置了所有运行依赖 |
| 零代码部署 | 通过单行命令即可完成模型的下载与运行,真正实现“一行命令跑 LLM” |
| 资源友好 | 最低仅需 4GB 内存即可运行基础模型,普通笔记本也能流畅体验 |
| 隐私安全 | 所有计算均在本地完成,数据无需上传云端,适合处理敏感信息 |
| 离线可用 | 下载好模型后,拔掉网线也能和 AI 聊天 |
| API 集成 | 提供标准 REST API 接口(默认端口 11434),可像调用云端 API 一样快速接入 Dify 等应用 |
安装指南(全平台)
| 操作系统 | 安装方式 |
|---|---|
| Windows | 访问 ollama.com 下载安装包(.msi),双击运行,确保勾选“添加到 PATH” |
| macOS | 访问官网下载 .zip 文件,解压后将 Ollama 拖入“应用程序”文件夹,双击运行 |
| Linux | 执行一键安装脚本:`curl -fsSL https://ollama.com/install.sh |
安装完成后,打开终端(Windows 用 CMD 或 PowerShell),执行以下命令验证:
ollama --version
若能正常输出版本号(如 ollama version 0.1.15),说明安装成功。
Ollama 常用命令表格
| 分类 | 命令 | 说明 |
|---|---|---|
| 模型操作 | ollama pull <模型名> |
从仓库拉取模型到本地(如 ollama pull llama3) |
ollama run <模型名> |
运行模型,自动下载(若本地无),并进入交互式对话 | |
ollama list 或 ollama ls |
列出本地已下载的所有模型 | |
ollama ps |
查看当前正在运行的模型 | |
ollama show <模型名> |
显示模型的详细信息(参数、模板等) | |
ollama cp <源模型> <目标模型> |
复制模型(可用于基于原模型创建自定义版本) | |
ollama rm <模型名> |
删除本地模型,释放磁盘空间 | |
| 服务管理 | ollama serve |
启动 Ollama API 服务(后台运行,监听 11434 端口) |
ollama stop <模型名> |
停止正在运行的模型 | |
| 自定义模型 | ollama create <模型名> -f <配置文件> |
通过 Modelfile 创建自定义模型 |
ollama push <模型名> |
将自己创建的模型推送到仓库 | |
