医学研究员开始用 Claude Code 写代码了,而且有点停不下来
开门见山:这不是"AI 帮你查文献"那种入门文章
去年我在金融行业做量化的时候,总觉得生物医学研究员是一个神秘的群体——他们写的代码,我懂; 他们研究的问题,我不懂。基因组、RNA 测序、单细胞聚类……这些词让我想起了高中生物课上画的 那些七扭八歪的双螺旋,和我考试的分数一样扭曲。
但最近,这两个世界的交界点突然变得很有意思:医学研究员开始大量使用 Claude Code 了, 而且用法已经远远超出"帮我解释一下这段 Python 报错"的水平。
2026年以来,从 Anthropic 发布 Claude for Life Sciences(2025年10月)、 再到 Claude for Healthcare(2026年1月 J.P. Morgan 大会正式上线), 再到 2026年4月29日 Anthropic 发布 BioMysteryBench 评测结果—— 一条清晰的线索已经浮现:Claude Code 正在成为医学科研实验室的标配工具之一。
这篇文章,我来认真讲讲这件事的技术内核、数据支撑和使用边界。
国内使用Claude Code确实有一些门槛,可以参考一个还算靠谱的订阅网站:claudemax.shop
先说数据,因为我知道你们不信"AI 革命生物医学"这种标题
Claude 在生信领域到底有多强?
Anthropic 研究团队在 2026年4月29日(就是半个多月前)发布了 BioMysteryBench 评测结果, 这是迄今为止最严格的生物信息学 AI 能力测试之一:
BioMysteryBench 由领域专家设计了 99 道生信题目,每道题都有客观的唯一正确答案, 基于真实实验数据推导而来。Claude 在隔离容器中完成任务,可以调用标准生信工具、 通过 pip/conda 安装额外工具,还能访问 NCBI 和 Ensembl 等真实数据库。
结果怎么样?
- Claude Opus 4.6 在 BixBench(100道计算生物学任务)上整体准确率达到 81%, 最难题目也有 69%
- Protocol QA 基准测试中,Claude Sonnet 4.5 得分 0.83,超过人类基准线 0.79 (旧版 Sonnet 4 是 0.74,一代模型进步显著)