| 辅助命令 | ollama --version |
显示 Ollama 版本信息 |
ollama --help |
显示所有命令的帮助信息 |
💡 首次运行提示:当你第一次执行
ollama run llama3时,系统会自动下载模型文件(大小通常 3-15GB),下载进度条走完后即可进入交互对话。你也可以在 Ollama 官方模型库 查看所有可用模型。
二,本地接入和API接入
在配置完Docker之后,我们就可以通过http://localhost/apps在浏览器中看到Dify了。
但是现在我们还没有接入大模型,所以在设置里面,需要手动配置模型供应商。
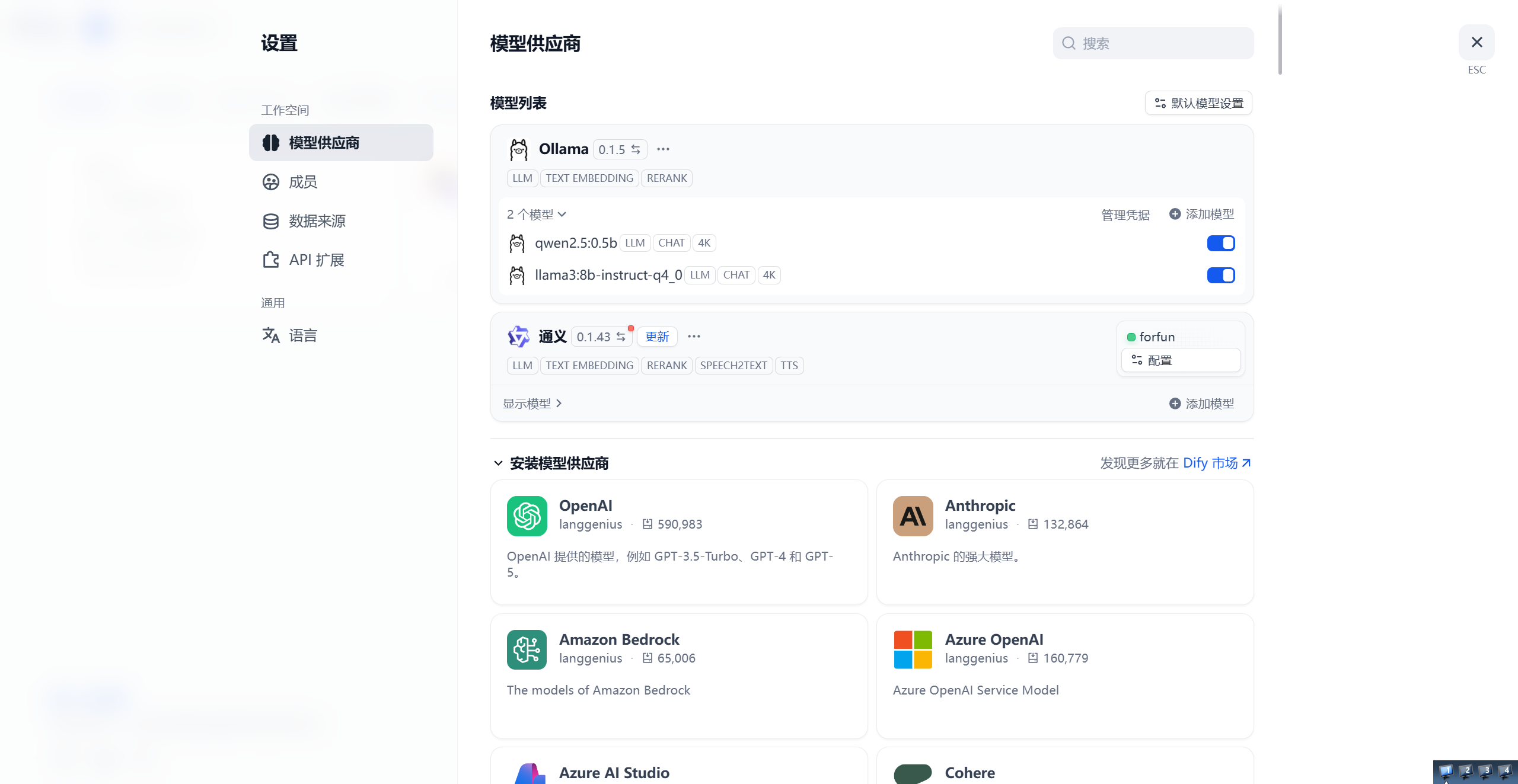
1.本地部署
我们下载的Ollama 负责在本地“跑起”大模型,Dify 负责“用好”大模型。
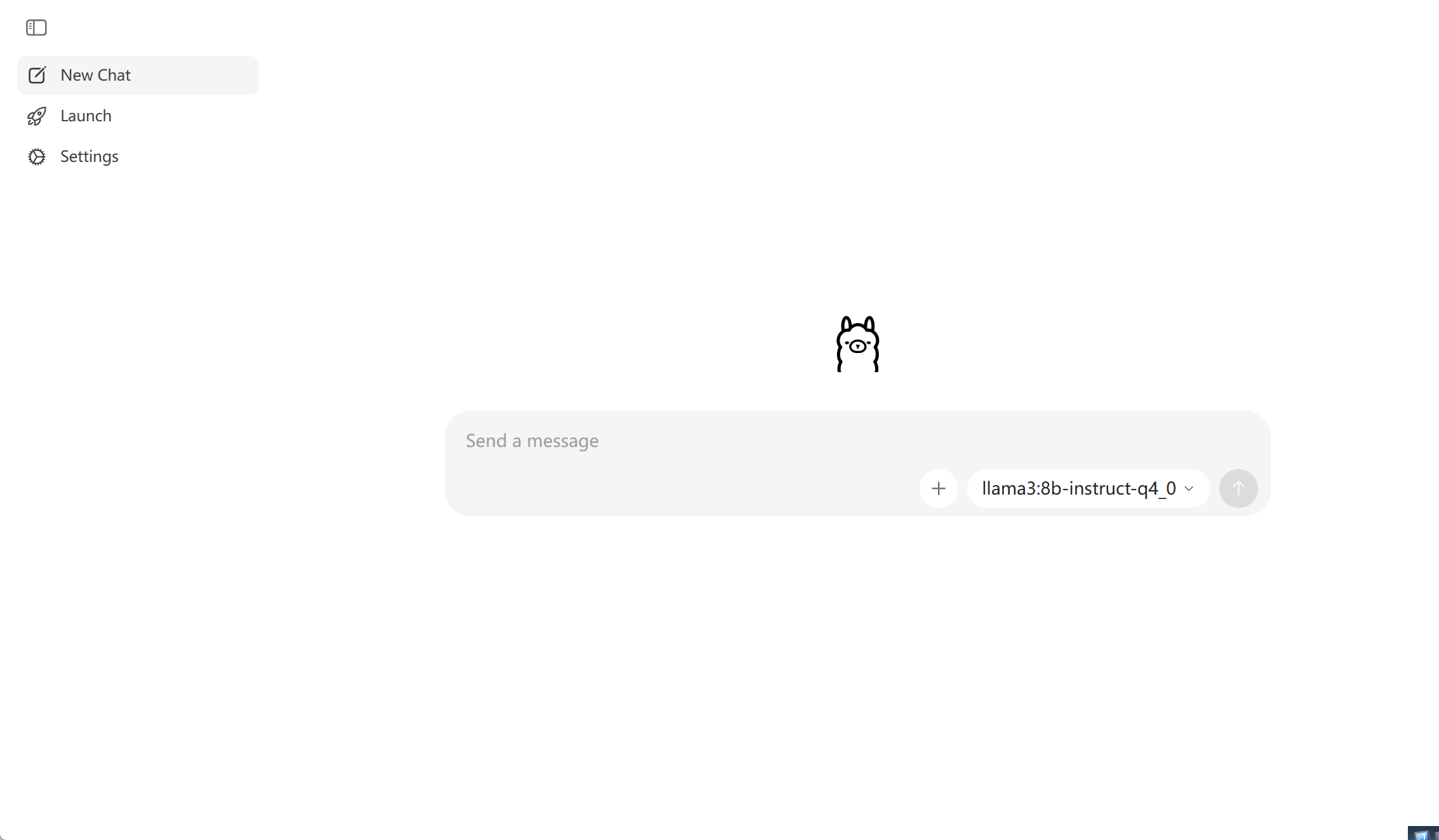
- 在Ollama中已经下载了一个大模型,通常选择较小的模型比较好。(如下图,在右下角选择模型之后,在聊天框中输入第一次对话就会自动下载,或者在命令窗口执行 Ollama run <模型名>,第一次也会自动下载)
-
在模型供应商中下载Ollama,并在弹窗中填入模型名称和URL
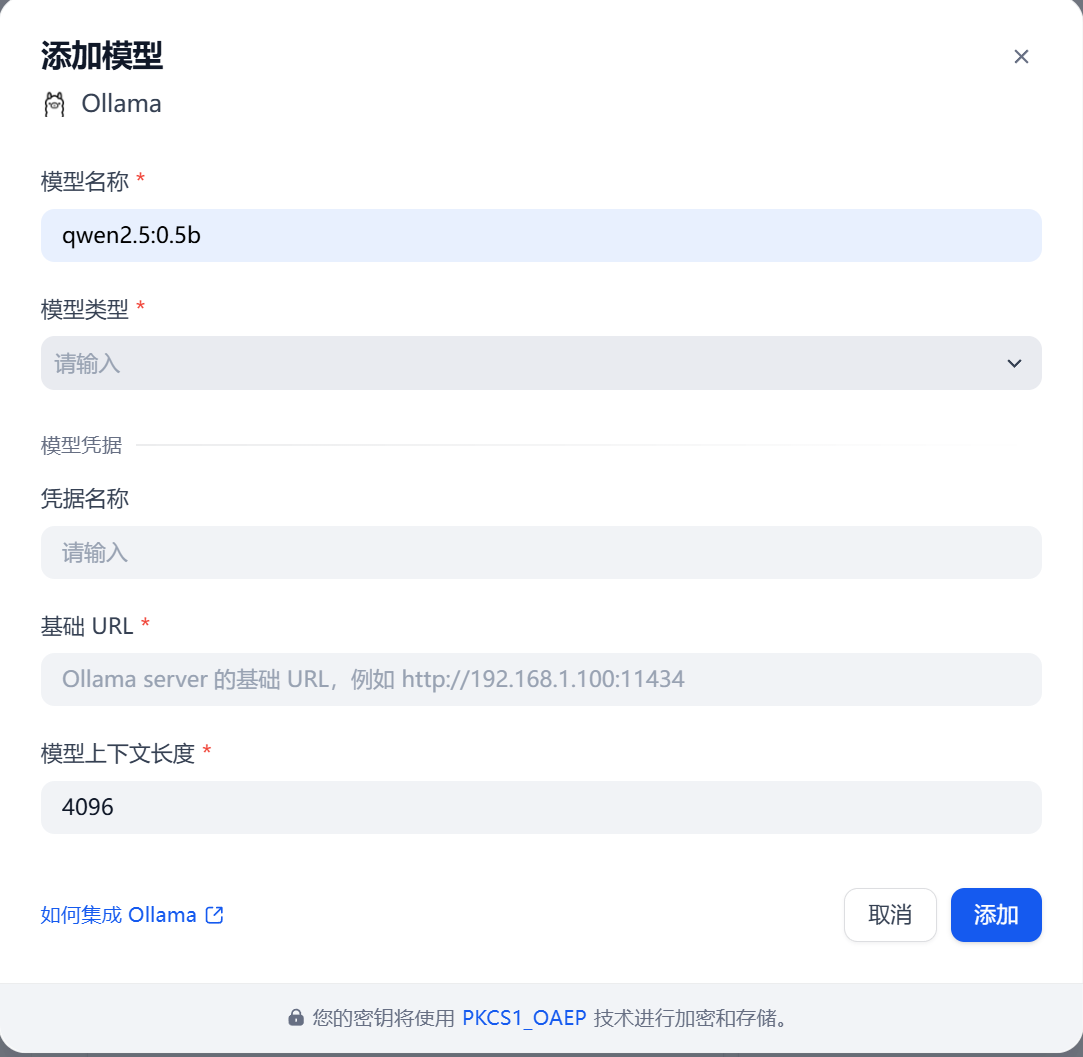
模型名称:你在 Ollama 中实际下载并运行的模型精确名称。
模型类型:点击下拉菜单,根据你这个模型的用途进行选择。(如果是普通的聊天、对话、推理模型(如 Llama, Qwen, DeepSeek),选LLM)
凭据名称:给这个连接起一个辨识用的别名。
基础 URL:你的部署场景 推荐填写的基础 URL 同机直接运行(Dify 和 Ollama 都直接在系统运行,未使用 Docker) http://localhost:11434或http://127.0.0.1:11434Docker 部署 Dify(Ollama 安装在 Windows / Mac 宿主机上) http://host.docker.internal:11434Docker 部署 Dify(Ollama 安装在 Linux 宿主机上) http://172.17.0.1:11434跨设备/局域网访问(Ollama 在另一台电脑或服务器上) http://<Ollama服务器的局域网IP>:11434
(例如:http://192.168.31.50:11434)
上下文长度:该模型单次对话能处理的最大 Token 数量。
配置好后就可以在dify中创建一个空白应用来测试了!