- 在某些"人类难以作答"的题目上,Claude 已经超过了由 5 名领域专家组成的专家小组
Anthropic 研究员在报告里写道,这些模型"不再只是跟上训练有素的科学家;在某些任务上, 它们已经领先了"。这句话如果放在 3 年前,任何一家 AI 公司说出来都会被当成 PPT 吹水。 现在有基准数据撑腰,我选择认真对待它。
Claude Code 在医学科研中的真实用法
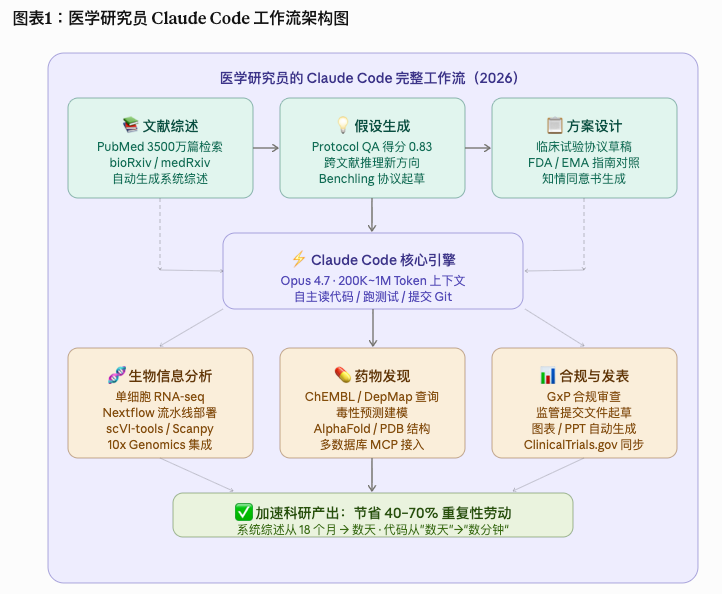
我翻了大量实际案例,把医学研究员使用 Claude Code 的场景整理成了一张完整的工作流图 (见正文配图)。以下是几个最有代表性的真实案例。
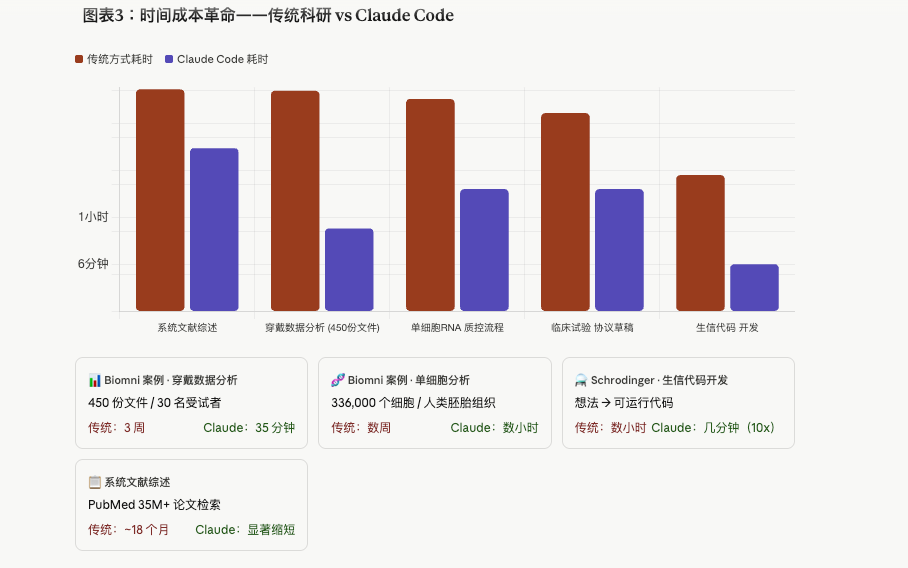
案例一:35分钟完成3周的工作
Biomni(一个基于 Claude 构建的科研 AI 系统)完成了一个让人下巴掉地上的案例:
用 Claude 分析了 30名受试者、450份穿戴设备数据文件(包含连续血糖监测、 体温、运动数据)。完成时间:35分钟。人类专家的预估时间:3周。
同一套系统,还处理了人类胚胎组织中 336,000个单细胞的基因活性数据, 不仅确认了科学界已知的调控关系,还识别出了之前没人注意到的转录因子—— 那些控制基因开关的蛋白质。在生物医学研究里,这不叫"加快了分析速度", 这叫"发现了新东西"。
案例二:分子克隆实验设计,媲美5年经验博士后
Biomni 还测试了另一个盲测场景:设计分子克隆实验协议。 评估结果显示,AI 给出的方案在协议完整性和实验设计质量上, 与一名拥有超过 5 年经验的博士后相当。
这个对比让我想起了金融行业的量化策略生成。过去我们花几个月调参的策略, 现在 AI 能在几小时内给出一个"差不多能用"的初版——人类的价值在于判断、修正、 承担责任,而不是从零打字。医学研究员正在面对同样的范式转变。
案例三:Schrodinger——10倍速代码开发
Schrodinger(知名药物设计软件公司)的 CTO Pat Lorton 在官方声明中表示, Claude Code 在最适合的项目上,能让他们从想法到可运行代码的速度提升约10倍。
"从小时到分钟",这四个字说起来容易,但如果你做过生信流水线开发, 你知道一个 RNA-seq 分析管道从写脚本到跑通,过去少则半天、多则数天。 现在呢?描述需求,等几分钟。