2.接入API大模型
在阿里云百炼中,大部分模型都有免费额度,我们可以创建一个API key,并像上面下载Ollama那样下载通义的供应商。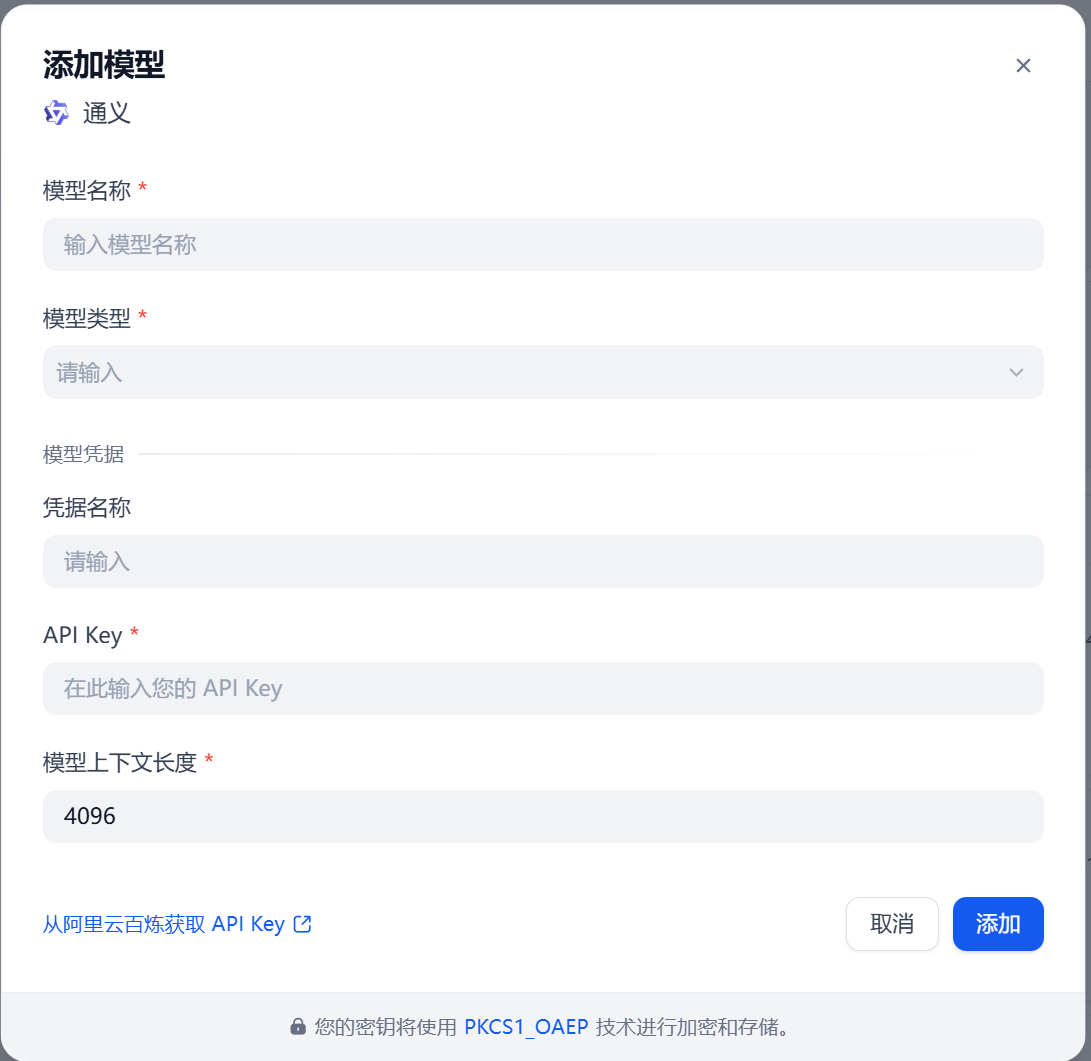
其它都一样,API key就填我们复制的那个。
自此,我们已经在本地部署了Dify,并且学会了如何通过本地和API接入大模型。
接下来我们就要了解【 提示词和知识库】,学习如何通过它们来让ai生成的回答更加准确。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)