案例四:MozzareLLM——Claude 发现了其他模型认为是"随机噪音"的东西
麻省理工的 Di Bernardo 实验室构建了 MozzareLLM(是的,就是那个奶酪), 用于基因组筛选中的基因发现。他们测试了多个 AI 模型,Claude 在一个关键任务中 正确识别了一条 RNA 修饰通路,而其他模型将其判断为随机噪音。
这不是"Claude 比较聪明"那种笼统的结论,而是领域特异性的推理能力差异—— 在生物信号中区分真实关联与统计噪音,本质上和量化里区分 alpha 信号和过拟合是一回事。
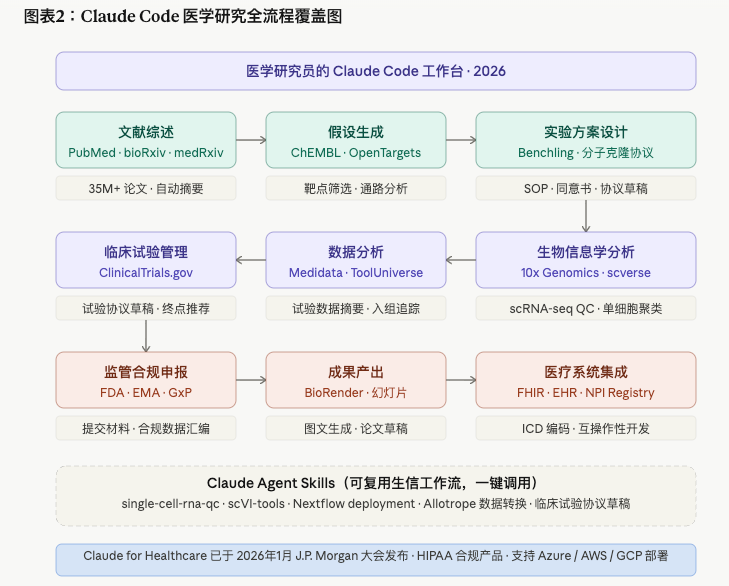
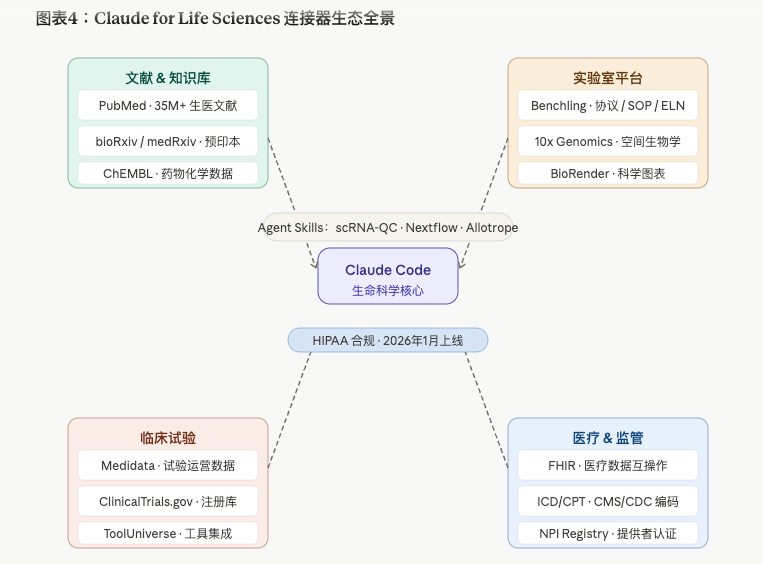
Claude for Life Sciences:连接器生态是真正的护城河
光有聪明的模型还不够。真正让医学研究员"离不开"的,是 Claude 背后的数据库连接器生态 (见正文配图:连接器全景图)。
截至 2026年5月16日,Claude for Life Sciences 支持连接的平台包括:
文献与知识库:
- PubMed:超过 3500万条生物医学文献,可直接检索引用并生成综述
- bioRxiv / medRxiv:预印本数据库,跟上最新研究前沿
- ChEMBL:药物化学数据库,服务靶点筛选和小分子分析
实验室平台:
- Benchling:电子实验室记录(ELN),可直接生成协议、SOP 和知情同意书草稿
- 10x Genomics:空间生物学和单细胞测序分析,过去需要命令行脚本的操作, 现在用自然语言就能执行
- BioRender:科学图表生成
临床试验:
- Medidata:临床试验运营数据,监控各试验点的表现和入组进度
- ClinicalTrials.gov:试验注册库
- ToolUniverse:科学工具集成
医疗与监管:
- FHIR(Fast Healthcare Interoperability Resources):医疗数据互操作标准, Claude 有专属 Agent Skill 加速系统间连接开发
- ICD/CPT 编码(来自 CMS 和 CDC):支持医疗编码、账单准确性和理赔管理
- NPI Registry:医疗提供者验证和资质认证
为什么这个生态很重要?
做过数据工程的人都知道,"能分析"和"能把数据弄进来"是两件完全不同的事。 一个博士生花在数据清洗、格式转换、API 调用上的时间,往往不亚于真正的科学分析。 Claude 把这些"脏活"通过连接器封装掉,研究员直接在 Claude 里问问题, 数据自动从正确的数据库拉进来——这才是效率提升的真正来源。
Agent Skills:把流水线变成一键调用
这是 2026年以来 Claude Code 在生命科学里最值得重点介绍的新功能。
Claude for Life Sciences 引入了 Agent Skills——可复用的生信工作流, 打包成"Claude 技能",一次配置、随时调用。
已发布的核心 Agent Skills 包括:
| Skill 名称 | 功能 |
|---|---|
single-cell-rna-qc |
单细胞 RNA 测序质控,基于 scverse 最佳实践,一键完成 |
scVI-tools |
单细胞变分推断工具包,预打包 |
Nextflow deployment |
生信管道部署和管理 |
Allotrope 数据转换 |
仪器数据转 Allotrope 数据格式(ADF)标准 |
临床试验协议草稿 |
生成包含终点推荐和监管考量的协议初稿 |
科学问题选择 |
帮助研究员识别和优先排序研究问题 |
2026年2月,Claude Code 2.1.0 发布,Skills 支持热重载(hot reloading)和 分叉子 Agent 上下文(forked sub-agent contexts),开发和测试 Skill 更加方便。
从工程角度看,这和金融行业的策略模板库是一个逻辑: 把高频重复的分析流程抽象成参数化的函数,新来的研究员不需要重新造轮子。 不同的是,这里的"轮子"是 RNA 质控和空间生物学分析,质量一致性更重要。
Claude for Healthcare:HIPAA 合规,终于可以进医院了
2026年1月,Anthropic 在 J.P. Morgan Healthcare Conference 上正式发布 Claude for Healthcare——这对整个医疗行业是个重大信号。
HIPAA 合规意味着什么?简单说:病人数据可以进入 Claude 的分析流程了。
具体包括:
- 医疗编码(ICD/CPT)查询,支持账单准确性和理赔管理
- 前置授权(Prior Authorization)审查
- 患者护理协调和分诊
- FHIR 互操作性开发
- 个人健康数据整合(医疗记录 + 穿戴设备 + 基因组数据), 且用户数据不用于模型训练
同月,EMA 和 FDA 联合发布了 AI 用于药品生命周期的 10 项共同原则, 这标志着监管机构正在为 AI 生成的 R&D 成果建立评估框架。 对制药行业来说,这条信号很重要:AI 辅助的临床材料,正在建立合法的使用路径。
AstraZeneca、Sanofi、Broad Institute、EvolutionaryScale…… 这些顶级机构的公开背书,不是 PPT 里的 logo 展示, 而是说明 Claude Code 已经在真实的 R&D 流程里跑起来了。
和金融行业的类比:你们比医学研究员早走了5年
做量化的朋友可能对以下这个体验很熟悉:
十年前,写个简单的因子回测要自己配环境、连数据库、写数据清洗逻辑, 然后才能开始真正的研究。现在有了因子研究平台、数据 API、回测框架, 研究员可以把 80% 的时间花在想法本身上,而不是数据管道。
医学研究员正在经历同样的转变,只是更晚、但速度更快。
Claude Code + Life Sciences 连接器,做的事情和 Wind + Tushare + Backtrader 在量化行业做的事情本质上是一样的:把研究员从"让数据可用"解放到"用数据思考"。
不同的地方在于:医学数据比金融数据更碎片化、隐私要求更高、 跨系统整合难度更大——而这正是 Claude Code 的 Agent 能力的优势所在。 它不只是查询工具,而是能跨多个系统联合推理的智能体。
我的判断:边界在哪里?
说了这么多好话,来说几句大实话。
Claude Code 在医学科研里的真实价值:
-
文献检索和综述:显著加速。传统 18 个月的系统综述,Claude 的辅助 可以大幅压缩到周量级(具体压缩多少取决于研究范围和质量要求)。
-
代码和分析管道:对非计算背景的湿实验室研究员帮助最大。 过去需要一个专职生信工程师的工作,现在一个有基础 Python 认知的研究员 配合 Claude Code 就能搞定。
-
协议和文档草稿:减少空白焦虑,提升初稿质量,但必须人工审核。 医学里的措辞精确性是生死攸关的事,不是"差不多可以"。
Claude Code 不能替代的:
-
科学判断和假设选择:模型会生成假设,但哪个假设值得花 3 个月验证, 这是科研直觉,不是推理能力。
-
结果解读和发表责任:模型可以发现 RNA 修饰通路,但论文作者署名的人, 要承担学术责任。Claude 不是你的共同作者,是你的工具。
-
监管申报的最终决策:Claude 能起草 IND(新药研究申请), 但最终对 FDA 签字负责的,是人。
-
真正的创新:像 AlphaFold 那样改变游戏规则的科学突破, 不是靠"加快工作流程"实现的。工具负责效率,创新靠洞见。
最后说一句
医学研究员和金融量化分析师,在我看来是这个时代最能"正确使用 AI"的两类人。
原因很简单:他们都有一个明确的衡量标准——量化有 Sharpe Ratio, 医学有 p 值和临床意义;他们都清楚自己的模型有边界; 他们都不会把"AI 给了一个答案"等同于"答案是正确的"。
Claude Code 在生命科学里的崛起,不是因为 AI 变得无所不能, 而是因为这群最挑剔的用户,找到了它确实能帮上忙的地方。
这才是 AI 落地的正确姿势。
点个赞,知乎算法才知道这篇文章对你有价值。有问题欢迎评论区对线,我几乎必回。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)